Deep Learning Accelerators
|
|
|
- Maurice Paul
- 5 years ago
- Views:
Transcription
1 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project
2 Outline Introduction Tensor Processing Unit (Google) TPU Architecture Evaluation Nvidia Tesla V100 Cloud TPU Eyeriss (MIT) What is Deep Learning? Why do we need Deep Learning Accelerators? A Primer on Neural Networks Convolutional Neural Networks (CNNs) Dataflow Taxonomy Eyeriss dataflow Evaluation How do Eyeriss and TPU compare? Many more DL accelerators References
3 Introduction




4 What is Deep Learning? Image Source: Google Images



5 Why do we need DL accelerators? DL models essentially comprise of compute intensive operations like matrix multiplication, convolution, FFT etc. Input data for these models is usually of the order of GBs Large amount of computation over massive amounts of data CPUs support computations spanning all kinds of applications, hence they are bound to be slower when compared to an application specific hardware CPUs are sophisticated due to their need to optimize control flow (branch prediction, speculation etc.) while Deep Learning barely has any control flow Energy consumption can be minimized with specialization 350k tweets / minute 350M images / day Sources: Twitter Facebook Youtube 300 hours of video / minute

6 A Primer on Neural Networks Matrix Multiplication
7 Tensor Processing Unit (Google)
![Tensor Processing Unit [TPU] Developed by Google to accelerate neural network computations Production-ready co-processor connected to host via PCIe Powers many of Google s services like Translate,](/docs-images/95/123058147/images/8-0.jpg "Search, Photos, Gmail etc. Why not GPUs?")
8 Tensor Processing Unit [TPU] Developed by Google to accelerate neural network computations Production-ready co-processor connected to host via PCIe Powers many of Google s services like Translate, Search, Photos, Gmail etc. Why not GPUs? GPUs don t meet the latency requirements for performing inference GPUs tend to be underutilized for inference due to small batch sizes GPUs are still relatively general-purpose Host sends instructions to TPU rather than the TPU fetching it itself TPU closer in spirit to a Floating Point Unit rather than a GPU
9 TPU Architecture Host sends instructions over PCIe bus into the instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators aggregate partial sums Weight Memory (WM) off-chip DRAM - 8 GB Weight FIFO (WFIFO) on-chip fetcher to read from WM Unified Buffer (UB) on-chip for intermediate values
10 TPU Architecture Host sends instructions over PCIe bus into the instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators aggregate partial sums Weight Memory (WM) off-chip DRAM - 8 GB Weight FIFO (WFIFO) on-chip fetcher to read from WM Unified Buffer (UB) on-chip for intermediate values
11 TPU Architecture Host sends instructions over PCIe bus into instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators aggregate partial sums Weight Memory (WM) off-chip DRAM - 8 GB Weight FIFO (WFIFO) on-chip fetcher to read from WM Unified Buffer (UB) on-chip for intermediate values
12 MMU implemented as a systolic array Multiplying an input vector by a weight matrix with a systolic array
13 TPU Architecture Host sends instructions over PCIe bus into instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators aggregate partial sums Weight Memory (WM) off-chip DRAM - 8 GB Weight FIFO (WFIFO) on-chip fetcher to read from WM Unified Buffer (UB) on-chip for intermediate values
14 TPU Architecture Host sends instructions over PCIe bus into instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators Aggregate partial sums Weight Memory (WM) Off-chip DRAM - 8 GB Weight FIFO (WFIFO) On-chip fetcher to read from WM Unified Buffer (UB) On-chip for intermediate values
 Off-chip DRAM - 8 GB Weight FIFO On-chip fetcher to read from WM Unified Buffer (UB) On-chip for intermediate")
15 TPU Architecture Host sends instructions over PCIe bus into instruction buffer Matrix Multiply Unit (MMU) heart of TPU 256x256 8-bit MACs Accumulators Aggregate partial sums Weight Memory (WM) Off-chip DRAM - 8 GB Weight FIFO On-chip fetcher to read from WM Unified Buffer (UB) On-chip for intermediate values
16 TPU ISA CISC instructions (average CPI = 10 to 20 cycles) 12 instructions Read_Host_Memory: reads data from host memory into Unified Buffer Read_Weights: reads weights from Weights Memory into Weight FIFO MatrixMultiply/Convolve: perform matmul/convolution on data from UB and WM and store into Accumulators B X 256 input and 256 X 256 weight => B X 256 output in B cycles (pipelined) Activate: apply activation function on inputs from Accumulator and store into Unified Buffer Write_Host_Memory: writes data from Unified Buffer into host memory Software stack - application code to be run on TPU written in Tensorflow and compiled into an API which can be run on TPU (or even GPU)

17 Evaluation Performance comparison based on predictions per second on common DL workloads overpowers GPUs massively for CNNs performs reasonably well than GPUs for MLPs performs close to GPUs for LSTMs Good programmability production ready Bad converts convolution into matmul which may not be most optimal no direct support for sparsity

18 Nvidia Tesla V100 Tensor cores programmable matrix-multiply-and-accumulate units 8 cores/sm => total = 640 cores input - 4x4 matrices A,B must be FP16 C,D can be FP16/FP32 Exposed as Warp-level matmul operation in CUDA 9 Specialized matrix load/multiply/accumulate/store operations Part of multi GPU system optimized using NvLink interconnect and High Bandwidth Memory

19 Cloud TPU Part of Google Cloud Each node comprises of 4 chips 2 tensor cores per chip each core has scalar, vector and matrix units (MXU) 8/16 GB on-chip HBM per core 8 cores per cloud TPU node coupled with high bandwidth interconnect TPU Estimator APIs used to generate tensorflow computation graph, which is sent over grpc and Just In Time compiled onto the cloud TPU node TPU chip (v2 and v3) as part of cloud TPU node
20 Eyeriss (MIT)

21 Convolutional Neural Networks Each convolution layer identifies certain fine grained features from the input image, aggregating over features from previous layers Very often there are certain optional layers in between CONV layers such as NORM/POOL layers to reduce the range/size of input values Convolutions account for more than 90% of overall computation, dominating runtime and energy consumption
 and")

22 2D Convolution operation 2D convolution is a set of multiply and accumulate operations of the kernel matrix (also known as filter) and the input image feature map by sliding the filter over the image Image Source: Understanding Convolutional Layers in Convolutional Neural Networks (CNNs)

23 Multi-channel input with multi-channel filters Each filter and fmap have C channels -> the application of a filter on an input fmap across C channels results in one cell of the output fmap Rest of the cells of the output fmap are obtained by sliding the filter over the input fmap producing one channel of the output fmap Application of M such filters results in a single M channeled output fmap with as many channels as the number of filters Previous steps are batched over multiple input fmaps resulting in multiple output fmaps
24 Things to note Operations exhibit high parallelism High throughput possible Memory access is the bottleneck Lot of scope for data reuse 200x 1x WORST CASE: all memory R/W are DRAM accesses Example: AlexNet [NIPS 2012] -> 724M MACs = 2896M DRAM accesses required
25 Memory access is the bottleneck
26 Memory access is the bottleneck 1 Opportunities: 1. Reuse filters/fmap reducing DRAM reads

27 Memory access is the bottleneck 1 2 Opportunities: 1. Reuse filters/fmap reducing DRAM reads 2. Partial sum accumulation does not have to access DRAM

28 Types of data reuse in DNN
 Inter PE communication Sharing among regions")
29 Spatial Architecture for DNN Efficient Data Reuse Distributed local storage (RF) Inter PE communication Sharing among regions of PEs
30 Data movement is expensive
31 Data movement is expensive How to exploit data reuse and local accumulation with limited low-cost local storage?

32 Data movement is expensive How to exploit data reuse and local accumulation with limited low-cost local storage? Require specialized processing dataflow!
33 Dataflow Taxonomy Weight Stationary (WS) - reduce movement of filter weights Output Stationary (OS) - reduce movement of partial sums No Local Reuse (NLR) - no local storage at the PE, use a global buffer of larger size

34 Weight Stationary Examples: Chakradhar [ISCA 2010], Origami [GLSVLSI 2015]

35 Output Stationary Examples: Gupta [ICML 2015], ShiDianNao [ISCA 2015]

36 No Local Reuse Examples: DaDianNao [MICRO 2014], Zhang [FPGA 2015]
37 Eyeriss data flow: Row Stationary Previous approaches only optimize for certain types of data reuse -> this may lead to performance degradation when input dimensions vary Eyeriss maximizes reuse and accumulation at RF Eyeriss optimizes for overall energy efficiency instead of only a specific input type (input fmap, filters, psums) Eyeriss tries to break high dimensional convolution into 1D convolutional primitives which operate on one row of filter weights, one row of input feature map generating one row of partial sums => Row Stationary
38 1D Row Convolution in PE

39 1D Row Convolution in PE
40 1D Row Convolution in PE
41 1D Row Convolution in PE Maximize row convolutional reuse in RF Keep a filter row and fmap sliding window in RF Maximize row psum accumulation in RF

42 2D convolution in a PE array
43 2D convolution in a PE array
44 2D convolution in a PE array

45 2D convolution in a PE array
46 Convolutional Reuse Maximized Filter rows are reused across PEs horizontally

47 Convolutional Reuse Maximized Fmap rows are reused across PEs diagonally


48 Convolutional Reuse Maximized Partial sums accumulated across PEs vertically

49 DNN Processing - The Full Picture

50 Mapping DNN to the PEs

51 Eyeriss Deep CNN Accelerator
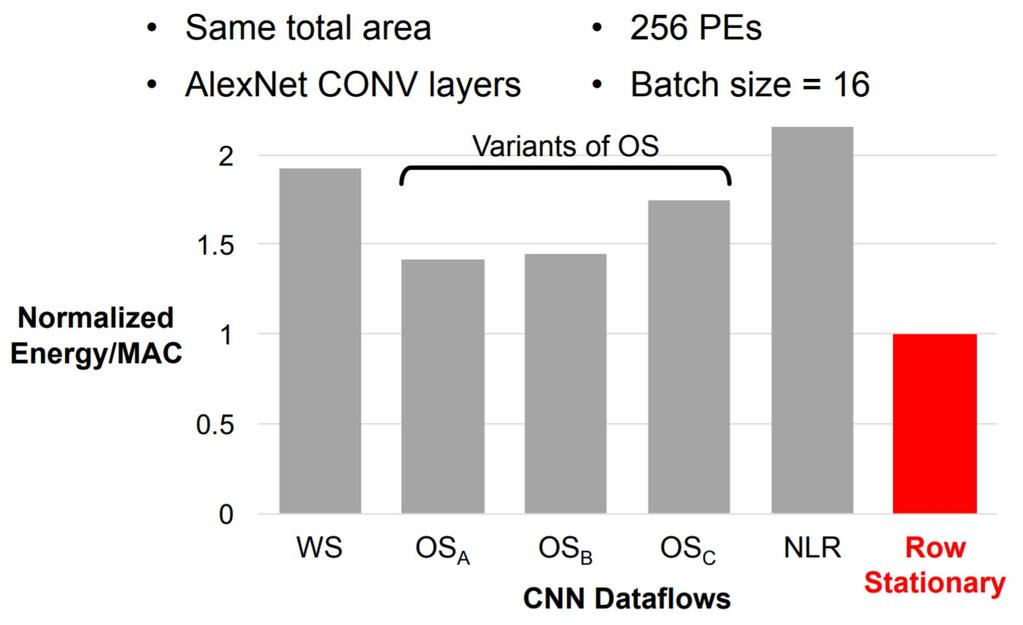
52 Evaluation
53 How do Eyeriss and TPU compare? Programmability? Usability? Eyeriss memory hierarchy also includes Inter PE communication while TPU s does not explicitly Applications? TPU is relatively more general purpose while Eyeriss is highly optimized for CNNs Memory hierarchy? TPU is far more programmable than Eyeriss TPUs are being pushed towards training workloads while Eyeriss is optimized for inference Energy? Chip size and cost?
54 Many more DL accelerators... State-of-the-art neural networks (AlexNet, ResNet, LeNet etc) large in size high power consumption due to memory access difficult to deploy on embedded devices End-to-end deployment solution (Song et.al.) use deep compression to make network fit into SRAM deploy it on EIE (Energy efficient Inference Engine) which accelerates resulting sparse vector matrix multiplication on the compressed network Accelerators for other DL models Generative Adversarial Networks - GANAX (Amir et.al.) RNNs, LSTMs - FPGA based accelerators, ESE (Song et.al.) Mobile phone SoCs Google Pixel 2 - Visual Core, IPhone X - Neural Engine, Samsung Exynos - NPU
55 References An in-depth look at Google s first Tensor Processing Unit (TPU) In-Datacenter Performance Analysis of a Tensor Processing Unit Images and some content pertaining to the Eyeriss architecture has been lifted as is from the Eyeriss tutorial. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks EIE: Efficient Inference Engine on Compressed Deep Neural Network GANAX: A Unified MIMD-SIMD Acceleration for Generative Adversarial Networks ESE: Efficient Speech Recognition Engine with Sparse LSTMs on FPGA
56 :)
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
 Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
DNN Accelerator Architectures
 DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS
 ... USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS... Yu-Hsin Chen Massachusetts Institute of Technology Joel Emer Nvidia and Massachusetts Institute of Technology Vivienne
... USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS... Yu-Hsin Chen Massachusetts Institute of Technology Joel Emer Nvidia and Massachusetts Institute of Technology Vivienne
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Scaling Neural Network Acceleration using Coarse-Grained Parallelism
 Scaling Neural Network Acceleration using Coarse-Grained Parallelism Mingyu Gao, Xuan Yang, Jing Pu, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2018 Neural Networks (NNs)
Scaling Neural Network Acceleration using Coarse-Grained Parallelism Mingyu Gao, Xuan Yang, Jing Pu, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2018 Neural Networks (NNs)
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design
 Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Computer Architectures for Deep Learning. Ethan Dell and Daniyal Iqbal
 Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System
 Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Speculations about Computer Architecture in Next Three Years. Jan. 20, 2018
 Speculations about Computer Architecture in Next Three Years shuchang.zhou@gmail.com Jan. 20, 2018 About me https://zsc.github.io/ Source-to-source transformation Cache simulation Compiler Optimization
Speculations about Computer Architecture in Next Three Years shuchang.zhou@gmail.com Jan. 20, 2018 About me https://zsc.github.io/ Source-to-source transformation Cache simulation Compiler Optimization
Maximizing Server Efficiency from μarch to ML accelerators. Michael Ferdman
 Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
How to Estimate the Energy Consumption of Deep Neural Networks
 How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs
 Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Adaptable Computing The Future of FPGA Acceleration. Dan Gibbons, VP Software Development June 6, 2018
 Adaptable Computing The Future of FPGA Acceleration Dan Gibbons, VP Software Development June 6, 2018 Adaptable Accelerated Computing Page 2 Three Big Trends The Evolution of Computing Trend to Heterogeneous
Adaptable Computing The Future of FPGA Acceleration Dan Gibbons, VP Software Development June 6, 2018 Adaptable Accelerated Computing Page 2 Three Big Trends The Evolution of Computing Trend to Heterogeneous
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory
 TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University
 ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University Lab 4: Binarized Convolutional Neural Networks Due Wednesday, October 31, 2018, 11:59pm
ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University Lab 4: Binarized Convolutional Neural Networks Due Wednesday, October 31, 2018, 11:59pm
Inference Optimization Using TensorRT with Use Cases. Jack Han / 한재근 Solutions Architect NVIDIA
 Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture
 The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm
 ECE5775 High-Level Digital Design Automation, Fall 2017 School of Electrical Computer Engineering, Cornell University Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm 1 Introduction
ECE5775 High-Level Digital Design Automation, Fall 2017 School of Electrical Computer Engineering, Cornell University Lab 4: Convolutional Neural Networks Due Friday, November 3, 2017, 11:59pm 1 Introduction
In Live Computer Vision
 EVA 2 : Exploiting Temporal Redundancy In Live Computer Vision Mark Buckler, Philip Bedoukian, Suren Jayasuriya, Adrian Sampson International Symposium on Computer Architecture (ISCA) Tuesday June 5, 2018
EVA 2 : Exploiting Temporal Redundancy In Live Computer Vision Mark Buckler, Philip Bedoukian, Suren Jayasuriya, Adrian Sampson International Symposium on Computer Architecture (ISCA) Tuesday June 5, 2018
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters
 Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 23 Domain- Specific Architectures
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 23 Domain- Specific Architectures Krste Asanovic Electrical Engineering and Computer Sciences University of California
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 23 Domain- Specific Architectures Krste Asanovic Electrical Engineering and Computer Sciences University of California
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Software Defined Hardware
 Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
EFFICIENT INFERENCE WITH TENSORRT. Han Vanholder
 EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Eyeriss v2: A Flexible and High-Performance Accelerator for Emerging Deep Neural Networks
 Eyeriss v2: A Flexible and High-Performance Accelerator for Emerging Deep Neural Networks Yu-Hsin Chen, Joel Emer and Vivienne Sze EECS, MIT Cambridge, MA 239 NVIDIA Research, NVIDIA Westford, MA 886 {yhchen,
Eyeriss v2: A Flexible and High-Performance Accelerator for Emerging Deep Neural Networks Yu-Hsin Chen, Joel Emer and Vivienne Sze EECS, MIT Cambridge, MA 239 NVIDIA Research, NVIDIA Westford, MA 886 {yhchen,
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
THE NVIDIA DEEP LEARNING ACCELERATOR
 THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array
 HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array Linghao Song, Jiachen Mao, Youwei Zhuo, Xuehai Qian, Hai Li, Yiran Chen Duke University, University of Southern California {linghao.song,
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array Linghao Song, Jiachen Mao, Youwei Zhuo, Xuehai Qian, Hai Li, Yiran Chen Duke University, University of Southern California {linghao.song,
Adaptable Intelligence The Next Computing Era
 Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
Adaptable Intelligence The Next Computing Era Hot Chips, August 21, 2018 Victor Peng, CEO, Xilinx Pervasive Intelligence from Cloud to Edge to Endpoints >> 1 Exponential Growth and Opportunities Data Explosion
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
arxiv: v1 [cs.cv] 11 Feb 2018
![arxiv: v1 [cs.cv] 11 Feb 2018](/thumbs/79/79222664.jpg "arxiv: v1 [cs.cv] 11 Feb 2018") arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
Matrix Multiplication
 Systolic Arrays Matrix Multiplication Is used in many areas of signal processing, graph theory, graphics, machine learning, physics etc Implementation considerations are based on precision, storage and
Systolic Arrays Matrix Multiplication Is used in many areas of signal processing, graph theory, graphics, machine learning, physics etc Implementation considerations are based on precision, storage and
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning
 TVM: An Automated End-to-End Optimizing Compiler for Deep Learning Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
NVIDIA PLATFORM FOR AI
 NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
XPU A Programmable FPGA Accelerator for Diverse Workloads
 XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
XPU A Programmable FPGA Accelerator for Diverse Workloads Jian Ouyang, 1 (ouyangjian@baidu.com) Ephrem Wu, 2 Jing Wang, 1 Yupeng Li, 1 Hanlin Xie 1 1 Baidu, Inc. 2 Xilinx Outlines Background - FPGA for
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks
 Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
Binary Convolutional Neural Network on RRAM
 Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
A Communication-Centric Approach for Designing Flexible DNN Accelerators
 THEME ARTICLE: Hardware Acceleration A Communication-Centric Approach for Designing Flexible DNN Accelerators Hyoukjun Kwon, High computational demands of deep neural networks Ananda Samajdar, and (DNNs)
THEME ARTICLE: Hardware Acceleration A Communication-Centric Approach for Designing Flexible DNN Accelerators Hyoukjun Kwon, High computational demands of deep neural networks Ananda Samajdar, and (DNNs)
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications
 Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
TVM Stack Overview. Tianqi Chen
 TVM Stack Overview Tianqi Chen Beginning of TVM Story Acclerator Beginning of TVM Story Acclerator Beginning of TVM Story Beginning of TVM Story Acclerator // Pseudo-code for convolution program for the
TVM Stack Overview Tianqi Chen Beginning of TVM Story Acclerator Beginning of TVM Story Acclerator Beginning of TVM Story Beginning of TVM Story Acclerator // Pseudo-code for convolution program for the
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Data Reuse
 Accepted for publication at Design, Automation and Test in Europe (DATE 2019). Florence, Italy CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Reuse Alberto Marchisio, Muhammad Abdullah
Accepted for publication at Design, Automation and Test in Europe (DATE 2019). Florence, Italy CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Reuse Alberto Marchisio, Muhammad Abdullah
Deep Learning on Modern Architectures. Keren Zhou 4/17/2017
 Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
The Explosion in Neural Network Hardware
 1 The Explosion in Neural Network Hardware USC Friday 19 th April Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For years the common wisdom
1 The Explosion in Neural Network Hardware USC Friday 19 th April Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For years the common wisdom
Versal: AI Engine & Programming Environment
 Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Shrinath Shanbhag Senior Software Engineer Microsoft Corporation
 Accelerating GPU inferencing with DirectML and DirectX 12 Shrinath Shanbhag Senior Software Engineer Microsoft Corporation Machine Learning Machine learning has become immensely popular over the last decade
Accelerating GPU inferencing with DirectML and DirectX 12 Shrinath Shanbhag Senior Software Engineer Microsoft Corporation Machine Learning Machine learning has become immensely popular over the last decade
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research
 Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
NVIDIA FOR DEEP LEARNING. Bill Veenhuis
 NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Efficient Processing for Deep Learning: Challenges and Opportuni:es
 Efficient Processing for Deep Learning: Challenges and Opportuni:es Vivienne Sze Massachuse@s Ins:tute of Technology Contact Info email: sze@mit.edu website: www.rle.mit.edu/eems In collabora*on with Yu-Hsin
Efficient Processing for Deep Learning: Challenges and Opportuni:es Vivienne Sze Massachuse@s Ins:tute of Technology Contact Info email: sze@mit.edu website: www.rle.mit.edu/eems In collabora*on with Yu-Hsin
An introduction to Machine Learning silicon
 An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
Enabling Technology for the Cloud and AI One Size Fits All?
 Enabling Technology for the Cloud and AI One Size Fits All? Tim Horel Collaborate. Differentiate. Win. DIRECTOR, FIELD APPLICATIONS The Growing Cloud Global IP Traffic Growth 40B+ devices with intelligence
Enabling Technology for the Cloud and AI One Size Fits All? Tim Horel Collaborate. Differentiate. Win. DIRECTOR, FIELD APPLICATIONS The Growing Cloud Global IP Traffic Growth 40B+ devices with intelligence
Hello Edge: Keyword Spotting on Microcontrollers
 Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
 Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
A Method to Estimate the Energy Consumption of Deep Neural Networks
 A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
Characterization and Benchmarking of Deep Learning. Natalia Vassilieva, PhD Sr. Research Manager
 Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
DNN Dataflow Choice Is Overrated
 DNN Dataflow Choice Is Overrated Xuan Yang *, Mingyu Gao *, Jing Pu *, Ankita Nayak *, Qiaoyi Liu *, Steven Emberton Bell *, Jeff Ou Setter *, Kaidi Cao, Heonjae Ha *, Christos Kozyrakis * and Mark Horowitz
DNN Dataflow Choice Is Overrated Xuan Yang *, Mingyu Gao *, Jing Pu *, Ankita Nayak *, Qiaoyi Liu *, Steven Emberton Bell *, Jeff Ou Setter *, Kaidi Cao, Heonjae Ha *, Christos Kozyrakis * and Mark Horowitz
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU
 NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Scalable Distributed Training with Parameter Hub: a whirlwind tour
 Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
Scalable Distributed Training with Parameter Hub: a whirlwind tour TVM Stack Optimization High-Level Differentiable IR Tensor Expression IR AutoTVM LLVM, CUDA, Metal VTA AutoVTA Edge FPGA Cloud FPGA ASIC
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
TensorFlow: A System for Learning-Scale Machine Learning. Google Brain
 TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
The Explosion in Neural Network Hardware
 1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm
 in 7nm") Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
Engineering Director, Xilinx Silicon Architecture Group Versal: The New Xilinx Adaptive Compute Acceleration Platform (ACAP) in 7nm Presented By Kees Vissers Fellow February 25, FPGA 2019 Technology scaling
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer
 S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
Addressing the Memory Wall
 Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control