Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D
|
|
|
- Gyles Patterson
- 6 years ago
- Views:
Transcription


1 Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D Michael Beißwenger, Eric Ehrhardt, Axel Herold, Harald Lüngen, Angelika Storrer
2 Background of this talk: CMC 2 TEI Computer-mediated communication (CMC) / social media : interaction mediated through computer networks (the internet), e.g. chats, forums, communication on social network sites, blog comments, tweets, Wikipedia talk pages, SMS and whatsapp conversations etc. New genres which the TEI has not yet envisioned (citation from TEI-P5 chapter about customization) TEI-SIG computer-mediated communication (CMC-SIG): How can TEI-P5 be adapted for the representation of CMC genres and corpora? Options: 1) customization 2) extension of standard CMC: not a niche phenomenon but with a high (still growing) impact on people s everyday lives, interactions, language and society
3 Background of this talk: CMC 2 TEI TEI-SIG computer-mediated communication (CMC-SIG): Next planned step (spring 2017): feature request for a basic structure for CMC based on the models discussed and schemas developed so far Results of the SIG work so far: Three schemas for modeling CMC corpora in TEI Several existing corpora (French & German) for different CMC genres (Wikipedia discussions, SMS, Twitter, chat etc.) that have entirely been represented using these schemas Most recent schema: CLARIN-D CMC-TEI : focus especially (but not only) on written CMC genres developed and used for remodeling an existing chat corpus for German


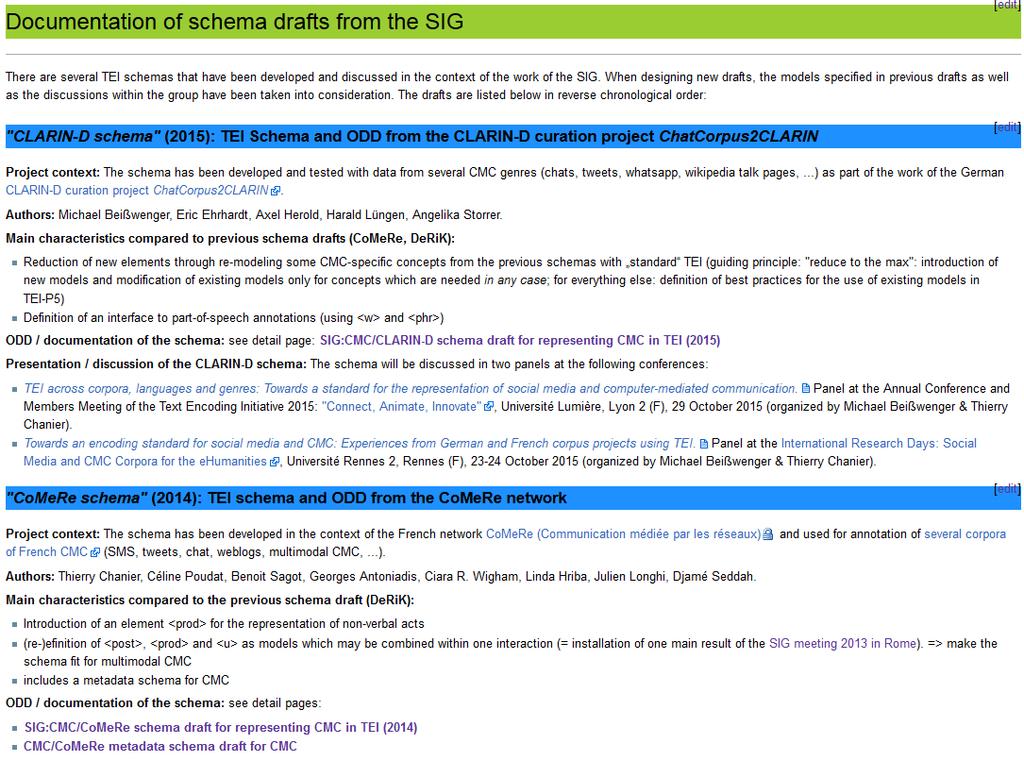
4 Schemas and resources of the CMC-SIG
5 Structure of the talk 1) Project background of the most recent schema ( CLARIN-D CMC-TEI ) 2) General challenge of modeling CMC in TEI 3) Outline of the schema on the example of selected features 4) Summary and outlook
.")
6 ChatCorpus2CLARIN: Project background Curation project of the CLARIN-D F-AG 1 German Philology Period: May 2015 February 2016 Task: develop a workflow and resources for the integration of an existing chat corpus into the CLARIN-D research infrastructure for language resources and tools in the Humanities and the Social Sciences ( One work package: remodeling of the corpus in a TEI-compliant format. Project team: Michael Beißwenger (U Dortmund / DUE), Angelika Storrer, Eric Ehrhardt (U Mannheim), Harald Lüngen (IDS Mannheim), Axel Herold (BBAW, Berlin) + other colleagues at the CLARIN-D hubs at IDS and BBAW.
7 The original resource (chat corpus 1.0) Dortmund Chat Corpus scope: Language use and linguistic variation in German chats corpus size: 478 logfiles with user posts / 1 million words availability: online for download since 2005 (together with a simple query tool, addressees: linguists) + as a collection of HTML pages (for online browsing, addressees: German teachers) XML-annotated on basis of a homegrown XML format ( ChatXML ) which describes: (1) the basic structure and properties of logfiles and postings ( messages ) (2) selected items on the micro-level of user posts (emoticons, acronyms, addressing terms, nickname mentions) (3) selected metadata about the chat platforms and users.
8 Goals of the project (1) Sustainability: Integrate the only CMC corpus for German which is freely availabe (and which is used by many researchers) into the CLARIN-D corpus infrastructure Additional lingustic annotations (part-of-speech) that will allow or more sophisticated corpus queries Interoperability: Represent the corpus compliant to an established standard in the Digital Humanities and thus make it interoperable with other resources in the CLARIN-D corpus infrastructure
9 Goals of the project (2) Create a showcase which demonstrates what researchers can gain when CMC corpora are made available for the community, CMC corpora as part of big, annotated corpus collections can be analyzed in combination with other language resources (text and speech corpora at IDS and BBAW) Why TEI? Therefore! Intended model character of the solutions developed in the project: solutions should be useful not only for the modeling and integration of the chat corpus but also for the modeling and integration of other CMC corpora into CLARIN-D (future projects)
10 Modeling CMC in TEI: The challenge Fundamental challenge: Written CMC shares characteristics both with text and spoken conversation... o Just like spoken conversation (and different from text), CMC is dialogic interaction in which each communivative move creates/changes the context for follow-up moves. o Just like text documents and different from spoken conversation, written CMC is organized through the exchange of stretches of written text which have completely been composed before they are transmitted and read. A basic model for the representation of user contributions to written CMC should reflect these properties.

11 CLARIN-D CMC SIG Schema ODD and RNG files:
12 CLARIN-D CMC-TEI Customisation: Introduction of specific models for CMC-specific concepts: e.g model.divpart.cmc, Definition of best practices for the use of standard TEI models (without modification; e.g. <div>, <participantlist>, <timeline>
13 The basic element for CMC: <post> Post: a stretch of text characterized by the following features: (1) produced to function as a contribution to an ongoing CMC interaction; (2) the process of verbalization is prior to (and finished before) the act of making it available for the addressees/interaction partners; (3) it is the largest unit of user generated content that is handed over to the technical system at once; (4) it is the atomic building block of CMC macrostructures (logfiles, threads, twitter timelines, ) Example from a social chat: A04: milkaq: wir kennten dich dann auch im Beiboot aussetzen A11: OK. Ich kann ja schwimmen. A02: KäptnMcMike holt ein Haustierchen aus der Kajüte
14 Example: posts in chat
15 model.divpart.cmc (HTML from ODD)
16 <post> declaration (HTML from ODD)
17 Extending the <post> model with attributes post metadata giving information that the researcher has reconstructed through interpretation and indicates to which previous post the current post replies or refers to. optional attribute which can be used for the annotation of thread structures
18 Extending the <post> model with attributes Posts which have been created not by a human participant of the interaction but by the system should be marked as automatically generated. The same holds for elements in the content of posts which have been automatically created, e.g. user signatures in posts on Wikipedia talk new attribute in att.global (type: data.xtruthvalue). marks whether the content of the respective element was automatically generated.
19 Best practices: Usage of available attributes <post auto="true" rend="color:blue" synch="#f t046" type="event" who="#f a01_system" xml:id="f m137"> <time> 22:01 </time> <name corresp="#f a04" type="nickname"> [_MALE-TEACHER-A04_]</name> entered the room <name type="roomname">[_roomname_]</name> at <time> 22:01:55 </time> </post>
20 Best practices: POS tags Inline annotation using <w> Tag set STTS-IBK (Beißwenger et al. 2015) <post auto="false" rend="color:black" synch="#f t047" type="standard" who="#f a03" xml:id="f m138"> <time> 22:02 </time> <anchor type="sentence_start"/> <w lemma="gut" type="adjd" xml:id="f m138.t1">gut</w> <w lemma="," type="$," xml:id="f m138.t2">,</w> <w lemma="die" type="pds" xml:id="f m138.t3">das</w> <w lemma="sollen" type="vmfin" xml:id="f m138.t4">sollte</w> [ ] </post>
21 Best practices: Chat metadata in <teiheader> We use <profiledesc>:<particdesc> for descriptions of the chat users this is in line with standardisation for speech corprora (ISO 24624, as of 2016) <profiledesc> <particdesc> <listperson> <person role="system" xml:id="f a01_system"> <persname type="nickname">system</persname> <sex evidence="estimated">system</sex> </person> <person role="expert" xml:id="f a02"> <persname type="nickname">[_male-expert- A02_]</persName> <sex evidence="estimated">male</sex>
22 Best practices: Chat metadata in <teiheader> Unlike in the standard for speech corpora, we put the <timeline> under <textdesc>:<interaction> In the timeline, absolute timepoints are recorded <textdesc> [ ] <interaction> <timeline> <when absolute="11:04:00" xml:id="f t001"/> <when absolute="11:11:00" xml:id="f t002"/> <when absolute="11:18:00" xml:id="f t003"/>
23 Best practices: Chat metadata in <teiheader> We used <recordingstmt> in <sourcedesc> for metadata about media (chat platform) <recordingstmt> <recording> <equipment> <p>plattformname=<name type="oth">[_chatplatform_]</name></p> <p>plattformurl=<ref type="url">[_wwwurl_]</ref></p> </equipment> [ ]
24 Result of the project: CLARIN-D-conformant resource Dortmund Chat corpus 2.0 # chat log files 470 # posts 131,033 # tokens 1,005,166 file Size (TEI-XML) 100MB

25 Availability of the integrated resource Integration in CLARIN-D repository at IDS: done Integration in CLARIN-D repository at BBAW: this week Downloadable only when full anonymisation is finished

26 Availability of the integrated resource To be integrated in the German Reference Corpus DeReKo at IDS and searchable through COSMAS II To be integrated in the DWDS corpus query interface at BBAW Will also be searchable via CLARIN web services and the CLARIN Federated Content Search
27 Summary and outlook (1) On the example of a schema developed for remodeling the Dortmund chat corpus we presented a rationale and selected models & best practices for the representation of CMC genres in TEI (based on models discussed and tested in the TEI-SIG computer-mediated communication ) Goal of this talk: Draw the attention of the TEI community the current state of the schemas developed by members of the SIG in order to ask for feedback, comments etc. on our ideas. Next milestone for the SIG: Submit a feature request on Github based on the schemas developed so far and the comments received from the community (feature requests planned for spring/summer 2017)
28 Summary and outlook (2): open issues How to encode <post>-specific meta data? In the project Chat2CLARIN, we chose to encode them using more and more attributes (regular and customised) <post auto="true" rend="color:blue" synch="#f t046" type="event" who="#f a01_system" xml:id="f m137"> [ ]
29 Summary and outlook (2): open issues How to encode <post>-specific meta data? However, you might alternatively want to encode them in a separate <postheader> in the <post>, containing e.g. feature structures <post auto="true" > <postheader> <fs> <f name= status"> <symbol value= delivered"/> </f> [ ]
30 Summary and outlook (2): open issues How to encode <post>-specific meta data? Or define <post> as a declaring element and point to post-specific metadata contained in declarable elements in the teiheader (cf. e.g. Stadler et al. 2016) <post auto="true decls= #correspdesc_01" > [ ]
31 Summary and outlook (3): Get in touch! Wiki page of the CMC-SIG with schemas (ODD & RNG), documentation of previous activities etc.: Mediated_Communication Google Group (for feedback, comments etc.): or in the SIG meeting right after the coffee break!

32 SIG meeting
33 Converting and Representing Social Media Corpora into TEI: Schema and Best Practices from CLARIN-D Thank you!
Integrating corpora of computer-mediated communication in CLARIN-D: Results from the curation project ChatCorpus2CLARIN
 Integrating corpora of computer-mediated communication in CLARIN-D: Results from the curation project ChatCorpus2CLARIN Harald Lüngen Institut für Deutsche Sprache luengen@ids-mannheim.de Michael Beißwenger
Integrating corpora of computer-mediated communication in CLARIN-D: Results from the curation project ChatCorpus2CLARIN Harald Lüngen Institut für Deutsche Sprache luengen@ids-mannheim.de Michael Beißwenger
A Discourse-structured Blog Corpus for German: Challenges of Compilation and Annotation
 A Discourse-structured Blog Corpus for German: Challenges of Compilation and Annotation Holger Grumt Suárez (D 410) 35394 Holger.H.Grumt- Suarez@ germanistik.unigiessen.de Natali Karlova-Bourbonus (D 406)
A Discourse-structured Blog Corpus for German: Challenges of Compilation and Annotation Holger Grumt Suárez (D 410) 35394 Holger.H.Grumt- Suarez@ germanistik.unigiessen.de Natali Karlova-Bourbonus (D 406)
<thread> <posting>... </posting> </thread> A TEI Schema for the Annotation of CMC Genres
 ... A TEI Schema for the Annotation of CMC Genres Michael Beißwenger, Maria Ermakova, Alexander Geyken, Lothar Lemnitzer, Angelika Storrer A TEI schema for the annotation
... A TEI Schema for the Annotation of CMC Genres Michael Beißwenger, Maria Ermakova, Alexander Geyken, Lothar Lemnitzer, Angelika Storrer A TEI schema for the annotation
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
Figure 0.1: RapidMiner user interface: import/export operators: reading and writing of data
 Software 1 Figure 0.1: RapidMiner user interface: This paper describes the software plugin Corpus Linguistic Plugin for RapdiMiner. We explain in detail the software and how it can be used to produce use
Software 1 Figure 0.1: RapidMiner user interface: This paper describes the software plugin Corpus Linguistic Plugin for RapdiMiner. We explain in detail the software and how it can be used to produce use
Néonaute: mining web archives for linguistic analysis
 Néonaute: mining web archives for linguistic analysis Sara Aubry, Bibliothèque nationale de France Emmanuel Cartier, LIPN, University of Paris 13 Peter Stirling, Bibliothèque nationale de France IIPC Web
Néonaute: mining web archives for linguistic analysis Sara Aubry, Bibliothèque nationale de France Emmanuel Cartier, LIPN, University of Paris 13 Peter Stirling, Bibliothèque nationale de France IIPC Web
How can CLARIN archive and curate my resources?
 How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
Sustainability of Text-Technological Resources
 Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
(Some) Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014
 Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014") (Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
(Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
Erhard Hinrichs, Thomas Zastrow University of Tübingen
 WebLicht A Service Oriented Architecture for Language Resources and Tools Erhard Hinrichs, Thomas Zastrow University of Tübingen Current Situation Many linguistic resources (corpora, dictionaries, ) and
WebLicht A Service Oriented Architecture for Language Resources and Tools Erhard Hinrichs, Thomas Zastrow University of Tübingen Current Situation Many linguistic resources (corpora, dictionaries, ) and
CLARIN for Linguists Portal & Searching for Resources. Jan Odijk LOT Summerschool Nijmegen,
 CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
Integrating TEI and EAD
 Integrating TEI and EAD Chris Turner LEADERS Project, School of Library, Archive and Information Studies, University College London Linking EAD to Electronically Developing a generic computer-based toolset
Integrating TEI and EAD Chris Turner LEADERS Project, School of Library, Archive and Information Studies, University College London Linking EAD to Electronically Developing a generic computer-based toolset
Contents. List of Figures. List of Tables. Acknowledgements
 Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
DIGITAL MARKETING For your Company
 DIGITAL MARKETING For your Company www.almada.co 1 About Us Established in 1998 with 8 developer team and 42 offshore team, a PCI DSS, ISO 27001, 9001 certified Data Center & service provider, a world-leading
DIGITAL MARKETING For your Company www.almada.co 1 About Us Established in 1998 with 8 developer team and 42 offshore team, a PCI DSS, ISO 27001, 9001 certified Data Center & service provider, a world-leading
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure
 WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
SharePoint 2013 End User Level II
 SharePoint 2013 End User Level II Course 55052A; 3 Days, Instructor-led Course Description This 3-day course explores several advanced topics of working with SharePoint 2013 sites. Topics include SharePoint
SharePoint 2013 End User Level II Course 55052A; 3 Days, Instructor-led Course Description This 3-day course explores several advanced topics of working with SharePoint 2013 sites. Topics include SharePoint
CORLI. a linguistic consortium for corpus, language and interaction
 CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
Formats and standards for metadata, coding and tagging. Paul Meurer
 Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
On the way to Language Resources sharing: principles, challenges, solutions
 On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
Implementation of the Data Seal of Approval
 Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Modeling Linguistic Research Data for a Repository for Historical Corpora. Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.
 Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
EUDAT. A European Collaborative Data Infrastructure. Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT
 EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
A Multilingual Social Media Linguistic Corpus
 A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
A Multilingual Social Media Linguistic Corpus Luis Rei 1,2 Dunja Mladenić 1,2 Simon Krek 1 1 Artificial Intelligence Laboratory Jožef Stefan Institute 2 Jožef Stefan International Postgraduate School 4th
Knowledge Hub Walkthrough
 Knowledge Hub Walkthrough Welcome page Sign in Use your Knowledge Hub account to sign in. Register Are you new to the Knowledge Hub, then please register a new account Forgotten Password? You will be asked
Knowledge Hub Walkthrough Welcome page Sign in Use your Knowledge Hub account to sign in. Register Are you new to the Knowledge Hub, then please register a new account Forgotten Password? You will be asked
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
SharePoint 2013 End User Level II
 Course 55052A: SharePoint 2013 End User Level II Course Details Course Outline Module 1: Overview A simple introduction module. Understand your course, classroom, classmates, facility and instructor. Module
Course 55052A: SharePoint 2013 End User Level II Course Details Course Outline Module 1: Overview A simple introduction module. Understand your course, classroom, classmates, facility and instructor. Module
Common Language Resources and Technology Infrastructure REVISED WEBSITE
 REVISED WEBSITE Responsible: Dan Cristea Contributing Partners: UAIC, FFGZ, DFKI, UIB/Unifob The ultimate objective of CLARIN is to create a European federation of existing digital repositories that include
REVISED WEBSITE Responsible: Dan Cristea Contributing Partners: UAIC, FFGZ, DFKI, UIB/Unifob The ultimate objective of CLARIN is to create a European federation of existing digital repositories that include
Utilising ANNIS for search and analysis of historical data
 Utilising ANNIS for search and analysis of historical data Stephan Druskat Thomas Krause Carolin Odebrecht Institut für deutsche Sprache und Linguistik Humboldt-Universität zu Berlin Reuse or New Development:
Utilising ANNIS for search and analysis of historical data Stephan Druskat Thomas Krause Carolin Odebrecht Institut für deutsche Sprache und Linguistik Humboldt-Universität zu Berlin Reuse or New Development:
verapdf: definitive, open source PDF/A validation for digital preservationists
 verapdf: definitive, open source PDF/A validation for digital preservationists Open Preservation Foundation PREFORMA Open Source Workshop 2016, Stockholm Presenters Joachim Jung, Open Preservation Foundation
verapdf: definitive, open source PDF/A validation for digital preservationists Open Preservation Foundation PREFORMA Open Source Workshop 2016, Stockholm Presenters Joachim Jung, Open Preservation Foundation
Conversion and Annotation Web Services for Spoken Language Data in CLARIN
 Conversion and Annotation Web Services for Spoken Language Data in CLARIN Thomas Schmidt Institute for the German Language (IDS) Mannheim thomas.schmidt@ ids-mannheim.de Hanna Hedeland Hamburg Centre for
Conversion and Annotation Web Services for Spoken Language Data in CLARIN Thomas Schmidt Institute for the German Language (IDS) Mannheim thomas.schmidt@ ids-mannheim.de Hanna Hedeland Hamburg Centre for
SocialMiner Configuration
 This section outlines the initial setup that must be performed when SocialMiner is first installed as well as the ongoing user-configurable options that can be used once the system is up and running. The
This section outlines the initial setup that must be performed when SocialMiner is first installed as well as the ongoing user-configurable options that can be used once the system is up and running. The
Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure
 Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure Twan Goosen 1 (CLARIN ERIC), Nuno Freire 2, Clemens Neudecker 3, Maria Eskevich
Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure Twan Goosen 1 (CLARIN ERIC), Nuno Freire 2, Clemens Neudecker 3, Maria Eskevich
Data Replication: Automated move and copy of data. PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013
 Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
Digital Messaging Center Feature List
 Digital Messaging Center Feature List Connecting Brands to Consumers Teradata Overview INTEGRATED DIGITAL MESSAGING Deliver Digital Messages with Personalized Precision Teradata s Digital Messaging Center
Digital Messaging Center Feature List Connecting Brands to Consumers Teradata Overview INTEGRATED DIGITAL MESSAGING Deliver Digital Messages with Personalized Precision Teradata s Digital Messaging Center
Data Exchange and Conversion Utilities and Tools (DExT)
") Data Exchange and Conversion Utilities and Tools (DExT) Louise Corti, Angad Bhat, Herve L Hours UK Data Archive CAQDAS Conference, April 2007 An exchange format for qualitative data Data exchange models
Data Exchange and Conversion Utilities and Tools (DExT) Louise Corti, Angad Bhat, Herve L Hours UK Data Archive CAQDAS Conference, April 2007 An exchange format for qualitative data Data exchange models
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE
 COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
COLLABORATIVE EUROPEAN DIGITAL ARCHIVE INFRASTRUCTURE Project Acronym: CENDARI Project Grant No.: 284432 Theme: FP7-INFRASTRUCTURES-2011-1 Project Start Date: 01 February 2012 Project End Date: 31 January
Information Retrieval
 Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Multimedia Computing: Algorithms, Systems, and Applications: Information Retrieval and Search Engine By Dr. Yu Cao Department of Computer Science The University of Massachusetts Lowell Lowell, MA 01854,
Cf. Gasch (2008), chapter 1.2 Generic and project-specific XML Schema design", p. 23 f. 5
, chapter 1.2 Generic and project-specific XML Schema design, p. 23 f. 5") DGD 2.0: A Web-based Navigation Platform for the Visualization, Presentation and Retrieval of German Speech Corpora 1. Introduction 1.1 The Collection of German Speech Corpora at the IDS The "Institut
DGD 2.0: A Web-based Navigation Platform for the Visualization, Presentation and Retrieval of German Speech Corpora 1. Introduction 1.1 The Collection of German Speech Corpora at the IDS The "Institut
Unit 3 Corpus markup
 Unit 3 Corpus markup 3.1 Introduction Data collected using a sampling frame as discussed in unit 2 forms a raw corpus. Yet such data typically needs to be processed before use. For example, spoken data
Unit 3 Corpus markup 3.1 Introduction Data collected using a sampling frame as discussed in unit 2 forms a raw corpus. Yet such data typically needs to be processed before use. For example, spoken data
UIMA-based Annotation Type System for a Text Mining Architecture
 UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
CLARIN s central infrastructure. Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna
 CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
EuroParl-UdS: Preserving and Extending Metadata in Parliamentary Debates
 EuroParl-UdS: Preserving and Extending Metadata in Parliamentary Debates Alina Karakanta, Mihaela Vela, Elke Teich Department of Language Science and Technology, Saarland University Outline Introduction
EuroParl-UdS: Preserving and Extending Metadata in Parliamentary Debates Alina Karakanta, Mihaela Vela, Elke Teich Department of Language Science and Technology, Saarland University Outline Introduction
7. METHODOLOGY FGDC metadata
 7. METHODOLOGY To enable an Internet browsing client to search and discover information through a federated metadatabase, four elements must be in place. 1. The client must be able to communicate with
7. METHODOLOGY To enable an Internet browsing client to search and discover information through a federated metadatabase, four elements must be in place. 1. The client must be able to communicate with
verapdf Industry supported PDF/A validation
 verapdf Industry supported PDF/A validation About this webinar What we ll be showing you: our current development status; the Consortium s development plans for 2016; how we ve been testing the software
verapdf Industry supported PDF/A validation About this webinar What we ll be showing you: our current development status; the Consortium s development plans for 2016; how we ve been testing the software
Technical and Financial Proposal SEO Proposal
 Technical and Financial Proposal SEO Proposal Prepared by: Fahim Khan Operations Manager Zaman IT Phone: +88 09612776677 Cell: +88 01973 009007 Email: Skype: masud007rana House # 63, Road # 13, Sector
Technical and Financial Proposal SEO Proposal Prepared by: Fahim Khan Operations Manager Zaman IT Phone: +88 09612776677 Cell: +88 01973 009007 Email: Skype: masud007rana House # 63, Road # 13, Sector
Page Title is one of the most important ranking factor. Every page on our site should have unique title preferably relevant to keyword.
 SEO can split into two categories as On-page SEO and Off-page SEO. On-Page SEO refers to all the things that we can do ON our website to rank higher, such as page titles, meta description, keyword, content,
SEO can split into two categories as On-page SEO and Off-page SEO. On-Page SEO refers to all the things that we can do ON our website to rank higher, such as page titles, meta description, keyword, content,
The Internet and World Wide Web. Chapter4
 The Internet and World Wide Web Chapter4 ITBIS105 IS-IT-UOB 2016 The Internet What is the Internet? Worldwide collection of millions of computers networks that connects ITBIS105 IS-IT-UOB 2016 2 History
The Internet and World Wide Web Chapter4 ITBIS105 IS-IT-UOB 2016 The Internet What is the Internet? Worldwide collection of millions of computers networks that connects ITBIS105 IS-IT-UOB 2016 2 History
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
This document is a preview generated by EVS
 INTERNATIONAL STANDARD ISO 24611 First edition 2012-11-01 Language resource management Morpho-syntactic annotation framework (MAF) Gestion des ressources langagières Cadre d'annotation morphosyntaxique
INTERNATIONAL STANDARD ISO 24611 First edition 2012-11-01 Language resource management Morpho-syntactic annotation framework (MAF) Gestion des ressources langagières Cadre d'annotation morphosyntaxique
Implementing a Variety of Linguistic Annotations
 Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
1. CONCEPTUAL MODEL 1.1 DOMAIN MODEL 1.2 UML DIAGRAM
 1 1. CONCEPTUAL MODEL 1.1 DOMAIN MODEL In the context of federation of repositories of Semantic Interoperability s, a number of entities are relevant. The primary entities to be described by ADMS are the
1 1. CONCEPTUAL MODEL 1.1 DOMAIN MODEL In the context of federation of repositories of Semantic Interoperability s, a number of entities are relevant. The primary entities to be described by ADMS are the
Lou Burnard Consulting
 Getting started with oxygen Lou Burnard Consulting 2014-06-21 1 Introducing oxygen In this first exercise we will use oxygen to : create a new XML document gradually add markup to the document carry out
Getting started with oxygen Lou Burnard Consulting 2014-06-21 1 Introducing oxygen In this first exercise we will use oxygen to : create a new XML document gradually add markup to the document carry out
Reflexive Community Information Systems
 Reflexive Community Information Systems RWTH University & Fraunhofer FIT I5-Jarke-0506-1 Three Facets of Enterprise Information Systems Human Work Practice Empower, E-Learning Human-Centered Computing
Reflexive Community Information Systems RWTH University & Fraunhofer FIT I5-Jarke-0506-1 Three Facets of Enterprise Information Systems Human Work Practice Empower, E-Learning Human-Centered Computing
Tools in Fronter, for student
 Tools in Fronter, for student This manual describes how to use the tools in Fronter and how to create content like news articles, folders and forums. Contents What tools are there in Fronter?... 3 Which
Tools in Fronter, for student This manual describes how to use the tools in Fronter and how to create content like news articles, folders and forums. Contents What tools are there in Fronter?... 3 Which
Text Encoding Fundamentals: Element list
 Text Encoding Fundamentals: Element list Elements for basic TEI documents This is more of a brief reference sheet than an exhaustive list of TEI elements: it is intended to provide you with a way to look
Text Encoding Fundamentals: Element list Elements for basic TEI documents This is more of a brief reference sheet than an exhaustive list of TEI elements: it is intended to provide you with a way to look
Gaggle 101 User Guide
 Gaggle 101 User Guide Home Tab The Home tab is the first page displayed upon login. Here you will see customized windows or widgets. Once set, the widgets can be accessed directly by clicking on them from
Gaggle 101 User Guide Home Tab The Home tab is the first page displayed upon login. Here you will see customized windows or widgets. Once set, the widgets can be accessed directly by clicking on them from
WhereScape RED Installation
 WhereScape RED Installation This document is intended for new WhereScape RED customers. It explains how to download RED, install license keys and obtain support if required. WhereScape RED is distributed
WhereScape RED Installation This document is intended for new WhereScape RED customers. It explains how to download RED, install license keys and obtain support if required. WhereScape RED is distributed
Metadata Workshop 3 March 2006 Part 1
 Metadata Workshop 3 March 2006 Part 1 Metadata overview and guidelines Amelia Breytenbach Ria Groenewald What metadata is Overview Types of metadata and their importance How metadata is stored, what metadata
Metadata Workshop 3 March 2006 Part 1 Metadata overview and guidelines Amelia Breytenbach Ria Groenewald What metadata is Overview Types of metadata and their importance How metadata is stored, what metadata
Introduction to Text Mining. Aris Xanthos - University of Lausanne
 Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen. WP5: Glossa Integration
 Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
 Glossary A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A App See Application Application An application (sometimes known as an app ) is a computer program which allows the user to perform a specific
Glossary A B C D E F G H I J K L M N O P Q R S T U V W X Y Z A App See Application Application An application (sometimes known as an app ) is a computer program which allows the user to perform a specific
To start work, go to Settings to create folders, file archives, forum and web pages.
 How to use the TwinSpace Each project has automatically its TwinSpace which can only be accessed by the members of the partnership and the people you decide to invite. You will find all the TwinSpaces
How to use the TwinSpace Each project has automatically its TwinSpace which can only be accessed by the members of the partnership and the people you decide to invite. You will find all the TwinSpaces
The Virtual Language Observatory!
 The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
Novell Vibe 3.4. Novell. July Quick Start. Starting Novell Vibe. Getting to Know the Novell Vibe Interface and Its Features
 Novell Vibe 3.4 July 2013 Novell Quick Start When you begin to use Novell Vibe, the first thing you might want to do is set up your personal workspace and create a team workspace. This document explains
Novell Vibe 3.4 July 2013 Novell Quick Start When you begin to use Novell Vibe, the first thing you might want to do is set up your personal workspace and create a team workspace. This document explains
CompuScholar, Inc. Alignment to Utah's Web Development I Standards
 Course Title: KidCoder: Web Design Course ISBN: 978-0-9887070-3-0 Course Year: 2015 CompuScholar, Inc. Alignment to Utah's Web Development I Standards Note: Citation(s) listed may represent a subset of
Course Title: KidCoder: Web Design Course ISBN: 978-0-9887070-3-0 Course Year: 2015 CompuScholar, Inc. Alignment to Utah's Web Development I Standards Note: Citation(s) listed may represent a subset of
The Road to 200,000 Downloads: The Cesium Story. Sarah
 The Road to 200,000 Downloads: The Cesium Story Sarah Chow @chowslc schow@agi.com What is Cesium? World-class 3D globes and maps in the browser Tile and host geospatial data with Cesium ion s simple workflow
The Road to 200,000 Downloads: The Cesium Story Sarah Chow @chowslc schow@agi.com What is Cesium? World-class 3D globes and maps in the browser Tile and host geospatial data with Cesium ion s simple workflow
SEXTANT 1. Purpose of the Application
 SEXTANT 1. Purpose of the Application Sextant has been used in the domains of Earth Observation and Environment by presenting its browsing and visualization capabilities using a number of link geospatial
SEXTANT 1. Purpose of the Application Sextant has been used in the domains of Earth Observation and Environment by presenting its browsing and visualization capabilities using a number of link geospatial
VisAssist Web Navigator
 VisAssist Web Navigator Software Requirements Specification Trevor Adams Nate Bomberger Tom Burdak Shawn Busolits Andrew Scott Matt Staniewicz Nate Vecchiarelli Contents Introduction... 4 Purpose... 4
VisAssist Web Navigator Software Requirements Specification Trevor Adams Nate Bomberger Tom Burdak Shawn Busolits Andrew Scott Matt Staniewicz Nate Vecchiarelli Contents Introduction... 4 Purpose... 4
Working towards a Metadata Federation of CLARIN and DARIAH-DE
 Working towards a Metadata Federation of CLARIN and DARIAH-DE Thomas Eckart Natural Language Processing Group University of Leipzig, Germany teckart@informatik.uni-leipzig.de Tobias Gradl Media Informatics
Working towards a Metadata Federation of CLARIN and DARIAH-DE Thomas Eckart Natural Language Processing Group University of Leipzig, Germany teckart@informatik.uni-leipzig.de Tobias Gradl Media Informatics
Traffic Triggers Domain Here.com
 www.your Domain Here.com - 1 - Table of Contents INTRODUCTION TO TRAFFIC TRIGGERS... 3 SEARCH ENGINE OPTIMIZATION... 4 PAY PER CLICK MARKETING... 6 SOCIAL MARKETING... 9 PRESS RELEASES... 11 ARTICLE MARKETING...
www.your Domain Here.com - 1 - Table of Contents INTRODUCTION TO TRAFFIC TRIGGERS... 3 SEARCH ENGINE OPTIMIZATION... 4 PAY PER CLICK MARKETING... 6 SOCIAL MARKETING... 9 PRESS RELEASES... 11 ARTICLE MARKETING...
Content Management Features & Benefits
 Content Publishing Features 01 Feedback Forms Use the drag-and-drop wizard to create feedback forms and then add them to your website. Responses are saved in your control panel and can be exported to Microsoft
Content Publishing Features 01 Feedback Forms Use the drag-and-drop wizard to create feedback forms and then add them to your website. Responses are saved in your control panel and can be exported to Microsoft
User s Guide Your Personal Profile and Settings Creating Professional Learning Communities
 User s Guide Your Personal Profile and Settings Creating Professional Learning Communities Table of Contents Page Welcome to the edweb 3 Your Personal Profile and Settings 4 Registration 4 Complete the
User s Guide Your Personal Profile and Settings Creating Professional Learning Communities Table of Contents Page Welcome to the edweb 3 Your Personal Profile and Settings 4 Registration 4 Complete the
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Introduction
 Introduction EuropeanaConnect All-Staff Meeting Berlin, May 10 12, 2010 Welcome to the All-Staff Meeting! Introduction This is a quite big meeting. This is the end of successful project year Project established
Introduction EuropeanaConnect All-Staff Meeting Berlin, May 10 12, 2010 Welcome to the All-Staff Meeting! Introduction This is a quite big meeting. This is the end of successful project year Project established
Melvyl Webinar UC and OCLC Roadmap Discussion
 Melvyl Webinar UC and OCLC Roadmap Discussion Leslie Wolf & Jeff Penka October 11, 2011 CDL Team Introduction Leslie Wolf, Melvyl Project Manager Ellen Meltzer, Information Services Manager Margery Tibbetts,
Melvyl Webinar UC and OCLC Roadmap Discussion Leslie Wolf & Jeff Penka October 11, 2011 CDL Team Introduction Leslie Wolf, Melvyl Project Manager Ellen Meltzer, Information Services Manager Margery Tibbetts,
What s new in SharePoint Search 2010 for end users. IW109 Mirjam van Olst
 What s new in SharePoint Search 2010 for end users IW109 Mirjam van Olst About Mirjam Microsoft Certified Master SharePoint 2007 MVP SharePoint Server SharePoint Architect at Macaw Co-organizer DIWUG and
What s new in SharePoint Search 2010 for end users IW109 Mirjam van Olst About Mirjam Microsoft Certified Master SharePoint 2007 MVP SharePoint Server SharePoint Architect at Macaw Co-organizer DIWUG and
Annotation Science From Theory to Practice and Use Introduction A bit of history
 Annotation Science From Theory to Practice and Use Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York 12604 USA ide@cs.vassar.edu Introduction Linguistically-annotated corpora
Annotation Science From Theory to Practice and Use Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York 12604 USA ide@cs.vassar.edu Introduction Linguistically-annotated corpora
C. M. Sperberg-McQueen Black Mesa Technologies LLC. Oliver Schonefeld Institut für Deutsche Sprache (IDS)
") Published in: Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). C. M. Sperberg-McQueen Black Mesa Technologies LLC
Published in: Proceedings of Balisage: The Markup Conference 2013. Balisage Series on Markup Technologies, vol. 10 (2013). C. M. Sperberg-McQueen Black Mesa Technologies LLC
Best practices in the design, creation and dissemination of speech corpora at The Language Archive
 LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
Comp 336/436 - Markup Languages. Fall Semester Week 2. Dr Nick Hayward
 Comp 336/436 - Markup Languages Fall Semester 2017 - Week 2 Dr Nick Hayward Digitisation - textual considerations comparable concerns with music in textual digitisation density of data is still a concern
Comp 336/436 - Markup Languages Fall Semester 2017 - Week 2 Dr Nick Hayward Digitisation - textual considerations comparable concerns with music in textual digitisation density of data is still a concern
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Towards a roadmap for standardization in language technology
 Towards a roadmap for standardization in language technology Laurent Romary & Nancy Ide Loria-INRIA Vassar College Overview General background on standardization Available standards On-going activities
Towards a roadmap for standardization in language technology Laurent Romary & Nancy Ide Loria-INRIA Vassar College Overview General background on standardization Available standards On-going activities
User Documentation. Studywiz Learning Environment. Student's Guide
 User Documentation Studywiz Learning Environment Student's Guide Studywiz Learning Environment Student's Guide Contents 1 Introduction 4 1.1 Studywiz 4 1.2 The Studywiz Student s Guide 4 2 What s New
User Documentation Studywiz Learning Environment Student's Guide Studywiz Learning Environment Student's Guide Contents 1 Introduction 4 1.1 Studywiz 4 1.2 The Studywiz Student s Guide 4 2 What s New
Automatic Transcription of Speech From Applied Research to the Market
 Think beyond the limits! Automatic Transcription of Speech From Applied Research to the Market Contact: Jimmy Kunzmann kunzmann@eml.org European Media Laboratory European Media Laboratory (founded 1997)
Think beyond the limits! Automatic Transcription of Speech From Applied Research to the Market Contact: Jimmy Kunzmann kunzmann@eml.org European Media Laboratory European Media Laboratory (founded 1997)
Types of Lesson Content
 Q U I CKSTART GUIDE Types of Lesson Content In Courses and Communities, you can add a variety of content. For example, videos, documents, tests, etc. 1 Navigate to 1-Courses/Communities > 2-Select Desired
Q U I CKSTART GUIDE Types of Lesson Content In Courses and Communities, you can add a variety of content. For example, videos, documents, tests, etc. 1 Navigate to 1-Courses/Communities > 2-Select Desired
A Repository of Metadata Crosswalks. Jean Godby, Devon Smith, Eric Childress, Jeffrey A. Young OCLC Online Computer Library Center Office of Research
 A Repository of Metadata Crosswalks Jean Godby, Devon Smith, Eric Childress, Jeffrey A. Young OCLC Online Computer Library Center Office of Research DLF-2004 Spring Forum April 21, 2004 Outline of this
A Repository of Metadata Crosswalks Jean Godby, Devon Smith, Eric Childress, Jeffrey A. Young OCLC Online Computer Library Center Office of Research DLF-2004 Spring Forum April 21, 2004 Outline of this
PDF statistics the universe of electronic documents
 PDF Days Europe 2018 PDF statistics the universe of electronic documents Duff Johnson of the A Presentation 2018 by 1 Introduction PDF is: Recognized worldwide Broadly adopted Accepted everywhere Supported
PDF Days Europe 2018 PDF statistics the universe of electronic documents Duff Johnson of the A Presentation 2018 by 1 Introduction PDF is: Recognized worldwide Broadly adopted Accepted everywhere Supported
Introducing IBM Lotus Sametime 7.5 software.
 Real-time collaboration solutions March 2006 Introducing IBM Lotus Sametime 7.5 software. Adam Gartenberg Offering Manager, Real-time and Team Collaboration Page 2 Contents 2 Introduction 3 Enhanced instant
Real-time collaboration solutions March 2006 Introducing IBM Lotus Sametime 7.5 software. Adam Gartenberg Offering Manager, Real-time and Team Collaboration Page 2 Contents 2 Introduction 3 Enhanced instant
An overview of the OAIS and Representation Information
 An overview of the OAIS and Representation Information JORUM, DCC and JISC Forum Long-term Curation and Preservation of Learning Objects February 9 th 2006 University of Glasgow Manjula Patel UKOLN and
An overview of the OAIS and Representation Information JORUM, DCC and JISC Forum Long-term Curation and Preservation of Learning Objects February 9 th 2006 University of Glasgow Manjula Patel UKOLN and
Institutional Repository using DSpace. Yatrik Patel Scientist D (CS)
") Institutional Repository using DSpace Yatrik Patel Scientist D (CS) yatrik@inflibnet.ac.in What is Institutional Repository? Institutional repositories [are]... digital collections capturing and preserving
Institutional Repository using DSpace Yatrik Patel Scientist D (CS) yatrik@inflibnet.ac.in What is Institutional Repository? Institutional repositories [are]... digital collections capturing and preserving
ICD Wiki Framework for Enabling Semantic Web Service Definition and Orchestration
 ICD Wiki Framework for Enabling Semantic Web Service Definition and Orchestration Dean Brown, Dominick Profico Lockheed Martin, IS&GS, Valley Forge, PA Abstract As Net-Centric enterprises grow, the desire
ICD Wiki Framework for Enabling Semantic Web Service Definition and Orchestration Dean Brown, Dominick Profico Lockheed Martin, IS&GS, Valley Forge, PA Abstract As Net-Centric enterprises grow, the desire
CONTENT CALENDAR USER GUIDE SOCIAL MEDIA TABLE OF CONTENTS. Introduction pg. 3
 TABLE OF CONTENTS SOCIAL MEDIA Introduction pg. 3 CONTENT 1 Chapter 1: What Is Historical Optimization? pg. 4 2 CALENDAR Chapter 2: Why Historical Optimization Is More Important Now Than Ever Before pg.
TABLE OF CONTENTS SOCIAL MEDIA Introduction pg. 3 CONTENT 1 Chapter 1: What Is Historical Optimization? pg. 4 2 CALENDAR Chapter 2: Why Historical Optimization Is More Important Now Than Ever Before pg.
Informatics 1: Data & Analysis
 Informatics 1: Data & Analysis Lecture 9: Trees and XML Ian Stark School of Informatics The University of Edinburgh Tuesday 11 February 2014 Semester 2 Week 5 http://www.inf.ed.ac.uk/teaching/courses/inf1/da
Informatics 1: Data & Analysis Lecture 9: Trees and XML Ian Stark School of Informatics The University of Edinburgh Tuesday 11 February 2014 Semester 2 Week 5 http://www.inf.ed.ac.uk/teaching/courses/inf1/da
SHARING GEOGRAPHIC INFORMATION ON THE INTERNET ICIMOD S METADATA/DATA SERVER SYSTEM USING ARCIMS
 SHARING GEOGRAPHIC INFORMATION ON THE INTERNET ICIMOD S METADATA/DATA SERVER SYSTEM USING ARCIMS Sushil Pandey* Birendra Bajracharya** *International Centre for Integrated Mountain Development (ICIMOD)
SHARING GEOGRAPHIC INFORMATION ON THE INTERNET ICIMOD S METADATA/DATA SERVER SYSTEM USING ARCIMS Sushil Pandey* Birendra Bajracharya** *International Centre for Integrated Mountain Development (ICIMOD)
ENCODING TEXTS FOR VISUALIZATION AND ANALYSES USING THE TEI STANDARD
 ENCODING TEXTS FOR VISUALIZATION AND ANALYSES USING THE TEI STANDARD William Chong http://dlinkup.com/workshops.html big D ata digitally R eady E ncoded A nalyzable M eaningful PRINCIPLES WORKSHOP ATTACK
ENCODING TEXTS FOR VISUALIZATION AND ANALYSES USING THE TEI STANDARD William Chong http://dlinkup.com/workshops.html big D ata digitally R eady E ncoded A nalyzable M eaningful PRINCIPLES WORKSHOP ATTACK
Online Communication. Chat Rooms Instant Messaging Blogging Social Media
 Online Communication E-mail Chat Rooms Instant Messaging Blogging Social Media Advantages: Reduces cost of postage Fast and convenient Eliminates phone charges Disadvantages: May be difficult to understand
Online Communication E-mail Chat Rooms Instant Messaging Blogging Social Media Advantages: Reduces cost of postage Fast and convenient Eliminates phone charges Disadvantages: May be difficult to understand
INDEPTH Network Introduction to NADA
 INDEPTH Network Introduction to NADA Sandeep Bhujbal ishare2 Support Team Outline What is Nada? Concepts of Nada. Why NADA for ishare2? INDEPTH Network NADA National Data Archive provided by the World
INDEPTH Network Introduction to NADA Sandeep Bhujbal ishare2 Support Team Outline What is Nada? Concepts of Nada. Why NADA for ishare2? INDEPTH Network NADA National Data Archive provided by the World
THE GREAT CONSOLIDATION: ENTERTAINMENT WEEKLY MIGRATION CASE STUDY JON PECK, MATT GRILL, PRESTON SO
 THE GREAT CONSOLIDATION: ENTERTAINMENT WEEKLY MIGRATION CASE STUDY JON PECK, MATT GRILL, PRESTON SO Slides: http://goo.gl/qji8kl WHO ARE WE? Jon Peck - drupal.org/u/fluxsauce Matt Grill - drupal.org/u/drpal
THE GREAT CONSOLIDATION: ENTERTAINMENT WEEKLY MIGRATION CASE STUDY JON PECK, MATT GRILL, PRESTON SO Slides: http://goo.gl/qji8kl WHO ARE WE? Jon Peck - drupal.org/u/fluxsauce Matt Grill - drupal.org/u/drpal