MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS
|
|
|
- Ashlee Lambert
- 5 years ago
- Views:
Transcription
1 MEMORY/RESOURCE MANAGEMENT IN MULTICORE SYSTEMS INSTRUCTOR: Dr. MUHAMMAD SHAABAN PRESENTED BY: MOHIT SATHAWANE AKSHAY YEMBARWAR

2 WHAT IS MULTICORE SYSTEMS? Multi-core processor architecture means placing two or more execution cores within a single package with private and or shared cache. Multi-core chips do more work per clock cycle, are able to run at a lower frequency, and may enhance user experience in several ways such as improving performance of compute- and bandwidth-intensive activities.

3 The Move to Multi-Core Architecture The doubling of transistors every couple of years has been maintained for several years. But scaling out cannot not continue indefinitely because of several laws of physics. Example: A 1993-era Intel Pentium Processor had around 3 million transistors, while today s Intel Itanium 2 processor has nearly 1 billion transistors. If this rate continued, Intel processors would soon be producing more heat per square centimeter than the surface of the sun-which is why the problem of heat is already setting hard limits to frequency increases. Despite these challenges, users continue to demand increased performance.



4 TYPES OF MEMORY Cache Memory: Cache memory is a very high speed semiconductor memory which can speed up CPU. It acts as a buffer between the CPU and main memory. It is used to hold those parts of data and program which are most frequently used by CPU. Primary Memory/Main Memory: Primary memory holds only those data and instructions on which computer is currently working. It has limited capacity and data is lost when power is switched off. It is generally made up of semiconductor device. These memories are not as fast as cache. The data and instruction required to be processed reside in main memory Secondary Memory: This type of memory is also known as external memory or non-volatile. It is the slowest kind of memory. These are used for storing data/information permanently.
5 TYPES OF CACHE LEVELS Level 1 (L1) cache is extremely fast but relatively small, and is usually embedded in the processor chip (CPU). Level 2 (L2) cache is larger than L1; it may be located on the CPU or on a separate chip or coprocessor with a high-speed alternative system bus interconnecting the cache to the CPU, so as not to be slowed by traffic on the main system bus. Level 3 (L3) cache is typically specialized memory that works to improve the performance of L1 and L2. It can be significantly slower than L1 or L2, but is usually double the speed of RAM. In the case of multicore processors, each core may have its own dedicated L1 and or L2 cache, but share a common L3 cache (L2 is shared if L3 is not present).
6 ADVANTAGES OF SHARED CACHE IN MULTICORE SYSTEMS Efficient usage of the last-level cache If one core idles, the other core takes all the shared cache Reduces resource underutilization Flexibility for programmers Allows more data-sharing opportunities for threads running on separate cores that are sharing cache One core can pre-/post-process data for the other core Alternative communication mechanisms between cores Reduce cache-coherency complexity Reduced false sharing because of the shared cache Less workload to maintain coherency, compared to the private cache architecture Reduce data-storage redundancy The same data only needs to be stored once Reduce front-side bus traffic Effective data sharing between cores allows data requests to be resolved at the shared-cache level instead of going all the way to the system memory

7 PROBLEM IN SHARED CACHE Example: In a simple dual-core processor configuration, each core has its own CPU and L1 cache. Both cores share an L2 cache. In this configuration, applications executing on Core 0 compete for the entire L2 cache with applications executing on Core 1. If application A on Core 0 uses data that maps to the same cache line(s) as application B on Core 1, then a collision occurs. Solution: To overcome this problem, the shared cache can be partitioned among all the cores. This can be done in a static or dynamic way.

8 STATIC CACHE PARTITIONING: In a simple dual-core processor configuration, each core has its own CPU and L1 cache and both cores share an L2 cache. The OS partitions the L2 cache such that each core has its own segment of L2, meaning that data used by applications on Core 0 will only be cached in Core 0 s L2 partition. Similarly, data used by applications on Core 1 will only be cached in Core 1 s L2 partition. This partitioning eliminates the possibility of applications on different cores interfering with one another via L2 collisions. But depending upon the work on different cores some may over utilize it s cache partition and some may under utilize it. To efficiently use the cache, the partitioning can be done in a dynamic way.
9 DYNAMIC CACHE PARTITIONING: DISTANCE AWARE CACHE PARTITIONING Many dynamic cache partitioning results in high cache access latency and higher offchip accesses. Distance aware Round Robin mapping is an OS-managed policy which addresses the trade-off between cache access latency and number of off-chip accesses. This is done by mapping the pages accessed by a core to its closest (local) bank. It also introduces an upper bound on the deviation of the distribution of memory pages among cache banks, which lessens the number of off-chip accesses. This tradeoff is addressed without requiring any extra hardware structure
10 The OS starts assigning physical addresses to the requested pages according to the physical address chosen by the OS. The OS stores a counter for each cache bank which is increased whenever a new physical page is assigned to this bank. In this way, banks with more physical pages assigned to them will have higher value for the counter. To minimize the amount of off-chip accesses we define an upper bound on the deviation of the distribution of pages among cache banks controlled by a threshold value. If the counter of the bank where a page should map has reached the threshold value, the page is assigned to another bank.


11 The algorithm starts checking the counters of the banks at one hop from the initial placement. The bank with smaller value is chosen. If all banks at one hop have reached the threshold value, then the banks at a distance of two hops are checked. This algorithm iterates until a bank whose value is under the threshold is found. The policy ensures that at least one of the banks has always a value smaller than the threshold value by decreasing by one unit all counters when all of them have values different than zero. A small threshold value, reduces the number of off-chip accesses. A high threshold reduces the average latency of the accesses to the cache.
12 ACCESS AWARE CACHE PARTITIONING CACHEBALANCER The Cache Balancer consists of two parts: Access Rate based memory allocator Pain-driven task mapper.
13 CACHEBALANCER: Access Rate based Memory Allocation: Cache Balancer uses a metric called Access Rate to determine the relative utilization of cache banks. Access rate is defined as the ratio of the number of accesses made to a particular cache bank versus the total number of shared cache accesses in the system. A high access rate indicates that a cache bank is frequently accessed, i.e. a hot cache. Conversely, a low access rates indicates a relatively less accessed cache bank, or a cold cache.
14 Cache Balancer uses two access rate thresholds to determine if cache banks are hot or cold. These are determined as: thot = α MR tcold = MR _ β HC(pi,mj) Here thot and tcold represent the access rate thresholds for a cache bank MR is the mid-range value of the access rate across N cache banks in the system HC(pi,mj) is the hop-count along the interconnect path between Processing Element i and cache bank j.
15 The α and β parameters are integer constants that control the spread of Cache Balancer s memory allocations. α for instance influences the memory allocator s sensitivity to hot caches. β on the other hand influences the spread of data by limiting candidate cache banks based on their distance from the allocating PE. A high value forces the localization of data, while a low value enables the allocation of data across a larger number of cache banks. Due to their characteristics, these parameters could be used within a runtime manager to adapt memory allocations based on system utilization, power and reliability.
16
17 Access rates are measured using two 8 bit access counters per cache bank. In order to prevent temporal fluctuations in access rates from causing oscillations in memory allocation targets, access rate samples are filtered using a walking average filter. Thus, the counters are sampled every 500 cycles and averaged with a finite number of previous samples in order to determine the current access rate. The calculated value is subsequently stored in a dedicated section of the address space accessible through the memory hierarchy. In order to allocate memory, the memory allocator function is called from tasks executing on PEs. This function first computes the thot and tcold thresholds using the cache bank access rates, and invokes the selection algorithm listed below in Algorithm 1 to obtain a target cache bank. Memory is subsequently allocated in a section that corresponds to this target cache bank.
18 Pain-driven Task Mapping: Memory-intensive tasks are more likely to utilize cache banks heavily than their counterparts with smaller data sets. The performance of tasks can become interdependent when they share a cache, especially when their execution characteristics vary significantly. It is therefore essential for task characteristics to be taken into consideration during task mapping in order to uniformly utilize system resources and minimize inter-task interference.
19 Cache Balancer uses an adapted version of the Pain metric that guides the mapping of tasks onto PEs. The metric describes, for each executing task, the performance degradation that would be experienced if a certain new task were to be mapped onto a particular PE. Pain is measured in terms of three parameters: 1. Cache Intensity: This parameter indicates how aggressively a cache bank is used by tasks. 2. Cache Sensitivity: This parameter indicates the sensitivity of tasks to contention in shared cache banks. 3. Communication Pain: The communication cost for a task consists of the pain it experiences as a result of sharing the system interconnect with other tasks.

20 ANALYSIS Cache Balancer is evaluated using a cycle-accurate SystemC model of a 3D stacked, network-on-chip based tiled multiprocessor array. In order to emulate worst case conditions, Cache Balancer was tested with a synthetic workload that uses parallel tasks to repeatedly allocate and write to memory pages, thus stressing the shared caches.
21

22 RESULTS Distance Aware partitioning Impact of the changes in the indexing of the private L1 caches for the workloads evaluated
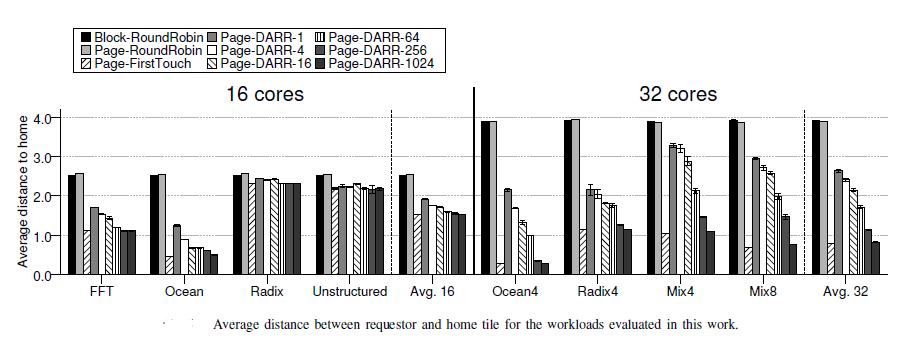
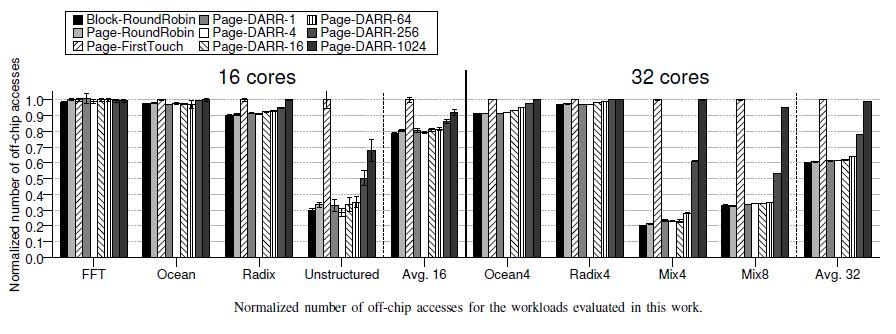
23
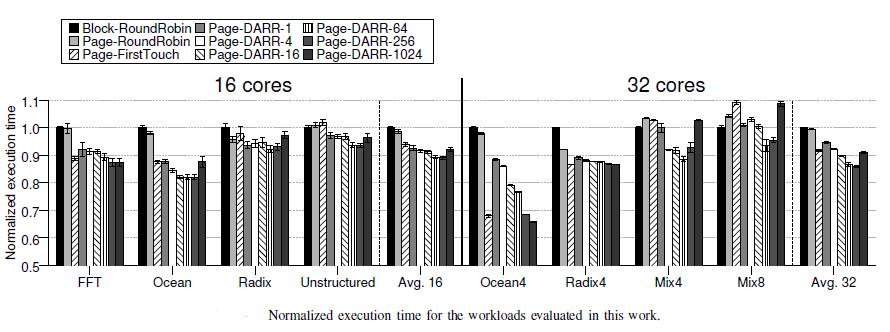
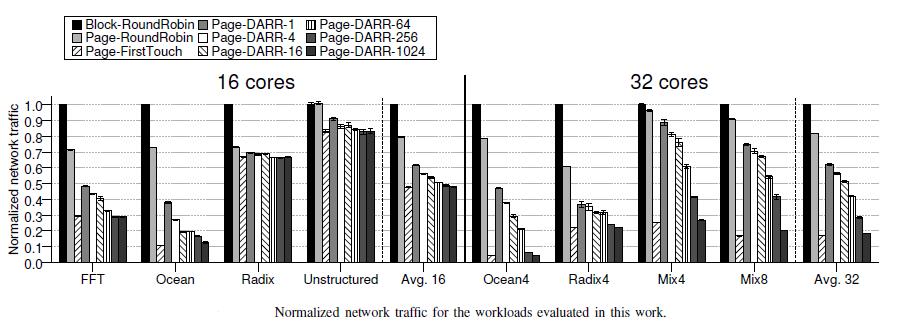
24

25 CACHE BALANCER
26 CONCLUSION Cache Balancer, a runtime resource management scheme for chip multiprocessors that uses the access rate and pain metrics to guide memory allocation and task mapping. The scheme achieved up to 60% lower contention by improving utilization of available cache banks, and reduced execution time by upto 22% as compared to competing proposals. The improved cache utilization further resulted in an energy density reduction of up to 50%.
27 REFERENCES 1. Alberto Ros, Marcelo Cintra, Manuel Acacio, Jose Garcia (2009) Distance-aware Round Robin Mapping for Large NUCA Caches. School of Informatics, University of Edinburgh. 2. Jurrien de Klerk, Sumeet Kumar, Rene Leuken (2014) CacheBalancer: Access Rate and Pain Based Resource Management for Chip Multiprocessors. Delft University of Technology, The Netherlands
Eastern Mediterranean University School of Computing and Technology CACHE MEMORY. Computer memory is organized into a hierarchy.
 Eastern Mediterranean University School of Computing and Technology ITEC255 Computer Organization & Architecture CACHE MEMORY Introduction Computer memory is organized into a hierarchy. At the highest
Eastern Mediterranean University School of Computing and Technology ITEC255 Computer Organization & Architecture CACHE MEMORY Introduction Computer memory is organized into a hierarchy. At the highest
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Cache memory. Lecture 4. Principles, structure, mapping
 Cache memory Lecture 4 Principles, structure, mapping Computer memory overview Computer memory overview By analyzing memory hierarchy from top to bottom, the following conclusions can be done: a. Cost
Cache memory Lecture 4 Principles, structure, mapping Computer memory overview Computer memory overview By analyzing memory hierarchy from top to bottom, the following conclusions can be done: a. Cost
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Lecture 2: Memory Systems
 Lecture 2: Memory Systems Basic components Memory hierarchy Cache memory Virtual Memory Zebo Peng, IDA, LiTH Many Different Technologies Zebo Peng, IDA, LiTH 2 Internal and External Memories CPU Date transfer
Lecture 2: Memory Systems Basic components Memory hierarchy Cache memory Virtual Memory Zebo Peng, IDA, LiTH Many Different Technologies Zebo Peng, IDA, LiTH 2 Internal and External Memories CPU Date transfer
(Advanced) Computer Organization & Architechture. Prof. Dr. Hasan Hüseyin BALIK (4 th Week)
 Computer Organization & Architechture. Prof. Dr. Hasan Hüseyin BALIK (4 th Week)") + (Advanced) Computer Organization & Architechture Prof. Dr. Hasan Hüseyin BALIK (4 th Week) + Outline 2. The computer system 2.1 A Top-Level View of Computer Function and Interconnection 2.2 Cache Memory
+ (Advanced) Computer Organization & Architechture Prof. Dr. Hasan Hüseyin BALIK (4 th Week) + Outline 2. The computer system 2.1 A Top-Level View of Computer Function and Interconnection 2.2 Cache Memory
OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI
 CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
CMPE 655- MULTIPLE PROCESSOR SYSTEMS OVERHEADS ENHANCEMENT IN MUTIPLE PROCESSING SYSTEMS BY ANURAG REDDY GANKAT KARTHIK REDDY AKKATI What is MULTI PROCESSING?? Multiprocessing is the coordinated processing
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
MICROPROCESSOR MEMORY ORGANIZATION
 MICROPROCESSOR MEMORY ORGANIZATION 1 3.1 Introduction 3.2 Main memory 3.3 Microprocessor on-chip memory management unit and cache 2 A memory unit is an integral part of any microcomputer, and its primary
MICROPROCESSOR MEMORY ORGANIZATION 1 3.1 Introduction 3.2 Main memory 3.3 Microprocessor on-chip memory management unit and cache 2 A memory unit is an integral part of any microcomputer, and its primary
Lecture 8: Virtual Memory. Today: DRAM innovations, virtual memory (Sections )
") Lecture 8: Virtual Memory Today: DRAM innovations, virtual memory (Sections 5.3-5.4) 1 DRAM Technology Trends Improvements in technology (smaller devices) DRAM capacities double every two years, but latency
Lecture 8: Virtual Memory Today: DRAM innovations, virtual memory (Sections 5.3-5.4) 1 DRAM Technology Trends Improvements in technology (smaller devices) DRAM capacities double every two years, but latency
12 Cache-Organization 1
 12 Cache-Organization 1 Caches Memory, 64M, 500 cycles L1 cache 64K, 1 cycles 1-5% misses L2 cache 4M, 10 cycles 10-20% misses L3 cache 16M, 20 cycles Memory, 256MB, 500 cycles 2 Improving Miss Penalty
12 Cache-Organization 1 Caches Memory, 64M, 500 cycles L1 cache 64K, 1 cycles 1-5% misses L2 cache 4M, 10 cycles 10-20% misses L3 cache 16M, 20 cycles Memory, 256MB, 500 cycles 2 Improving Miss Penalty
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Virtual Memory 11282011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review Cache Virtual Memory Projects 3 Memory
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Virtual Memory 11282011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review Cache Virtual Memory Projects 3 Memory
Lecture 14: Cache Innovations and DRAM. Today: cache access basics and innovations, DRAM (Sections )
") Lecture 14: Cache Innovations and DRAM Today: cache access basics and innovations, DRAM (Sections 5.1-5.3) 1 Reducing Miss Rate Large block size reduces compulsory misses, reduces miss penalty in case
Lecture 14: Cache Innovations and DRAM Today: cache access basics and innovations, DRAM (Sections 5.1-5.3) 1 Reducing Miss Rate Large block size reduces compulsory misses, reduces miss penalty in case
Chapter 8. Virtual Memory
 Operating System Chapter 8. Virtual Memory Lynn Choi School of Electrical Engineering Motivated by Memory Hierarchy Principles of Locality Speed vs. size vs. cost tradeoff Locality principle Spatial Locality:
Operating System Chapter 8. Virtual Memory Lynn Choi School of Electrical Engineering Motivated by Memory Hierarchy Principles of Locality Speed vs. size vs. cost tradeoff Locality principle Spatial Locality:
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Cache 11232011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review Memory Components/Boards Two-Level Memory Hierarchy
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Cache 11232011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review Memory Components/Boards Two-Level Memory Hierarchy
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
Computer-System Organization (cont.)
") Computer-System Organization (cont.) Interrupt time line for a single process doing output. Interrupts are an important part of a computer architecture. Each computer design has its own interrupt mechanism,
Computer-System Organization (cont.) Interrupt time line for a single process doing output. Interrupts are an important part of a computer architecture. Each computer design has its own interrupt mechanism,
Memory Systems and Compiler Support for MPSoC Architectures. Mahmut Kandemir and Nikil Dutt. Cap. 9
 Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
Memory Systems and Compiler Support for MPSoC Architectures Mahmut Kandemir and Nikil Dutt Cap. 9 Fernando Moraes 28/maio/2013 1 MPSoC - Vantagens MPSoC architecture has several advantages over a conventional
Chapter 5 (Part II) Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs
 Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs") Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip
 STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
William Stallings Computer Organization and Architecture 10 th Edition Pearson Education, Inc., Hoboken, NJ. All rights reserved.
 + William Stallings Computer Organization and Architecture 10 th Edition 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. 2 + Chapter 4 Cache Memory 3 Location Internal (e.g. processor registers,
+ William Stallings Computer Organization and Architecture 10 th Edition 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. 2 + Chapter 4 Cache Memory 3 Location Internal (e.g. processor registers,
Final Lecture. A few minutes to wrap up and add some perspective
 Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Final Lecture A few minutes to wrap up and add some perspective 1 2 Instant replay The quarter was split into roughly three parts and a coda. The 1st part covered instruction set architectures the connection
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
WEEK 7. Chapter 4. Cache Memory Pearson Education, Inc., Hoboken, NJ. All rights reserved.
 WEEK 7 + Chapter 4 Cache Memory Location Internal (e.g. processor registers, cache, main memory) External (e.g. optical disks, magnetic disks, tapes) Capacity Number of words Number of bytes Unit of Transfer
WEEK 7 + Chapter 4 Cache Memory Location Internal (e.g. processor registers, cache, main memory) External (e.g. optical disks, magnetic disks, tapes) Capacity Number of words Number of bytes Unit of Transfer
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
ParalleX. A Cure for Scaling Impaired Parallel Applications. Hartmut Kaiser
 ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
ParalleX A Cure for Scaling Impaired Parallel Applications Hartmut Kaiser (hkaiser@cct.lsu.edu) 2 Tianhe-1A 2.566 Petaflops Rmax Heterogeneous Architecture: 14,336 Intel Xeon CPUs 7,168 Nvidia Tesla M2050
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Operating system Dr. Shroouq J.
 2.2.2 DMA Structure In a simple terminal-input driver, when a line is to be read from the terminal, the first character typed is sent to the computer. When that character is received, the asynchronous-communication
2.2.2 DMA Structure In a simple terminal-input driver, when a line is to be read from the terminal, the first character typed is sent to the computer. When that character is received, the asynchronous-communication
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 2: Memory Hierarchy Design Part 2
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
Systems Programming and Computer Architecture ( ) Timothy Roscoe
 Timothy Roscoe") Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
Systems Group Department of Computer Science ETH Zürich Systems Programming and Computer Architecture (252-0061-00) Timothy Roscoe Herbstsemester 2016 AS 2016 Caches 1 16: Caches Computer Architecture
LECTURE 11. Memory Hierarchy
 LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
LECTURE 11 Memory Hierarchy MEMORY HIERARCHY When it comes to memory, there are two universally desirable properties: Large Size: ideally, we want to never have to worry about running out of memory. Speed
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
CSE 502: Computer Architecture Multi-{Socket,,Thread} Getting More Performance Keep pushing IPC and/or frequenecy Design complexity (time to market) Cooling (cost) Power delivery (cost) Possible, but too
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Lecture notes for CS Chapter 2, part 1 10/23/18
 Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Chapter 2: Memory Hierarchy Design Part 2 Introduction (Section 2.1, Appendix B) Caches Review of basics (Section 2.1, Appendix B) Advanced methods (Section 2.3) Main Memory Virtual Memory Fundamental
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design
 Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design Based on papers by: A.Fedorova, M.Seltzer, C.Small, and D.Nussbaum Pisa November 6, 2006 Multithreaded Chip
Performance of Multithreaded Chip Multiprocessors and Implications for Operating System Design Based on papers by: A.Fedorova, M.Seltzer, C.Small, and D.Nussbaum Pisa November 6, 2006 Multithreaded Chip
The University of Adelaide, School of Computer Science 13 September 2018
 Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 1: Introduction. Operating System Concepts 9 th Edit9on
 Chapter 1: Introduction Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 Objectives To describe the basic organization of computer systems To provide a grand tour of the major
Chapter 1: Introduction Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 Objectives To describe the basic organization of computer systems To provide a grand tour of the major
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
Embedded Systems Dr. Santanu Chaudhury Department of Electrical Engineering Indian Institute of Technology, Delhi
 Embedded Systems Dr. Santanu Chaudhury Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 13 Virtual memory and memory management unit In the last class, we had discussed
Embedded Systems Dr. Santanu Chaudhury Department of Electrical Engineering Indian Institute of Technology, Delhi Lecture - 13 Virtual memory and memory management unit In the last class, we had discussed
Chapter 1 Computer System Overview
 Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Seventh Edition By William Stallings Objectives of Chapter To provide a grand tour of the major computer system components:
Operating Systems: Internals and Design Principles Chapter 1 Computer System Overview Seventh Edition By William Stallings Objectives of Chapter To provide a grand tour of the major computer system components:
Lecture 1 Introduction (Chapter 1 of Textbook)
") Bilkent University Department of Computer Engineering CS342 Operating Systems Lecture 1 Introduction (Chapter 1 of Textbook) Dr. İbrahim Körpeoğlu http://www.cs.bilkent.edu.tr/~korpe 1 References The slides
Bilkent University Department of Computer Engineering CS342 Operating Systems Lecture 1 Introduction (Chapter 1 of Textbook) Dr. İbrahim Körpeoğlu http://www.cs.bilkent.edu.tr/~korpe 1 References The slides
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 9: Performance Issues in Shared Memory. The Lecture Contains:
 The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
The Lecture Contains: Data Access and Communication Data Access Artifactual Comm. Capacity Problem Temporal Locality Spatial Locality 2D to 4D Conversion Transfer Granularity Worse: False Sharing Contention
Memory Hierarchy. Reading. Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 (2) Lecture notes from MKP, H. H. Lee and S.
, 5.9 (2) Lecture notes from MKP, H. H. Lee and S.") Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
Memory Hierarchy Lecture notes from MKP, H. H. Lee and S. Yalamanchili Sections 5.1, 5.2, 5.3, 5.4, 5.8 (some elements), 5.9 Reading (2) 1 SRAM: Value is stored on a pair of inerting gates Very fast but
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Operating Systems. Introduction & Overview. Outline for today s lecture. Administrivia. ITS 225: Operating Systems. Lecture 1
 ITS 225: Operating Systems Operating Systems Lecture 1 Introduction & Overview Jan 15, 2004 Dr. Matthew Dailey Information Technology Program Sirindhorn International Institute of Technology Thammasat
ITS 225: Operating Systems Operating Systems Lecture 1 Introduction & Overview Jan 15, 2004 Dr. Matthew Dailey Information Technology Program Sirindhorn International Institute of Technology Thammasat
Addressing the Memory Wall
 Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Memory Management. Reading: Silberschatz chapter 9 Reading: Stallings. chapter 7 EEL 358
 Memory Management Reading: Silberschatz chapter 9 Reading: Stallings chapter 7 1 Outline Background Issues in Memory Management Logical Vs Physical address, MMU Dynamic Loading Memory Partitioning Placement
Memory Management Reading: Silberschatz chapter 9 Reading: Stallings chapter 7 1 Outline Background Issues in Memory Management Logical Vs Physical address, MMU Dynamic Loading Memory Partitioning Placement
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology
 Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
Using Industry Standards to Exploit the Advantages and Resolve the Challenges of Multicore Technology September 19, 2007 Markus Levy, EEMBC and Multicore Association Enabling the Multicore Ecosystem Multicore
An Introduction to Parallel Programming
 An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
An Introduction to Parallel Programming Ing. Andrea Marongiu (a.marongiu@unibo.it) Includes slides from Multicore Programming Primer course at Massachusetts Institute of Technology (MIT) by Prof. SamanAmarasinghe
Contents. Memory System Overview Cache Memory. Internal Memory. Virtual Memory. Memory Hierarchy. Registers In CPU Internal or Main memory
 Memory Hierarchy Contents Memory System Overview Cache Memory Internal Memory External Memory Virtual Memory Memory Hierarchy Registers In CPU Internal or Main memory Cache RAM External memory Backing
Memory Hierarchy Contents Memory System Overview Cache Memory Internal Memory External Memory Virtual Memory Memory Hierarchy Registers In CPU Internal or Main memory Cache RAM External memory Backing
Scheduling the Intel Core i7
 Third Year Project Report University of Manchester SCHOOL OF COMPUTER SCIENCE Scheduling the Intel Core i7 Ibrahim Alsuheabani Degree Programme: BSc Software Engineering Supervisor: Prof. Alasdair Rawsthorne
Third Year Project Report University of Manchester SCHOOL OF COMPUTER SCIENCE Scheduling the Intel Core i7 Ibrahim Alsuheabani Degree Programme: BSc Software Engineering Supervisor: Prof. Alasdair Rawsthorne
Module 10: "Design of Shared Memory Multiprocessors" Lecture 20: "Performance of Coherence Protocols" MOESI protocol.
 MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
MOESI protocol Dragon protocol State transition Dragon example Design issues General issues Evaluating protocols Protocol optimizations Cache size Cache line size Impact on bus traffic Large cache line
Computer Architecture. Memory Hierarchy. Lynn Choi Korea University
 Computer Architecture Memory Hierarchy Lynn Choi Korea University Memory Hierarchy Motivated by Principles of Locality Speed vs. Size vs. Cost tradeoff Locality principle Temporal Locality: reference to
Computer Architecture Memory Hierarchy Lynn Choi Korea University Memory Hierarchy Motivated by Principles of Locality Speed vs. Size vs. Cost tradeoff Locality principle Temporal Locality: reference to
Computer Architecture and OS. EECS678 Lecture 2
 Computer Architecture and OS EECS678 Lecture 2 1 Recap What is an OS? An intermediary between users and hardware A program that is always running A resource manager Manage resources efficiently and fairly
Computer Architecture and OS EECS678 Lecture 2 1 Recap What is an OS? An intermediary between users and hardware A program that is always running A resource manager Manage resources efficiently and fairly
CSC501 Operating Systems Principles. OS Structure
 CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
CSC501 Operating Systems Principles OS Structure 1 Announcements q TA s office hour has changed Q Thursday 1:30pm 3:00pm, MRC-409C Q Or email: awang@ncsu.edu q From department: No audit allowed 2 Last
Performance and Optimization Issues in Multicore Computing
 Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
Performance and Optimization Issues in Multicore Computing Minsoo Ryu Department of Computer Science and Engineering 2 Multicore Computing Challenges It is not easy to develop an efficient multicore program
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 18 Multicore Computers
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
William Stallings Computer Organization and Architecture 8 th Edition Chapter 18 Multicore Computers Hardware Performance Issues Microprocessors have seen an exponential increase in performance Improved
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Science 146. Computer Architecture
 Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 18: Virtual Memory Lecture Outline Review of Main Memory Virtual Memory Simple Interleaving Cycle
Computer Architecture Spring 2004 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 18: Virtual Memory Lecture Outline Review of Main Memory Virtual Memory Simple Interleaving Cycle
Introduction. Memory Hierarchy
 Introduction Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year 1 Memory Hierarchy Levels of memory with different sizes & speeds close to
Introduction Why memory subsystem design is important CPU speeds increase 25%-30% per year DRAM speeds increase 2%-11% per year 1 Memory Hierarchy Levels of memory with different sizes & speeds close to
vsphere Resource Management Update 1 11 JAN 2019 VMware vsphere 6.7 VMware ESXi 6.7 vcenter Server 6.7
 vsphere Resource Management Update 1 11 JAN 2019 VMware vsphere 6.7 VMware ESXi 6.7 vcenter Server 6.7 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/
vsphere Resource Management Update 1 11 JAN 2019 VMware vsphere 6.7 VMware ESXi 6.7 vcenter Server 6.7 You can find the most up-to-date technical documentation on the VMware website at: https://docs.vmware.com/
The levels of a memory hierarchy. Main. Memory. 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms
 The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
The levels of a memory hierarchy CPU registers C A C H E Memory bus Main Memory I/O bus External memory 500 By 1MB 4GB 500GB 0.25 ns 1ns 20ns 5ms 1 1 Some useful definitions When the CPU finds a requested
Q.1 Explain Computer s Basic Elements
 Q.1 Explain Computer s Basic Elements Ans. At a top level, a computer consists of processor, memory, and I/O components, with one or more modules of each type. These components are interconnected in some
Q.1 Explain Computer s Basic Elements Ans. At a top level, a computer consists of processor, memory, and I/O components, with one or more modules of each type. These components are interconnected in some
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 1: Introduction Dr. Ali Fanian. Operating System Concepts 9 th Edit9on
 Chapter 1: Introduction Dr. Ali Fanian Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 1.2 Silberschatz, Galvin and Gagne 2013 Organization Lectures Homework Quiz Several homeworks
Chapter 1: Introduction Dr. Ali Fanian Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 1.2 Silberschatz, Galvin and Gagne 2013 Organization Lectures Homework Quiz Several homeworks
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Real-Time Mixed-Criticality Wormhole Networks
 eal-time Mixed-Criticality Wormhole Networks Leandro Soares Indrusiak eal-time Systems Group Department of Computer Science University of York United Kingdom eal-time Systems Group 1 Outline Wormhole Networks
eal-time Mixed-Criticality Wormhole Networks Leandro Soares Indrusiak eal-time Systems Group Department of Computer Science University of York United Kingdom eal-time Systems Group 1 Outline Wormhole Networks
EECS750: Advanced Operating Systems. 2/24/2014 Heechul Yun
 EECS750: Advanced Operating Systems 2/24/2014 Heechul Yun 1 Administrative Project Feedback of your proposal will be sent by Wednesday Midterm report due on Apr. 2 3 pages: include intro, related work,
EECS750: Advanced Operating Systems 2/24/2014 Heechul Yun 1 Administrative Project Feedback of your proposal will be sent by Wednesday Midterm report due on Apr. 2 3 pages: include intro, related work,
Stack Machines. Towards Scalable Stack Based Parallelism. 1 of 53. Tutorial Organizer: Dr Chris Crispin-Bailey
 1 of 53 Stack Machines Towards Scalable Stack Based Parallelism Tutorial Organizer: Department of Computer Science University of York 2 of 53 Today s Speakers Dr Mark Shannon Dr Huibin Shi 3 of 53 Stack
1 of 53 Stack Machines Towards Scalable Stack Based Parallelism Tutorial Organizer: Department of Computer Science University of York 2 of 53 Today s Speakers Dr Mark Shannon Dr Huibin Shi 3 of 53 Stack
Virtual Memory. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
Virtual Memory Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Precise Definition of Virtual Memory Virtual memory is a mechanism for translating logical
a process may be swapped in and out of main memory such that it occupies different regions
 Virtual Memory Characteristics of Paging and Segmentation A process may be broken up into pieces (pages or segments) that do not need to be located contiguously in main memory Memory references are dynamically
Virtual Memory Characteristics of Paging and Segmentation A process may be broken up into pieces (pages or segments) that do not need to be located contiguously in main memory Memory references are dynamically
Asymmetry-aware execution placement on manycore chips
 Asymmetry-aware execution placement on manycore chips Alexey Tumanov Joshua Wise, Onur Mutlu, Greg Ganger CARNEGIE MELLON UNIVERSITY Introduction: Core Scaling? Moore s Law continues: can still fit more
Asymmetry-aware execution placement on manycore chips Alexey Tumanov Joshua Wise, Onur Mutlu, Greg Ganger CARNEGIE MELLON UNIVERSITY Introduction: Core Scaling? Moore s Law continues: can still fit more
Multiprocessor Systems. Chapter 8, 8.1
 Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Multiprocessor Systems Chapter 8, 8.1 1 Learning Outcomes An understanding of the structure and limits of multiprocessor hardware. An appreciation of approaches to operating system support for multiprocessor
Chapter 2: Computer-System Structures. Hmm this looks like a Computer System?
 Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
Chapter 2: Computer-System Structures Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure of a computer system and understanding
A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b
 5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b 1 School of
5th International Conference on Advanced Materials and Computer Science (ICAMCS 2016) A task migration algorithm for power management on heterogeneous multicore Manman Peng1, a, Wen Luo1, b 1 School of
Uniprocessor Computer Architecture Example: Cray T3E
 Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
Chapter 2: Computer-System Structures MP Example: Intel Pentium Pro Quad Lab 1 is available online Last lecture: why study operating systems? Purpose of this lecture: general knowledge of the structure
Virtual Memory. Reading. Sections 5.4, 5.5, 5.6, 5.8, 5.10 (2) Lecture notes from MKP and S. Yalamanchili
 Lecture notes from MKP and S. Yalamanchili") Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
Virtual Memory Lecture notes from MKP and S. Yalamanchili Sections 5.4, 5.5, 5.6, 5.8, 5.10 Reading (2) 1 The Memory Hierarchy ALU registers Cache Memory Memory Memory Managed by the compiler Memory Managed
High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur
 High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 23 Hierarchical Memory Organization (Contd.) Hello
High Performance Computer Architecture Prof. Ajit Pal Department of Computer Science and Engineering Indian Institute of Technology, Kharagpur Lecture - 23 Hierarchical Memory Organization (Contd.) Hello
Chapter 1: Introduction. Operating System Concepts 8th Edition,
 Chapter 1: Introduction, Administrivia Reading: Chapter 1. Next time: Continued Grand Tour. 1.2 Outline Common computer system devices. Parallelism within an operating system. Interrupts. Storage operation,
Chapter 1: Introduction, Administrivia Reading: Chapter 1. Next time: Continued Grand Tour. 1.2 Outline Common computer system devices. Parallelism within an operating system. Interrupts. Storage operation,
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 2 Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 2 What is an Operating System? What is
CS370 Operating Systems Colorado State University Yashwant K Malaiya Spring 2018 Lecture 2 Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 2 What is an Operating System? What is
Optimizing Replication, Communication, and Capacity Allocation in CMPs
 Optimizing Replication, Communication, and Capacity Allocation in CMPs Zeshan Chishti, Michael D Powell, and T. N. Vijaykumar School of ECE Purdue University Motivation CMP becoming increasingly important
Optimizing Replication, Communication, and Capacity Allocation in CMPs Zeshan Chishti, Michael D Powell, and T. N. Vijaykumar School of ECE Purdue University Motivation CMP becoming increasingly important
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs
 GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
William Stallings Computer Organization and Architecture 8th Edition. Chapter 5 Internal Memory
 William Stallings Computer Organization and Architecture 8th Edition Chapter 5 Internal Memory Semiconductor Memory The basic element of a semiconductor memory is the memory cell. Although a variety of
William Stallings Computer Organization and Architecture 8th Edition Chapter 5 Internal Memory Semiconductor Memory The basic element of a semiconductor memory is the memory cell. Although a variety of
Lecture: Large Caches, Virtual Memory. Topics: cache innovations (Sections 2.4, B.4, B.5)
") Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Intel Montecito Cache Two cores, each with a private 12 MB L3 cache and 1 MB L2 Naffziger et al., Journal of Solid-State
Lecture: Large Caches, Virtual Memory Topics: cache innovations (Sections 2.4, B.4, B.5) 1 Intel Montecito Cache Two cores, each with a private 12 MB L3 cache and 1 MB L2 Naffziger et al., Journal of Solid-State
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Lecture 16. Today: Start looking into memory hierarchy Cache$! Yay!
 Lecture 16 Today: Start looking into memory hierarchy Cache$! Yay! Note: There are no slides labeled Lecture 15. Nothing omitted, just that the numbering got out of sequence somewhere along the way. 1
Lecture 16 Today: Start looking into memory hierarchy Cache$! Yay! Note: There are no slides labeled Lecture 15. Nothing omitted, just that the numbering got out of sequence somewhere along the way. 1