GRAMPS Beyond Rendering. Jeremy Sugerman 11 December 2009 PPL Retreat
|
|
|
- Regina Harrison
- 5 years ago
- Views:
Transcription
1 GRAMPS Beyond Rendering Jeremy Sugerman 11 December 2009 PPL Retreat
 Domain Embedding Language (Scala) DSL Infrastructure Domain specific optimization Common Parallel Runtime (Delite, Sequoia) Task & data parallelism Locality aware scheduling")
2 The PPL Vision: GRAMPS Applications Scientific Engineering Virtual Worlds Personal Robotics Data informatics Domain Specific Languages Rendering Physics (Liszt) Scripting Probabilistic Machine Learning (OptiML) Domain Embedding Language (Scala) DSL Infrastructure Domain specific optimization Common Parallel Runtime (Delite, Sequoia) Task & data parallelism Locality aware scheduling Heterogeneous Hardware OOO Cores Programmable Hierarchies Hardware Architecture SIMD Cores Scalable Coherence Threaded Cores Isolation & Atomicity Pervasive Monitoring 2
3 Introduction Past: GRAMPS for building renderers This Talk: GRAMPS in two new domains: map-reduce and rigid body physics Brief mention of other GRAMPS projects 3
4 GRAMPS Review (1) Programming model / API / run-time for heterogeneous many-core machines Applications are: Graphs of multiple stages (cycles allowed) Connected via queues Interesting workloads are irregular 4
5 GRAMPS Review (2) Shaders: data-parallel, plus push Threads/Fixed-function: stateful / tasks Rast Fragment Shade Example Rasterization Pipeline Blend Framebuffer 5
6 GRAMPS Review (3) Rast Queue set: Fragment Shade Blend single logical queue, independent subqueues Synchronization and parallel consumption Binning, screen-space subdivision, etc. Framebuffer 6
7 Map-Reduce Popular parallel idiom: Map: Foreach(input) { Do something Emit(key, &val) } Reduce: Foreach(key) { Process values EmitFinalResult() } Used at both cluster and multi-core scale Analytics, indexing, machine learning, 7
8 Map-Reduce: Combine Reduce often has high overhead: Buffering of intermediate pairs (storage, stall) Load imbalance across keys Serialization within a key In practice, Reduce is often associative and commutative (and simple). Combine phase enables incremental, parallel reduction 8
9 Preparing GRAMPS for Map-Reduce
10 Queue Sets, Instanced Threads Make queue sets more dynamic Create subqueues on demand Sparsely indexed keyed subqueues ANY_SUBQUEUE flag for Reserve Make-Grid(obj): For (cells in o.bbox) { key = linearize(cell) PushKey(out, key, &o) Collide(subqueue): For (each o1, o2 pair) if (o1 overlaps o2)... } 10
11 Fan-in Shaders Use shaders for parallel partial reductions Input: One packet, Output: One element Can operate in-place or as a filter Run-time coalesces mostly empty packets Histogram(pixels): For (i < pixels.numel){ c =.3r +.6g +.1b PushKey(out,c/256,1) } Sum(packet): For (i < packet.numel) sum += packet.v[i] packet.v[0] = sum packet.numel = 1 11
12 Fan-in + In-place is a builtin Alternatives: Regular shader accumulating with atomics GPGPU multi-pass shader reduction Manually replicated thread stages Fan-in with same queue as input and output Reality: Messy, micro-managed, slow Run-time should hide complexity, not export it 12
13 GRAMPS Map-Reduce Input Params Produce Splits Map Three Apps (based on Phoenix): Histogram, Linear Regression, PCA Run-time Provides: Pairs: Key0: vals[] Key1: vals[] Combine (in-place) Pairs: Key0: vals[] Key1: vals[] Reduce (instanced) API, GRAMPS bindings, elems per packet Output 13
14 Map-Reduce App Results Occupancy Footprint Footprint (CPU-Like) (Avg.) (Peak) Histogram % 2300 KB 4700 KB (combine) 96.2% 10 KB 20 KB LR % 100 KB 205 KB (combine) 97.0% 1 KB 1.5 KB PCA %.5 KB 1 KB 14

15 Reduce vs Combine: Histogram Reduce Combine 15
16 Two Pass: PCA (GPU-Like) 16

17 Sphere Physics 17
18 GRAMPS: Sphere Physics Params Spheres Split Make Grid Collide Cell Resolve 1. Split Spheres into chunks of N 2. Emit(cell, spherenum) for each sphere 3. Emit(s1, s2) for each intersection in cell 4. For each sphere, resolve and update 18
19 256 Spheres (CPU-Like) 19

20 Other People s Work Improved sim: model ILP and caches Micropolygon rasterization, fixed functions x86 many-core: 20
21 Thank You Questions? 21
22 Backup Slides
23 Optimizations for Map-Reduce Aggressive shader instancing Per-subqueue push coalescing Per-core scoreboard 23
24 GRAMPS Map-Reduce Apps Based on Phoenix map-reduce apps: Histogram: Quantize input image into 256 buckets Linear Regression: For a set of (x,y) pairs, compute average x, x², y, y², and xy PCA: For a matrix M, compute the mean of each row and the covariance of all pairs of rows 24
25 Histogram 512x512 25

26 Histogram 512x512 (Combine) 26

27 Histogram 512x512 (GPU) 27
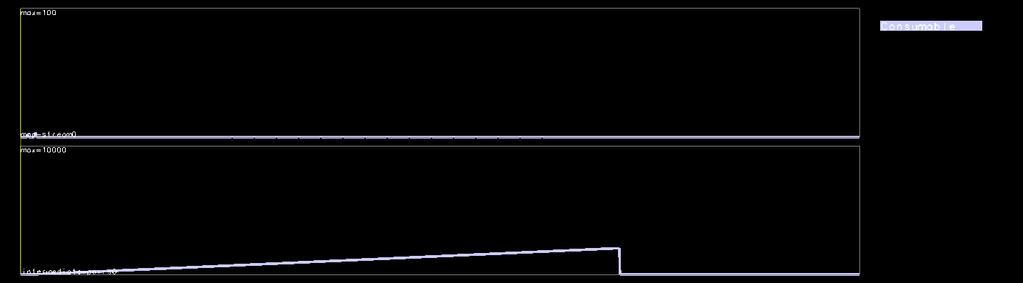

28 Linear Regression

29 PCA 128x128 (CPU) 29
30 Sphere Physics A (simplified) proxy for rigid body physics: Generate N spheres, initial velocity while(true) { } Find all pairs of intersecting spheres Compute v to resolve collision (conserve energy, momentum) Compute updated result velocity and position 30
31 Future Work Tuning: Push, combine coalesce efficiency Map-Reduce chunk sizes for split, reduce Extensions to enable more shader usage in Sphere Physics? Flesh out how/where to apply application enhancements, optimizations 31
Further Developing GRAMPS. Jeremy Sugerman FLASHG January 27, 2009
 Further Developing GRAMPS Jeremy Sugerman FLASHG January 27, 2009 Introduction Evaluation of what/where GRAMPS is today Planned next steps New graphs: MapReduce and Cloth Sim Speculative potpourri, outside
Further Developing GRAMPS Jeremy Sugerman FLASHG January 27, 2009 Introduction Evaluation of what/where GRAMPS is today Planned next steps New graphs: MapReduce and Cloth Sim Speculative potpourri, outside
Introduction to Parallel Programming Models
 Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
Introduction to Parallel Programming Models Tim Foley Stanford University Beyond Programmable Shading 1 Overview Introduce three kinds of parallelism Used in visual computing Targeting throughput architectures
GRAMPS: A Programming Model for Graphics Pipelines and Heterogeneous Parallelism Jeremy Sugerman March 5, 2009 EEC277
 GRAMPS: A Programming Model for Graphics Pipelines and Heterogeneous Parallelism Jeremy Sugerman March 5, 2009 EEC277 History GRAMPS grew from, among other things, our GPGPU and Cell processor work, especially
GRAMPS: A Programming Model for Graphics Pipelines and Heterogeneous Parallelism Jeremy Sugerman March 5, 2009 EEC277 History GRAMPS grew from, among other things, our GPGPU and Cell processor work, especially
Dynamic Fine Grain Scheduling of Pipeline Parallelism. Presented by: Ram Manohar Oruganti and Michael TeWinkle
 Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Dynamic Fine Grain Scheduling of Pipeline Parallelism Presented by: Ram Manohar Oruganti and Michael TeWinkle Overview Introduction Motivation Scheduling Approaches GRAMPS scheduling method Evaluation
Next-Generation Graphics on Larrabee. Tim Foley Intel Corp
 Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
Next-Generation Graphics on Larrabee Tim Foley Intel Corp Motivation The killer app for GPGPU is graphics We ve seen Abstract models for parallel programming How those models map efficiently to Larrabee
Delite: A Framework for Heterogeneous Parallel DSLs
 Delite: A Framework for Heterogeneous Parallel DSLs Hassan Chafi, Arvind Sujeeth, Kevin Brown, HyoukJoong Lee, Kunle Olukotun Stanford University Tiark Rompf, Martin Odersky EPFL Heterogeneous Parallel
Delite: A Framework for Heterogeneous Parallel DSLs Hassan Chafi, Arvind Sujeeth, Kevin Brown, HyoukJoong Lee, Kunle Olukotun Stanford University Tiark Rompf, Martin Odersky EPFL Heterogeneous Parallel
Real-Time Reyes: Programmable Pipelines and Research Challenges. Anjul Patney University of California, Davis
 Real-Time Reyes: Programmable Pipelines and Research Challenges Anjul Patney University of California, Davis Real-Time Reyes-Style Adaptive Surface Subdivision Anjul Patney and John D. Owens SIGGRAPH Asia
Real-Time Reyes: Programmable Pipelines and Research Challenges Anjul Patney University of California, Davis Real-Time Reyes-Style Adaptive Surface Subdivision Anjul Patney and John D. Owens SIGGRAPH Asia
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS.
 About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED
About Phoenix FD PLUGIN FOR 3DS MAX AND MAYA. SIMULATING AND RENDERING BOTH LIQUIDS AND FIRE/SMOKE. USED IN MOVIES, GAMES AND COMMERCIALS. Phoenix FD core SIMULATION & RENDERING. SIMULATION CORE - GRID-BASED
Kunle Olukotun Pervasive Parallelism Laboratory Stanford University
 Kunle Olukotun Pervasive Parallelism Laboratory Stanford University Unleash full power of future computing platforms Make parallel application development practical for the masses (Joe the programmer)
Kunle Olukotun Pervasive Parallelism Laboratory Stanford University Unleash full power of future computing platforms Make parallel application development practical for the masses (Joe the programmer)
PowerVR Hardware. Architecture Overview for Developers
 Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Hardware Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Lecture 6: Input Compaction and Further Studies
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions.
 1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
Working with Metal Overview
 Graphics and Games #WWDC14 Working with Metal Overview Session 603 Jeremy Sandmel GPU Software 2014 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission
Graphics and Games #WWDC14 Working with Metal Overview Session 603 Jeremy Sandmel GPU Software 2014 Apple Inc. All rights reserved. Redistribution or public display not permitted without written permission
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Today Finishing up from last time Brief discussion of graphics workload metrics
GPU Memory Model Overview
 GPU Memory Model Overview John Owens University of California, Davis Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization SciDAC Institute for Ultrascale Visualization
GPU Memory Model Overview John Owens University of California, Davis Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization SciDAC Institute for Ultrascale Visualization
Beyond Programmable Shading Keeping Many Cores Busy: Scheduling the Graphics Pipeline
 Keeping Many s Busy: Scheduling the Graphics Pipeline Jonathan Ragan-Kelley, MIT CSAIL 29 July 2010 This talk How to think about scheduling GPU-style pipelines Four constraints which drive scheduling decisions
Keeping Many s Busy: Scheduling the Graphics Pipeline Jonathan Ragan-Kelley, MIT CSAIL 29 July 2010 This talk How to think about scheduling GPU-style pipelines Four constraints which drive scheduling decisions
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Beyond Programmable Shading. Scheduling the Graphics Pipeline
 Beyond Programmable Shading Scheduling the Graphics Pipeline Jonathan Ragan-Kelley, MIT CSAIL 9 August 2011 Mike s just showed how shaders can use large, coherent batches of work to achieve high throughput.
Beyond Programmable Shading Scheduling the Graphics Pipeline Jonathan Ragan-Kelley, MIT CSAIL 9 August 2011 Mike s just showed how shaders can use large, coherent batches of work to achieve high throughput.
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Scalable Multi Agent Simulation on the GPU. Avi Bleiweiss NVIDIA Corporation San Jose, 2009
 Scalable Multi Agent Simulation on the GPU Avi Bleiweiss NVIDIA Corporation San Jose, 2009 Reasoning Explicit State machine, serial Implicit Compute intensive Fits SIMT well Collision avoidance Motivation
Scalable Multi Agent Simulation on the GPU Avi Bleiweiss NVIDIA Corporation San Jose, 2009 Reasoning Explicit State machine, serial Implicit Compute intensive Fits SIMT well Collision avoidance Motivation
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
") Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems
 Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems Matthew D. Sinclair *, Johnathan Alsop^, Sarita V. Adve + * University of Wisconsin-Madison ^ AMD Research + University
Chasing Away RAts: Semantics and Evaluation for Relaxed Atomics on Heterogeneous Systems Matthew D. Sinclair *, Johnathan Alsop^, Sarita V. Adve + * University of Wisconsin-Madison ^ AMD Research + University
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
The Application Stage. The Game Loop, Resource Management and Renderer Design
 1 The Application Stage The Game Loop, Resource Management and Renderer Design Application Stage Responsibilities 2 Set up the rendering pipeline Resource Management 3D meshes Textures etc. Prepare data
1 The Application Stage The Game Loop, Resource Management and Renderer Design Application Stage Responsibilities 2 Set up the rendering pipeline Resource Management 3D meshes Textures etc. Prepare data
Apple LLVM GPU Compiler: Embedded Dragons. Charu Chandrasekaran, Apple Marcello Maggioni, Apple
 Apple LLVM GPU Compiler: Embedded Dragons Charu Chandrasekaran, Apple Marcello Maggioni, Apple 1 Agenda How Apple uses LLVM to build a GPU Compiler Factors that affect GPU performance The Apple GPU compiler
Apple LLVM GPU Compiler: Embedded Dragons Charu Chandrasekaran, Apple Marcello Maggioni, Apple 1 Agenda How Apple uses LLVM to build a GPU Compiler Factors that affect GPU performance The Apple GPU compiler
Scaling Without Sharding. Baron Schwartz Percona Inc Surge 2010
 Scaling Without Sharding Baron Schwartz Percona Inc Surge 2010 Web Scale!!!! http://www.xtranormal.com/watch/6995033/ A Sharding Thought Experiment 64 shards per proxy [1] 1 TB of data storage per node
Scaling Without Sharding Baron Schwartz Percona Inc Surge 2010 Web Scale!!!! http://www.xtranormal.com/watch/6995033/ A Sharding Thought Experiment 64 shards per proxy [1] 1 TB of data storage per node
Could you make the XNA functions yourself?
 1 Could you make the XNA functions yourself? For the second and especially the third assignment, you need to globally understand what s going on inside the graphics hardware. You will write shaders, which
1 Could you make the XNA functions yourself? For the second and especially the third assignment, you need to globally understand what s going on inside the graphics hardware. You will write shaders, which
Enhancing Traditional Rasterization Graphics with Ray Tracing. October 2015
 Enhancing Traditional Rasterization Graphics with Ray Tracing October 2015 James Rumble Developer Technology Engineer, PowerVR Graphics Overview Ray Tracing Fundamentals PowerVR Ray Tracing Pipeline Using
Enhancing Traditional Rasterization Graphics with Ray Tracing October 2015 James Rumble Developer Technology Engineer, PowerVR Graphics Overview Ray Tracing Fundamentals PowerVR Ray Tracing Pipeline Using
Parallel Compact Roadmap Construction of 3D Virtual Environments on the GPU
 Parallel Compact Roadmap Construction of 3D Virtual Environments on the GPU Avi Bleiweiss NVIDIA Corporation Programmability GPU Computing CUDA C++ Parallel Debug Heterogeneous Computing Productivity Efficiency
Parallel Compact Roadmap Construction of 3D Virtual Environments on the GPU Avi Bleiweiss NVIDIA Corporation Programmability GPU Computing CUDA C++ Parallel Debug Heterogeneous Computing Productivity Efficiency
Virtual Reality in Assembly Simulation
 Virtual Reality in Assembly Simulation Collision Detection, Simulation Algorithms, and Interaction Techniques Contents 1. Motivation 2. Simulation and description of virtual environments 3. Interaction
Virtual Reality in Assembly Simulation Collision Detection, Simulation Algorithms, and Interaction Techniques Contents 1. Motivation 2. Simulation and description of virtual environments 3. Interaction
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Hammer Slide: Work- and CPU-efficient Streaming Window Aggregation
 Large-Scale Data & Systems Group Hammer Slide: Work- and CPU-efficient Streaming Window Aggregation Georgios Theodorakis, Alexandros Koliousis, Peter Pietzuch, Holger Pirk Large-Scale Data & Systems (LSDS)
Large-Scale Data & Systems Group Hammer Slide: Work- and CPU-efficient Streaming Window Aggregation Georgios Theodorakis, Alexandros Koliousis, Peter Pietzuch, Holger Pirk Large-Scale Data & Systems (LSDS)
Overview. Think Silicon is a privately held company founded in 2007 by the core team of Atmel MMC IC group
 Nema An OpenGL & OpenCL Embedded Programmable Engine Georgios Keramidas & Iakovos Stamoulis Think Silicon mobile GRAPHICS Overview Think Silicon is a privately held company founded in 2007 by the core
Nema An OpenGL & OpenCL Embedded Programmable Engine Georgios Keramidas & Iakovos Stamoulis Think Silicon mobile GRAPHICS Overview Think Silicon is a privately held company founded in 2007 by the core
Scheduling the Graphics Pipeline on a GPU
 Lecture 20: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems Today Real-time 3D graphics workload metrics Scheduling the graphics pipeline on a modern GPU Quick aside: tessellation Triangle
Lecture 20: Scheduling the Graphics Pipeline on a GPU Visual Computing Systems Today Real-time 3D graphics workload metrics Scheduling the graphics pipeline on a modern GPU Quick aside: tessellation Triangle
Simplifying Parallel Programming with Domain Specific Languages
 Simplifying Parallel Programming with Domain Specific Languages Hassan Chafi, HyoukJoong Lee, Arvind Sujeeth, Kevin Brown, Anand Atreya, Nathan Bronson, Kunle Olukotun Stanford University Pervasive Parallelism
Simplifying Parallel Programming with Domain Specific Languages Hassan Chafi, HyoukJoong Lee, Arvind Sujeeth, Kevin Brown, Anand Atreya, Nathan Bronson, Kunle Olukotun Stanford University Pervasive Parallelism
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Anatomy of AMD s TeraScale Graphics Engine
 Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
Anatomy of AMD s TeraScale Graphics Engine Mike Houston Design Goals Focus on Efficiency f(perf/watt, Perf/$) Scale up processing power and AA performance Target >2x previous generation Enhance stream
A DOMAIN SPECIFIC APPROACH TO HETEROGENEOUS PARALLELISM
 A DOMAIN SPECIFIC APPROACH TO HETEROGENEOUS PARALLELISM Hassan Chafi, Arvind Sujeeth, Kevin Brown, HyoukJoong Lee, Anand Atreya, Kunle Olukotun Stanford University Pervasive Parallelism Laboratory (PPL)
A DOMAIN SPECIFIC APPROACH TO HETEROGENEOUS PARALLELISM Hassan Chafi, Arvind Sujeeth, Kevin Brown, HyoukJoong Lee, Anand Atreya, Kunle Olukotun Stanford University Pervasive Parallelism Laboratory (PPL)
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Capriccio : Scalable Threads for Internet Services
 Capriccio : Scalable Threads for Internet Services - Ron von Behren &et al - University of California, Berkeley. Presented By: Rajesh Subbiah Background Each incoming request is dispatched to a separate
Capriccio : Scalable Threads for Internet Services - Ron von Behren &et al - University of California, Berkeley. Presented By: Rajesh Subbiah Background Each incoming request is dispatched to a separate
Here s the general problem we want to solve efficiently: Given a light and a set of pixels in view space, resolve occlusion between each pixel and
 1 Here s the general problem we want to solve efficiently: Given a light and a set of pixels in view space, resolve occlusion between each pixel and the light. 2 To visualize this problem, consider the
1 Here s the general problem we want to solve efficiently: Given a light and a set of pixels in view space, resolve occlusion between each pixel and the light. 2 To visualize this problem, consider the
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Dynamic Fine-Grain Scheduling of Pipeline Parallelism
 Appears in the Proceedings of the th International Conference on Parallel Architectures and Compilation Techniques (PACT), 11 Dynamic Fine-Grain Scheduling of Pipeline Parallelism Daniel Sanchez, David
Appears in the Proceedings of the th International Conference on Parallel Architectures and Compilation Techniques (PACT), 11 Dynamic Fine-Grain Scheduling of Pipeline Parallelism Daniel Sanchez, David
Building scalable 3D applications. Ville Miettinen Hybrid Graphics
 Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
Building scalable 3D applications Ville Miettinen Hybrid Graphics What s going to happen... (1/2) Mass market: 3D apps will become a huge success on low-end and mid-tier cell phones Retro-gaming New game
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
Architecture-Conscious Database Systems
 Architecture-Conscious Database Systems 2009 VLDB Summer School Shanghai Peter Boncz (CWI) Sources Thank You! l l l l Database Architectures for New Hardware VLDB 2004 tutorial, Anastassia Ailamaki Query
Architecture-Conscious Database Systems 2009 VLDB Summer School Shanghai Peter Boncz (CWI) Sources Thank You! l l l l Database Architectures for New Hardware VLDB 2004 tutorial, Anastassia Ailamaki Query
PowerVR Series5. Architecture Guide for Developers
 Public Imagination Technologies PowerVR Series5 Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
Public Imagination Technologies PowerVR Series5 Public. This publication contains proprietary information which is subject to change without notice and is supplied 'as is' without warranty of any kind.
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
Accelerating MapReduce on a Coupled CPU-GPU Architecture
 Accelerating MapReduce on a Coupled CPU-GPU Architecture Linchuan Chen Xin Huo Gagan Agrawal Department of Computer Science and Engineering The Ohio State University Columbus, OH 43210 {chenlinc,huox,agrawal}@cse.ohio-state.edu
Accelerating MapReduce on a Coupled CPU-GPU Architecture Linchuan Chen Xin Huo Gagan Agrawal Department of Computer Science and Engineering The Ohio State University Columbus, OH 43210 {chenlinc,huox,agrawal}@cse.ohio-state.edu
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance
 Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance Rachata Ausavarungnirun Saugata Ghose, Onur Kayiran, Gabriel H. Loh Chita Das, Mahmut Kandemir, Onur Mutlu Overview of This Talk Problem:
Exploiting Inter-Warp Heterogeneity to Improve GPGPU Performance Rachata Ausavarungnirun Saugata Ghose, Onur Kayiran, Gabriel H. Loh Chita Das, Mahmut Kandemir, Onur Mutlu Overview of This Talk Problem:
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps
 A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
A Case for Core-Assisted Bottleneck Acceleration in GPUs Enabling Flexible Data Compression with Assist Warps Nandita Vijaykumar Gennady Pekhimenko, Adwait Jog, Abhishek Bhowmick, Rachata Ausavarangnirun,
EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT
 EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT JOSEPH L. GREATHOUSE, MAYANK DAGA AMD RESEARCH 11/20/2014 THIS TALK IN ONE SLIDE Demonstrate how to save space and time
EFFICIENT SPARSE MATRIX-VECTOR MULTIPLICATION ON GPUS USING THE CSR STORAGE FORMAT JOSEPH L. GREATHOUSE, MAYANK DAGA AMD RESEARCH 11/20/2014 THIS TALK IN ONE SLIDE Demonstrate how to save space and time
Vulkan: Architecture positive How Vulkan maps to PowerVR GPUs Kevin sun Lead Developer Support Engineer, APAC PowerVR Graphics.
 Vulkan: Architecture positive How Vulkan maps to PowerVR GPUs Kevin sun Lead Developer Support Engineer, APAC PowerVR Graphics www.imgtec.com Introduction Who am I? Kevin Sun Working at Imagination Technologies
Vulkan: Architecture positive How Vulkan maps to PowerVR GPUs Kevin sun Lead Developer Support Engineer, APAC PowerVR Graphics www.imgtec.com Introduction Who am I? Kevin Sun Working at Imagination Technologies
Whiz-Bang Graphics and Media Performance for Java Platform, Micro Edition (JavaME)
") Whiz-Bang Graphics and Media Performance for Java Platform, Micro Edition (JavaME) Pavel Petroshenko, Sun Microsystems, Inc. Ashmi Bhanushali, NVIDIA Corporation Jerry Evans, Sun Microsystems, Inc. Nandini
Whiz-Bang Graphics and Media Performance for Java Platform, Micro Edition (JavaME) Pavel Petroshenko, Sun Microsystems, Inc. Ashmi Bhanushali, NVIDIA Corporation Jerry Evans, Sun Microsystems, Inc. Nandini
Take GPU Processing Power Beyond Graphics with Mali GPU Computing
 Take GPU Processing Power Beyond Graphics with Mali GPU Computing Roberto Mijat Visual Computing Marketing Manager August 2012 Introduction Modern processor and SoC architectures endorse parallelism as
Take GPU Processing Power Beyond Graphics with Mali GPU Computing Roberto Mijat Visual Computing Marketing Manager August 2012 Introduction Modern processor and SoC architectures endorse parallelism as
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ME964 High Performance Computing for Engineering Applications Execution Scheduling in CUDA Revisiting Memory Issues in CUDA February 17, 2011 Dan Negrut, 2011 ME964 UW-Madison Computers are useless. They
ADR and DataCutter. Sergey Koren CMSC818S. Thursday March 4 th, 2004
 ADR and DataCutter Sergey Koren CMSC818S Thursday March 4 th, 2004 Active Data Repository Used for building parallel databases from multidimensional data sets Integrates storage, retrieval, and processing
ADR and DataCutter Sergey Koren CMSC818S Thursday March 4 th, 2004 Active Data Repository Used for building parallel databases from multidimensional data sets Integrates storage, retrieval, and processing
Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload)
") Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Lecture 2: Parallelizing Graphics Pipeline Execution (+ Basics of Characterizing a Rendering Workload) Visual Computing Systems Analyzing a 3D Graphics Workload Where is most of the work done? Memory Vertex
Enabling immersive gaming experiences Intro to Ray Tracing
 Enabling immersive gaming experiences Intro to Ray Tracing Overview What is Ray Tracing? Why Ray Tracing? PowerVR Wizard Architecture Example Content Unity Hybrid Rendering Demonstration 3 What is Ray
Enabling immersive gaming experiences Intro to Ray Tracing Overview What is Ray Tracing? Why Ray Tracing? PowerVR Wizard Architecture Example Content Unity Hybrid Rendering Demonstration 3 What is Ray
Duksu Kim. Professional Experience Senior researcher, KISTI High performance visualization
 Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Duksu Kim Assistant professor, KORATEHC Education Ph.D. Computer Science, KAIST Parallel Proximity Computation on Heterogeneous Computing Systems for Graphics Applications Professional Experience Senior
Comparing Memory Systems for Chip Multiprocessors
 Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
B-KD Trees for Hardware Accelerated Ray Tracing of Dynamic Scenes
 B-KD rees for Hardware Accelerated Ray racing of Dynamic Scenes Sven Woop Gerd Marmitt Philipp Slusallek Saarland University, Germany Outline Previous Work B-KD ree as new Spatial Index Structure DynR
B-KD rees for Hardware Accelerated Ray racing of Dynamic Scenes Sven Woop Gerd Marmitt Philipp Slusallek Saarland University, Germany Outline Previous Work B-KD ree as new Spatial Index Structure DynR
Programming as Successive Refinement. Partitioning for Performance
 Programming as Successive Refinement Not all issues dealt with up front Partitioning often independent of architecture, and done first View machine as a collection of communicating processors balancing
Programming as Successive Refinement Not all issues dealt with up front Partitioning often independent of architecture, and done first View machine as a collection of communicating processors balancing
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Kunle Olukotun. EPFL August 26, 2009
 Kunle Olukotun EPFL August 26, 2009 The end of uniprocessors Embedded, server, desktop New Moore s Law is 2X cores per chip every technology generation Cores are the new GHz! No other viable options for
Kunle Olukotun EPFL August 26, 2009 The end of uniprocessors Embedded, server, desktop New Moore s Law is 2X cores per chip every technology generation Cores are the new GHz! No other viable options for
Accelerating CFD with Graphics Hardware
 Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
PROCESS VIRTUAL MEMORY. CS124 Operating Systems Winter , Lecture 18
 PROCESS VIRTUAL MEMORY CS124 Operating Systems Winter 2015-2016, Lecture 18 2 Programs and Memory Programs perform many interactions with memory Accessing variables stored at specific memory locations
PROCESS VIRTUAL MEMORY CS124 Operating Systems Winter 2015-2016, Lecture 18 2 Programs and Memory Programs perform many interactions with memory Accessing variables stored at specific memory locations
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Shaders. Slide credit to Prof. Zwicker
 Shaders Slide credit to Prof. Zwicker 2 Today Shader programming 3 Complete model Blinn model with several light sources i diffuse specular ambient How is this implemented on the graphics processor (GPU)?
Shaders Slide credit to Prof. Zwicker 2 Today Shader programming 3 Complete model Blinn model with several light sources i diffuse specular ambient How is this implemented on the graphics processor (GPU)?
Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Active thread Idle thread
 Active thread Idle thread") Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Intra-Warp Compaction Techniques Sudhakar Yalamanchili, Georgia Institute of Technology (except as indicated) Goal Active thread Idle thread Compaction Compact threads in a warp to coalesce (and eliminate)
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
EECS 487: Interactive Computer Graphics
 EECS 487: Interactive Computer Graphics Lecture 21: Overview of Low-level Graphics API Metal, Direct3D 12, Vulkan Console Games Why do games look and perform so much better on consoles than on PCs with
EECS 487: Interactive Computer Graphics Lecture 21: Overview of Low-level Graphics API Metal, Direct3D 12, Vulkan Console Games Why do games look and perform so much better on consoles than on PCs with
Jeremy W. Sheaffer 1 David P. Luebke 2 Kevin Skadron 1. University of Virginia Computer Science 2. NVIDIA Research
 A Hardware Redundancy and Recovery Mechanism for Reliable Scientific Computation on Graphics Processors Jeremy W. Sheaffer 1 David P. Luebke 2 Kevin Skadron 1 1 University of Virginia Computer Science
A Hardware Redundancy and Recovery Mechanism for Reliable Scientific Computation on Graphics Processors Jeremy W. Sheaffer 1 David P. Luebke 2 Kevin Skadron 1 1 University of Virginia Computer Science
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Enhancing Traditional Rasterization Graphics with Ray Tracing. March 2015
 Enhancing Traditional Rasterization Graphics with Ray Tracing March 2015 Introductions James Rumble Developer Technology Engineer Ray Tracing Support Justin DeCell Software Design Engineer Ray Tracing
Enhancing Traditional Rasterization Graphics with Ray Tracing March 2015 Introductions James Rumble Developer Technology Engineer Ray Tracing Support Justin DeCell Software Design Engineer Ray Tracing
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
The Bifrost GPU architecture and the ARM Mali-G71 GPU
 The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
The Bifrost GPU architecture and the ARM Mali-G71 GPU Jem Davies ARM Fellow and VP of Technology Hot Chips 28 Aug 2016 Introduction to ARM Soft IP ARM licenses Soft IP cores (amongst other things) to our
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies
 Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Vulkan (including Vulkan Fast Paths)
") Vulkan (including Vulkan Fast Paths) Łukasz Migas Software Development Engineer WS Graphics Let s talk about OpenGL (a bit) History 1.0-1992 1.3-2001 multitexturing 1.5-2003 vertex buffer object 2.0-2004
Vulkan (including Vulkan Fast Paths) Łukasz Migas Software Development Engineer WS Graphics Let s talk about OpenGL (a bit) History 1.0-1992 1.3-2001 multitexturing 1.5-2003 vertex buffer object 2.0-2004
Lecture 23: Domain-Specific Parallel Programming
 Lecture 23: Domain-Specific Parallel Programming CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Acknowledgments: Pat Hanrahan, Hassan Chafi Announcements List of class final projects
Lecture 23: Domain-Specific Parallel Programming CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Acknowledgments: Pat Hanrahan, Hassan Chafi Announcements List of class final projects
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
 in the Stanford Hydra Chip Multiprocessor (CMP)") Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) A 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) A 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy
 Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
Optimisation. CS7GV3 Real-time Rendering
 Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
Optimisation CS7GV3 Real-time Rendering Introduction Talk about lower-level optimization Higher-level optimization is better algorithms Example: not using a spatial data structure vs. using one After that
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC
 GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
GPU ACCELERATED SELF-JOIN FOR THE DISTANCE SIMILARITY METRIC MIKE GOWANLOCK NORTHERN ARIZONA UNIVERSITY SCHOOL OF INFORMATICS, COMPUTING & CYBER SYSTEMS BEN KARSIN UNIVERSITY OF HAWAII AT MANOA DEPARTMENT
Breaking Down Barriers: An Intro to GPU Synchronization. Matt Pettineo Lead Engine Programmer Ready At Dawn Studios
 Breaking Down Barriers: An Intro to GPU Synchronization Matt Pettineo Lead Engine Programmer Ready At Dawn Studios Who am I? Ready At Dawn for 9 years Lead Engine Programmer for 5 I like GPUs and APIs!
Breaking Down Barriers: An Intro to GPU Synchronization Matt Pettineo Lead Engine Programmer Ready At Dawn Studios Who am I? Ready At Dawn for 9 years Lead Engine Programmer for 5 I like GPUs and APIs!
EE 4702 GPU Programming
 fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
fr 1 Final Exam Review When / Where EE 4702 GPU Programming fr 1 Tuesday, 4 December 2018, 12:30-14:30 (12:30 PM - 2:30 PM) CST Room 226 Tureaud Hall (Here) Conditions Closed Book, Closed Notes Bring one
The Power of Batching in the Click Modular Router
 The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering