I/O and Scheduling aspects in DEEP-EST
|
|
|
- Tyler Gibson
- 5 years ago
- Views:
Transcription
1 I/O and Scheduling aspects in DEEP-EST Norbert Eicker Jülich Supercomputing Centre & University of Wuppertal The research leading to these results has received funding from the European Community's Seventh Framework Programme (FP7/ ) under Grant Agreement n and n

2 Collaborative R&D in DEEP projects (DEEP + DEEP-ER + DEEP-EST) EU-Exascale projects 27 partners Total budget: 44 M EU-funding: 30 M Nov 2011 Jun

3 September 2017 Lippert I/O and Scheduling aspects in Thomas DEEP-EST EIUG Workshop Hamburg 3 3 Slide
 ~ 350 Trainees Research for the future for key technologies of the next")
4 Science Campus Jülich 5,700 staff members Budget (2015): 558 mio. Institutional funding: 320 mio. Third party funding: 238 mio. Project management: 1,6 billion Teaching: ~ 900 PhD students (Campus Jülich) ~ 350 Trainees Research for the future for key technologies of the next generation and Information Slide 4


5 Past: Supercomputer JSC IBM Power 4+ JUMP, 9 TFlop/s IBM Blue Gene/L JUBL, 45 TFlop/s IBM Power 6 JUMP, 9 TFlop/s JUROPA 200 TFlop/s HPC-FF 100 TFlop/s IBM Blue Gene/P JUGENE, 1 PFlop/s File Server IBM Blue Gene/Q JUQUEEN 5.9 PFlop/s Lustre GPFS JURECA 2 PFlop/s + Booster ~ 5 PFlop/s JUQUEEN successor Modular System Highly Scalable Slide 5

6 Research Field Usage 11/ /2017 Leadership-Class System General-Purpose Supercomputer Granting periods 05/ / / /2016 Slide 6



7 Application's Scalability Only few application capable to scale to O(450k) cores Sparse matrix-vector codes Highly regular communication patterns Well suited for BG/Q Most applications are more complex Less regular control flow / memory access Complicated communication patterns Less capable to exploit accelerators How to map different requirements to most suited hardware Heterogeneity might be beneficial Do we need better programming models? Slide 7
8 Heterogeneous Clusters GPU GPU GPU Flat IB-topology Simple management of resources InfiniBand GPU GPU GPU Static assignment of CPUs to GPUs Accelerators not capable to act autonomously 8
9 Alternative Integration Go for more capable accelerators (e.g. MIC) Acc Attach all nodes to a low-latency fabric All nodes might act autonomously Acc Acc Acc Dynamical assignment of cluster-nodes and accelerators Acc IB can be assumed as fast as PCIe besides latency Ability to off-load more complex (including parallel) kernels communication between CPU and Accelerator less frequently larger messages i.e. less sensitive to latency 9
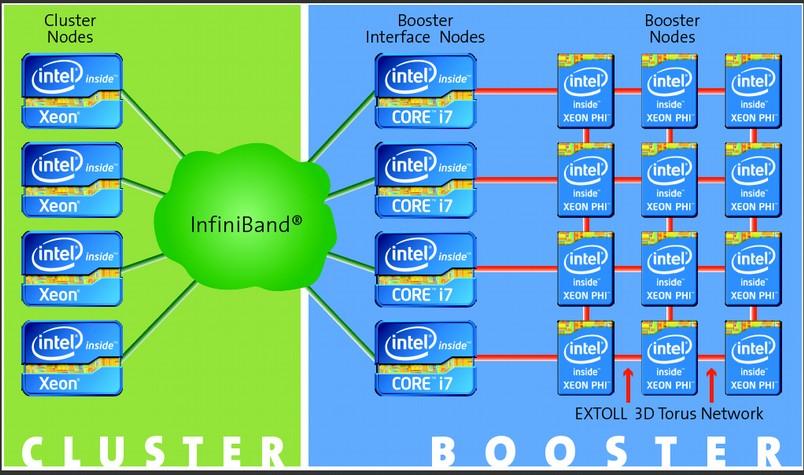
10 Hardware Architecture 10

11 CyI Climate Simulation 11
 Computational fluid engineering (CERFACS) High temperature superconductivity (CINECA) Seismic imaging (CGG) Human")
 Goals: Co-design and evaluation of architecture and its programmability Analysis of the I/O and resiliency requirements of")
12 Application-driven approach DEEP+DEEP-ER applications: Brain simulation (EPFL) Space weather simulation (KULeuven) Climate simulation (Cyprus Institute) Computational fluid engineering (CERFACS) High temperature superconductivity (CINECA) Seismic imaging (CGG) Human exposure to electromagnetic fields (INRIA) Geoscience (LRZ Munich) Radio astronomy (Astron) Oil exploration (BSC) Lattice QCD (University of Regensburg) Goals: Co-design and evaluation of architecture and its programmability Analysis of the I/O and resiliency requirements of HPC codes 12
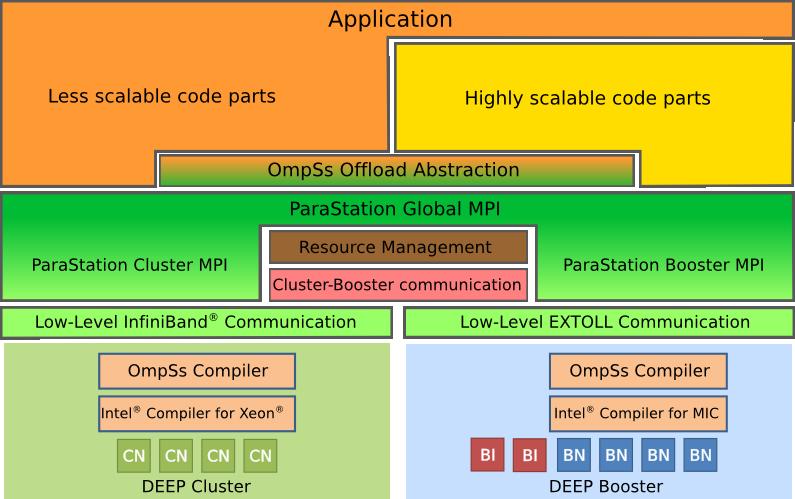
13 Software Architecture 13
14 Application Startup Application highly scalable code-part main() part OmpSs Global MPI Resource management er t s Clu Application's main()-part runs on Cluster-nodes () only Actual spawn done via global MPI OmpSs acts as an abstraction layer er t s o Bo Spawn is a collective operation of Cluster-processes Highly scalable code-parts (HSCP) utilize multiple Booster-nodes (BN) 14
15 MPI Process Creation The inter-communicator contains all parents on the one side and all children on the other side. Returned by MPI_Comm_spawn for the parents Returned by MPI_Get_parent by the children Rank numbers are the same as in the the corresponding intracommunicator. Cluster comm MPI_COMM_WORLD (A) BN MPI BN BN MPI_COMM_WORLD (B) Inter-Communicator Booster 15
16 Programming Booster Interface Cluster Booster ParaStation global MPI Cluster Booster Protocol Extoll Infiniband MPI_Comm_spawn 16
 onto (com, size*rank+1) Compiler Application binaries DEEP Runtime")
17 Application running on DEEP Source code #pragma omp task in( ) out ( ) onto (com, size*rank+1) Compiler Application binaries DEEP Runtime 17
18 Modular Supercomputing Generalization of the Cluster-Booster concept Module 1: Storage Disk Disk Module 2: Cluster Module 3: Many core Booster BN BN BN BN BN BN Module 4: Memory Booster DN NAM BN BN DN Module 6: Graphics Booster BN Module 5: Data Analytics NAM GN NIC NIC NIC MEM NVM MEM BN NIC NAM GN NIC GN 18
19 Modular Supercomputing Workload 1 Workload 2 Workload 3 19

20 Modular Supercomputing 20




21 SLURM JSC decided to go for SLURM with the start of JURECA in 2015 Close collaboration with ParTec for deep integration with PS-MPI Currently waiting for job-packs We expect to extend the scheduling capabilities for support of complex job requirements Workflows without communication via the filesystem 21




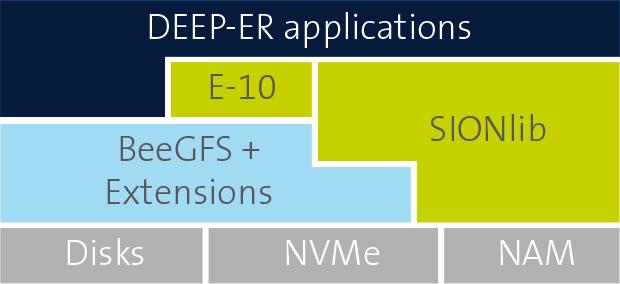
22 Scalable I/O in DEEP-ER Improve I/O scalability on all usage-levels Used also for checkpointing 22




23 BeeGFS and Caching Two instances: Global FS on HDD server Cache FS on NVM at node API for cache domain handling Synchronous version Asynchronous version 23
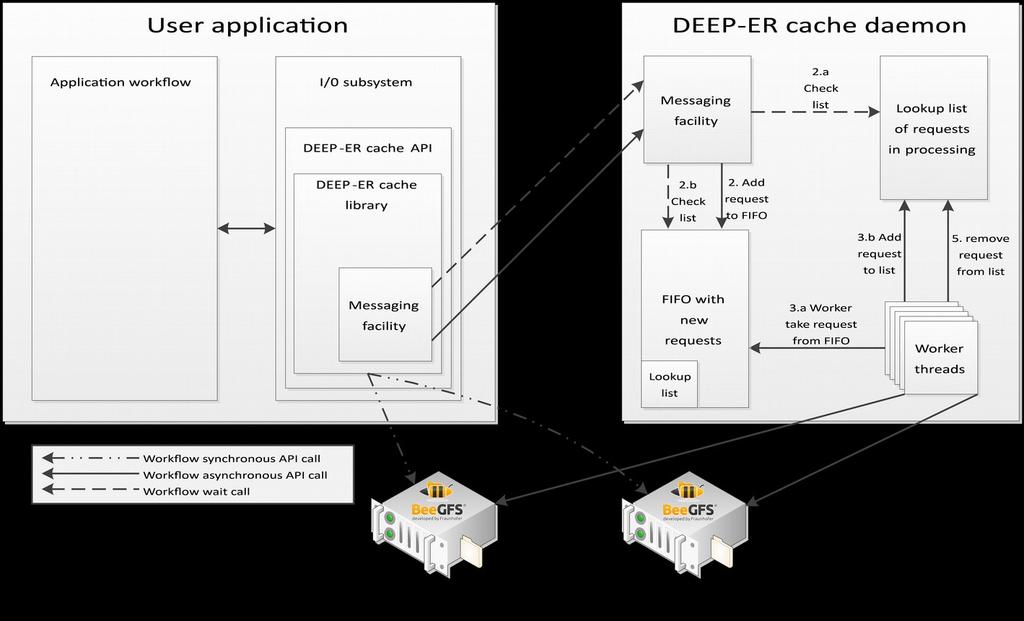
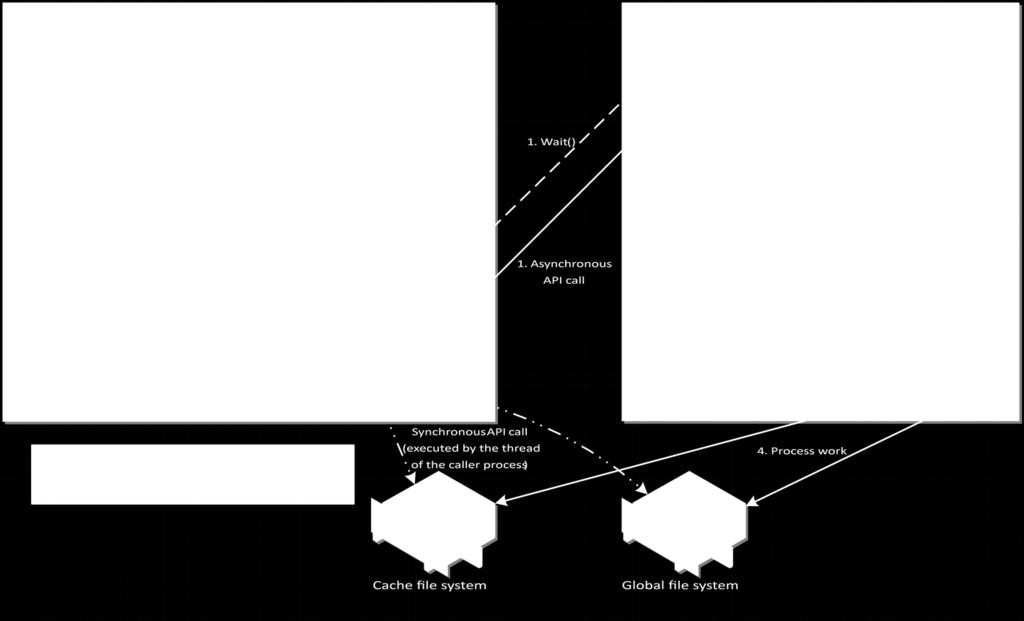
24 Asynchronous Cache API 24
25 Cache Integration in ROMIO New MPI-IO Hints Developed in DEEP-ER and tested on DEEP Cluster e10_cache e10_cache_path Global Sync Group (MPI_COMM_WORLD) e10_cache_flush_flag Processes e10_cache_discard_flag e10_cache_threads ROMIO ADIO (Abstract Device IO) GPFS Driver UFS Driver BeeGFS Driver Common Layer (DEEP-ER Cache) Parallel File System Buffers Collective Buffers MPI-IO Lustre Driver 0 Collective I/O DEEP-ER Cache Independent I/O Parallel File System 25
26 MPIWRAP Support Library MPI_Init, MPI_Finalize MPI_File_open, MPI_File_close MPI-IO hints are defined in a config file and injected by libmpiwrap into the middleware Provides deeper and more flexible control of MPI-IO functionalities to the users Provides transparent integration of E10 functionalities into applications Works with any high level library (e.g. phdf5) MPIWRAP MPI-IO ROMIO ADIO (Abstract Device IO) Lustre Driver GPFS Driver UFS Driver BeeGFS Driver Common Layer (DEEP-ER Cache) Parallel File System 26
: time to sync S(k) with the parallel file system C (k): compute time at phase k")
27 Effects of the Cache S (k): amount of data written to the file at phase k Tc(k): time to write S(k) to the cache Ts(k): time to sync S(k) with the parallel file system C (k): compute time at phase k 27
 writing a 32GB share file varying # of aggregators and collective buffer size TBW represents the maximum theoretical bandwidth achievable when writing to the cache")
28 Exper. Results IOR 512 processes (8/node) writing a 32GB share file varying # of aggregators and collective buffer size TBW represents the maximum theoretical bandwidth achievable when writing to the cache without flushing it to the parallel file system In IOR the last write sync phase is not overlapped with any computation and thus it is CONGIU, G., et al IEEE affecting the overall bandwidth performance 28
 writing a 32GB share file varying # of aggregators and collective buffer size TBW represents the maximum theoretical bandwidth achievable when writing to the cache")
29 Exper. Results IOR 512 processes (8/node) writing a 32GB share file varying # of aggregators and collective buffer size TBW represents the maximum theoretical bandwidth achievable when writing to the cache without flushing it to the parallel file system In IOR the last write sync phase is not overlapped with any computation and thus it is CONGIU, G., et al IEEE affecting the overall bandwidth performance 29



30 SIONlib API resembles logical task-local files Simple integration into application code Internal mapping to single or few large files Reduces load on meta data server Serial program t1 Application Tasks t3 tn-2 t2 tn-1 tn Logical task-local files Physical multi-file SIONlib Parallel file system 30
31 Write buddy checkpoint SIONlib MPI Node Global File System local t1 local data Node local buddy t2 local data Node local buddy Node t3 local data local t4 local data buddy Node local buddy t5 local data Node local buddy t6 local data buddy lcom Open: sid=sion_paropen_mpi(, bw,buddy,mpi_comm_world, lcom, ) Write: sion_coll_write_mpi(data,size,n,sid) Close: sion_parclose(sid) Write-Call will write data first to local chunk, and then sent it to the associated buddy which writes the data to a second file 31
 + 0.")
32 JURECA Cluster Hardware T-Platforms V210 blade server solution 28 Racks 1884 Nodes: Intel Xeon Haswell (24 cores) DDR4: 128 / 256 / 512 GiB InfiniBand EDR (100 Gbps) - Fat tree topology NVIDIA GPUs: 75 2 K K40 Installed at JSC since July 2015 Peak performance: 1.8PF (CPUs) + 0.4PF(GPUs) Main memory: 281 TiB Software CentOS 7 Linux SLURM batch system ParaStation Cluster Management GPFS file system 32
33 JURECA Booster Collaboration of JSC, Intel (+DELL) & ParTec Network Bridge EDR-OPA (Cluster-Booster) Management of heterogeneous resources in SLURM Hardware 1640 nodes KNL 7250-F Installation to be completed in GB DDR4 16 GB MCDRAM 200 GB local SSD Intel OmniPath (OPA) Fat tree topology Fully integrated with JURECA Cluster 198 OPA-to-EDR bridges to connect to Cluster Same login nodes Software (Not the real Booster, just to give an impression) SLURM (orchestrating jointly Cluster and Booster) ParaStation Cluster Management GPFS file system 33


34 Summary The DEEP projects bring a new view to heterogeneity Cluster-Booster architecture Hardware, software and applications jointly developed Strongly co-design driven DEEP-ER explored future directions of I/O On filesystem level BeeGFS On MPI-IO level E10 On POSIX optimization level SIONlib Test and combine the approaches Step into production in preparation Booster to be attached to JURECA Cluster in coming months Future: Modular Supercomputing More modules to come 34


35 Future: Modular Design Principle First Step: JURECA will be enhanced by a highly scalable Module Slide 35
The DEEP (and DEEP-ER) projects
 projects") The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
The DEEP-ER take on I/O
 Wolfgang Frings Jülich Supercomputing Centre Workshop Exascale I/O: Challenges, Innovations and Solutions SC16, Salt Lake City 18 November 2016 The research leading to these results has received funding
Wolfgang Frings Jülich Supercomputing Centre Workshop Exascale I/O: Challenges, Innovations and Solutions SC16, Salt Lake City 18 November 2016 The research leading to these results has received funding
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
MPI RUNTIMES AT JSC, NOW AND IN THE FUTURE
 , NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
, NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
Dynamical Exascale Entry Platform
 DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Monday, May 18 13:00-13:30 Welcome
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Thursday, Nov 26 13:00-13:30
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Thursday, Nov 26 13:00-13:30
I/O at JSC. I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O. Wolfgang Frings
 Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms
 Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Parallel & Scalable Machine Learning Introduction to Machine Learning Algorithms Dr. Ing. Morris Riedel Adjunct Associated Professor School of Engineering and Natural Sciences, University of Iceland Research
Programming model and application porting to the Dynamical Exascale Entry Platform (DEEP)
") Programming model and application porting to the Dynamical Exascale Entry Platform (DEEP) EASC 2013 April 10 th, Edinburgh Damián A. Mallón The research leading to these results has received funding from
Programming model and application porting to the Dynamical Exascale Entry Platform (DEEP) EASC 2013 April 10 th, Edinburgh Damián A. Mallón The research leading to these results has received funding from
Parallel I/O on JUQUEEN
 Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
NVIDIA Application Lab at Jülich
 Mitglied der Helmholtz- Gemeinschaft NVIDIA Application Lab at Jülich Dirk Pleiter Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich at a Glance (status 2010) Budget: 450 mio Euro Staff: 4,800
Mitglied der Helmholtz- Gemeinschaft NVIDIA Application Lab at Jülich Dirk Pleiter Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich at a Glance (status 2010) Budget: 450 mio Euro Staff: 4,800
Porting Scientific Applications to OpenPOWER
 Porting Scientific Applications to OpenPOWER Dirk Pleiter Forschungszentrum Jülich / JSC #OpenPOWERSummit Join the conversation at #OpenPOWERSummit 1 JSC s HPC Strategy IBM Power 6 JUMP, 9 TFlop/s Intel
Porting Scientific Applications to OpenPOWER Dirk Pleiter Forschungszentrum Jülich / JSC #OpenPOWERSummit Join the conversation at #OpenPOWERSummit 1 JSC s HPC Strategy IBM Power 6 JUMP, 9 TFlop/s Intel
Systems Architectures towards Exascale
 Systems Architectures towards Exascale D. Pleiter German-Indian Workshop on HPC Architectures and Applications Pune 29 November 2016 Outline Introduction Exascale computing Technology trends Architectures
Systems Architectures towards Exascale D. Pleiter German-Indian Workshop on HPC Architectures and Applications Pune 29 November 2016 Outline Introduction Exascale computing Technology trends Architectures
Index LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS
 LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS 3 The Power of Heterogeneity 4 A DEEP-ER Look 5 DEEP-ER Hardware Architecture 9 DEEP-ER Co-Design 11 DEEP-ER Software Stack 15 DEEP-ER
LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS 3 The Power of Heterogeneity 4 A DEEP-ER Look 5 DEEP-ER Hardware Architecture 9 DEEP-ER Co-Design 11 DEEP-ER Software Stack 15 DEEP-ER
Jülich Supercomputing Centre
 Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre Norbert Attig Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich (FZJ) Aug 26, 2009 DOAG Regionaltreffen NRW 2 Supercomputing at
Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre Norbert Attig Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich (FZJ) Aug 26, 2009 DOAG Regionaltreffen NRW 2 Supercomputing at
A Breakthrough in Non-Volatile Memory Technology FUJITSU LIMITED
 A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
Trends in HPC Architectures
 Mitglied der Helmholtz-Gemeinschaft Trends in HPC Architectures Norbert Eicker Institute for Advanced Simulation Jülich Supercomputing Centre PRACE/LinkSCEEM-2 CyI 2011 Winter School Nikosia, Cyprus Forschungszentrum
Mitglied der Helmholtz-Gemeinschaft Trends in HPC Architectures Norbert Eicker Institute for Advanced Simulation Jülich Supercomputing Centre PRACE/LinkSCEEM-2 CyI 2011 Winter School Nikosia, Cyprus Forschungszentrum
HPC projects. Grischa Bolls
 HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
PRACE Project Access Technical Guidelines - 19 th Call for Proposals
 PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy
 Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Short Talk: System abstractions to facilitate data movement in supercomputers with deep memory and interconnect hierarchy François Tessier, Venkatram Vishwanath Argonne National Laboratory, USA July 19,
Vectorisation and Portable Programming using OpenCL
 Vectorisation and Portable Programming using OpenCL Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre (JSC) Andreas Beckmann, Ilya Zhukov, Willi Homberg, JSC Wolfram Schenck, FH Bielefeld
Vectorisation and Portable Programming using OpenCL Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre (JSC) Andreas Beckmann, Ilya Zhukov, Willi Homberg, JSC Wolfram Schenck, FH Bielefeld
The RAMDISK Storage Accelerator
 The RAMDISK Storage Accelerator A Method of Accelerating I/O Performance on HPC Systems Using RAMDISKs Tim Wickberg, Christopher D. Carothers wickbt@rpi.edu, chrisc@cs.rpi.edu Rensselaer Polytechnic Institute
The RAMDISK Storage Accelerator A Method of Accelerating I/O Performance on HPC Systems Using RAMDISKs Tim Wickberg, Christopher D. Carothers wickbt@rpi.edu, chrisc@cs.rpi.edu Rensselaer Polytechnic Institute
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies
 Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
Toward portable I/O performance by leveraging system abstractions of deep memory and interconnect hierarchies François Tessier, Venkatram Vishwanath, Paul Gressier Argonne National Laboratory, USA Wednesday
THOUGHTS ABOUT THE FUTURE OF I/O
 THOUGHTS ABOUT THE FUTURE OF I/O Dagstuhl Seminar Challenges and Opportunities of User-Level File Systems for HPC Franz-Josef Pfreundt, May 2017 Deep Learning I/O Challenges Memory Centric Computing :
THOUGHTS ABOUT THE FUTURE OF I/O Dagstuhl Seminar Challenges and Opportunities of User-Level File Systems for HPC Franz-Josef Pfreundt, May 2017 Deep Learning I/O Challenges Memory Centric Computing :
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 14 th CALL (T ier0) Contributing sites and the corresponding computer systems for this call are: GENCI CEA, France Bull Bullx cluster GCS HLRS, Germany Cray
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Early Evaluation of the "Infinite Memory Engine" Burst Buffer Solution
 Early Evaluation of the "Infinite Memory Engine" Burst Buffer Solution Wolfram Schenck Faculty of Engineering and Mathematics, Bielefeld University of Applied Sciences, Bielefeld, Germany Salem El Sayed,
Early Evaluation of the "Infinite Memory Engine" Burst Buffer Solution Wolfram Schenck Faculty of Engineering and Mathematics, Bielefeld University of Applied Sciences, Bielefeld, Germany Salem El Sayed,
Application Performance on IME
 Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
HPC state of play. HPC Ecosystem. HPC system supply. HPC use 24% EU 4,3% EU. Application software & tools. Academia 23% Bio-sciences 22% CAE 21%
 Only half of US GDP spending HPC state of play HPC Ecosystem HPC system supply 4,3% EU EU market: 630 M/yr (EU lost 10% capacity from 2007 to 2009) 24% EU HPC use Academia 23% Bio-sciences 22% CAE 21%
Only half of US GDP spending HPC state of play HPC Ecosystem HPC system supply 4,3% EU EU market: 630 M/yr (EU lost 10% capacity from 2007 to 2009) 24% EU HPC use Academia 23% Bio-sciences 22% CAE 21%
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
BeeGFS. Parallel Cluster File System. Container Workshop ISC July Marco Merkel VP ww Sales, Consulting
 BeeGFS The Parallel Cluster File System Container Workshop ISC 28.7.18 www.beegfs.io July 2018 Marco Merkel VP ww Sales, Consulting HPC & Cognitive Workloads Demand Today Flash Storage HDD Storage Shingled
BeeGFS The Parallel Cluster File System Container Workshop ISC 28.7.18 www.beegfs.io July 2018 Marco Merkel VP ww Sales, Consulting HPC & Cognitive Workloads Demand Today Flash Storage HDD Storage Shingled
libhio: Optimizing IO on Cray XC Systems With DataWarp
 libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
Comet Virtualization Code & Design Sprint
 Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Recent Developments in Supercomputing
 John von Neumann Institute for Computing Recent Developments in Supercomputing Th. Lippert published in NIC Symposium 2008, G. Münster, D. Wolf, M. Kremer (Editors), John von Neumann Institute for Computing,
John von Neumann Institute for Computing Recent Developments in Supercomputing Th. Lippert published in NIC Symposium 2008, G. Münster, D. Wolf, M. Kremer (Editors), John von Neumann Institute for Computing,
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Fujitsu SC 18. Human Centric Innovation Co-creation for Success 2018 FUJITSU
 Fujitsu SC 18 Human Centric Innovation Co-creation for Success 2018 FUJITSU A Breakthrough in Non-Volatile Memory Technology & 2018 FUJITSU IT needs to accelerate time-to-market Situation: End users and
Fujitsu SC 18 Human Centric Innovation Co-creation for Success 2018 FUJITSU A Breakthrough in Non-Volatile Memory Technology & 2018 FUJITSU IT needs to accelerate time-to-market Situation: End users and
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
JURECA Tuning for the platform
 JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
JURECA Tuning for the platform Usage of ParaStation MPI 2017-11-23 Outline ParaStation MPI Compiling your program Running your program Tuning parameters Resources 2 ParaStation MPI Based on MPICH (3.2)
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
High Performance Computing at the Jülich Supercomputing Center
 Mitglied der Helmholtz-Gemeinschaft High Performance Computing at the Jülich Supercomputing Center Jutta Docter Institute for Advanced Simulation (IAS) Jülich Supercomputing Centre (JSC) Overview Jülich
Mitglied der Helmholtz-Gemeinschaft High Performance Computing at the Jülich Supercomputing Center Jutta Docter Institute for Advanced Simulation (IAS) Jülich Supercomputing Centre (JSC) Overview Jülich
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 13 th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System x idataplex CINECA, Italy Lenovo System
Application Example Running on Top of GPI-Space Integrating D/C
 Application Example Running on Top of GPI-Space Integrating D/C Tiberiu Rotaru Fraunhofer ITWM This project is funded from the European Union s Horizon 2020 Research and Innovation programme under Grant
Application Example Running on Top of GPI-Space Integrating D/C Tiberiu Rotaru Fraunhofer ITWM This project is funded from the European Union s Horizon 2020 Research and Innovation programme under Grant
S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE. Presenter: Louis Capps, Solution Architect, NVIDIA,
 S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
Parallel I/O and Portable Data Formats I/O strategies
 Parallel I/O and Portable Data Formats I/O strategies Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Common I/O strategies
Parallel I/O and Portable Data Formats I/O strategies Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Common I/O strategies
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
pnfs, POSIX, and MPI-IO: A Tale of Three Semantics
 Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
SEVENTH FRAMEWORK PROGRAMME
 SEVENTH FRAMEWORK PROGRAMME FP7-ICT-2013-10 DEEP-ER DEEP Extended Reach Grant Agreement Number: 610476 D7.1 Report on performance extrapolation based on design decisions Approved Version: 2.0 Author(s):
SEVENTH FRAMEWORK PROGRAMME FP7-ICT-2013-10 DEEP-ER DEEP Extended Reach Grant Agreement Number: 610476 D7.1 Report on performance extrapolation based on design decisions Approved Version: 2.0 Author(s):
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
How то Use HPC Resources Efficiently by a Message Oriented Framework.
 How то Use HPC Resources Efficiently by a Message Oriented Framework www.hp-see.eu E. Atanassov, T. Gurov, A. Karaivanova Institute of Information and Communication Technologies Bulgarian Academy of Science
How то Use HPC Resources Efficiently by a Message Oriented Framework www.hp-see.eu E. Atanassov, T. Gurov, A. Karaivanova Institute of Information and Communication Technologies Bulgarian Academy of Science
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
CSD3 The Cambridge Service for Data Driven Discovery. A New National HPC Service for Data Intensive science
 CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
Introduction of Oakforest-PACS
 Introduction of Oakforest-PACS Hiroshi Nakamura Director of Information Technology Center The Univ. of Tokyo (Director of JCAHPC) Outline Supercomputer deployment plan in Japan What is JCAHPC? Oakforest-PACS
Introduction of Oakforest-PACS Hiroshi Nakamura Director of Information Technology Center The Univ. of Tokyo (Director of JCAHPC) Outline Supercomputer deployment plan in Japan What is JCAHPC? Oakforest-PACS
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
CS500 SMARTER CLUSTER SUPERCOMPUTERS
 CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
CS500 SMARTER CLUSTER SUPERCOMPUTERS OVERVIEW Extending the boundaries of what you can achieve takes reliable computing tools matched to your workloads. That s why we tailor the Cray CS500 cluster supercomputer
NEXTGenIO Performance Tools for In-Memory I/O
 NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Smarter Clusters from the Supercomputer Experts
 Smarter Clusters from the Supercomputer Experts Maximize Your Results with Flexible, High-Performance Cray CS500 Cluster Supercomputers In science and business, as soon as one question is answered another
Smarter Clusters from the Supercomputer Experts Maximize Your Results with Flexible, High-Performance Cray CS500 Cluster Supercomputers In science and business, as soon as one question is answered another
HPC Innovation Lab Update. Dell EMC HPC Community Meeting 3/28/2017
 HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
DDN About Us Solving Large Enterprise and Web Scale Challenges
 1 DDN About Us Solving Large Enterprise and Web Scale Challenges History Founded in 98 World s Largest Private Storage Company Growing, Profitable, Self Funded Headquarters: Santa Clara and Chatsworth,
1 DDN About Us Solving Large Enterprise and Web Scale Challenges History Founded in 98 World s Largest Private Storage Company Growing, Profitable, Self Funded Headquarters: Santa Clara and Chatsworth,
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
Design and Evaluation of a 2048 Core Cluster System
 Design and Evaluation of a 2048 Core Cluster System, Torsten Höfler, Torsten Mehlan and Wolfgang Rehm Computer Architecture Group Department of Computer Science Chemnitz University of Technology December
Design and Evaluation of a 2048 Core Cluster System, Torsten Höfler, Torsten Mehlan and Wolfgang Rehm Computer Architecture Group Department of Computer Science Chemnitz University of Technology December
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
ECMWF's Next Generation IO for the IFS Model and Product Generation
 ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
How To Design a Cluster
 How To Design a Cluster PRESENTED BY ROBERT C. JACKSON, MSEE FACULTY AND RESEARCH SUPPORT MANAGER INFORMATION TECHNOLOGY STUDENT ACADEMIC SERVICES GROUP THE UNIVERSITY OF TEXAS-RIO GRANDE VALLEY Abstract
How To Design a Cluster PRESENTED BY ROBERT C. JACKSON, MSEE FACULTY AND RESEARCH SUPPORT MANAGER INFORMATION TECHNOLOGY STUDENT ACADEMIC SERVICES GROUP THE UNIVERSITY OF TEXAS-RIO GRANDE VALLEY Abstract
Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence
 Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence Jens Domke Research Staff at MATSUOKA Laboratory GSIC, Tokyo Institute of Technology, Japan Omni-Path User Group 2017/11/14 Denver,
Results from TSUBAME3.0 A 47 AI- PFLOPS System for HPC & AI Convergence Jens Domke Research Staff at MATSUOKA Laboratory GSIC, Tokyo Institute of Technology, Japan Omni-Path User Group 2017/11/14 Denver,
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
User Training Cray XC40 IITM, Pune
 User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Architectures for Scalable Media Object Search
 Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
InfiniBand-based HPC Clusters
 Boosting Scalability of InfiniBand-based HPC Clusters Asaf Wachtel, Senior Product Manager 2010 Voltaire Inc. InfiniBand-based HPC Clusters Scalability Challenges Cluster TCO Scalability Hardware costs
Boosting Scalability of InfiniBand-based HPC Clusters Asaf Wachtel, Senior Product Manager 2010 Voltaire Inc. InfiniBand-based HPC Clusters Scalability Challenges Cluster TCO Scalability Hardware costs
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
HPC-CINECA infrastructure: The New Marconi System. HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati,
 HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Data center: The center of possibility
 Data center: The center of possibility Diane bryant Executive vice president & general manager Data center group, intel corporation Data center: The center of possibility The future is Thousands of Clouds
Data center: The center of possibility Diane bryant Executive vice president & general manager Data center group, intel corporation Data center: The center of possibility The future is Thousands of Clouds
The Spider Center-Wide File System
 The Spider Center-Wide File System Presented by Feiyi Wang (Ph.D.) Technology Integration Group National Center of Computational Sciences Galen Shipman (Group Lead) Dave Dillow, Sarp Oral, James Simmons,
The Spider Center-Wide File System Presented by Feiyi Wang (Ph.D.) Technology Integration Group National Center of Computational Sciences Galen Shipman (Group Lead) Dave Dillow, Sarp Oral, James Simmons,
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
CERN openlab & IBM Research Workshop Trip Report
 CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
I/O Profiling Towards the Exascale
 I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
Modernizing OpenMP for an Accelerated World
 Modernizing OpenMP for an Accelerated World Tom Scogland Bronis de Supinski This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract
Modernizing OpenMP for an Accelerated World Tom Scogland Bronis de Supinski This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract