CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 6: Information Retrieval I. Aidan Hogan
|
|
|
- Lily Singleton
- 5 years ago
- Views:
Transcription
1 CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 6: Information Retrieval I Aidan Hogan aidhog@gmail.com

2 Postponing

3

4 MANAGING TEXT DATA

5 Information Overload
 All information = Zero")
6 If we didn t have search Contains all books with 25 unique characters 80 characters per line 40 lines per page 410 pages 410 x 40 x 80 = 1,312,000 chars 25 1,312,000 books Would contain any book imaginable Including a book with the location of useful books ;) All information = Zero information
7 The book that indexes the library
8 WEB SEARCH/RETRIEVAL
9 Building Google Web-search
10 Building Google Web-search What processes/algorithms does Google need to implement Web search? Crawling 1. Parse links from webpages 2. Schedule links for crawling 3. Download pages, GOTO 1 Ranking 1. How relevant is a page? (TF-IDF) 2. How important is it? (PageRank) 3. How many users clicked it? Indexing 1. Parse keywords from webpages 2. Index keywords to webpages 3. Manage updates...
11 INFORMATION RETRIEVAL: CRAWLING



12 How does Google know about the Web?
13 Crawling Download the Web. crawl(list seedurls) frontier_i = seedurls while(!frontier_i.isempty()) new list frontier_i+1 for url : frontier_i page = downloadpage(url) frontier_i+1.addall(extracturls(page)) store(page) i++ What s missing?
14 Crawling: Avoid Cycles Download the Web. crawl(list seedurls) frontier_i = seedurls new set urlsseen while(!frontier_i.isempty()) new list frontier_i+1 for url : frontier_i page = downloadpage(url) urlsseen.add(url) frontier_i+1.addall(extracturls(page).removeall(urlsseen)) store(page) i++ Performance?
15 Crawling: Avoid Cycles Download the Web. crawl(list seedurls) frontier_i = seedurls new set urlsseen while(!frontier_i.isempty()) new list frontier_i+1 for url : frontier_i page = downloadpage(url) urlsseen.add(url) frontier_i+1.addall(extracturls(page).removeall(urlsseen)) store(page) i++ Performance?
 frontier_i = seedurls new set urlsseen while(!")
) new list frontier_i+1 for url : frontier_i page =")
 Majority of time spent waiting for connection Disk/CPU")
16 Crawling: Avoid Cycles Download the Web. crawl(list seedurls) frontier_i = seedurls new set urlsseen while(!frontier_i.isempty()) new list frontier_i+1 for url : frontier_i page = downloadpage(url) i++ urlsseen.add(url) Majority of time spent waiting for connection Disk/CPU usage will be near 0 store(page) Bandwidth will not be maximised frontier_i+1.addall(extracturls(page).removeall(urlsseen)) Performance?
17 Crawling: Multi-threading Important crawl(list seedurls) frontier_i = seedurls new set urlsseen while(!frontier_i.isempty()) new list frontier_i+1 new list threads for url : frontier_i thread = new DownloadPageThread.run(url,urlsSeen,fronter_i+1) threads.add(thread) threads.poll() i++ DownloadPageThread: run(url,urlsseen,frontier_i+1) page = downloadpage(url) synchronised: urlsseen.add(url) synchronised: frontier_i+1.addall(extracturls(page).removeall(urlsseen)) synchronised: store(page)
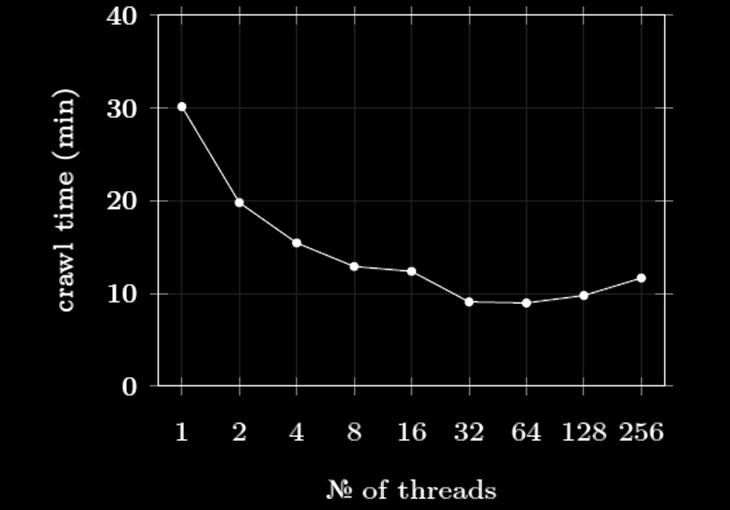


18 Crawling: Multi-threading Important Crawl 1,000 URLs
 Denial of Server Attack:")
19 Crawling: Important to be Polite! (Distributed) Denial of Server Attack: (D)DoS
DoSing")


20 Crawling: Avoid (D)DoSing Christopher Weatherhead 18 months prison more likely your IP range will be banned
21 Crawling: Web-site Scheduler crawl(list seedurls) frontier_i = seedurls new set urlsseen while(!frontier_i.isempty()) new list frontier_i+1 new list threads for url : schedule(frontier_i) #maximise time between two pages on one site thread = new DownloadPageThread.run(url,urlsSeen,fronter_i+1) threads.add(thread) threads.poll() i++ DownloadPageThread: run(url,urlsseen,frontier_i+1) page = downloadpage(url) synchronised: urlsseen.add(url) synchronised: frontier_i+1.addall(extracturls(page).removeall(urlsseen)) synchronised: store(page)
22 Robots Exclusion Protocol User-agent: * Disallow: / No bots allowed on the website. User-agent: * Disallow: /user/ Disallow: /main/login.html No bots allowed in /user/ sub-folder or login page. User-agent: googlebot Disallow: / Ban only the bot with user-agent googlebot.
23 Robots Exclusion Protocol (non-standard) User-agent: googlebot Crawl-delay: 10 Tell the googlebot to only crawl a page from this host no more than once every 10 seconds. User-agent: * Disallow: / Allow: /public/ Ban everything but the /public/ folder for all agents User-agent: * Sitemap: Tell user-agents about your site-map
24 Site-Map: Additional crawler information
25 Crawling: Important Points Seed-list: Entry point for crawling Frontier: Extract links from current pages for next round Seen-list: Avoid cycles Threading: Keep machines busy Politeness: Don t annoy web-sites Set delay between crawling pages on the same web-site Stick to what s stated in the robots.txt file Check for a site-map
26 Crawling: Distribution How might we implement a distributed crawler? for url : frontier_i-1 map(url,count) Similar benefits to multi-threading What will be the bottleneck as machines increase? Bandwidth or politeness delays

27 Crawling: All the Web? Can we crawl all the Web?
28 Crawling: All the Web? Can we crawl all the Web? Can Google crawl all the Web?

29 Crawling: Inaccessible (Bow-Tie) Broder et al. Graph structure in the web, Comput. Networks, vol. 33, no. 1-6, pp , 2000
30 Crawling: Inaccessible (Deep Web) What is the Deep Web?
31 Crawling: Inaccessible (Deep Web) What is the Deep Web? Dynamically-generated content
32 Crawling: Inaccessible (Deep Web) What is the Deep Web? Dynamically-generated content Password-protected
33 Crawling: Inaccessible (Deep Web) What is the Deep Web? Dynamically-generated content Password-protected Dark Web
 What is the")


34 Crawling: Inaccessible (Deep Web) What is the Deep Web? Dynamically-generated content Password-protected Dark Web 46% of statistics made up on the spot


35 Crawling: All the Web? Can we crawl all the Web? Can Google crawl all the Web? Can Google crawl itself?

36 Apache Nutch Open-source crawling framework! Compatible with Hadoop!
37 INFORMATION RETRIEVAL: INVERTED-INDEXING
38 Inverted Index Inverted Index: A map from words to documents Inverted because usually documents map to words Examples of applications?
39 Inverted Index: Example 1 Fruitvale Station is a 2013 American drama film written and directed by Ryan Coogler. Inverted index: Term List a american and by directed drama Posting List (1,2, ) (1,5, ) (1,2, ) (1,2, ) (1,2, ) (1,16, )
40 Inverted Index: Example Search american drama AND: Intersect posting lists OR: Union posting lists PHRASE:??? How should we implement PHRASE? Inverted index: Term List a american and by directed drama Posting List (1,2, ) (1,5, ) (1,2, ) (1,2, ) (1,2, ) (1,16, )
, (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212,")
41 Inverted Index: Example Fruitvale Station is a 2013 American drama film written and directed by Ryan Coogler. Inverted index: Term List a american and by directed drama Posting Lists (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
42 Inverted Index Flavours Record-level inverted index: Maps words to documents without positional information Word-level inverted index: Additionally maps words with positional information
43 Inverted Index: Word Normalisation drama america How can we solve this problem? Inverted index: Term List a american and by directed drama Posting Lists (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
44 Inverted Index: Word Normalisation drama america How can we solve this problem? Normalise words: Stemming cuts the ends off of words using generic rules: { America, American, americas, americanise } { america } Inverted index: Term List a american and by directed drama Posting Lists (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
45 Inverted Index: Word Normalisation Inverted index: drama america How can we solve this problem? Normalise words: Stemming cuts the ends off of words using generic rules: { America, American, americas, americanise } { america } Lemmatisation uses knowledge of the word to normalise: { better, goodly, best } { good } Term List Posting Lists a american and by directed drama (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
46 Inverted Index: Word Normalisation Inverted index: Lemmatisation uses knowledge of the word to normalise: { better, goodly, best } { good } Term List Posting Lists a Synonym expansion { american film, movie } { movie } and by directed drama drama america How can we solve this problem? Normalise words: Stemming cuts the ends off of words using generic rules: { America, American, americas, americanise } { america } (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
47 Inverted Index: Word Normalisation Inverted index: Lemmatisation uses knowledge of the word to normalise: { better, goodly, best } { good } Term List Posting Lists a Synonym expansion { american film, movie } { movie } and directed drama drama america How can we solve this problem? Normalise words: Stemming cuts the ends off of words using generic rules: { America, American, americas, americanise } { america } (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), Language specific! by Use same normalisation on query and document! (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
48 Inverted Index: Space Record-level inverted index: Maps words to documents without positional information Space? Word-level inverted index: Additionally maps words with positional information Space?

49 Number of unique words in text Inverted Index: Unique Words Not so many unique words Heap s law: English text K [10,100] β [0.4,0.6] Raw words versus unique words Number of words in text


50 Inverted Index: Space Record-level inverted index: Maps words to documents without positional information Space? Word-level inverted index: Additionally maps words with positional information Space?
51 Inverted Index: Common Words Many occurrences of few words Zipf s law In English text: the 7% of 3.5% and 2.7% 135 words cover half of all occurrences / Few occurrences of many words Zipf s law: the most popular word will occur twice as often as the second most popular word, thrice as often as the third most popular word, n times as often as the n-most popular word.
52 Inverted Index: Common Words Many occurrences of few words Zipf s law In English text: the 7% of 3.5% and 2.7% 135 words cover half of all occurrences / Few occurrences of many words Expect long posting lists for common words Zipf s law: the most popular word will occur twice as often as the second most popular word, thrice as often as the third most popular word, n times as often as the n-most popular word.
53 Inverted Index: Common Words Perhaps implement stop-words? Most common words contain least information the drama in america
54 Inverted Index: Common Words Perhaps implement stop-words? Perhaps implement block-addressing? Fruitvale Station is a 2013 American drama film written and directed by Ryan Coogler. Block 1 Block 2 What is the effect on phrase search? Small blocks ~ okay Big blocks ~ not okay Term List a american and by Posting Lists (1,[1, ]), (2,[ ]), (1,[1, ]), (5,[ ]), (1,[2, ]), (2,[ ]), (1,[2, ]), (2,[ ]),

55 Inverted Index: Common Words Many occurrences of few words Zipf s law In English text: / Few occurrences of many words Expect long posting lists for common words Expect the more 7% queries for common words of 3.5% and 2.7% 135 words cover half of all occurrences Zipf s law: the most popular word will occur twice as often as the second most popular word, thrice as often as the third most popular word, n times as often as the n-most popular word.

56 The Long Tail of Search


57 The Long Tail of Search How to optimise for this? Caching for common queries like coffee
58 If interested
59 Search Implementation Vocabulary keys: Hashing: O(1) lookups (assuming good hashing) no range queries relatively easy to update (though rehashing expensive!) Sorting/B-Tree: O(log(u)) lookups, u unique words range queries tricky to update (standard methods for B-trees) Tries/FST: O(l) lookups, l length of the word range queries, compressed, auto-completion! referencing becomes tricky (on disk) Tries? FSTs? (in class)
60 Memory Sizes Term list (vocabulary keys) small: Often will fit in memory! Posting lists larger: On disk / Hot regions cached Term List a american and by directed drama Posting List (1,[21,96,103, ]), (2,[ ]), (1,[28,123]), (5,[ ]), (1,[57,139, ]), (2,[ ]), (1,[70,157, ]), (2,[ ]), (1,[61,212, ]), (4,[ ]), (1,[38,87, ]), (16,[ ]),
61 Compression techniques Numeric compression important Term List country Posting Lists (1), (2), (3), (4), (6), (7),
62 Compression techniques: High Level Interval indexing Example for record-level indexing Could also be applied for block-level indexing, etc. Term List country Posting List (1), (2), (3), (4), (6), (7), Term List Posting List country (1 4), (6 7),
63 Compression techniques: High Level Gap indexing Example for record-level indexing Could also be applied for block-level indexing, etc. Term List country Posting List (1), (3), (4), (8), (9), Term List Posting Lists country (1), 2, 1, 4, 1 Benefit? Repeated small numbers easier to compress!
64 Compression techniques: Bit Level Variable length coding: bit-level techniques For example, Elias γ (gamma) encoding Assumes many small numbers z: integer to encode n = log 2 (z) coded in unary a zero marker next n binary numbers final Elias γ code Can you decode ? <1,2,1,1,4,8,5>
65 Compression techniques: Bit Level Variable length coding: bit-level techniques For example, Elias δ (delta) encoding Better for some distributions z: integer to encode n = log 2 (z) coded in Elias γ next n binary numbers final Elias δ code Can you decode ? <1,9,3,1,17>
66 Compression techniques: Byte Level Use variable length byte codes Use last bit of byte to indicate if the number ends For example: = 18, = 81, = 274
67 Parametric compression Previous methods non-parametric Don t take an input value Other compression techniques parametric: for example, Golomb-3 code: z: integer to encode n = (z-1)/3 coded in unary Zero separator binary remainder final Golomb-3 code
68 Other Optimisations Top-Doc: Order posting lists to give likely top documents first: good for top-k results Selectivity: Load the posting lists for the most rare keywords first; apply thresholds Sharding: Distribute over multiple machines How to distribute? (in class)

69 Extremely Scalable/Efficient When engineered correctly
70 AN INVERTED INDEX SOLUTION

71 Apache Lucene Inverted Index They built one so you don t have to! Open Source in Java


72 (Apache Solr) Built on top of Apache Lucene Lucene is the inverted index Solr is a distributed search platform, with distribution, fault tolerance, etc. (We will work with Lucene)
73 Apache Lucene: Indexing Documents continued
74 Apache Lucene: Indexing Documents continued
75 Apache Lucene: Searching Documents
76 Apache Lucene: Searching Documents
77 RECAP
78 Recap Crawling: Cycles, multi-threading, politeness, DDoS, robots exclusion, sitemaps, distribution, deep web Inverted Indexing: boolean queries, record-level vs. word-level vs. block-level, word normalisation, lemmatisation, space, Heap s law, Zipf s law, stop-words, tries, hashing, long tail, compression, interval coding, variable length encoding, Elias encoding, top doc, sharding, selectivity
79 CONTROL
80 Monday, 24th April 1.5 hours Four questions, all mandatory 1. Distributed systems 2. GFS 3. MapReduce/Hadoop 4. PIG One page of notes (back and front)
81 CLASS PROJECTS
82 Course Marking 50% for Weekly Labs (~3% a lab!) 35% for Controls 15% for Small Class Project

83 Class Project Done in threes Goal: Use what you ve learned to do something cool/fun (hopefully) Expected difficulty: A bit more than a lab s worth But without guidance (can extend lab code) Marked on: Difficulty, appropriateness, scale, good use of techniques, presentation, coolness, creativity, value Ambition is appreciated, even if you don t succeed: feel free to bite off more than you can chew! I will take this into account. Process: Start thinking up topics If you need data or get stuck, I will (try to) help out Deliverables: 4 minute presentation & short report

84

85 Questions?
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 6 Information Retrieval: Crawling & Indexing Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval I. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 7: Information Retrieval I Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains all books with
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 7: Information Retrieval I Aidan Hogan aidhog@gmail.com MANAGING TEXT DATA Information Overload If we didn t have search Contains all books with
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 7: Information Retrieval II. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2017 Lecture 7: Information Retrieval II Aidan Hogan aidhog@gmail.com How does Google know about the Web? Inverted Index: Example 1 Fruitvale Station is a 2013
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO Lecture 12: Conclusion. Aidan Hogan
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 12: Conclusion Aidan Hogan aidhog@gmail.com FULL-CIRCLE The value of data Twitter architecture Google architecture Generalise concepts to Working
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2016 Lecture 12: Conclusion Aidan Hogan aidhog@gmail.com FULL-CIRCLE The value of data Twitter architecture Google architecture Generalise concepts to Working
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
CS6200 Information Retrieval. David Smith College of Computer and Information Science Northeastern University
 CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
CS6200 Information Retrieval David Smith College of Computer and Information Science Northeastern University Indexing Process!2 Indexes Storing document information for faster queries Indexes Index Compression
Information Retrieval. Lecture 10 - Web crawling
 Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
Information Retrieval Lecture 10 - Web crawling Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Crawling: gathering pages from the
How Does a Search Engine Work? Part 1
 How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
How Does a Search Engine Work? Part 1 Dr. Frank McCown Intro to Web Science Harding University This work is licensed under Creative Commons Attribution-NonCommercial 3.0 What we ll examine Web crawling
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
COMP6237 Data Mining Searching and Ranking
 COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
COMP6237 Data Mining Searching and Ranking Jonathon Hare jsh2@ecs.soton.ac.uk Note: portions of these slides are from those by ChengXiang Cheng Zhai at UIUC https://class.coursera.org/textretrieval-001
Crawling the Web. Web Crawling. Main Issues I. Type of crawl
 Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Web Crawling Crawling the Web v Retrieve (for indexing, storage, ) Web pages by using the links found on a page to locate more pages. Must have some starting point 1 2 Type of crawl Web crawl versus crawl
Recap: lecture 2 CS276A Information Retrieval
 Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Recap: lecture 2 CS276A Information Retrieval Stemming, tokenization etc. Faster postings merges Phrase queries Lecture 3 This lecture Index compression Space estimation Corpus size for estimates Consider
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines. Informa1on Retrieval in Prac1ce. Annotations by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Today s lecture. Information Retrieval. Basic crawler operation. Crawling picture. What any crawler must do. Simple picture complications
 Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning, Pandu Nayak and Prabhakar Raghavan Crawling and Duplicates
THE WEB SEARCH ENGINE
 International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) Vol.1, Issue 2 Dec 2011 54-60 TJPRC Pvt. Ltd., THE WEB SEARCH ENGINE Mr.G. HANUMANTHA RAO hanu.abc@gmail.com
Administrative. Distributed indexing. Index Compression! What I did last summer lunch talks today. Master. Tasks
 Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Administrative Index Compression! n Assignment 1? n Homework 2 out n What I did last summer lunch talks today David Kauchak cs458 Fall 2012 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
EECS 395/495 Lecture 5: Web Crawlers. Doug Downey
 EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
EECS 395/495 Lecture 5: Web Crawlers Doug Downey Interlude: US Searches per User Year Searches/month (mlns) Internet Users (mlns) Searches/user-month 2008 10800 220 49.1 2009 14300 227 63.0 2010 15400
Web Information Retrieval. Lecture 4 Dictionaries, Index Compression
 Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
Web Information Retrieval Lecture 4 Dictionaries, Index Compression Recap: lecture 2,3 Stemming, tokenization etc. Faster postings merges Phrase queries Index construction This lecture Dictionary data
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 17 September 2018 Some slides courtesy Manning, Raghavan, and Schütze Other characteristics Significant duplication Syntactic
Today s lecture. Basic crawler operation. Crawling picture. What any crawler must do. Simple picture complications
 Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning and Pandu Nayak Crawling and Duplicates 2 Sec. 20.2
Today s lecture Introduction to Information Retrieval Web Crawling (Near) duplicate detection CS276 Information Retrieval and Web Search Chris Manning and Pandu Nayak Crawling and Duplicates 2 Sec. 20.2
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Information Retrieval
 Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Introduction to Information Retrieval CS3245 12 Lecture 12: Crawling and Link Analysis Information Retrieval Last Time Chapter 11 1. Probabilistic Approach to Retrieval / Basic Probability Theory 2. Probability
Collection Building on the Web. Basic Algorithm
 Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Collection Building on the Web CS 510 Spring 2010 1 Basic Algorithm Initialize URL queue While more If URL is not a duplicate Get document with URL [Add to database] Extract, add to queue CS 510 Spring
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm
 Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Computer Science 572 Midterm Prof. Horowitz Thursday, March 8, 2012, 2:00pm 3:00pm Name: Student Id Number: 1. This is a closed book exam. 2. Please answer all questions. 3. There are a total of 40 questions.
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
Introduction to Information Retrieval http://informationretrieval.org IIR 20: Crawling Hinrich Schütze Center for Information and Language Processing, University of Munich 2009.07.14 1/36 Outline 1 Recap
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 6: Index Compression Paul Ginsparg Cornell University, Ithaca, NY 15 Sep
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Inverted Indexes. Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5
 Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
Crawling CE-324: Modern Information Retrieval Sharif University of Technology
 Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Crawling CE-324: Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2017 Most slides have been adapted from: Profs. Manning, Nayak & Raghavan (CS-276, Stanford) Sec. 20.2 Basic
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Static Pruning of Terms In Inverted Files
 In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
In Inverted Files Roi Blanco and Álvaro Barreiro IRLab University of A Corunna, Spain 29th European Conference on Information Retrieval, Rome, 2007 Motivation : to reduce inverted files size with lossy
CC PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018
 CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 1: Introduction Aidan Hogan aidhog@gmail.com THE VALUE OF DATA Soho, London, 1854 Cholera: What we know now Cholera: What we knew in 1854 1854:
CC5212-1 PROCESAMIENTO MASIVO DE DATOS OTOÑO 2018 Lecture 1: Introduction Aidan Hogan aidhog@gmail.com THE VALUE OF DATA Soho, London, 1854 Cholera: What we know now Cholera: What we knew in 1854 1854:
CS6200 Informa.on Retrieval. David Smith College of Computer and Informa.on Science Northeastern University
 CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
Relevant?!? Algoritmi per IR. Goal of a Search Engine. Prof. Paolo Ferragina, Algoritmi per "Information Retrieval" Web Search
 Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
Algoritmi per IR Web Search Goal of a Search Engine Retrieve docs that are relevant for the user query Doc: file word or pdf, web page, email, blog, e-book,... Query: paradigm bag of words Relevant?!?
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Full-Text Indexing For Heritrix
 Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Full-Text Indexing For Heritrix Project Advisor: Dr. Chris Pollett Committee Members: Dr. Mark Stamp Dr. Jeffrey Smith Darshan Karia CS298 Master s Project Writing 1 2 Agenda Introduction Heritrix Design
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Query Answering Using Inverted Indexes
 Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Query Answering Using Inverted Indexes Inverted Indexes Query Brutus AND Calpurnia J. Pei: Information Retrieval and Web Search -- Query Answering Using Inverted Indexes 2 Document-at-a-time Evaluation
Crawling. CS6200: Information Retrieval. Slides by: Jesse Anderton
 Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
Crawling CS6200: Information Retrieval Slides by: Jesse Anderton Motivating Problem Internet crawling is discovering web content and downloading it to add to your index. This is a technically complex,
INFO 4300 / CS4300 Information Retrieval. slides adapted from Hinrich Schütze s, linked from
 INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 7: Scores in a Complete Search System Paul Ginsparg Cornell University, Ithaca,
INFO 4300 / CS4300 Information Retrieval slides adapted from Hinrich Schütze s, linked from http://informationretrieval.org/ IR 7: Scores in a Complete Search System Paul Ginsparg Cornell University, Ithaca,
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December ISSN Web Search Engine
 International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
International Journal of Scientific & Engineering Research Volume 2, Issue 12, December-2011 1 Web Search Engine G.Hanumantha Rao*, G.NarenderΨ, B.Srinivasa Rao+, M.Srilatha* Abstract This paper explains
Query Processing and Alternative Search Structures. Indexing common words
 Query Processing and Alternative Search Structures CS 510 Winter 2007 1 Indexing common words What is the indexing overhead for a common term? I.e., does leaving out stopwords help? Consider a word such
Query Processing and Alternative Search Structures CS 510 Winter 2007 1 Indexing common words What is the indexing overhead for a common term? I.e., does leaving out stopwords help? Consider a word such
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 6: Index Compression 6 Last Time: index construction Sort- based indexing Blocked Sort- Based Indexing Merge sort is effective
modern database systems lecture 4 : information retrieval
 modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
modern database systems lecture 4 : information retrieval Aristides Gionis Michael Mathioudakis spring 2016 in perspective structured data relational data RDBMS MySQL semi-structured data data-graph representation
Elementary IR: Scalable Boolean Text Search. (Compare with R & G )
") Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
Elementary IR: Scalable Boolean Text Search (Compare with R & G 27.1-3) Information Retrieval: History A research field traditionally separate from Databases Hans P. Luhn, IBM, 1959: Keyword in Context
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
CS6200 Information Retreival. Crawling. June 10, 2015
 CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
CS6200 Information Retreival Crawling Crawling June 10, 2015 Crawling is one of the most important tasks of a search engine. The breadth, depth, and freshness of the search results depend crucially on
Logistics. CSE Case Studies. Indexing & Retrieval in Google. Review: AltaVista. BigTable. Index Stream Readers (ISRs) Advanced Search
 Advanced Search") CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
CSE 454 - Case Studies Indexing & Retrieval in Google Some slides from http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm Logistics For next class Read: How to implement PageRank Efficiently Projects
MG4J: Managing Gigabytes for Java. MG4J - intro 1
 MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
MG4J: Managing Gigabytes for Java MG4J - intro 1 Managing Gigabytes for Java Schedule: 1. Introduction to MG4J framework. 2. Exercitation: try to set up a search engine on a particular collection of documents.
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
Information Retrieval Suan Lee - Information Retrieval - 05 Index Compression 1 05 Index Compression - Information Retrieval - 05 Index Compression 2 Last lecture index construction Sort-based indexing
CS47300: Web Information Search and Management
 CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
CS47300: Web Information Search and Management Web Search Prof. Chris Clifton 18 October 2017 Some slides courtesy Croft et al. Web Crawler Finds and downloads web pages automatically provides the collection
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
whitepaper RediSearch: A High Performance Search Engine as a Redis Module
 whitepaper RediSearch: A High Performance Search Engine as a Redis Module Author: Dvir Volk, Senior Architect, Redis Labs Table of Contents RediSearch At-a-Glance 2 A Little Taste: RediSearch in Action
whitepaper RediSearch: A High Performance Search Engine as a Redis Module Author: Dvir Volk, Senior Architect, Redis Labs Table of Contents RediSearch At-a-Glance 2 A Little Taste: RediSearch in Action
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 5: Index Compression Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-04-17 1/59 Overview
VK Multimedia Information Systems
 VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Results Exercise 01 Exercise 02 Retrieval
VK Multimedia Information Systems Mathias Lux, mlux@itec.uni-klu.ac.at This work is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Results Exercise 01 Exercise 02 Retrieval
Index Compression. David Kauchak cs160 Fall 2009 adapted from:
 Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
Index Compression David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture5-indexcompression.ppt Administrative Homework 2 Assignment 1 Assignment 2 Pair programming?
Anatomy of a search engine. Design criteria of a search engine Architecture Data structures
 Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
Anatomy of a search engine Design criteria of a search engine Architecture Data structures Step-1: Crawling the web Google has a fast distributed crawling system Each crawler keeps roughly 300 connection
Building Search Applications
 Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Building Search Applications Lucene, LingPipe, and Gate Manu Konchady Mustru Publishing, Oakton, Virginia. Contents Preface ix 1 Information Overload 1 1.1 Information Sources 3 1.2 Information Management
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Open Source Search. Andreas Pesenhofer. max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria
 Open Source Search Andreas Pesenhofer max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria max.recall information systems max.recall is a software and consulting company enabling
Open Source Search Andreas Pesenhofer max.recall information systems GmbH Künstlergasse 11/1 A-1150 Wien Austria max.recall information systems max.recall is a software and consulting company enabling
Recap of the previous lecture. This lecture. A naïve dictionary. Introduction to Information Retrieval. Dictionary data structures Tolerant retrieval
 Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
CS377: Database Systems Text data and information. Li Xiong Department of Mathematics and Computer Science Emory University
 CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
CS377: Database Systems Text data and information retrieval Li Xiong Department of Mathematics and Computer Science Emory University Outline Information Retrieval (IR) Concepts Text Preprocessing Inverted
Text Technologies for Data Science INFR Indexing (2) Instructor: Walid Magdy
 Instructor: Walid Magdy") Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 03-Oct-2018 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 03-Oct-2018 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
CS/INFO 1305 Summer 2009
 Information Retrieval Information Retrieval (Search) IR Search Using a computer to find relevant pieces of information Text search Idea popularized in the article As We May Think by Vannevar Bush in 1945
Information Retrieval Information Retrieval (Search) IR Search Using a computer to find relevant pieces of information Text search Idea popularized in the article As We May Think by Vannevar Bush in 1945
CS252 S05. Main memory management. Memory hardware. The scale of things. Memory hardware (cont.) Bottleneck
 Bottleneck") Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
Main memory management CMSC 411 Computer Systems Architecture Lecture 16 Memory Hierarchy 3 (Main Memory & Memory) Questions: How big should main memory be? How to handle reads and writes? How to find
Text Technologies for Data Science INFR Indexing (2) Instructor: Walid Magdy
 Instructor: Walid Magdy") Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 10-Oct-2017 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 10-Oct-2017 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Chapter 27 Introduction to Information Retrieval and Web Search
 Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
Chapter 27 Introduction to Information Retrieval and Web Search Copyright 2011 Pearson Education, Inc. Publishing as Pearson Addison-Wesley Chapter 27 Outline Information Retrieval (IR) Concepts Retrieval
BUbiNG. Massive Crawling for the Masses. Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna
 BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
BUbiNG Massive Crawling for the Masses Paolo Boldi, Andrea Marino, Massimo Santini, Sebastiano Vigna Dipartimento di Informatica Università degli Studi di Milano Italy Once upon a time UbiCrawler UbiCrawler
Running Head: HOW A SEARCH ENGINE WORKS 1. How a Search Engine Works. Sara Davis INFO Spring Erika Gutierrez.
 Running Head: 1 How a Search Engine Works Sara Davis INFO 4206.001 Spring 2016 Erika Gutierrez May 1, 2016 2 Search engines come in many forms and types, but they all follow three basic steps: crawling,
Running Head: 1 How a Search Engine Works Sara Davis INFO 4206.001 Spring 2016 Erika Gutierrez May 1, 2016 2 Search engines come in many forms and types, but they all follow three basic steps: crawling,
Data Structures and Algorithms Dr. Naveen Garg Department of Computer Science and Engineering Indian Institute of Technology, Delhi.
 Data Structures and Algorithms Dr. Naveen Garg Department of Computer Science and Engineering Indian Institute of Technology, Delhi Lecture 18 Tries Today we are going to be talking about another data
Data Structures and Algorithms Dr. Naveen Garg Department of Computer Science and Engineering Indian Institute of Technology, Delhi Lecture 18 Tries Today we are going to be talking about another data
Search Like a Pro. How Search Engines Work. Comparison Search Engine. Comparison Search Engine. How Search Engines Work
 Search Like a Pro Nancy Warren AkLA Conference 2010 How Search Engines Work http://computer.howstuffworks.com/search-engine1.htm Google How Search Engines Crawl a Web Site Yahoo Comparison Search Engine
Search Like a Pro Nancy Warren AkLA Conference 2010 How Search Engines Work http://computer.howstuffworks.com/search-engine1.htm Google How Search Engines Crawl a Web Site Yahoo Comparison Search Engine
Information Networks. Hacettepe University Department of Information Management DOK 422: Information Networks
 Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
Information Networks Hacettepe University Department of Information Management DOK 422: Information Networks Search engines Some Slides taken from: Ray Larson Search engines Web Crawling Web Search Engines
SEARCH ENGINE INSIDE OUT
 SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
SEARCH ENGINE INSIDE OUT From Technical Views r86526020 r88526016 r88526028 b85506013 b85506010 April 11,2000 Outline Why Search Engine so important Search Engine Architecture Crawling Subsystem Indexing
Parametric Search using In-memory Auxiliary Index
 Parametric Search using In-memory Auxiliary Index Nishant Verman and Jaideep Ravela Stanford University, Stanford, CA {nishant, ravela}@stanford.edu Abstract In this paper we analyze the performance of
Parametric Search using In-memory Auxiliary Index Nishant Verman and Jaideep Ravela Stanford University, Stanford, CA {nishant, ravela}@stanford.edu Abstract In this paper we analyze the performance of
Desktop Crawls. Document Feeds. Document Feeds. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval INFO 4300 / CS 4300! Web crawlers Retrieving web pages Crawling the web» Desktop crawlers» Document feeds File conversion Storing the documents Removing noise Desktop Crawls! Used
Information Retrieval 6. Index compression
 Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
Information Retrieval
 Information Retrieval Course presentation João Magalhães 1 Relevance vs similarity Multimedia documents Information retrieval application Query Documents Information side User side What is the best [search
Information Retrieval Course presentation João Magalhães 1 Relevance vs similarity Multimedia documents Information retrieval application Query Documents Information side User side What is the best [search
230 Million Tweets per day
 Tweets per day Queries per day Indexing latency Avg. query response time Earlybird - Realtime Search @twitter Michael Busch @michibusch michael@twitter.com buschmi@apache.org Earlybird - Realtime Search
Tweets per day Queries per day Indexing latency Avg. query response time Earlybird - Realtime Search @twitter Michael Busch @michibusch michael@twitter.com buschmi@apache.org Earlybird - Realtime Search
Web-Page Indexing Based on the Prioritized Ontology Terms
 Web-Page Indexing Based on the Prioritized Ontology Terms Sukanta Sinha 1,2, Rana Dattagupta 2, and Debajyoti Mukhopadhyay 1,3 1 WIDiCoReL Research Lab, Green Tower, C-9/1, Golf Green, Kolkata 700095,
Web-Page Indexing Based on the Prioritized Ontology Terms Sukanta Sinha 1,2, Rana Dattagupta 2, and Debajyoti Mukhopadhyay 1,3 1 WIDiCoReL Research Lab, Green Tower, C-9/1, Golf Green, Kolkata 700095,
Architecture and Implementation of Database Systems (Summer 2018)
") Jens Teubner Architecture & Implementation of DBMS Summer 2018 1 Architecture and Implementation of Database Systems (Summer 2018) Jens Teubner, DBIS Group jens.teubner@cs.tu-dortmund.de Summer 2018 Jens
Jens Teubner Architecture & Implementation of DBMS Summer 2018 1 Architecture and Implementation of Database Systems (Summer 2018) Jens Teubner, DBIS Group jens.teubner@cs.tu-dortmund.de Summer 2018 Jens
Information Retrieval. Lecture 3 - Index compression. Introduction. Overview. Characterization of an index. Wintersemester 2007
 Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Information Retrieval Lecture 3 - Index compression Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 30 Introduction Dictionary and inverted index:
Search & Google. Melissa Winstanley
 Search & Google Melissa Winstanley mwinst@cs.washington.edu The size of data Byte: a single character Kilobyte: a short story, a simple web html file Megabyte: a photo, a short song Gigabyte: a movie,
Search & Google Melissa Winstanley mwinst@cs.washington.edu The size of data Byte: a single character Kilobyte: a short story, a simple web html file Megabyte: a photo, a short song Gigabyte: a movie,
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
EPL660: Information Retrieval and Search Engines Lab 8
 EPL660: Information Retrieval and Search Engines Lab 8 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science What is Apache Nutch? Production ready Web Crawler Operates
EPL660: Information Retrieval and Search Engines Lab 8 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science What is Apache Nutch? Production ready Web Crawler Operates
Outline of the course
 Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Outline of the course Introduction to Digital Libraries (15%) Description of Information (30%) Access to Information (30%) User Services (10%) Additional topics (15%) Buliding of a (small) digital library
Web-page Indexing based on the Prioritize Ontology Terms
 Web-page Indexing based on the Prioritize Ontology Terms Sukanta Sinha 1, 4, Rana Dattagupta 2, Debajyoti Mukhopadhyay 3, 4 1 Tata Consultancy Services Ltd., Victoria Park Building, Salt Lake, Kolkata
Web-page Indexing based on the Prioritize Ontology Terms Sukanta Sinha 1, 4, Rana Dattagupta 2, Debajyoti Mukhopadhyay 3, 4 1 Tata Consultancy Services Ltd., Victoria Park Building, Salt Lake, Kolkata
Introduction to IR Systems: Supporting Boolean Text Search
 Introduction to IR Systems: Supporting Boolean Text Search Ramakrishnan & Gehrke: Chapter 27, Sections 27.1 27.2 CPSC 404 Laks V.S. Lakshmanan 1 Information Retrieval A research field traditionally separate
Introduction to IR Systems: Supporting Boolean Text Search Ramakrishnan & Gehrke: Chapter 27, Sections 27.1 27.2 CPSC 404 Laks V.S. Lakshmanan 1 Information Retrieval A research field traditionally separate
Chapter 2. Architecture of a Search Engine
 Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Chapter 2 Architecture of a Search Engine Search Engine Architecture A software architecture consists of software components, the interfaces provided by those components and the relationships between them
Information Retrieval. hussein suleman uct cs
 Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
Information Management Information Retrieval hussein suleman uct cs 303 2004 Introduction Information retrieval is the process of locating the most relevant information to satisfy a specific information
The Topic Specific Search Engine
 The Topic Specific Search Engine Benjamin Stopford 1 st Jan 2006 Version 0.1 Overview This paper presents a model for creating an accurate topic specific search engine through a focussed (vertical)
The Topic Specific Search Engine Benjamin Stopford 1 st Jan 2006 Version 0.1 Overview This paper presents a model for creating an accurate topic specific search engine through a focussed (vertical)
Information retrieval
 Information retrieval Ryan Tibshirani Data Mining: 36-462/36-662 January 17 2013 1 What we use to do I want to learn about that magic trick with the rings! Then: go to the library Librarian Card catalog
Information retrieval Ryan Tibshirani Data Mining: 36-462/36-662 January 17 2013 1 What we use to do I want to learn about that magic trick with the rings! Then: go to the library Librarian Card catalog