EuroParl-UdS: Preserving and Extending Metadata in Parliamentary Debates
|
|
|
- Elijah Long
- 5 years ago
- Views:
Transcription

1 EuroParl-UdS: Preserving and Extending Metadata in Parliamentary Debates Alina Karakanta, Mihaela Vela, Elke Teich Department of Language Science and Technology, Saarland University
2 Outline Introduction Motivation EuroParl-Uds Corpus processing Metadata proceedings Metadata MEPs Sorting and alignment Corpus structure Corpus statistics Possible applications 2
3 Introduction Parliamentary corpora as a rich high-quality resource for linguistic applications Metadata Structure, organise, filter Related projects: Europarl (Koehn, 2005) Corrected and Structured EuroParl corpus (Gräen et al., 2014) European Comparable and Parallel Corpora (Calzada Perez et al., 2006) Digital Corpus of the European Parliament (Hajlaouiet al., 2014) Talk of Europe Travelling CLARIN Campus/LinkedEP (van Aggelen et al., 2017) 3
4 Motivation Machine translation Gender identification (Koppel et al., 2002) Topic detection (Yang et al., 2011; Blei, 2012) Translation studies (translationese) Status: Original vs. Translation (Rabinovich et al., 2015) Producer: Native vs. Non-native (Nisioi et al., 2016) 4
5 EuroParl-UdS Parallel corpora where the source language (SL) sentences come from native SL speakers and are aligned to sentences in the required target language (TL) (SL_native - TL) and comparable monolingual corpora of the target languages, where the sentences come from native TL speakers (TL_native). A complete pipeline to compile such a corpus from European Parliament debates. Supported languages (so far) : EN, DE, ES 5



6 Corpus processing xml csv 1. Download proceedings in HTML 4. Model proceedings as XML 3. Extract MEPs information 2. Download MEPs metadata in HTML 5. Filter out text not in the expected language xml_metadata 6. Add MEPs metadata to proceedings 7. Add sentence boundaries 8. Annotate token, lemma, PoS 10. Extract text into raw format EN_o EN_t EN_n EN_n DE 9. Separate originals from translations and filter by native speakers 11. Sentence align 7
7 Corpus processing xml csv 1. Download proceedings in HTML 4. Model proceedings as XML 3. Extract MEPs information 2. Download MEPs metadata in HTML 8




8 Metadata - Proceedings text id lang date place edition YYYYMMDD.XX, date and language 2-letter ISO code for the language version YYYY-MM-DD section id title ID as in the HTML for reference CDATA, text of the heading/headline intervention id speaker_id name is_mep mode role ID as in the HTML for reference if MEMP, unique code True or False spoken or written function of the speaker at the moment of speaking paragraph sl PCDATA Source language The actual text annotations text CDATA 9




9 Metadata - MEPs meps id name nationality birth date birth place death date death place national_ parties Id start date end date name of the party political_ parties Id member state start date end date name of the group role in the group 10
10 Corpus processing xml csv 1. Download proceedings in HTML 4. Model proceedings as XML 3. Extract MEPs information 2. Download MEPs metadata in HTML 5. Filter out text not in the expected language xml_metadata 6. Add MEPs metadata to proceedings 7. Add sentence boundaries 8. Annotate token, lemma, PoS 11
11 Corpus processing xml csv 1. Download proceedings in HTML 4. Model proceedings as XML 3. Extract MEPs information 2. Download MEPs metadata in HTML 5. Filter out text not in the expected language xml_metadata 6. Add MEPs metadata to proceedings 7. Add sentence boundaries 8. Annotate token, lemma, PoS 10. Extract text into raw format EN_o EN_t EN_n EN_n DE 9. Separate originals from translations and filter by native speakers 11. Sentence align 12
12 Sorting and alignment Language identifiers to filter text not in the expected language (Python: langid, langdetect) PoS-Tagging, lemmatisation (TreeTagger) Sentence split (Punkt, NLTK) Filter by: Originals vs. Translations Native vs. Non-native For the parallel corpus: Automatically align text per intervention (hunalign) 13
13 Corpus structure 14
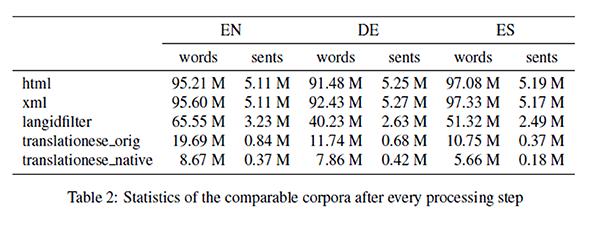
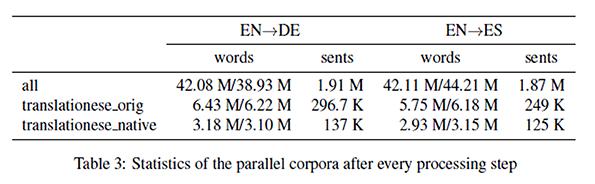
14 Corpus statistics 15


15 Possible applications Careful data selection for improving MT (Kurokawa et al., 2009; Lembersky et al., 2012a) Translationese features Modelling human translation choice (Teich, E. and Martınez Martınez, J., in press) Adequacy = Fidelity to SL + Conformity with TL 16
16 EuroParl-UdS The corpus: The code: Thank you! Questions: Special thanks to our colleague Jose Martinez Martinez for by providing us his scripts ( for crawling the data - while building this resource. 17
Implementing a Variety of Linguistic Annotations
 Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
LING203: Corpus. March 9, 2009
 LING203: Corpus March 9, 2009 Corpus A collection of machine readable texts SJSU LLD have many corpora http://linguistics.sjsu.edu/bin/view/public/chltcorpora Each corpus has a link to a description page
LING203: Corpus March 9, 2009 Corpus A collection of machine readable texts SJSU LLD have many corpora http://linguistics.sjsu.edu/bin/view/public/chltcorpora Each corpus has a link to a description page
Introduction to Text Mining. Aris Xanthos - University of Lausanne
 Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Corpus methods for sociolinguistics. Emily M. Bender NWAV 31 - October 10, 2002
 Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic
Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic
Best practices in the design, creation and dissemination of speech corpora at The Language Archive
 LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion
 MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
Benedikt Perak, * Filip Rodik,
 Building a corpus of the Croatian parliamentary debates using UDPipe open source NLP tools and Neo4j graph database for creation of social ontology model, text classification and extraction of semantic
Building a corpus of the Croatian parliamentary debates using UDPipe open source NLP tools and Neo4j graph database for creation of social ontology model, text classification and extraction of semantic
Parallel Concordancing and Translation. Michael Barlow
 [Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
[Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
Semantics Isn t Easy Thoughts on the Way Forward
 Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Corpus Acquisition from the Internet
 Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Maca a configurable tool to integrate Polish morphological data. Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology
 Maca a configurable tool to integrate Polish morphological data Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology Outline Morphological resources for Polish Tagset and segmentation differences
Maca a configurable tool to integrate Polish morphological data Adam Radziszewski Tomasz Śniatowski Wrocław University of Technology Outline Morphological resources for Polish Tagset and segmentation differences
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen. WP5: Glossa Integration
 Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
How can CLARIN archive and curate my resources?
 How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
Stand-off annotation of web content as a legally safer alternative to bitext crawling for distribution 1
 Stand-off annotation of web content as a legally safer alternative to bitext crawling for distribution 1 Mikel L. Forcada Miquel Esplà-Gomis Juan A. Pérez-Ortiz {mlf,mespla,japerez}@dlsi.ua.es Departament
Stand-off annotation of web content as a legally safer alternative to bitext crawling for distribution 1 Mikel L. Forcada Miquel Esplà-Gomis Juan A. Pérez-Ortiz {mlf,mespla,japerez}@dlsi.ua.es Departament
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
A BNC-like corpus of American English
 The American National Corpus Everything You Always Wanted To Know... And Weren t Afraid To Ask Nancy Ide Department of Computer Science Vassar College What is the? A BNC-like corpus of American English
The American National Corpus Everything You Always Wanted To Know... And Weren t Afraid To Ask Nancy Ide Department of Computer Science Vassar College What is the? A BNC-like corpus of American English
DepPattern User Manual beta version. December 2008
 DepPattern User Manual beta version December 2008 Contents 1 DepPattern: A Grammar Based Generator of Multilingual Parsers 1 1.1 Contributions....................................... 1 1.2 Supported Languages..................................
DepPattern User Manual beta version December 2008 Contents 1 DepPattern: A Grammar Based Generator of Multilingual Parsers 1 1.1 Contributions....................................... 1 1.2 Supported Languages..................................
NLPL - The Nordic Language Processing Laboratory.
 NLPL - The Nordic Language Processing Laboratory http://nlpl.eu/ What is NLPL? Vision virtual laboratory for large-scale NLP research share high-performance computing and data resources across language
NLPL - The Nordic Language Processing Laboratory http://nlpl.eu/ What is NLPL? Vision virtual laboratory for large-scale NLP research share high-performance computing and data resources across language
Machine Translation Research in META-NET
 Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
ISLE Metadata Initiative (IMDI) PART 1 B. Metadata Elements for Catalogue Descriptions
 PART 1 B. Metadata Elements for Catalogue Descriptions") ISLE Metadata Initiative (IMDI) PART 1 B Metadata Elements for Catalogue Descriptions Version 3.0.13 August 2009 INDEX 1 INTRODUCTION...3 2 CATALOGUE ELEMENTS OVERVIEW...4 3 METADATA ELEMENT DEFINITIONS...6
ISLE Metadata Initiative (IMDI) PART 1 B Metadata Elements for Catalogue Descriptions Version 3.0.13 August 2009 INDEX 1 INTRODUCTION...3 2 CATALOGUE ELEMENTS OVERVIEW...4 3 METADATA ELEMENT DEFINITIONS...6
Contents. List of Figures. List of Tables. Acknowledgements
 Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
ANC2Go: A Web Application for Customized Corpus Creation
 ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
Formats and standards for metadata, coding and tagging. Paul Meurer
 Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Manual vs Automatic Bitext Extraction
 Manual vs Automatic Bitext Extraction Aibek Makazhanov, Bagdat Myrzakhmetov, Zhenisbek Assylbekov Nazarbayev University, National Laboratory Astana Nazarbayev University, School of Science and Technology
Manual vs Automatic Bitext Extraction Aibek Makazhanov, Bagdat Myrzakhmetov, Zhenisbek Assylbekov Nazarbayev University, National Laboratory Astana Nazarbayev University, School of Science and Technology
TextProc a natural language processing framework
 TextProc a natural language processing framework Janez Brezovnik, Milan Ojsteršek Abstract Our implementation of a natural language processing framework (called TextProc) is described in this paper. We
TextProc a natural language processing framework Janez Brezovnik, Milan Ojsteršek Abstract Our implementation of a natural language processing framework (called TextProc) is described in this paper. We
STS Infrastructural considerations. Christian Chiarcos
 STS Infrastructural considerations Christian Chiarcos chiarcos@uni-potsdam.de Infrastructure Requirements Candidates standoff-based architecture (Stede et al. 2006, 2010) UiMA (Ferrucci and Lally 2004)
STS Infrastructural considerations Christian Chiarcos chiarcos@uni-potsdam.de Infrastructure Requirements Candidates standoff-based architecture (Stede et al. 2006, 2010) UiMA (Ferrucci and Lally 2004)
XML. extensible Markup Language. ... and its usefulness for linguists
 XML extensible Markup Language... and its usefulness for linguists Thomas Mayer thomas.mayer@uni-konstanz.de Fachbereich Sprachwissenschaft, Universität Konstanz Seminar Computerlinguistik II (Miriam Butt)
XML extensible Markup Language... and its usefulness for linguists Thomas Mayer thomas.mayer@uni-konstanz.de Fachbereich Sprachwissenschaft, Universität Konstanz Seminar Computerlinguistik II (Miriam Butt)
BYTE / BOOL A BYTE is an unsigned 8 bit integer. ABOOL is a BYTE that is guaranteed to be either 0 (False) or 1 (True).
 or 1 (True).") NAME CQi tutorial how to run a CQP query DESCRIPTION This tutorial gives an introduction to the Corpus Query Interface (CQi). After a short description of the data types used by the CQi, a simple application
NAME CQi tutorial how to run a CQP query DESCRIPTION This tutorial gives an introduction to the Corpus Query Interface (CQi). After a short description of the data types used by the CQi, a simple application
ResPubliQA 2010
 SZTAKI @ ResPubliQA 2010 David Mark Nemeskey Computer and Automation Research Institute, Hungarian Academy of Sciences, Budapest, Hungary (SZTAKI) Abstract. This paper summarizes the results of our first
SZTAKI @ ResPubliQA 2010 David Mark Nemeskey Computer and Automation Research Institute, Hungarian Academy of Sciences, Budapest, Hungary (SZTAKI) Abstract. This paper summarizes the results of our first
INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS. Jan Tore Lønning, Lecture 8, 12 Oct
 1 INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS Jan Tore Lønning, Lecture 8, 12 Oct. 2016 jtl@ifi.uio.no Today 2 Preparing bitext Parameter tuning Reranking Some linguistic issues STMT so far 3 We
1 INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS Jan Tore Lønning, Lecture 8, 12 Oct. 2016 jtl@ifi.uio.no Today 2 Preparing bitext Parameter tuning Reranking Some linguistic issues STMT so far 3 We
Exploring archives with probabilistic models: Topic modelling for the European Commission Archives
 Exploring archives with probabilistic models: Topic modelling for the European Commission Archives Simon Hengchen, Mathias Coeckelbergs, Seth van Hooland, Ruben Verborgh & Thomas Steiner Université libre
Exploring archives with probabilistic models: Topic modelling for the European Commission Archives Simon Hengchen, Mathias Coeckelbergs, Seth van Hooland, Ruben Verborgh & Thomas Steiner Université libre
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
Parts of Speech, Named Entity Recognizer
 Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
Parts of Speech, Named Entity Recognizer Artificial Intelligence @ Allegheny College Janyl Jumadinova November 8, 2018 Janyl Jumadinova Parts of Speech, Named Entity Recognizer November 8, 2018 1 / 25
ANNIS3 Multiple Segmentation Corpora Guide
 ANNIS3 Multiple Segmentation Corpora Guide (For the latest documentation see also: http://korpling.github.io/annis) title: version: ANNIS3 Multiple Segmentation Corpora Guide 2013-6-15a author: Amir Zeldes
ANNIS3 Multiple Segmentation Corpora Guide (For the latest documentation see also: http://korpling.github.io/annis) title: version: ANNIS3 Multiple Segmentation Corpora Guide 2013-6-15a author: Amir Zeldes
Deliverable D Adapted tools for the QTLaunchPad infrastructure
 This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad). This project has received funding from the
This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad). This project has received funding from the
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
CORLI. a linguistic consortium for corpus, language and interaction
 CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
Workshop on statistical machine translation for curious translators. Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L.
 Workshop on statistical machine translation for curious translators Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L. Outline 1) Introduction to machine translation 2) 3)Acquisition of parallel
Workshop on statistical machine translation for curious translators Víctor M. Sánchez-Cartagena Prompsit Language Engineering, S.L. Outline 1) Introduction to machine translation 2) 3)Acquisition of parallel
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF
 Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
The Goal of this Document. Where to Start?
 A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
A QUICK INTRODUCTION TO THE SEMILAR APPLICATION Mihai Lintean, Rajendra Banjade, and Vasile Rus vrus@memphis.edu linteam@gmail.com rbanjade@memphis.edu The Goal of this Document This document introduce
RLAT Rapid Language Adaptation Toolkit
 RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
Package word.alignment
 Type Package Package word.alignment October 26, 2017 Title Computing Word Alignment Using IBM Model 1 (and Symmetrization) for a Given Parallel Corpus and Its Evaluation Version 1.0.7 Date 2017-10-10 Author
Type Package Package word.alignment October 26, 2017 Title Computing Word Alignment Using IBM Model 1 (and Symmetrization) for a Given Parallel Corpus and Its Evaluation Version 1.0.7 Date 2017-10-10 Author
L435/L555. Dept. of Linguistics, Indiana University Fall 2016
 for : for : L435/L555 Dept. of, Indiana University Fall 2016 1 / 12 What is? for : Decent definition from wikipedia: Computer programming... is a process that leads from an original formulation of a computing
for : for : L435/L555 Dept. of, Indiana University Fall 2016 1 / 12 What is? for : Decent definition from wikipedia: Computer programming... is a process that leads from an original formulation of a computing
Linguistic Resources for Handwriting Recognition and Translation Evaluation
 Linguistic Resources for Handwriting Recognition and Translation Evaluation Zhiyi Song*, Safa Ismael*, Steven Grimes*, David Doermann, Stephanie Strassel* *Linguistic Data Consortium, University of Pennsylvania,
Linguistic Resources for Handwriting Recognition and Translation Evaluation Zhiyi Song*, Safa Ismael*, Steven Grimes*, David Doermann, Stephanie Strassel* *Linguistic Data Consortium, University of Pennsylvania,
Processing Hansard Documents with Portage
 Processing Hansard Documents with Portage George Foster November 12, 2010 1 Introduction The House of Commons translation task involves handling documents that are transcriptions of parliamentary sessions
Processing Hansard Documents with Portage George Foster November 12, 2010 1 Introduction The House of Commons translation task involves handling documents that are transcriptions of parliamentary sessions
Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D
 Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D Michael Beißwenger, Eric Ehrhardt, Axel Herold, Harald Lüngen, Angelika Storrer Background of this talk:
Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D Michael Beißwenger, Eric Ehrhardt, Axel Herold, Harald Lüngen, Angelika Storrer Background of this talk:
CLARIN for Linguists Portal & Searching for Resources. Jan Odijk LOT Summerschool Nijmegen,
 CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
Progress Report STEVIN Projects
 Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
Using the Ellogon Natural Language Engineering Infrastructure
 Using the Ellogon Natural Language Engineering Infrastructure Georgios Petasis, Vangelis Karkaletsis, Georgios Paliouras, and Constantine D. Spyropoulos Software and Knowledge Engineering Laboratory, Institute
Using the Ellogon Natural Language Engineering Infrastructure Georgios Petasis, Vangelis Karkaletsis, Georgios Paliouras, and Constantine D. Spyropoulos Software and Knowledge Engineering Laboratory, Institute
Tokenization and Sentence Segmentation. Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017
 Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
Tokenization and Sentence Segmentation Yan Shao Department of Linguistics and Philology, Uppsala University 29 March 2017 Outline 1 Tokenization Introduction Exercise Evaluation Summary 2 Sentence segmentation
The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER An Experimental Management System. Philipp Koehn
 The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER 2010 87 96 An Experimental Management System Philipp Koehn University of Edinburgh Abstract We describe Experiment.perl, an experimental
The Prague Bulletin of Mathematical Linguistics NUMBER 94 SEPTEMBER 2010 87 96 An Experimental Management System Philipp Koehn University of Edinburgh Abstract We describe Experiment.perl, an experimental
Automated Classification. Lars Marius Garshol Topic Maps
 Automated Classification Lars Marius Garshol Topic Maps 2007 2007-03-21 Automated classification What is it? Why do it? 2 What is automated classification? Create parts of a topic map
Automated Classification Lars Marius Garshol Topic Maps 2007 2007-03-21 Automated classification What is it? Why do it? 2 What is automated classification? Create parts of a topic map
Evaluation of alignment methods for HTML parallel text 1
 Evaluation of alignment methods for HTML parallel text 1 Enrique Sánchez-Villamil, Susana Santos-Antón, Sergio Ortiz-Rojas, Mikel L. Forcada Transducens Group, Departament de Llenguatges i Sistemes Informàtics
Evaluation of alignment methods for HTML parallel text 1 Enrique Sánchez-Villamil, Susana Santos-Antón, Sergio Ortiz-Rojas, Mikel L. Forcada Transducens Group, Departament de Llenguatges i Sistemes Informàtics
A System of Exploiting and Building Homogeneous and Large Resources for the Improvement of Vietnamese-Related Machine Translation Quality
 A System of Exploiting and Building Homogeneous and Large Resources for the Improvement of Vietnamese-Related Machine Translation Quality Huỳnh Công Pháp 1 and Nguyễn Văn Bình 2 The University of Danang
A System of Exploiting and Building Homogeneous and Large Resources for the Improvement of Vietnamese-Related Machine Translation Quality Huỳnh Công Pháp 1 and Nguyễn Văn Bình 2 The University of Danang
<Insert Picture Here> Oracle Policy Automation 10.3 Features and Benefits
 Oracle Policy Automation 10.3 Features and Benefits June 2011 Introducing Oracle Policy Automation 10.3 Highlights include: Fast and easy generation of documents such as decision
Oracle Policy Automation 10.3 Features and Benefits June 2011 Introducing Oracle Policy Automation 10.3 Highlights include: Fast and easy generation of documents such as decision
PSI-Toolkit - a customizable set of linguistic tools
 PSI-Toolkit - a customizable set of linguistic tools Krzysztof Jassem Adam Mickiewicz University Poznań, Poland jassem@amu.edu.pl Abstract The paper describes PSI-Toolkit, a set of NLP tools designed within
PSI-Toolkit - a customizable set of linguistic tools Krzysztof Jassem Adam Mickiewicz University Poznań, Poland jassem@amu.edu.pl Abstract The paper describes PSI-Toolkit, a set of NLP tools designed within
A cocktail approach to the VideoCLEF 09 linking task
 A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
Machine Learning in GATE
 Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
Machine Learning in GATE Angus Roberts, Horacio Saggion, Genevieve Gorrell Recap Previous two days looked at knowledge engineered IE This session looks at machine learned IE Supervised learning Effort
The American National Corpus First Release
 The American National Corpus First Release Nancy Ide and Keith Suderman Department of Computer Science, Vassar College, Poughkeepsie, NY 12604-0520 USA ide@cs.vassar.edu, suderman@cs.vassar.edu Abstract
The American National Corpus First Release Nancy Ide and Keith Suderman Department of Computer Science, Vassar College, Poughkeepsie, NY 12604-0520 USA ide@cs.vassar.edu, suderman@cs.vassar.edu Abstract
XML Support for Annotated Language Resources
 XML Support for Annotated Language Resources Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York USA ide@cs.vassar.edu Laurent Romary Equipe Langue et Dialogue LORIA/CNRS Vandoeuvre-lès-Nancy,
XML Support for Annotated Language Resources Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York USA ide@cs.vassar.edu Laurent Romary Equipe Langue et Dialogue LORIA/CNRS Vandoeuvre-lès-Nancy,
LIDER Survey. Overview. Number of participants: 24. Participant profile (organisation type, industry sector) Relevant use-cases
 Relevant use-cases") LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
Computing Similarity between Cultural Heritage Items using Multimodal Features
 Computing Similarity between Cultural Heritage Items using Multimodal Features Nikolaos Aletras and Mark Stevenson Department of Computer Science, University of Sheffield Could the combination of textual
Computing Similarity between Cultural Heritage Items using Multimodal Features Nikolaos Aletras and Mark Stevenson Department of Computer Science, University of Sheffield Could the combination of textual
Error annotation in adjective noun (AN) combinations
 combinations") Error annotation in adjective noun (AN) combinations This document describes the annotation scheme devised for annotating errors in AN combinations and explains how the inter-annotator agreement has been
Error annotation in adjective noun (AN) combinations This document describes the annotation scheme devised for annotating errors in AN combinations and explains how the inter-annotator agreement has been
JU_CSE_TE: System Description 2010 ResPubliQA
 JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
JU_CSE_TE: System Description QA@CLEF 2010 ResPubliQA Partha Pakray 1, Pinaki Bhaskar 1, Santanu Pal 1, Dipankar Das 1, Sivaji Bandyopadhyay 1, Alexander Gelbukh 2 Department of Computer Science & Engineering
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
IF ONLY WE D KNOWN: COLLECTING RESEARCH DATA
 FACULTY LIBRARY OF ARTS & PHILOSOPHY IF ONLY WE D KNOWN: COLLECTING RESEARCH DATA Katrien Deroo - LW Research Day WHAT IS DATA MANAGEMENT ABOUT? Spreadsheet bursting at the seams Database reconstruction
FACULTY LIBRARY OF ARTS & PHILOSOPHY IF ONLY WE D KNOWN: COLLECTING RESEARCH DATA Katrien Deroo - LW Research Day WHAT IS DATA MANAGEMENT ABOUT? Spreadsheet bursting at the seams Database reconstruction
Refresher on Dependency Syntax and the Nivre Algorithm
 Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
Refresher on Dependency yntax and Nivre Algorithm Richard Johansson 1 Introduction This document gives more details about some important topics that re discussed very quickly during lecture: dependency
Incremental Integer Linear Programming for Non-projective Dependency Parsing
 Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel James Clarke ICCS, University of Edinburgh 22. July 2006 EMNLP 2006 S. Riedel, J. Clarke (ICCS, Edinburgh)
Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel James Clarke ICCS, University of Edinburgh 22. July 2006 EMNLP 2006 S. Riedel, J. Clarke (ICCS, Edinburgh)
Learning to find transliteration on the Web
 Learning to find transliteration on the Web Chien-Cheng Wu Department of Computer Science National Tsing Hua University 101 Kuang Fu Road, Hsin chu, Taiwan d9283228@cs.nthu.edu.tw Jason S. Chang Department
Learning to find transliteration on the Web Chien-Cheng Wu Department of Computer Science National Tsing Hua University 101 Kuang Fu Road, Hsin chu, Taiwan d9283228@cs.nthu.edu.tw Jason S. Chang Department
Finding parallel texts on the web using cross-language information retrieval
 Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
Growing interests in. Urgent needs of. Develop a fieldworkers toolkit (fwtk) for the research of endangered languages
 for the research of endangered languages") ELPR IV International Conference 2002 Topics Reitaku University College of Foreign Languages Developing Tools for Creating-Maintaining-Analyzing Field Shoju CHIBA Reitaku University, Japan schiba@reitaku-u.ac.jp
ELPR IV International Conference 2002 Topics Reitaku University College of Foreign Languages Developing Tools for Creating-Maintaining-Analyzing Field Shoju CHIBA Reitaku University, Japan schiba@reitaku-u.ac.jp
Annotation by category - ELAN and ISO DCR
 Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Using metadata for interoperability. CS 431 February 28, 2007 Carl Lagoze Cornell University
 Using metadata for interoperability CS 431 February 28, 2007 Carl Lagoze Cornell University What is the problem? Getting heterogeneous systems to work together Providing the user with a seamless information
Using metadata for interoperability CS 431 February 28, 2007 Carl Lagoze Cornell University What is the problem? Getting heterogeneous systems to work together Providing the user with a seamless information
An efficient and user-friendly tool for machine translation quality estimation
 An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
Building and Annotating Corpora of Collaborative Authoring in Wikipedia
 Building and Annotating Corpora of Collaborative Authoring in Wikipedia Johannes Daxenberger, Oliver Ferschke and Iryna Gurevych Workshop: Building Corpora of Computer-Mediated Communication: Issues, Challenges,
Building and Annotating Corpora of Collaborative Authoring in Wikipedia Johannes Daxenberger, Oliver Ferschke and Iryna Gurevych Workshop: Building Corpora of Computer-Mediated Communication: Issues, Challenges,
Word counts and match values
 integrated translation environment Word counts and match values 2004-2014 Kilgray Translation Technologies. All rights reserved. 2004-2014 ZAAC. All rights reserved. Contents Contents... 2 1 General...
integrated translation environment Word counts and match values 2004-2014 Kilgray Translation Technologies. All rights reserved. 2004-2014 ZAAC. All rights reserved. Contents Contents... 2 1 General...
EU Terminology: Building text-related & translation-oriented projects for IATE
 EU Terminology: Building text-related & translation-oriented projects for IATE 20th European Symposium on Languages for Special Purposes University of Vienna 8-10 July 2015 Rodolfo Maslias European Parliament
EU Terminology: Building text-related & translation-oriented projects for IATE 20th European Symposium on Languages for Special Purposes University of Vienna 8-10 July 2015 Rodolfo Maslias European Parliament
Introducing XAIRA. Lou Burnard Tony Dodd. An XML aware tool for corpus indexing and searching. Research Technology Services, OUCS
 Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
Building the Multilingual Web of Data. Integrating NLP with Linked Data and RDF using the NLP Interchange Format
 Building the Multilingual Web of Data Integrating NLP with Linked Data and RDF using the NLP Interchange Format Presenter name 1 Outline 1. Introduction 2. NIF Basics 3. NIF corpora 4. NIF tools & services
Building the Multilingual Web of Data Integrating NLP with Linked Data and RDF using the NLP Interchange Format Presenter name 1 Outline 1. Introduction 2. NIF Basics 3. NIF corpora 4. NIF tools & services
Finding viable seed URLs for web corpora
 Finding viable seed URLs for web corpora A scouting approach and comparative study of available sources Adrien Barbaresi ICAR Lab @ ENS Lyon 9th Web as Corpus Workshop Gothenburg April 26, 2014 Adrien
Finding viable seed URLs for web corpora A scouting approach and comparative study of available sources Adrien Barbaresi ICAR Lab @ ENS Lyon 9th Web as Corpus Workshop Gothenburg April 26, 2014 Adrien
CSC 5930/9010: Text Mining GATE Developer Overview
 1 CSC 5930/9010: Text Mining GATE Developer Overview Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 GATE Components 2 We will deal primarily with GATE Developer:
1 CSC 5930/9010: Text Mining GATE Developer Overview Dr. Paula Matuszek Paula.Matuszek@villanova.edu Paula.Matuszek@gmail.com (610) 647-9789 GATE Components 2 We will deal primarily with GATE Developer:
From Web Page Storage to Living Web Archives
 From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
From Web Page Storage to Living Web Archives Thomas Risse JISC, the DPC and the UK Web Archiving Consortium Workshop British Library, London, 21.7.2009 1 Agenda Web Crawling today & Open Issues LiWA Living
Module 10: Advanced GATE Applications
 Module 10: Advanced GATE Applications The University of Sheffield, 1995-2010 This work is licenced under the Creative Commons Attribution-NonCommercial-ShareAlike Licence About this tutorial This tutorial
Module 10: Advanced GATE Applications The University of Sheffield, 1995-2010 This work is licenced under the Creative Commons Attribution-NonCommercial-ShareAlike Licence About this tutorial This tutorial
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Thot Toolkit for Statistical Machine Translation. User Manual. Daniel Ortiz Martínez Webinterpret
 Thot Toolkit for Statistical Machine Translation User Manual Daniel Ortiz Martínez daniel.o@webinterpret.com Webinterpret January 2018 CONTENTS 1 Introduction 1 1.1 Statistical Foundations.............................
Thot Toolkit for Statistical Machine Translation User Manual Daniel Ortiz Martínez daniel.o@webinterpret.com Webinterpret January 2018 CONTENTS 1 Introduction 1 1.1 Statistical Foundations.............................
The Multilingual Language Library
 The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
Schemachine. (C) 2002 Rick Jelliffe. A framework for modular validation of XML documents
 2002 Rick Jelliffe. A framework for modular validation of XML documents") June 21, 2002 Schemachine (C) 2002 Rick Jelliffe A framework for modular validation of XML documents This note specifies a possible framework for supporting modular XML validation. It has no official status
June 21, 2002 Schemachine (C) 2002 Rick Jelliffe A framework for modular validation of XML documents This note specifies a possible framework for supporting modular XML validation. It has no official status
Ortolang Tools : MarsaTag
 Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Large Crawls of the Web for Linguistic Purposes
 Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
Large Crawls of the Web for Linguistic Purposes SSLMIT, University of Bologna Birmingham, July 2005 Outline Introduction 1 Introduction 2 3 Basics Heritrix My ongoing crawl 4 Filtering and cleaning 5 Annotation
NLTK Tutorial: Basics
 Table of Contents NLTK Tutorial: Basics Edward Loper 1. Goals...3 2. Accessing NLTK...3 3. Words...4 3.1. Types and Tokens...4 3.2. Text Locations...4 3.2.1. Units...5 3.2.2. Sources...6 3.3. Tokens and
Table of Contents NLTK Tutorial: Basics Edward Loper 1. Goals...3 2. Accessing NLTK...3 3. Words...4 3.1. Types and Tokens...4 3.2. Text Locations...4 3.2.1. Units...5 3.2.2. Sources...6 3.3. Tokens and
The Muc7 T Corpus. 1 Introduction. 2 Creation of Muc7 T
 The Muc7 T Corpus Katrin Tomanek and Udo Hahn Jena University Language & Information Engineering (JULIE) Lab Friedrich-Schiller-Universität Jena, Germany {katrin.tomanek udo.hahn}@uni-jena.de 1 Introduction
The Muc7 T Corpus Katrin Tomanek and Udo Hahn Jena University Language & Information Engineering (JULIE) Lab Friedrich-Schiller-Universität Jena, Germany {katrin.tomanek udo.hahn}@uni-jena.de 1 Introduction
Converting the Corpus Query Language to the Natural Language
 Converting the Corpus Query Language to the Natural Language Daniela Ryšavá 1, Nikol Volková 1, Adam Rambousek 2 1 Faculty of Arts, Masaryk University Arne Nováka 1, 602 00 Brno, Czech Republic 399364@mail.muni.cz,
Converting the Corpus Query Language to the Natural Language Daniela Ryšavá 1, Nikol Volková 1, Adam Rambousek 2 1 Faculty of Arts, Masaryk University Arne Nováka 1, 602 00 Brno, Czech Republic 399364@mail.muni.cz,
How to.. What is the point of it?
 Program's name: Linguistic Toolbox 3.0 α-version Short name: LIT Authors: ViatcheslavYatsko, Mikhail Starikov Platform: Windows System requirements: 1 GB free disk space, 512 RAM,.Net Farmework Supported
Program's name: Linguistic Toolbox 3.0 α-version Short name: LIT Authors: ViatcheslavYatsko, Mikhail Starikov Platform: Windows System requirements: 1 GB free disk space, 512 RAM,.Net Farmework Supported
Query Translation for Cross-lingual Search in the Academic Search Engine PubPsych
 Query Translation for Cross-lingual Search in the Academic Search Engine PubPsych Cristina España-Bonet 1, Juliane Stiller 2, Roland Ramthun 3, Josef van Genabith 1 and Vivien Petras 2 1 Universität des
Query Translation for Cross-lingual Search in the Academic Search Engine PubPsych Cristina España-Bonet 1, Juliane Stiller 2, Roland Ramthun 3, Josef van Genabith 1 and Vivien Petras 2 1 Universität des
Language Resources and Linked Data
 Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
Integrating NLP with Linked Data: the NIF Format Milan Dojchinovski @EKAW 2014 November 24-28, 2014, Linkoping, Sweden milan.dojchinovski@fit.cvut.cz - @m1ci - http://dojchinovski.mk Web Intelligence Research
Information Retrieval CS Lecture 01. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Information Retrieval CS 6900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Information Retrieval Information Retrieval (IR) is finding material of an unstructured
Adelheid 1.0 Annotation Tool Manual. Introduction
 Adelheid 1.0 Annotation Tool Manual Introduction Adelheid is tagger-lemmatizer system for historical Dutch, available through the Clarin infrastructure. Its output is in an XML format, which, although
Adelheid 1.0 Annotation Tool Manual Introduction Adelheid is tagger-lemmatizer system for historical Dutch, available through the Clarin infrastructure. Its output is in an XML format, which, although