Nvidia Jetson TX2 and its Software Toolset. João Fernandes 2017/2018
|
|
|
- Victoria Logan
- 5 years ago
- Views:
Transcription


1 Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018
2 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks Tensorflow A case study


3 NVIDIA Jetson TX2 NVIDIA Jetson TX2 Developer Kit
 architectures using the NVIDIA cudnn and TensorRT")
4 NVIDIA Jetson TX2 Jetson is the world s leading low-power embedded platform, enabling server-class AI compute performance for edge devices everywhere Edge computing is an emerging paradigm which uses local computing to enable analytics at the source of the data Jetson TX2 accelerates cutting-edge deep neural network (DNN) architectures using the NVIDIA cudnn and TensorRT libraries
5 Hardware Specifications NVIDIA Jetson TX2 CPU ARM Cortex-A57 2GHz + NVIDIA Denver2 2GHz GPU 256-core 1300MHz (2 SM s) Memory 8GB 128-bit 1866Mhz 59.7 GB/s Storage 32GB emmc 5.1 I/O UART, SPI, I2C, I2S, GPIOs, HDMI 2.0, USB, Ethernet, CAN
6 Heterogeneous Multi-Processing: Cortex-A57 vs Denver2 4xCortex - A57 2xDenver2 ARM ISA ARMv8 (32/64 bits) ARMv8 (32/64 bits) Frequency Up to 2 GHz Up to 2 GHz L1 Cache 48 KB (Inst) + 32 KB (Data) 128KB (Inst) + 64 KB (Data) L2 Cache 2MB (shared between the 2 Chips) 2MB (shared between the 2 Chips) GFLOPS(FP32) Full coherency guaranteed across the 2 CPU Clusters
7 Hardware Architecture
8 Performance Modes Mode Mode Name Denver2 ARM A57 GPU Freq. 0 Max-N 2.0 GHz 2.0 GHz 1.30 GHz 1 Max-Q GHz 0.85 GHz 2 Max-P Core All 1.4 GHz 1.4 GHz 1.12 GHz 3 Max-P ARM GHz 1.12 GHz 4 Max-P Denver 2.0 GHz GHz Can be changed at run time using: sudo nvpmodel -m <desired mode>
9 Max-Q vs Max-P GoogLeNet AlexNet Max-N Max-P Max-Q Perf 290 FPS 253 FPS 196 FPS Power Consumption 12.8 W 8.9 W 5.9 W Efficiency (FPS/W) Perf 692 FPS 601 FPS 463 FPS Power Consumption 12.4 W 8.6 W 5.6 W Efficiency
10 The Software: NVIDIA JetPack A set of software tools to ease the development for the Jetson platform: Flash Jetson Developer Kit with the latest OS image Install developer tools for both host PC and Developer Kit Install libraries and APIs Samples and documentation Key Software: OS: L4T (Based on Ubuntu) CUDA 8 TensorRT 2.1 cudnn 6.0 Requires Ubuntu 14 on the Host!
11 The Software CUDA CUDA Toolkit provides a comprehensive development environment for C and C++ developers building GPU-accelerated applications. It includes a compiler for NVIDIA GPUs, math libraries, and tools for debugging and optimizing the performance of your applications cudnn CUDA Deep Neural Network library provides high-performance primitives for all deep learning frameworks. It includes support for convolutions, activation functions and tensor transformations. TensorRT 2.1 TensorRT is a high performance deep learning inference runtime for image classification, segmentation, and object detection neural networks. It speeds up deep learning inference as well as reducing the runtime memory footprint for convolutional and deconv neural networks. Multimedia API The Jetson Multimedia API package provides low level APIs for image acquisition (via camers). It enables video decode, encode, format conversion and scaling functionality


12 Real World Utilization
13 Relative Performance (GTX 1070) Matrix-Mul FP32
14 Machine Learning Machine learning is the science of getting the computer to perform a certain task without explicitly programming it. Normally, this requires a sample dataset from which the algorithm can infer the model parameters (commonly known as the training phase). Decision tree learning Clustering Neural Networks

15 Neural Networks
16 Neural Networks: The neuron

17 Convolutional Neural Networks

18 Convolutional Neural Networks
19 State of the art: Object Classification (VGG16) Others: Inception, ResNet

20 Tensorflow TensorFlow is an open source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional communicated between them. data arrays (tensors)
 dot_operation = tf.matmul(r2, r1) start_time = time.time() result = session.")
21 Computational Graph with tf.session() as session: r1 = tf.random_uniform(shape=shape, minval=0, maxval=1, dtype=data_type) r2 = tf.random_uniform(shape=shape, minval=0, maxval=1, dtype=data_type) dot_operation = tf.matmul(r2, r1) start_time = time.time() result = session.run(dot_operation)





22 The Case Study
23 Naive Implementation while(true): image = CaptureFrame() (boxes, scores, classes, num) = sess.run( [detection_boxes, detection_scores, detection_classes, num_detections], feed_dict={image_tensor: image_np_expanded}) DrawBBoxes(image, boxes, scores,...) ShowFrame(image)
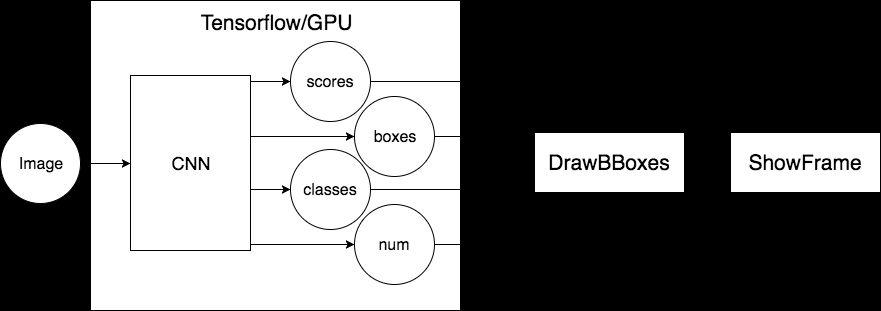

24 Naive Implementation: Computational Graph


25 Implementation: Computational Graph
26 Conclusion Performance Engineering can look like it s changing But the basics are always the same: Measure/Profile Identify and Understand the Bottleneck Start the iterative tuning process Validade Be scientific
Deep Learning: Transforming Engineering and Science The MathWorks, Inc.
 Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
THE LEADER IN VISUAL COMPUTING
 MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
NVIDIA FOR DEEP LEARNING. Bill Veenhuis
 NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
Embedded Computing without Compromise. Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM -Aitech Systems GTC Israel 2017
 Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM - Systems GTC Israel 2017 Agenda Current GPGPU systems NVIDIA Jetson TX1 and TX2 evaluation Conclusions New Products 2 GPGPU Product
Evolution of the Rugged GPGPU Computer Session: SIL7127 Dan Mor PLM - Systems GTC Israel 2017 Agenda Current GPGPU systems NVIDIA Jetson TX1 and TX2 evaluation Conclusions New Products 2 GPGPU Product
Deep learning in MATLAB From Concept to CUDA Code
 Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Deploying Deep Learning Networks to Embedded GPUs and CPUs
 Deploying Deep Learning Networks to Embedded GPUs and CPUs Rishu Gupta, PhD Senior Application Engineer, Computer Vision 2015 The MathWorks, Inc. 1 MATLAB Deep Learning Framework Access Data Design + Train
Deploying Deep Learning Networks to Embedded GPUs and CPUs Rishu Gupta, PhD Senior Application Engineer, Computer Vision 2015 The MathWorks, Inc. 1 MATLAB Deep Learning Framework Access Data Design + Train
A176 Cyclone. GPGPU Fanless Small FF RediBuilt Supercomputer. IT and Instrumentation for industry. Aitech I/O
 The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS, and it consumes less than 17W at full load (8-10W at typical
Small is the New Big: Data Analytics on the Edge
 Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
A176 C clone. GPGPU Fanless Small FF RediBuilt Supercomputer. Aitech
 The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS at a remarkable level of energy efficiency, providing all the
The A176 Cyclone is the smallest and most powerful Rugged-GPGPU, ideally suited for distributed systems. Its 256 CUDA cores reach 1 TFLOPS at a remarkable level of energy efficiency, providing all the
NVIDIA AI BRAIN OF SELF DRIVING AND HD MAPPING. September 13, 2016
 NVIDIA AI BRAIN OF SELF DRIVING AND HD MAPPING September 13, 2016 AI FOR AUTONOMOUS DRIVING MAPPING KALDI LOCALIZATION DRIVENET Training on DGX-1 NVIDIA DGX-1 NVIDIA DRIVE PX 2 Driving with DriveWorks
NVIDIA AI BRAIN OF SELF DRIVING AND HD MAPPING September 13, 2016 AI FOR AUTONOMOUS DRIVING MAPPING KALDI LOCALIZATION DRIVENET Training on DGX-1 NVIDIA DGX-1 NVIDIA DRIVE PX 2 Driving with DriveWorks
Introduction to the Tegra SoC Family and the ARM Architecture. Kristoffer Robin Stokke, PhD FLIR UAS
 Introduction to the Tegra SoC Family and the ARM Architecture Kristoffer Robin Stokke, PhD FLIR UAS Goals of Lecture To give you something concrete to start on Simple introduction to ARMv8 NEON programming
Introduction to the Tegra SoC Family and the ARM Architecture Kristoffer Robin Stokke, PhD FLIR UAS Goals of Lecture To give you something concrete to start on Simple introduction to ARMv8 NEON programming
EFFICIENT INFERENCE WITH TENSORRT. Han Vanholder
 EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
EFFICIENT INFERENCE WITH TENSORRT Han Vanholder AI INFERENCING IS EXPLODING 2 Trillion Messages Per Day On LinkedIn 500M Daily active users of iflytek 140 Billion Words Per Day Translated by Google 60
GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB
 GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB Ram Kokku 2018 The MathWorks, Inc. 1 GPUs and CUDA programming faster Performance CUDA OpenCL C/C++ GPU Coder MATLAB Python Ease of programming
GPU Coder: Automatic CUDA and TensorRT code generation from MATLAB Ram Kokku 2018 The MathWorks, Inc. 1 GPUs and CUDA programming faster Performance CUDA OpenCL C/C++ GPU Coder MATLAB Python Ease of programming
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
TENSORRT. RN _v01 January Release Notes
 TENSORRT RN-08624-030_v01 January 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter 1. 2. 3. 4. Overview...1 Release 3.0.2... 2 Release 3.0.1... 4 Release 2.1... 10 RN-08624-030_v01
TENSORRT RN-08624-030_v01 January 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter 1. 2. 3. 4. Overview...1 Release 3.0.2... 2 Release 3.0.1... 4 Release 2.1... 10 RN-08624-030_v01
Wu Zhiwen.
 Wu Zhiwen zhiwen.wu@intel.com Agenda Background information OpenCV DNN module OpenCL acceleration Vulkan backend Sample 2 What is OpenCV? Open Source Compute Vision (OpenCV) library 2500+ Optimized algorithms
Wu Zhiwen zhiwen.wu@intel.com Agenda Background information OpenCV DNN module OpenCL acceleration Vulkan backend Sample 2 What is OpenCV? Open Source Compute Vision (OpenCV) library 2500+ Optimized algorithms
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM. Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive)
 & Yunsup Lee (SiFive)") NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
NVIDIA'S DEEP LEARNING ACCELERATOR MEETS SIFIVE'S FREEDOM PLATFORM Frans Sijstermans (NVIDIA) & Yunsup Lee (SiFive) NVDLA NVIDIA DEEP LEARNING ACCELERATOR IP Core for deep learning part of NVIDIA s Xavier
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017
 A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
A NEW COMPUTING ERA JENSEN HUANG, FOUNDER & CEO GTC CHINA 2017 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 6 10 5 1.1X per year 10 4 10 3 10 2 1.5X per year Single-threaded
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
Introduction to Deep Learning in Signal Processing & Communications with MATLAB
 Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
Introduction to Deep Learning in Signal Processing & Communications with MATLAB Dr. Amod Anandkumar Pallavi Kar Application Engineering Group, Mathworks India 2019 The MathWorks, Inc. 1 Different Types
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
. SMARC 2.0 Compliant
 MSC SM2S-IMX8 NXP i.mx8 ARM Cortex -A72/A53 Description The new MSC SM2S-IMX8 module offers a quantum leap in terms of computing and graphics performance. It integrates the currently most powerful i.mx8
MSC SM2S-IMX8 NXP i.mx8 ARM Cortex -A72/A53 Description The new MSC SM2S-IMX8 module offers a quantum leap in terms of computing and graphics performance. It integrates the currently most powerful i.mx8
Implementing Deep Learning for Video Analytics on Tegra X1.
 Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
Elaborazione dati real-time su architetture embedded many-core e FPGA
 Elaborazione dati real-time su architetture embedded many-core e FPGA DAVIDE ROSSI A L E S S A N D R O C A P O T O N D I G I U S E P P E T A G L I A V I N I A N D R E A M A R O N G I U C I R I - I C T
Elaborazione dati real-time su architetture embedded many-core e FPGA DAVIDE ROSSI A L E S S A N D R O C A P O T O N D I G I U S E P P E T A G L I A V I N I A N D R E A M A R O N G I U C I R I - I C T
Autonomous Driving Solutions
 Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
Autonomous Driving Solutions Oct, 2017 DrivePX2 & DriveWorks Marcus Oh (moh@nvidia.com) Sr. Solution Architect, NVIDIA This work is licensed under a Creative Commons Attribution-Share Alike 4.0 (CC BY-SA
Kevin Meehan Stephen Moskal Computer Architecture Winter 2012 Dr. Shaaban
 Kevin Meehan Stephen Moskal Computer Architecture Winter 2012 Dr. Shaaban Contents Raspberry Pi Foundation Raspberry Pi overview & specs ARM11 overview ARM11 cache, pipeline, branch prediction ARM11 vs.
Kevin Meehan Stephen Moskal Computer Architecture Winter 2012 Dr. Shaaban Contents Raspberry Pi Foundation Raspberry Pi overview & specs ARM11 overview ARM11 cache, pipeline, branch prediction ARM11 vs.
An introduction to Machine Learning silicon
 An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
DEEP LEARNING AND DIGITS DEEP LEARNING GPU TRAINING SYSTEM
 DEEP LEARNING AND DIGITS DEEP LEARNING GPU TRAINING SYSTEM AGENDA 1 Introduction to Deep Learning 2 What is DIGITS 3 How to use DIGITS Practical DEEP LEARNING Examples Image Classification, Object Detection,
DEEP LEARNING AND DIGITS DEEP LEARNING GPU TRAINING SYSTEM AGENDA 1 Introduction to Deep Learning 2 What is DIGITS 3 How to use DIGITS Practical DEEP LEARNING Examples Image Classification, Object Detection,
A NEW COMPUTING ERA. Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA
 A NEW COMPUTING ERA Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA THE ERA OF AI AI CLOUD MOBILE PC 2 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 5 1.1X
A NEW COMPUTING ERA Shanker Trivedi Senior Vice President Enterprise Business at NVIDIA THE ERA OF AI AI CLOUD MOBILE PC 2 TWO FORCES DRIVING THE FUTURE OF COMPUTING 10 7 Transistors (thousands) 10 5 1.1X
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Embedded GPGPU and Deep Learning for Industrial Market
 Embedded GPGPU and Deep Learning for Industrial Market Author: Dan Mor GPGPU and HPEC Product Line Manager September 2018 Table of Contents 1. INTRODUCTION... 3 2. DIFFICULTIES IN CURRENT EMBEDDED INDUSTRIAL
Embedded GPGPU and Deep Learning for Industrial Market Author: Dan Mor GPGPU and HPEC Product Line Manager September 2018 Table of Contents 1. INTRODUCTION... 3 2. DIFFICULTIES IN CURRENT EMBEDDED INDUSTRIAL
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer
 S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
S8822 OPTIMIZING NMT WITH TENSORRT Micah Villmow Senior TensorRT Software Engineer 2 100 倍以上速く 本当に可能ですか? 2 DOUGLAS ADAMS BABEL FISH Neural Machine Translation Unit 3 4 OVER 100X FASTER, IS IT REALLY POSSIBLE?
AutoTVM & Device Fleet
 AutoTVM & Device Fleet ` Learning to Optimize Tensor Programs Frameworks High-level data flow graph and optimizations Hardware Learning to Optimize Tensor Programs Frameworks High-level data flow graph
AutoTVM & Device Fleet ` Learning to Optimize Tensor Programs Frameworks High-level data flow graph and optimizations Hardware Learning to Optimize Tensor Programs Frameworks High-level data flow graph
A Lightweight YOLOv2:
 FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
FPGA2018 @Monterey A Lightweight YOLOv2: A Binarized CNN with a Parallel Support Vector Regression for an FPGA Hiroki Nakahara, Haruyoshi Yonekawa, Tomoya Fujii, Shimpei Sato Tokyo Institute of Technology,
Intelligent Hybrid Flash Management
 Intelligent Hybrid Flash Management Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Flash Memory Summit 2018 Santa Clara, CA 1 Research context Analysis of system &
Intelligent Hybrid Flash Management Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Flash Memory Summit 2018 Santa Clara, CA 1 Research context Analysis of system &
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
NVIDIA PLATFORM FOR AI
 NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
NVIDIA PLATFORM FOR AI João Paulo Navarro, Solutions Architect - Linkedin i am ai HTTPS://WWW.YOUTUBE.COM/WATCH?V=GIZ7KYRWZGQ 2 NVIDIA Gaming VR AI & HPC Self-Driving Cars GPU Computing 3 GPU COMPUTING
Democratizing Machine Learning on Kubernetes
 Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
MIOVISION DEEP LEARNING TRAFFIC ANALYTICS SYSTEM FOR REAL-WORLD DEPLOYMENT. Kurtis McBride CEO, Miovision
 MIOVISION DEEP LEARNING TRAFFIC ANALYTICS SYSTEM FOR REAL-WORLD DEPLOYMENT Kurtis McBride CEO, Miovision ABOUT MIOVISION COMPANY Founded in 2005 40% growth, year over year Offices in Kitchener, Canada
MIOVISION DEEP LEARNING TRAFFIC ANALYTICS SYSTEM FOR REAL-WORLD DEPLOYMENT Kurtis McBride CEO, Miovision ABOUT MIOVISION COMPANY Founded in 2005 40% growth, year over year Offices in Kitchener, Canada
User Manual. Nvidia Jetson Series Carrier board Aetina ACE-N622
 User Manual Nvidia Jetson Series Carrier board Aetina ACE-N622 i Document Change History Version Date Description Authors V1 2018/05/23 Initial Release. Eric Chu V2 2018/06/22 Specification change Eric
User Manual Nvidia Jetson Series Carrier board Aetina ACE-N622 i Document Change History Version Date Description Authors V1 2018/05/23 Initial Release. Eric Chu V2 2018/06/22 Specification change Eric
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
F28HS Hardware-Software Interface: Systems Programming
 F28HS Hardware-Software Interface: Systems Programming Hans-Wolfgang Loidl School of Mathematical and Computer Sciences, Heriot-Watt University, Edinburgh Semester 2 2017/18 0 No proprietary software has
F28HS Hardware-Software Interface: Systems Programming Hans-Wolfgang Loidl School of Mathematical and Computer Sciences, Heriot-Watt University, Edinburgh Semester 2 2017/18 0 No proprietary software has
Inference Optimization Using TensorRT with Use Cases. Jack Han / 한재근 Solutions Architect NVIDIA
 Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Brainchip OCTOBER
 Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Hugo Cunha. Senior Firmware Developer Globaltronics
 Hugo Cunha Senior Firmware Developer Globaltronics NB-IoT Product Acceleration Platforms 2018 Speaker Hugo Cunha Project Developper Agenda About us NB IoT Platforms The WIIPIIDO The Gateway FE 1 About
Hugo Cunha Senior Firmware Developer Globaltronics NB-IoT Product Acceleration Platforms 2018 Speaker Hugo Cunha Project Developper Agenda About us NB IoT Platforms The WIIPIIDO The Gateway FE 1 About
Understanding the Role of GPGPU-accelerated SoC-based ARM Clusters
 Understanding the Role of GPGPU-accelerated SoC-based ARM Clusters Reza Azimi, Tyler Fox and Sherief Reda Brown University Providence, RI firstname lastname@brown.edu Abstract The last few years saw the
Understanding the Role of GPGPU-accelerated SoC-based ARM Clusters Reza Azimi, Tyler Fox and Sherief Reda Brown University Providence, RI firstname lastname@brown.edu Abstract The last few years saw the
GPU-Accelerated Deep Learning
 GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA
 sur CPU, GPU et FPGA") Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks
 Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
The Path to Embedded Vision & AI using a Low Power Vision DSP. Yair Siegel, Director of Segment Marketing Hotchips August 2016
 The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
DEEP NEURAL NETWORKS AND GPUS. Julie Bernauer
 DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
S2C K7 Prodigy Logic Module Series
 S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
S2C K7 Prodigy Logic Module Series Low-Cost Fifth Generation Rapid FPGA-based Prototyping Hardware The S2C K7 Prodigy Logic Module is equipped with one Xilinx Kintex-7 XC7K410T or XC7K325T FPGA device
What s inside: What is deep learning Why is deep learning taking off now? Multiple applications How to implement a system.
 Point Grey White Paper Series What s inside: What is deep learning Why is deep learning taking off now? Multiple applications How to implement a system More and more, machine vision systems are expected
Point Grey White Paper Series What s inside: What is deep learning Why is deep learning taking off now? Multiple applications How to implement a system More and more, machine vision systems are expected
P I X E V I A : A I B A S E D, R E A L - T I M E C O M P U T E R V I S I O N S Y S T E M F O R D R O N E S
 P I X E V I A : A I B A S E D, R E A L - T I M E C O M P U T E R V I S I O N S Y S T E M F O R D R O N E S Mindaugas Eglinskas, CEO at PIXEVIA www.pixevia.com Origins in R&D projects for Lithuanian MoD.
P I X E V I A : A I B A S E D, R E A L - T I M E C O M P U T E R V I S I O N S Y S T E M F O R D R O N E S Mindaugas Eglinskas, CEO at PIXEVIA www.pixevia.com Origins in R&D projects for Lithuanian MoD.
S INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS
 S8497 - INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS Chris Lamb CUDA and NGC Engineering, NVIDIA John Barco NGC Product Management, NVIDIA NVIDIA GPU Cloud (NGC) overview AGENDA Using NGC
S8497 - INSIDE NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORK CONTAINERS Chris Lamb CUDA and NGC Engineering, NVIDIA John Barco NGC Product Management, NVIDIA NVIDIA GPU Cloud (NGC) overview AGENDA Using NGC
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
TENSORRT. RN _v01 June Release Notes
 TENSORRT RN-08624-030_v01 June 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. 6. Overview...1 Release 4.0.1... 2 Release 3.0.4... 6 Release 3.0.2...
TENSORRT RN-08624-030_v01 June 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. 6. Overview...1 Release 4.0.1... 2 Release 3.0.4... 6 Release 3.0.2...
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
STM32MP1 Microprocessor Continuing the STM32 Success Story. Press Presentation
 STM32MP1 Microprocessor Continuing the STM32 Success Story Press Presentation What Happens when STM32 meets Linux? 2 + = Linux The STM32MP1 Microprocessor Happens! 3 Available NOW! Extending STM32 success
STM32MP1 Microprocessor Continuing the STM32 Success Story Press Presentation What Happens when STM32 meets Linux? 2 + = Linux The STM32MP1 Microprocessor Happens! 3 Available NOW! Extending STM32 success
THE NVIDIA DEEP LEARNING ACCELERATOR
 THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
 Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Embedded Linux Conference San Diego 2016
 Embedded Linux Conference San Diego 2016 Linux Power Management Optimization on the Nvidia Jetson Platform Merlin Friesen merlin@gg-research.com About You Target Audience - The presentation is introductory
Embedded Linux Conference San Diego 2016 Linux Power Management Optimization on the Nvidia Jetson Platform Merlin Friesen merlin@gg-research.com About You Target Audience - The presentation is introductory
Deep Neural Network Enhanced VSLAM Landmark Selection
 Deep Neural Network Enhanced VSLAM Landmark Selection Dr. Patrick Benavidez Overview 1 Introduction 2 Background on methods used in VSLAM 3 Proposed Method 4 Testbed 5 Preliminary Results What is VSLAM?
Deep Neural Network Enhanced VSLAM Landmark Selection Dr. Patrick Benavidez Overview 1 Introduction 2 Background on methods used in VSLAM 3 Proposed Method 4 Testbed 5 Preliminary Results What is VSLAM?
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads. Natalia Vassilieva, Sergey Serebryakov
 HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
Movidius Neural Compute Stick
 Movidius Neural Compute Stick You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to
Movidius Neural Compute Stick You may not use or facilitate the use of this document in connection with any infringement or other legal analysis concerning Intel products described herein. You agree to
Cisco UCS C480 ML M5 Rack Server Performance Characterization
 White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
SOM PRODUCTS BRIEF. S y s t e m o n M o d u l e. Engicam. SOMProducts ver
 SOM S y s t e m o n M o d u l e PRODUCTS BRIEF GEA M6425IB ARM9 TM Low cost solution Reduced Time to Market Very small form factor Low cost multimedia solutions Industrial Automotive Consumer Single power
SOM S y s t e m o n M o d u l e PRODUCTS BRIEF GEA M6425IB ARM9 TM Low cost solution Reduced Time to Market Very small form factor Low cost multimedia solutions Industrial Automotive Consumer Single power
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
ROC-RK3328-CC Product Specifications
 ROC-RK3328-CC Product Specifications Author T-chip Intelligent Technology Co.,Ltd. Version V1.0 Date 2018-06-23 Version Date Updated content V1.0 2018-06-23 Original version - 1 - Directory 1. Product
ROC-RK3328-CC Product Specifications Author T-chip Intelligent Technology Co.,Ltd. Version V1.0 Date 2018-06-23 Version Date Updated content V1.0 2018-06-23 Original version - 1 - Directory 1. Product
INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES. Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp.
 INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp. Computer Vision in Mobile Tegra K1 It s time! AGENDA Use cases categories
INTEGRATING COMPUTER VISION SENSOR INNOVATIONS INTO MOBILE DEVICES Eli Savransky Principal Architect - CTO Office Mobile BU NVIDIA corp. Computer Vision in Mobile Tegra K1 It s time! AGENDA Use cases categories
NVIDIA DATA LOADING LIBRARY (DALI)
") NVIDIA DATA LOADING LIBRARY (DALI) RN-09096-001 _v01 September 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. DALI DALI DALI DALI DALI Overview...1 Release
NVIDIA DATA LOADING LIBRARY (DALI) RN-09096-001 _v01 September 2018 Release Notes TABLE OF CONTENTS Chapter Chapter Chapter Chapter Chapter 1. 2. 3. 4. 5. DALI DALI DALI DALI DALI Overview...1 Release
Turing Architecture and CUDA 10 New Features. Minseok Lee, Developer Technology Engineer, NVIDIA
 Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Snapdragon NPE Overview
 March 2018 Linaro Connect Hong Kong Snapdragon NPE Overview Mark Charlebois Director, Engineering Qualcomm Technologies, Inc. Caffe2 Snapdragon Neural Processing Engine Efficient execution on Snapdragon
March 2018 Linaro Connect Hong Kong Snapdragon NPE Overview Mark Charlebois Director, Engineering Qualcomm Technologies, Inc. Caffe2 Snapdragon Neural Processing Engine Efficient execution on Snapdragon
Building blocks for 64-bit Systems Development of System IP in ARM
 Building blocks for 64-bit Systems Development of System IP in ARM Research seminar @ University of York January 2015 Stuart Kenny stuart.kenny@arm.com 1 2 64-bit Mobile Devices The Mobile Consumer Expects
Building blocks for 64-bit Systems Development of System IP in ARM Research seminar @ University of York January 2015 Stuart Kenny stuart.kenny@arm.com 1 2 64-bit Mobile Devices The Mobile Consumer Expects
Introduction to Sitara AM437x Processors
 Introduction to Sitara AM437x Processors AM437x: Highly integrated, scalable platform with enhanced industrial communications and security AM4376 AM4378 Software Key Features AM4372 AM4377 High-performance
Introduction to Sitara AM437x Processors AM437x: Highly integrated, scalable platform with enhanced industrial communications and security AM4376 AM4378 Software Key Features AM4372 AM4377 High-performance
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA
 EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
Neural Network Exchange Format
 Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
Copyright Khronos Group 2017 - Page 1 Neural Network Exchange Format Deploying Trained Networks to Inference Engines Viktor Gyenes, specification editor Copyright Khronos Group 2017 - Page 2 Outlook The
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC
 TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
TOWARDS ACCELERATED DEEP LEARNING IN HPC AND HYPERSCALE ARCHITECTURES Environnement logiciel pour l apprentissage profond dans un contexte HPC TERATECH Juin 2017 Gunter Roth, François Courteille DRAMATIC
CNN optimization. Rassadin A
 CNN optimization Rassadin A. 01.2017-02.2017 What to optimize? Training stage time consumption (CPU / GPU) Inference stage time consumption (CPU / GPU) Training stage memory consumption Inference stage
CNN optimization Rassadin A. 01.2017-02.2017 What to optimize? Training stage time consumption (CPU / GPU) Inference stage time consumption (CPU / GPU) Training stage memory consumption Inference stage
TENSORRT. SWE-SWDOCTRT-001-RELN_vTensorRT October Release Notes
 TENSORRT SWE-SWDOCTRT-001-RELN_v 5.0.3 October 2018 Release Notes TABLE OF CONTENTS Chapter 1. Overview...1 Chapter 2. Release 5.x.x... 2 2.1. Release 5.0.3... 2 2.2. Release 5.0.2... 3 2.3. Release 5.0.1
TENSORRT SWE-SWDOCTRT-001-RELN_v 5.0.3 October 2018 Release Notes TABLE OF CONTENTS Chapter 1. Overview...1 Chapter 2. Release 5.x.x... 2 2.1. Release 5.0.3... 2 2.2. Release 5.0.2... 3 2.3. Release 5.0.1
FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers
 FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers Rene Griessl, Meysam Peykanu, Lennart Tigges, Jens Hagemeyer, Mario Porrmann Center of Excellence Cognitive Interaction Technology
FiPS and M2DC: Novel Architectures for Reconfigurable Hyperscale Servers Rene Griessl, Meysam Peykanu, Lennart Tigges, Jens Hagemeyer, Mario Porrmann Center of Excellence Cognitive Interaction Technology
. Micro SD Card Socket. SMARC 2.0 Compliant
 MSC SM2S-IMX6 NXP i.mx6 ARM Cortex -A9 Description The design of the MSC SM2S-IMX6 module is based on NXP s i.mx 6 processors offering quad-, dual- and single-core ARM Cortex -A9 compute performance at
MSC SM2S-IMX6 NXP i.mx6 ARM Cortex -A9 Description The design of the MSC SM2S-IMX6 module is based on NXP s i.mx 6 processors offering quad-, dual- and single-core ARM Cortex -A9 compute performance at
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK
 Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Object recognition and computer vision using MATLAB and NVIDIA Deep Learning SDK 17 May 2016, Melbourne 24 May 2016, Sydney Werner Scholz, CTO and Head of R&D, XENON Systems Mike Wang, Solutions Architect,
Won Woo Ro, Ph.D. School of Electrical and Electronic Engineering
 Won Woo Ro, Ph.D. School of Electrical and Electronic Engineering 학위 공학박사, EE, University of Southern California, USA (2004. 5) 공학석사, EE, University of Southern California, USA (1999. 5) 공학사, EE, Yonsei
Won Woo Ro, Ph.D. School of Electrical and Electronic Engineering 학위 공학박사, EE, University of Southern California, USA (2004. 5) 공학석사, EE, University of Southern California, USA (1999. 5) 공학사, EE, Yonsei
Using MRAM to Create Intelligent SSDs
 Using MRAM to Create Intelligent SSDs Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Santa Clara, CA 1 Study context Analysis of system & application Performance modeling
Using MRAM to Create Intelligent SSDs Jérôme Gaysse Senior Technology&Market Analyst jerome.gaysse@silinnov-consulting.com Santa Clara, CA 1 Study context Analysis of system & application Performance modeling
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
CUDNN. DU _v07 December Installation Guide
 CUDNN DU-08670-001_v07 December 2017 Installation Guide TABLE OF CONTENTS Chapter Overview... 1 Chapter Installing on Linux... 2 Prerequisites... 2 Installing NVIDIA Graphics Drivers... 2 Installing CUDA...
CUDNN DU-08670-001_v07 December 2017 Installation Guide TABLE OF CONTENTS Chapter Overview... 1 Chapter Installing on Linux... 2 Prerequisites... 2 Installing NVIDIA Graphics Drivers... 2 Installing CUDA...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU
 NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
Characterization and Benchmarking of Deep Learning. Natalia Vassilieva, PhD Sr. Research Manager
 Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
In partnership with. VelocityAI REFERENCE ARCHITECTURE WHITE PAPER
 In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
In partnership with VelocityAI REFERENCE JULY // 2018 Contents Introduction 01 Challenges with Existing AI/ML/DL Solutions 01 Accelerate AI/ML/DL Workloads with Vexata VelocityAI 02 VelocityAI Reference
A new Computer Vision Processor Chip Design for automotive ADAS CNN applications in 22nm FDSOI based on Cadence VP6 Technology
 Dr.-Ing Jens Benndorf (DCT) Gregor Schewior (DCT) A new Computer Vision Processor Chip Design for automotive ADAS CNN applications in 22nm FDSOI based on Cadence VP6 Technology Tensilica Day 2017 16th
Dr.-Ing Jens Benndorf (DCT) Gregor Schewior (DCT) A new Computer Vision Processor Chip Design for automotive ADAS CNN applications in 22nm FDSOI based on Cadence VP6 Technology Tensilica Day 2017 16th
NVIDIA DEEP LEARNING PLATFORM
 TECHNICAL OVERVIEW NVIDIA DEEP LEARNING PLATFORM Giant Leaps in Performance and Efficiency for AI Services, From the Data Center to the Network s Edge Introduction Artificial intelligence (AI), the dream
TECHNICAL OVERVIEW NVIDIA DEEP LEARNING PLATFORM Giant Leaps in Performance and Efficiency for AI Services, From the Data Center to the Network s Edge Introduction Artificial intelligence (AI), the dream