Corpus Acquisition from the Interwebs. Christian Buck, University of Edinburgh
|
|
|
- Lester Barrett
- 6 years ago
- Views:
Transcription
1 Corpus Acquisition from the Interwebs Christian Buck, University of Edinburgh

2 There is no data like more data (Bob Mercer, 1985)
3 Mining Bilingual Text "Same text in different languages" Usually: one side translation of the other Full page or interface/content only Potentially translation from same page Twitter, Facebook posts Human translation preferred Anything that improves BLEU









4
5

6
7

8

9 STRAND (Resnik, 1998, 1999, 2003) Structural Translation Recognition, Acquiring Natural Data
10 Pipeline 1. Candidate Generation 2. Candidate Ranking 3. Filtering 4. Optional: Sentence Alignment 5. Evaluation
11 STRAND: parent pages A page that links to different language versions English French Spanish x.com/en/cat.html x.com/fr/chat.html Require that links are close together
12 Example parent page

13 STRAND: sibling pages A page that links to itself in another language
14 Candidate Generation without links 1. Find and download multilingual sites 2. Find some URL pattern to generate candidate pairs xyz.com/en/ xyz.com/fr/ xyz.com/bla.htm xyz.com/bla.htm?lang=fr xyz.com/the_cat xyz.fr/le_chat
15 Generating language independent URLs Common key:
16 Grep ing for.*=en (with counts) lang=en lang=eng lng=en uil=english LANG=en ln=en hl=en Language=EN language=en lang=en tlng=en language=english l=en lang=engcro locale=en store=en langue=en
17 Grep ing for lang.*=.* (with counts) lang=en setlang=pt lang=fr ang=nl lang=de LANG=en lang=es setlang=de setlang=fr setlang=es lang=it language=en langue=fr language=fr setlang=it language=es setlang=sv language=de
18 Filtering Candidates: Length Extract texts and compare lengths (Smith 2001) Length(E) C * Length(F) learned, language-specific parameter Document- or sentence-level
19 Filtering Candidates: Structure
20 Filtering Candidates: Structure
21 Linearized Structure
22 Levenshtein Alignment
23 Levenshtein Alignment When does this break?
24 Variables characterizing alignment quality dp % inserted/deleted tokens n # aligned text chunks of unequal length r (Pearson) correlation of lengths of aligned text chunks p significance level of r
25 Beyond structure
26 Content Similarity NULL
27 Content Similarity NULL
28 Filtering with Features Idea: Learn good/bad decision rule Training data: Ask raters for content equivalence Positive examples easy Challenges: Representative negative examples? Class skew Evaluation metric
29 Experiments on Internet Archive 120TB / 10B pages reported in 2003 paper! Setup similar to MapReduce (2004) Map: For each URL generate language-independent URL Shuffle: Group identical language-independent URLs together Reduce: Match pairs, write parallel text Executed on 2 crawls of 8/12 TB Found ~8,300 EN-AR candidates After filtering: 1400 document pairs
30 Challenges Translations on other sites siemens.com vs. siemens-systems.de News reported by different outlets Machine Translation Too high scores look suspicious Partial Translations SEO (keywords in URLs)

31

32

33 Some industry approaches

34 Focused crawling Idea: Collect domain specific corpus by browsing Steps 1. Start with parallel page pair 2. Align structure 3. Follow the same link in both documents 4. Stop if new documents are not aligned
35 Dom tree alignment A DOM tree alignment model for mining parallel data from the Web Shi, Niu, Zhou, and Gao, Microsoft, ACL 2006 Key Idea: Find alignment of nodes such that: If (parent) nodes A and B are aligned then Children are also aligned (or deleted) No reordering of children
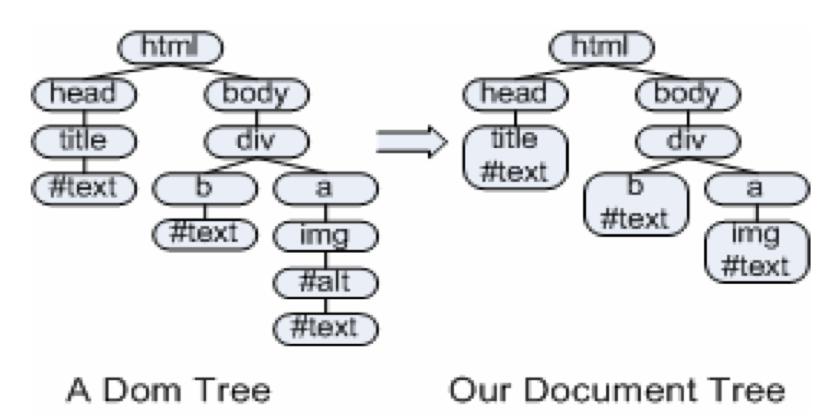
36 DOM simplification
37 DOM Alignment Model Similar to synchronous tree substitution grammar (Hajic, 2004): Support deletion / insertion / substitution No reordering of children Search for best alignment using DP Parameters: Text-translation probabilities: Tag-mapping probabilities, e.g. Node deletion probability

38
39
40


41 What Google does (or did in 2010) For each non-english document: 1. Translate document into English using MT 2. Google it 3. Profit New task: Cross-lingual near duplicate detection
 b. used for matching only 2.")
42 Near duplicate candidates 1. Find distinctive ngrams: a. rare, but not too rare (5-grams) b. used for matching only 2. Build inverted index: n-gram -> documents
43 N-gram* to document index [cat sat on] -> {[doc_1, ES], [doc_3, DE], } [on the mat] -> {[doc_1, ES], [doc_2, ES], } [on the table] -> {[doc_3, DE]} * Here: 3-grams, actually 5-grams
44 Matching using inverted index [cat sat on] -> {[doc_1, ES], [doc_3, DE], } [on the mat] -> {[doc_1, ES], [doc_2, ES], } [on the table] -> {[doc_3, DE]} For each n-gram: Generate all pairs where: document list short (<= 50) source language different {[doc_1, doc_3],...}
45 Scoring using forward index Forward index maps documents to n-grams n = 2 for higher recall For each document pair [d_1, d_2]: Collect scoring n-grams for both documents Build IDF-weighted vector Distance: cosine similarity

46 Conclusion General pipeline: Find pairs Within a single site / All over the Web URL restrictions IR methods Extract features Structural similarity Content similarity Metadata Score pairs
47 Reading Material Uszkoreit et al: Large Scale Parallel Document Mining for Machine Translation, 2010 Resnik and Smith: The Web as a Parallel Corpus, 2003 Shi et al: A DOM tree alignment model for mining parallel data from the Web, 2006
Corpus Acquisition from the Internet
 Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Corpus Acquisition from the Internet Philipp Koehn partially based on slides from Christian Buck 26 October 2017 Big Data 1 For many language pairs, lots of text available. Text you read in your lifetime
Finding parallel texts on the web using cross-language information retrieval
 Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
Finding parallel texts on the web using cross-language information retrieval Achim Ruopp University of Washington, Seattle, WA 98195, USA achimr@u.washington.edu Fei Xia University of Washington Seattle,
Ranked Retrieval. Evaluation in IR. One option is to average the precision scores at discrete. points on the ROC curve But which points?
 Ranked Retrieval One option is to average the precision scores at discrete Precision 100% 0% More junk 100% Everything points on the ROC curve But which points? Recall We want to evaluate the system, not
Ranked Retrieval One option is to average the precision scores at discrete Precision 100% 0% More junk 100% Everything points on the ROC curve But which points? Recall We want to evaluate the system, not
WebMining: An unsupervised parallel corpora web retrieval system
 WebMining: An unsupervised parallel corpora web retrieval system Jesús Tomás Instituto Tecnológico de Informática Universidad Politécnica de Valencia jtomas@upv.es Jaime Lloret Dpto. de Comunicaciones
WebMining: An unsupervised parallel corpora web retrieval system Jesús Tomás Instituto Tecnológico de Informática Universidad Politécnica de Valencia jtomas@upv.es Jaime Lloret Dpto. de Comunicaciones
An Iterative Link-based Method for Parallel Web Page Mining
 An Iterative Link-based Method for Parallel Web Page Mining Le Liu 1, Yu Hong 1*, Jun Lu 2, Jun Lang 2, Heng Ji 3, Jianmin Yao 1 1 School of Computer Science & Technology, Soochow University, Suzhou, 215006,
An Iterative Link-based Method for Parallel Web Page Mining Le Liu 1, Yu Hong 1*, Jun Lu 2, Jun Lang 2, Heng Ji 3, Jianmin Yao 1 1 School of Computer Science & Technology, Soochow University, Suzhou, 215006,
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval
 Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Basic Tokenizing, Indexing, and Implementation of Vector-Space Retrieval 1 Naïve Implementation Convert all documents in collection D to tf-idf weighted vectors, d j, for keyword vocabulary V. Convert
Outline. Possible solutions. The basic problem. How? How? Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity
 Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Outline Relevance Feedback, Query Expansion, and Inputs to Ranking Beyond Similarity Lecture 10 CS 410/510 Information Retrieval on the Internet Query reformulation Sources of relevance for feedback Using
Deliverable D Multilingual corpus acquisition software
 This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad).This project has received funding from the European
This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad).This project has received funding from the European
Training a Super Model Look-Alike:Featuring Edit Distance, N-Gram Occurrence,and One Reference Translation p.1/40
 Training a Super Model Look-Alike: Featuring Edit Distance, N-Gram Occurrence, and One Reference Translation Eva Forsbom, Uppsala University evafo@stp.ling.uu.se MT Summit IX Workshop on Machine Translation
Training a Super Model Look-Alike: Featuring Edit Distance, N-Gram Occurrence, and One Reference Translation Eva Forsbom, Uppsala University evafo@stp.ling.uu.se MT Summit IX Workshop on Machine Translation
Relevance Feedback and Query Reformulation. Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price. Outline
 Relevance Feedback and Query Reformulation Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price IR on the Internet, Spring 2010 1 Outline Query reformulation Sources of relevance
Relevance Feedback and Query Reformulation Lecture 10 CS 510 Information Retrieval on the Internet Thanks to Susan Price IR on the Internet, Spring 2010 1 Outline Query reformulation Sources of relevance
Mining Parallel Documents Using Low Bandwidth and High Precision CLIR from the Heterogeneous Web
 Mining Parallel Documents Using Low Bandwidth and High Precision CLIR from the Heterogeneous Web Simon Shi 1, Pascale Fung 1, Emmanuel Prochasson 2, Chi-kiu Lo 1 and Dekai Wu 1 1 Human Language Technology
Mining Parallel Documents Using Low Bandwidth and High Precision CLIR from the Heterogeneous Web Simon Shi 1, Pascale Fung 1, Emmanuel Prochasson 2, Chi-kiu Lo 1 and Dekai Wu 1 1 Human Language Technology
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence!
 James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
James Mayfield! The Johns Hopkins University Applied Physics Laboratory The Human Language Technology Center of Excellence! (301) 219-4649 james.mayfield@jhuapl.edu What is Information Retrieval? Evaluation
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information
 Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Ngram Search Engine with Patterns Combining Token, POS, Chunk and NE Information Satoshi Sekine Computer Science Department New York University sekine@cs.nyu.edu Kapil Dalwani Computer Science Department
Large Scale Parallel Document Mining for Machine Translation
 Large Scale Parallel Document Mining for Machine Translation Jakob Uszkoreit Jay M. Ponte Ashok C. Popat Moshe Dubiner Google, Inc. {uszkoreit,ponte,popat,moshe}@google.com Abstract A distributed system
Large Scale Parallel Document Mining for Machine Translation Jakob Uszkoreit Jay M. Ponte Ashok C. Popat Moshe Dubiner Google, Inc. {uszkoreit,ponte,popat,moshe}@google.com Abstract A distributed system
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Information Retrieval. (M&S Ch 15)
") Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Information Retrieval (M&S Ch 15) 1 Retrieval Models A retrieval model specifies the details of: Document representation Query representation Retrieval function Determines a notion of relevance. Notion
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 6: Similar Item Detection Jimmy Lin University of Maryland Thursday, February 28, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 6: Similar Item Detection Jimmy Lin University of Maryland Thursday, February 28, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
RLAT Rapid Language Adaptation Toolkit
 RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
NTT SMT System for IWSLT Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs.
 NTT SMT System for IWSLT 2008 Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs., Japan Overview 2-stage translation system k-best translation
NTT SMT System for IWSLT 2008 Katsuhito Sudoh, Taro Watanabe, Jun Suzuki, Hajime Tsukada, and Hideki Isozaki NTT Communication Science Labs., Japan Overview 2-stage translation system k-best translation
CS54701: Information Retrieval
 CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
CS54701: Information Retrieval Basic Concepts 19 January 2016 Prof. Chris Clifton 1 Text Representation: Process of Indexing Remove Stopword, Stemming, Phrase Extraction etc Document Parser Extract useful
First Steps Towards Coverage-Based Document Alignment
 First Steps Towards Coverage-Based Document Alignment Luís Gomes 1, Gabriel Pereira Lopes 1, 1 NOVA LINCS, Faculdade de Ciências e Tecnologia, Universidade Nova de Lisboa, Portugal ISTRION BOX, Translation
First Steps Towards Coverage-Based Document Alignment Luís Gomes 1, Gabriel Pereira Lopes 1, 1 NOVA LINCS, Faculdade de Ciências e Tecnologia, Universidade Nova de Lisboa, Portugal ISTRION BOX, Translation
An Unsupervised Model for Joint Phrase Alignment and Extraction
 An Unsupervised Model for Joint Phrase Alignment and Extraction Graham Neubig 1,2, Taro Watanabe 2, Eiichiro Sumita 2, Shinsuke Mori 1, Tatsuya Kawahara 1 1 Graduate School of Informatics, Kyoto University
An Unsupervised Model for Joint Phrase Alignment and Extraction Graham Neubig 1,2, Taro Watanabe 2, Eiichiro Sumita 2, Shinsuke Mori 1, Tatsuya Kawahara 1 1 Graduate School of Informatics, Kyoto University
Natural Language Processing
 Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Natural Language Processing Information Retrieval Potsdam, 14 June 2012 Saeedeh Momtazi Information Systems Group based on the slides of the course book Outline 2 1 Introduction 2 Indexing Block Document
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Creating a Classifier for a Focused Web Crawler
 Creating a Classifier for a Focused Web Crawler Nathan Moeller December 16, 2015 1 Abstract With the increasing size of the web, it can be hard to find high quality content with traditional search engines.
Creating a Classifier for a Focused Web Crawler Nathan Moeller December 16, 2015 1 Abstract With the increasing size of the web, it can be hard to find high quality content with traditional search engines.
Basic techniques. Text processing; term weighting; vector space model; inverted index; Web Search
 Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Basic techniques Text processing; term weighting; vector space model; inverted index; Web Search Overview Indexes Query Indexing Ranking Results Application Documents User Information analysis Query processing
Fractional Similarity : Cross-lingual Feature Selection for Search
 : Cross-lingual Feature Selection for Search Jagadeesh Jagarlamudi University of Maryland, College Park, USA Joint work with Paul N. Bennett Microsoft Research, Redmond, USA Using All the Data Existing
: Cross-lingual Feature Selection for Search Jagadeesh Jagarlamudi University of Maryland, College Park, USA Joint work with Paul N. Bennett Microsoft Research, Redmond, USA Using All the Data Existing
CSE 494: Information Retrieval, Mining and Integration on the Internet
 CSE 494: Information Retrieval, Mining and Integration on the Internet Midterm. 18 th Oct 2011 (Instructor: Subbarao Kambhampati) In-class Duration: Duration of the class 1hr 15min (75min) Total points:
CSE 494: Information Retrieval, Mining and Integration on the Internet Midterm. 18 th Oct 2011 (Instructor: Subbarao Kambhampati) In-class Duration: Duration of the class 1hr 15min (75min) Total points:
Information Retrieval
 Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2014 Information Retrieval Dr. Mariana Neves June 18th, 2014 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
University of Virginia Department of Computer Science. CS 4501: Information Retrieval Fall 2015
 University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
University of Virginia Department of Computer Science CS 4501: Information Retrieval Fall 2015 5:00pm-6:15pm, Monday, October 26th Name: ComputingID: This is a closed book and closed notes exam. No electronic
Machine Translation Research in META-NET
 Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS. Jan Tore Lønning, Lecture 8, 12 Oct
 1 INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS Jan Tore Lønning, Lecture 8, 12 Oct. 2016 jtl@ifi.uio.no Today 2 Preparing bitext Parameter tuning Reranking Some linguistic issues STMT so far 3 We
1 INF5820/INF9820 LANGUAGE TECHNOLOGICAL APPLICATIONS Jan Tore Lønning, Lecture 8, 12 Oct. 2016 jtl@ifi.uio.no Today 2 Preparing bitext Parameter tuning Reranking Some linguistic issues STMT so far 3 We
Marcello Federico MMT Srl / FBK Trento, Italy
 Marcello Federico MMT Srl / FBK Trento, Italy Proceedings for AMTA 2018 Workshop: Translation Quality Estimation and Automatic Post-Editing Boston, March 21, 2018 Page 207 Symbiotic Human and Machine Translation
Marcello Federico MMT Srl / FBK Trento, Italy Proceedings for AMTA 2018 Workshop: Translation Quality Estimation and Automatic Post-Editing Boston, March 21, 2018 Page 207 Symbiotic Human and Machine Translation
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
CLEF 2017 Microblog Cultural Contextualization Lab Overview
 CLEF 2017 Microblog Cultural Contextualization Lab Overview Liana Ermakova, Lorraine Goeuriot, Josiane Mothe, Philippe Mulhem, Jian-Yun Nie, Eric SanJuan Avignon, Grenoble, Lorraine and Montréal Universities
CLEF 2017 Microblog Cultural Contextualization Lab Overview Liana Ermakova, Lorraine Goeuriot, Josiane Mothe, Philippe Mulhem, Jian-Yun Nie, Eric SanJuan Avignon, Grenoble, Lorraine and Montréal Universities
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
How SPICE Language Modeling Works
 How SPICE Language Modeling Works Abstract Enhancement of the Language Model is a first step towards enhancing the performance of an Automatic Speech Recognition system. This report describes an integrated
How SPICE Language Modeling Works Abstract Enhancement of the Language Model is a first step towards enhancing the performance of an Automatic Speech Recognition system. This report describes an integrated
Sparse Feature Learning
 Sparse Feature Learning Philipp Koehn 1 March 2016 Multiple Component Models 1 Translation Model Language Model Reordering Model Component Weights 2 Language Model.05 Translation Model.26.04.19.1 Reordering
Sparse Feature Learning Philipp Koehn 1 March 2016 Multiple Component Models 1 Translation Model Language Model Reordering Model Component Weights 2 Language Model.05 Translation Model.26.04.19.1 Reordering
Google Marketing Boot Camp
 Google Marketing Boot Camp MKTG01; 3 Days, Instructor-led Course Description This Google training course will give you the knowledge and experience necessary to transform into a highly qualified online
Google Marketing Boot Camp MKTG01; 3 Days, Instructor-led Course Description This Google training course will give you the knowledge and experience necessary to transform into a highly qualified online
Normalizing Social Media Texts by Combining Word Embeddings and Edit Distances in a Random Forest Regressor
 Normalizing Social Media Texts by Combining Word Embeddings and Edit Distances in a Random Forest Regressor Rob van der Goot r.van.der.goot@rug.nl 28-05-2016 Rob van der Goot r.van.der.goot@rug.nl 28-05-2016
Normalizing Social Media Texts by Combining Word Embeddings and Edit Distances in a Random Forest Regressor Rob van der Goot r.van.der.goot@rug.nl 28-05-2016 Rob van der Goot r.van.der.goot@rug.nl 28-05-2016
Improving Synoptic Querying for Source Retrieval
 Improving Synoptic Querying for Source Retrieval Notebook for PAN at CLEF 2015 Šimon Suchomel and Michal Brandejs Faculty of Informatics, Masaryk University {suchomel,brandejs}@fi.muni.cz Abstract Source
Improving Synoptic Querying for Source Retrieval Notebook for PAN at CLEF 2015 Šimon Suchomel and Michal Brandejs Faculty of Informatics, Masaryk University {suchomel,brandejs}@fi.muni.cz Abstract Source
CS371R: Final Exam Dec. 18, 2017
 CS371R: Final Exam Dec. 18, 2017 NAME: This exam has 11 problems and 16 pages. Before beginning, be sure your exam is complete. In order to maximize your chance of getting partial credit, show all of your
CS371R: Final Exam Dec. 18, 2017 NAME: This exam has 11 problems and 16 pages. Before beginning, be sure your exam is complete. In order to maximize your chance of getting partial credit, show all of your
Exam IST 441 Spring 2011
 Exam IST 441 Spring 2011 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Exam IST 441 Spring 2011 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Search Engine Architecture. Hongning Wang
 Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine
Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine
Information Retrieval
 Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Natural Language Processing SoSe 2015 Information Retrieval Dr. Mariana Neves June 22nd, 2015 (based on the slides of Dr. Saeedeh Momtazi) Outline Introduction Indexing Block 2 Document Crawling Text Processing
Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _
 COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
Flynax SEO Guide Flynax
 Flynax SEO Guide Flynax 2018 1 Ì ÌFlynax SEO Guide Due to the fact that every project has its own purpose, audience and location preferences, it is almost impossible to make the script that will meet SEO
Flynax SEO Guide Flynax 2018 1 Ì ÌFlynax SEO Guide Due to the fact that every project has its own purpose, audience and location preferences, it is almost impossible to make the script that will meet SEO
Exam IST 441 Spring 2014
 Exam IST 441 Spring 2014 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Exam IST 441 Spring 2014 Last name: Student ID: First name: I acknowledge and accept the University Policies and the Course Policies on Academic Integrity This 100 point exam determines 30% of your grade.
Full-Text Indexing For Heritrix
 Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Top-To-Bottom (And Beyond) On-Page Optimization Guidebook
 On-Page Optimization Guidebook") SEOPressor Connect Presents: Top-To-Bottom (And Beyond) On-Page Optimization Guidebook Copyright 2017 SEOPressor Connect All Rights Reserved 2 If you re looking for a guideline how to optimize your SEO
SEOPressor Connect Presents: Top-To-Bottom (And Beyond) On-Page Optimization Guidebook Copyright 2017 SEOPressor Connect All Rights Reserved 2 If you re looking for a guideline how to optimize your SEO
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Instructor: Stefan Savev
 LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
LECTURE 2 What is indexing? Indexing is the process of extracting features (such as word counts) from the documents (in other words: preprocessing the documents). The process ends with putting the information
Querying Introduction to Information Retrieval INF 141 Donald J. Patterson. Content adapted from Hinrich Schütze
 Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Boolean Retrieval Weighted Boolean Retrieval Zone Indices
Introduction to Information Retrieval INF 141 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Overview Boolean Retrieval Weighted Boolean Retrieval Zone Indices
CROSS LANGUAGE INFORMATION ACCESS IN TELUGU
 CROSS LANGUAGE INFORMATION ACCESS IN TELUGU by Vasudeva Varma, Aditya Mogadala Mogadala, V. Srikanth Reddy, Ram Bhupal Reddy in Siliconandhrconference (Global Internet forum for Telugu) Report No: IIIT/TR/2011/-1
CROSS LANGUAGE INFORMATION ACCESS IN TELUGU by Vasudeva Varma, Aditya Mogadala Mogadala, V. Srikanth Reddy, Ram Bhupal Reddy in Siliconandhrconference (Global Internet forum for Telugu) Report No: IIIT/TR/2011/-1
OnCrawl Metrics. What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for.
 1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
1 OnCrawl Metrics What SEO indicators do we analyze for you? Dig into our board of metrics to find the one you are looking for. UNLEASH YOUR SEO POTENTIAL Table of content 01 Crawl Analysis 02 Logs Monitoring
CLEF-IP 2009: Exploring Standard IR Techniques on Patent Retrieval
 DCU @ CLEF-IP 2009: Exploring Standard IR Techniques on Patent Retrieval Walid Magdy, Johannes Leveling, Gareth J.F. Jones Centre for Next Generation Localization School of Computing Dublin City University,
DCU @ CLEF-IP 2009: Exploring Standard IR Techniques on Patent Retrieval Walid Magdy, Johannes Leveling, Gareth J.F. Jones Centre for Next Generation Localization School of Computing Dublin City University,
Same-language MT for local flavours/flavors
 Same-language MT for local flavours/flavors Janice Campbell - Adobe Gema Ramírez - Prompsit Proceedings of AMTA 2018, vol. 2: MT Users' Track Boston, March 17-21, 2018 Page 35 Intro: brief history of AltLang
Same-language MT for local flavours/flavors Janice Campbell - Adobe Gema Ramírez - Prompsit Proceedings of AMTA 2018, vol. 2: MT Users' Track Boston, March 17-21, 2018 Page 35 Intro: brief history of AltLang
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Internet Search. (COSC 488) Nazli Goharian Nazli Goharian, 2005, Outline
 Nazli Goharian Nazli Goharian, 2005, Outline") Internet Search (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Nazli Goharian, 2005, 2012 1 Outline Web: Indexing & Efficiency Partitioned Indexing Index Tiering & other early termination techniques
Internet Search (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Nazli Goharian, 2005, 2012 1 Outline Web: Indexing & Efficiency Partitioned Indexing Index Tiering & other early termination techniques
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
A Novel Method for Bilingual Web Page Acquisition from Search Engine Web Records
 A Novel Method for Bilingual Web Page Acquisition from Search Engine Web Records Yanhui Feng, Yu Hong, Zhenxiang Yan, Jianmin Yao, Qiaoming Zhu School of Computer Science & Technology, Soochow University
A Novel Method for Bilingual Web Page Acquisition from Search Engine Web Records Yanhui Feng, Yu Hong, Zhenxiang Yan, Jianmin Yao, Qiaoming Zhu School of Computer Science & Technology, Soochow University
Chapter 4. Processing Text
 Chapter 4 Processing Text Processing Text Modifying/Converting documents to index terms Convert the many forms of words into more consistent index terms that represent the content of a document What are
Chapter 4 Processing Text Processing Text Modifying/Converting documents to index terms Convert the many forms of words into more consistent index terms that represent the content of a document What are
3 Publishing Technique
 Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
D6.1.2: Second report on scientific evaluations
 D6.1.2: Second report on scientific evaluations UPVLC, XEROX, JSI-K4A, RWTH, EML and DDS Distribution: Public translectures Transcription and Translation of Video Lectures ICT Project 287755 Deliverable
D6.1.2: Second report on scientific evaluations UPVLC, XEROX, JSI-K4A, RWTH, EML and DDS Distribution: Public translectures Transcription and Translation of Video Lectures ICT Project 287755 Deliverable
Introduction to Text Mining. Hongning Wang
 Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Introduction to Text Mining Hongning Wang CS@UVa Who Am I? Hongning Wang Assistant professor in CS@UVa since August 2014 Research areas Information retrieval Data mining Machine learning CS@UVa CS6501:
Learn how to login to Sitefinity and what possible errors you can get if you do not have proper permissions.
 USER GUIDE This guide is intended for users of all levels of expertise. The guide describes in detail Sitefinity user interface - from logging to completing a project. Use it to learn how to create pages
USER GUIDE This guide is intended for users of all levels of expertise. The guide describes in detail Sitefinity user interface - from logging to completing a project. Use it to learn how to create pages
Data Analytics Framework and Methodology for WhatsApp Chats
 Data Analytics Framework and Methodology for WhatsApp Chats Transliteration of Thanglish and Short WhatsApp Messages P. Sudhandradevi Department of Computer Applications Bharathiar University Coimbatore,
Data Analytics Framework and Methodology for WhatsApp Chats Transliteration of Thanglish and Short WhatsApp Messages P. Sudhandradevi Department of Computer Applications Bharathiar University Coimbatore,
How to Add Categories and Subcategories to WordPress
 How to Add Categories and Subcategories to WordPress WordPress comes with the ability to sort your content into categories, tags, and taxonomies. One of the major differences between categories and tags
How to Add Categories and Subcategories to WordPress WordPress comes with the ability to sort your content into categories, tags, and taxonomies. One of the major differences between categories and tags
A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation.
 A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation May 29, 2003 Shankar Kumar and Bill Byrne Center for Language and Speech Processing
A Weighted Finite State Transducer Implementation of the Alignment Template Model for Statistical Machine Translation May 29, 2003 Shankar Kumar and Bill Byrne Center for Language and Speech Processing
Web Search Ranking. (COSC 488) Nazli Goharian Evaluation of Web Search Engines: High Precision Search
 Nazli Goharian Evaluation of Web Search Engines: High Precision Search") Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
Web Search Ranking (COSC 488) Nazli Goharian nazli@cs.georgetown.edu 1 Evaluation of Web Search Engines: High Precision Search Traditional IR systems are evaluated based on precision and recall. Web search
An efficient and user-friendly tool for machine translation quality estimation
 An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
An efficient and user-friendly tool for machine translation quality estimation Kashif Shah, Marco Turchi, Lucia Specia Department of Computer Science, University of Sheffield, UK {kashif.shah,l.specia}@sheffield.ac.uk
Semantic Estimation for Texts in Software Engineering
 Semantic Estimation for Texts in Software Engineering 汇报人 : Reporter:Xiaochen Li Dalian University of Technology, China 大连理工大学 2016 年 11 月 29 日 Oscar Lab 2 Ph.D. candidate at OSCAR Lab, in Dalian University
Semantic Estimation for Texts in Software Engineering 汇报人 : Reporter:Xiaochen Li Dalian University of Technology, China 大连理工大学 2016 年 11 月 29 日 Oscar Lab 2 Ph.D. candidate at OSCAR Lab, in Dalian University
GUI Translation HOWTO
 GUI Translation HOWTO GUI Translation HOWTO ii December 17, 2016 GUI Translation HOWTO iii Contents 1 Needed files and tools 2 1.1 Download PoEdit................................................... 2 1.2
GUI Translation HOWTO GUI Translation HOWTO ii December 17, 2016 GUI Translation HOWTO iii Contents 1 Needed files and tools 2 1.1 Download PoEdit................................................... 2 1.2
A General-Purpose Rule Extractor for SCFG-Based Machine Translation
 A General-Purpose Rule Extractor for SCFG-Based Machine Translation Greg Hanneman, Michelle Burroughs, and Alon Lavie Language Technologies Institute Carnegie Mellon University Fifth Workshop on Syntax
A General-Purpose Rule Extractor for SCFG-Based Machine Translation Greg Hanneman, Michelle Burroughs, and Alon Lavie Language Technologies Institute Carnegie Mellon University Fifth Workshop on Syntax
WordNet-based User Profiles for Semantic Personalization
 PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
PIA 2005 Workshop on New Technologies for Personalized Information Access WordNet-based User Profiles for Semantic Personalization Giovanni Semeraro, Marco Degemmis, Pasquale Lops, Ignazio Palmisano LACAM
Crawling Back and Forth: Using Back and Out Links to Locate Bilingual Sites
 Crawling Back and Forth: Using Back and Out Links to Locate Bilingual Sites Luciano Barbosa AT&T Labs Research 180 Park Ave Florham Park, NJ 07932 lbarbosa@research.att.com Srinivas Bangalore AT&T Labs
Crawling Back and Forth: Using Back and Out Links to Locate Bilingual Sites Luciano Barbosa AT&T Labs Research 180 Park Ave Florham Park, NJ 07932 lbarbosa@research.att.com Srinivas Bangalore AT&T Labs
Search Engines Information Retrieval in Practice
 Search Engines Information Retrieval in Practice W. BRUCE CROFT University of Massachusetts, Amherst DONALD METZLER Yahoo! Research TREVOR STROHMAN Google Inc. ----- PEARSON Boston Columbus Indianapolis
Search Engines Information Retrieval in Practice W. BRUCE CROFT University of Massachusetts, Amherst DONALD METZLER Yahoo! Research TREVOR STROHMAN Google Inc. ----- PEARSON Boston Columbus Indianapolis
The Late Night Blog Post SEO Checklist
 The Late Night Blog Post SEO Checklist ü Do you know what keywords your post is targeting? When you write a blog post, you need to know WHY you are writing it. What action do you want the reader to take?
The Late Night Blog Post SEO Checklist ü Do you know what keywords your post is targeting? When you write a blog post, you need to know WHY you are writing it. What action do you want the reader to take?
Search Engine Optimization & Web Analytics SHOP LOCAL RALEIGH TECH TUESDAY
 Search Engine Optimization & Web Analytics SHOP LOCAL RALEIGH TECH TUESDAY Jonathan Kamin Owner, Preferred Digital Solutions What is Digital Marketing? Digital marketing is the marketing of products or
Search Engine Optimization & Web Analytics SHOP LOCAL RALEIGH TECH TUESDAY Jonathan Kamin Owner, Preferred Digital Solutions What is Digital Marketing? Digital marketing is the marketing of products or
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries
 Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Digital Libraries: Language Technologies
 Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
Digital Libraries: Language Technologies RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Recall: Inverted Index..........................................
16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science
 16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science Quantitative Analysis of Textual Data 5.5 years of development, 17 releases 6,791 commits; 719
16 January 2018 Ken Benoit, Kohei Watanabe & Akitaka Matsuo London School of Economics and Political Science Quantitative Analysis of Textual Data 5.5 years of development, 17 releases 6,791 commits; 719
Building Search Applications
 Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Comprehensive Technical SEO Site Audit. PolyTab.com
 Comprehensive Technical SEO Site Audit PolyTab.com Conclusion - The competition in this segment is HIGH (There are many authority sites competing for a similar set of keywords). With strong content - strong
Comprehensive Technical SEO Site Audit PolyTab.com Conclusion - The competition in this segment is HIGH (There are many authority sites competing for a similar set of keywords). With strong content - strong
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
ΕΠΛ660. Ανάκτηση µε το µοντέλο διανυσµατικού χώρου
 Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
PART I: Formatting the Appearance of the Blog
 1 Wordpress Basics PUR4103 Public Relations Visual Communication Tappan Contents Part I: Formatting the Appearance of the Blog Choosing a theme Header image size Choosing a background color Finding a hex
1 Wordpress Basics PUR4103 Public Relations Visual Communication Tappan Contents Part I: Formatting the Appearance of the Blog Choosing a theme Header image size Choosing a background color Finding a hex
Automatic people tagging for expertise profiling in the enterprise
 Automatic people tagging for expertise profiling in the enterprise Pavel Serdyukov * (Yandex, Moscow, Russia) Mike Taylor, Vishwa Vinay, Matthew Richardson, Ryen White (Microsoft Research, Cambridge /
Automatic people tagging for expertise profiling in the enterprise Pavel Serdyukov * (Yandex, Moscow, Russia) Mike Taylor, Vishwa Vinay, Matthew Richardson, Ryen White (Microsoft Research, Cambridge /
Models for Document & Query Representation. Ziawasch Abedjan
 Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
Models for Document & Query Representation Ziawasch Abedjan Overview Introduction & Definition Boolean retrieval Vector Space Model Probabilistic Information Retrieval Language Model Approach Summary Overview
MMT Modern Machine Translation. First Evaluation Plan
 This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No 645487. MMT Modern Machine Translation First Evaluation Plan Author(s):
This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No 645487. MMT Modern Machine Translation First Evaluation Plan Author(s):
Informa/on Retrieval. Text Search. CISC437/637, Lecture #23 Ben CartereAe. Consider a database consis/ng of long textual informa/on fields
 Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Parallel Strands: A Preliminary Investigation. into Mining the Web for Bilingual Text. Philip Resnik
 Parallel Strands: A Preliminary Investigation into Mining the Web for Bilingual Text Philip Resnik Department of Linguistics and Institute for Advanced Computer Studies University of Maryland, College
Parallel Strands: A Preliminary Investigation into Mining the Web for Bilingual Text Philip Resnik Department of Linguistics and Institute for Advanced Computer Studies University of Maryland, College
CS 288: Statistical NLP Assignment 1: Language Modeling
 CS 288: Statistical NLP Assignment 1: Language Modeling Due September 12, 2014 Collaboration Policy You are allowed to discuss the assignment with other students and collaborate on developing algorithms
CS 288: Statistical NLP Assignment 1: Language Modeling Due September 12, 2014 Collaboration Policy You are allowed to discuss the assignment with other students and collaborate on developing algorithms
SEO Meta Descriptions: The What, Why, and How
 Topics Alexa.com Home > SEO > SEO Meta Descriptions: The What, Why, and How ABOUT THE AUTHOR: JENNIFER YESBECK SEO Meta Descriptions: The What, Why, and How 7 minute read When it comes to using content
Topics Alexa.com Home > SEO > SEO Meta Descriptions: The What, Why, and How ABOUT THE AUTHOR: JENNIFER YESBECK SEO Meta Descriptions: The What, Why, and How 7 minute read When it comes to using content