Intel Compiler. Advanced Technical Skills (ATS) North America. IBM High Performance Computing February 2010 Y. Joanna Wong, Ph.D.
|
|
|
- Oswin Phillips
- 6 years ago
- Views:
Transcription


1 Intel Compiler IBM High Performance Computing February 2010 Y. Joanna Wong, Ph.D. 2/22/2010
2 Nehalem-EP CPU Summary Performance/Features: 4 cores 8M on-chip Shared Cache Simultaneous Multi- Threading capability (SMT) Intel QuickPath Interconnect up to 6.4 GT/s, each direct. per link Integrated Memory Controller (DDR3) New instructions Power: 95W, 80W, 60W Nehalem-EP Memory Controller 3x DDR3 channels 8M Shared Cache Link Controller 2x Intel QuickPath interconnect Socket: New LGA 1366 Socket Process Technology: 45nm CPU Platform Compatibility Tylersburg (TBG) ICH9/10 Driving performance through Multi- Technology and platform enhancements 2 2 Source: Intel Corporation
3 Intel Xeon 5500 Series (Nehalem-EP) Overview PCI Express* Gen 1, 2 Up to 25.6 Gb/sec bandwidth per link Nehalem QPI DMI Nehalem I/O Hub ICH Key Technologies New 45nm Intel Microarchitecture New Intel QuickPath Interconnect Integrated Memory Controller Next Generation Memory (DDR3) PCI Express Gen 2 IT Benefits More application performance Improved energy efficiency End to end HW assist (virtualization technology improvements) Stable IT image Software compatible Live migration compatible with today s dual and quad-core Intel microarchitecture products using enabled virtualization software Source: Intel Corporation 3
 new new Automatic operation or")
4 Energy Efficiency Enhancements Intel Intelligent Power Technologies Integrated Power Gates 1 Automated Low Power States Enables idle cores to go to near zero power independently Voltage (cores) More & Lower CPU Power States Reduced latency during transitions Power management now on memory, I/O Enhanced Memory System, Cache, I/O Voltage (rest of processor) new new Automatic operation or manual core disable 2 Adjusts system power consumption based on real-time load Source: 1 Integrated power gates (C6) requires OS support 2 Requires BIOS setting change and system reboot Source: Intel Corporation 4
5 More Efficient Chipset and Memory Memory Power Management DIMMs are automatically placed into a lower power state when not utilized 1 DIMMs are automatically idled when all CPU cores in the system are idle 2 Chipset Power Management QPI links and PCIe lanes placed in power reduction states when not active 3 Capable of placing PCIe* cards in the lowest power state possible 4 Intel Xeon 5500 QPI PCIe* Intel Xeon 5500 Intel 5500 Chipset End-to-end platform power management Source: 1 Using DIMM CKE (Clock Enable) 2 Using DIMM self refresh 3 Using L0s and L1 states 4 Using cards enabled with ASPM (Active State Power Management) 5 Source: Intel Corporation

6 Performance Enhancements Intel Xeon 5500 Series Processor (Nehalem-EP) Intel Turbo Boost Technology Intel Hyper-Threading Technology Increases performance by increasing processor frequency and enabling faster speeds when conditions allow Normal 4C Turbo <4C Turbo Increases performance for threaded applications delivering greater throughput and responsiveness Frequency Up to 30% higher All cores operate at rated frequency All cores operate at higher frequency Fewer cores may operate at even higher frequencies Higher performance on demand Higher performance for threaded workloads Source: Intel internal measurements, January For notes and disclaimers, see performance and legal information slides at end of this presentation. Source: Intel Corporation 6
7 Nehalem-EP Turbo Mode Frequencies Basic (80W) Standard (80W) Perf (95W) E5502 E5504 E5506 E5520 E5530 E5540 X5550 X5560 X5570 WS (130W) 3.46 GHz GHz C/3C/2C operation 3.20 GHz GHz GHz GHz GHz 2.53 GHz C turbo only 2.40 GHz +1 1C/2C turbo 2.26 GHz 2.13 GHz 2.00 GHz 4C/3C turbo 1.86 GHz DC Base Freq Source: Intel Corporation 7
8 Optimizing for Memory Performance: General Guidelines and Potential Configurations Use identical DIMM types throughout the platform: Same size, speed, and number of ranks Use a balanced platform configuration: Populate the same for each channel and each socket Maximize number of channels populated for highest bandwidth IT Requirements (assumes two 4C Nehalem-EP CPUs) GB/core Platform Capacity Potential Configurations 2 GB DIMM 2x2 4x2 6x2 8x2 12x2 18x2 4 GB DIMM 2x4 4x4 6x4 8x4 12x4 18x4 8 GB DIMM 2x8 4x8 6x8 8x8 12x8 18x8 DDR3 1333, 1066, 800 support DDR3 1066, 800 support DDR3 800 only Indicates memory sweet spot that equally populates all 6 memory channels Source: Intel Corporation 8
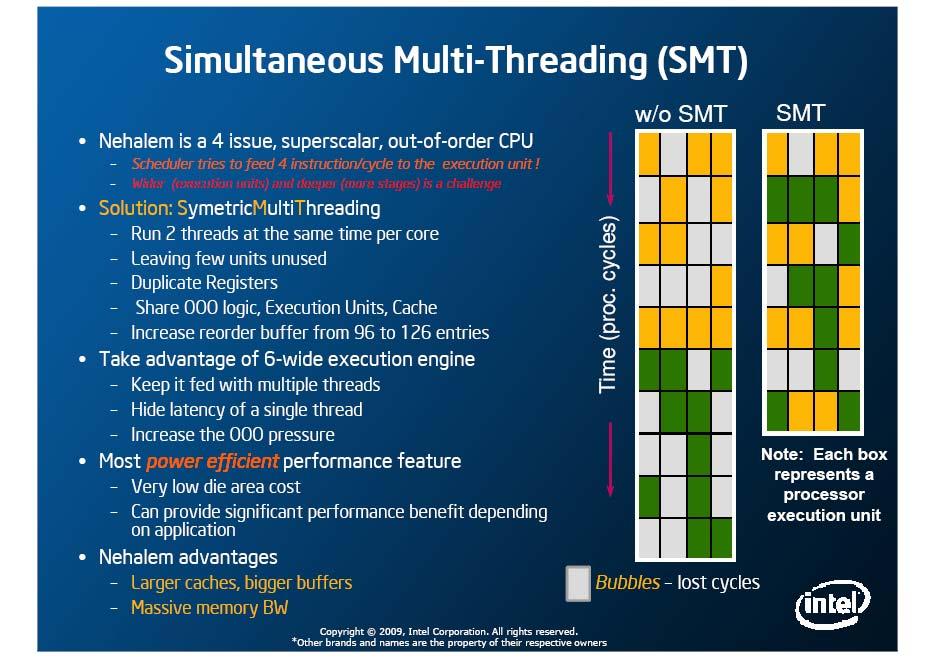
9 9

10 10

11 Intel Smart Cache Caches New 3-level Cache Hierarchy 1 st level caches 32kB Instruction cache 32kB, 8-way Data Cache Support more L1 misses in parallel than Intel 2 microarchitecture 2 nd level Cache 32kB L1 32kB L1 Data Cache Inst. Cache New cache introduced in Intel microarchitecture (Nehalem) Unified (holds code and data) 256 kb per core (8-way) Performance: Very low latency 10 cycle load-to-use Scalability: As core count increases, reduce pressure on shared cache 256kB L2 Cache Source: Intel Corporation 11
12 Intel Smart Cache 3 rd Level Cache Shared across all cores Size depends on # of cores Quad-core: Up to 8MB (16-ways) Scalability: L1 Caches L1 Caches L1 Caches Built to vary size with varied core counts Built to easily increase L3 size in future parts Perceived latency depends on frequency ratio between core & uncore ~ 40 clocks Inclusive cache policy for best performance L2 Cache L2 Cache L3 Cache L2 Cache Address residing in L1/L2 must be present in 3 rd level cache Source: Intel Corporation 12
13 Why Inclusive? Inclusive cache provides benefit of an on-die snoop filter Valid Bits 1 bit per core per cache line If line may be in a core, set core valid bit Snoop only needed if line is in L3 and core valid bit is set Guaranteed that line is not modified if multiple bits set Scalability Addition of cores/sockets does not increase snoop traffic seen by cores Latency Minimize effective cache latency by eliminating cross-core snoops in the common case Minimize snoop response time for cross-socket cases Source: Intel Corporation 13
14 Hardware Prefetching (HWP) HW Prefetching critical to hiding memory latency Structure of HWPs similar as in Intel 2 microarchitecture Algorithmic improvements in Intel microarchitecture (Nehalem) for higher performance L1 Prefetchers Based on instruction history and/or load address pattern L2 Prefetchers Prefetches loads/rfos/code fetches based on address pattern Intel microarchitecture (Nehalem) changes: Efficient Prefetch mechanism Remove the need for Intel Xeon processors to disable HWP Increase prefetcher aggressiveness Locks on address streams quicker, adapts to change faster, issues more prefetchers more aggressively (when appropriate) Source: Intel Corporation 14
15 Extending Performance and Energy Efficiency - Intel SSE4.2 Instruction Set Architecture (ISA) Accelerated String and Text Processing Faster XML parsing Faster search and pattern matching Novel parallel data matching and comparison operations STTNI SSE4 (45nm CPUs) Accelerated Searching & Pattern Recognition of Large Data Sets Improved performance for Genome Mining, Handwriting recognition. Fast Hamming distance / Population count SSE4.1 (Penryn ) SSE4.2 (Nehalem ) New Communications Capabilities Hardware based CRC instruction Accelerated Network attached storage Improved power efficiency for Software I-SCSI, RDMA, and SCTP ATA STTNI e.g. XML acceleration POPCNT e.g. Genome Mining ATA (Application Targeted Accelerators) CRC32 e.g. iscsi Application Projected 3.8x kernel speedup on XML parsing & 2.7x savings on instruction cycles Source: Intel Corporation 15
16 Tools Support for Intel Microarchitecture (Nehalem) Intel Compiler 10.x supports the new instructions Nehalem specific compiler optimizations SSE4.2 supported via vectorization and intrinsics Inline assembly supported on both IA-32 and Intel 64 architecture targets Necessary to include required header files in order to access intrinsics Intel XML Software Suite High performance C++ and Java runtime libraries Version 1.0 (C++), version 1.01 (Java) available now Version 1.1 w/sse4.2 optimizations planned for September 2008 Microsoft Visual Studio* 2008 VC++ SSE4.2 supported via intrinsics Inline assembly supported on IA-32 only Necessary to include required header files in order to access intrinsics VC tools masm, msdis, and debuggers recognize the new instructions GCC* Support Intel microarchitecture (Merom), 45nm next generation Intel microarchitecture (Penryn), Intel microarchitecture (Nehalem) via mtune=generic. Support SSE4.1 and SSE4.2 through vectorizer and intrinsics 16

17 Optimization Guidelines with Intel Compiler for Intel i7 processor Source: Intel Developer Forum, Tuning your Software for the Next Generation Intel Microarchitecture (Nehalem) 17

18 18

19 19
20 Unaligned Loads / Stores Unaligned loads are as fast as aligned loads Optimized accesses that span two cache-lines Generating misaligned references less of a concern One instruction can replace sequences of up to 7 Fewer instructions Less register pressure Increased opportunities for several optimizations Vectorization memcpy / memset Dynamic Stack alignment less necessary for 32-bit stacks 20

21 Source: Intel Corporation 21

22 22

23 23
24 Common Intel Compiler Features General optimization settings Cache-management features Interprocedural optimization (IPO) methods Profile-guided optimization (PGO) methods Multithreading support Floating-point arithmetic precision and consistency Compiler optimization and vectorization report Source: Intel white paper Optimization Applications with Intel C++ and Fortran Compilers for Windows, Linux and Mac Os X 24

25 Source: Intel Corporation 25

26 Source: Intel Corporation 26
27 Common Intel Compiler Features Target systems with processor-specific options: -xsse4.2 -xhost -axsse4.2 A good start: generate optimized code specialized for the Intel (Intel i7) processor family that executes the program optimize for and use the most advanced instruction set for the processor on which you compile Generate multiple processor-specific auto-dispatch code paths for Intel processors if there is performance benefit. Executable will run on Intel processor architecture other than Intel i7 -O2 xsse4.2 or -O2 -xhost -O3 xsse4.2 or -O3 -xhost -fast : -O3 ipo no-prec-div static 27
28 Parallel programming with MPI 2/22/2010
29 Parallel Scalability Amdahl s Law the law of diminishing returns T n = S + P/n Assumption: Parallel content scales inversely with number of parallel tasks, Ignoring computation and communication load imbalance The maximum parallel speedup is: P/S + 1 source: wikipedia 29
30 Strong vs Weak Scaling Strong scaling Scalability of a fixed total problem size with the number of processors Weak Scaling Scalability of a fixed problem size per processor with the number of processors 30
31 Thread: An independent flow of control, may operate within a process with other threads. An schedulable entity Has its own stack, thread-specific data, and own registers Set of pending and blocked signals Process Can not share memory directly Can not share file descriptors A process can own multiple threads An OpenMP job is a process. It creates and owns one or more SMP threads. All the SMP threads share the same PID An MPI job is a set of concurrent processes (or tasks). Each process has its own PID and communicates with other processes via MPI calls 31

32 Shared Memory Characteristics Single address space Single operating system Limitations Memory Contention Bandwidth Cache coherency snoop traffic gets very expensive as more L2 caches in node Benefits Memory size Programming models 32
33 Distributed Memory Characteristics Multiple address spaces Multiple operating systems Limitations Switch Contention Bandwidth Local memory size Benefits Economically scale to large processor counts Cache coherency not needed between nodes Shared Memory Node Network 33
34 Comparison: Shared Memory Programming vs. Distributed Memory Programming Shared memory Single process ID for all threads List threads ps elf Distributed memory Each task has own process ID List tasks: ps Process A Process A Process B Process C Thread 0 Thread 1 Process A Task 0 Task 1 Task 2 Thread 2 As we saw in SMP chapter 34
35 Parallel Programming on HPC cluster Message Passing (MPI) between Nodes High Performance Interconnect memory memory memory memory OpenMP / Multi-threading within SMP node Cluster of Shared Memory Nodes 35
36 Parallel Programming choices MPI Good for tightly coupled computations Exploits all networks and all OS Significant programming effort; debugging can be difficult Master/Slave paradigm is supported. OpenMP Easier to get parallel speed up Limited to SMP (single node) Typically applied at loop level limited scalability Automatic parallelization by compiler Need clean programming to get advantage pthreads = Posix threads Good for loosely coupled computations User controlled instantiation and locks fork/execl Standard Unix/Linux technique 36
37 Schematic Flow of an SMP Code th d0 37 Program ParallelWork start the program read input set up comp. parameters initialize variable DO i=1,imax End do serial work DO i=1,imax End do serial work DO i=1,imax End do Output End program ParallelWork th d0 th d1 th d2 th d3 master slaves fork join (sync.) spin/yield gang sched join (sync.) spin/yield join (sync.) spin/yield
38 Schematic Flow of an MPI code Program ParallelWork start the program Call MPI_Init(ierr) read input set up comp. parameters DO i=1,imax End do serial work DO i=1,imax End do serial work DO i=1,imax End do Output Call MPI_Finalize End program ParallelWork 38 master slaves proc0 proc1 proc2 proc3 MPI_Init msg passing: Input parameters barrier if needed message passing message passing message passing barrier if needed MPI Finalize wait for msg, synchronization
39 MPI Basics MPI = Message Passing Interface A message passing library standard based on the consensus of MPI Forum, with participants from vendors (hardware & software), academics, software developers Initially developed to support distributed memory program architecture Not an IEEE or ISO standard, now the defacto industry standard NOT a library -- specification on what the library should be, but not on the implementation MPI-1.0, released 1994 MPI-2.2 (latest), released 2009 MPI-3.0 standard, ongoing 39
40 MPI tutorials 40
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Intel Workstation Technology
 Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
AMD Opteron 4200 Series Processor
 What s new in the AMD Opteron 4200 Series Processor (Codenamed Valencia ) and the new Bulldozer Microarchitecture? Platform Processor Socket Chipset Opteron 4000 Opteron 4200 C32 56x0 / 5100 (codenamed
What s new in the AMD Opteron 4200 Series Processor (Codenamed Valencia ) and the new Bulldozer Microarchitecture? Platform Processor Socket Chipset Opteron 4000 Opteron 4200 C32 56x0 / 5100 (codenamed
Best Practices for Setting BIOS Parameters for Performance
 White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
White Paper Best Practices for Setting BIOS Parameters for Performance Cisco UCS E5-based M3 Servers May 2013 2014 Cisco and/or its affiliates. All rights reserved. This document is Cisco Public. Page
Intel Core i7 Processor
 Intel Core i7 Processor Vishwas Raja 1, Mr. Danish Ather 2 BSc (Hons.) C.S., CCSIT, TMU, Moradabad 1 Assistant Professor, CCSIT, TMU, Moradabad 2 1 vishwasraja007@gmail.com 2 danishather@gmail.com Abstract--The
Intel Core i7 Processor Vishwas Raja 1, Mr. Danish Ather 2 BSc (Hons.) C.S., CCSIT, TMU, Moradabad 1 Assistant Professor, CCSIT, TMU, Moradabad 2 1 vishwasraja007@gmail.com 2 danishather@gmail.com Abstract--The
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
White Paper. First the Tick, Now the Tock: Next Generation Intel Microarchitecture (Nehalem)
") White Paper First the Tick, Now the Tock: Next Generation Intel Microarchitecture (Nehalem) Introducing a New Dynamically and Design- Scalable Microarchitecture that Rewrites the Book On Energy Efficiency
White Paper First the Tick, Now the Tock: Next Generation Intel Microarchitecture (Nehalem) Introducing a New Dynamically and Design- Scalable Microarchitecture that Rewrites the Book On Energy Efficiency
Simultaneous Multithreading on Pentium 4
 Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
Hyper-Threading: Simultaneous Multithreading on Pentium 4 Presented by: Thomas Repantis trep@cs.ucr.edu CS203B-Advanced Computer Architecture, Spring 2004 p.1/32 Overview Multiple threads executing on
FAST FORWARD TO YOUR <NEXT> CREATION
 FAST FORWARD TO YOUR CREATION THE ULTIMATE PROFESSIONAL WORKSTATIONS POWERED BY INTEL XEON PROCESSORS 7 SEPTEMBER 2017 WHAT S NEW INTRODUCING THE NEW INTEL XEON SCALABLE PROCESSOR BREAKTHROUGH PERFORMANCE
FAST FORWARD TO YOUR CREATION THE ULTIMATE PROFESSIONAL WORKSTATIONS POWERED BY INTEL XEON PROCESSORS 7 SEPTEMBER 2017 WHAT S NEW INTRODUCING THE NEW INTEL XEON SCALABLE PROCESSOR BREAKTHROUGH PERFORMANCE
EPYC VIDEO CUG 2018 MAY 2018
 AMD UPDATE CUG 2018 EPYC VIDEO CRAY AND AMD PAST SUCCESS IN HPC AMD IN TOP500 LIST 2002 TO 2011 2011 - AMD IN FASTEST MACHINES IN 11 COUNTRIES ZEN A FRESH APPROACH Designed from the Ground up for Optimal
AMD UPDATE CUG 2018 EPYC VIDEO CRAY AND AMD PAST SUCCESS IN HPC AMD IN TOP500 LIST 2002 TO 2011 2011 - AMD IN FASTEST MACHINES IN 11 COUNTRIES ZEN A FRESH APPROACH Designed from the Ground up for Optimal
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Scalability issues : HPC Applications & Performance Tools
 High Performance Computing Systems and Technology Group Scalability issues : HPC Applications & Performance Tools Chiranjib Sur HPC @ India Systems and Technology Lab chiranjib.sur@in.ibm.com Top 500 :
High Performance Computing Systems and Technology Group Scalability issues : HPC Applications & Performance Tools Chiranjib Sur HPC @ India Systems and Technology Lab chiranjib.sur@in.ibm.com Top 500 :
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Server-Related Policy Configuration
 BIOS Settings, page 1 CIMC Security Policies, page 63 Graphics Card Policies, page 68 Configuring Local Disk Configuration Policies, page 70 Scrub Policies, page 87 Configuring DIMM Error Management, page
BIOS Settings, page 1 CIMC Security Policies, page 63 Graphics Card Policies, page 68 Configuring Local Disk Configuration Policies, page 70 Scrub Policies, page 87 Configuring DIMM Error Management, page
Dell PowerEdge 11 th Generation Servers: R810, R910, and M910 Memory Guidance
 Dell PowerEdge 11 th Generation Servers: R810, R910, and M910 Memory Guidance A Dell Technical White Paper Dell Product Group Armando Acosta and James Pledge THIS WHITE PAPER IS FOR INFORMATIONAL PURPOSES
Dell PowerEdge 11 th Generation Servers: R810, R910, and M910 Memory Guidance A Dell Technical White Paper Dell Product Group Armando Acosta and James Pledge THIS WHITE PAPER IS FOR INFORMATIONAL PURPOSES
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
LS-DYNA Performance on Intel Scalable Solutions
 LS-DYNA Performance on Intel Scalable Solutions Nick Meng, Michael Strassmaier, James Erwin, Intel nick.meng@intel.com, michael.j.strassmaier@intel.com, james.erwin@intel.com Jason Wang, LSTC jason@lstc.com
LS-DYNA Performance on Intel Scalable Solutions Nick Meng, Michael Strassmaier, James Erwin, Intel nick.meng@intel.com, michael.j.strassmaier@intel.com, james.erwin@intel.com Jason Wang, LSTC jason@lstc.com
POWER7: IBM's Next Generation Server Processor
 POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
Performance Profiler. Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava,
 Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Performance Profiler Klaus-Dieter Oertel Intel-SSG-DPD IT4I HPC Workshop, Ostrava, 08-09-2016 Faster, Scalable Code, Faster Intel VTune Amplifier Performance Profiler Get Faster Code Faster With Accurate
Martin Kruliš, v
 Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Martin Kruliš 1 Optimizations in General Code And Compilation Memory Considerations Parallelism Profiling And Optimization Examples 2 Premature optimization is the root of all evil. -- D. Knuth Our goal
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Comp. Org II, Spring
 Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Intel Workstation Platforms
 Product Brief Intel Workstation Platforms Intel Workstation Platforms For intelligent performance, automated energy efficiency, and flexible expandability How quickly can you change complex data into actionable
Product Brief Intel Workstation Platforms Intel Workstation Platforms For intelligent performance, automated energy efficiency, and flexible expandability How quickly can you change complex data into actionable
Intel VTune Amplifier XE
 Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Intel VTune Amplifier XE Vladimir Tsymbal Performance, Analysis and Threading Lab 1 Agenda Intel VTune Amplifier XE Overview Features Data collectors Analysis types Key Concepts Collecting performance
Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor)
") Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor) Martyn Corden Developer Products Division Software & Services Group Intel Corporation
Compiling for Nehalem (the Intel Core Microarchitecture, Intel Xeon 5500 processor family and the Intel Core i7 processor) Martyn Corden Developer Products Division Software & Services Group Intel Corporation
BIOS Parameters by Server Model
 This appendix contains the following sections: S3260 M3 Servers, on page 1 S3260 M4 Servers, on page 20 S3260 M3 Servers Main Tab Reboot Host Immediately checkbox Upon checking, reboots the host server
This appendix contains the following sections: S3260 M3 Servers, on page 1 S3260 M4 Servers, on page 20 S3260 M3 Servers Main Tab Reboot Host Immediately checkbox Upon checking, reboots the host server
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Six-Core AMD Opteron Processor
 What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
POWER7: IBM's Next Generation Server Processor
 Hot Chips 21 POWER7: IBM's Next Generation Server Processor Ronald Kalla Balaram Sinharoy POWER7 Chief Engineer POWER7 Chief Core Architect Acknowledgment: This material is based upon work supported by
Hot Chips 21 POWER7: IBM's Next Generation Server Processor Ronald Kalla Balaram Sinharoy POWER7 Chief Engineer POWER7 Chief Core Architect Acknowledgment: This material is based upon work supported by
BIOS Parameters by Server Model
 BIOS Parameters by Server Model This appendix contains the following sections: C22 and C24 Servers, page 1 C200 and C210 Servers, page 16 C220 and C240 Servers, page 29 C250 Servers, page 44 C260 Servers,
BIOS Parameters by Server Model This appendix contains the following sections: C22 and C24 Servers, page 1 C200 and C210 Servers, page 16 C220 and C240 Servers, page 29 C250 Servers, page 44 C260 Servers,
Pactron FPGA Accelerated Computing Solutions
 Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Pactron FPGA Accelerated Computing Solutions Intel Xeon + Altera FPGA 2015 Pactron HJPC Corporation 1 Motivation for Accelerators Enhanced Performance: Accelerators compliment CPU cores to meet market
Comp. Org II, Spring
 Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Parallel Processing & Multicore computers
 Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Silvermont. Introducing Next Generation Low Power Microarchitecture: Dadi Perlmutter
 Introducing Next Generation Low Power Microarchitecture: Silvermont Dadi Perlmutter Executive Vice President General Manager, Intel Architecture Group Chief Product Officer Risk Factors Today s presentations
Introducing Next Generation Low Power Microarchitecture: Silvermont Dadi Perlmutter Executive Vice President General Manager, Intel Architecture Group Chief Product Officer Risk Factors Today s presentations
Does the Intel Xeon Phi processor fit HEP workloads?
 Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
Does the Intel Xeon Phi processor fit HEP workloads? October 17th, CHEP 2013, Amsterdam Andrzej Nowak, CERN openlab CTO office On behalf of Georgios Bitzes, Havard Bjerke, Andrea Dotti, Alfio Lazzaro,
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Chapter 7. Multicores, Multiprocessors, and Clusters. Goal: connecting multiple computers to get higher performance
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 18 Multicore Computers
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
Parallel Algorithm Engineering
 Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Parallel Algorithm Engineering Kenneth S. Bøgh PhD Fellow Based on slides by Darius Sidlauskas Outline Background Current multicore architectures UMA vs NUMA The openmp framework and numa control Examples
Vector Engine Processor of SX-Aurora TSUBASA
 Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
PRACE Autumn School Basic Programming Models
 PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
Introducing the Cray XMT. Petr Konecny May 4 th 2007
 Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Intel Workstation Platforms
 Product Brief Intel Workstation Platforms Intel Workstation Platforms For intelligent performance, automated Workstations based on the new Intel Microarchitecture, codenamed Nehalem, are designed giving
Product Brief Intel Workstation Platforms Intel Workstation Platforms For intelligent performance, automated Workstations based on the new Intel Microarchitecture, codenamed Nehalem, are designed giving
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Shared Memory and Distributed Multiprocessing. Bhanu Kapoor, Ph.D. The Saylor Foundation
 Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Shared Memory and Distributed Multiprocessing Bhanu Kapoor, Ph.D. The Saylor Foundation 1 Issue with Parallelism Parallel software is the problem Need to get significant performance improvement Otherwise,
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
( ZIH ) Center for Information Services and High Performance Computing. Overvi ew over the x86 Processor Architecture
 Center for Information Services and High Performance Computing. Overvi ew over the x86 Processor Architecture") ( ZIH ) Center for Information Services and High Performance Computing Overvi ew over the x86 Processor Architecture Daniel Molka Ulf Markwardt Daniel.Molka@tu-dresden.de ulf.markwardt@tu-dresden.de Outline
( ZIH ) Center for Information Services and High Performance Computing Overvi ew over the x86 Processor Architecture Daniel Molka Ulf Markwardt Daniel.Molka@tu-dresden.de ulf.markwardt@tu-dresden.de Outline
Performance Tuning Guide for Cisco UCS M5 Servers
 Performance Tuning Guide for Cisco UCS M5 Servers For Cisco UCS M5 Blade and Rack Servers Using the Intel Xeon Scalable Processor Family. February 2018 2018 Cisco and/or its affiliates. All rights reserved.
Performance Tuning Guide for Cisco UCS M5 Servers For Cisco UCS M5 Blade and Rack Servers Using the Intel Xeon Scalable Processor Family. February 2018 2018 Cisco and/or its affiliates. All rights reserved.
Enabling Performance-per-Watt Gains in High-Performance Cluster Computing
 WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
Performance and Energy Efficiency of the 14 th Generation Dell PowerEdge Servers
 Performance and Energy Efficiency of the 14 th Generation Dell PowerEdge Servers This white paper details the performance improvements of Dell PowerEdge servers with the Intel Xeon Processor Scalable CPU
Performance and Energy Efficiency of the 14 th Generation Dell PowerEdge Servers This white paper details the performance improvements of Dell PowerEdge servers with the Intel Xeon Processor Scalable CPU
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Nehalem Hochleistungsrechnen für reale Anwendungen
 Nehalem Hochleistungsrechnen für reale Anwendungen T-Systems HPCN Workshop DLR Braunschweig May 14-15, 2009 Hans-Joachim Plum Intel GmbH 1 Performance tests and ratings are measured using specific computer
Nehalem Hochleistungsrechnen für reale Anwendungen T-Systems HPCN Workshop DLR Braunschweig May 14-15, 2009 Hans-Joachim Plum Intel GmbH 1 Performance tests and ratings are measured using specific computer
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
WHITE PAPER FUJITSU PRIMERGY SERVERS PERFORMANCE REPORT PRIMERGY BX924 S2
 WHITE PAPER PERFORMANCE REPORT PRIMERGY BX924 S2 WHITE PAPER FUJITSU PRIMERGY SERVERS PERFORMANCE REPORT PRIMERGY BX924 S2 This document contains a summary of the benchmarks executed for the PRIMERGY BX924
WHITE PAPER PERFORMANCE REPORT PRIMERGY BX924 S2 WHITE PAPER FUJITSU PRIMERGY SERVERS PERFORMANCE REPORT PRIMERGY BX924 S2 This document contains a summary of the benchmarks executed for the PRIMERGY BX924
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
HP ProLiant BladeSystem Gen9 vs Gen8 and G7 Server Blades on Data Warehouse Workloads
 HP ProLiant BladeSystem Gen9 vs Gen8 and G7 Server Blades on Data Warehouse Workloads Gen9 server blades give more performance per dollar for your investment. Executive Summary Information Technology (IT)
HP ProLiant BladeSystem Gen9 vs Gen8 and G7 Server Blades on Data Warehouse Workloads Gen9 server blades give more performance per dollar for your investment. Executive Summary Information Technology (IT)
Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations
 Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
April 2 nd, Bob Burroughs Director, HPC Solution Sales
 April 2 nd, 2019 Bob Burroughs Director, HPC Solution Sales Today - Introducing 2 nd Generation Intel Xeon Scalable Processors how Intel Speeds HPC performance Work Time System Peak Efficiency Software
April 2 nd, 2019 Bob Burroughs Director, HPC Solution Sales Today - Introducing 2 nd Generation Intel Xeon Scalable Processors how Intel Speeds HPC performance Work Time System Peak Efficiency Software
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
White Paper. Technical Advances in the SGI. UV Architecture
 White Paper Technical Advances in the SGI UV Architecture TABLE OF CONTENTS 1. Introduction 1 2. The SGI UV Architecture 2 2.1. SGI UV Compute Blade 3 2.1.1. UV_Hub ASIC Functionality 4 2.1.1.1. Global
White Paper Technical Advances in the SGI UV Architecture TABLE OF CONTENTS 1. Introduction 1 2. The SGI UV Architecture 2 2.1. SGI UV Compute Blade 3 2.1.1. UV_Hub ASIC Functionality 4 2.1.1.1. Global
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Using Intel VTune Amplifier XE and Inspector XE in.net environment
 Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
Using Intel VTune Amplifier XE and Inspector XE in.net environment Levent Akyil Technical Computing, Analyzers and Runtime Software and Services group 1 Refresher - Intel VTune Amplifier XE Intel Inspector
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Intel High-Performance Computing. Technologies for Engineering
 6. LS-DYNA Anwenderforum, Frankenthal 2007 Keynote-Vorträge II Intel High-Performance Computing Technologies for Engineering H. Cornelius Intel GmbH A - II - 29 Keynote-Vorträge II 6. LS-DYNA Anwenderforum,
6. LS-DYNA Anwenderforum, Frankenthal 2007 Keynote-Vorträge II Intel High-Performance Computing Technologies for Engineering H. Cornelius Intel GmbH A - II - 29 Keynote-Vorträge II 6. LS-DYNA Anwenderforum,
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
THE PROGRAMMER S GUIDE TO THE APU GALAXY. Phil Rogers, Corporate Fellow AMD
 THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
THE PROGRAMMER S GUIDE TO THE APU GALAXY Phil Rogers, Corporate Fellow AMD THE OPPORTUNITY WE ARE SEIZING Make the unprecedented processing capability of the APU as accessible to programmers as the CPU
Intel Core X-Series. The Ultimate platform with unprecedented scalability. The Intel Core i9 Extreme Edition processor
 Product Brief New Intel Core X-series Processor Family Introducing the NEW Intel Core X-Series Processor Family The Ultimate platform with unprecedented scalability The Intel Core i9 Extreme Edition processor
Product Brief New Intel Core X-series Processor Family Introducing the NEW Intel Core X-Series Processor Family The Ultimate platform with unprecedented scalability The Intel Core i9 Extreme Edition processor
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Appendix A Technology and Terms
 Appendix A Technology and Terms AC ACNT ACPI APIC AR ASHRAE ASPM Avoton AVX Bin BIOS BMC CC0/CC1/CC3/CC6 Centerton Alternating current. A term commonly used to describe the IA32_APERF MSR used to calculate
Appendix A Technology and Terms AC ACNT ACPI APIC AR ASHRAE ASPM Avoton AVX Bin BIOS BMC CC0/CC1/CC3/CC6 Centerton Alternating current. A term commonly used to describe the IA32_APERF MSR used to calculate
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
MICROPROCESSOR TECHNOLOGY
 MICROPROCESSOR TECHNOLOGY Assis. Prof. Hossam El-Din Moustafa Lecture 20 Ch.10 Intel Core Duo Processor Architecture 2-Jun-15 1 Chapter Objectives Understand the concept of dual core technology. Look inside
MICROPROCESSOR TECHNOLOGY Assis. Prof. Hossam El-Din Moustafa Lecture 20 Ch.10 Intel Core Duo Processor Architecture 2-Jun-15 1 Chapter Objectives Understand the concept of dual core technology. Look inside
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Meet the Increased Demands on Your Infrastructure with Dell and Intel. ServerWatchTM Executive Brief
 Meet the Increased Demands on Your Infrastructure with Dell and Intel ServerWatchTM Executive Brief a QuinStreet Excutive Brief. 2012 Doing more with less is the mantra that sums up much of the past decade,
Meet the Increased Demands on Your Infrastructure with Dell and Intel ServerWatchTM Executive Brief a QuinStreet Excutive Brief. 2012 Doing more with less is the mantra that sums up much of the past decade,