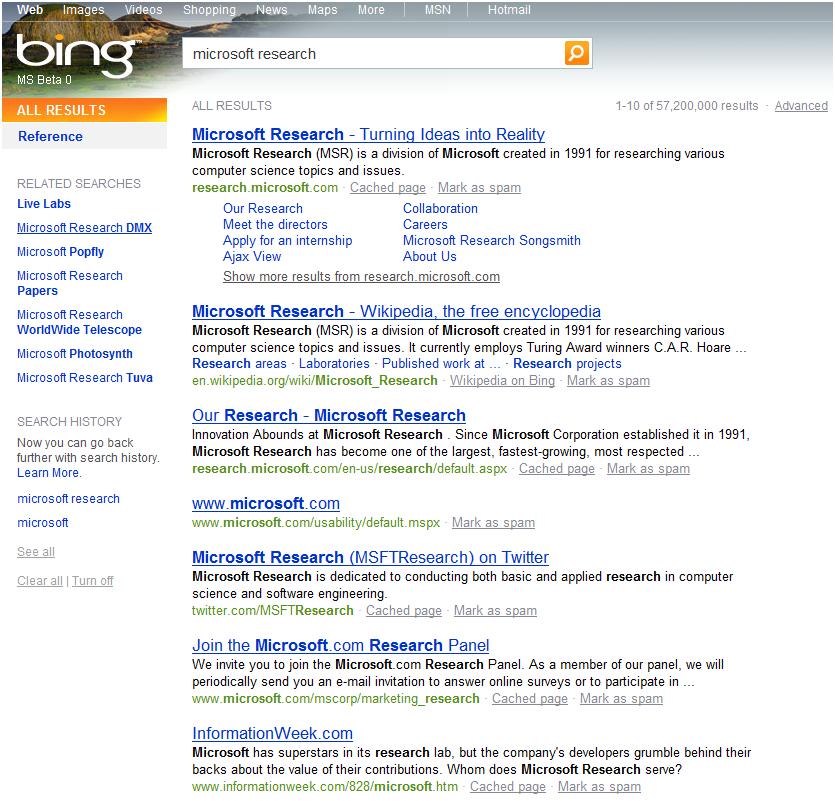
Link Analysis Informa0on Retrieval. Evangelos Kanoulas
|
|
|
- Gordon Gervais Clark
- 6 years ago
- Views:
Transcription
1 Link Analysis Informa0on Retrieval Evangelos Kanoulas













2 How Search Works Logging Clicks Context Crawling Quality Freshness Spaminess Text processing & Indexing Ranking Algorithm Content Query understanding
3 Friendship Networks, Cita0on Networks, Link analysis studies the rela0onships (e.g., friendship, cita0on) between objects (e.g., people, publica0ons) to find out about their characteris0cs (e.g., popularity, impact) Social Network Analysis (e.g., on a friendship network) Closeness centrality of a person v is the frac0on of shortest paths between any two persons (u, w) that pass through v Bibliometrics (e.g., on a cita0on network) Co- cita0on measures how many papers cite both u and v Co- reference measures how many common papers both u and v refer to
4 , and the Web? World Wide Web can be seen as directed graph G(V, E) web pages correspond to ver0ces (or, nodes) V hyperlinks between them correspond to edges E Link analysis on the Web graph can give us clues about which web pages are important and should thus be ranked higher which pairs of web pages are similar to each other which web pages are probably spam and should be ignored
5 Link Analysis PageRank HITS Random Surfer Model, Markov Chains Hyperlinked- Induced Topic Search Topic- Specific and Personalized PageRank Biased Random Jumps, Linearity of PageRank Similarity Search SimRank, Random Walk with Restarts Spam Detec0on LinkSpam, TrustRank, SpamRank Social Networks SocialPageRank, TunkRank

6 PageRank Hyperlinks can be interpreted as endorsements for the target web page In- degree as a measure of the importance/ authority/popularity of a web page v is easy to manipulate and does not consider the importance of the source web pages Larry Page & Sergey Brin PageRank considers a web page v important if many important web pages link to it Random surfer model follows a uniform random outgoing link with probability (1-ε) jumps to a uniform random web page with probability ε Intuition: Important web pages are the ones that are visited often
7 Stochas0c Processes & Markov Chains Discrete stochas0c process is a family of random variables {X t t 2 T } with T = {0, 1, 2, } as discrete 0me domain Stochas0c process is a Markov chain if P [X t = x X t 1 = w,..., X 0 = a] = P [X t = x X t 1 = w] holds, i.e., it is memoryless Markov chain is 0me- homogeneous if for all 0mes t P [X t+1 = x X t = w] =P [X t = x X t 1 = w] holds, i.e., transi0on probabili0es do not depend on 0me
8 State Space & Transi0on Probability Matrix State space of a Markov chain { X t t T} is the countable set S of all values that X t can assume X t : Ω S Markov chain is in state s at 0me t if X t = s Markov chain is finite if it has a finite state space If a Markov chain is finite and 0me- homogeneous, its transi0on probabili0es can be described as a matrix P = (p ij ) p ij = P [X t = j X t 1 = i] For S = n the transi0on probability matrix P is an n- by- n right- stochas0c matrix (i.e., its rows sum up to 1) 8i : X j p ij =1
9 Proper0es of Markov Chains State i is reachable from state j if there exists a n 0 such that (P n ) ij > 0 States i and j communicate if i is reachable from j and vice versa Markov chain is irreducible if all states i,j in S communicate Markov chain is posi0ve recurrent if the recurrence probability is 1 and the mean recurrence 0me is finite for every state i
10 Proper0es of Markov Chains Markov chain is aperiodic if every state I has period 1 Markov chain is ergodic if it is 0me- homogeneous, irreducible, posi0ve recurrent, and aperiodic The 1- by- n vector is the sta0onary state distribu0on of the Markov chain described by P if i 0 X i =1 P = π i is the limit probability that Markov chain is in state i 1/π i reflects the average 0me un0l the Markov chain returns to state i Theorem: If a Markov chain is finite and ergodic, then there exists a unique sta0onary state distribu0on
11 PageRank as a Markov Chain Random surfer model Follows a uniform random outgoing link with probability (1- ε) Jumps to a uniform random web page with probability ε Let A be the adjacency matrix of the Web graph, matrix T captures following of a uniform random outgoing link T ij = ( 1/out(i) (i, j) 2 E 0 otherwise A = T = /2 0 1/ /2 0 1/ / /1 0 0
12 PageRank as a Markov Chain Random surfer model Follows a uniform random outgoing link with probability (1- ε) Jumps to a uniform random web page with probability ε Vector j captures jumping to a uniform random web page j i =1/ V Transi0on probability matrix of Markov chain then obtained as P =(1 )T + [1...1] T j
13 Compu0ng π Markov Chain Monte Carlo Sta0onary state distribu0on can be cast into a system of linear equa0ons Solu0on can be found, e.g., using Gauss elimina0on Sta0onary state probability distribu0on is the led eigenvector of the transi0on probability matrix P for eigenvalue λ = 1 P = Can be computed using the characteris0c polynomial (P I) =0
14 Compu0ng π (in prac0ce) Sta0onary state distribu0on is the limit distribu0on Idea: Compute k- step state probabili0es π k un0l they converge Power (itera0on) method Select arbitrarily ini0al state probability distribu0on π 0 Compute π k = π k- 1 P un0l they converge (e.g. π k - π k- 1 < ε) Power (itera0on) method basically simulates the Markov chain and is the method of choice in prac0ce when dealing with huge state spaces, exploi0ng that matrix- vector mul0plica0on is easy to parallelize
15 Link Analysis PageRank HITS Random Surfer Model, Markov Chains Hyperlinked- Induced Topic Search Topic- Specific and Personalized PageRank Biased Random Jumps, Linearity of PageRank Similarity Search SimRank, Random Walk with Restarts Spam Detec0on LinkSpam, TrustRank, SpamRank Social Networks SocialPageRank, TunkRank
16 Topic- specific and personalized PageRank PageRank produces one- size- fits- all ranking determined assuming uniform following of links and random jumps How can we obtain topic- specific (e.g., for Sports) or personalized (e.g., based on my bookmarks) rankings? bias random jump probabili0es (i.e., modify the vector j) bias link- following probabili0es (i.e., modify the matrix T) What if we do not have hyperlinks between documents? construct implicit- link graph from user behavior or document contents
17 Topic- specific PageRank Input: Set of topics C (e.g., Sports, Poli0cs, Food, ) Set of web pages S c for each topic c (e.g., from dmoz.org) Idea: Compute a topic- specific ranking for c by biasing the random jump in PageRank toward web pages S c of that topic P c =(1 )T + [1...1] T j c with jci = ( 1/ S c Method: Precompute topic- specific PageRank vectors π c Classify user query q to obtain topic probabili0es P[c q] Final importance score obtained as linear combina0on = X P [c q] c c2c i 2 S c 0 i/2 S c T. H. Haveliwala: Topic- Sensi,ve PageRank: A Context- Sensi,ve Ranking Algorithm for Web Search, TKDE 15(4): , 2003
18 Personalized PageRank Idea: Provide every user with a personalized ranking based on her favorite web pages F (e.g., from bookmarks or likes) ( 1/ F i 2 F P F =(1 )T + [1...1] T j F with j Fi = 0 i/2 F Problem: Compu0ng and storing a personalized PageRank vector for every single user is too expensive G. Jeh and J. Widom: Scaling Personalized Web Search, KDD 2003
19 PageRank in prac0ce PageRank- style methods are used somewhat in ranking Google: probably more important in the early days than today Use case: index selec0on which pages to include in the index which pages to include in which 0er of the index which pages to update more oden Use case: spam figh0ng which sites to exclude from search
20 Link Analysis PageRank HITS Random Surfer Model, Markov Chains Hyperlinked- Induced Topic Search Topic- Specific and Personalized PageRank Biased Random Jumps, Linearity of PageRank Similarity Search SimRank, Random Walk with Restarts Spam Detec0on LinkSpam, TrustRank, SpamRank Social Networks SocialPageRank, TunkRank
21 Similarity Search How can we use the links between objects to figure out which objects are similar to each other? Not limited to the Web graph but also applicable to k- par0te graphs derived from rela0onal database (students, lecture, etc.) implicit graphs derived from observed user behavior word co- occurrence graphs Applica0ons: Iden0fica0on of similar pairs of objects (e.g., documents or queries) Recommenda0on of similar objects (e.g., documents based on a query)
22 SimRank Intui0on: Two objects are similar if similar objects point to them s(u, v) = C I(u) I(v) I(u) X i=1 I(v) X j=1 s(i i (u),i j (v)) with confidence constant C < 1, in- neighbors I(u) and I(v), and I i (u) and I j (v) as the i- th and j- th in- neighbor of u and v Example: Universi0es, Professors, Students U1 P1 P2 S1 S2 With C = 0.8: s(p1, P2) = s(s1, S2) = s(u1, P2) = s(p1, S2) = s(p2, S2) = s(p2, S1) = s(u1, S2) = 0.034
23 SimRank s (0) (u, v) = ( 1 u = v 0 otherwise Repeat un0l convergence: s (k+1) (u, v) = C I(u) I(v) I(u) X i=1 I(v) X j=1 s (k) (I i (u),i j (v)) u 6= v SimRank score s(u, v) can be interpreted as the expected number of steps that it takes two random surfers to meet if they start at nodes u and v walk the graph backwards in lock step (i.e., their steps are synchronous) G. Jeh and J. Widom: SimRank: A Measure of Structural- Contextual Similarity, KDD 2002

24 Random Walks on Click Graph Consider bi- par0te click graph with queries and documents as ver0ces and weighted edges (q, d) indica0ng users tendency to click on document d for query q giant panda panda bear d1 d2 2.0 Perform PageRank- style random walk with link- following probabili0es propor0onal to edge weights and random jump to single query or document fiat panda 1.0 d3 k= Applica0ons: query- to- document search query- to- query sugges0on document- by- query annota0on document- to- document sugges0on Annota0on using a random walk: P Query boxer dog puppies boxer puppy pics boxer puppies puppy boxer boxer puppy pictures boxer pups boxer puppy puppy boxers boxer pup baby boxer Distance
25 Random Walks on Query Flow Graph Consider query- flow graph with queries as ver0ces and weighted edges (q, q ) reflec0ng how oden q is issued ader q Recommend related queries by performing PageRank- style random walk on the query- flow graph with link- following probabili0es propor0onal to edge weights and random jump to current query (or last few queries) 2.0 endangered species 1.0 panda bear 3.0 giant panda banana apple banana beatles apple beatles banana apple usb no banana cs giant chocolate bar where is the seed in anut banana shoe fruit banana banana cloths eating bugs banana eating bugs banana holiday opening a banana banana shoe fruit banana recipe 22 feb 08 banana jules oliver banana cs banana cloths beatles apple apple ipod scarring srg peppers artwork ill get you bashles dundee folk songs the beatles love album place lyrics beatles beatles scarring paul mcartney yarns from ireland statutory instrument A55 silver beatles tribute band beatles mp3 GHOST S ill get you fugees triger finger remix P. Boldi, F. Bonchi, C. CasYllo, D. Donato, A. Gionis, and S. Vigna: The Query- flow Graph: Model and ApplicaTons, CIKM 2008
26 Link Analysis PageRank HITS Random Surfer Model, Markov Chains Hyperlinked- Induced Topic Search Topic- Specific and Personalized PageRank Biased Random Jumps, Linearity of PageRank Similarity Search SimRank, Random Walk with Restarts Spam Detec0on LinkSpam, TrustRank, SpamRank Social Networks SocialPageRank, TunkRank
 black hat (manipulates search results by web spamming techniques) Web spamming techniques")
27 Spam Detec0on Discoverability of web pages has oden a direct impact on the commercial success of the business behind them Search Engine Op0miza0on (SEO) seeks to op0mize web pages to make them easier to discover for poten0al customers white hat (op0mizes for the user and respects to search engine policies) black hat (manipulates search results by web spamming techniques) Web spamming techniques and search engines evolved in parallel ini0ally: only content spam, then: link spam, now: social media spam
28 Content Spam vs. Link Spam vs. Content Hiding Content spam keyword stuffing add unrelated but oden- sought keywords to page invisible content unrelated content invisible to users (like this) Link spam link farms collec0on of pages aiming to manipulate PageRank honeypots create valuable web pages with links to spam page link hijacking leave comments on reputable web pages or blogs Content hiding cloaking show different content to search engine s crawler and users
29 TrustRank, BadRank Idea: Pages linked to by trustworthy pages tend to be trustworthy TrustRank performs PageRank- style random walk with random jumps only to an explicitly selected set of trusted pages T Idea: Pages linking to spam pages tend to be spam themselves BadRank performs PageRank- style backwards random walk (i.e., following incoming links) with random jumps only to an explicitly selected set of blacklisted pages B Problems: Sets of trusted and blacklisted pages are difficult to maintain TrustRank and BadRank scores are hard to interpret and combine



30 Spam, Damn Spam and Sta0s0cs Idea: Look for sta0s0cal devia0on Content spam: Compare word frequency distribu0on to distribu0on in good hosts Link spam: Iden0fy outliers in out- degree and in- degree distribu0ons and inspect intersec0on 1E+8 1E+9 1E+7 1E+8 1E+6 1E+7 1E+6 Number of pages 1E+5 1E+4 1E+3 Number of pages 1E+5 1E+4 1E+3 1E+2 1E+2 1E+1 1E+1 1E+0 1E+0 1E+1 1E+2 1E+3 Out-degree 1E+4 1E+5 1E+6 1E+0 1E+0 1E+1 1E+2 1E+3 1E+4 1E+5 In-degree 1E+6 1E+7 1E+8
31 SpamMass Idea: Measure spam mass as the amount of PageRank score that a web page receives from web pages known to be spam Assume that web pages are parti0oned into good pages V + and bad pages V - and that a good core C V + is known Absolute spam mass of page p is then es0mated as SM (p) = π(p) π C (p) with π(p) as its PageRank score and πc (p) as its PageRank score with random jumps only to pages in the good core Rela0ve spam mass of page p is rsm (p) = SM (p)/π(p)
32 Link Analysis PageRank HITS Random Surfer Model, Markov Chains Hyperlinked- Induced Topic Search Topic- Specific and Personalized PageRank Biased Random Jumps, Linearity of PageRank Similarity Search SimRank, Random Walk with Restarts Spam Detec0on LinkSpam, TrustRank, SpamRank Social Networks SocialPageRank, TunkRank


 between")


")




33 Social Networks Social networks diverse rela0ons (e.g., friendship, liking, check- in, following) between diverse types of objects (e.g., people, en00es, posts, images, videos) Folksonomies (~ folk + taxonomy) allow users to organize objects by tagging no centrally controlled vocabulary Link analysis methods give insights into importance and similarity of objects (e.g., for ranking or recommenda0on)
34 TunkRank Idea: Measure a Twi}er user s influence as the expected number of people who will read a tweet (including re- tweets) by the user Considers Twi}er s follower graph G(V, E) consis0ng of users as ver0ces V and directed edges E with edge (i, j) indica0ng that user i follows user j Assump0ons: if i follows j, i reads tweet by j with probability 1 / out(i) constant re- twee0ng probability p r(j) = X (i,j)2e (1 + p r(i)) out(i) D. Tunkelang: A TwiGer Analog to PageRank, 2009 h\p://thenoisychannel.com/2009/01/13/a- twi\er- analog- to- pagerank/
35 Twi}erRank Considers Twi}er s follower graph G(V, E) consis0ng of users as ver0ces V and directed edges E with edge (i, j) indica0ng that user i follows user j PageRank- style random walk with link- following probabili0es T ij = ( N j P(i,k)2E N k sim(i, j) (i, j) 2 E 0 otherwise with N i as the number of tweets published by user i and sim(i, j) reflec0ng similarity between tweets by i and j J. Weng, E.- P. Lim, J. Jiang, and Q. He: TwiGerRank: finding topic- sensi,ve influen,al twigerers, WSDM 2010
36 Take- Home message Link analysis methods can be used to measure importance and similarity with applica0ons in search and recommenda0on is performed on the basis of finite and ergodic Markov Chains theory with computa0ons easily parallelizable MapReduce
CS60092: Informa0on Retrieval
 Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address ques)ons
Introduc)on to CS60092: Informa0on Retrieval Sourangshu Bha1acharya Today s lecture hypertext and links We look beyond the content of documents We begin to look at the hyperlinks between them Address ques)ons
Web consists of web pages and hyperlinks between pages. A page receiving many links from other pages may be a hint of the authority of the page
 Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Link Analysis Links Web consists of web pages and hyperlinks between pages A page receiving many links from other pages may be a hint of the authority of the page Links are also popular in some other information
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Chris Manning and Pandu Nayak Link analysis Today s lecture hypertext and links We look beyond the content of documents We
Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Chris Manning and Pandu Nayak Link analysis Today s lecture hypertext and links We look beyond the content of documents We
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Today s lecture hypertext and links
 Today s lecture hypertext and links Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Chris Manning and Pandu Nayak Link analysis We look beyond the content of documents We
Today s lecture hypertext and links Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Chris Manning and Pandu Nayak Link analysis We look beyond the content of documents We
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Link Structure Analysis
 Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
Link Structure Analysis Kira Radinsky All of the following slides are courtesy of Ronny Lempel (Yahoo!) Link Analysis In the Lecture HITS: topic-specific algorithm Assigns each page two scores a hub score
INTRODUCTION TO DATA SCIENCE. Link Analysis (MMDS5)
") INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
INTRODUCTION TO DATA SCIENCE Link Analysis (MMDS5) Introduction Motivation: accurate web search Spammers: want you to land on their pages Google s PageRank and variants TrustRank Hubs and Authorities (HITS)
Link Analysis. Hongning Wang
 Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
Link Analysis Hongning Wang CS@UVa Structured v.s. unstructured data Our claim before IR v.s. DB = unstructured data v.s. structured data As a result, we have assumed Document = a sequence of words Query
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
PPI Network Alignment Advanced Topics in Computa8onal Genomics
 PPI Network Alignment 02-715 Advanced Topics in Computa8onal Genomics PPI Network Alignment Compara8ve analysis of PPI networks across different species by aligning the PPI networks Find func8onal orthologs
PPI Network Alignment 02-715 Advanced Topics in Computa8onal Genomics PPI Network Alignment Compara8ve analysis of PPI networks across different species by aligning the PPI networks Find func8onal orthologs
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today
 HW3 will be posted today") 3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Web search before Google. (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.)
, The PageRank Citation Ranking: Bringing Order to the Web.)") ' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
Analysis of Large Graphs: TrustRank and WebSpam
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
An applica)on of Markov Chains: PageRank. Finding relevant informa)on on the Web
on of Markov Chains: PageRank. Finding relevant informa)on on the Web") An applica)on of Markov Chains: PageRank Finding relevant informa)on on the Web Please Par)cipate h>p://www.st.ewi.tudelc.nl/~marco/lectures.html How much do you know about PageRank? 1) Nothing. 2) I
An applica)on of Markov Chains: PageRank Finding relevant informa)on on the Web Please Par)cipate h>p://www.st.ewi.tudelc.nl/~marco/lectures.html How much do you know about PageRank? 1) Nothing. 2) I
CS6200 Information Retreival. The WebGraph. July 13, 2015
 CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
CS6200 Information Retreival The WebGraph The WebGraph July 13, 2015 1 Web Graph: pages and links The WebGraph describes the directed links between pages of the World Wide Web. A directed edge connects
Introduction to Data Mining
 Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Introduction to Data Mining Lecture #11: Link Analysis 3 Seoul National University 1 In This Lecture WebSpam: definition and method of attacks TrustRank: how to combat WebSpam HITS algorithm: another algorithm
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Lecture 27: Learning from relational data
 Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
World Wide Web has specific challenges and opportunities
 6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
6. Web Search Motivation Web search, as offered by commercial search engines such as Google, Bing, and DuckDuckGo, is arguably one of the most popular applications of IR methods today World Wide Web has
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
1 Starting around 1996, researchers began to work on. 2 In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a
 filed a") !"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
!"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Search Engines. Informa1on Retrieval in Prac1ce. Annota1ons by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annota1ons by Michael L. Nelson All slides Addison Wesley, 2008 Evalua1on Evalua1on is key to building effec$ve and efficient search engines measurement usually
Search Engines Informa1on Retrieval in Prac1ce Annota1ons by Michael L. Nelson All slides Addison Wesley, 2008 Evalua1on Evalua1on is key to building effec$ve and efficient search engines measurement usually
CS47300 Web Information Search and Management
 CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
CS47300 Web Information Search and Management Search Engine Optimization Prof. Chris Clifton 31 October 2018 What is Search Engine Optimization? 90% of search engine clickthroughs are on the first page
Social Networks Measures. Single- node Measures: Based on some proper7es of specific nodes Graph- based measures: Based on the graph- structure
 Social Networks Measures Single- node Measures: Based on some proper7es of specific nodes Graph- based measures: Based on the graph- structure of the network Graph- based measures of social influence Previously
Social Networks Measures Single- node Measures: Based on some proper7es of specific nodes Graph- based measures: Based on the graph- structure of the network Graph- based measures of social influence Previously
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Pagerank Scoring. Imagine a browser doing a random walk on web pages:
 Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
Ranking Sec. 21.2 Pagerank Scoring Imagine a browser doing a random walk on web pages: Start at a random page At each step, go out of the current page along one of the links on that page, equiprobably
Network Centrality. Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017
 Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Unit VIII. Chapter 9. Link Analysis
 Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Unit VIII Link Analysis: Page Ranking in web search engines, Efficient Computation of Page Rank using Map-Reduce and other approaches, Topic-Sensitive Page Rank, Link Spam, Hubs and Authorities (Text Book:2
Brief (non-technical) history
 history") Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Web Data Management Part 2 Advanced Topics in Database Management (INFSCI 2711) Textbooks: Database System Concepts - 2010 Introduction to Information Retrieval - 2008 Vladimir Zadorozhny, DINS, SCI, University
Introduction to Information Retrieval
 Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Introduction to Information Retrieval http://informationretrieval.org IIR 21: Link Analysis Hinrich Schütze Center for Information and Language Processing, University of Munich 2014-06-18 1/80 Overview
Graph Algorithms. Revised based on the slides by Ruoming Kent State
 Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Informa(on Retrieval
 Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 18: Link analysis Today s lecture hypertext and links We look beyond the content
Introduc*on to Informa(on Retrieval CS276 Informa*on Retrieval and Web Search Pandu Nayak and Prabhakar Raghavan Lecture 18: Link analysis Today s lecture hypertext and links We look beyond the content
Agenda. Math Google PageRank algorithm. 2 Developing a formula for ranking web pages. 3 Interpretation. 4 Computing the score of each page
 Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Informa/on Retrieval. Text Search. CISC437/637, Lecture #23 Ben CartereAe. Consider a database consis/ng of long textual informa/on fields
 Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
Informa/on Retrieval CISC437/637, Lecture #23 Ben CartereAe Copyright Ben CartereAe 1 Text Search Consider a database consis/ng of long textual informa/on fields News ar/cles, patents, web pages, books,
CSCI 599 Class Presenta/on. Zach Levine. Markov Chain Monte Carlo (MCMC) HMM Parameter Es/mates
 HMM Parameter Es/mates") CSCI 599 Class Presenta/on Zach Levine Markov Chain Monte Carlo (MCMC) HMM Parameter Es/mates April 26 th, 2012 Topics Covered in this Presenta2on A (Brief) Review of HMMs HMM Parameter Learning Expecta2on-
CSCI 599 Class Presenta/on Zach Levine Markov Chain Monte Carlo (MCMC) HMM Parameter Es/mates April 26 th, 2012 Topics Covered in this Presenta2on A (Brief) Review of HMMs HMM Parameter Learning Expecta2on-
COMP 4601 Hubs and Authorities
 COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
COMP 4601 Hubs and Authorities 1 Motivation PageRank gives a way to compute the value of a page given its position and connectivity w.r.t. the rest of the Web. Is it the only algorithm: No! It s just one
Social Networks 2015 Lecture 10: The structure of the web and link analysis
 04198250 Social Networks 2015 Lecture 10: The structure of the web and link analysis The structure of the web Information networks Nodes: pieces of information Links: different relations between information
04198250 Social Networks 2015 Lecture 10: The structure of the web and link analysis The structure of the web Information networks Nodes: pieces of information Links: different relations between information
Introduction to Data Mining
 Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University
 CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Instead of generic popularity, can we measure popularity within a topic? E.g., computer science, health Bias the random walk When
Link Analysis in Web Mining
 Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Problem formulation (998) Link Analysis in Web Mining Hubs and Authorities Spam Detection Suppose we are given a collection of documents on some broad topic e.g., stanford, evolution, iraq perhaps obtained
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/6/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 High dim. data Graph data Infinite data Machine
Page rank computation HPC course project a.y Compute efficient and scalable Pagerank
 Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Recent Researches on Web Page Ranking
 Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
CS395T Visual Recogni5on and Search. Gautam S. Muralidhar
 CS395T Visual Recogni5on and Search Gautam S. Muralidhar Today s Theme Unsupervised discovery of images Main mo5va5on behind unsupervised discovery is that supervision is expensive Common tasks include
CS395T Visual Recogni5on and Search Gautam S. Muralidhar Today s Theme Unsupervised discovery of images Main mo5va5on behind unsupervised discovery is that supervision is expensive Common tasks include
Query Sugges*ons. Debapriyo Majumdar Information Retrieval Spring 2015 Indian Statistical Institute Kolkata
 Query Sugges*ons Debapriyo Majumdar Information Retrieval Spring 2015 Indian Statistical Institute Kolkata Search engines User needs some information search engine tries to bridge this gap ssumption: the
Query Sugges*ons Debapriyo Majumdar Information Retrieval Spring 2015 Indian Statistical Institute Kolkata Search engines User needs some information search engine tries to bridge this gap ssumption: the
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis
 Chapter 21 Link analysis") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis Content Anchor text Link analysis for ranking Pagerank and variants HITS The Web as a Directed Graph Page A Anchor
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 21 Link analysis Content Anchor text Link analysis for ranking Pagerank and variants HITS The Web as a Directed Graph Page A Anchor
SEMINAR: GRAPH-BASED METHODS FOR NLP
 SEMINAR: GRAPH-BASED METHODS FOR NLP Organisatorisches: Seminar findet komplett im Mai statt Seminarausarbeitungen bis 15. Juli (?) Hilfen Seminarvortrag / Ausarbeitung auf der Webseite Tucan number for
SEMINAR: GRAPH-BASED METHODS FOR NLP Organisatorisches: Seminar findet komplett im Mai statt Seminarausarbeitungen bis 15. Juli (?) Hilfen Seminarvortrag / Ausarbeitung auf der Webseite Tucan number for
Search Engines. Informa1on Retrieval in Prac1ce. Annotations by Michael L. Nelson
 Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
Search Engines Informa1on Retrieval in Prac1ce Annotations by Michael L. Nelson All slides Addison Wesley, 2008 Indexes Indexes are data structures designed to make search faster Text search has unique
PageRank Algorithm Abstract: Keywords: I. Introduction II. Text Ranking Vs. Page Ranking
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 1, Ver. III (Jan.-Feb. 2017), PP 01-07 www.iosrjournals.org PageRank Algorithm Albi Dode 1, Silvester
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 19, Issue 1, Ver. III (Jan.-Feb. 2017), PP 01-07 www.iosrjournals.org PageRank Algorithm Albi Dode 1, Silvester
Advanced Computer Architecture: A Google Search Engine
 Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
TODAY S LECTURE HYPERTEXT AND
 LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
LINK ANALYSIS TODAY S LECTURE HYPERTEXT AND LINKS We look beyond the content of documents We begin to look at the hyperlinks between them Address questions like Do the links represent a conferral of authority
Graphs / Networks. CSE 6242/ CX 4242 Feb 18, Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
Social Dynamics of Informa0on Kris0na Lerman USC Informa0on Sciences Ins0tute
 Social Dynamics of Informa0on Kris0na Lerman USC Informa0on Sciences Ins0tute h"p://www.isi.edu/~lerman Social media has changed how people create, share and consume informa:on h"p://blog.socialflow.com/post/5246404319/
Social Dynamics of Informa0on Kris0na Lerman USC Informa0on Sciences Ins0tute h"p://www.isi.edu/~lerman Social media has changed how people create, share and consume informa:on h"p://blog.socialflow.com/post/5246404319/
Jeffrey D. Ullman Stanford University/Infolab
 Jeffrey D. Ullman Stanford University/Infolab Spamming = any deliberate action intended solely to boost a Web page s position in searchengine results. Web Spam = Web pages that are the result of spamming.
Jeffrey D. Ullman Stanford University/Infolab Spamming = any deliberate action intended solely to boost a Web page s position in searchengine results. Web Spam = Web pages that are the result of spamming.
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Information Networks: Hubs and Authorities
 Information Networks: Hubs and Authorities Web Science (VU) (706.716) Elisabeth Lex KTI, TU Graz June 11, 2018 Elisabeth Lex (KTI, TU Graz) Links June 11, 2018 1 / 61 Repetition Opinion Dynamics Culture
Information Networks: Hubs and Authorities Web Science (VU) (706.716) Elisabeth Lex KTI, TU Graz June 11, 2018 Elisabeth Lex (KTI, TU Graz) Links June 11, 2018 1 / 61 Repetition Opinion Dynamics Culture
A Modified Algorithm to Handle Dangling Pages using Hypothetical Node
 A Modified Algorithm to Handle Dangling Pages using Hypothetical Node Shipra Srivastava Student Department of Computer Science & Engineering Thapar University, Patiala, 147001 (India) Rinkle Rani Aggrawal
A Modified Algorithm to Handle Dangling Pages using Hypothetical Node Shipra Srivastava Student Department of Computer Science & Engineering Thapar University, Patiala, 147001 (India) Rinkle Rani Aggrawal
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
Social Network Analysis
 Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material.
 Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
About the Course. Reading List. Assignments and Examina5on
 Uppsala University Department of Linguis5cs and Philology About the Course Introduc5on to machine learning Focus on methods used in NLP Decision trees and nearest neighbor methods Linear models for classifica5on
Uppsala University Department of Linguis5cs and Philology About the Course Introduc5on to machine learning Focus on methods used in NLP Decision trees and nearest neighbor methods Linear models for classifica5on
DSCI 575: Advanced Machine Learning. PageRank Winter 2018
 DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
Exploring both Content and Link Quality for Anti-Spamming
 Exploring both Content and Link Quality for Anti-Spamming Lei Zhang, Yi Zhang, Yan Zhang National Laboratory on Machine Perception Peking University 100871 Beijing, China zhangl, zhangyi, zhy @cis.pku.edu.cn
Exploring both Content and Link Quality for Anti-Spamming Lei Zhang, Yi Zhang, Yan Zhang National Laboratory on Machine Perception Peking University 100871 Beijing, China zhangl, zhangyi, zhy @cis.pku.edu.cn
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Recommender Systems Collabora2ve Filtering and Matrix Factoriza2on
 Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
Recommender Systems Collaborave Filtering and Matrix Factorizaon Narges Razavian Thanks to lecture slides from Alex Smola@CMU Yahuda Koren@Yahoo labs and Bing Liu@UIC We Know What You Ought To Be Watching
CS6200 Informa.on Retrieval. David Smith College of Computer and Informa.on Science Northeastern University
 CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
CS6200 Informa.on Retrieval David Smith College of Computer and Informa.on Science Northeastern University Indexing Process Indexes Indexes are data structures designed to make search faster Text search
Lec 8: Adaptive Information Retrieval 2
 Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Lec 8: Adaptive Information Retrieval 2 Advaith Siddharthan Introduction to Information Retrieval by Manning, Raghavan & Schütze. Website: http://nlp.stanford.edu/ir-book/ Linear Algebra Revision Vectors:
Fast Iterative Solvers for Markov Chains, with Application to Google's PageRank. Hans De Sterck
 Fast Iterative Solvers for Markov Chains, with Application to Google's PageRank Hans De Sterck Department of Applied Mathematics University of Waterloo, Ontario, Canada joint work with Steve McCormick,
Fast Iterative Solvers for Markov Chains, with Application to Google's PageRank Hans De Sterck Department of Applied Mathematics University of Waterloo, Ontario, Canada joint work with Steve McCormick,
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Jeffrey D. Ullman Stanford University 3 Mutually recursive definition: A hub links to many authorities; An authority is linked to by many hubs. Authorities turn out to be places where information can
Graph-Parallel Problems. ML in the Context of Parallel Architectures
 Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
Link Analysis. Paolo Boldi DSI LAW (Laboratory for Web Algorithmics) Università degli Studi di Milan
 Università degli Studi di Milan") DSI LAW (Laboratory for Web Algorithmics) Università degli Studi di Milan Ranking, search engines, social networks Ranking is of uttermost importance in IR, search engines and also in other social networks
DSI LAW (Laboratory for Web Algorithmics) Università degli Studi di Milan Ranking, search engines, social networks Ranking is of uttermost importance in IR, search engines and also in other social networks
Oral Exams Dates. Distributed Data Management Summer Semester 2013 TU Kaiserslautern. Recap: Map and Reduce. (Equi) Join of 3 Rela9ons
 Join of 3 Rela9ons") Oral Exams Dates Distributed Data Management Summer Semester 203 TU Kaiserslautern Dr.- Ing. Sebas9an Michel smichel@mmci.uni- saarland.de Note: Last week of teaching at University, SS 3 July 5 - July
Oral Exams Dates Distributed Data Management Summer Semester 203 TU Kaiserslautern Dr.- Ing. Sebas9an Michel smichel@mmci.uni- saarland.de Note: Last week of teaching at University, SS 3 July 5 - July
F. Aiolli - Sistemi Informativi 2007/2008. Web Search before Google
 Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Web Search Engines 1 Web Search before Google Web Search Engines (WSEs) of the first generation (up to 1998) Identified relevance with topic-relateness Based on keywords inserted by web page creators (META
Machine Learning Crash Course: Part I
 Machine Learning Crash Course: Part I Ariel Kleiner August 21, 2012 Machine learning exists at the intersec
Machine Learning Crash Course: Part I Ariel Kleiner August 21, 2012 Machine learning exists at the intersec
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule
 Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Lecture Notes: Social Networks: Models, Algorithms, and Applications Lecture 28: Apr 26, 2012 Scribes: Mauricio Monsalve and Yamini Mule 1 How big is the Web How big is the Web? In the past, this question
Generalized Social Networks. Social Networks and Ranking. How use links to improve information search? Hypertext
 Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
Generalized Social Networs Social Networs and Raning Represent relationship between entities paper cites paper html page lins to html page A supervises B directed graph A and B are friends papers share
Web Spam. Seminar: Future Of Web Search. Know Your Neighbors: Web Spam Detection using the Web Topology
 Seminar: Future Of Web Search University of Saarland Web Spam Know Your Neighbors: Web Spam Detection using the Web Topology Presenter: Sadia Masood Tutor : Klaus Berberich Date : 17-Jan-2008 The Agenda
Seminar: Future Of Web Search University of Saarland Web Spam Know Your Neighbors: Web Spam Detection using the Web Topology Presenter: Sadia Masood Tutor : Klaus Berberich Date : 17-Jan-2008 The Agenda
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Motivation. Motivation
 COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
Corso di Biblioteche Digitali
 Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
Corso di Biblioteche Digitali Vittore Casarosa casarosa@isti.cnr.it tel. 050-315 3115 cell. 348-397 2168 Ricevimento dopo la lezione o per appuntamento Valutazione finale 70-75% esame orale 25-30% progetto
A Survey of Google's PageRank
 http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
CS 6604: Data Mining Large Networks and Time-Series
 CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking
CS 6604: Data Mining Large Networks and Time-Series Soumya Vundekode Lecture #12: Centrality Metrics Prof. B Aditya Prakash Agenda Link Analysis and Web Search Searching the Web: The Problem of Ranking