Navigating the Web graph
|
|
|
- Megan Nichols
- 5 years ago
- Views:
Transcription




1 Navigating the Web graph Workshop on Networks and Navigation Santa Fe Institute, August 2008 Filippo Menczer Informatics & Computer Science Indiana University, Bloomington
2 Outline Topical locality: Content, link, and semantic topologies Implications for growth models and navigation Applications Topical Web crawlers Distributed collaborative peer search
3 The Web as a text corpus Pages close in word vector space tend to be related Cluster hypothesis (van Rijsbergen 1979) mass destruction p 1 p 2 weapons The WebCrawler (Pinkerton 1994) The whole first generation of search engines
 = α N")
 l : j")

4 Enter the Web s link structure p(i) = α N + (1 α) j:j i Brin & Page 1998 p(j) l : j l Barabasi & Albert 1999 Broder & al. 2000
5 Three network topologies Text Links
6 Three network topologies Text Meaning Links
7 The link-cluster conjecture Connection between semantic topology (topicality or relevance) and link topology (hypertext) G = Pr[rel(p)] ~ fraction of relevant pages (generality) R = Pr[rel(p) rel(q) AND link(q,p)] Related nodes are clustered if R > G (modularity) Necessary and sufficient condition for a random crawler to find pages related to start points G = 5/15 C = 2 R = 3/6 = 2/4 ICML 1997
) G η(t) η t η G = 1 (R G) η > G R > G η G 1 = R G 1 (R G) Conjecture Value")
8 Link-cluster conjecture Stationary hit rate for a random crawler: η(t + 1) = η(t) R + (1 η(t)) G η(t) η t η G = 1 (R G) η > G R > G η G 1 = R G 1 (R G) Conjecture Value added
![R(q,δ) G(q) Pr[ rel( p) rel(q) path(q, p) δ] Pr[rel(p)] Link-cluster conjecture Pages that link to each other tend to be](/docs-images/83/87491407/images/9-1.jpg "related Preservation of semantics (meaning) A.k.a. topic drift L(q,δ) { p: path(q,p) δ } path(q, p) {p : path(q, p) δ} JASIST 2004")
9 R(q,δ) G(q) Pr[ rel( p) rel(q) path(q, p) δ] Pr[rel(p)] Link-cluster conjecture Pages that link to each other tend to be related Preservation of semantics (meaning) A.k.a. topic drift L(q,δ) { p: path(q,p) δ } path(q, p) {p : path(q, p) δ} JASIST 2004
: average link distance S(δ): average similarity to start (topic) page from pages up to distance δ Correlation ρ(l,s) = 0.")
10 The link-content conjecture Correlation of lexical and linkage topology S(q,δ) { p: path(q,p) δ } sim(q, p) {p : path(q, p) δ} L(δ): average link distance S(δ): average similarity to start (topic) page from pages up to distance δ Correlation ρ(l,s) =
 signif. diff. a & b (p<0.")
11 Heterogeneity of link-content correlation S = c + (1 c)e alb edu net gov org com signif. diff. a only (p<0.05) signif. diff. a & b (p<0.05)
12 Mapping the relationship between links, content, and semantic topologies Given any pair of pages, need similarity or proximity metric for each topology: Content: textual/lexical (cosine) similarity Link: co-citation/bibliographic coupling Semantic: relatedness inferred from manual classification Data: Open Directory Project (dmoz.org) ~ 1 M pages after cleanup ~ 1.3*10 12 page pairs!

 = U p 1 U p2 U p1")
13 σ ( c p 1, p ) 2 = p 1 p 2 p 1 p 2 term j p 1 p 2 Content similarity term k term i Link similarity p 1 p 2 σ l ( p 1, p 2 ) = U p 1 U p2 U p1 U p2
 = 2logPr[lca(c 1,c 2 )] logpr[c 1 ] + logpr[c 2 ] Classic path distance in special case of balanced tree")
14 Semantic similarity top lca c 2 c 1 Information-theoretic measure based on classification tree (Lin 1998) σ s (c 1,c 2 ) = 2logPr[lca(c 1,c 2 )] logpr[c 1 ] + logpr[c 2 ] Classic path distance in special case of balanced tree
15 Individual metric distributions conten t semantic link
16 Precision = Recall = Retrieved & Relevant Retrieved Retrieved & Relevant Relevant
17 Precision = Recall = Retrieved & Relevant Retrieved Retrieved & Relevant Relevant P(s c,s l ) = { p,q:σ c = s c,σ l = s l } σ s ( p,q) {p,q :σ c = s c,σ l = s l } Averaging semantic similarity R(s c,s l ) = { p,q:σ c = s c,σ l = s l } { p,q} σ s ( p,q) σ s ( p,q) Summing semantic similarity


18 Science log Recall σ l Precision σ c

19 log Recall Adult σ l Precision σ c
20 log Recall News σ l Precision σ c
21 All pairs log Recall σ l Precision σ c
22 Outline Topical locality: Content, link, and semantic topologies Implications for growth models and navigation Applications Topical Web crawlers Distributed collaborative peer search
23 Link probability vs lexical distance r =1 σ c 1 Pr(λ ρ) = ( p,q) : r = ρ σ l > λ ( p,q) : r = ρ
 ~ ρ α(λ) Proc. Natl. Acad. Sci.")
24 Link probability vs lexical distance r =1 σ c 1 Pr(λ ρ) = ( p,q) : r = ρ σ l > λ ( p,q) : r = ρ Phase transition ρ * Power law tail Pr(λ ρ) ~ ρ α(λ) Proc. Natl. Acad. Sci. USA 99(22): , 2002
 = i, p t ) < ρ * mt c[r(p i, p t )] α otherwise")
 only for nearby (similar/")
25 Local content-based growth model k(i) if r( p Pr(p t p i<t ) = i, p t ) < ρ * mt c[r(p i, p t )] α otherwise Similar to preferential attachment (BA) Use degree info (popularity/ importance) only for nearby (similar/ related) pages
26 So, many models can predict degree distributions... Which is right? Need an independent observation (other than degree) to validate models Distribution of content similarity across linked pairs
27 None of these models is right!
28 The mixture model Pr(i) ψ 1 degree-uniform mixture t + (1 ψ) k(i) mt a i 2 b i 2 c i 2 i 1 i 1 i 1 t i 3 t i 3 t i 3
29 The mixture model Pr(i) ψ 1 degree-uniform mixture t + (1 ψ) k(i) mt a i 2 b i 2 c i 2 i 1 i 1 i 1 t i 3 t i 3 t i 3 Bias choice by content similarity instead of uniform distribution
30 Degree-similarity mixture model Pr(i) ψ ˆPr(i) + (1 ψ) k(i) mt
 k(i) mt ˆPr(i) [r(i, t)] α ψ = 0.2, α = 1.")
31 Degree-similarity mixture model Pr(i) ψ ˆPr(i) + (1 ψ) k(i) mt ˆPr(i) [r(i, t)] α ψ = 0.2, α = 1.7
32 Both mixture models get the degree distribution right
33 but the degree-similarity mixture model predicts the similarity distribution better Proc. Natl. Acad. Sci. USA 101: , 2004
34 Citation networks 1 PNAS 15,785 articles published in PNAS between 1997 and 2002! l ! c
35 Citation networks

36 Citation networks

37 Open Questions Understand distribution of content similarity across all pairs of pages Growth model to explain co-evolution of both link topology and content similarity The role of search engines
38 Efficient crawling algorithms? Theory: since the Web is a small world network, or has a scale free degree distribution, short paths exist between any two pages: ~ log N (Barabasi & Albert 1999) ~ log N / log log N (Bollobas 2001)
39 Efficient crawling algorithms? Theory: since the Web is a small world network, or has a scale free degree distribution, short paths exist between any two pages: ~ log N (Barabasi & Albert 1999) ~ log N / log log N (Bollobas 2001) Practice: can t find them! Greedy algorithms based on location in geographical small world networks: ~ poly(n) (Kleinberg 2000) Greedy algorithms based on degree in power law networks: ~ N (Adamic, Huberman & al. 2001)
40 Exception # 1 Geographical networks (Kleinberg 2000) Local links to all lattice neighbors Long-range link probability distribution: power law Pr ~ r α r: lattice (Manhattan) distance α: constant clustering exponent t ~ log 2 N α = D
 1 local")
41 Is the Web a geographical network? Replace lattice distance by lexical distance r = (1 / σ c ) 1 local links long range links (power law tail)
42 Exception # 2 h=1 h=2 Hierarchical networks (Kleinberg 2002, Watts & al. 2002) Nodes are classified at the leaves of tree Link probability distribution: exponential tail Pr ~ e h h: tree distance (height of lowest common ancestor) t ~ log ε N,ε 1

43 Is the Web a hierarchical network? Replace tree distance by semantic distance h = 1 σ s top exponential tail lca c 2 c 1
44 Take home message: the Web is a friendly place!
45 Outline Topical locality: Content, link, and semantic topologies Implications for growth models and navigation Applications Topical Web crawlers Distributed collaborative peer search
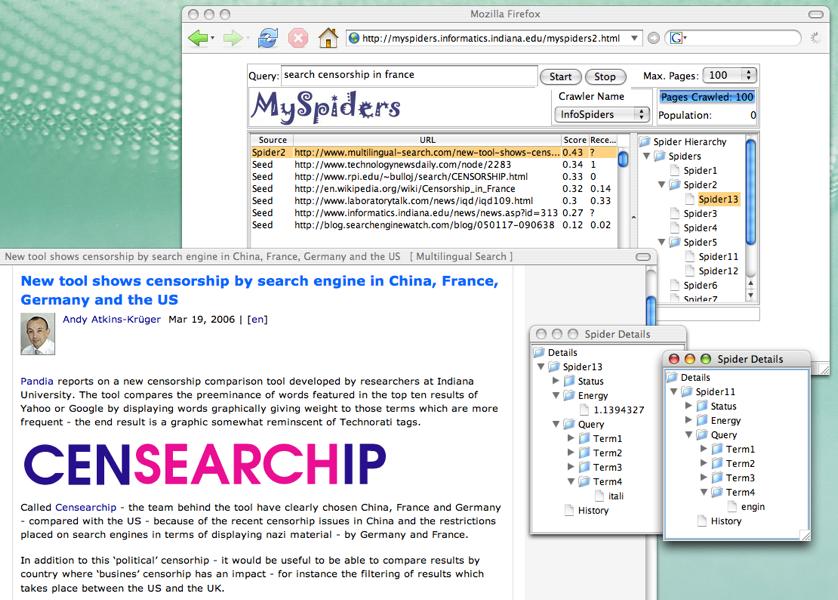
46 Crawler applications Universal Crawlers Search engines! Topical crawlers Live search (e.g., myspiders.informatics.indiana.edu) Topical search engines & portals Business intelligence (find competitors/partners) Distributed, collaborative search


47 Topical [sic] crawlers spears
48 Evaluating topical crawlers Goal: build better crawlers to support applications Build an unbiased evaluation framework Define common tasks of measurable difficulty Identify topics, relevant targets Identify appropriate performance measures Effectiveness: quality of crawler pages, order, etc. Efficiency: separate CPU & memory of crawler algorithms from bandwidth & common utilities Information Retrieval 2005

49 Evaluating topical crawlers: Topics Automate evaluation using edited directories Different sources of relevance assessments Keywords Description Targets
50 Evaluating topical crawlers: Tasks Start from seeds, find targets and/or pages similar to target descriptions d=3 d=2
51 Examples of crawling algorithms Breadth-First Visit links in order encountered Best-First Priority queue sorted by similarity Variants: explore top N at a time tag tree context hub scores SharkSearch Priority queue sorted by combination of similarity, anchor text, similarity of parent, etc. InfoSpiders
52 Examples of crawling algorithms Breadth-First Visit links in order encountered Best-First Priority queue sorted by similarity Variants: explore top N at a time tag tree context hub scores SharkSearch Priority queue sorted by combination of similarity, anchor text, similarity of parent, etc. InfoSpiders
53 Exploration vs. Exploitation Avg target recall Pages crawled

54 Co-citation: hub scores Link score hub = linear combination between link and hub score
55 Recall (159 ODP topics) average target (%) Breadth-First Naive Best-First DOM Hub-Seeker average target (%) Breadth-First Naive Best-First DOM Hub-Seeker N (pages crawled) N (pages crawled) Split ODP URLs between seeds and targets Add 10 best hubs to seeds for 94 topics ECDL 2003
56 InfoSpiders adaptive distributed algorithm using an evolving population of learning agents
57 InfoSpiders adaptive distributed algorithm using an evolving population of learning agents local frontier keyword vector neural net
58 InfoSpiders adaptive distributed algorithm using an evolving population of learning agents local frontier keyword vector neural net offspring
59
60
61
62 match resource bias Evolutionary Local Selection Algorithm (ELSA) Foreach agent thread: Pick & follow link from local frontier Evaluate new links, merge frontier Adjust link estimator E := E + payoff - cost If E < 0: Die reinforcement learning Elsif E > Selection_Threshold: Clone offspring Split energy with offspring Split frontier with offspring Mutate offspring selective query expansion


63 Action selection
64 Q-learning Compare estimated relevance of visited document with estimated relevance of link followed from previous page Teaching input: E(D) + µ max l(d) λ l

65 Performance Avg target recall Pages crawled ACM Trans. Internet Technology 2003
66

67
68

69
70
71 WWW 6S: Collaborative Peer Search bookmarks Index Crawler Peer query query local storage query A query B WWW2004 WWW2005 WTAS2005 P2PIR2006 query C
72 WWW 6S: Collaborative Peer Search bookmarks Index Crawler Peer query query local storage query query A hit B WWW2004 WWW2005 WTAS2005 P2PIR2006 query hit Data mining & referral opportunities C
73 WWW 6S: Collaborative Peer Search bookmarks Index Crawler Peer query query local storage query query A hit B WWW2004 WWW2005 WTAS2005 P2PIR2006 query hit Data mining & referral opportunities C Emerging communities

74 Reinforcement Learning

75 Query Routing

76 Simulating 500 Users ODP (dmoz.org) Maguitman, Menczer et al.: Algorithmic computation and approximation of semantic similarity. WWW2005, WWWJ 2006
77 Simulating 500 Users ODP (dmoz.org) Maguitman, Menczer et al.: Algorithmic computation and approximation of semantic similarity. WWW2005, WWWJ 2006
 Maguitman, Menczer et al.")

78 Simulating 500 Users ODP (dmoz.org) Maguitman, Menczer et al.: Algorithmic computation and approximation of semantic similarity. WWW2005, WWWJ 2006

79
80 Precision S Centralized Search Engine Google Recall Distributed vs Centralized
81 #%! 39)-:*+.3;*<<,3,*5: =,0>*:*+ #$! #!! 01*+02*.34052*.678 '! &! %! $!!!$!! " #! #" $! $" ()*+,*-./*+./**+ Small-world
82 Semantic Similarity



83 Business/E-Commerce/Developers Business/Telecommunications/Call_Centers Computers/Programming/Graphics Shopping/Clothing/Accessories Shopping/Sports/Cycling Semantic Similarity Sports/Cycling/Racing Business/Arts_and_Entertainment/Fashion Shopping/Clothing/Footwear Shopping/Clothing/Uniforms Arts/Movies/Filmmaking Shopping/Visual_Arts/Artist_Created_Prints Health/Professions/Midwifery Health/Reproductive_Health/Birth_Control Home/Family/Pregnancy Society/Issues/Abortion Health/Conditions_and_Diseases/Cancer Health/Mental_Health/Grief,_Loss_and_Bereavement Society/People/Women
84 Ongoing Work Improve coverage/diversity in query routing algorithm Spam protection: trust/reputation subsystem User study with 6S application

85 User study

86 Query network

87 Result network

88 Questions?


89 Thank you! Questions? informatics.indiana.edu/fil Research supported by NSF CAREER Award IIS
Web Structure & Content (not a theory talk)
") Web Structure & Content (not a theory talk) Filippo Menczer The University of Iowa http://dollar.biz.uiowa.edu/~fil/ Research supported by NSF CAREER Award IIS-0133124 Exploiting the Web s text and link
Web Structure & Content (not a theory talk) Filippo Menczer The University of Iowa http://dollar.biz.uiowa.edu/~fil/ Research supported by NSF CAREER Award IIS-0133124 Exploiting the Web s text and link
arxiv:cs/ v1 [cs.ir] 26 Apr 2002
![arxiv:cs/ v1 [cs.ir] 26 Apr 2002](/thumbs/91/105111363.jpg "arxiv:cs/ v1 [cs.ir] 26 Apr 2002") Navigating the Small World Web by Textual Cues arxiv:cs/0204054v1 [cs.ir] 26 Apr 2002 Filippo Menczer Department of Management Sciences The University of Iowa Iowa City, IA 52242 Phone: (319) 335-0884
Navigating the Small World Web by Textual Cues arxiv:cs/0204054v1 [cs.ir] 26 Apr 2002 Filippo Menczer Department of Management Sciences The University of Iowa Iowa City, IA 52242 Phone: (319) 335-0884
A Framework for adaptive focused web crawling and information retrieval using genetic algorithms
 A Framework for adaptive focused web crawling and information retrieval using genetic algorithms Kevin Sebastian Dept of Computer Science, BITS Pilani kevseb1993@gmail.com 1 Abstract The web is undeniably
A Framework for adaptive focused web crawling and information retrieval using genetic algorithms Kevin Sebastian Dept of Computer Science, BITS Pilani kevseb1993@gmail.com 1 Abstract The web is undeniably
The link structure of the Web is attracting considerable
 Growing and navigating the small world Web by local content Filippo Menczer Department of Management Sciences, University of Iowa, Iowa City, IA 52242 Edited by Elwyn R. Berlekamp, University of California,
Growing and navigating the small world Web by local content Filippo Menczer Department of Management Sciences, University of Iowa, Iowa City, IA 52242 Edited by Elwyn R. Berlekamp, University of California,
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
MAE 298, Lecture 9 April 30, Web search and decentralized search on small-worlds
 MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
MAE 298, Lecture 9 April 30, 2007 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in
Focused crawling: a new approach to topic-specific Web resource discovery. Authors
 Focused crawling: a new approach to topic-specific Web resource discovery Authors Soumen Chakrabarti Martin van den Berg Byron Dom Presented By: Mohamed Ali Soliman m2ali@cs.uwaterloo.ca Outline Why Focused
Focused crawling: a new approach to topic-specific Web resource discovery Authors Soumen Chakrabarti Martin van den Berg Byron Dom Presented By: Mohamed Ali Soliman m2ali@cs.uwaterloo.ca Outline Why Focused
Personalizing PageRank Based on Domain Profiles
 Personalizing PageRank Based on Domain Profiles Mehmet S. Aktas, Mehmet A. Nacar, and Filippo Menczer Computer Science Department Indiana University Bloomington, IN 47405 USA {maktas,mnacar,fil}@indiana.edu
Personalizing PageRank Based on Domain Profiles Mehmet S. Aktas, Mehmet A. Nacar, and Filippo Menczer Computer Science Department Indiana University Bloomington, IN 47405 USA {maktas,mnacar,fil}@indiana.edu
Wednesday, March 8, Complex Networks. Presenter: Jirakhom Ruttanavakul. CS 790R, University of Nevada, Reno
 Wednesday, March 8, 2006 Complex Networks Presenter: Jirakhom Ruttanavakul CS 790R, University of Nevada, Reno Presented Papers Emergence of scaling in random networks, Barabási & Bonabeau (2003) Scale-free
Wednesday, March 8, 2006 Complex Networks Presenter: Jirakhom Ruttanavakul CS 790R, University of Nevada, Reno Presented Papers Emergence of scaling in random networks, Barabási & Bonabeau (2003) Scale-free
Web Crawling As Nonlinear Dynamics
 Progress in Nonlinear Dynamics and Chaos Vol. 1, 2013, 1-7 ISSN: 2321 9238 (online) Published on 28 April 2013 www.researchmathsci.org Progress in Web Crawling As Nonlinear Dynamics Chaitanya Raveendra
Progress in Nonlinear Dynamics and Chaos Vol. 1, 2013, 1-7 ISSN: 2321 9238 (online) Published on 28 April 2013 www.researchmathsci.org Progress in Web Crawling As Nonlinear Dynamics Chaitanya Raveendra
Part I: Data Mining Foundations
 Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web and the Internet 2 1.3. Web Data Mining 4 1.3.1. What is Data Mining? 6 1.3.2. What is Web Mining?
Overlay (and P2P) Networks
 Networks") Overlay (and P2P) Networks Part II Recap (Small World, Erdös Rényi model, Duncan Watts Model) Graph Properties Scale Free Networks Preferential Attachment Evolving Copying Navigation in Small World Samu
Overlay (and P2P) Networks Part II Recap (Small World, Erdös Rényi model, Duncan Watts Model) Graph Properties Scale Free Networks Preferential Attachment Evolving Copying Navigation in Small World Samu
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p.
 Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
Introduction p. 1 What is the World Wide Web? p. 1 A Brief History of the Web and the Internet p. 2 Web Data Mining p. 4 What is Data Mining? p. 6 What is Web Mining? p. 6 Summary of Chapters p. 8 How
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 CS 347 Notes 12 5 Web Search Engine Crawling
CS 347 Parallel and Distributed Data Processing
 CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
CS 347 Parallel and Distributed Data Processing Spring 2016 Notes 12: Distributed Information Retrieval CS 347 Notes 12 2 CS 347 Notes 12 3 CS 347 Notes 12 4 Web Search Engine Crawling Indexing Computing
Mapping the Semantics of Web Text and Links
 Mapping the Semantics of Web Text and Links Needles and Haystacks Search engines use content and links to search, rank, cluster, and classify Web pages. These information discovery applications use similarity
Mapping the Semantics of Web Text and Links Needles and Haystacks Search engines use content and links to search, rank, cluster, and classify Web pages. These information discovery applications use similarity
ECS 289 / MAE 298, Lecture 9 April 29, Web search and decentralized search on small-worlds
 ECS 289 / MAE 298, Lecture 9 April 29, 2014 Web search and decentralized search on small-worlds Announcements HW2 and HW2b now posted: Due Friday May 9 Vikram s ipython and NetworkX notebooks posted Project
ECS 289 / MAE 298, Lecture 9 April 29, 2014 Web search and decentralized search on small-worlds Announcements HW2 and HW2b now posted: Due Friday May 9 Vikram s ipython and NetworkX notebooks posted Project
Searching the Web [Arasu 01]
![Searching the Web [Arasu 01]](/thumbs/74/70312179.jpg "Searching the Web [Arasu 01]") Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
Searching the Web [Arasu 01] Most user simply browse the web Google, Yahoo, Lycos, Ask Others do more specialized searches web search engines submit queries by specifying lists of keywords receive web
DATA MINING II - 1DL460. Spring 2014"
 DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2014" A second course in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt14 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Information Retrieval Spring Web retrieval
 Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
Information Retrieval Spring 2016 Web retrieval The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically infinite due to the dynamic
An Evolving Network Model With Local-World Structure
 The Eighth International Symposium on Operations Research and Its Applications (ISORA 09) Zhangjiajie, China, September 20 22, 2009 Copyright 2009 ORSC & APORC, pp. 47 423 An Evolving Network odel With
The Eighth International Symposium on Operations Research and Its Applications (ISORA 09) Zhangjiajie, China, September 20 22, 2009 Copyright 2009 ORSC & APORC, pp. 47 423 An Evolving Network odel With
FILTERING OF URLS USING WEBCRAWLER
 FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
FILTERING OF URLS USING WEBCRAWLER Arya Babu1, Misha Ravi2 Scholar, Computer Science and engineering, Sree Buddha college of engineering for women, 2 Assistant professor, Computer Science and engineering,
NUCLEAR EXPERT WEB MINING SYSTEM: MONITORING AND ANALYSIS OF NUCLEAR ACCEPTANCE BY INFORMATION RETRIEVAL AND OPINION EXTRACTION ON THE INTERNET
 2011 International Nuclear Atlantic Conference - INAC 2011 Belo Horizonte, MG, Brazil, October 24-28, 2011 ASSOCIAÇÃO BRASILEIRA DE ENERGIA NUCLEAR - ABEN ISBN: 978-85-99141-04-5 NUCLEAR EXPERT WEB MINING
2011 International Nuclear Atlantic Conference - INAC 2011 Belo Horizonte, MG, Brazil, October 24-28, 2011 ASSOCIAÇÃO BRASILEIRA DE ENERGIA NUCLEAR - ABEN ISBN: 978-85-99141-04-5 NUCLEAR EXPERT WEB MINING
Bing Liu. Web Data Mining. Exploring Hyperlinks, Contents, and Usage Data. With 177 Figures. Springer
 Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Bing Liu Web Data Mining Exploring Hyperlinks, Contents, and Usage Data With 177 Figures Springer Table of Contents 1. Introduction 1 1.1. What is the World Wide Web? 1 1.2. A Brief History of the Web
Improving Relevance Prediction for Focused Web Crawlers
 2012 IEEE/ACIS 11th International Conference on Computer and Information Science Improving Relevance Prediction for Focused Web Crawlers Mejdl S. Safran 1,2, Abdullah Althagafi 1 and Dunren Che 1 Department
2012 IEEE/ACIS 11th International Conference on Computer and Information Science Improving Relevance Prediction for Focused Web Crawlers Mejdl S. Safran 1,2, Abdullah Althagafi 1 and Dunren Che 1 Department
CS224W: Social and Information Network Analysis Project Report: Edge Detection in Review Networks
 CS224W: Social and Information Network Analysis Project Report: Edge Detection in Review Networks Archana Sulebele, Usha Prabhu, William Yang (Group 29) Keywords: Link Prediction, Review Networks, Adamic/Adar,
CS224W: Social and Information Network Analysis Project Report: Edge Detection in Review Networks Archana Sulebele, Usha Prabhu, William Yang (Group 29) Keywords: Link Prediction, Review Networks, Adamic/Adar,
Dynamic network generative model
 Dynamic network generative model Habiba, Chayant Tantipathanananandh, Tanya Berger-Wolf University of Illinois at Chicago. In this work we present a statistical model for generating realistic dynamic networks
Dynamic network generative model Habiba, Chayant Tantipathanananandh, Tanya Berger-Wolf University of Illinois at Chicago. In this work we present a statistical model for generating realistic dynamic networks
Web Structure Mining using Link Analysis Algorithms
 Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Web Structure Mining using Link Analysis Algorithms Ronak Jain Aditya Chavan Sindhu Nair Assistant Professor Abstract- The World Wide Web is a huge repository of data which includes audio, text and video.
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material.
 Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Representation/Indexing (fig 1.2) IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s
 IR models - overview (fig 2.1) IR models - vector space. Weighting TF*IDF. U s e r. T a s k s") Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Summary agenda Summary: EITN01 Web Intelligence and Information Retrieval Anders Ardö EIT Electrical and Information Technology, Lund University March 13, 2013 A Ardö, EIT Summary: EITN01 Web Intelligence
Creating a Classifier for a Focused Web Crawler
 Creating a Classifier for a Focused Web Crawler Nathan Moeller December 16, 2015 1 Abstract With the increasing size of the web, it can be hard to find high quality content with traditional search engines.
Creating a Classifier for a Focused Web Crawler Nathan Moeller December 16, 2015 1 Abstract With the increasing size of the web, it can be hard to find high quality content with traditional search engines.
Dynamic Visualization of Hubs and Authorities during Web Search
 Dynamic Visualization of Hubs and Authorities during Web Search Richard H. Fowler 1, David Navarro, Wendy A. Lawrence-Fowler, Xusheng Wang Department of Computer Science University of Texas Pan American
Dynamic Visualization of Hubs and Authorities during Web Search Richard H. Fowler 1, David Navarro, Wendy A. Lawrence-Fowler, Xusheng Wang Department of Computer Science University of Texas Pan American
CAIM: Cerca i Anàlisi d Informació Massiva
 1 / 72 CAIM: Cerca i Anàlisi d Informació Massiva FIB, Grau en Enginyeria Informàtica Slides by Marta Arias, José Balcázar, Ricard Gavaldá Department of Computer Science, UPC Fall 2016 http://www.cs.upc.edu/~caim
1 / 72 CAIM: Cerca i Anàlisi d Informació Massiva FIB, Grau en Enginyeria Informàtica Slides by Marta Arias, José Balcázar, Ricard Gavaldá Department of Computer Science, UPC Fall 2016 http://www.cs.upc.edu/~caim
Plan for today. CS276B Text Retrieval and Mining Winter Evolution of search engines. Connectivity analysis
 CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
CS276B Text Retrieval and Mining Winter 2005 Lecture 7 Plan for today Review search engine history (slightly more technically than in the first lecture) Web crawling/corpus construction Distributed crawling
Web Crawling. Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India
 Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
Web Crawling Jitali Patel 1, Hardik Jethva 2 Dept. of Computer Science and Engineering, Nirma University, Ahmedabad, Gujarat, India - 382 481. Abstract- A web crawler is a relatively simple automated program
(Social) Networks Analysis III. Prof. Dr. Daning Hu Department of Informatics University of Zurich
 Networks Analysis III. Prof. Dr. Daning Hu Department of Informatics University of Zurich") (Social) Networks Analysis III Prof. Dr. Daning Hu Department of Informatics University of Zurich Outline Network Topological Analysis Network Models Random Networks Small-World Networks Scale-Free Networks
(Social) Networks Analysis III Prof. Dr. Daning Hu Department of Informatics University of Zurich Outline Network Topological Analysis Network Models Random Networks Small-World Networks Scale-Free Networks
UNIT-V WEB MINING. 3/18/2012 Prof. Asha Ambhaikar, RCET Bhilai.
 UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
UNIT-V WEB MINING 1 Mining the World-Wide Web 2 What is Web Mining? Discovering useful information from the World-Wide Web and its usage patterns. 3 Web search engines Index-based: search the Web, index
AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM
 AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM Masahito Yamamoto, Hidenori Kawamura and Azuma Ohuchi Graduate School of Information Science and Technology, Hokkaido University, Japan
AN EFFICIENT COLLECTION METHOD OF OFFICIAL WEBSITES BY ROBOT PROGRAM Masahito Yamamoto, Hidenori Kawamura and Azuma Ohuchi Graduate School of Information Science and Technology, Hokkaido University, Japan
DATA MINING - 1DL105, 1DL111
 1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
1 DATA MINING - 1DL105, 1DL111 Fall 2007 An introductory class in data mining http://user.it.uu.se/~udbl/dut-ht2007/ alt. http://www.it.uu.se/edu/course/homepage/infoutv/ht07 Kjell Orsborn Uppsala Database
LINK context is utilized in various Web-based information
 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 18, NO. 1, JANUARY 2006 107 Link Contexts in Classifier-Guided Topical Crawlers Gautam Pant and Padmini Srinivasan Abstract Context of a hyperlink
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 18, NO. 1, JANUARY 2006 107 Link Contexts in Classifier-Guided Topical Crawlers Gautam Pant and Padmini Srinivasan Abstract Context of a hyperlink
Search Engine Architecture. Hongning Wang
 Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine
Search Engine Architecture Hongning Wang CS@UVa CS@UVa CS4501: Information Retrieval 2 Document Analyzer Classical search engine architecture The Anatomy of a Large-Scale Hypertextual Web Search Engine
Application of rough ensemble classifier to web services categorization and focused crawling
 With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
With the expected growth of the number of Web services available on the web, the need for mechanisms that enable the automatic categorization to organize this vast amount of data, becomes important. A
Exploiting routing information encoded into backlinks to improve topical crawling
 2009 International Conference of Soft Computing and Pattern Recognition Exploiting routing information encoded into backlinks to improve topical crawling Alban Mouton Valoria European University of Brittany
2009 International Conference of Soft Computing and Pattern Recognition Exploiting routing information encoded into backlinks to improve topical crawling Alban Mouton Valoria European University of Brittany
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK VII SEMESTER CS6007-INFORMATION RETRIEVAL Regulation 2013 Academic Year 2018
Competitive Intelligence and Web Mining:
 Competitive Intelligence and Web Mining: Domain Specific Web Spiders American University in Cairo (AUC) CSCE 590: Seminar1 Report Dr. Ahmed Rafea 2 P age Khalid Magdy Salama 3 P age Table of Contents Introduction
Competitive Intelligence and Web Mining: Domain Specific Web Spiders American University in Cairo (AUC) CSCE 590: Seminar1 Report Dr. Ahmed Rafea 2 P age Khalid Magdy Salama 3 P age Table of Contents Introduction
Approaches to Mining the Web
 Approaches to Mining the Web Olfa Nasraoui University of Louisville Web Mining: Mining Web Data (3 Types) Structure Mining: extracting info from topology of the Web (links among pages) Hubs: pages pointing
Approaches to Mining the Web Olfa Nasraoui University of Louisville Web Mining: Mining Web Data (3 Types) Structure Mining: extracting info from topology of the Web (links among pages) Hubs: pages pointing
CS473: Course Review CS-473. Luo Si Department of Computer Science Purdue University
 CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
CS473: CS-473 Course Review Luo Si Department of Computer Science Purdue University Basic Concepts of IR: Outline Basic Concepts of Information Retrieval: Task definition of Ad-hoc IR Terminologies and
Uninformed Search Methods. Informed Search Methods. Midterm Exam 3/13/18. Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall
 Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Midterm Exam Thursday, March 15, 7:30 9:30 p.m. room 125 Ag Hall Covers topics through Decision Trees and Random Forests (does not include constraint satisfaction) Closed book 8.5 x 11 sheet with notes
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Web Crawler Finds and downloads web pages automatically provides the collection for searching Web is huge and constantly
Searching the Deep Web
 Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
Searching the Deep Web 1 What is Deep Web? Information accessed only through HTML form pages database queries results embedded in HTML pages Also can included other information on Web can t directly index
The Structure of Information Networks. Jon Kleinberg. Cornell University
 The Structure of Information Networks Jon Kleinberg Cornell University 1 TB 1 GB 1 MB How much information is there? Wal-Mart s transaction database Library of Congress (text) World Wide Web (large snapshot,
The Structure of Information Networks Jon Kleinberg Cornell University 1 TB 1 GB 1 MB How much information is there? Wal-Mart s transaction database Library of Congress (text) World Wide Web (large snapshot,
Information Retrieval. Lecture 11 - Link analysis
 Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
Information Retrieval Lecture 11 - Link analysis Seminar für Sprachwissenschaft International Studies in Computational Linguistics Wintersemester 2007 1/ 35 Introduction Link analysis: using hyperlinks
M.E.J. Newman: Models of the Small World
 A Review Adaptive Informatics Research Centre Helsinki University of Technology November 7, 2007 Vocabulary N number of nodes of the graph l average distance between nodes D diameter of the graph d is
A Review Adaptive Informatics Research Centre Helsinki University of Technology November 7, 2007 Vocabulary N number of nodes of the graph l average distance between nodes D diameter of the graph d is
CS-E5740. Complex Networks. Scale-free networks
 CS-E5740 Complex Networks Scale-free networks Course outline 1. Introduction (motivation, definitions, etc. ) 2. Static network models: random and small-world networks 3. Growing network models: scale-free
CS-E5740 Complex Networks Scale-free networks Course outline 1. Introduction (motivation, definitions, etc. ) 2. Static network models: random and small-world networks 3. Growing network models: scale-free
Graph Model Selection using Maximum Likelihood
 Graph Model Selection using Maximum Likelihood Ivona Bezáková Adam Tauman Kalai Rahul Santhanam Theory Canal, Rochester, April 7 th 2008 [ICML 2006 (International Conference on Machine Learning)] Overview
Graph Model Selection using Maximum Likelihood Ivona Bezáková Adam Tauman Kalai Rahul Santhanam Theory Canal, Rochester, April 7 th 2008 [ICML 2006 (International Conference on Machine Learning)] Overview
Lecture 9: I: Web Retrieval II: Webology. Johan Bollen Old Dominion University Department of Computer Science
 Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
Lecture 9: I: Web Retrieval II: Webology Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen April 10, 2003 Page 1 WWW retrieval Two approaches
An Introduction to Search Engines and Web Navigation
 An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
An Introduction to Search Engines and Web Navigation MARK LEVENE ADDISON-WESLEY Ал imprint of Pearson Education Harlow, England London New York Boston San Francisco Toronto Sydney Tokyo Singapore Hong
Properties of Biological Networks
 Properties of Biological Networks presented by: Ola Hamud June 12, 2013 Supervisor: Prof. Ron Pinter Based on: NETWORK BIOLOGY: UNDERSTANDING THE CELL S FUNCTIONAL ORGANIZATION By Albert-László Barabási
Properties of Biological Networks presented by: Ola Hamud June 12, 2013 Supervisor: Prof. Ron Pinter Based on: NETWORK BIOLOGY: UNDERSTANDING THE CELL S FUNCTIONAL ORGANIZATION By Albert-László Barabási
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Recent Researches on Web Page Ranking
 Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Recent Researches on Web Page Pradipta Biswas School of Information Technology Indian Institute of Technology Kharagpur, India Importance of Web Page Internet Surfers generally do not bother to go through
Information Retrieval May 15. Web retrieval
 Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Information Retrieval May 15 Web retrieval What s so special about the Web? The Web Large Changing fast Public - No control over editing or contents Spam and Advertisement How big is the Web? Practically
Evaluating the Usefulness of Sentiment Information for Focused Crawlers
 Evaluating the Usefulness of Sentiment Information for Focused Crawlers Tianjun Fu 1, Ahmed Abbasi 2, Daniel Zeng 1, Hsinchun Chen 1 University of Arizona 1, University of Wisconsin-Milwaukee 2 futj@email.arizona.edu,
Evaluating the Usefulness of Sentiment Information for Focused Crawlers Tianjun Fu 1, Ahmed Abbasi 2, Daniel Zeng 1, Hsinchun Chen 1 University of Arizona 1, University of Wisconsin-Milwaukee 2 futj@email.arizona.edu,
Midterm Examination CS 540-2: Introduction to Artificial Intelligence
 Midterm Examination CS 54-2: Introduction to Artificial Intelligence March 9, 217 LAST NAME: FIRST NAME: Problem Score Max Score 1 15 2 17 3 12 4 6 5 12 6 14 7 15 8 9 Total 1 1 of 1 Question 1. [15] State
Midterm Examination CS 54-2: Introduction to Artificial Intelligence March 9, 217 LAST NAME: FIRST NAME: Problem Score Max Score 1 15 2 17 3 12 4 6 5 12 6 14 7 15 8 9 Total 1 1 of 1 Question 1. [15] State
Clustering Results. Result List Example. Clustering Results. Information Retrieval
 Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
Information Retrieval INFO 4300 / CS 4300! Presenting Results Clustering Clustering Results! Result lists often contain documents related to different aspects of the query topic! Clustering is used to
A Survey on Web Information Retrieval Technologies
 A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
A Survey on Web Information Retrieval Technologies Lan Huang Computer Science Department State University of New York, Stony Brook Presented by Kajal Miyan Michigan State University Overview Web Information
The Establishment Game. Motivation
 Motivation Motivation The network models so far neglect the attributes, traits of the nodes. A node can represent anything, people, web pages, computers, etc. Motivation The network models so far neglect
Motivation Motivation The network models so far neglect the attributes, traits of the nodes. A node can represent anything, people, web pages, computers, etc. Motivation The network models so far neglect
Bruno Martins. 1 st Semester 2012/2013
 Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Link Analysis Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 2 3 4
Searching the Web What is this Page Known for? Luis De Alba
 Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Searching the Web What is this Page Known for? Luis De Alba ldealbar@cc.hut.fi Searching the Web Arasu, Cho, Garcia-Molina, Paepcke, Raghavan August, 2001. Stanford University Introduction People browse
Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff Dr Ahmed Rafea
 Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff http://www9.org/w9cdrom/68/68.html Dr Ahmed Rafea Outline Introduction Link Analysis Path Analysis Using Markov Chains Applications
Path Analysis References: Ch.10, Data Mining Techniques By M.Berry, andg.linoff http://www9.org/w9cdrom/68/68.html Dr Ahmed Rafea Outline Introduction Link Analysis Path Analysis Using Markov Chains Applications
Search Engines. Information Retrieval in Practice
 Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
Search Engines Information Retrieval in Practice All slides Addison Wesley, 2008 Classification and Clustering Classification and clustering are classical pattern recognition / machine learning problems
An Improved PageRank Method based on Genetic Algorithm for Web Search
 Available online at www.sciencedirect.com Procedia Engineering 15 (2011) 2983 2987 Advanced in Control Engineeringand Information Science An Improved PageRank Method based on Genetic Algorithm for Web
Available online at www.sciencedirect.com Procedia Engineering 15 (2011) 2983 2987 Advanced in Control Engineeringand Information Science An Improved PageRank Method based on Genetic Algorithm for Web
Genetic Algorithms Variations and Implementation Issues
 Genetic Algorithms Variations and Implementation Issues CS 431 Advanced Topics in AI Classic Genetic Algorithms GAs as proposed by Holland had the following properties: Randomly generated population Binary
Genetic Algorithms Variations and Implementation Issues CS 431 Advanced Topics in AI Classic Genetic Algorithms GAs as proposed by Holland had the following properties: Randomly generated population Binary
arxiv:cond-mat/ v1 21 Oct 1999
 Emergence of Scaling in Random Networks Albert-László Barabási and Réka Albert Department of Physics, University of Notre-Dame, Notre-Dame, IN 46556 arxiv:cond-mat/9910332 v1 21 Oct 1999 Systems as diverse
Emergence of Scaling in Random Networks Albert-László Barabási and Réka Albert Department of Physics, University of Notre-Dame, Notre-Dame, IN 46556 arxiv:cond-mat/9910332 v1 21 Oct 1999 Systems as diverse
Topic mash II: assortativity, resilience, link prediction CS224W
 Topic mash II: assortativity, resilience, link prediction CS224W Outline Node vs. edge percolation Resilience of randomly vs. preferentially grown networks Resilience in real-world networks network resilience
Topic mash II: assortativity, resilience, link prediction CS224W Outline Node vs. edge percolation Resilience of randomly vs. preferentially grown networks Resilience in real-world networks network resilience
Administrative. Web crawlers. Web Crawlers and Link Analysis!
 Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
Web Crawlers and Link Analysis! David Kauchak cs458 Fall 2011 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture15-linkanalysis.ppt http://webcourse.cs.technion.ac.il/236522/spring2007/ho/wcfiles/tutorial05.ppt
10/10/13. Traditional database system. Information Retrieval. Information Retrieval. Information retrieval system? Information Retrieval Issues
 COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
COS 597A: Principles of Database and Information Systems Information Retrieval Traditional database system Large integrated collection of data Uniform access/modifcation mechanisms Model of data organization
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Web Crawling. Introduction to Information Retrieval CS 150 Donald J. Patterson
 Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
Web Crawling Introduction to Information Retrieval CS 150 Donald J. Patterson Content adapted from Hinrich Schütze http://www.informationretrieval.org Robust Crawling A Robust Crawl Architecture DNS Doc.
TELCOM2125: Network Science and Analysis
 School of Information Sciences University of Pittsburgh TELCOM2125: Network Science and Analysis Konstantinos Pelechrinis Spring 2015 Figures are taken from: M.E.J. Newman, Networks: An Introduction 2
School of Information Sciences University of Pittsburgh TELCOM2125: Network Science and Analysis Konstantinos Pelechrinis Spring 2015 Figures are taken from: M.E.J. Newman, Networks: An Introduction 2
Information Retrieval (IR) Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.
 Introduction to Information Retrieval. Lecture Overview. Why do we need IR? Basics of an IR system.") Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Introduction to Information Retrieval Ethan Phelps-Goodman Some slides taken from http://www.cs.utexas.edu/users/mooney/ir-course/ Information Retrieval (IR) The indexing and retrieval of textual documents.
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Enhanced Performance of Search Engine with Multitype Feature Co-Selection of Db-scan Clustering Algorithm
 Enhanced Performance of Search Engine with Multitype Feature Co-Selection of Db-scan Clustering Algorithm K.Parimala, Assistant Professor, MCA Department, NMS.S.Vellaichamy Nadar College, Madurai, Dr.V.Palanisamy,
Enhanced Performance of Search Engine with Multitype Feature Co-Selection of Db-scan Clustering Algorithm K.Parimala, Assistant Professor, MCA Department, NMS.S.Vellaichamy Nadar College, Madurai, Dr.V.Palanisamy,
Summary: What We Have Learned So Far
 Summary: What We Have Learned So Far small-world phenomenon Real-world networks: { Short path lengths High clustering Broad degree distributions, often power laws P (k) k γ Erdös-Renyi model: Short path
Summary: What We Have Learned So Far small-world phenomenon Real-world networks: { Short path lengths High clustering Broad degree distributions, often power laws P (k) k γ Erdös-Renyi model: Short path
Administrivia. Crawlers: Nutch. Course Overview. Issues. Crawling Issues. Groups Formed Architecture Documents under Review Group Meetings CSE 454
 Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Administrivia Crawlers: Nutch Groups Formed Architecture Documents under Review Group Meetings CSE 454 4/14/2005 12:54 PM 1 4/14/2005 12:54 PM 2 Info Extraction Course Overview Ecommerce Standard Web Search
Adaptive Focused Crawling
 7 Adaptive Focused Crawling Alessandro Micarelli and Fabio Gasparetti Department of Computer Science and Automation Artificial Intelligence Laboratory Roma Tre University Via della Vasca Navale, 79 00146
7 Adaptive Focused Crawling Alessandro Micarelli and Fabio Gasparetti Department of Computer Science and Automation Artificial Intelligence Laboratory Roma Tre University Via della Vasca Navale, 79 00146
Automatically Constructing a Directory of Molecular Biology Databases
 Automatically Constructing a Directory of Molecular Biology Databases Luciano Barbosa, Sumit Tandon, and Juliana Freire School of Computing, University of Utah Abstract. There has been an explosion in
Automatically Constructing a Directory of Molecular Biology Databases Luciano Barbosa, Sumit Tandon, and Juliana Freire School of Computing, University of Utah Abstract. There has been an explosion in
How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200?
 How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200? Questions from last time Avg. FB degree is 200 (suppose).
How to explore big networks? Question: Perform a random walk on G. What is the average node degree among visited nodes, if avg degree in G is 200? Questions from last time Avg. FB degree is 200 (suppose).
Failure in Complex Social Networks
 Journal of Mathematical Sociology, 33:64 68, 2009 Copyright # Taylor & Francis Group, LLC ISSN: 0022-250X print/1545-5874 online DOI: 10.1080/00222500802536988 Failure in Complex Social Networks Damon
Journal of Mathematical Sociology, 33:64 68, 2009 Copyright # Taylor & Francis Group, LLC ISSN: 0022-250X print/1545-5874 online DOI: 10.1080/00222500802536988 Failure in Complex Social Networks Damon
Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _
 COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
COURSE DELIVERY PLAN - THEORY Page 1 of 6 Department of Computer Science and Engineering B.E/B.Tech/M.E/M.Tech : B.E. Regulation: 2013 PG Specialisation : _ LP: CS6007 Rev. No: 01 Date: 27/06/2017 Sub.
Problem 1: Complexity of Update Rules for Logistic Regression
 Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Case Study 1: Estimating Click Probabilities Tackling an Unknown Number of Features with Sketching Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox January 16 th, 2014 1
Chapter 6: Information Retrieval and Web Search. An introduction
 Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Chapter 6: Information Retrieval and Web Search An introduction Introduction n Text mining refers to data mining using text documents as data. n Most text mining tasks use Information Retrieval (IR) methods
Crawler with Search Engine based Simple Web Application System for Forum Mining
 IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 Crawler with Search Engine based Simple Web Application System for Forum Mining Parina
IJSRD - International Journal for Scientific Research & Development Vol. 3, Issue 04, 2015 ISSN (online): 2321-0613 Crawler with Search Engine based Simple Web Application System for Forum Mining Parina
Review of Various Web Page Ranking Algorithms in Web Structure Mining
 National Conference on Recent Research in Engineering Technology (NCRRET -2015) International Journal of Advance Engineering Research Development (IJAERD) e-issn: 2348-4470, print-issn:2348-6406 Review
National Conference on Recent Research in Engineering Technology (NCRRET -2015) International Journal of Advance Engineering Research Development (IJAERD) e-issn: 2348-4470, print-issn:2348-6406 Review
Developing Focused Crawlers for Genre Specific Search Engines
 Developing Focused Crawlers for Genre Specific Search Engines Nikhil Priyatam Thesis Advisor: Prof. Vasudeva Varma IIIT Hyderabad July 7, 2014 Examples of Genre Specific Search Engines MedlinePlus Naukri.com
Developing Focused Crawlers for Genre Specific Search Engines Nikhil Priyatam Thesis Advisor: Prof. Vasudeva Varma IIIT Hyderabad July 7, 2014 Examples of Genre Specific Search Engines MedlinePlus Naukri.com
Information Retrieval and Web Search
 Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
Information Retrieval and Web Search Web Crawling Instructor: Rada Mihalcea (some of these slides were adapted from Ray Mooney s IR course at UT Austin) The Web by the Numbers Web servers 634 million Users
An Application of Personalized PageRank Vectors: Personalized Search Engine
 An Application of Personalized PageRank Vectors: Personalized Search Engine Mehmet S. Aktas 1,2, Mehmet A. Nacar 1,2, and Filippo Menczer 1,3 1 Indiana University, Computer Science Department Lindley Hall
An Application of Personalized PageRank Vectors: Personalized Search Engine Mehmet S. Aktas 1,2, Mehmet A. Nacar 1,2, and Filippo Menczer 1,3 1 Indiana University, Computer Science Department Lindley Hall
Abstract. 1. Introduction
 A Visualization System using Data Mining Techniques for Identifying Information Sources on the Web Richard H. Fowler, Tarkan Karadayi, Zhixiang Chen, Xiaodong Meng, Wendy A. L. Fowler Department of Computer
A Visualization System using Data Mining Techniques for Identifying Information Sources on the Web Richard H. Fowler, Tarkan Karadayi, Zhixiang Chen, Xiaodong Meng, Wendy A. L. Fowler Department of Computer
beyond social networks
 beyond social networks Small world phenomenon: high clustering C network >> C random graph low average shortest path l network ln( N)! neural network of C. elegans,! semantic networks of languages,! actor
beyond social networks Small world phenomenon: high clustering C network >> C random graph low average shortest path l network ln( N)! neural network of C. elegans,! semantic networks of languages,! actor
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS
 CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network