Graphs / Networks CSE 6242/ CX Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
|
|
|
- Caroline Fox
- 5 years ago
- Views:
Transcription
1 CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le Song
2 Centrality = Importance



3 Why Node Centrality? What can we do if we can rank all the nodes in a graph (e.g., Facebook, LinkedIn, Twitter)? Find celebrities or influential people in a social network (Twitter) Find gatekeepers who connect communities (headhunters love to find them on LinkedIn) What else? 3
4 More generally Helps graph analysis, visualization, understanding, e.g., Let us rank nodes, group or study them by centrality Only show subgraph formed by the top 100 nodes, out of the millions in the full graph Similar to google search results (ranked, and they only show you 10 per page) Most graph analysis packages already have centrality algorithms implemented. Use them! Can also compute edge centrality. Here we focus on node centrality. 4
5 Degree Centrality (easiest) Degree = number of neighbors For directed graphs In degree = No. of incoming edges Out degree = No. of outgoing edges 4 For undirected graphs, only degree is defined. Algorithms? Sequential scan through edge list What about for a graph stored in SQLite? 5
6 Computing Degrees using SQL Recall simplest way to store a graph in SQLite: edges(source_id, target_id) 1. If slow, first create index for each column 2. Use group by statement to find in degrees select count(*) from edges group by source_id; 6

7 Betweenness Centrality High betweenness = gatekeeper Betweenness of a node v = Number of shortest paths between s and t that goes through v Number of shortest paths between s and t = how often a node serves as the bridge that connects two other nodes. Betweenness is very well studied. 7
8 (Local) Clustering Coefficient A node s clustering coefficient is a measure of how close the node s neighbors are from forming a clique. 1 = neighbors form a clique 0 = No edges among neighbors (Assuming undirected graph) Local means it s for a node; can also compute a graph s global coefficient Image source: 8
9 Computing Clustering Coefficients... Requires triangle counting Real social networks have a lot of triangles Friends of friends are friends Triangles are expensive to compute (neighborhood intersections; several approx. algos) Can we do that quickly? Algorithm details: Faster Clustering Coefficient Using Vertex Covers 9
![Super Fast Triangle Counting [Tsourakakis ICDM 2008] details But:](/docs-images/89/98528114/images/10-0.jpg "triangles are expensive to compute (3-way join; several approx.")
 (and, because of skewness, we only")
10 Super Fast Triangle Counting [Tsourakakis ICDM 2008] details But: triangles are expensive to compute (3-way join; several approx. algos) Q: Can we do that quickly? A: Yes! #triangles = 1/6 Sum ( λi 3 ) (and, because of skewness, we only need the top few eigenvalues! 10
11 Power Law in Eigenvalues of Adjacency Matrix Eigenvalue Eigen exponent = slope = Rank of decreasing eigenvalue 11
12 1000x+ speed-up, >90% accuracy 12
13 More Centrality Measures Degree Betweenness Closeness, by computing Shortest paths Proximity (usually via random walks) used successfully in a lot of applications Eigenvector 13

14 PageRank (Google) Larry Page Sergey Brin Brin, Sergey and Lawrence Page (1998). Anatomy of a Large-Scale Hypertextual Web Search Engine. 7th Intl World Wide Web Conf.
15 PageRank: Problem Given a directed graph, find its most interesting/central node A node is important, if it is connected with important nodes (recursive, but OK!)
16 PageRank: Solution Given a directed graph, find its most interesting/central node Proposed solution: use random walk; spot most popular node (-> steady state probability (ssp)) A node has high ssp, if it is connected with high ssp nodes state = webpage (recursive, but OK!)
17 (Simplified) PageRank Let B be the transition matrix: transposed, column-normalized To From B = 4 5
18 (Simplified) PageRank B p = p B p = p = 4 5
19 (Simplified) PageRank B p = 1 * p Thus, p is the eigenvector that corresponds to the highest eigenvalue (=1, since the matrix is column-normalized) Why does such a p exist? p exists if B is nxn, nonnegative, irreducible [Perron Frobenius theorem]
20 (Simplified) PageRank In short: imagine a particle randomly moving along the edges Compute its steady-state probability (ssp) Full version of algorithm: with occasional random jumps Why? To make the matrix irreducible
/n 1 => p = (1-c)/n [I - c B] -1 1 4")
21 Full Algorithm With probability 1-c, fly-out to a random node Then, we have p = c B p + (1-c)/n 1 => p = (1-c)/n [I - c B]
22 How to compute PageRank for huge matrix? Use the power iteration method 4 p = c B p + (1-c)/n 1 5 p B p = c + (1-c) 1/n Can initialize this vector to any non-zero vector, e.g., all 1 s
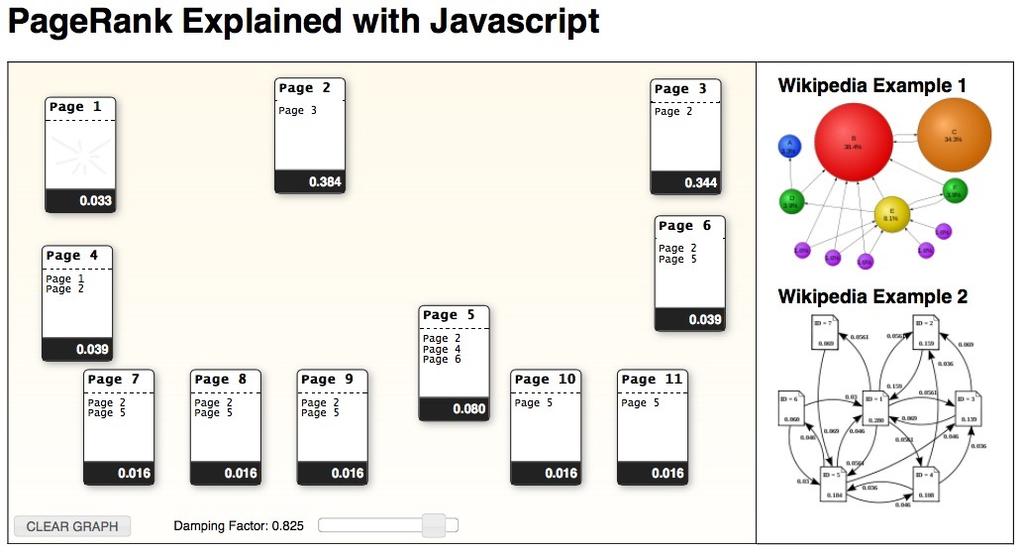
23 23
24 PageRank for graphs (generally) You can compute PageRank for any graphs Should be in your algorithm toolbox Better than simple centrality measure (e.g., degree) Fast to compute for large graphs (O(E)) But can be misled (Google Bomb) How? 24
25 Personalized PageRank Make one small variation of PageRank Intuition: not all pages are equal, some more relevant to a person s specific needs How? 25
26 Personalizing PageRank With probability 1-c, fly-out to a random node some preferred nodes Then, we have p = c B p + (1-c)/n 1 => p = (1-c)/n [I - c B] -1 1
27 Why learn Personalized PageRank? Can be used for recommendation, e.g., If I like this webpage, what would I also be interested? If I like this product, what other products I also like? (in a user-product bipartite graph) Also helps with visualizing large graphs Instead of visualizing every single nodes, visualize the most important ones Again, very flexible. Can be run on any graph. 27
28 Interactive Application
29 Building an interactive application Will show you an example application (Apolo) that uses a diffusion-based algorithm to perform recommendation on a large graph Personalized PageRank (= Random Walk with Restart) Belief Propagation (powerful inference algorithm, for fraud detection, image segmentation, error-correcting codes, etc.) Spreading activation or degree of interest in Human- Computer Interaction (HCI) Guilt-by-association techniques 29
30 Building an interactive application Why diffusion-based algorithms are widely used? Intuitive to interpret uses network effect, homophily, etc. Easy to implement Math is relatively simple Fast run time linear to #edges, or better Probabilistic meaning 30
31 Human-In-The-Loop Graph Mining Apolo: Machine Learning + Visualization CHI 2011 Apolo: Making Sense of Large Network Data by Combining Rich User Interaction and Machine Learning 31
32 Finding More Relevant Nodes HCI Paper Citation network Data Mining Paper 32
33 Finding More Relevant Nodes HCI Paper Citation network Data Mining Paper 32
34 Finding More Relevant Nodes HCI Paper Citation network Data Mining Paper Apolo uses guilt-by-association (Belief Propagation, similar to personalized PageRank) 32
35 Demo: Mapping the Sensemaking Literature Nodes: 80k papers from Google Scholar (node size: #citation) Edges: 150k citations 33
36

37

38 Key Ideas (Recap) Specify exemplars Find other relevant nodes (BP) 35
39 Apolo s Contributions 1 Human + Machine It was like having a partnership with the machine. Apolo User 2 Personalized Landscape 36

40 Apolo


41 Apolo
42 Apolo ,000 lines of code. Java 1.6. Swing. Uses SQLite3 to store graph on disk 39

43 User Study Used citation network Task: Find related papers for 2 sections in a survey paper on user interface Model-based generation of UI Rapid prototyping tools 40
44 Between subjects design Participants: grad student or research staff 41
45 41
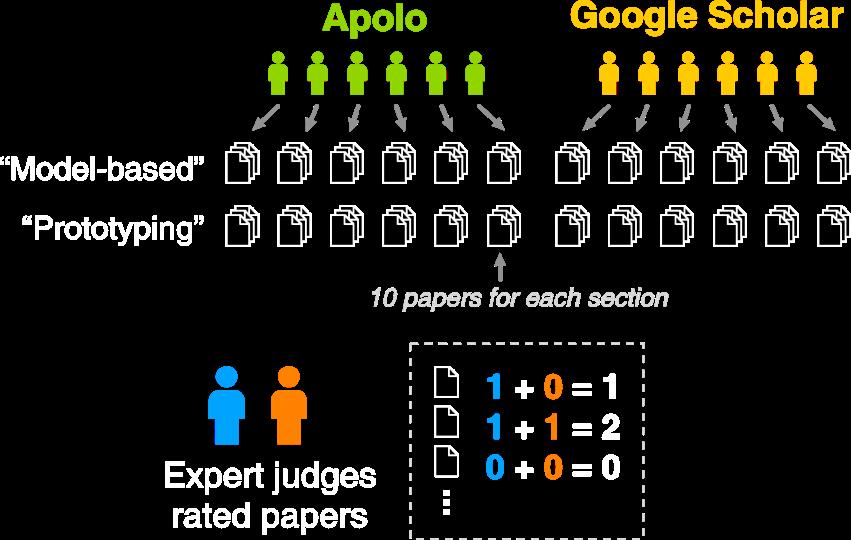
46 41
47 Judges Scores 16 Apolo Scholar Score 8 0 Modelbased *Prototyping *Average Higher is better. Apolo wins. * Statistically significant, by two-tailed t test, p <
48 Apolo: Recap A mixed-initiative approach for exploring and creating personalized landscape for large network data Apolo = ML + Visualization + Interaction 43
49 Feldspar Finding Information by Association. CHI 2008 Polo Chau, Brad Myers, Andrew Faulring YouTube: Paper: 44
50 Feldspar What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 45
51 Feldspar A system that helps people find things on their computers when typical search or browsing tools don t work What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 45
52 Feldspar A system that helps people find things on their computers when typical search or browsing tools don t work An example scenario What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 45
53 Find the webpage mentioned in the from the person I met at an event What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 46
54 Find the webpage mentioned in the from the person I met at an event If I can t remember the specifics, such as any text in the webpage, , etc. à Can t search What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 46
55 Find the webpage mentioned in the from the person I met at an event If I can t remember the specifics, such as any text in the webpage, , etc. à Can t search If I haven t bookmarked the webpage à Can t browse What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 46
56 Find the webpage mentioned in the from the person I met at an event What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 47
57 Find the webpage mentioned in the from the person I met at an event But I can describe the webpage with a chain of associations. What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 47
58 Find the webpage mentioned in the from the person I met at an event But I can describe the webpage with a chain of associations. webpage person event What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 47
59 Find the webpage mentioned in the from the person I met at an event But I can describe the webpage with a chain of associations. webpage person event The psychology literature has shown that people often remember things exactly like this. What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 47
60 Natural question: Can I find things by associations? What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 48
61 Natural question: Can I find things by associations? Can I find the webpage by specifying its associated information ( , person, and event)? What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 48
62 Natural question: Can I find things by associations? Can I find the webpage by specifying its associated information ( , person, and event)? We created Feldspar, which supports this associative retrieval of information. What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 48
63 Feldspar stands for. What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 49


64 F Finding E Elements by L Leveraging Feldspar stands for. D Diverse Sources of P Pertinent A Associative Recollection What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 49
65 Implementation: Overview Create a graph database to store the associations among items on the computer Develop an algorithm that processes the query and returns results What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 50
66 Creating an Association Database (a graph) Install Google Desktop and let it index all the items on the computer What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 51
67 Creating an Association Database (a graph) Focus on 7 types Install Google Desktop and let it index all the items on the computer What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 51
68 Creating an Association Database (a graph) Identify associations and build our database, which is a directed graph Focus on 7 types Install Google Desktop and let it index all the items on the computer What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 51
69 Creating an Association Database (a graph) Identify associations and build our database, which is a directed graph Focus on 7 types Install Google Desktop and let it index all the items on the computer What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 51



70 Creating an Association Database (a graph) Identify associations and build our database, which is a directed graph Focus on 7 types Install Google Desktop and let it index all the items on the computer What to Do When Search Fails: Finding Information by Association Polo Chau, Brad Myers, Andrew Faulring 51
71 Practitioners guide to building (interactive) applications Think about scalability early e.g., picking a scalable algorithm early on When building interactive applications, use iterative design approach (as in Apolo) Why? It s hard to get it right the first time Create prototype, evaluate, modify prototype, evaluate,... Quick evaluation helps you identify important fixes early (can save you a lot of time) 52
72 Practitioners guide to building (interactive) applications How to do iterative design? What kinds of prototypes? Paper prototype, lo-fi prototype, high-fi prototype What kinds of evaluation? Important to involve REAL users as early as possible Recruit your friends to try your tools Lab study (controlled, as in Apolo) Longitudinal study (usage over months) Deploy it and see the world s reaction! To learn more: CS 6750 Human-Computer Interaction CS 6455 User Interface Design and Evaluation 53

73 If you want to know more about people 54

74 Polonium: Web-Scale Malware Detection SDM 2011 Polonium: Tera-Scale Graph Mining and Inference for Malware Detection

75 Typical Malware Detection Method Signature-based detection 1.Collect malware 2.Generate signatures 3.Distribute to users 4.Scan computers for matches What about zero-day malware? No samples à No signatures à No detection How to detect them early? 56



76 Reputation-Based Detection Computes reputation score for each application e.g., MSWord.exe Poor reputation = Malware 57
77 Polonium Text Patented I led initial design and development Serving 120 million users Answered trillions of queries 58



78 Polonium Text Propagation of leverage of network influence unearths malware Patented I led initial design and development Serving 120 million users Answered trillions of queries 58
 Goal: label malware and good files")
79 Polonium works with 60 Terabyte Data 50 million machines anonymously reported their executable files 900 million unique files (Identified by their cryptographic hash values) Goal: label malware and good files 59
80 Why A Hard Problem? Existing Research Polonium Small dataset Huge dataset (60 terabytes) Detects specific malware (e.g., worm, trojans) Detects all types (needs a general method) Many false alarms (>10%) Strict (<1%) 60
81 Polonium: Problem Definition Given Undirected machine-file bipartite graph 37 billion edges, 1 billion nodes (machines, files) Some file labels from Symantec (good or bad) Find Labels for all unknown files 61

82 Where to Get Good and Bad Labels? Symantec has a ground truth database of known-good and known-bad files e.g., set known-good file s prior to


83 How to Gauge Machine Reputation? Computed using Symantec s proprietary formula; a value between 0 and 1 Derived from anonymous aspects of machine s usage and behavior 63
84 How to propagate known information to the unknown? 64
85 Key Idea: Guilt-by-Association GOOD files likely appear on GOOD machines BAD files likely appear on BAD machines Also known as Homophily Machine Good Bad Good File Bad
 A powerful inference algorithm Used in image processing,")
86 How to propagate known information to the unknown? Adapts Belief Propagation (BP) A powerful inference algorithm Used in image processing, computer vision, error-correcting codes, etc. 66
87 Propagating Reputation Example Machine Good Bad File Good Bad Machines A B C Files
88 Propagating Reputation Example Machine Good Bad File Good Bad Machines A B C Files
89 Propagating Reputation Example Machine Good Bad File Good Bad Machines A B C Files
90 Propagating Reputation Example Machine Good Bad File Good Bad Machines A B C Files
91 Propagating Reputation Example Machine Good Bad File Good Bad Machines A B C Files
92 Two Equations in Belief Propagation Details 68
93 Computing Node Belief (Reputation) Details 69
94 Computing Node Belief (Reputation) Details Belief Prior belief Neighbors opinions 69

95 Computing Node Belief (Reputation) A B C Details Belief Prior belief Neighbors opinions 69
96 Creating Message for Neighbor Details 70
97 Creating Message for Neighbor Details Opinion for neighbor Edge potential Belief Good Bad Good Bad
98 Creating Message for Neighbor A B C Details Opinion for neighbor Edge potential Belief Good Bad Good Bad
99 Evaluation Using millions of ground truth files,10-fold cross validation True Positive Rate % of bad correctly labeled Ideal 85% True Positive Rate 1% False Alarms False Positive Rate (False Alarms) % of good labeled as bad 71
 % of good labeled as")
100 Evaluation Using millions of ground truth files,10-fold cross validation True Positive Rate % of bad correctly labeled Ideal 85% True Positive Rate 1% False Alarms Boosted existing methods by 10 absolute % point False Positive Rate (False Alarms) % of good labeled as bad 71
101 Multi-Iteration Results True Positive Rate % of bad correctly labeled False Positive Rate (False Alarm) % of good labeled as bad 72
102 Scalability Running Time Per Iteration Linux 16-core Opteron 256GB RAM 3 hours, 37 billion edges 73
103 Scalability How Did I Scale Up BP? Details 1.Early termination (after 6 iterations) à Faster 2.Keep edges on disk à Saves 200GB of RAM 3.Computes half of the messages à Twice as fast 74
![Further Scale Up Belief Propagation Use Hadoop if graph doesn t fit in memory [ICDE 11] Speed scales up linearly](/docs-images/89/98528114/images/104-0.jpg "with number of machines Scale-up Yahoo! M45 cluster 480 machines 1.5 PB storage 3.")
104 Further Scale Up Belief Propagation Use Hadoop if graph doesn t fit in memory [ICDE 11] Speed scales up linearly with number of machines Scale-up Yahoo! M45 cluster 480 machines 1.5 PB storage 3.5TB machine Number of machines 75
Graphs / Networks CSE 6242/ CX Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
CSE 6242/ CX 4242 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John
Graphs / Networks. CSE 6242/ CX 4242 Feb 18, Centrality measures, algorithms, interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
CSE 6242/ CX 4242 Feb 18, 2014 Graphs / Networks Centrality measures, algorithms, interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey
Graphs III. CSE 6242 A / CS 4803 DVA Feb 26, Duen Horng (Polo) Chau Georgia Tech. (Interactive) Applications
 Chau Georgia Tech. (Interactive) Applications") CSE 6242 A / CS 4803 DVA Feb 26, 2013 Graphs III (Interactive) Applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos
CSE 6242 A / CS 4803 DVA Feb 26, 2013 Graphs III (Interactive) Applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos
Graphs / Networks CSE 6242/ CX Interactive applications. Duen Horng (Polo) Chau Georgia Tech
 Chau Georgia Tech") CSE 6242/ CX 4242 Graphs / Networks Interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le Song
CSE 6242/ CX 4242 Graphs / Networks Interactive applications Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le Song
Analytics Building Blocks
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Analytics Building Blocks Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Analytics Building Blocks Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based
Data Integration. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Integration Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Integration Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
CSE 6242 / CX 4242 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Text Analytics (Text Mining)
") CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
CSE 6242 / CX 4242 Apr 1, 2014 Text Analytics (Text Mining) Concepts and Algorithms Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer,
Graphs / Networks CSE 6242/ CX Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know
 CSE 6242/ CX 4242 Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors
CSE 6242/ CX 4242 Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo) Chau Georgia Tech Partly based on materials by Professors
Lecture #3: PageRank Algorithm The Mathematics of Google Search
 Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Lecture #3: PageRank Algorithm The Mathematics of Google Search We live in a computer era. Internet is part of our everyday lives and information is only a click away. Just open your favorite search engine,
Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Graphs / Networks Basics, how to build & store graphs, laws, etc. Centrality, and algorithms you should know Duen Horng (Polo)
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second
Data Collection, Simple Storage (SQLite) & Cleaning
 & Cleaning") Data Collection, Simple Storage (SQLite) & Cleaning Duen Horng (Polo) Chau Georgia Tech CSE 6242 A / CS 4803 DVA Jan 15, 2013 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Data Collection, Simple Storage (SQLite) & Cleaning Duen Horng (Polo) Chau Georgia Tech CSE 6242 A / CS 4803 DVA Jan 15, 2013 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko,
Link Analysis and Web Search
 Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Link Analysis and Web Search Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ based on material by prof. Bing Liu http://www.cs.uic.edu/~liub/webminingbook.html
Scaling Up 1 CSE 6242 / CX Duen Horng (Polo) Chau Georgia Tech. Hadoop, Pig
 Chau Georgia Tech. Hadoop, Pig") CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
CSE 6242 / CX 4242 Scaling Up 1 Hadoop, Pig Duen Horng (Polo) Chau Georgia Tech Some lectures are partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos, Le
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Lecture 27: Learning from relational data
 Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Lecture 27: Learning from relational data STATS 202: Data mining and analysis December 2, 2017 1 / 12 Announcements Kaggle deadline is this Thursday (Dec 7) at 4pm. If you haven t already, make a submission
Social Network Analysis
 Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Social Network Analysis Giri Iyengar Cornell University gi43@cornell.edu March 14, 2018 Giri Iyengar (Cornell Tech) Social Network Analysis March 14, 2018 1 / 24 Overview 1 Social Networks 2 HITS 3 Page
Agenda. Math Google PageRank algorithm. 2 Developing a formula for ranking web pages. 3 Interpretation. 4 Computing the score of each page
 Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
Agenda Math 104 1 Google PageRank algorithm 2 Developing a formula for ranking web pages 3 Interpretation 4 Computing the score of each page Google: background Mid nineties: many search engines often times
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS
 CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
CS249: SPECIAL TOPICS MINING INFORMATION/SOCIAL NETWORKS Overview of Networks Instructor: Yizhou Sun yzsun@cs.ucla.edu January 10, 2017 Overview of Information Network Analysis Network Representation Network
How to organize the Web?
 How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
How to organize the Web? First try: Human curated Web directories Yahoo, DMOZ, LookSmart Second try: Web Search Information Retrieval attempts to find relevant docs in a small and trusted set Newspaper
COMP5331: Knowledge Discovery and Data Mining
 COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
COMP5331: Knowledge Discovery and Data Mining Acknowledgement: Slides modified based on the slides provided by Lawrence Page, Sergey Brin, Rajeev Motwani and Terry Winograd, Jon M. Kleinberg 1 1 PageRank
Classification Key Concepts
 http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Classification Key Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Parishit
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Classification Key Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Parishit
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
Web search before Google. (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.)
, The PageRank Citation Ranking: Bringing Order to the Web.)") ' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
' Sta306b May 11, 2012 $ PageRank: 1 Web search before Google (Taken from Page et al. (1999), The PageRank Citation Ranking: Bringing Order to the Web.) & % Sta306b May 11, 2012 PageRank: 2 Web search
Data Mining Concepts & Tasks
 Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Sept 9, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Sept 9, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
COMP Page Rank
 COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
COMP 4601 Page Rank 1 Motivation Remember, we were interested in giving back the most relevant documents to a user. Importance is measured by reference as well as content. Think of this like academic paper
modern database systems lecture 10 : large-scale graph processing
 modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
Big Data Analytics CSCI 4030
 High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Community Detection Web advertising
Social-Network Graphs
 Social-Network Graphs Mining Social Networks Facebook, Google+, Twitter Email Networks, Collaboration Networks Identify communities Similar to clustering Communities usually overlap Identify similarities
Social-Network Graphs Mining Social Networks Facebook, Google+, Twitter Email Networks, Collaboration Networks Identify communities Similar to clustering Communities usually overlap Identify similarities
Part 1: Link Analysis & Page Rank
 Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Chapter 8: Graph Data Part 1: Link Analysis & Page Rank Based on Leskovec, Rajaraman, Ullman 214: Mining of Massive Datasets 1 Graph Data: Social Networks [Source: 4-degrees of separation, Backstrom-Boldi-Rosa-Ugander-Vigna,
Information Networks: PageRank
 Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Information Networks: PageRank Web Science (VU) (706.716) Elisabeth Lex ISDS, TU Graz June 18, 2018 Elisabeth Lex (ISDS, TU Graz) Links June 18, 2018 1 / 38 Repetition Information Networks Shape of the
Page rank computation HPC course project a.y Compute efficient and scalable Pagerank
 Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Page rank computation HPC course project a.y. 2012-13 Compute efficient and scalable Pagerank 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and used by the Google Internet
Introduction to Data Mining
 Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
Introduction to Data Mining Lecture #10: Link Analysis-2 Seoul National University 1 In This Lecture Pagerank: Google formulation Make the solution to converge Computing Pagerank for very large graphs
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Scaling Up Pig. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up Pig Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
Social Network Analysis
 Social Network Analysis Mathematics of Networks Manar Mohaisen Department of EEC Engineering Adjacency matrix Network types Edge list Adjacency list Graph representation 2 Adjacency matrix Adjacency matrix
Social Network Analysis Mathematics of Networks Manar Mohaisen Department of EEC Engineering Adjacency matrix Network types Edge list Adjacency list Graph representation 2 Adjacency matrix Adjacency matrix
Motivation. Motivation
 COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
COMS11 Motivation PageRank Department of Computer Science, University of Bristol Bristol, UK 1 November 1 The World-Wide Web was invented by Tim Berners-Lee circa 1991. By the late 199s, the amount of
Large-Scale Networks. PageRank. Dr Vincent Gramoli Lecturer School of Information Technologies
 Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
Large-Scale Networks PageRank Dr Vincent Gramoli Lecturer School of Information Technologies Introduction Last week we talked about: - Hubs whose scores depend on the authority of the nodes they point
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material.
 Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
Link Analysis from Bing Liu. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, Springer and other material. 1 Contents Introduction Network properties Social network analysis Co-citation
A brief history of Google
 the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
the math behind Sat 25 March 2006 A brief history of Google 1995-7 The Stanford days (aka Backrub(!?)) 1998 Yahoo! wouldn't buy (but they might invest...) 1999 Finally out of beta! Sergey Brin Larry Page
Extracting Information from Complex Networks
 Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Extracting Information from Complex Networks 1 Complex Networks Networks that arise from modeling complex systems: relationships Social networks Biological networks Distinguish from random networks uniform
Lecture 8: Linkage algorithms and web search
 Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
Lecture 8: Linkage algorithms and web search Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group ronan.cummins@cl.cam.ac.uk 2017
1 Starting around 1996, researchers began to work on. 2 In Feb, 1997, Yanhong Li (Scotch Plains, NJ) filed a
 filed a") !"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
!"#$ %#& ' Introduction ' Social network analysis ' Co-citation and bibliographic coupling ' PageRank ' HIS ' Summary ()*+,-/*,) Early search engines mainly compare content similarity of the query and
Data Mining Concepts & Tasks
 Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Jan 16, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Data Mining Concepts & Tasks Duen Horng (Polo) Chau Georgia Tech CSE6242 / CX4242 Jan 16, 2014 Partly based on materials by Professors Guy Lebanon, Jeffrey Heer, John Stasko, Christos Faloutsos Last Time
Detecting and Analyzing Communities in Social Network Graphs for Targeted Marketing
 Detecting and Analyzing Communities in Social Network Graphs for Targeted Marketing Gautam Bhat, Rajeev Kumar Singh Department of Computer Science and Engineering Shiv Nadar University Gautam Buddh Nagar,
Detecting and Analyzing Communities in Social Network Graphs for Targeted Marketing Gautam Bhat, Rajeev Kumar Singh Department of Computer Science and Engineering Shiv Nadar University Gautam Buddh Nagar,
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods
 Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Lecture Notes to Big Data Management and Analytics Winter Term 2017/2018 Node Importance and Neighborhoods Matthias Schubert, Matthias Renz, Felix Borutta, Evgeniy Faerman, Christian Frey, Klaus Arthur
Pregel. Ali Shah
 Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Data Mining Concepts. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Data Mining Concepts Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu HITS (Hypertext Induced Topic Selection) Is a measure of importance of pages or documents, similar to PageRank
Centralities (4) By: Ralucca Gera, NPS. Excellence Through Knowledge
 By: Ralucca Gera, NPS. Excellence Through Knowledge") Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Centralities (4) By: Ralucca Gera, NPS Excellence Through Knowledge Some slide from last week that we didn t talk about in class: 2 PageRank algorithm Eigenvector centrality: i s Rank score is the sum
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Analysis of Biological Networks. 1. Clustering 2. Random Walks 3. Finding paths
 Analysis of Biological Networks 1. Clustering 2. Random Walks 3. Finding paths Problem 1: Graph Clustering Finding dense subgraphs Applications Identification of novel pathways, complexes, other modules?
Analysis of Biological Networks 1. Clustering 2. Random Walks 3. Finding paths Problem 1: Graph Clustering Finding dense subgraphs Applications Identification of novel pathways, complexes, other modules?
CENTRALITIES. Carlo PICCARDI. DEIB - Department of Electronics, Information and Bioengineering Politecnico di Milano, Italy
 CENTRALITIES Carlo PICCARDI DEIB - Department of Electronics, Information and Bioengineering Politecnico di Milano, Italy email carlo.piccardi@polimi.it http://home.deib.polimi.it/piccardi Carlo Piccardi
CENTRALITIES Carlo PICCARDI DEIB - Department of Electronics, Information and Bioengineering Politecnico di Milano, Italy email carlo.piccardi@polimi.it http://home.deib.polimi.it/piccardi Carlo Piccardi
Graph Theory and Network Measurment
 Graph Theory and Network Measurment Social and Economic Networks MohammadAmin Fazli Social and Economic Networks 1 ToC Network Representation Basic Graph Theory Definitions (SE) Network Statistics and
Graph Theory and Network Measurment Social and Economic Networks MohammadAmin Fazli Social and Economic Networks 1 ToC Network Representation Basic Graph Theory Definitions (SE) Network Statistics and
Mining Web Data. Lijun Zhang
 Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
Mining Web Data Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction Web Crawling and Resource Discovery Search Engine Indexing and Query Processing Ranking Algorithms Recommender Systems
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu SPAM FARMING 2/11/2013 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 2/11/2013 Jure Leskovec, Stanford
Degree Distribution: The case of Citation Networks
 Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is a
Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is a
Apache Giraph. for applications in Machine Learning & Recommendation Systems. Maria Novartis
 Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Graph Data Management
 Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Information Retrieval Lecture 4: Web Search. Challenges of Web Search 2. Natural Language and Information Processing (NLIP) Group
 Group") Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Information Retrieval Lecture 4: Web Search Computer Science Tripos Part II Simone Teufel Natural Language and Information Processing (NLIP) Group sht25@cl.cam.ac.uk (Lecture Notes after Stephen Clark)
Mosaic: Processing a Trillion-Edge Graph on a Single Machine
 Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
Mosaic: Processing a Trillion-Edge Graph on a Single Machine Steffen Maass, Changwoo Min, Sanidhya Kashyap, Woonhak Kang, Mohan Kumar, Taesoo Kim Georgia Institute of Technology Best Student Paper @ EuroSys
CSE 190 Lecture 16. Data Mining and Predictive Analytics. Small-world phenomena
 CSE 190 Lecture 16 Data Mining and Predictive Analytics Small-world phenomena Another famous study Stanley Milgram wanted to test the (already popular) hypothesis that people in social networks are separated
CSE 190 Lecture 16 Data Mining and Predictive Analytics Small-world phenomena Another famous study Stanley Milgram wanted to test the (already popular) hypothesis that people in social networks are separated
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
Graph and Link Mining
 Graph and Link Mining Graphs - Basics A graph is a powerful abstraction for modeling entities and their pairwise relationships. G = (V,E) Set of nodes V = v,, v 5 Set of edges E = { v, v 2, v 4, v 5 }
Graph and Link Mining Graphs - Basics A graph is a powerful abstraction for modeling entities and their pairwise relationships. G = (V,E) Set of nodes V = v,, v 5 Set of edges E = { v, v 2, v 4, v 5 }
Mining Social Network Graphs
 Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
Mining Social Network Graphs Analysis of Large Graphs: Community Detection Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com Note to other teachers and users of these slides: We would be
Link Analysis. CSE 454 Advanced Internet Systems University of Washington. 1/26/12 16:36 1 Copyright D.S.Weld
 Link Analysis CSE 454 Advanced Internet Systems University of Washington 1/26/12 16:36 1 Ranking Search Results TF / IDF or BM25 Tag Information Title, headers Font Size / Capitalization Anchor Text on
Link Analysis CSE 454 Advanced Internet Systems University of Washington 1/26/12 16:36 1 Ranking Search Results TF / IDF or BM25 Tag Information Title, headers Font Size / Capitalization Anchor Text on
The Anatomy of a Large-Scale Hypertextual Web Search Engine
 The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
The Anatomy of a Large-Scale Hypertextual Web Search Engine Article by: Larry Page and Sergey Brin Computer Networks 30(1-7):107-117, 1998 1 1. Introduction The authors: Lawrence Page, Sergey Brin started
PEGASUS: A peta-scale graph mining system Implementation. and observations. U. Kang, C. E. Tsourakakis, C. Faloutsos
 PEGASUS: A peta-scale graph mining system Implementation and observations U. Kang, C. E. Tsourakakis, C. Faloutsos What is Pegasus? Open source Peta Graph Mining Library Can deal with very large Giga-,
PEGASUS: A peta-scale graph mining system Implementation and observations U. Kang, C. E. Tsourakakis, C. Faloutsos What is Pegasus? Open source Peta Graph Mining Library Can deal with very large Giga-,
A New Parallel Algorithm for Connected Components in Dynamic Graphs. Robert McColl Oded Green David Bader
 A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
Algorithmic and Economic Aspects of Networks. Nicole Immorlica
 Algorithmic and Economic Aspects of Networks Nicole Immorlica Syllabus 1. Jan. 8 th (today): Graph theory, network structure 2. Jan. 15 th : Random graphs, probabilistic network formation 3. Jan. 20 th
Algorithmic and Economic Aspects of Networks Nicole Immorlica Syllabus 1. Jan. 8 th (today): Graph theory, network structure 2. Jan. 15 th : Random graphs, probabilistic network formation 3. Jan. 20 th
Similarity Ranking in Large- Scale Bipartite Graphs
 Similarity Ranking in Large- Scale Bipartite Graphs Alessandro Epasto Brown University - 20 th March 2014 1 Joint work with J. Feldman, S. Lattanzi, S. Leonardi, V. Mirrokni [WWW, 2014] 2 AdWords Ads Ads
Similarity Ranking in Large- Scale Bipartite Graphs Alessandro Epasto Brown University - 20 th March 2014 1 Joint work with J. Feldman, S. Lattanzi, S. Leonardi, V. Mirrokni [WWW, 2014] 2 AdWords Ads Ads
Jure Leskovec Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah
 Jure Leskovec (@jure) Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah 2 My research group at Stanford: Mining and modeling large social and information networks
Jure Leskovec (@jure) Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah 2 My research group at Stanford: Mining and modeling large social and information networks
Advanced Computer Architecture: A Google Search Engine
 Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
Advanced Computer Architecture: A Google Search Engine Jeremy Bradley Room 372. Office hour - Thursdays at 3pm. Email: jb@doc.ic.ac.uk Course notes: http://www.doc.ic.ac.uk/ jb/ Department of Computing,
Using! to Teach Graph Theory
 !! Using! to Teach Graph Theory Todd Abel Mary Elizabeth Searcy Appalachian State University Why Graph Theory? Mathematical Thinking (Habits of Mind, Mathematical Practices) Accessible to students at a
!! Using! to Teach Graph Theory Todd Abel Mary Elizabeth Searcy Appalachian State University Why Graph Theory? Mathematical Thinking (Habits of Mind, Mathematical Practices) Accessible to students at a
DSCI 575: Advanced Machine Learning. PageRank Winter 2018
 DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
DSCI 575: Advanced Machine Learning PageRank Winter 2018 http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf Web Search before Google Unsupervised Graph-Based Ranking We want to rank importance based on
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
CS425: Algorithms for Web Scale Data
 CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
CS425: Algorithms for Web Scale Data Most of the slides are from the Mining of Massive Datasets book. These slides have been modified for CS425. The original slides can be accessed at: www.mmds.org J.
Data mining --- mining graphs
 Data mining --- mining graphs University of South Florida Xiaoning Qian Today s Lecture 1. Complex networks 2. Graph representation for networks 3. Markov chain 4. Viral propagation 5. Google s PageRank
Data mining --- mining graphs University of South Florida Xiaoning Qian Today s Lecture 1. Complex networks 2. Graph representation for networks 3. Markov chain 4. Viral propagation 5. Google s PageRank
PageRank. CS16: Introduction to Data Structures & Algorithms Spring 2018
 PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
PageRank CS16: Introduction to Data Structures & Algorithms Spring 2018 Outline Background The Internet World Wide Web Search Engines The PageRank Algorithm Basic PageRank Full PageRank Spectral Analysis
Overview of this week
 Overview of this week Debugging tips for ML algorithms Graph algorithms at scale A prototypical graph algorithm: PageRank n memory Putting more and more on disk Sampling from a graph What is a good sample
Overview of this week Debugging tips for ML algorithms Graph algorithms at scale A prototypical graph algorithm: PageRank n memory Putting more and more on disk Sampling from a graph What is a good sample
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org A 3.3 B 38.4 C 34.3 D 3.9 E 8.1 F 3.9 1.6 1.6 1.6 1.6 1.6 2 y 0.8 ½+0.2 ⅓ M 1/2 1/2 0 0.8 1/2 0 0 + 0.2 0 1/2 1 [1/N]
Graph Theory Problem Ideas
 Graph Theory Problem Ideas April 15, 017 Note: Please let me know if you have a problem that you would like me to add to the list! 1 Classification Given a degree sequence d 1,...,d n, let N d1,...,d n
Graph Theory Problem Ideas April 15, 017 Note: Please let me know if you have a problem that you would like me to add to the list! 1 Classification Given a degree sequence d 1,...,d n, let N d1,...,d n
Sampling Large Graphs for Anticipatory Analysis
 Sampling Large Graphs for Anticipatory Analysis Lauren Edwards*, Luke Johnson, Maja Milosavljevic, Vijay Gadepally, Benjamin A. Miller IEEE High Performance Extreme Computing Conference September 16, 2015
Sampling Large Graphs for Anticipatory Analysis Lauren Edwards*, Luke Johnson, Maja Milosavljevic, Vijay Gadepally, Benjamin A. Miller IEEE High Performance Extreme Computing Conference September 16, 2015
Structure of Social Networks
 Structure of Social Networks Outline Structure of social networks Applications of structural analysis Social *networks* Twitter Facebook Linked-in IMs Email Real life Address books... Who Twitter #numbers
Structure of Social Networks Outline Structure of social networks Applications of structural analysis Social *networks* Twitter Facebook Linked-in IMs Email Real life Address books... Who Twitter #numbers
A Survey of Google's PageRank
 http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
http://pr.efactory.de/ A Survey of Google's PageRank Within the past few years, Google has become the far most utilized search engine worldwide. A decisive factor therefore was, besides high performance
Network Centrality. Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017
 Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Network Centrality Saptarshi Ghosh Department of CSE, IIT Kharagpur Social Computing course, CS60017 Node centrality n Relative importance of a node in a network n How influential a person is within a
Sergei Silvestrov, Christopher Engström. January 29, 2013
 Sergei Silvestrov, January 29, 2013 L2: t Todays lecture:. L2: t Todays lecture:. measurements. L2: t Todays lecture:. measurements. s. L2: t Todays lecture:. measurements. s.. First we would like to define
Sergei Silvestrov, January 29, 2013 L2: t Todays lecture:. L2: t Todays lecture:. measurements. L2: t Todays lecture:. measurements. s. L2: t Todays lecture:. measurements. s.. First we would like to define
ScienceDirect A NOVEL APPROACH FOR ANALYZING THE SOCIAL NETWORK
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 48 (2015 ) 686 691 International Conference on Intelligent Computing, Communication & Convergence (ICCC-2015) (ICCC-2014)
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 48 (2015 ) 686 691 International Conference on Intelligent Computing, Communication & Convergence (ICCC-2015) (ICCC-2014)
Graph Analytics and Machine Learning A Great Combination Mark Hornick
 Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Graph Analytics and Machine Learning A Great Combination Mark Hornick Oracle Advanced Analytics and Machine Learning November 3, 2017 Safe Harbor Statement The following is intended to outline our research
Einführung in Web und Data Science Community Analysis. Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme
 Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Einführung in Web und Data Science Community Analysis Prof. Dr. Ralf Möller Universität zu Lübeck Institut für Informationssysteme Today s lecture Anchor text Link analysis for ranking Pagerank and variants
Introduction Types of Social Network Analysis Social Networks in the Online Age Data Mining for Social Network Analysis Applications Conclusion
 Introduction Types of Social Network Analysis Social Networks in the Online Age Data Mining for Social Network Analysis Applications Conclusion References Social Network Social Network Analysis Sociocentric
Introduction Types of Social Network Analysis Social Networks in the Online Age Data Mining for Social Network Analysis Applications Conclusion References Social Network Social Network Analysis Sociocentric
Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System
 Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System Seunghwa Kang David A. Bader 1 A Challenge Problem Extracting a subgraph from
Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System Seunghwa Kang David A. Bader 1 A Challenge Problem Extracting a subgraph from
HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration
![HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration](/thumbs/86/94153784.jpg "HW 4: PageRank & MapReduce. 1 Warmup with PageRank and stationary distributions [10 points], collaboration") CMS/CS/EE 144 Assigned: 1/25/2018 HW 4: PageRank & MapReduce Guru: Joon/Cathy Due: 2/1/2018 at 10:30am We encourage you to discuss these problems with others, but you need to write up the actual solutions
CMS/CS/EE 144 Assigned: 1/25/2018 HW 4: PageRank & MapReduce Guru: Joon/Cathy Due: 2/1/2018 at 10:30am We encourage you to discuss these problems with others, but you need to write up the actual solutions
Diffusion and Clustering on Large Graphs
 Diffusion and Clustering on Large Graphs Alexander Tsiatas Final Defense 17 May 2012 Introduction Graphs are omnipresent in the real world both natural and man-made Examples of large graphs: The World
Diffusion and Clustering on Large Graphs Alexander Tsiatas Final Defense 17 May 2012 Introduction Graphs are omnipresent in the real world both natural and man-made Examples of large graphs: The World
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today
 HW3 will be posted today") 3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu
3 announcements: Thanks for filling out the HW1 poll HW2 is due today 5pm (scans must be readable) HW3 will be posted today CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu