Predicting GPU Performance from CPU Runs Using Machine Learning
|
|
|
- Conrad Osborne
- 5 years ago
- Views:
Transcription



1 Predicting GPU Performance from CPU Runs Using Machine Learning Ioana Baldini Stephen Fink Erik Altman IBM T. J. Watson Research Center Yorktown Heights, NY USA 1






2 To exploit GPGPU acceleration need to port code to GPGPU programming model GPU Pitfalls: Porting costs time/money Sometimes GPU speedup is not worth the effort Problem: Can a non-expert predict whether a data-parallel application is likely to perform well on a GPU, without incurring the costs of porting? 2


3 Maybe this is easy? Suppose we already have data parallel CPU Version, e.g. Hypothesis : Since data parallelism is data parallelism, SMP speedup predicts GPU speedup GPU speedup OpenMP speedup 3
4 What is correlation between OpenMP and GPU performance? ρ =


5 Selected results, OpenMP vs. GPU Speedup vs. single-thread CPU Similar scaling on CPU/OpenMP GPU results vary based on device/code 5
6 GPU performance prediction: traditional approaches Detailed analytic model of algorithm + Detailed model of GPU architecture Accurate Performance Models GPU Relatively simple code structures Reasoning about non-trivial transformations Expert knowledge Complex mappings Device Specific Models 6
7 Desired Solution: Fully automatic, for non-experts No static analysis No detailed architectural models Automatically tune for new device Our Approach: Use machine learning to learn from past experiences porting sequential code to GPUs Input: corpus of past ports from sequential (C) to GPU/parallel code features from sequential code Output: model of GPU speedup Notes: Does not explicitly model specific transformations or architectural detail - Unlikely to produce highly accurate model, but rough estimate may be useful Input to model includes human expert knowledge embodied in previous ports 7
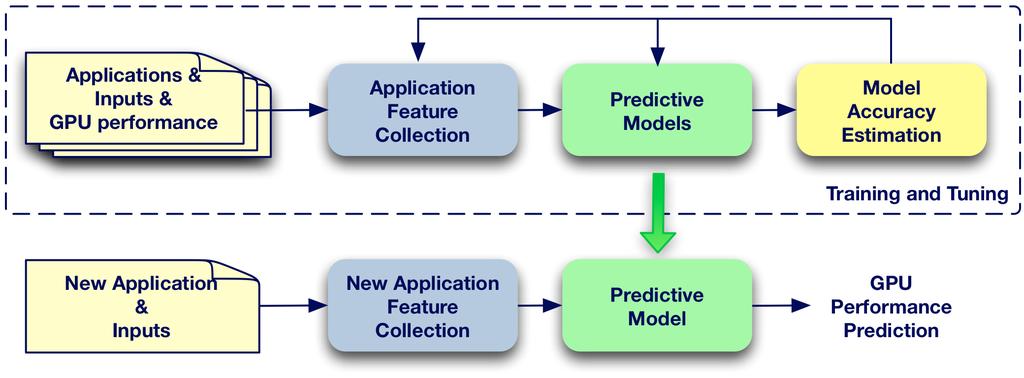
8 System architecture 8
9 Application Features Dynamic Instrumentation (Pin) Category Feature Mnemonic Computation Arithmetic and logic instructions SIMD-based instructions Memory Memory loads LD Control Flow OpenMP Memory stores Memory fences Conditional and unconditional branches Speedup of 12 threads over sequential execution ALU SIMD ST FENCE BR OMP Aggregates Total number of instructions TOTAL Ratio of computation over memory Ratio of computation over GPU communication ALU-MEM ALU-COMM 9
10 Supervised Learning: [WEKA 3] Binary/Ternary classifiers Nearest Neighbors with Generalized Exemplars (NNGE) Support Vector Machines (SVM) Source: [Martin 95] 10



11 Methodology System Dual-processor Intel Xeon X cores 3.47 GHz ATI FirePro v9800 Nvidia Tesla C2050 Benchmarks Parboil 2.0 Rodinia 2.2 Runs 48 runs total Cross validation: - Leave one out - Leave two out 11


12 Learning whether GPU acceleration is beneficial Binary classifier: GPU Speedup > 1 Classifier Accuracy Features Selected SVM NNGE Tesla ALU, LD, BR, TOTAL ALU, LD, ST, ALU-MEM, BR, TOTAL FirePro ALU, LD, BR, TOTAL ALU, LD, BR, TOTAL, OMP 12
 5 Binary classifiers: GPU")

13 Learning the speedup factor of GPU execution (SVM) 5 Binary classifiers: GPU Speedup > 1 GPU Speedup > 2 GPU Speedup > 3 GPU Speedup > 4 GPU Speedup > 5 Classifier Accuracy 13


14 Predicting the Best Device for OpenCL runs Which of 3 devices is best for a particular program? 3-way classifier using NNGE: CPU, Tesla, FirePro Classifer prediction Normalized Performance Correct 39 of 46 runs. Effective accuracy = 91% 14
15 Summary of Results Classifiers are ~80% effective at deciding GPU speedup class for k = 1,, 5 Small set of features (ALU, LD, BR) are sufficient Predictions are effective for heterogeneous scheduling problem Bottom Line Is 80% classifier accuracy good enough? Useful? Machine Learning doesn t illuminate cause-and-effect Early days results are promising, but much more exploration needed 15
16 Backup 16
17 Related Work Jia et al. [14] used regression techniques to predict the results of simulations of GPU architectures. Grewe et al. [7], [8] use machine learning to help split code between cores of a CPU and a GPU. GROPHECY [23] predict GPU performance for loops. Uses a detailed analytic model with pattern-matching static analysis. Kremlin [6] provides a methodology to discover opportunities for parallelization in sequential code Primarily by deriving upper bounds on potential parallelism from a dynamic critical path measurement. Parallel Prophet [16] estimates parallel performance in the presence of memory contention. Based on instrumented, annotated serial programs. Hong et al. [11] model GPU performance from GPU memory access patterns and computational density per memory request It requires a detailed model of the code to run on the device.
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening. Alberto Magni, Christophe Dubach, Michael O'Boyle
 A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
A Large-Scale Cross-Architecture Evaluation of Thread-Coarsening Alberto Magni, Christophe Dubach, Michael O'Boyle Introduction Wide adoption of GPGPU for HPC Many GPU devices from many of vendors AMD
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
FPGA-based Supercomputing: New Opportunities and Challenges
 FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
OpenMP for next generation heterogeneous clusters
 OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
OpenMP for next generation heterogeneous clusters Jens Breitbart Research Group Programming Languages / Methodologies, Universität Kassel, jbreitbart@uni-kassel.de Abstract The last years have seen great
Native Offload of Haskell Repa Programs to Integrated GPUs
 Native Offload of Haskell Repa Programs to Integrated GPUs Hai (Paul) Liu with Laurence Day, Neal Glew, Todd Anderson, Rajkishore Barik Intel Labs. September 28, 2016 General purpose computing on integrated
Native Offload of Haskell Repa Programs to Integrated GPUs Hai (Paul) Liu with Laurence Day, Neal Glew, Todd Anderson, Rajkishore Barik Intel Labs. September 28, 2016 General purpose computing on integrated
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania
 OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
OpenCL Base Course Ing. Marco Stefano Scroppo, PhD Student at University of Catania Course Overview This OpenCL base course is structured as follows: Introduction to GPGPU programming, parallel programming
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Towards a Holistic Approach to Auto-Parallelization
 Towards a Holistic Approach to Auto-Parallelization Integrating Profile-Driven Parallelism Detection and Machine-Learning Based Mapping Georgios Tournavitis, Zheng Wang, Björn Franke and Michael F.P. O
Towards a Holistic Approach to Auto-Parallelization Integrating Profile-Driven Parallelism Detection and Machine-Learning Based Mapping Georgios Tournavitis, Zheng Wang, Björn Franke and Michael F.P. O
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Semi-supervised learning and active learning
 Semi-supervised learning and active learning Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Combining classifiers Ensemble learning: a machine learning paradigm where multiple learners
Semi-supervised learning and active learning Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Combining classifiers Ensemble learning: a machine learning paradigm where multiple learners
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s)
") Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
Directed Optimization On Stencil-based Computational Fluid Dynamics Application(s) Islam Harb 08/21/2015 Agenda Motivation Research Challenges Contributions & Approach Results Conclusion Future Work 2
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
LIQUID METAL Taming Heterogeneity
 LIQUID METAL Taming Heterogeneity Stephen Fink IBM Research! IBM Research Liquid Metal Team (IBM T. J. Watson Research Center) Josh Auerbach Perry Cheng 2 David Bacon Stephen Fink Ioana Baldini Rodric
LIQUID METAL Taming Heterogeneity Stephen Fink IBM Research! IBM Research Liquid Metal Team (IBM T. J. Watson Research Center) Josh Auerbach Perry Cheng 2 David Bacon Stephen Fink Ioana Baldini Rodric
General Purpose GPU Programming. Advanced Operating Systems Tutorial 7
 General Purpose GPU Programming Advanced Operating Systems Tutorial 7 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
General Purpose GPU Programming Advanced Operating Systems Tutorial 7 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
Instruction Set Architecture ( ISA ) 1 / 28
 1 / 28") Instruction Set Architecture ( ISA ) 1 / 28 instructions 2 / 28 Instruction Set Architecture Also called (computer) architecture Implementation --> actual realisation of ISA ISA can have multiple implementations
Instruction Set Architecture ( ISA ) 1 / 28 instructions 2 / 28 Instruction Set Architecture Also called (computer) architecture Implementation --> actual realisation of ISA ISA can have multiple implementations
1 Overview. 2 A Classification of Parallel Hardware. 3 Parallel Programming Languages 4 C+MPI. 5 Parallel Haskell
 Table of Contents Distributed and Parallel Technology Revision Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 1 Overview 2 A Classification of Parallel
Table of Contents Distributed and Parallel Technology Revision Hans-Wolfgang Loidl School of Mathematical and Computer Sciences Heriot-Watt University, Edinburgh 1 Overview 2 A Classification of Parallel
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
AMath 483/583, Lecture 24, May 20, Notes: Notes: What s a GPU? Notes: Some GPU application areas
 AMath 483/583 Lecture 24 May 20, 2011 Today: The Graphical Processing Unit (GPU) GPU Programming Today s lecture developed and presented by Grady Lemoine References: Andreas Kloeckner s High Performance
AMath 483/583 Lecture 24 May 20, 2011 Today: The Graphical Processing Unit (GPU) GPU Programming Today s lecture developed and presented by Grady Lemoine References: Andreas Kloeckner s High Performance
Accelerating Data Warehousing Applications Using General Purpose GPUs
 Accelerating Data Warehousing Applications Using General Purpose s Sponsors: Na%onal Science Founda%on, LogicBlox Inc., IBM, and NVIDIA The General Purpose is a many core co-processor 10s to 100s of cores
Accelerating Data Warehousing Applications Using General Purpose s Sponsors: Na%onal Science Founda%on, LogicBlox Inc., IBM, and NVIDIA The General Purpose is a many core co-processor 10s to 100s of cores
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
OpenCL for programming shared memory multicore CPUs
 OpenCL for programming shared memory multicore CPUs Akhtar Ali, Usman Dastgeer, and Christoph Kessler PELAB, Dept. of Computer and Information Science, Linköping University, Sweden akhal935@student.liu.se
OpenCL for programming shared memory multicore CPUs Akhtar Ali, Usman Dastgeer, and Christoph Kessler PELAB, Dept. of Computer and Information Science, Linköping University, Sweden akhal935@student.liu.se
Evaluating the Error Resilience of Parallel Programs
 Evaluating the Error Resilience of Parallel Programs Bo Fang, Karthik Pattabiraman, Matei Ripeanu, The University of British Columbia Sudhanva Gurumurthi AMD Research 1 Reliability trends The soft error
Evaluating the Error Resilience of Parallel Programs Bo Fang, Karthik Pattabiraman, Matei Ripeanu, The University of British Columbia Sudhanva Gurumurthi AMD Research 1 Reliability trends The soft error
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Locality-Aware Mapping of Nested Parallel Patterns on GPUs
 Locality-Aware Mapping of Nested Parallel Patterns on GPUs HyoukJoong Lee *, Kevin Brown *, Arvind Sujeeth *, Tiark Rompf, Kunle Olukotun * * Pervasive Parallelism Laboratory, Stanford University Purdue
Locality-Aware Mapping of Nested Parallel Patterns on GPUs HyoukJoong Lee *, Kevin Brown *, Arvind Sujeeth *, Tiark Rompf, Kunle Olukotun * * Pervasive Parallelism Laboratory, Stanford University Purdue
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Multi-threaded Queries. Intra-Query Parallelism in LLVM
 Multi-threaded Queries Intra-Query Parallelism in LLVM Multithreaded Queries Intra-Query Parallelism in LLVM Yang Liu Tianqi Wu Hao Li Interpreted vs Compiled (LLVM) Interpreted vs Compiled (LLVM) Interpreted
Multi-threaded Queries Intra-Query Parallelism in LLVM Multithreaded Queries Intra-Query Parallelism in LLVM Yang Liu Tianqi Wu Hao Li Interpreted vs Compiled (LLVM) Interpreted vs Compiled (LLVM) Interpreted
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Accelerating sequential computer vision algorithms using commodity parallel hardware
 Accelerating sequential computer vision algorithms using commodity parallel hardware Platform Parallel Netherlands GPGPU-day, 28 June 2012 Jaap van de Loosdrecht NHL Centre of Expertise in Computer Vision
Accelerating sequential computer vision algorithms using commodity parallel hardware Platform Parallel Netherlands GPGPU-day, 28 June 2012 Jaap van de Loosdrecht NHL Centre of Expertise in Computer Vision
Exploration of Supervised Machine Learning Techniques for Runtime Selection of CPU vs.gpu Execution in Java Programs
 Exploration of Supervised Machine Learning Techniques for Runtime Selection of CPU vs.gpu Execution in Java Programs Gloria Kim (Rice University) Akihiro Hayashi (Rice University) Vivek Sarkar (Georgia
Exploration of Supervised Machine Learning Techniques for Runtime Selection of CPU vs.gpu Execution in Java Programs Gloria Kim (Rice University) Akihiro Hayashi (Rice University) Vivek Sarkar (Georgia
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform
 Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory
 Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
Generating Efficient Data Movement Code for Heterogeneous Architectures with Distributed-Memory Roshan Dathathri Thejas Ramashekar Chandan Reddy Uday Bondhugula Department of Computer Science and Automation
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules
 Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules Toomas Remmelg Michel Steuwer Christophe Dubach The 4th South of England Regional Programming Language Seminar 27th
Lift: a Functional Approach to Generating High Performance GPU Code using Rewrite Rules Toomas Remmelg Michel Steuwer Christophe Dubach The 4th South of England Regional Programming Language Seminar 27th
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
General Purpose GPU Programming. Advanced Operating Systems Tutorial 9
 General Purpose GPU Programming Advanced Operating Systems Tutorial 9 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
General Purpose GPU Programming Advanced Operating Systems Tutorial 9 Tutorial Outline Review of lectured material Key points Discussion OpenCL Future directions 2 Review of Lectured Material Heterogeneous
Visual Analysis of Lagrangian Particle Data from Combustion Simulations
 Visual Analysis of Lagrangian Particle Data from Combustion Simulations Hongfeng Yu Sandia National Laboratories, CA Ultrascale Visualization Workshop, SC11 Nov 13 2011, Seattle, WA Joint work with Jishang
Visual Analysis of Lagrangian Particle Data from Combustion Simulations Hongfeng Yu Sandia National Laboratories, CA Ultrascale Visualization Workshop, SC11 Nov 13 2011, Seattle, WA Joint work with Jishang
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC
 GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
How GPUs can find your next hit: Accelerating virtual screening with OpenCL. Simon Krige
 How GPUs can find your next hit: Accelerating virtual screening with OpenCL Simon Krige ACS 2013 Agenda > Background > About blazev10 > What is a GPU? > Heterogeneous computing > OpenCL: a framework for
How GPUs can find your next hit: Accelerating virtual screening with OpenCL Simon Krige ACS 2013 Agenda > Background > About blazev10 > What is a GPU? > Heterogeneous computing > OpenCL: a framework for
Power 7. Dan Christiani Kyle Wieschowski
 Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Compiling for HSA accelerators with GCC
 Compiling for HSA accelerators with GCC Martin Jambor SUSE Labs 8th August 2015 Outline HSA branch: svn://gcc.gnu.org/svn/gcc/branches/hsa Table of contents: Very Brief Overview of HSA Generating HSAIL
Compiling for HSA accelerators with GCC Martin Jambor SUSE Labs 8th August 2015 Outline HSA branch: svn://gcc.gnu.org/svn/gcc/branches/hsa Table of contents: Very Brief Overview of HSA Generating HSAIL
Computing on GPUs. Prof. Dr. Uli Göhner. DYNAmore GmbH. Stuttgart, Germany
 Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
Computing on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Summary: The increasing power of GPUs has led to the intent to transfer computing load from CPUs to GPUs. A first example has been
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Fahad Zafar, Dibyajyoti Ghosh, Lawrence Sebald, Shujia Zhou. University of Maryland Baltimore County
 Accelerating a climate physics model with OpenCL Fahad Zafar, Dibyajyoti Ghosh, Lawrence Sebald, Shujia Zhou University of Maryland Baltimore County Introduction The demand to increase forecast predictability
Accelerating a climate physics model with OpenCL Fahad Zafar, Dibyajyoti Ghosh, Lawrence Sebald, Shujia Zhou University of Maryland Baltimore County Introduction The demand to increase forecast predictability
OpenACC Based GPU Parallelization of Plane Sweep Algorithm for Geometric Intersection. Anmol Paudel Satish Puri Marquette University Milwaukee, WI
 OpenACC Based GPU Parallelization of Plane Sweep Algorithm for Geometric Intersection Anmol Paudel Satish Puri Marquette University Milwaukee, WI Introduction Scalable spatial computation on high performance
OpenACC Based GPU Parallelization of Plane Sweep Algorithm for Geometric Intersection Anmol Paudel Satish Puri Marquette University Milwaukee, WI Introduction Scalable spatial computation on high performance
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
ET International HPC Runtime Software. ET International Rishi Khan SC 11. Copyright 2011 ET International, Inc.
 HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
HPC Runtime Software Rishi Khan SC 11 Current Programming Models Shared Memory Multiprocessing OpenMP fork/join model Pthreads Arbitrary SMP parallelism (but hard to program/ debug) Cilk Work Stealing
How to Write Fast Code , spring th Lecture, Mar. 31 st
 How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
How to Write Fast Code 18-645, spring 2008 20 th Lecture, Mar. 31 st Instructor: Markus Püschel TAs: Srinivas Chellappa (Vas) and Frédéric de Mesmay (Fred) Introduction Parallelism: definition Carrying
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Some features of modern CPUs. and how they help us
 Some features of modern CPUs and how they help us RAM MUL core Wide operands RAM MUL core CP1: hardware can multiply 64-bit floating-point numbers Pipelining: can start the next independent operation before
Some features of modern CPUs and how they help us RAM MUL core Wide operands RAM MUL core CP1: hardware can multiply 64-bit floating-point numbers Pipelining: can start the next independent operation before
Utilizing Graphics Processing Units for Rapid Facial Recognition using Video Input
 Utilizing Graphics Processing Units for Rapid Facial Recognition using Video Input Charles Gala, Dr. Raj Acharya Department of Computer Science and Engineering Pennsylvania State University State College,
Utilizing Graphics Processing Units for Rapid Facial Recognition using Video Input Charles Gala, Dr. Raj Acharya Department of Computer Science and Engineering Pennsylvania State University State College,
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Use of Synthetic Benchmarks for Machine- Learning-based Performance Auto-tuning
 Use of Synthetic Benchmarks for Machine- Learning-based Performance Auto-tuning Tianyi David Han and Tarek S. Abdelrahman The Edward S. Rogers Department of Electrical and Computer Engineering University
Use of Synthetic Benchmarks for Machine- Learning-based Performance Auto-tuning Tianyi David Han and Tarek S. Abdelrahman The Edward S. Rogers Department of Electrical and Computer Engineering University
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
ParalleX. A Cure for Scaling Impaired Parallel Applications. Hartmut Kaiser
 ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Splotch: High Performance Visualization using MPI, OpenMP and CUDA
 Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University Scalable Tools Workshop 7 August 2017
 Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University http://hpctoolkit.org Scalable Tools Workshop 7 August 2017 HPCToolkit 1 HPCToolkit Workflow source code compile &
Evolving HPCToolkit John Mellor-Crummey Department of Computer Science Rice University http://hpctoolkit.org Scalable Tools Workshop 7 August 2017 HPCToolkit 1 HPCToolkit Workflow source code compile &
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Cougar Open CL v1.0. Users Guide for Open CL support for Delphi/ C++Builder and.net
 Cougar Open CL v1.0 Users Guide for Open CL support for Delphi/ C++Builder and.net MtxVec version v4, rev 2.0 1999-2011 Dew Research www.dewresearch.com Table of Contents Cougar Open CL v1.0... 2 1 About
Cougar Open CL v1.0 Users Guide for Open CL support for Delphi/ C++Builder and.net MtxVec version v4, rev 2.0 1999-2011 Dew Research www.dewresearch.com Table of Contents Cougar Open CL v1.0... 2 1 About
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Height field ambient occlusion using CUDA
 Height field ambient occlusion using CUDA 3.6.2009 Outline 1 2 3 4 Theory Kernel 5 Height fields Self occlusion Current methods Marching several directions from each fragment Sampling several times along
Height field ambient occlusion using CUDA 3.6.2009 Outline 1 2 3 4 Theory Kernel 5 Height fields Self occlusion Current methods Marching several directions from each fragment Sampling several times along
Visualization of OpenCL Application Execution on CPU-GPU Systems
 Visualization of OpenCL Application Execution on CPU-GPU Systems A. Ziabari*, R. Ubal*, D. Schaa**, D. Kaeli* *NUCAR Group, Northeastern Universiy **AMD Northeastern University Computer Architecture Research
Visualization of OpenCL Application Execution on CPU-GPU Systems A. Ziabari*, R. Ubal*, D. Schaa**, D. Kaeli* *NUCAR Group, Northeastern Universiy **AMD Northeastern University Computer Architecture Research
Accelerated Machine Learning Algorithms in Python
 Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors
 ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
ad-heap: an Efficient Heap Data Structure for Asymmetric Multicore Processors Weifeng Liu and Brian Vinter Niels Bohr Institute University of Copenhagen Denmark {weifeng, vinter}@nbi.dk March 1, 2014 Weifeng
THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT HARDWARE PLATFORMS
 Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
Computer Science 14 (4) 2013 http://dx.doi.org/10.7494/csci.2013.14.4.679 Dominik Żurek Marcin Pietroń Maciej Wielgosz Kazimierz Wiatr THE COMPARISON OF PARALLEL SORTING ALGORITHMS IMPLEMENTED ON DIFFERENT
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Concurrent execution of an analytical workload on a POWER8 server with K40 GPUs A Technology Demonstration
 Concurrent execution of an analytical workload on a POWER8 server with K40 GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Berni Schiefer schiefer@ca.ibm.com Tuesday March 17th at 12:00
Concurrent execution of an analytical workload on a POWER8 server with K40 GPUs A Technology Demonstration Sina Meraji sinamera@ca.ibm.com Berni Schiefer schiefer@ca.ibm.com Tuesday March 17th at 12:00