Deep Network for the Integrated 3D Sensing of Multiple People in Natural Images
|
|
|
- Ami Carpenter
- 5 years ago
- Views:
Transcription
1 Deep Network for the Integrated 3D Sensing of Multiple People in Natural Images Andrei Zanfir 2 Elisabeta Marinoiu 2 Mihai Zanfir 2 Alin-Ionut Popa 2 Cristian Sminchisescu 1,2 {andrei.zanfir, elisabeta.marinoiu, mihai.zanfir, alin.popa}@imar.ro, cristian.sminchisescu@math.lth.se 1 Department of Mathematics, Faculty of Engineering, Lund University 2 Institute of Mathematics of the Romanian Academy Abstract We present MubyNet a feed-forward, multitask, bottom up system for the integrated localization, as well as 3d pose and shape estimation, of multiple people in monocular images. The challenge is the formal modeling of the problem that intrinsically requires discrete and continuous computation, e.g. grouping people vs. predicting 3d pose. The model identifies human body structures (joints and limbs) in images, groups them based on 2d and 3d information fused using learned scoring functions, and optimally aggregates such responses into partial or complete 3d human skeleton hypotheses under kinematic tree constraints, but without knowing in advance the number of people in the scene and their visibility relations. We design a multi-task deep neural network with differentiable stages where the person grouping problem is formulated as an integer program based on learned body part scores parameterized by both 2d and 3d information. This avoids suboptimality resulting from separate 2d and 3d reasoning, with grouping performed based on the combined representation. The final stage of 3d pose and shape prediction is based on a learned attention process where information from different human body parts is optimally integrated. State-of-the-art results are obtained in large scale datasets like Human3.6M and Panoptic, and qualitatively by reconstructing the 3d shape and pose of multiple people, under occlusion, in difficult monocular images. 1 Introduction The recent years have witnessed a resurgence of human sensing methods for body keypoint estimation [1; 2; 3; 4; 5; 6; 7] as well as 3d pose and shape reconstruction [8; 9; 10; 11; 12; 13; 14; 15; 16; 17; 18; 19; 20; 21]. Some of the challenges are in the level of modeling shifting towards accurate 3d pose and shape, not just 2d keypoints or skeletons, and the integration of 2d and 3d reasoning with automatic person localization and grouping. The discrete aspect of grouping and the continuous nature of pose estimation makes the formal integration of such computations difficult. In this paper we propose a novel, feedforward deep network, supporting different supervision regimes, that predicts the 3d pose and shape of multiple people in monocular images. We formulate and integrate human localization and grouping into the network, as a binary linear integer program with optimal solution based on learned body part compatibility functions constructed using 2d and 3d information. State-of-the-art results on Human3.6M and Panoptic illustrate the feasibility of the proposed approach. Related Work. Several authors focused on integrating different human sensing tasks into a singleshot end-to-end pipeline[22; 23; 24; 13]. The models are usually designed to handle a single person and often rely on a prior stage of detection. [13] encode the 3d information of a single person inside a feature map forcing the network to output 3d joint positions for each semantic body joint at its 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada.

2 corresponding 2d location. However, if some joints are occluded or hard to recover, their method may not provide accurate estimates. [9] use a discretized 3d space around the person, from which they read 3d joint activations. Their method is designed for one person and cannot easily be extended to handle large, crowded scenes. [25] use Region Proposal Networks [26] to obtain human bounding boxes and feeds them to predictive networks to obtain 2d and 3d pose. [27] provide a framework for the 3d human pose and shape estimation of multiple people. They start with a feedforward semantic segmentation of body parts, and 3d pose estimates based on DMHS [22], then refine the pose and shape parameters of a human body model [12] using non-linear optimization based on semantic fitting a form of feedback. In contrast, we provide an integrated, yet feedforward, bottom up deep learning framework for multi-person localization as well as 3d pose and shape estimation. One of the challenges in the visual sensing of multiple people is grouping identifying the components belonging to each person, their level of visibility, and the number of people in the scene. Our network aggregates different body joint proposals represented using both 2d and 3d information, to hypothesize limbs, and later these are assembled into person instances based on the results of a joint optimization problem. To address the arguably simpler, yet challenging problem of locating multiple people in the image (but not in 3d) [1] assign their network the task of regressing an additional feature map, where a slice encodes either the x or y coordinate of the normalized direction of ground-truth limbs. The information is redundant, as it is placed on the 2d projection of the ground truth limbs, within a distance σ from the line segment. Such part affinity fields are used to represent candidate part detection associations. The authors provide several solutions, one that is global but inefficient (running times of 6 minutes/image being common) and one greedy. In the greedy algorithm, larger human body hypotheses (skeletons) are grown incrementally by solving a series of intermediate bipartite matching problems along kinematic trees. While the algorithm is efficient, it cannot be immediately formalized as a cost function with global solution, it relies solely on 2d information, and the affinity functions are handcrafted. In contrast, we provide a method that leverages a volumetric 3d scene representation with learned scoring functions for the component parts, and an efficient global linear integer programming solution for person grouping with kinematic constraint generation, and amenable to efficient solvers (e.g. 30ms/image). Figure 1: Our multiple person sensing pipeline, MubyNet. The model is feed-forward and supports simultaneous multiple person localization, as well as 3d pose and shape estimation. Multitask losses constrain the output of the Deep Volume Encoding, Limb Scoring and 3D Pose & Shape Estimation modules. Given an image I, the processing stages are as follows: Deep Feature Extractor to compute features M I, Deep Volume Encoding to regress volumes containing 2d and 3d pose information V I. Limb Scoring collects all possible kinematic connections between 2d detected joints given their type, and predicts corresponding scores c, Skeleton Grouping performs multiple person localization, by assembling limbs into skeletons, V p I, by solving a binary integer linear program. For each person, the 3D Pose Decoding & Shape Estimation module estimates the 3d pose and shape (j p 3d, θp, β p ). 2 Methodology Our modeling and computational pipeline is shown in fig.1. The image is processed using a deep convolutional feature extractor to produce a representation M I. This is passed to a deep volume encoding module containing multiple 2d and 3d feature maps concatenated as V I = M I M 2d M 3d. The volume encoding is passed to a limb scoring module that identifies different human body 2


3 joint hypotheses and their type in images, connects ones that are compatible (can form parent-child relations in a human kinematic tree), and assigns them scores 1 given input features sampled in the deep volume encoding VI, along the spatial direction connecting their putative image locations. The resulting scores are assembled in a vector c and passed to a binary integer programming module that optimally computes skeletons for multiple people under kinematic constraints. The output is the original dense deep volume encoding VIp, annotated now with additional person skeleton grouping information. This is passed to a final stage, producing 3d pose and shape estimates for each person based on attention maps and deep auto-encoders. Figure 2: The volume encoding of multiple 3d ground truth skeletons in a scene. We associate a slice (column) in the volume to each one of the NJ 3 joint components. We encode each 3d skeleton jp3d associated to a person p, by writing each of its components in the corresponding slice, but only for columns intercepting spatial locations associated with the image projection of the skeleton. Figure 3: (a) Detailed view of a single stage t of our multi-stage Deep Volume Encoding (2d/3d) t 1 module. The image features MI, as well as predictions from the previous stage, Mt 1 3d and M2d, t t are used to refine the current representations M3d P and M2d. The multi-stage P module outputs VI, which represents the concatenation of MI, M2d = t Mt2d and M3d = t Mt3d. (b) Detail of the 3D Pose Decoding & Shape Estimation module. Given the estimated volume encoding VI, and the additional information from the estimation of person partitions VIp, we decode the 3d pose jp3d. By using auto-encoders, we recover the model pose and shape parameters (θ p, β p ). Given a monocular RGB image I Rh w 3, our goal is to recover the set of persons P present in the image, where (jp2d, jp3d, θ p, β p, tp ) P with 1 p P, j2d R2NJ 1 is the 2d skeleton, j3d R3NJ 1 is the 3d skeleton, (θ, β) R82 1 is the SMPL [12] shape embedding, and t R3 1 is the person s scene translation. 2.1 Deep Volume Encoding (2d/3d) Given the resolution of the input image, the resolution of the final maps produced by the network is H W with the network resolution of final maps h w. For the 2d and 3d skeletons, we adopt the Human3.6M [28] representation, with NJ = 17 joints and NL = 16 limbs. We refer to K {0, 1}NJ NJ as the kinematic tree, where K(i, j) = 1 means that nodes i and j are endpoints of a limb, in which i is the parent and j the child node. We denote by MI Rh w 128 the image 1 At this stage there is no person assignment so body joints very far apart have a putative connection as long as they are kinematically compatible. 3
4 features, by M 2d R h w N J the 2d human joint activation maps, and by M 3d R h w 3N J a volume that densely encodes 3d information. We start with a deep feature extractor (e.g. VGG-16, module M I ). Our pipeline progressively encodes volumes of intermediate 2d and 3d signals (i.e. M 2d and M 3d ) which are decoded by specialized layers later on. An illustration is given in fig. 3. The processing in modules such as Deep Volume Encoding is multi-stage [29; 22]. The input and the results of previous stages of processing are iteratively fed into the next, for refinement. We use different internal representations than [29; 22], and rely on a single supervised loss at the end of the multi-stage chain of processing, where outputs (activation maps) are fused and compared against ground truth. We found this approach to converge faster and produce slightly better results than the more standard per-stage supervision [29; 22]. We construct a representation combining 2d and 3d information capable of encoding multiple people in the following way: given an input image I, our Deep Volume Encoding module produces an output tensor M 3d containing the 3d structure of all people present in the image. At training time, for any ground-truth person p with g p 2d, gp 3d joints, kinematic tree structure K, and limbs L 2d = {(i, j) K(i, j) = 1, i, j N, 1 i, j N j }, we define a ground-truth volume G 3d. For all points (x, y) on the line segment of any limb l L 2d connecting joints in g p 2d, we set G 3d (x, y) = (g p 3d ). The procedure is illustrated in fig. 2. This module also produces M 2d, which encodes 2d joints activations. The corresponding ground-truth volume, G 2d, will be composed of confidence maps, one for each joint type aggregating Gaussian peaks placed at the corresponding 2d joint positions. The loss function will then measure the error between the predicted M 3d, M 2d and the ground-truth G 3d, G 2d L I = 1 x h,1 y w ρ 2d (M 2d (x, y), G 2d (x, y)) + 1 x h,1 y w G 3d (x,y) is valid ρ 3d (M 3d (x, y), G 3d (x, y)) (1) We choose ρ 2d to be the squared Euclidean loss, and ρ 3d the mean per-joint 3d position error (MPJPE). We explicitly train the network to output redundant 3d information along the 2d projection of a person s limbs. In this way, occlusion, blurry or hard-to-infer cases do not negatively impact the final, estimated {j p 3d }, in a significant way. 2.2 Skeleton Grouping Our skeleton grouping strategy relies on detecting potential human body joints and their type in images, assembling putative limbs, scoring them using trainable functions, and solving a global, optimal assignment problem (binary integer linear program) to find all connected components satisfying strong kinematic tree constraints each component being a different person. Limb Scoring By accessing the M 2d maps in V I we extract, via non-max suppression, N joint proposals J = {i 1 i N}, with t an index set of J such that if i J, t(i) {1,..., N J } is the joint type of i (e.g. shoulder, elbow, knee, etc.). The list of all the feasible kinematic connections (i.e. limbs) is then L = {(i, j) K(i, j) = 1, i, j N, 1 i, j J }. One needs a function to assess the quality of different limb hypotheses. In order to learn the scoring c, an additional network layer Limb Scoring is introduced. This takes as input the volume encoding map V I, and passes the result through a series of Conv/ReLU operations to build a map M c R h w 128. A subsequent process over M c and M 2d builds the candidate limb list L by sampling a fixed number N samples of features from M c for every l L, along the 2d direction of l. The resulting features have dimensions N L N samples 128, and are passed to a multi-layer perceptron head followed by a softmax non-linearity to regress the final scoring c [0, 1] N L 1. Supervision is applicable on outputs of Limb Scoring, via a cross-entropy loss L c. Any dataset containing 2d annotations of human body limbs can be used for training. People Grouping as a Binary Integer Programming Problem The problem of identifying the skeletons of multiple people is posed as estimating the optimal L L such that graph G = (J, L ) has properties (i) any connected component of G falls on a single person, (ii) p, q L, p = (i 1, j 1 ) and q = (i 2, j 2 ) with t(i 1 ) = t(i 2 ) and t(j 1 ) = t(j 2 ): if j 1 = j 2 then 4
5 i 1 i 2 and if i 1 = i 2 then j 1 j 2 these constraints ensure that connected components select at most one joint of a given type, and (iii) the connected components are as large as possible. Computing L is equivalent to finding a binary indicator x {0, 1} L 1 in the set L. We can encode the kinematic constraints (ii), by iterating over all limbs p L, and finding all the limbs q L that connect the same type of joints as p, and also share an end-point with it. Clearly, for any p, the solution x can select at most one of these limbs q. This can be written row-by-row, as a sparse matrix A {0, 1} L L, that constrains x such that Ax b, where b is the all-ones vector 1 L. In order to satisfy requirement (i), we need a cost that well qualifies the semantic and geometrical relationships between elements of the scene, learned as explained in the Limb Scoring paragraph above. The limb score c(l), l L measures how likely is that l is a limb of a person with the particular joint endpoint types. To satisfy requirement (iii), we need to encourage the selection of as many limbs as possible while still satisfying kinematic constraints. Given all these, the problem can naturally be modeled as a binary integer program x (c) = arg max c x, subject to Ax b, x {0, 1} N L 1 (2) x where an approximation to the optimal c = arg max c x (c) g c is learned within the Limb Scoring module. At testing time, given the learned scoring c, we apply (2) to compute the final, binarized solution x obeying all constraints. The global solution is very fast and accurate taking in the order of milliseconds per images with multiple people, as shown in the experimental section d Pose Decoding and Shape Estimation An immediate way of decoding the M 3d volume into 3d pose estimates for all the persons in the image, is to simply average 3d skeleton predictions at spatial locations given by the limbs selected by the people grouping module. However, this does not take into account the differences in joint visibility. We propose to learn a function that selectively attends to different regions in the M 3d volume, when decoding the 3d position for each joint. Given the feature volume V p I of a person and its identified skeleton, we collect a fixed number of samples along the direction of each 2d limb (see fig. 3 (b)). We train a multilayer perceptron to assign a score (weight) to each sample and for each 3d joint. The final predicted 3d skeleton j p 3d is the weighted sum of the 3d samples encoded in Mp 3d. The loss L p 3d is computed as the MPJPE between jp 3d and the ground truth skeleton gp 3d. In order to further represent the 3d shape of each person, we use a SMPL-based human model representation [12] controlled by a set of parameters θ R 72 1, which encode joint angle rotations, and β R 10 1 body dimensions, respectively. The model vertices are obtained as a function V(θ, β) R , and the joints as the product j s = Rvec(V) R 3N J 1, where R is a regression matrix and V is the matrix of all 3d vertices in the final mesh. Our goal is to map the predicted j 3d into a pair (θ, β) that best explains the 3d skeleton. Previous approaches [14] formulated this task as a supervised problem of regressing (θ, β), or forcing the projection of j s to match 2d estimates j 2d. The problem is at least two-fold: 1) θ encode axis-angle transformations that are cyclic in the angle and not unique in the axis, 2) regression on (θ, β) does not balance the importance of each parameter (e.g., the global rotation encoded in θ 0 is more important than the right foot rotation, encoded in a θ i ) in correctly inferring the full 3d body model. To address such difficulties, we model the problem as unsupervised auto-encoding inside a deep network, where the code is (θ, β), and the decoder is Rvec(V(θ, β)), which is a specialized layer. This is a natural approach, as the loss is then simply L s 3d = ρ 3d(j 3d, j s ), which does not force θ to have a unique or a specific value, and naturally balances the importance of each parameter. Additionally, the task is unsupervised. The encoder is a simple MLP with ReLUs as non-linearities. To account for the unnatural twists along limb directions that may appear, and the fact that β is not unique for a 3d skeleton (it is unique only for a given V), we also include in the loss function a GMM prior on the θ parameters, and a L2 prior on β. For those examples where we have ground-truth (θ, β) parameters available, they are fitted in a supervised manner using images and their corresponding shape and pose targets. The 3d loss can be derived as L 3d = L s 3d + L p 3d (3) 3 Experiments We provide quantitative results on two datasets, Human3.6m [28] and CMU Panoptic [30] as well as qualitative 3d reconstructions for complex images. 5
6 Human3.6m [28] is a large, single person dataset with accurate 2d and 3d ground truth obtained from a motion capture system. The dataset contains 15 actions performed by 11 actors in a laboratory environment. We provide results on the withheld, official test set which has over 900,000 images, as well as on the Human80K test set [31]. Human80K is a smaller, representative subset of Human3.6m. It contains 80,000 images (55, 144 for training and 24, 416 for testing). While this dataset does not allow us to assess the quality of sensing multiple people, it allows us to extensively evaluate the performance of our single-person component pipeline. CMU Panoptic [30] is a dataset that contains multiple people performing different social activities (e.g. society games, playing instruments, dancing) in an indoor dome where multiple cameras are placed. We will only consider the monocular case for both training and testing. The setup is difficult due to multiple people interacting, partial views and challenging camera angles. Following [27], we test our method on 9, 600 sequences selected from four activities: Haggling, Mafia, Ultimatum, and Pizza and two cameras, 16 and 30 (we run the monocular system on each camera, independently, and the total errors are averaged). Training Procedure. We use multiple datasets with different types of annotations for training our network. Specifically, we first train our M 2d component on COCO [32] which contains a large variety of images with multiple people in natural scenes. Then, we use the Human80K dataset to learn the 3d volume M 3d, once M 2d is fixed. Human80K contains accurate 3d joint positions annotations, however limited to single person, fully visible images, recorded in a laboratory setup. We further use the CMU Panoptic dataset for fine-tuning the M 3d component on images with multiple people and for a large variety of (monocular) viewpoints, which results in occlusions and partial views. Based on the learned 2d joint map activations M 2d, the 3d volume M 3d and the image features M I, we proceed to learn the limb scoring function, c. For this task we use the COCO dataset. The attention-based decoding is learned on CMU Panoptic since having multiple people in the same scene helps the decoder understand the difficult poses and learn where to focus in the case of occlusions and partially visible people. Finally, Human80K is used to learn the 3d shape auto-encoder due to its variability in body pose configurations. We use a Nesterov solver with a learning rate of 1e 5 and a momentum of 0.9. Our models are implemented in Caffe [33]. Figure 4: (Left) The distribution of the learned score c compared to the distribution of the selected limbs x after optimizing (2). Note that in the learned limb probability scores there are already many components close to 0 or 1 which indicates a well tuned function. (Right) Running time of our Binary Linear Integer Programming solver as a function of the number of components, dim(x). Notice fast running times for global solutions. Experimental Results. Table 2 (left) provides results of our method on Human80K. Firstly, we show the performance without the attention-based decoding (simply averaging 3d skeletons at 2d locations in M 3d volume). This setup already performs better than DMHS [22]. Note that DMHS uses ground truth person bounding boxes while our method runs on full images. Our method with attention-based decoding obtains state-of-the art results on Human80K dataset. We also provide results on the withheld test set of Human3.6m (over 900,000 images), where we considerably improve over the state-of-the art (60 mm compared to 73 mm error). Results are detailed for each action in table 1. For the CMU Panoptic dataset, results are shown for each action in table 2 (right). When our method uses only Human80K as supervision for the 3d task, it already performs better than [27]. In 6
7 table 2 (right) we also show results with a fine-tuned version of our method on the Panoptic dataset. We sampled data from the Haggling, Mafia, Ultimatum actions (different recordings than those in test data) and from all cameras for fine-tuning our model. We obtained a total of 74, 936 data samples where the number of people per image ranges from 1 to 8. Our fine-tuned method improves the previous results by a large margin notice errors of 72.1 mm down from mm. We show visual results of our method on natural images with complex interactions in fig. 5. We are able to correctly identify all the persons in an image as well as their associated 3d pose configuration, even when they are far in depth (first row) or severely occluded (last four rows). Limb Scoring. In fig. 4 (left) we show the distribution of the learned scores c for the kinematically admissible putative limbs and the distribution of the optimal limb indicator vector components x over 100 images from the COCO validation set. The learned limb scoring already has many of its components close to either 0 or 1, although a considerable number still are undecided resulting in non-trivial integer programming problems. We tested the average time taken by the binary integer programming solver as a function of the number of detected limbs (the length of the score vector c). Figure 4 (right) shows that the method scales favorably with the number of components, i.e. dim(x). Method A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15 Mean [22] [27] MubyNet Table 1: Mean per joint 3d position error (in mm) on the Human3.6M dataset. MubyNet improves the state-of-the-art by a large margin for all actions. Method MPJPE(mm) [22] MubyNet MubyNet attention Method Haggling Mafia Ultimatum Pizza Mean [22] [27] MubyNet MubyNet fine-tuned Table 2: Mean per joint 3d position error (in mm). (Left) Human80K dataset. Our method with a mean decoding of the 3d volume obtains state-of-the art results. Adding the attention mechanism further improves the performance. (Right) CMU Panoptic dataset. Our method with 3d supervision only from Human80K performs better than previous works. Fine-tuning on the CMU Panoptic dataset drastically reduces the error. 4 Conclusions We have presented a bottom up trainable model for the 2d and 3d human sensing of multiple people in monocular images. The proposed model, MubyNet, is multitask and feed-forward, differentiable, and thus conveniently supports training all component parameters. The difficult problem of localizing and grouping people is formulated as a binary linear integer program, and solved globally and optimally under kinematic problem domain constraints and based on learned scoring functions that combine 2d and 3d information for accurate reasoning. Both 3d human pose and shape are computed in a final predictive stage that fuses information based on learned attention maps and deep auto-encoders. Ablation studies and model component analysis illustrate the adequacy of various design choices including the efficiency of our global, binary integer linear programming solution, under kinematic constraints, for the human grouping problem. Our large-scale experimental evaluation in datasets like Human3.6M and Panoptic, and for withheld test sets of over 1 million samples, offers competitive results. Qualitative examples show that our model can reliably estimate the 3d properties of multiple people in natural scenes, with occlusion, partial views, and complex backgrounds. Acknowledgments: This work was supported in part by the European Research Council Consolidator grant SEED, CNCS-UEFISCDI (PN-III-P4-ID-PCE , PN-III-P4-ID-PCCF ), the EU Horizon 2020 grant DE-ENIGMA (688835), and SSF. 7



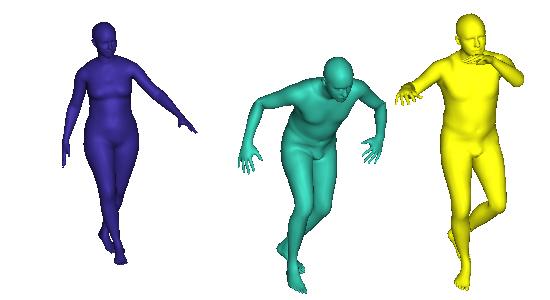











8 Figure 5: Human pose and shape reconstruction of multiple people produced by MubyNet illustrate good 3d estimates for distant people, complex poses or occlusion. For global translations, we optimize the Euclidean loss between the 2d joint detections and the projections predicted by our 3d models. 8
9 References [1] Z. Cao, T. Simon, S. Wei, and Y. Sheikh, Realtime multi-person 2d pose estimation using part affinity fields, in CVPR, [2] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, and B. Schiele, DeeperCut: A deeper, stronger, and faster multi-person pose estimation model, in ECCV, [3] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy, Towards accurate multi-person pose estimation in the wild, in CVPR, [4] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler, Joint training of a convolutional network and a graphical model for human pose estimation, in NIPS, [5] A. Toshev and C. Szegedy, Deeppose: Human pose estimation via deep neural networks, in CVPR, [6] G. Gkioxari, B. Hariharan, R. Girshick, and J. Malik, Using k-poselets for detecting people and localizing their keypoints, in CVPR, pp , [7] U. Iqbal and J. Gall, Multi-person pose estimation with local joint-to-person associations, in ECCV, [8] J. Martinez, R. Hossain, J. Romero, and J. J. Little, A simple yet effective baseline for 3d human pose estimation, in ICCV, [9] G. Pavlakos, X. Zhou, K. G. Derpanis, and K. Daniilidis, Coarse-to-fine volumetric prediction for single-image 3d human pose, in CVPR, [10] X. Zhou, M. Zhu, K. Derpanis, and K. Daniilidis, Sparseness meets deepness: 3d human pose estimation from monocular video, in CVPR, [11] F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M. J. Black, Keep it SMPL: Automatic estimation of 3d human pose and shape from a single image, in ECCV, [12] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, SMPL: A skinned multi-person linear model, SIGGRAPH, vol. 34, no. 6, pp. 248:1 16, [13] D. Mehta, S. Sridhar, O. Sotnychenko, H. Rhodin, M. Shafiei, H.-P. Seidel, W. Xu, D. Casas, and C. Theobalt, Vnect: Real-time 3d human pose estimation with a single rgb camera, ACM Transactions on Graphics (TOG), vol. 36, no. 4, p. 44, [14] A. Kanazawa, M. J. Black, D. W. Jacobs, and J. Malik, End-to-end recovery of human shape and pose, in CVPR, [15] C.-H. Chen and D. Ramanan, 3d human pose estimation= 2d pose estimation+ matching, in CVPR, [16] F. Moreno-Noguer, 3d human pose estimation from a single image via distance matrix regression, in CVPR, [17] I. Katircioglu, B. Tekin, M. Salzmann, V. Lepetit, and P. Fua, Learning latent representations of 3d human pose with deep neural networks, IJCV, pp. 1 16, [18] X. Zhou, Q. Huang, X. Sun, X. Xue, and Y. Wei, Towards 3d human pose estimation in the wild: a weakly-supervised approach, in ICCV, [19] S. Li and A. B. Chan, 3d human pose estimation from monocular images with deep convolutional neural network, in ACCV, [20] E. Brau and H. Jiang, 3d human pose estimation via deep learning from 2d annotations, in 3D Vision (3DV), 2016 Fourth International Conference on, pp , IEEE, [21] W. Chen, H. Wang, Y. Li, H. Su, Z. Wang, C. Tu, D. Lischinski, D. Cohen-Or, and B. Chen, Synthesizing training images for boosting human 3d pose estimation, in 3D Vision (3DV),
10 [22] A. I. Popa, M. Zanfir, and C. Sminchisescu, Deep multitask architecture for integrated 2d and 3d human sensing, in CVPR, [23] G. Rogez and C. Schmid, Mocap-guided data augmentation for 3d pose estimation in the wild, in NIPS, [24] B. Tekin, P. Marquez Neila, M. Salzmann, and P. Fua, Learning to fuse 2d and 3d image cues for monocular body pose estimation, in ICCV, [25] G. Rogez, P. Weinzaepfel, and C. Schmid, Lcr-net: Localization-classification-regression for human pose, in CVPR, [26] S. Ren, K. He, R. Girshick, and J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, in NIPS, pp , [27] A. Zanfir, E. Marinoiu, and C. Sminchisescu, Monocular 3D Pose and Shape Estimation of Multiple People in Natural Scenes The Importance of Multiple Scene Constraints, in CVPR, [28] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, Human3.6M: Large scale datasets and predictive methods for 3d human sensing in natural environments, PAMI, [29] S. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, Convolutional pose machines, in CVPR, June [30] H. Joo, H. Liu, L. Tan, L. Gui, B. Nabbe, I. Matthews, T. Kanade, S. Nobuhara, and Y. Sheikh, Panoptic studio: A massively multiview system for social motion capture, in ICCV, [31] C. Ionescu, J. Carreira, and C. Sminchisescu, Iterated second-order label sensitive pooling for 3d human pose estimation, in CVPR, pp , [32] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, Microsoft coco: Common objects in context, in ECCV, [33] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell, Caffe: Convolutional architecture for fast feature embedding, arxiv preprint arxiv: ,
arxiv: v1 [cs.cv] 31 Jan 2017
![arxiv: v1 [cs.cv] 31 Jan 2017](/thumbs/75/71971098.jpg "arxiv: v1 [cs.cv] 31 Jan 2017") Deep Multitask Architecture for Integrated 2D and 3D Human Sensing Alin-Ionut Popa 2, Mihai Zanfir 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, mihai.zanfir@imar.ro cristian.sminchisescu@math.lth.se
Deep Multitask Architecture for Integrated 2D and 3D Human Sensing Alin-Ionut Popa 2, Mihai Zanfir 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, mihai.zanfir@imar.ro cristian.sminchisescu@math.lth.se
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB
 Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2],OleksandrSotnychenko [1,2],FranziskaMueller [1,2], Weipeng Xu [1,2],SrinathSridhar [3],GerardPons-Moll [1,2], Christian
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2],OleksandrSotnychenko [1,2],FranziskaMueller [1,2], Weipeng Xu [1,2],SrinathSridhar [3],GerardPons-Moll [1,2], Christian
arxiv: v1 [cs.cv] 14 Jan 2019
![arxiv: v1 [cs.cv] 14 Jan 2019](/thumbs/93/114117280.jpg "arxiv: v1 [cs.cv] 14 Jan 2019") Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views arxiv:1901.04111v1 [cs.cv] 14 Jan 2019 Junting Dong Zhejiang University jtdong@zju.edu.cn Abstract Hujun Bao Zhejiang University bao@cad.zju.edu.cn
Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views arxiv:1901.04111v1 [cs.cv] 14 Jan 2019 Junting Dong Zhejiang University jtdong@zju.edu.cn Abstract Hujun Bao Zhejiang University bao@cad.zju.edu.cn
arxiv: v3 [cs.cv] 28 Aug 2018
![arxiv: v3 [cs.cv] 28 Aug 2018](/thumbs/86/94638636.jpg "arxiv: v3 [cs.cv] 28 Aug 2018") Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2], Oleksandr Sotnychenko [1,2], Franziska Mueller [1,2], Weipeng Xu [1,2], Srinath Sridhar [3], Gerard Pons-Moll [1,2],
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB Dushyant Mehta [1,2], Oleksandr Sotnychenko [1,2], Franziska Mueller [1,2], Weipeng Xu [1,2], Srinath Sridhar [3], Gerard Pons-Moll [1,2],
A Dual-Source Approach for 3D Human Pose Estimation from Single Images
 1 Computer Vision and Image Understanding journal homepage: www.elsevier.com A Dual-Source Approach for 3D Human Pose Estimation from Single Images Umar Iqbal a,, Andreas Doering a, Hashim Yasin b, Björn
1 Computer Vision and Image Understanding journal homepage: www.elsevier.com A Dual-Source Approach for 3D Human Pose Estimation from Single Images Umar Iqbal a,, Andreas Doering a, Hashim Yasin b, Björn
Integral Human Pose Regression
 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, and Yichen Wei 1 1 Microsoft Research, Beijing, China {xias, Bin.Xiao, yichenw}@microsoft.com 2 Peking University,
arxiv: v3 [cs.cv] 20 Mar 2018
![arxiv: v3 [cs.cv] 20 Mar 2018](/thumbs/77/75966172.jpg "arxiv: v3 [cs.cv] 20 Mar 2018") arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
arxiv:1711.08229v3 [cs.cv] 20 Mar 2018 Integral Human Pose Regression Xiao Sun 1, Bin Xiao 1, Fangyin Wei 2, Shuang Liang 3, Yichen Wei 1 1 Microsoft Research, 2 Peking University, 3 Tongji University
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material
 Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
Learning to Estimate 3D Human Pose and Shape from a Single Color Image Supplementary material Georgios Pavlakos 1, Luyang Zhu 2, Xiaowei Zhou 3, Kostas Daniilidis 1 1 University of Pennsylvania 2 Peking
3D Pose Estimation using Synthetic Data over Monocular Depth Images
 3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
3D Pose Estimation using Synthetic Data over Monocular Depth Images Wei Chen cwind@stanford.edu Xiaoshi Wang xiaoshiw@stanford.edu Abstract We proposed an approach for human pose estimation over monocular
Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation
 Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation Mohamed Omran 1 Christoph Lassner 2 Gerard Pons-Moll 1 Peter V. Gehler 2 Bernt Schiele 1 1 Max Planck Institute
Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation Mohamed Omran 1 Christoph Lassner 2 Gerard Pons-Moll 1 Peter V. Gehler 2 Bernt Schiele 1 1 Max Planck Institute
arxiv: v4 [cs.cv] 12 Sep 2018
![arxiv: v4 [cs.cv] 12 Sep 2018](/thumbs/94/118550082.jpg "arxiv: v4 [cs.cv] 12 Sep 2018") arxiv:1711.08585v4 [cs.cv] 12 Sep 2018 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia
arxiv:1711.08585v4 [cs.cv] 12 Sep 2018 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
 Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, Yichen Wei UT Austin & MSRA & Fudan Human Pose Estimation Pose representation
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document
 Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Real-time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor Supplemental Document Franziska Mueller 1,2 Dushyant Mehta 1,2 Oleksandr Sotnychenko 1 Srinath Sridhar 1 Dan Casas 3 Christian Theobalt
Exploiting temporal information for 3D human pose estimation
 Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia {rayat137,little}@cs.ubc.ca Abstract.
Exploiting temporal information for 3D human pose estimation Mir Rayat Imtiaz Hossain, James J. Little Department of Computer Science, University of British Columbia {rayat137,little}@cs.ubc.ca Abstract.
arxiv: v1 [cs.cv] 18 Dec 2017
![arxiv: v1 [cs.cv] 18 Dec 2017](/thumbs/78/78715631.jpg "arxiv: v1 [cs.cv] 18 Dec 2017") End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v1 [cs.cv] 18 Dec 2017 Angjoo Kanazawa1,3, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v1 [cs.cv] 18 Dec 2017 Angjoo Kanazawa1,3, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
arxiv:submit/ [cs.cv] 14 Apr 2017
![arxiv:submit/ [cs.cv] 14 Apr 2017](/thumbs/74/70798537.jpg "arxiv:submit/ [cs.cv] 14 Apr 2017") Harvesting Multiple Views for Marker-less 3D Human Pose Annotations Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Harvesting Multiple Views for Marker-less 3D Human Pose Annotations Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
End-to-end Recovery of Human Shape and Pose
 End-to-end Recovery of Human Shape and Pose Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for Intelligent Systems, Tu bingen, Germany,
End-to-end Recovery of Human Shape and Pose Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for Intelligent Systems, Tu bingen, Germany,
arxiv: v2 [cs.cv] 24 Mar 2018
![arxiv: v2 [cs.cv] 24 Mar 2018](/thumbs/85/92932763.jpg "arxiv: v2 [cs.cv] 24 Mar 2018") Learning Monocular 3D Human Pose Estimation from Multi-view Images Helge Rhodin Frédéric Meyer3 arxiv:803.04775v [cs.cv] 4 Mar 08 Jörg Spörri,4 Erich Müller4 CVLab, EPFL, Lausanne, Switzerland 3 UNIL,
Learning Monocular 3D Human Pose Estimation from Multi-view Images Helge Rhodin Frédéric Meyer3 arxiv:803.04775v [cs.cv] 4 Mar 08 Jörg Spörri,4 Erich Müller4 CVLab, EPFL, Lausanne, Switzerland 3 UNIL,
arxiv: v2 [cs.cv] 23 Jun 2018
![arxiv: v2 [cs.cv] 23 Jun 2018](/thumbs/85/92598818.jpg "arxiv: v2 [cs.cv] 23 Jun 2018") End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v2 [cs.cv] 23 Jun 2018 Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
End-to-end Recovery of Human Shape and Pose arxiv:1712.06584v2 [cs.cv] 23 Jun 2018 Angjoo Kanazawa1, Michael J. Black2, David W. Jacobs3, Jitendra Malik1 1 University of California, Berkeley 2 MPI for
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
arxiv: v3 [cs.cv] 2 Aug 2017
![arxiv: v3 [cs.cv] 2 Aug 2017](/thumbs/75/72344857.jpg "arxiv: v3 [cs.cv] 2 Aug 2017") Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
arxiv: v1 [cs.cv] 17 May 2016
![arxiv: v1 [cs.cv] 17 May 2016](/thumbs/74/69966525.jpg "arxiv: v1 [cs.cv] 17 May 2016") arxiv:1605.05180v1 [cs.cv] 17 May 2016 TEKIN ET AL.: STRUCTURED PREDICTION OF 3D HUMAN POSE 1 Structured Prediction of 3D Human Pose with Deep Neural Networks Bugra Tekin 1 bugra.tekin@epfl.ch Isinsu Katircioglu
arxiv:1605.05180v1 [cs.cv] 17 May 2016 TEKIN ET AL.: STRUCTURED PREDICTION OF 3D HUMAN POSE 1 Structured Prediction of 3D Human Pose with Deep Neural Networks Bugra Tekin 1 bugra.tekin@epfl.ch Isinsu Katircioglu
arxiv: v1 [cs.cv] 17 Sep 2016
![arxiv: v1 [cs.cv] 17 Sep 2016](/thumbs/90/104468396.jpg "arxiv: v1 [cs.cv] 17 Sep 2016") arxiv:1609.05317v1 [cs.cv] 17 Sep 2016 Deep Kinematic Pose Regression Xingyi Zhou 1, Xiao Sun 2, Wei Zhang 1, Shuang Liang 3, Yichen Wei 2 1 Shanghai Key Laboratory of Intelligent Information Processing
arxiv:1609.05317v1 [cs.cv] 17 Sep 2016 Deep Kinematic Pose Regression Xingyi Zhou 1, Xiao Sun 2, Wei Zhang 1, Shuang Liang 3, Yichen Wei 2 1 Shanghai Key Laboratory of Intelligent Information Processing
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera
 VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera By Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, Christian
VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera By Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, Christian
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Ordinal Depth Supervision for 3D Human Pose Estimation
 Ordinal Depth Supervision for 3D Human Pose Estimation Georgios Pavlakos 1, Xiaowei Zhou 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 State Key Lab of CAD&CG, Zhejiang University Abstract Our
Ordinal Depth Supervision for 3D Human Pose Estimation Georgios Pavlakos 1, Xiaowei Zhou 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 State Key Lab of CAD&CG, Zhejiang University Abstract Our
3D Human Pose Estimation in the Wild by Adversarial Learning
 3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
3D Human Pose Estimation in the Wild by Adversarial Learning Wei Yang 1 Wanli Ouyang 2 Xiaolong Wang 3 Jimmy Ren 4 Hongsheng Li 1 Xiaogang Wang 1 1 CUHK-SenseTime Joint Lab, The Chinese University of Hong
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Compositional Human Pose Regression
 Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
Compositional Human Pose Regression Xiao Sun 1, Jiaxiang Shang 1, Shuang Liang 2, Yichen Wei 1 1 Microsoft Research, 2 Tongji University {xias, yichenw}@microsoft.com, jiaxiang.shang@gmail.com, shuangliang@tongji.edu.cn
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
 Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose Georgios Pavlakos 1, Xiaowei Zhou 1, Konstantinos G. Derpanis 2, Kostas Daniilidis 1 1 University of Pennsylvania 2 Ryerson University
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Pose Estimation on Depth Images with Convolutional Neural Network
 Pose Estimation on Depth Images with Convolutional Neural Network Jingwei Huang Stanford University jingweih@stanford.edu David Altamar Stanford University daltamar@stanford.edu Abstract In this paper
Pose Estimation on Depth Images with Convolutional Neural Network Jingwei Huang Stanford University jingweih@stanford.edu David Altamar Stanford University daltamar@stanford.edu Abstract In this paper
arxiv: v1 [cs.cv] 30 Nov 2015
![arxiv: v1 [cs.cv] 30 Nov 2015](/thumbs/74/70553581.jpg "arxiv: v1 [cs.cv] 30 Nov 2015") accepted at CVPR 016 Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video Xiaowei Zhou, Menglong Zhu, Spyridon Leonardos, Kosta Derpanis, Kostas Daniilidis University of Pennsylvania
accepted at CVPR 016 Sparseness Meets Deepness: 3D Human Pose Estimation from Monocular Video Xiaowei Zhou, Menglong Zhu, Spyridon Leonardos, Kosta Derpanis, Kostas Daniilidis University of Pennsylvania
Propagating LSTM: 3D Pose Estimation based on Joint Interdependency
 Propagating LSTM: 3D Pose Estimation based on Joint Interdependency Kyoungoh Lee, Inwoong Lee, and Sanghoon Lee ( ) Department of Electrical Electronic Engineering, Yonsei University {kasinamooth, mayddb100,
Propagating LSTM: 3D Pose Estimation based on Joint Interdependency Kyoungoh Lee, Inwoong Lee, and Sanghoon Lee ( ) Department of Electrical Electronic Engineering, Yonsei University {kasinamooth, mayddb100,
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
arxiv: v2 [cs.cv] 21 Mar 2018
![arxiv: v2 [cs.cv] 21 Mar 2018](/thumbs/81/84591831.jpg "arxiv: v2 [cs.cv] 21 Mar 2018") 2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning Diogo C. Luvizon 1, David Picard 1,2, Hedi Tabia 1 1 ETIS UMR 8051, Paris Seine University, ENSEA, CNRS, F-95000, Cergy, France
2D/3D Pose Estimation and Action Recognition using Multitask Deep Learning Diogo C. Luvizon 1, David Picard 1,2, Hedi Tabia 1 1 ETIS UMR 8051, Paris Seine University, ENSEA, CNRS, F-95000, Cergy, France
arxiv: v1 [cs.cv] 5 Dec 2018
![arxiv: v1 [cs.cv] 5 Dec 2018](/thumbs/91/107005907.jpg "arxiv: v1 [cs.cv] 5 Dec 2018") Capture Dense: Markerless Motion Capture Meets Dense Pose Estimation Xiu Li,2 Yebin Liu Hanbyul Joo 2 Qionghai Dai Yaser Sheikh 2 Tsinghua University Carnegie Mellon University 2 arxiv:82.783v [cs.cv]
Capture Dense: Markerless Motion Capture Meets Dense Pose Estimation Xiu Li,2 Yebin Liu Hanbyul Joo 2 Qionghai Dai Yaser Sheikh 2 Tsinghua University Carnegie Mellon University 2 arxiv:82.783v [cs.cv]
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images
 Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Multi-scale Adaptive Structure Network for Human Pose Estimation from Color Images Wenlin Zhuang 1, Cong Peng 2, Siyu Xia 1, and Yangang, Wang 1 1 School of Automation, Southeast University, Nanjing, China
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
arxiv: v2 [cs.cv] 11 Apr 2017
![arxiv: v2 [cs.cv] 11 Apr 2017](/thumbs/79/80229724.jpg "arxiv: v2 [cs.cv] 11 Apr 2017") 3D Human Pose Estimation = 2D Pose Estimation + Matching Ching-Hang Chen Carnegie Mellon University chinghac@andrew.cmu.edu Deva Ramanan Carnegie Mellon University deva@cs.cmu.edu arxiv:1612.06524v2 [cs.cv]
3D Human Pose Estimation = 2D Pose Estimation + Matching Ching-Hang Chen Carnegie Mellon University chinghac@andrew.cmu.edu Deva Ramanan Carnegie Mellon University deva@cs.cmu.edu arxiv:1612.06524v2 [cs.cv]
Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation
 Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation Helge Rhodin [3 2692 0801], Mathieu Salzmann [2 8347 8637], and Pascal Fua [2 6702 9970] CVLab, EPFL, Lausanne, Switzerland {helge.rhodin,mathieu.salzmann,pascal.fua}@epfl.ch
Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation Helge Rhodin [3 2692 0801], Mathieu Salzmann [2 8347 8637], and Pascal Fua [2 6702 9970] CVLab, EPFL, Lausanne, Switzerland {helge.rhodin,mathieu.salzmann,pascal.fua}@epfl.ch
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network
 Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Supplementary Material: Pixelwise Instance Segmentation with a Dynamically Instantiated Network Anurag Arnab and Philip H.S. Torr University of Oxford {anurag.arnab, philip.torr}@eng.ox.ac.uk 1. Introduction
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Cross-View Person Identification by Matching Human Poses Estimated with Confidence on Each Body Joint
 Cross-View Person Identification by Matching Human Poses Estimated with Confidence on Each Body Joint Guoqiang Liang 1,, Xuguang Lan 1, Kang Zheng, Song Wang, 3, Nanning Zheng 1 1 Institute of Artificial
Cross-View Person Identification by Matching Human Poses Estimated with Confidence on Each Body Joint Guoqiang Liang 1,, Xuguang Lan 1, Kang Zheng, Song Wang, 3, Nanning Zheng 1 1 Institute of Artificial
arxiv: v1 [cs.cv] 15 Mar 2018
![arxiv: v1 [cs.cv] 15 Mar 2018](/thumbs/82/85612196.jpg "arxiv: v1 [cs.cv] 15 Mar 2018") arxiv:1803.05959v1 [cs.cv] 15 Mar 2018 Mo 2 Cap 2 : Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera Weipeng Xu 1 Avishek Chatterjee 1 Michael Zollhoefer 1,2 Helge Rhodin 3 Pascal Fua
arxiv:1803.05959v1 [cs.cv] 15 Mar 2018 Mo 2 Cap 2 : Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera Weipeng Xu 1 Avishek Chatterjee 1 Michael Zollhoefer 1,2 Helge Rhodin 3 Pascal Fua
Stereo Human Keypoint Estimation
 Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Stereo Human Keypoint Estimation Kyle Brown Stanford University Stanford Intelligent Systems Laboratory kjbrown7@stanford.edu Abstract The goal of this project is to accurately estimate human keypoint
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Human Appearance Transfer
 Human Appearance Transfer Mihai Zanfir 2 Alin-Ionut Popa 2 Andrei Zanfir 2 Cristian Sminchisescu 1,2 {mihai.zanfir, alin.popa, andrei.zanfir}@imar.ro cristian.sminchisescu@math.lth.se 1 Department of Mathematics,
Human Appearance Transfer Mihai Zanfir 2 Alin-Ionut Popa 2 Andrei Zanfir 2 Cristian Sminchisescu 1,2 {mihai.zanfir, alin.popa, andrei.zanfir}@imar.ro cristian.sminchisescu@math.lth.se 1 Department of Mathematics,
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, and Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
 Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields Yaadhav Raaj Haroon Idrees Gines Hidalgo Yaser Sheikh The Robotics Institute, Carnegie Mellon University {raaj@cmu.edu,
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields Yaadhav Raaj Haroon Idrees Gines Hidalgo Yaser Sheikh The Robotics Institute, Carnegie Mellon University {raaj@cmu.edu,
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
 Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image Federica Bogo 2,, Angjoo Kanazawa 3,, Christoph Lassner 1,4, Peter Gehler 1,4, Javier Romero 1, Michael J. Black 1 1 Max
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image Federica Bogo 2,, Angjoo Kanazawa 3,, Christoph Lassner 1,4, Peter Gehler 1,4, Javier Romero 1, Michael J. Black 1 1 Max
arxiv: v5 [cs.cv] 4 Feb 2018
![arxiv: v5 [cs.cv] 4 Feb 2018](/thumbs/78/77842416.jpg "arxiv: v5 [cs.cv] 4 Feb 2018") RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Monocular 3D Human Pose Estimation by Predicting Depth on Joints
 Monocular 3D Human Pose Estimation by Predicting Depth on Joints Bruce Xiaohan Nie 1, Ping Wei 2,1, and Song-Chun Zhu 1 1 Center for Vision, Cognition, Learning, and Autonomy, UCLA, USA 2 Xi an Jiaotong
Monocular 3D Human Pose Estimation by Predicting Depth on Joints Bruce Xiaohan Nie 1, Ping Wei 2,1, and Song-Chun Zhu 1 1 Center for Vision, Cognition, Learning, and Autonomy, UCLA, USA 2 Xi an Jiaotong
arxiv: v4 [cs.cv] 2 Sep 2017
![arxiv: v4 [cs.cv] 2 Sep 2017](/thumbs/81/83455566.jpg "arxiv: v4 [cs.cv] 2 Sep 2017") RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
RMPE: Regional Multi-Person Pose Estimation Hao-Shu Fang 1, Shuqin Xie 1, Yu-Wing Tai 2, Cewu Lu 1 1 Shanghai Jiao Tong University, China 2 Tencent YouTu fhaoshu@gmail.com qweasdshu@sjtu.edu.cn yuwingtai@tencent.com
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields Authors: Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh Presented by: Suraj Kesavan, Priscilla Jennifer ECS 289G: Visual Recognition
Multi-Scale Structure-Aware Network for Human Pose Estimation
 Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Multi-Scale Structure-Aware Network for Human Pose Estimation Lipeng Ke 1, Ming-Ching Chang 2, Honggang Qi 1, Siwei Lyu 2 1 University of Chinese Academy of Sciences, Beijing, China 2 University at Albany,
Multi-Person Pose Estimation with Local Joint-to-Person Associations
 Multi-Person Pose Estimation with Local Joint-to-Person Associations Umar Iqbal and Juergen Gall omputer Vision Group University of Bonn, Germany {uiqbal,gall}@iai.uni-bonn.de Abstract. Despite of the
Multi-Person Pose Estimation with Local Joint-to-Person Associations Umar Iqbal and Juergen Gall omputer Vision Group University of Bonn, Germany {uiqbal,gall}@iai.uni-bonn.de Abstract. Despite of the
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Classifying a specific image region using convolutional nets with an ROI mask as input
 Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Classifying a specific image region using convolutional nets with an ROI mask as input 1 Sagi Eppel Abstract Convolutional neural nets (CNN) are the leading computer vision method for classifying images.
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
An Efficient Convolutional Network for Human Pose Estimation
 RAFI, KOSTRIKOV, GALL, LEIBE: EFFICIENT CNN FOR HUMAN POSE ESTIMATION 1 An Efficient Convolutional Network for Human Pose Estimation Umer Rafi 1 rafi@vision.rwth-aachen.de Ilya Kostrikov 1 ilya.kostrikov@rwth-aachen.de
RAFI, KOSTRIKOV, GALL, LEIBE: EFFICIENT CNN FOR HUMAN POSE ESTIMATION 1 An Efficient Convolutional Network for Human Pose Estimation Umer Rafi 1 rafi@vision.rwth-aachen.de Ilya Kostrikov 1 ilya.kostrikov@rwth-aachen.de
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
arxiv: v2 [cs.cv] 8 Nov 2018
![arxiv: v2 [cs.cv] 8 Nov 2018](/thumbs/93/114381583.jpg "arxiv: v2 [cs.cv] 8 Nov 2018") 3D Human Pose Estimation with 2D Marginal Heatmaps Aiden Nibali Zhen He Stuart Morgan Luke Prendergast La Trobe University, Australia anibali@students.latrobe.edu.au arxiv:1806.01484v2 [cs.cv] 8 Nov 2018
3D Human Pose Estimation with 2D Marginal Heatmaps Aiden Nibali Zhen He Stuart Morgan Luke Prendergast La Trobe University, Australia anibali@students.latrobe.edu.au arxiv:1806.01484v2 [cs.cv] 8 Nov 2018
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera
 Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera Timo von Marcard 1, Roberto Henschel 1, Michael J. Black 2, Bodo Rosenhahn 1, and Gerard Pons-Moll 3 1 Leibniz Universität Hannover,
Recovering Accurate 3D Human Pose in The Wild Using IMUs and a Moving Camera Timo von Marcard 1, Roberto Henschel 1, Michael J. Black 2, Bodo Rosenhahn 1, and Gerard Pons-Moll 3 1 Leibniz Universität Hannover,
Parametric Image Segmentation of Humans with Structural Shape Priors
 Parametric Image Segmentation of Humans with Structural Shape Priors Alin-Ionut Popa 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, cristian.sminchisescu@math.lth.se 1 Department of Mathematics, Faculty
Parametric Image Segmentation of Humans with Structural Shape Priors Alin-Ionut Popa 2, Cristian Sminchisescu 1,2 alin.popa@imar.ro, cristian.sminchisescu@math.lth.se 1 Department of Mathematics, Faculty
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
DensePose: Dense Human Pose Estimation In The Wild
 DensePose: Dense Human Pose Estimation In The Wild Rıza Alp Güler INRIA-CentraleSupélec riza.guler@inria.fr Natalia Neverova Facebook AI Research nneverova@fb.com Iasonas Kokkinos Facebook AI Research
DensePose: Dense Human Pose Estimation In The Wild Rıza Alp Güler INRIA-CentraleSupélec riza.guler@inria.fr Natalia Neverova Facebook AI Research nneverova@fb.com Iasonas Kokkinos Facebook AI Research
arxiv: v1 [cs.cv] 6 Oct 2017
![arxiv: v1 [cs.cv] 6 Oct 2017](/thumbs/79/79518536.jpg "arxiv: v1 [cs.cv] 6 Oct 2017") Human Pose Regression by Combining Indirect Part Detection and Contextual Information arxiv:1710.02322v1 [cs.cv] 6 Oct 2017 Diogo C. Luvizon Abstract In this paper, we propose an end-to-end trainable regression
Human Pose Regression by Combining Indirect Part Detection and Contextual Information arxiv:1710.02322v1 [cs.cv] 6 Oct 2017 Diogo C. Luvizon Abstract In this paper, we propose an end-to-end trainable regression
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand