Human Pose Estimation in images and videos
|
|
|
- Winfred McCoy
- 6 years ago
- Views:
Transcription

1 Human Pose Estimation in images and videos Andrew Zisserman Department of Engineering Science University of Oxford, UK



2 Objective and motivation Determine human body pose (layout) Why? To recognize poses, gestures, actions





3 Activities characterized by a pose

4 Activities characterized by a pose



5 Activities characterized by a pose








6 Challenges: articulations and deformations
7 Challenges: of (almost) unconstrained images varying illumination and low contrast; moving camera and background; multiple people; scale changes; extensive clutter; any clothing

8
9 Outline Review of pictorial structures for articulated models Inference given the model: Strong supervision, full generative model Gold-standard model Image parsing: learning the model for a specific image Recent advances Datasets and challenges
10 Pictorial Structures Intuitive model of an object Model has two components 1. parts (2D image fragments) 2. structure (configuration of parts) Dates back to Fischler & Elschlager 1973
 function that reflects both Appearance: how well each part matches at given location Configuration: degree to")
11 Localize multi-part objects at arbitrary locations in an image Generic object models such as person or car Allow for articulated objects Simultaneous use of appearance and spatial information Provide efficient and practical algorithms To fit model to image: minimize an energy (or cost) function that reflects both Appearance: how well each part matches at given location Configuration: degree to which parts match 2D spatial layout

12 Long tradition of using pictorial structures for humans Finding People by Sampling Ioffe & Forsyth, ICCV 1999 Pictorial Structure Models for Object Recognition Felzenszwalb & Huttenlocher, 2000 Learning to Parse Pictures of People Ronfard, Schmid & Triggs, ECCV 2002




13 Felzenszwalb & Huttenlocher NB: requires background subtraction

14 Variety of Poses
15 Variety of Poses
16 Objective: detect human and determine upper body pose (layout) s i f a 2 a 1 Model as a graph labelling problem Vertices V are parts, a i,i=1,,n Edges E are pairwise linkages between parts For each part there are h possible poses p j =(x j,y j, φ j,s j ) Label each part by its pose: f : V {1,,h}, i.e.parta takes pose p f(a).
17 Pictorial structure model CRF s i f a 2 a 1 Each labelling has an energy (cost): E(f) = X a V θ a;f(a) + unary terms (appearance) X (a,b) E θ ab;f(a)f(b) pairwise terms (configuration) Fit model (inference) as labelling with lowest energy Features for unary: colour HOG for limbs/torso




18 Unary term: appearance feature I - colour input image skin torso background colour posteriors
 L2")
19 Unary term: appearance feature II - HOG Histogram of oriented gradients (HOG) Dalal & Triggs, CVPR 2005 HOG of image HOG of lower arm template (learned) L2 Distance
20 Pairwise terms: kinematic layout θ ab;ij = w ab d( i-j ) d d i - j Truncated Quadratic i - j Potts
21 Pictorial structure model CRF s i f a 2 a 1 Each labelling has an energy (cost): E(f) = X a V θ a;f(a) + unary terms (appearance) X (a,b) E θ ab;f(a)f(b) pairwise terms (configuration) Fit model (inference) as labelling with lowest energy Features for unary: colour HOG for limbs/torso

22 Complexity s i f a 2 n parts a 1 For each part there are h possible poses p j =(x j,y j, φ j,s j ) There are h n possible labellings Problem: any reasonable discretization (e.g. 12 scales and 36 angles for upper and lower arm, etc) gives a number of configurations 10^12 10^14 Brute force search not feasible
23 Are trees the answer? He T left UA LA Ha right UA LA Ha With n parts and h possible discrete locations per part, O(h n ) For a tree, using dynamic programming this reduces to O(nh 2 ) If model is a tree and has certain edge costs, then complexity reduces to O(nh) using a distance transform [Felzenszwalb & Huttenlocher, 2000, 2005]

24 Problems with tree structured pictorial structures Layout model defines the foreground, i.e. it chooses the pixels to explain ignores skin and strong edge in background double counting Generative model of foreground only

25 Kinematic structure vs graphical (independence) structure Graph G = (V,E) He T He T left UA right UA left UA right UA LA Ha LA Ha LA Ha LA Ha Requires more connections than a tree
26 And for the background problem 1. Add background model so that every pixel in region explained E full = E(f)+ X pixels x i not in f E(x i bgcol) 2. f lays out parts in back-to-front depth order (painter s algorithm) Colour is pixel-wise labelling by parts (back-to-front) Generative model of entire region
27 Outline Review of pictorial structures for articulated models Inference given the model: Strong supervision, full generative model Gold-standard model Image parsing: learning the model for a specific image Recent advances Datasets and challenges
28 Long Term Arm and Hand Tracking for Continuous Sign Language TV Broadcasts Patrick Buehler, Mark Everingham, Daniel Huttenlocher, Andrew Zisserman British Machine Vision Conference 2008

29 Objective Detect hands and arms of person signing British Sign Language Hour long sequences Strong but minimal supervision






30 Learning the model Strong supervision: manual input Learn colour model Learn HOG templates Provide head and body examples 5 frames 40 frames 15 frames 15 frames 40 annotated frames per video, used for pose estimation in > 50,000 frames




31 Inference (model fitting) Fit head and torso [Navaratnam et al. 2005] Then: arms and hands Input Intermediate step Output Head and torso fitting Find arm/hand pose with minimum cost Problem: Brute force search is still not feasible
 Pr(f data): Sample from max-marginal with heuristics 1000 times cf Felzenszwalb & Huttenlocher 2005")
32 Model fitting by sampling Sample configurations from inexpensive model Evaluate configuration using full model samples Input Output best arm candidate For sampling use tree structured pictorial Structures: [Felzenszwalb & Huttenlocher 2000, 2005] Complexity linear in the number of parts O(nh) Pr(f data): Sample from max-marginal with heuristics 1000 times cf Felzenszwalb & Huttenlocher 2005 sampled from marginal

33 Model fitting by sampling Sample configurations from inexpensive tree structured model Evaluate configuration using full model



34 Example results
35 Pose estimation results
36 Application Learning sign language by watching TV (using weakly aligned subtitles) Patrick Buehler Mark Everingham Andrew Zisserman CVPR 2009


37 Objective Learn signs in British Sign Language (BSL) corresponding to text words: Training data from TV broadcasts with simultaneous signing Supervision solely from sub-titles Input: video + subtitle Output: automatically learned signs (4x slow motion) Office Government Use subtitles to find video sequences containing word. These are the positive training sequences. Use other sequences as negative training sequences.
38 Overview Given an English word e.g. tree what is the corresponding British Sign Language sign? positive sequences negative set
39 Use sliding window to choose subsequence of poses in one positive sequence and determine if 1 st sliding window same sub-sequence of poses occurs in other positive sequences somewhere, but does not occur in the negative set positive sequences negative set


40 Use sliding window to choose subsequence of poses in one positive sequence and determine if same sub-sequence of poses occurs in other positive sequences somewhere, but does not occur in the negative set 5 th sliding window positive sequences negative set
41 Multiple instance learning Positive bags Negative bag sign of interest










42 Evaluation Good results for a variety of signs: Signs where hand movement is important Signs where hand shape is important Signs where both hands are together Signs which are finger-- spelled Signs which are perfomed in front of the face Navy Lung Fungi Kew Whale Prince Garden Golf Bob Rose
43 Summary Given a good appearance model and proper account of foreground and background, then problems such as occlusion and ordering can be resolved. The cost of inference still remains though. Next: - How to obtain models automatically in videos and images - If the appearance features are discriminative, how far can one go with foreground only pictorial structures and tree based inference?
44 Outline Review of pictorial structures for articulated models Inference given the model: Strong supervision, full generative model Gold-standard model Image parsing: learning the model for a specific image Recent advances Datasets and challenges

45 Learning appearance models in videos Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan, David Forsyth and Andrew Zisserman, CVPR 2005


46 edges walking pose pictorial structure efficient matching



47 Build Model small scale find discriminative features torso bg learn limb classifiers (limb pixels alone are poor model) unusual pose


48 Build Model & Detect torso small scale arm learn limb classifiers label pixels leg general pose pictorial structure head unusual pose


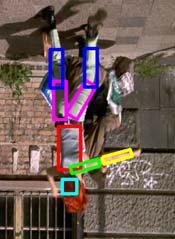

49 Running Example




50 How well do classifiers generalize?



 E")














51 Image Parsing Ramanan NIPS 06 E(f) = P a V θ a;f(a) + P (a,b) E θ ab;f(a)f(b) unary terms (edges/colour) pairwise terms (configuration) Learn image and person specific unary terms initial iteration edges following iterations edges & colour 57



52



53 (Almost) unconstrained images Extremely difficult when knowing nothing about appearance/pose/location
54 Failure of direct pose estimation Ramanan NIPS 2006 unaided Not powerful enough for a cluttered image where size is not given
55 Progressive search space reduction for human pose estimation Vitto Ferrari, Manuel Marin-Jimenez, Andrew Zisserman CVPR 2008/2009

")



 DETECTOR")
56 Restrict search space using detector Find (x,y,s) coordinate frame for a person detection window (upper-body, face etc.) DETECTOR Ferrari et al. 08, Andriluka et al. 09, Gammeter et al
57 Learn an image and person specific model Supervision None Weaker model Tree structured graphical model Overlap not modelled Single scale parameter No background model Inference Detect person use upper body detector Use upper body region to restrict search Use colour segmentation to restrict search further Parsing pictorial structure by Ramanan NIPS 06



58 Search space reduction by upper body human detection (1) detect human; (2) reduce search from h n Train Test Idea get approximate location and scale with a detector generic over pose and appearance Building an upper-body detector - based on Dalal and Triggs CVPR train = 96 frames X 12 perturbations detected enlarged Benefits for pose estimation + fixes scale of body parts + sets bounds on x,y locations + detects also back views + fast - little info about pose (arms)



59 Upper body detector using HOGs average training data
 Benefits for pose estimation initialization output + further reduce clutter + conservative (no loss 95.")
60 Search space reduction by foreground highlighting Idea exploit knowledge about structure of search area to initialize Grabcut Initialization - learn fg/bg models from regions where person likely present/absent - clamp central strip to fg - don t clamp bg (arms can be anywhere) Benefits for pose estimation initialization output + further reduce clutter + conservative (no loss 95.5% times) + needs no knowledge of background + allows for moving background


 Benefits for pose estimation + further")
 + needs no knowledge of background + allows")
61 Search space reduction by foreground highlighting Idea exploit knowledge about structure of search area to initialize Grabcut Initialization - learn fg/bg models from regions where person likely present/absent - clamp central strip to fg - don t clamp bg (arms can be anywhere) Benefits for pose estimation + further reduce clutter + conservative (no loss 95.5% times) + needs no knowledge of background + allows for moving background
 = P a V θ a;f(a) + P (a,b) E θ ab;f(a)f(b)")


62 Pose estimation by image parsing - Ramanan NIPS 06 Goal estimate posterior of part configuration E(f) = P a V θ a;f(a) + P (a,b) E θ ab;f(a)f(b) unary terms (edges/colour) pairwise terms (configuration) Algorithm 1. inference with edges unary 2. learn appearance models of body parts and background 3. inference with edges + colour unary edge parse appearance edge + col parse Advantages of space reduction + much more robust + much faster (10x-100x)


63 Failure of direct pose estimation Ramanan NIPS 2006 unaided

64 Results on Buffy frames

65 Results on PASCAL flickr images

66 What is missed?

67 What is missed? truncation is not modelled

68 What is missed? occlusion is not modelled

69 Application: Pose Search Given user-selected query frame+person query retrieve shots with persons in the same pose from video database CVPR 2009 video database
 - Batthacharrya /")
70 Pose Search Pose descriptors - soft-segmentations of body parts - distributions over orient+location for parts and pairs of parts Similarity measures - dot-product (= soft intersection) - Batthacharrya / Chi-square
71 Processing Off-line: Detect upper bodies in every frame Link (track) upper body detections Estimate upper body pose for each frame of track Compute descriptor (vector) for each upper body pose Run-time: Rank each track by its similarity to the query pose

72 Pose Search Q hips pose

73 Pose Search Q rest pose



74 Pose Search Q rest pose

75 Other poses query interesting pose Hollywood movies Query on Gandhi, Search Hugh Grant opus Q

76

77

78

79 Other poses query interesting pose Hollywood movies Query on Gandhi, Search Hugh Grant opus Q

80

81

82

83
84 Outline Review of pictorial structures for articulated models Inference given the model: Strong supervision, full generative model Gold-standard model Image parsing: learning the model for a specific image Recent advances Datasets and challenges



85 Better appearance models for pictorial structures Marcin Eichner, Vittorio Ferrari BMVC







86 relative location (wrt detection window): stable, e.g. head, torso unstable, e.g. upper/lower arms 97









87 Appearance of different body parts is related long sleeves short sleeves no sleeves Use stable parts to improve the prediction of the unstable ones 98
88 torso upper arms LP encodes: variability of poses detection window inaccuracy lower arms head learnt location priors (PASCAL & Buffy 3,4) 99














89 input coordinate frame LP estimate initial AM detection window output TM Pictorial Structures inference compute unary term Φ: apply appearance transfer 100
90 Efficient Discriminative Learning of Partsbased Models Pawan Kumar, Phil Torr, Andrew Zisserman ICCV 2009
91 Learning a discriminative model Supervision bounding rectangles for limbs for positive examples Weak model Tree structured graphical model Parts labelled as occluded or not Scale of parts known Discriminative learning Similar to Max-margin Markov network But much more efficient inference
92 Problem formulation Energy of a labelling: E(f) = X θ a;f(a) + a V Assume the following form X (a,b) E θ ab;f(a)f(b) + b = w > θ f + b Unary term: θ a;f(a) = w > a θ a;f(a), Pairwise term: θ ab;f(a)f(b) = w > ab θ ab;f(a)f(b), where θ a;f(a) is the feature vector for part a (HOG + colour) θ ab;f(a)f(b) are the pairwise features (spatial configuration) We want to learn the parameters w =(w a ; w ab )andb

93 Training data Positive examples Negative examples all other configurations
94 Wide margin formulation for learning (w,b )= argmin w,b 1 2 w 2 + C( P k ξ k + P l ξ l ), s.t. w > θ k + + b 1 ξk, k (positive examples), w > θ l + b 1+ξ l, l (negative examples), Convex formulation. Similar to: ξ k 0, k, ξ l 0, l. Tsochantaridis, Hofmann, Joachims, & Altun. Support vector learning for interdependent and structured output spaces.icml, (supervised version of) Felzenszwalb, McAllester, & Ramanan. A discriminatively trained, multiscale, deformable part model. CVPR, 2008

95 Results
96 H3D: Humans in 3D Lubomir Bourdev & Jitendra Malik ICCV 2009

97
98

99

100

101
102

103 AP =0.394
104
105 Further ideas: Human Pose Estimation Using Consistent Max-Covering, Hao Jiang, ICCV 09 Max-margin hidden conditional random fields for human action recognition, Yang Wang and Greg Mori, CVPR 09 Adaptive pose priors for pictorial structures, B. Sapp, C. Jordan, and B. Taskar, CVPR 10
106 Outline Review of pictorial structures for articulated models Inference given the model: Strong supervision, full generative model Gold-standard model Image parsing: learning the model for a specific image Recent advances Datasets and challenges



 Berkeley H3D")

107 Datasets & Evaluation Some efforts evaluating person image parsing PASCAL VOC Person Layout Oxford Buffy Stickmen 276 frames x 6 = 1656 body parts (sticks) Berkeley H3D ETHZ Pascal stickmen set 549 images x6 = 3294 body parts (sticks)

108 The PASCAL Visual Object Classes Challenge 2010 (VOC2010) Mark Everingham, Luc Van Gool Chris Williams, John Winn Andrew Zisserman

109 Person Layout Taster Given the bounding box of a person, predict the visibility and positions of head, hands and feet. About 600 training examples But can also use any training data (not overlapping with test set)



110 Human Action Classes Taster Given the bounding box of a person, determine which, if any, of 9 action classes apply suggested by Ivan Laptev choice of classes governed by availability from flickr evaluation is by AP on each class training images for each class phoning playing instrument reading working on computer





111 Human Action Classes Taster continued riding horse riding bike running walking taking photo
Better appearance models for pictorial structures
 EICHNER, FERRARI: BETTER APPEARANCE MODELS FOR PICTORIAL STRUCTURES 1 Better appearance models for pictorial structures Marcin Eichner eichner@vision.ee.ethz.ch Vittorio Ferrari ferrari@vision.ee.ethz.ch
EICHNER, FERRARI: BETTER APPEARANCE MODELS FOR PICTORIAL STRUCTURES 1 Better appearance models for pictorial structures Marcin Eichner eichner@vision.ee.ethz.ch Vittorio Ferrari ferrari@vision.ee.ethz.ch
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS
 HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
Development in Object Detection. Junyuan Lin May 4th
 Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Category-level localization
 Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Pose Search: retrieving people using their pose
 Pose Search: retrieving people using their pose Vittorio Ferrari ETH Zurich ferrari@vision.ee.ethz.ch Manuel Marín-Jiménez University of Granada mjmarin@decsai.ugr.es Andrew Zisserman University of Oxford
Pose Search: retrieving people using their pose Vittorio Ferrari ETH Zurich ferrari@vision.ee.ethz.ch Manuel Marín-Jiménez University of Granada mjmarin@decsai.ugr.es Andrew Zisserman University of Oxford
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Object Detection with Discriminatively Trained Part Based Models
 Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwelb, Ross B. Girshick, David McAllester and Deva Ramanan Presented by Fabricio Santolin da Silva Kaustav Basu Some slides
Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwelb, Ross B. Girshick, David McAllester and Deva Ramanan Presented by Fabricio Santolin da Silva Kaustav Basu Some slides
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation
 Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Articulated Pose Estimation using Discriminative Armlet Classifiers
 Articulated Pose Estimation using Discriminative Armlet Classifiers Georgia Gkioxari 1, Pablo Arbeláez 1, Lubomir Bourdev 2 and Jitendra Malik 1 1 University of California, Berkeley - Berkeley, CA 94720
Articulated Pose Estimation using Discriminative Armlet Classifiers Georgia Gkioxari 1, Pablo Arbeláez 1, Lubomir Bourdev 2 and Jitendra Malik 1 1 University of California, Berkeley - Berkeley, CA 94720
Improved Human Parsing with a Full Relational Model
 Improved Human Parsing with a Full Relational Model Duan Tran and David Forsyth University of Illinois at Urbana-Champaign, USA {ddtran2,daf}@illinois.edu Abstract. We show quantitative evidence that a
Improved Human Parsing with a Full Relational Model Duan Tran and David Forsyth University of Illinois at Urbana-Champaign, USA {ddtran2,daf}@illinois.edu Abstract. We show quantitative evidence that a
Modern Object Detection. Most slides from Ali Farhadi
 Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation
 JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
Recognizing Human Actions from Still Images with Latent Poses
 Recognizing Human Actions from Still Images with Latent Poses Weilong Yang, Yang Wang, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada wya16@sfu.ca, ywang12@cs.sfu.ca,
Recognizing Human Actions from Still Images with Latent Poses Weilong Yang, Yang Wang, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada wya16@sfu.ca, ywang12@cs.sfu.ca,
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
CS229 Final Project Report. A Multi-Task Feature Learning Approach to Human Detection. Tiffany Low
 CS229 Final Project Report A Multi-Task Feature Learning Approach to Human Detection Tiffany Low tlow@stanford.edu Abstract We focus on the task of human detection using unsupervised pre-trained neutral
CS229 Final Project Report A Multi-Task Feature Learning Approach to Human Detection Tiffany Low tlow@stanford.edu Abstract We focus on the task of human detection using unsupervised pre-trained neutral
Using k-poselets for detecting people and localizing their keypoints
 Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
Finding people in repeated shots of the same scene
 1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
High Level Computer Vision
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de http://www.d2.mpi-inf.mpg.de/cv Please Note No
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de http://www.d2.mpi-inf.mpg.de/cv Please Note No
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Graphical Models for Computer Vision
 Graphical Models for Computer Vision Pedro F Felzenszwalb Brown University Joint work with Dan Huttenlocher, Joshua Schwartz, Ross Girshick, David McAllester, Deva Ramanan, Allie Shapiro, John Oberlin
Graphical Models for Computer Vision Pedro F Felzenszwalb Brown University Joint work with Dan Huttenlocher, Joshua Schwartz, Ross Girshick, David McAllester, Deva Ramanan, Allie Shapiro, John Oberlin
A Discriminatively Trained, Multiscale, Deformable Part Model
 A Discriminatively Trained, Multiscale, Deformable Part Model Pedro Felzenszwalb University of Chicago pff@cs.uchicago.edu David McAllester Toyota Technological Institute at Chicago mcallester@tti-c.org
A Discriminatively Trained, Multiscale, Deformable Part Model Pedro Felzenszwalb University of Chicago pff@cs.uchicago.edu David McAllester Toyota Technological Institute at Chicago mcallester@tti-c.org
Strike a Pose: Tracking People by Finding Stylized Poses
 Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
2D Human Pose Estimation in TV Shows
 2D Human Pose Estimation in TV Shows Vittorio Ferrari ETH Zurich ferrari@vision.ee.ethz.ch, Manuel Marín-Jiménez University of Granada mjmarin@decsai.ugr.es, and Andrew Zisserman University of Oxford az@robots.ox.ac.uk
2D Human Pose Estimation in TV Shows Vittorio Ferrari ETH Zurich ferrari@vision.ee.ethz.ch, Manuel Marín-Jiménez University of Granada mjmarin@decsai.ugr.es, and Andrew Zisserman University of Oxford az@robots.ox.ac.uk
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations
 Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations Xianjie Chen University of California, Los Angeles Los Angeles, CA 90024 cxj@ucla.edu Alan Yuille University of
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations Xianjie Chen University of California, Los Angeles Los Angeles, CA 90024 cxj@ucla.edu Alan Yuille University of
Video Retrieval by Mimicking Poses
 Video Retrieval by Mimicking Poses Nataraj Jammalamadaka IIIT-Hyderabad, India nataraj.j@research.iiit.ac.in Vittorio Ferrari University of Edinburgh, UK ferrari@vision.ee.ethz.ch Andrew Zisserman University
Video Retrieval by Mimicking Poses Nataraj Jammalamadaka IIIT-Hyderabad, India nataraj.j@research.iiit.ac.in Vittorio Ferrari University of Edinburgh, UK ferrari@vision.ee.ethz.ch Andrew Zisserman University
Easy Minimax Estimation with Random Forests for Human Pose Estimation
 Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Object Recognition with Deformable Models
 Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Learning Realistic Human Actions from Movies
 Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Find that! Visual Object Detection Primer
 Find that! Visual Object Detection Primer SkTech/MIT Innovation Workshop August 16, 2012 Dr. Tomasz Malisiewicz tomasz@csail.mit.edu Find that! Your Goals...imagine one such system that drives information
Find that! Visual Object Detection Primer SkTech/MIT Innovation Workshop August 16, 2012 Dr. Tomasz Malisiewicz tomasz@csail.mit.edu Find that! Your Goals...imagine one such system that drives information
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Detecting Actions, Poses, and Objects with Relational Phraselets
 Detecting Actions, Poses, and Objects with Relational Phraselets Chaitanya Desai and Deva Ramanan University of California at Irvine, Irvine CA, USA {desaic,dramanan}@ics.uci.edu Abstract. We present a
Detecting Actions, Poses, and Objects with Relational Phraselets Chaitanya Desai and Deva Ramanan University of California at Irvine, Irvine CA, USA {desaic,dramanan}@ics.uci.edu Abstract. We present a
Learning to parse images of articulated bodies
 Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Exploring the Spatial Hierarchy of Mixture Models for Human Pose Estimation
 Exploring the Spatial Hierarchy of Mixture Models for Human Pose Estimation Yuandong Tian 1, C. Lawrence Zitnick 2, and Srinivasa G. Narasimhan 1 1 Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh,
Exploring the Spatial Hierarchy of Mixture Models for Human Pose Estimation Yuandong Tian 1, C. Lawrence Zitnick 2, and Srinivasa G. Narasimhan 1 1 Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh,
Strong Appearance and Expressive Spatial Models for Human Pose Estimation
 2013 IEEE International Conference on Computer Vision Strong Appearance and Expressive Spatial Models for Human Pose Estimation Leonid Pishchulin 1 Mykhaylo Andriluka 1 Peter Gehler 2 Bernt Schiele 1 1
2013 IEEE International Conference on Computer Vision Strong Appearance and Expressive Spatial Models for Human Pose Estimation Leonid Pishchulin 1 Mykhaylo Andriluka 1 Peter Gehler 2 Bernt Schiele 1 1
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
c 2011 by Pedro Moises Crisostomo Romero. All rights reserved.
 c 2011 by Pedro Moises Crisostomo Romero. All rights reserved. HAND DETECTION ON IMAGES BASED ON DEFORMABLE PART MODELS AND ADDITIONAL FEATURES BY PEDRO MOISES CRISOSTOMO ROMERO THESIS Submitted in partial
c 2011 by Pedro Moises Crisostomo Romero. All rights reserved. HAND DETECTION ON IMAGES BASED ON DEFORMABLE PART MODELS AND ADDITIONAL FEATURES BY PEDRO MOISES CRISOSTOMO ROMERO THESIS Submitted in partial
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
A Comparison on Different 2D Human Pose Estimation Method
 A Comparison on Different 2D Human Pose Estimation Method Santhanu P.Mohan 1, Athira Sugathan 2, Sumesh Sekharan 3 1 Assistant Professor, IT Department, VJCET, Kerala, India 2 Student, CVIP, ASE, Tamilnadu,
A Comparison on Different 2D Human Pose Estimation Method Santhanu P.Mohan 1, Athira Sugathan 2, Sumesh Sekharan 3 1 Assistant Professor, IT Department, VJCET, Kerala, India 2 Student, CVIP, ASE, Tamilnadu,
DPM Configurations for Human Interaction Detection
 DPM Configurations for Human Interaction Detection Coert van Gemeren Ronald Poppe Remco C. Veltkamp Interaction Technology Group, Department of Information and Computing Sciences, Utrecht University, The
DPM Configurations for Human Interaction Detection Coert van Gemeren Ronald Poppe Remco C. Veltkamp Interaction Technology Group, Department of Information and Computing Sciences, Utrecht University, The
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Object Recognition Using Pictorial Structures. Daniel Huttenlocher Computer Science Department. In This Talk. Object recognition in computer vision
 Object Recognition Using Pictorial Structures Daniel Huttenlocher Computer Science Department Joint work with Pedro Felzenszwalb, MIT AI Lab In This Talk Object recognition in computer vision Brief definition
Object Recognition Using Pictorial Structures Daniel Huttenlocher Computer Science Department Joint work with Pedro Felzenszwalb, MIT AI Lab In This Talk Object recognition in computer vision Brief definition
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
2D Human Pose Estimation in TV Shows
 2D Human Pose Estimation in TV Shows Vittorio Ferrari 1, Manuel Marín-Jiménez 2, and Andrew Zisserman 3 1 ETH Zurich ferrari@vision.ee.ethz.ch 2 University of Granada mjmarin@decsai.ugr.es 3 University
2D Human Pose Estimation in TV Shows Vittorio Ferrari 1, Manuel Marín-Jiménez 2, and Andrew Zisserman 3 1 ETH Zurich ferrari@vision.ee.ethz.ch 2 University of Granada mjmarin@decsai.ugr.es 3 University
Estimating Human Pose with Flowing Puppets
 2013 IEEE International Conference on Computer Vision Estimating Human Pose with Flowing Puppets Silvia Zuffi 1,3 Javier Romero 2 Cordelia Schmid 4 Michael J. Black 2 1 Department of Computer Science,
2013 IEEE International Conference on Computer Vision Estimating Human Pose with Flowing Puppets Silvia Zuffi 1,3 Javier Romero 2 Cordelia Schmid 4 Michael J. Black 2 1 Department of Computer Science,
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
A Segmentation-aware Object Detection Model with Occlusion Handling
 A Segmentation-aware Object Detection Model with Occlusion Handling Tianshi Gao 1 Benjamin Packer 2 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer
A Segmentation-aware Object Detection Model with Occlusion Handling Tianshi Gao 1 Benjamin Packer 2 Daphne Koller 2 1 Department of Electrical Engineering, Stanford University 2 Department of Computer
Recognizing human actions in still images: a study of bag-of-features and part-based representations
 DELAITRE, LAPTEV, SIVIC: RECOGNIZING HUMAN ACTIONS IN STILL IMAGES. 1 Recognizing human actions in still images: a study of bag-of-features and part-based representations Vincent Delaitre 1 vincent.delaitre@ens-lyon.org
DELAITRE, LAPTEV, SIVIC: RECOGNIZING HUMAN ACTIONS IN STILL IMAGES. 1 Recognizing human actions in still images: a study of bag-of-features and part-based representations Vincent Delaitre 1 vincent.delaitre@ens-lyon.org
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos
 Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Object Category Detection: Sliding Windows
 04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
Human Pose Estimation Using Consistent Max-Covering
 Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
Joint Segmentation and Pose Tracking of Human in Natural Videos
 23 IEEE International Conference on Computer Vision Joint Segmentation and Pose Tracking of Human in Natural Videos Taegyu Lim,2 Seunghoon Hong 2 Bohyung Han 2 Joon Hee Han 2 DMC R&D Center, Samsung Electronics,
23 IEEE International Conference on Computer Vision Joint Segmentation and Pose Tracking of Human in Natural Videos Taegyu Lim,2 Seunghoon Hong 2 Bohyung Han 2 Joon Hee Han 2 DMC R&D Center, Samsung Electronics,
A Discriminatively Trained, Multiscale, Deformable Part Model
 A Discriminatively Trained, Multiscale, Deformable Part Model by Pedro Felzenszwalb, David McAllester, and Deva Ramanan CS381V Visual Recognition - Paper Presentation Slide credit: Duan Tran Slide credit:
A Discriminatively Trained, Multiscale, Deformable Part Model by Pedro Felzenszwalb, David McAllester, and Deva Ramanan CS381V Visual Recognition - Paper Presentation Slide credit: Duan Tran Slide credit:
Category-level Localization
 Category-level Localization Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Includes slides from: Ondra Chum, Alyosha Efros, Mark Everingham, Pedro Felzenszwalb,
Category-level Localization Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Includes slides from: Ondra Chum, Alyosha Efros, Mark Everingham, Pedro Felzenszwalb,
Modeling 3D viewpoint for part-based object recognition of rigid objects
 Modeling 3D viewpoint for part-based object recognition of rigid objects Joshua Schwartz Department of Computer Science Cornell University jdvs@cs.cornell.edu Abstract Part-based object models based on
Modeling 3D viewpoint for part-based object recognition of rigid objects Joshua Schwartz Department of Computer Science Cornell University jdvs@cs.cornell.edu Abstract Part-based object models based on
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Structured output regression for detection with partial truncation
 Structured output regression for detection with partial truncation Andrea Vedaldi Andrew Zisserman Department of Engineering University of Oxford Oxford, UK {vedaldi,az}@robots.ox.ac.uk Abstract We develop
Structured output regression for detection with partial truncation Andrea Vedaldi Andrew Zisserman Department of Engineering University of Oxford Oxford, UK {vedaldi,az}@robots.ox.ac.uk Abstract We develop
Detecting and Segmenting Humans in Crowded Scenes
 Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Full Body Pose Estimation During Occlusion using Multiple Cameras Fihl, Preben; Cosar, Serhan
 Aalborg Universitet Full Body Pose Estimation During Occlusion using Multiple Cameras Fihl, Preben; Cosar, Serhan Publication date: 2010 Document Version Publisher's PDF, also known as Version of record
Aalborg Universitet Full Body Pose Estimation During Occlusion using Multiple Cameras Fihl, Preben; Cosar, Serhan Publication date: 2010 Document Version Publisher's PDF, also known as Version of record
Multiple Pose Context Trees for estimating Human Pose in Object Context
 Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
Fast Online Upper Body Pose Estimation from Video
 CHANG et al.: FAST ONLINE UPPER BODY POSE ESTIMATION FROM VIDEO 1 Fast Online Upper Body Pose Estimation from Video Ming-Ching Chang 1,2 changm@ge.com Honggang Qi 1,3 hgqi@ucas.ac.cn Xin Wang 1 xwang26@albany.edu
CHANG et al.: FAST ONLINE UPPER BODY POSE ESTIMATION FROM VIDEO 1 Fast Online Upper Body Pose Estimation from Video Ming-Ching Chang 1,2 changm@ge.com Honggang Qi 1,3 hgqi@ucas.ac.cn Xin Wang 1 xwang26@albany.edu
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
Category vs. instance recognition
 Category vs. instance recognition Category: Find all the people Find all the buildings Often within a single image Often sliding window Instance: Is this face James? Find this specific famous building
Category vs. instance recognition Category: Find all the people Find all the buildings Often within a single image Often sliding window Instance: Is this face James? Find this specific famous building
Poselet Conditioned Pictorial Structures
 Poselet Conditioned Pictorial Structures Leonid Pishchulin 1 Mykhaylo Andriluka 1 Peter Gehler 2 Bernt Schiele 1 1 Max Planck Institute for Informatics, Saarbrücken, Germany 2 Max Planck Institute for
Poselet Conditioned Pictorial Structures Leonid Pishchulin 1 Mykhaylo Andriluka 1 Peter Gehler 2 Bernt Schiele 1 1 Max Planck Institute for Informatics, Saarbrücken, Germany 2 Max Planck Institute for
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Human Pose Estimation using Body Parts Dependent Joint Regressors
 2013 IEEE Conference on Computer Vision and Pattern Recognition Human Pose Estimation using Body Parts Dependent Joint Regressors Matthias Dantone 1 Juergen Gall 2 Christian Leistner 3 Luc Van Gool 1 ETH
2013 IEEE Conference on Computer Vision and Pattern Recognition Human Pose Estimation using Body Parts Dependent Joint Regressors Matthias Dantone 1 Juergen Gall 2 Christian Leistner 3 Luc Van Gool 1 ETH
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Learning to Localize Objects with Structured Output Regression
 Learning to Localize Objects with Structured Output Regression Matthew B. Blaschko and Christoph H. Lampert Max Planck Institute for Biological Cybernetics 72076 Tübingen, Germany {blaschko,chl}@tuebingen.mpg.de
Learning to Localize Objects with Structured Output Regression Matthew B. Blaschko and Christoph H. Lampert Max Planck Institute for Biological Cybernetics 72076 Tübingen, Germany {blaschko,chl}@tuebingen.mpg.de
Global Pose Estimation Using Non-Tree Models
 Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Parsing Human Motion with Stretchable Models
 Parsing Human Motion with Stretchable Models Benjamin Sapp David Weiss Ben Taskar University of Pennsylvania Philadelphia, PA 19104 {bensapp,djweiss,taskar}@cis.upenn.edu Abstract We address the problem
Parsing Human Motion with Stretchable Models Benjamin Sapp David Weiss Ben Taskar University of Pennsylvania Philadelphia, PA 19104 {bensapp,djweiss,taskar}@cis.upenn.edu Abstract We address the problem
Beyond Actions: Discriminative Models for Contextual Group Activities
 Beyond Actions: Discriminative Models for Contextual Group Activities Tian Lan School of Computing Science Simon Fraser University tla58@sfu.ca Weilong Yang School of Computing Science Simon Fraser University
Beyond Actions: Discriminative Models for Contextual Group Activities Tian Lan School of Computing Science Simon Fraser University tla58@sfu.ca Weilong Yang School of Computing Science Simon Fraser University
Video Google faces. Josef Sivic, Mark Everingham, Andrew Zisserman. Visual Geometry Group University of Oxford
 Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Video Google faces Josef Sivic, Mark Everingham, Andrew Zisserman Visual Geometry Group University of Oxford The objective Retrieve all shots in a video, e.g. a feature length film, containing a particular
Fast, Accurate Detection of 100,000 Object Classes on a Single Machine
 Fast, Accurate Detection of 100,000 Object Classes on a Single Machine Thomas Dean etal. Google, Mountain View, CA CVPR 2013 best paper award Presented by: Zhenhua Wang 2013.12.10 Outline Background This
Fast, Accurate Detection of 100,000 Object Classes on a Single Machine Thomas Dean etal. Google, Mountain View, CA CVPR 2013 best paper award Presented by: Zhenhua Wang 2013.12.10 Outline Background This
Human Focused Action Localization in Video
 Human Focused Action Localization in Video Alexander Kläser 1, Marcin Marsza lek 2, Cordelia Schmid 1, and Andrew Zisserman 2 1 INRIA Grenoble, LEAR, LJK {klaser,schmid}@inrialpes.fr 2 Engineering Science,
Human Focused Action Localization in Video Alexander Kläser 1, Marcin Marsza lek 2, Cordelia Schmid 1, and Andrew Zisserman 2 1 INRIA Grenoble, LEAR, LJK {klaser,schmid}@inrialpes.fr 2 Engineering Science,
MODEC: Multimodal Decomposable Models for Human Pose Estimation
 13 IEEE Conference on Computer Vision and Pattern Recognition MODEC: Multimodal Decomposable Models for Human Pose Estimation Ben Sapp Google, Inc bensapp@google.com Ben Taskar University of Washington
13 IEEE Conference on Computer Vision and Pattern Recognition MODEC: Multimodal Decomposable Models for Human Pose Estimation Ben Sapp Google, Inc bensapp@google.com Ben Taskar University of Washington
CS 664 Flexible Templates. Daniel Huttenlocher
 CS 664 Flexible Templates Daniel Huttenlocher Flexible Template Matching Pictorial structures Parts connected by springs and appearance models for each part Used for human bodies, faces Fischler&Elschlager,
CS 664 Flexible Templates Daniel Huttenlocher Flexible Template Matching Pictorial structures Parts connected by springs and appearance models for each part Used for human bodies, faces Fischler&Elschlager,
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Histogram of Oriented Gradients (HOG) for Object Detection
 for Object Detection") Histogram of Oriented Gradients (HOG) for Object Detection Navneet DALAL Joint work with Bill TRIGGS and Cordelia SCHMID Goal & Challenges Goal: Detect and localise people in images and videos n Wide variety
Histogram of Oriented Gradients (HOG) for Object Detection Navneet DALAL Joint work with Bill TRIGGS and Cordelia SCHMID Goal & Challenges Goal: Detect and localise people in images and videos n Wide variety
Lecture 15: Detecting Objects by Parts
 Lecture 15: Detecting Objects by Parts David R. Morales, Austin O. Narcomey, Minh-An Quinn, Guilherme Reis, Omar Solis Department of Computer Science Stanford University Stanford, CA 94305 {mrlsdvd, aon2,
Lecture 15: Detecting Objects by Parts David R. Morales, Austin O. Narcomey, Minh-An Quinn, Guilherme Reis, Omar Solis Department of Computer Science Stanford University Stanford, CA 94305 {mrlsdvd, aon2,
Test-time Adaptation for 3D Human Pose Estimation
 Test-time Adaptation for 3D Human Pose Estimation Sikandar Amin,2, Philipp Müller 2, Andreas Bulling 2, and Mykhaylo Andriluka 2,3 Technische Universität München, Germany 2 Max Planck Institute for Informatics,
Test-time Adaptation for 3D Human Pose Estimation Sikandar Amin,2, Philipp Müller 2, Andreas Bulling 2, and Mykhaylo Andriluka 2,3 Technische Universität München, Germany 2 Max Planck Institute for Informatics,
A Generative Model for Simultaneous Estimation of Human Body Shape and Pixel-level Segmentation
 A Generative Model for Simultaneous Estimation of Human Body Shape and Pixel-level Segmentation Ingmar Rauschert and Robert T. Collins Pennsylvania State University, University Park, 16802 PA, USA Abstract.
A Generative Model for Simultaneous Estimation of Human Body Shape and Pixel-level Segmentation Ingmar Rauschert and Robert T. Collins Pennsylvania State University, University Park, 16802 PA, USA Abstract.
Improving an Object Detector and Extracting Regions using Superpixels
 Improving an Object Detector and Extracting Regions using Superpixels Guang Shu, Afshin Dehghan, Mubarak Shah Computer Vision Lab, University of Central Florida {gshu, adehghan, shah}@eecs.ucf.edu Abstract
Improving an Object Detector and Extracting Regions using Superpixels Guang Shu, Afshin Dehghan, Mubarak Shah Computer Vision Lab, University of Central Florida {gshu, adehghan, shah}@eecs.ucf.edu Abstract
Cascaded Models for Articulated Pose Estimation
 Cascaded Models for Articulated Pose Estimation Benjamin Sapp, Alexander Toshev, and Ben Taskar University of Pennsylvania, Philadelphia, PA 19104 USA {bensapp,toshev,taskar}@cis.upenn.edu Abstract. We
Cascaded Models for Articulated Pose Estimation Benjamin Sapp, Alexander Toshev, and Ben Taskar University of Pennsylvania, Philadelphia, PA 19104 USA {bensapp,toshev,taskar}@cis.upenn.edu Abstract. We
The Caltech-UCSD Birds Dataset
 The Caltech-UCSD Birds-200-2011 Dataset Catherine Wah 1, Steve Branson 1, Peter Welinder 2, Pietro Perona 2, Serge Belongie 1 1 University of California, San Diego 2 California Institute of Technology
The Caltech-UCSD Birds-200-2011 Dataset Catherine Wah 1, Steve Branson 1, Peter Welinder 2, Pietro Perona 2, Serge Belongie 1 1 University of California, San Diego 2 California Institute of Technology
Deformable Part Models
 Deformable Part Models References: Felzenszwalb, Girshick, McAllester and Ramanan, Object Detec@on with Discrimina@vely Trained Part Based Models, PAMI 2010 Code available at hkp://www.cs.berkeley.edu/~rbg/latent/
Deformable Part Models References: Felzenszwalb, Girshick, McAllester and Ramanan, Object Detec@on with Discrimina@vely Trained Part Based Models, PAMI 2010 Code available at hkp://www.cs.berkeley.edu/~rbg/latent/
Joint learning of visual attributes, object classes and visual saliency
 Joint learning of visual attributes, object classes and visual saliency Gang Wang Dept. of Electrical and Computer Engineering University of Illinois at Urbana-Champaign gwang6@uiuc.edu David Forsyth Dept.
Joint learning of visual attributes, object classes and visual saliency Gang Wang Dept. of Electrical and Computer Engineering University of Illinois at Urbana-Champaign gwang6@uiuc.edu David Forsyth Dept.
Automatic Discovery of Meaningful Object Parts with Latent CRFs
 Automatic Discovery of Meaningful Object Parts with Latent CRFs Paul Schnitzspan 1 Stefan Roth 1 Bernt Schiele 1,2 1 Department of Computer Science, TU Darmstadt 2 MPI Informatics, Saarbrücken Abstract
Automatic Discovery of Meaningful Object Parts with Latent CRFs Paul Schnitzspan 1 Stefan Roth 1 Bernt Schiele 1,2 1 Department of Computer Science, TU Darmstadt 2 MPI Informatics, Saarbrücken Abstract
Local Features based Object Categories and Object Instances Recognition
 Local Features based Object Categories and Object Instances Recognition Eric Nowak Ph.D. thesis defense 17th of March, 2008 1 Thesis in Computer Vision Computer vision is the science and technology of
Local Features based Object Categories and Object Instances Recognition Eric Nowak Ph.D. thesis defense 17th of March, 2008 1 Thesis in Computer Vision Computer vision is the science and technology of
and we can apply the recursive definition of the cost-to-go function to get
 Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Lecture 16: Object recognition: Part-based generative models
 Lecture 16: Object recognition: Part-based generative models Professor Stanford Vision Lab 1 What we will learn today? Introduction Constellation model Weakly supervised training One-shot learning (Problem
Lecture 16: Object recognition: Part-based generative models Professor Stanford Vision Lab 1 What we will learn today? Introduction Constellation model Weakly supervised training One-shot learning (Problem
Qualitative Pose Estimation by Discriminative Deformable Part Models
 Qualitative Pose Estimation by Discriminative Deformable Part Models Hyungtae Lee, Vlad I. Morariu, and Larry S. Davis University of Maryland, College Park Abstract. We present a discriminative deformable
Qualitative Pose Estimation by Discriminative Deformable Part Models Hyungtae Lee, Vlad I. Morariu, and Larry S. Davis University of Maryland, College Park Abstract. We present a discriminative deformable
Visuelle Perzeption für Mensch- Maschine Schnittstellen
 Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Actions and Attributes from Wholes and Parts
 Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Boosted Multiple Deformable Trees for Parsing Human Poses
 Boosted Multiple Deformable Trees for Parsing Human Poses Yang Wang and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,mori}@cs.sfu.ca Abstract. Tree-structured
Boosted Multiple Deformable Trees for Parsing Human Poses Yang Wang and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,mori}@cs.sfu.ca Abstract. Tree-structured