The RAMDISK Storage Accelerator
|
|
|
- Lucy Hall
- 5 years ago
- Views:
Transcription



1 The RAMDISK Storage Accelerator A Method of Accelerating I/O Performance on HPC Systems Using RAMDISKs Tim Wickberg, Christopher D. Carothers wickbt@rpi.edu, chrisc@cs.rpi.edu Rensselaer Polytechnic Institute
2 Background CPUs performance doubles every 18 months HPC system performance follows this trend Disk I/O throughput doubles once every 10 years This creates an exponentially widening gap between compute and storage systems We can't continue to throw disks at the problem to keep current compute to I/O ratio intact More disks not only cost more, but failure rates also cause problems
3 RAMDISK Storage Accelerator Introduce new layer to HPC data storage the RAMDISK Storage Accelerator (RSA) Functions as a high-speed data staging area Allocated per job, in proportion to compute resources Requires no application modification, only a few settings in job scripts to enable
4 RSA Aggregate RAMDISKs on RSA nodes together using a parallel filesystem PVFS in our tests Lustre, GPFS, Ceph and others possible as well Parallel RAMDISK is exported to I/O nodes in the system
5 Bind mount mount o bind /rsa /place/on/diskfs Application sees a single FS hierarchy, doesn't need to know if the RSA is functional or not Decouples RSA from the compute system, allows the application to function regardless of RSA availability
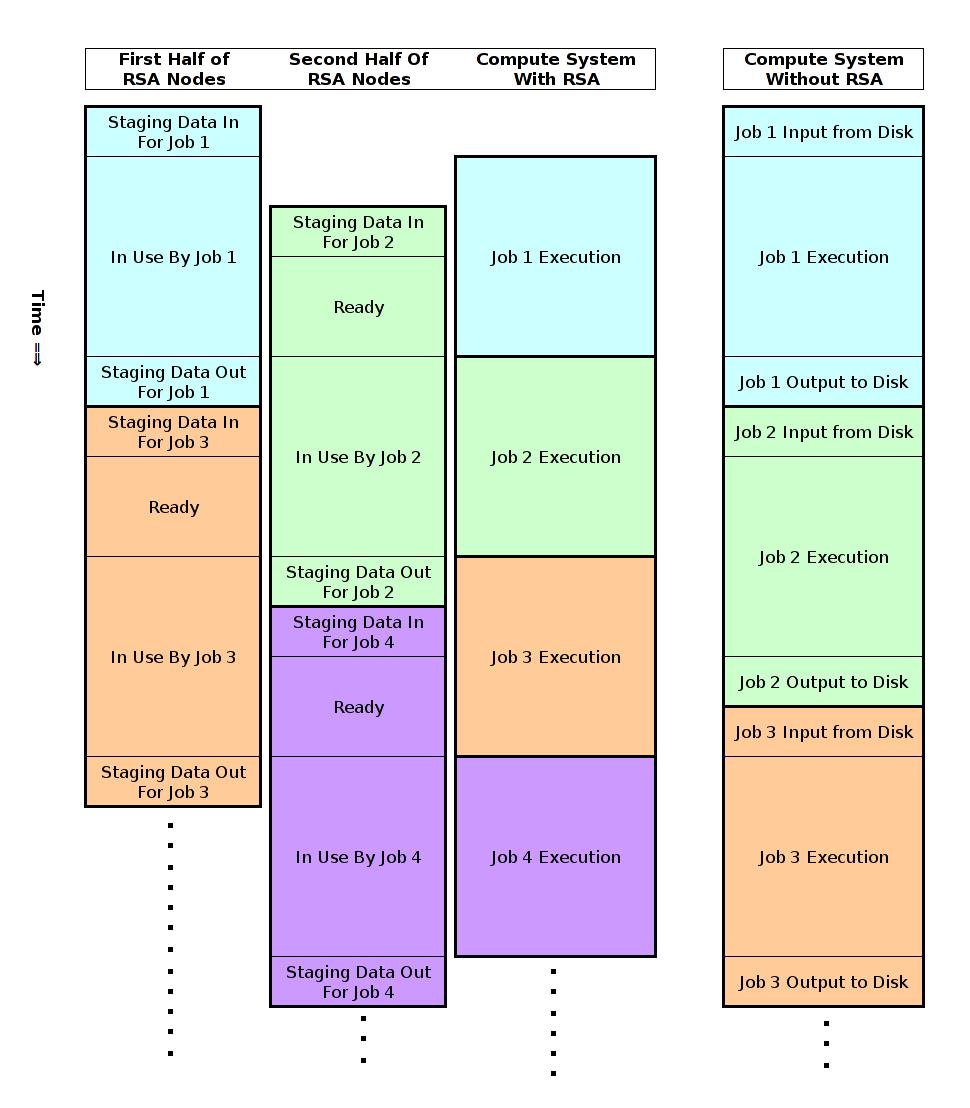
6 Scheduling Set aside half the I/O nodes for active jobs, and the other half for jobs that have finished or will start soon Allocate RSA nodes in proportion to the compute system Data moves asynchronous to job execution, and frees the compute system up sooner.
7 Example job flow Before job begins, selected as next-likely to start. Stage data in to RSA. Job Starts on compute system Reads data in from RSA Checkpoints to RSA Job execution finishes results written to RSA Compute system released RSA pushes results back to disk storage after compute system has moved on to the next job
8 Compare to traditional job flow Initial load: 15 minute read in from disk Checkpoints: 10 minutes per checkpoint, once an hour, 24 hour job run Results back out: 10 minutes 225 minutes spent on I/O
9 RSA Initial load: happens before compute job starts Checkpoints: 1 minute each Results out: 1 minute to RSA Afterwards: results from RSA back to disk storage 25 minutes spent on I/O Saved 200 minutes on the compute system Asynchronous data staging seems likely for any large scale system at this point
10

11 Test System 1-rack Blue Gene/L 16 RSA nodes (borrowed from another cluster), 32GB RAM each Due to networking constraints, a single Gigabit Ethernet link connects the RSA to the BG/L functional network. Bottleneck evident in results.
12 Example RSA Scheduler RSA scheduler implements the scheduling, RSA construction/destruction, data staging Proof-of-concept constructed alongside the SLURM job scheduler
13 Test Results More details in the paper, but briefly: Example test: file-per-process, 2048 processes, 2GB data total GPFS disk: 1100 seconds to write out test data High contention exacerbates problems with GPFS metadata locking RSA: 36 seconds to write to RSA 222 seconds after compute system is released to push data back to GPFS Data staged back from single system avoids GPFS contention issues 2800% speedup from the application / compute system's viewpoint
 Blue Gene/Q 32 RSA Nodes, each 128GB+ RAM, 4TB+ total.")
14 Future Work Full-scale test system to be CCNI in the next six months 1-rack (200 TFLOPS) Blue Gene/Q 32 RSA Nodes, each 128GB+ RAM, 4TB+ total. FDR (56Gbps) Infiniband fabric
15 Extensions RAM is faster, but SSDs are catching up, and provide better price/capacity. Everything shown here can extend to SSD-backed systems as well. Overhead in Linux memory management. Data copied in-memory ~5 times on the way in or out, this could be reduced with major modification to the kernel. Or, perhaps a simplified OS could be developed to support this. Handle RSA scheduling directly in job scheduler, rather than external
16 Conclusions: I/O continues to fall behind compute capacity The RSA provides a method to mitigate this problem Frees the compute system faster, reduce pressure on disk storage I/O Possible to integrate into HPC systems without changing applications
17 Thank You
18 Questions?
Parallel File Systems. John White Lawrence Berkeley National Lab
 Parallel File Systems John White Lawrence Berkeley National Lab Topics Defining a File System Our Specific Case for File Systems Parallel File Systems A Survey of Current Parallel File Systems Implementation
Parallel File Systems John White Lawrence Berkeley National Lab Topics Defining a File System Our Specific Case for File Systems Parallel File Systems A Survey of Current Parallel File Systems Implementation
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Slurm at the George Washington University Tim Wickberg - Slurm User Group Meeting 2015
 Slurm at the George Washington University Tim Wickberg - wickberg@gwu.edu Slurm User Group Meeting 2015 September 16, 2015 Colonial One What s new? Only major change was switch to FairTree Thanks to BYU
Slurm at the George Washington University Tim Wickberg - wickberg@gwu.edu Slurm User Group Meeting 2015 September 16, 2015 Colonial One What s new? Only major change was switch to FairTree Thanks to BYU
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
HPC Storage Use Cases & Future Trends
 Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Azor: Using Two-level Block Selection to Improve SSD-based I/O caches
 Azor: Using Two-level Block Selection to Improve SSD-based I/O caches Yannis Klonatos, Thanos Makatos, Manolis Marazakis, Michail D. Flouris, Angelos Bilas {klonatos, makatos, maraz, flouris, bilas}@ics.forth.gr
Azor: Using Two-level Block Selection to Improve SSD-based I/O caches Yannis Klonatos, Thanos Makatos, Manolis Marazakis, Michail D. Flouris, Angelos Bilas {klonatos, makatos, maraz, flouris, bilas}@ics.forth.gr
Triton file systems - an introduction. slide 1 of 28
 Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Triton file systems - an introduction slide 1 of 28 File systems Motivation & basic concepts Storage locations Basic flow of IO Do's and Don'ts Exercises slide 2 of 28 File systems: Motivation Case #1:
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage
![Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage](/thumbs/92/109196544.jpg "Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage") Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Habanero Operating Committee. January
 Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
IBM V7000 Unified R1.4.2 Asynchronous Replication Performance Reference Guide
 V7 Unified Asynchronous Replication Performance Reference Guide IBM V7 Unified R1.4.2 Asynchronous Replication Performance Reference Guide Document Version 1. SONAS / V7 Unified Asynchronous Replication
V7 Unified Asynchronous Replication Performance Reference Guide IBM V7 Unified R1.4.2 Asynchronous Replication Performance Reference Guide Document Version 1. SONAS / V7 Unified Asynchronous Replication
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT
 INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT Abhisek Pan 2, J.P. Walters 1, Vijay S. Pai 1,2, David Kang 1, Stephen P. Crago 1 1 University of Southern California/Information Sciences Institute 2
INTEGRATING HPFS IN A CLOUD COMPUTING ENVIRONMENT Abhisek Pan 2, J.P. Walters 1, Vijay S. Pai 1,2, David Kang 1, Stephen P. Crago 1 1 University of Southern California/Information Sciences Institute 2
Coordinating Parallel HSM in Object-based Cluster Filesystems
 Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Lustre at Scale The LLNL Way
 Lustre at Scale The LLNL Way D. Marc Stearman Lustre Administration Lead Livermore uting - LLNL This work performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory
Lustre at Scale The LLNL Way D. Marc Stearman Lustre Administration Lead Livermore uting - LLNL This work performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Application Performance on IME
 Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
Beyond Petascale. Roger Haskin Manager, Parallel File Systems IBM Almaden Research Center
 Beyond Petascale Roger Haskin Manager, Parallel File Systems IBM Almaden Research Center GPFS Research and Development! GPFS product originated at IBM Almaden Research Laboratory! Research continues to
Beyond Petascale Roger Haskin Manager, Parallel File Systems IBM Almaden Research Center GPFS Research and Development! GPFS product originated at IBM Almaden Research Laboratory! Research continues to
Cluster Setup and Distributed File System
 Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
Cluster Setup and Distributed File System R&D Storage for the R&D Storage Group People Involved Gaetano Capasso - INFN-Naples Domenico Del Prete INFN-Naples Diacono Domenico INFN-Bari Donvito Giacinto
Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments
 LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
LCI HPC Revolution 2005 26 April 2005 Shared Parallel Filesystems in Heterogeneous Linux Multi-Cluster Environments Matthew Woitaszek matthew.woitaszek@colorado.edu Collaborators Organizations National
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems
 Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems Adnan Haider 1, Sheri Mickelson 2, John Dennis 2 1 Illinois Institute of Technology, USA; 2 National Center of Atmospheric Research,
Lessons from Post-processing Climate Data on Modern Flash-based HPC Systems Adnan Haider 1, Sheri Mickelson 2, John Dennis 2 1 Illinois Institute of Technology, USA; 2 National Center of Atmospheric Research,
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Extraordinary HPC file system solutions at KIT
 Extraordinary HPC file system solutions at KIT Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State Roland of Baden-Württemberg Laifer Lustre and tools for ldiskfs investigation
Extraordinary HPC file system solutions at KIT Roland Laifer STEINBUCH CENTRE FOR COMPUTING - SCC KIT University of the State Roland of Baden-Württemberg Laifer Lustre and tools for ldiskfs investigation
I/O and Scheduling aspects in DEEP-EST
 I/O and Scheduling aspects in DEEP-EST Norbert Eicker Jülich Supercomputing Centre & University of Wuppertal The research leading to these results has received funding from the European Community's Seventh
I/O and Scheduling aspects in DEEP-EST Norbert Eicker Jülich Supercomputing Centre & University of Wuppertal The research leading to these results has received funding from the European Community's Seventh
GFS: The Google File System
 GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
GFS: The Google File System Brad Karp UCL Computer Science CS GZ03 / M030 24 th October 2014 Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads
 Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
Network Design Considerations for Grid Computing
 Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
Network Design Considerations for Grid Computing Engineering Systems How Bandwidth, Latency, and Packet Size Impact Grid Job Performance by Erik Burrows, Engineering Systems Analyst, Principal, Broadcom
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung SOSP 2003 presented by Kun Suo Outline GFS Background, Concepts and Key words Example of GFS Operations Some optimizations in
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
Flux: The State of the Cluster
 Flux: The State of the Cluster Andrew Caird acaird@umich.edu 7 November 2012 Questions Thank you all for coming. Questions? Andy Caird (acaird@umich.edu, hpc-support@umich.edu) Flux Since Last November
Flux: The State of the Cluster Andrew Caird acaird@umich.edu 7 November 2012 Questions Thank you all for coming. Questions? Andy Caird (acaird@umich.edu, hpc-support@umich.edu) Flux Since Last November
InfiniBand Networked Flash Storage
 InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
InfiniBand Networked Flash Storage Superior Performance, Efficiency and Scalability Motti Beck Director Enterprise Market Development, Mellanox Technologies Flash Memory Summit 2016 Santa Clara, CA 1 17PB
SuperMike-II Launch Workshop. System Overview and Allocations
 : System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
: System Overview and Allocations Dr Jim Lupo CCT Computational Enablement jalupo@cct.lsu.edu SuperMike-II: Serious Heterogeneous Computing Power System Hardware SuperMike provides 442 nodes, 221TB of
Voltaire Making Applications Run Faster
 Voltaire Making Applications Run Faster Asaf Somekh Director, Marketing Voltaire, Inc. Agenda HPC Trends InfiniBand Voltaire Grid Backbone Deployment examples About Voltaire HPC Trends Clusters are the
Voltaire Making Applications Run Faster Asaf Somekh Director, Marketing Voltaire, Inc. Agenda HPC Trends InfiniBand Voltaire Grid Backbone Deployment examples About Voltaire HPC Trends Clusters are the
Progress Report on Transparent Checkpointing for Supercomputing
 Progress Report on Transparent Checkpointing for Supercomputing Jiajun Cao, Rohan Garg College of Computer and Information Science, Northeastern University {jiajun,rohgarg}@ccs.neu.edu August 21, 2015
Progress Report on Transparent Checkpointing for Supercomputing Jiajun Cao, Rohan Garg College of Computer and Information Science, Northeastern University {jiajun,rohgarg}@ccs.neu.edu August 21, 2015
ECE7995 (3) Basis of Caching and Prefetching --- Locality
 Basis of Caching and Prefetching --- Locality") ECE7995 (3) Basis of Caching and Prefetching --- Locality 1 What s locality? Temporal locality is a property inherent to programs and independent of their execution environment. Temporal locality: the
ECE7995 (3) Basis of Caching and Prefetching --- Locality 1 What s locality? Temporal locality is a property inherent to programs and independent of their execution environment. Temporal locality: the
Mission-Critical Lustre at Santos. Adam Fox, Lustre User Group 2016
 Mission-Critical Lustre at Santos Adam Fox, Lustre User Group 2016 About Santos One of the leading oil and gas producers in APAC Founded in 1954 South Australia Northern Territory Oil Search Cooper Basin
Mission-Critical Lustre at Santos Adam Fox, Lustre User Group 2016 About Santos One of the leading oil and gas producers in APAC Founded in 1954 South Australia Northern Territory Oil Search Cooper Basin
BeeGFS. Parallel Cluster File System. Container Workshop ISC July Marco Merkel VP ww Sales, Consulting
 BeeGFS The Parallel Cluster File System Container Workshop ISC 28.7.18 www.beegfs.io July 2018 Marco Merkel VP ww Sales, Consulting HPC & Cognitive Workloads Demand Today Flash Storage HDD Storage Shingled
BeeGFS The Parallel Cluster File System Container Workshop ISC 28.7.18 www.beegfs.io July 2018 Marco Merkel VP ww Sales, Consulting HPC & Cognitive Workloads Demand Today Flash Storage HDD Storage Shingled
HIGH-PERFORMANCE STORAGE FOR DISCOVERY THAT SOARS
 HIGH-PERFORMANCE STORAGE FOR DISCOVERY THAT SOARS OVERVIEW When storage demands and budget constraints collide, discovery suffers. And it s a growing problem. Driven by ever-increasing performance and
HIGH-PERFORMANCE STORAGE FOR DISCOVERY THAT SOARS OVERVIEW When storage demands and budget constraints collide, discovery suffers. And it s a growing problem. Driven by ever-increasing performance and
1. ALMA Pipeline Cluster specification. 2. Compute processing node specification: $26K
 1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
Parallel File Systems for HPC
 Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
HIGH PERFORMANCE COMPUTING FROM SUN
 HIGH PERFORMANCE COMPUTING FROM SUN Update for IDC HPC User Forum, Norfolk, VA April 2008 Bjorn Andersson Director, HPC and Integrated Systems Sun Microsystems Sun Constellation System Integrating the
HIGH PERFORMANCE COMPUTING FROM SUN Update for IDC HPC User Forum, Norfolk, VA April 2008 Bjorn Andersson Director, HPC and Integrated Systems Sun Microsystems Sun Constellation System Integrating the
Improving I/O Bandwidth With Cray DVS Client-Side Caching
 Improving I/O Bandwidth With Cray DVS Client-Side Caching Bryce Hicks Cray Inc. Bloomington, MN USA bryceh@cray.com Abstract Cray s Data Virtualization Service, DVS, is an I/O forwarder providing access
Improving I/O Bandwidth With Cray DVS Client-Side Caching Bryce Hicks Cray Inc. Bloomington, MN USA bryceh@cray.com Abstract Cray s Data Virtualization Service, DVS, is an I/O forwarder providing access
Data Movement & Tiering with DMF 7
 Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
Xyratex ClusterStor6000 & OneStor
 Xyratex ClusterStor6000 & OneStor Proseminar Ein-/Ausgabe Stand der Wissenschaft von Tim Reimer Structure OneStor OneStorSP OneStorAP ''Green'' Advancements ClusterStor6000 About Scale-Out Storage Architecture
Xyratex ClusterStor6000 & OneStor Proseminar Ein-/Ausgabe Stand der Wissenschaft von Tim Reimer Structure OneStor OneStorSP OneStorAP ''Green'' Advancements ClusterStor6000 About Scale-Out Storage Architecture
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
IBM s Data Warehouse Appliance Offerings
 IBM s Data Warehouse Appliance Offerings RChaitanya IBM India Software Labs Agenda 1 IBM Smart Analytics System (D5600) System Overview Technical Architecture Software / Hardware stack details 2 Netezza
IBM s Data Warehouse Appliance Offerings RChaitanya IBM India Software Labs Agenda 1 IBM Smart Analytics System (D5600) System Overview Technical Architecture Software / Hardware stack details 2 Netezza
Milestone Systems Husky Network Video Recorders Product Comparison Chart September 9, 2016
 Systems Husky Network Video Recorders Product Comparison Chart September 9, 2016 Husky comparison chart Husky NVR series The innovative Husky series of network video recorders (NVRs) delivers fully-integrated,
Systems Husky Network Video Recorders Product Comparison Chart September 9, 2016 Husky comparison chart Husky NVR series The innovative Husky series of network video recorders (NVRs) delivers fully-integrated,
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
Filesystem Performance on FreeBSD
 Filesystem Performance on FreeBSD Kris Kennaway kris@freebsd.org BSDCan 2006, Ottawa, May 12 Introduction Filesystem performance has many aspects No single metric for quantifying it I will focus on aspects
Filesystem Performance on FreeBSD Kris Kennaway kris@freebsd.org BSDCan 2006, Ottawa, May 12 Introduction Filesystem performance has many aspects No single metric for quantifying it I will focus on aspects
Current Status of the Ceph Based Storage Systems at the RACF
 Journal of Physics: Conference Series PAPER OPEN ACCESS Current Status of the Ceph Based Storage Systems at the RACF To cite this article: A. Zaytsev et al 2015 J. Phys.: Conf. Ser. 664 042027 View the
Journal of Physics: Conference Series PAPER OPEN ACCESS Current Status of the Ceph Based Storage Systems at the RACF To cite this article: A. Zaytsev et al 2015 J. Phys.: Conf. Ser. 664 042027 View the
CSCS HPC storage. Hussein N. Harake
 CSCS HPC storage Hussein N. Harake Points to Cover - XE6 External Storage (DDN SFA10K, SRP, QDR) - PCI-E SSD Technology - RamSan 620 Technology XE6 External Storage - Installed Q4 2010 - In Production
CSCS HPC storage Hussein N. Harake Points to Cover - XE6 External Storage (DDN SFA10K, SRP, QDR) - PCI-E SSD Technology - RamSan 620 Technology XE6 External Storage - Installed Q4 2010 - In Production
High Performance Solid State Storage Under Linux
 High Performance Solid State Storage Under Linux Eric Seppanen, Matthew T. O Keefe, David J. Lilja Electrical and Computer Engineering University of Minnesota April 20, 2010 Motivation SSDs breaking through
High Performance Solid State Storage Under Linux Eric Seppanen, Matthew T. O Keefe, David J. Lilja Electrical and Computer Engineering University of Minnesota April 20, 2010 Motivation SSDs breaking through
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
LQCD Facilities at Jefferson Lab. Chip Watson May 6, 2011
 LQCD Facilities at Jefferson Lab Chip Watson May 6, 2011 Page 1 Outline Overview of hardware at Jefferson Lab GPU evolution since last year GPU R&D activities Operations Summary Page 2 CPU + Infiniband
LQCD Facilities at Jefferson Lab Chip Watson May 6, 2011 Page 1 Outline Overview of hardware at Jefferson Lab GPU evolution since last year GPU R&D activities Operations Summary Page 2 CPU + Infiniband
CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING. M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś
 CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś Presentation plan 2 Cyfronet introduction System description SLURM modifications Job
CYFRONET SITE REPORT IMPROVING SLURM USABILITY AND MONITORING M. Pawlik, J. Budzowski, L. Flis, P. Lasoń, M. Magryś Presentation plan 2 Cyfronet introduction System description SLURM modifications Job
Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures
 Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures Min Li, Sudharshan S. Vazhkudai, Ali R. Butt, Fei Meng, Xiaosong Ma, Youngjae Kim,Christian Engelmann, and Galen Shipman
Functional Partitioning to Optimize End-to-End Performance on Many-core Architectures Min Li, Sudharshan S. Vazhkudai, Ali R. Butt, Fei Meng, Xiaosong Ma, Youngjae Kim,Christian Engelmann, and Galen Shipman
Cray XD1 Supercomputer Release 1.3 CRAY XD1 DATASHEET
 CRAY XD1 DATASHEET Cray XD1 Supercomputer Release 1.3 Purpose-built for HPC delivers exceptional application performance Affordable power designed for a broad range of HPC workloads and budgets Linux,
CRAY XD1 DATASHEET Cray XD1 Supercomputer Release 1.3 Purpose-built for HPC delivers exceptional application performance Affordable power designed for a broad range of HPC workloads and budgets Linux,
The Economics of InfiniBand Virtual Device I/O
 The Economics of InfiniBand Virtual Device I/O IBTA's Technical Forum '08: InfiniBand and the Enterprise Data Center Jacob Hall Wachovia Corporate & Investment Banking VP, Chief Architect Technology Products
The Economics of InfiniBand Virtual Device I/O IBTA's Technical Forum '08: InfiniBand and the Enterprise Data Center Jacob Hall Wachovia Corporate & Investment Banking VP, Chief Architect Technology Products
LHConCRAY. Acceptance Tests 2017 Run4 System Report Miguel Gila, CSCS August 03, 2017
 LHConCRAY Acceptance Tests 2017 Run4 System Report Miguel Gila, CSCS August 03, 2017 Table of Contents 1. Changes since Run2/3 2. DataWarp 3. Current configuration 4. System statistics 5. Next steps LHConCRAY
LHConCRAY Acceptance Tests 2017 Run4 System Report Miguel Gila, CSCS August 03, 2017 Table of Contents 1. Changes since Run2/3 2. DataWarp 3. Current configuration 4. System statistics 5. Next steps LHConCRAY
Creating High Performance Clusters for Embedded Use
 Creating High Performance Clusters for Embedded Use 1 The Hype.. The Internet of Things has the capacity to create huge amounts of data Gartner forecasts 35ZB of data from things by 2020 etc Intel Putting
Creating High Performance Clusters for Embedded Use 1 The Hype.. The Internet of Things has the capacity to create huge amounts of data Gartner forecasts 35ZB of data from things by 2020 etc Intel Putting
The rcuda technology: an inexpensive way to improve the performance of GPU-based clusters Federico Silla
 The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
IBM Spectrum Scale IO performance
 IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine
 SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine April 2007 Part No 820-1270-11 Revision 1.1, 4/18/07
SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine April 2007 Part No 820-1270-11 Revision 1.1, 4/18/07
Parallel File Systems Compared
 Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Picking the right number of targets per server for BeeGFS. Jan Heichler March 2015 v1.3
 Picking the right number of targets per server for BeeGFS Jan Heichler March 2015 v1.3 Picking the right number of targets per server for BeeGFS 2 Abstract In this paper we will show the performance of
Picking the right number of targets per server for BeeGFS Jan Heichler March 2015 v1.3 Picking the right number of targets per server for BeeGFS 2 Abstract In this paper we will show the performance of
Parallel Storage Systems for Large-Scale Machines
 Parallel Storage Systems for Large-Scale Machines Doctoral Showcase Christos FILIPPIDIS (cfjs@outlook.com) Department of Informatics and Telecommunications, National and Kapodistrian University of Athens
Parallel Storage Systems for Large-Scale Machines Doctoral Showcase Christos FILIPPIDIS (cfjs@outlook.com) Department of Informatics and Telecommunications, National and Kapodistrian University of Athens
Architecting Storage for Semiconductor Design: Manufacturing Preparation
 White Paper Architecting Storage for Semiconductor Design: Manufacturing Preparation March 2012 WP-7157 EXECUTIVE SUMMARY The manufacturing preparation phase of semiconductor design especially mask data
White Paper Architecting Storage for Semiconductor Design: Manufacturing Preparation March 2012 WP-7157 EXECUTIVE SUMMARY The manufacturing preparation phase of semiconductor design especially mask data
NetApp High-Performance Storage Solution for Lustre
 Technical Report NetApp High-Performance Storage Solution for Lustre Solution Design Narjit Chadha, NetApp October 2014 TR-4345-DESIGN Abstract The NetApp High-Performance Storage Solution (HPSS) for Lustre,
Technical Report NetApp High-Performance Storage Solution for Lustre Solution Design Narjit Chadha, NetApp October 2014 TR-4345-DESIGN Abstract The NetApp High-Performance Storage Solution (HPSS) for Lustre,
AIST Super Green Cloud
 AIST Super Green Cloud A build-once-run-everywhere high performance computing platform Takahiro Hirofuchi, Ryosei Takano, Yusuke Tanimura, Atsuko Takefusa, and Yoshio Tanaka Information Technology Research
AIST Super Green Cloud A build-once-run-everywhere high performance computing platform Takahiro Hirofuchi, Ryosei Takano, Yusuke Tanimura, Atsuko Takefusa, and Yoshio Tanaka Information Technology Research
Automated Configuration and Administration of a Storage-class Memory System to Support Supercomputer-based Scientific Workflows
 Automated Configuration and Administration of a Storage-class Memory System to Support Supercomputer-based Scientific Workflows J. Bernard 1, P. Morjan 2, B. Hagley 3, F. Delalondre 1, F. Schürmann 1,
Automated Configuration and Administration of a Storage-class Memory System to Support Supercomputer-based Scientific Workflows J. Bernard 1, P. Morjan 2, B. Hagley 3, F. Delalondre 1, F. Schürmann 1,
GPUfs: Integrating a file system with GPUs
 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
Comet Virtualization Code & Design Sprint
 Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
DATARMOR: Comment s'y préparer? Tina Odaka
 DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
The bidder should be willing to arrange for a demonstration of equipment offered at free of cost on
 INDIAN INSTITUTE OF TECHNOLOGY TIRUPATI RENIGUNTA ROAD, TIRUPATI- 517 506 Date: 26.04.2018 Public Tender No.IITT/Comp/09/2017-18/08 Due date extended up to 21.05.2018 at 15.30 hours Name of supply: Supply
INDIAN INSTITUTE OF TECHNOLOGY TIRUPATI RENIGUNTA ROAD, TIRUPATI- 517 506 Date: 26.04.2018 Public Tender No.IITT/Comp/09/2017-18/08 Due date extended up to 21.05.2018 at 15.30 hours Name of supply: Supply
Lustre TM. Scalability
 Lustre TM Scalability An Oak Ridge National Laboratory/ Lustre Center of Excellence White Paper February 2009 2 Sun Microsystems, Inc Table of Contents Executive Summary...3 HPC Trends...3 Lustre File
Lustre TM Scalability An Oak Ridge National Laboratory/ Lustre Center of Excellence White Paper February 2009 2 Sun Microsystems, Inc Table of Contents Executive Summary...3 HPC Trends...3 Lustre File
Diamond Networks/Computing. Nick Rees January 2011
 Diamond Networks/Computing Nick Rees January 2011 2008 computing requirements Diamond originally had no provision for central science computing. Started to develop in 2007-2008, with a major development
Diamond Networks/Computing Nick Rees January 2011 2008 computing requirements Diamond originally had no provision for central science computing. Started to develop in 2007-2008, with a major development
Warehouse- Scale Computing and the BDAS Stack
 Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
New Storage Technologies First Impressions: SanDisk IF150 & Intel Omni-Path. Brian Marshall GPFS UG - SC16 November 13, 2016
 New Storage Technologies First Impressions: SanDisk IF150 & Intel Omni-Path Brian Marshall GPFS UG - SC16 November 13, 2016 Presenter Background Brian Marshall Computational Scientist at Virginia Tech
New Storage Technologies First Impressions: SanDisk IF150 & Intel Omni-Path Brian Marshall GPFS UG - SC16 November 13, 2016 Presenter Background Brian Marshall Computational Scientist at Virginia Tech
NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC
 Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
Segregated storage and compute NFS, GPFS, PVFS, Lustre Batch-scheduled systems: Clusters, Grids, and Supercomputers Programming paradigm: HPC, MTC, and HTC Co-located storage and compute HDFS, GFS Data
A New NSF TeraGrid Resource for Data-Intensive Science
 A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
GFS: The Google File System. Dr. Yingwu Zhu
 GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
GFS: The Google File System Dr. Yingwu Zhu Motivating Application: Google Crawl the whole web Store it all on one big disk Process users searches on one big CPU More storage, CPU required than one PC can
Structuring PLFS for Extensibility
 Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Virtual Machine Migration
 Virtual Machine Migration Network Startup Resource Center www.nsrc.org These materials are licensed under the Creative Commons Attribution-NonCommercial 4.0 International license (http://creativecommons.org/licenses/by-nc/4.0/)
Virtual Machine Migration Network Startup Resource Center www.nsrc.org These materials are licensed under the Creative Commons Attribution-NonCommercial 4.0 International license (http://creativecommons.org/licenses/by-nc/4.0/)
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
The Last Bottleneck: How Parallel I/O can improve application performance
 The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who
The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who