arxiv: v1 [cs.cv] 16 Oct 2014
|
|
|
- Gabriella Fisher
- 5 years ago
- Views:
Transcription
1 Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2, Stella X. Yu 3, and Pietro Perona 2 arxiv: v1 [cs.cv] 16 Oct TTI Chicago 2 California Institute of Technology 3 University of California at Berkeley / ICSI mmaire@ttic.edu, stellayu@berkeley.edu, perona@caltech.edu Abstract. We frame the task of predicting a semantic labeling as a sparse reconstruction procedure that applies a target-specific learned transfer function to a generic deep sparse code representation of an image. This strategy partitions training into two distinct stages. First, in an unsupervised manner, we learn a set of dictionaries optimized for sparse coding of image patches. These generic dictionaries minimize error with respect to representing image appearance and are independent of any particular target task. We train a multilayer representation via recursive sparse dictionary learning on pooled codes output by earlier layers. Second, we encode all training images with the generic dictionaries and learn a transfer function that optimizes reconstruction of patches extracted from annotated ground-truth given the sparse codes of their corresponding image patches. At test time, we encode a novel image using the generic dictionaries and then reconstruct using the transfer function. The output reconstruction is a semantic labeling of the test image. Applying this strategy to the task of contour detection, we demonstrate performance competitive with state-of-the-art systems. Unlike almost all prior work, our approach obviates the need for any form of hand-designed features or filters. Our model is entirely learned from image and ground-truth patches, with only patch sizes, dictionary sizes and sparsity levels, and depth of the network as chosen parameters. To illustrate the general applicability of our approach, we also show initial results on the task of semantic part labeling of human faces. The effectiveness of our data-driven approach opens new avenues for research on deep sparse representations. Our classifiers utilize this representation in a novel manner. Rather than acting on nodes in the deepest layer, they attach to nodes along a slice through multiple layers of the network in order to make predictions about local patches. Our flexible combination of a generatively learned sparse representation with discriminatively trained transfer classifiers extends the notion of sparse reconstruction to encompass arbitrary semantic labeling tasks. 1 Introduction A multitude of recent work establishes the power of learning hierarchical representations for visual recognition tasks. Noteworthy examples include deep autoencoders [1], deep convolutional networks [2,3], deconvolutional networks [4],
2 2 Maire, Yu, Perona hierarchical sparse coding [5], and multipath sparse coding [6]. Though modeling choices and learning techniques vary, these architectures share the overall strategy of concatenating coding (or convolution) operations followed by pooling operations in a repeating series of layers. Typically, the representation at the topmost layer (or pooled codes from multiple layers [6]) serves as an input feature vector for an auxiliary classifier, such as a support vector machine (SVM), tasked with assigning a category label to the image. Our work is motivated by exploration of the information content of the representation constructed by the rest of the network. While the topmost or pooled features robustly encode object category, what semantics can be extracted from the spatially distributed activations in the earlier network layers? Previous work attacks this question through development of tools for visualizing and probing network behavior [7]. We provide a direct result: a multilayer slice above a particular spatial location contains sufficient information for semantic labeling of a local patch. Combining predicted labels across overlapping patches yields a semantic segmentation of the entire image. In the case of contour detection (regarded as a binary labeling problem), we show that a single layer sparse representation (albeit over multiple image scales and patch sizes) suffices to recover most edges, while a second layer adds the ability to differentiate (and suppress) texture edges. This suggests that contour detection (and its dual problem, image segmentation [8]) emerge implicitly as byproducts of deep representations. Moreover, our reconstruction algorithm is not specific to contours. It is a recipe for transforming a generic sparse representation into a task-specific semantic labeling. We are able to reuse the same multilayer network structure for contours in order to train a system for semantic segmentation of human faces. We make these claims in the specific context of the multipath sparse coding architecture of Bo et al. [6]. We learn sparse codes for different patch resolutions on image input, and, for deeper layers, on pooled and subsampled sparse representations of earlier layers. However, instead of a final step that pools codes into a single feature vector for the entire image, we use the distributed encoding in the setting of sparse reconstruction. This encoding associates a high-dimensional sparse feature vector with each pixel. For the traditional image denoising reconstruction task, convolving these vectors with the patch dictionary from the encoding stage and averaging overlapping areas yields a denoised version of the original image [9]. Our strategy is to instead swap in an entirely different dictionary for use in reconstruction. Here we generalize the notion of dictionary to include any function which takes a sparse feature vector as input and outputs predicted labels for a patch. Throughout the paper, these transfer dictionaries take the form of a set of logistic regression functions: one function for predicting the label of each pixel in the output patch. For a simplified toy example, Figure 1 illustrates the reconstruction obtained with such a dictionary learned for the contour detection task. Figure 2 diagrams the much larger multipath sparse coding network that our actual system uses to generate high-dimensional sparse representations. The
 Rectified Sparse Codes Transfer Dictionary coefficients Contour Detection pixels Reconstruction Fig. 1: Reconstructive sparse code transfer.")
![Top: Applying batch orthogonal matching pursuit (BOMP) [10,11] against a learned appearance dictionary determines a sparse code for each patch in the image.](/docs-images/95/122492349/images/3-1.jpg "We subtract means of patch RGB channels prior to encoding. Bottom: Convolving the sparse code representation with the same dictionary reconstructs a locally zero-mean version of the input image.")
 and simple transfer functions (logistic classifiers) whose coefficients are rendered as a corresponding")
3 Reconstructive Sparse Code Transfer 3 Patch Dictionary Image coefficients Sparse Codes Batch OMP pixels Patch Dictionary Sparse Codes coefficients pixels Reconstruction Reconstructed Image (locally zero-mean) Rectified Sparse Codes Transfer Dictionary coefficients Contour Detection pixels Reconstruction Fig. 1: Reconstructive sparse code transfer. Top: Applying batch orthogonal matching pursuit (BOMP) [10,11] against a learned appearance dictionary determines a sparse code for each patch in the image. We subtract means of patch RGB channels prior to encoding. Bottom: Convolving the sparse code representation with the same dictionary reconstructs a locally zero-mean version of the input image. Alternatively, rectifying the representation and applying a transfer function (learned for contour detection) reconstructs an edge map. For illustrative purposes, we show a small singlelayer dictionary (64 11x11 patches) and simple transfer functions (logistic classifiers) whose coefficients are rendered as a corresponding dictionary. Our deeper representations (Figure 2) are much higher-dimensional and yield better performing, but not easily visualized, transfer functions.

 and encode each using dictionaries learned for different patch sizes and atom counts.")
4 4 Maire, Yu, Perona Multiple Scales Layer 1 Dictionaries 5x5 patches, 64 atoms 11x11 patches, 64 atoms 5x5 patches, 512 atoms 11x11 patches, 512 atoms 21x21 patches, 512 atoms pooling = Layer 2 Dictionaries 5x5 patches, 512 atoms 5x5 patches, 512 atoms rectify, upsample, concatenate sparse activation maps 31x31 patches, 512 atoms = dimensions Contour Reconstruction Sparse Representation Fig. 2: Multipath sparse coding and reconstruction network. We resize an image to 6 different scales (3 shown) and encode each using dictionaries learned for different patch sizes and atom counts. Encoding sparsity is 2 and 4 nonzero coefficients for 64 and 512 atom dictionaries, respectively. The output representation of the smaller dictionaries is pooled, subsampled, and fed to a second sparse coding layer. We then rectify all sparse activation maps, upsample them to the original grid size, and concatenate to form a dimensional sparse representation for each pixel on the image grid. A set of logistic classifiers then transform the sparse vector associated with each pixel (red vertical slice) into a predicted labeling of the surrounding patch (red box). structural similarity to the multipath network of Bo et al. [6] is by design. They tap part of such a network for object recognition; we tap a different part of the network for semantic segmentation. This suggests that it may be possible to use an underlying shared representation for both tasks. In addition to being an implicit aspect of deep representations used for object recognition, our approach to contour detection is entirely free of reliance on hand-crafted features. As Section 2 reviews, this characteristic is unique amongst competing contour detection algorithms. Sections 3, 4, and 5 describe the technical details behind our two-stage approach of sparse coding and reconstructive transfer. Section 6 visualizes and benchmarks results for our primary application of contour detection on the Berkeley segmentation dataset (BSDS) [12]. We also show results for a secondary application of semantic part labeling on the Labeled Faces in the Wild (LFW) dataset [13,14]. Section 7 concludes. 2 Related Work Contour detection has long been a major research focus in computer vision. Arbeláez et al. [8] catalogue a vast set of historical and modern algorithms. Three
5 Reconstructive Sparse Code Transfer 5 different approaches [8,15,16] appear competitive for state-of-the-art accuracy. Arbeláez et al. [8] derive pairwise pixel affinities from local color and texture gradients [17] and apply spectral clustering [18] followed by morphological operations to obtain a global boundary map. Ren and Bo [15] adopt the same pipeline, but use gradients of sparse codes instead of the color and texture gradients developed by Martin et al. [17]. Note that this is completely different from the manner in which we propose to use sparse coding for contour detection. In [15], sparse codes from a dictionary of small 5 5 patches serve as replacement for the textons [19] used in previous work [17,8]. Borrowing the hand-designed filtering scheme of [17], half-discs at multiple orientations act as regions over which codes are pooled into feature vectors and then classified using an SVM. In contrast, we use a range of patch resolutions, from 5 5 to 31 31, without hand-designed gradient operations, in a reconstructive setting through application of a learned transfer dictionary. Our sparse codes assume a role different than that of serving as glorified textons. Dollár and Zitnick [16] learn a random decision forest on feature channels consisting of image color, gradient magnitude at multiple orientations, and pairwise patch differences. They cluster ground-truth edge patches by similarity and train the random forest to predict structured output. The emphasis on describing local edge structure in both [16] and previous work [20,21] matches our intuition. However, sparse coding offers a more flexible methodology for achieving this goal. Unlike [16], we learn directly from image data (not predefined features), in an unsupervised manner, a generic (not contour-specific) representation, which can then be ported to many tasks via a second stage of supervised transfer learning. Mairal et al. [22] use sparse models as the foundation for developing an edge detector. However, they focus on discriminative dictionary training and per-pixel labeling using a linear classifier on feature vectors derived from error residuals during sparse coding of patches. This scheme does not benefit from the spatial averaging of overlapping predictions that occurs in structured output paradigms such as [16] and our proposed algorithm. It also does not incorporate deeper layers of coding, an aspect we find to be crucial for capturing texture characteristics in the sparse representation. Yang et al. [23] study the problem of learning dictionaries for coupled feature spaces with image super-resolution as an application. We share their motivation of utilizing sparse coding in a transfer learning context. As the following sections detail, we differ in our choice of a modular training procedure split into distinct unsupervised (generic) and supervised (transfer) phases. We are unique in targeting contour detection and face part labeling as applications. 3 Sparse Representation Given image I consisting of c channels (c = 3 for an RGB color image) defined over a 2-dimension grid, our sparse coding problem is to represent each m m c patch x I as a sparse linear combination z of elements from a dictionary D = [d 0, d 1,..., d L 1 ] R (m m c) L. From a collection of patches X = [x 0, x 1,...]
6 6 Maire, Yu, Perona randomly sampled from a set of training images, we learn the corresponding sparse representations Z = [z 0, z 1,...] as well as the dictionary D using the MI- KSVD algorithm proposed by Bo et al. [6]. MI-KSVD finds an approximate solution to the following optimization problem: argmin D, Z L 1 X DZ 2 F + λ L 1 i=0 j=0,j i s.t. i, d i 2 = 1 and n, z n 0 K d T i d j where F denotes Frobenius norm and K is the desired sparsity level. MI- KSVD adapts KSVD [24] by balancing reconstruction error with mutual incoherence of the dictionary. This unsupervised training stage is blind to any task-specific uses of the sparse representation. Once the dictionary is fixed, the desired encoding z R L of a novel patch x R m m c is: argmin x Dz 2 s.t. z 0 K (2) z Obtaining the exact optimal z is NP-hard, but the orthogonal matching pursuit (OMP) algorithm [10] is a greedy iterative routine that works well in practice. Over each of K rounds, it selects the dictionary atom (codeword) best correlated with the residual after orthogonal projection onto the span of previously selected codewords. Batch orthogonal matching pursuit [11] precomputes correlations between codewords to significantly speed the process of coding many signals against the same dictionary. We extract the m m patch surrounding each pixel in an image and encode all patches using batch orthogonal matching pursuit. (1) 4 Dictionary Transfer Coding an image I as described in the previous section produces a sparse matrix Z R L N, where N is the number of pixels in the image and each column of Z has at most K nonzeros. Reshaping each of the L rows of Z into a 2-dimensional grid matching the image size, convolving with the corresponding codeword from D, and summing the results approximately reconstructs the original image. Figure 1 (middle) shows an example with the caveat that we drop patch means from the sparse representation and hence also from the reconstruction. Equivalently, one can view D as defining a function that maps a sparse vector z R L associated with a pixel to a predicted patch P R m m c which is superimposed on the surrounding image grid and added to overlapping predictions. We want to replace D with a function F (z) such that applying this procedure with F ( ) produces overlapping patch predictions that, when averaged, reconstruct signal Ĝ which closely approximates some desired ground-truth labeling G. G lives on the same 2-dimensional grid as I, but may differ in number of channels. For contour detection, G is a single-channel binary image indicating presence or absence of an edge at each pixel. For semantic labeling, G may
7 Reconstructive Sparse Code Transfer 7 have as many channels as categories with each channel serving as an indicator function for category presence at every location. We regard choice of F ( ) as a transfer learning problem given examples of sparse representations and corresponding ground-truth, {(Z 0, G 0 ), (Z 1, G 1 ),...}. To further simplify the problem, we consider only patch-wise correspondence. Viewing Z and G as living on the image grid, we sample a collection of patches {g 0, g 1,...} from {G 0, G 1,...} along with the length L sparse coefficient vectors located at the center of each sampled patch, {z 0, z 1,...}. We rectify each of these sparse vectors and append a constant term: ẑ i = [ max(z T i, 0), max( z T i, 0), 1 ] T (3) Our patch-level transfer learning problem is now to find F ( ) such that: F (ẑ i ) g i i (4) where ẑ i R 2L+1 is a vector of sparse coefficients and g i R m m h is a target ground-truth patch. Here, h denotes the number of channels in the ground-truth (and its predicted reconstruction). While one could still choose any method for modeling F ( ), we make an extremely simple and efficient choice, with the expectation that the sparse representation will be rich enough that simple transfer functions will work well. Specifically, we split F ( ) into a set [f 0, f 1,..., f (m2 h 1)] of independently trained predictors f( ), one for each of the m 2 h elements of the output patch. Our transfer learning problem is now: f j (ẑ i ) g i [j] i, j (5) As all experiments in this paper deal with ground-truth in the form of binary indicator vectors, we set each f j ( ) to be a logistic classifier and train its coefficients using L2-regularized logistic regression. Predicting m m patches means that each element of the output reconstruction is an average of outputs from m 2 different f j ( ) classifiers. Moreover, one would expect (and we observe in practice) the accuracy of the classifiers to be spatially varying. Predicted labels of pixels more distant from the patch center are less reliable than those nearby. To correct for this, we weight predicted patches with a Gaussian kernel when spatially averaging them during reconstruction. Additionally, we would like the computation time for prediction to grow more slowly than O(m 2 ) as patch size increases. Because predictions originating from similar spatial locations are likely to be correlated and a Gaussian kernel gives distant neighbors small weight, we construct an adaptive kernel W, which approximates the Gaussian, taking fewer samples with increasing distance, but upweighting them to compensate for decreased sample density. Specifically: W(x, y; σ) = { G(x, y; σ)/ρ(x, y) if (x, y) S 0 otherwise (6)
8 8 Maire, Yu, Perona #nonzeros = Fig. 3: Subsampled patch averaging kernels. Instead of uniformly averaging overlapping patch predictions during reconstruction, we weight them with a Gaussian kernel to model their spatially varying reliability. As a classifier evaluation can be skipped if its prediction will receive zero weight within the averaging procedure, we adaptively sparsify the kernel to achieve a runtime speedup. Using the aggressively subsampled (rightmost) kernel is 3x faster than using the non-subsampled (leftmost) version, and offers equivalent accuracy. We also save the expense of training unused classifiers. where G is a 2D Gaussian, S is a set of sample points, and ρ(x, y) measures the local density of sample points. Figure 3 provides an illustration of W for fixed σ and sampling patterns which repeatedly halve density at various radii. We report all experimental results using the adaptively sampled approximate Gaussian kernel during reconstruction. We found it to perform equivalently to the full Gaussian kernel and better than uniform patch weighting. The adaptive weight kernel not only reduces runtime, but also reduces training time as we neither run nor train the f j ( ) classifiers that the kernel assigns zero weight. 5 Multipath Network Sections 3 and 4 describe our system for reconstructive sparse code transfer in the context of a single generatively learned patch dictionary D and the resulting sparse representation. In practice, we must offer the system a richer view of the input than can be obtained from coding against a single dictionary. To accomplish this, we borrow the multipath sparse coding framework of Bo et al. [6] which combines two strategies for building richer representations. First, the image is rescaled and all scales are coded against multiple dictionaries for patches of varying size. Second, the output sparse representation is pooled, subsampled, and then treated as a new input signal for another layer of sparse coding. Figure 2 describes the network architecture we have chosen in order to implement this strategy. We use rectification followed by hybrid averagemax pooling (the average of nonzero coefficients) between layers 1 and 2. For 5 5 patches, we pool over 3 3 windows and subsample by a factor of 2, while for patches, we pool over 5 5 windows and subsample by a factor of 4. We concatenate all representations generated by the 512-atom dictionaries, rectify, and upsample them so that they live on the original image grid. This results in a dimensional sparse vector representation for each image pixel. Despite the high dimensionality, there are only a few hundred nonzero entries per pixel, so total computational work is quite reasonable.
9 Reconstructive Sparse Code Transfer 9 The dictionary transfer stage described in Section 4 now operates on these high-dimensional concatenated sparse vectors (L = 36000) instead of the output of a single dictionary. Training is more expensive, but classification and reconstruction is still cheap. The cost of evaluating the logistic classifiers scales with the number of nonzero coefficients in the sparse representations rather than the dimensionality. As a speedup for training, we drop a different random 50% of the representation for each of the logistic classifiers. 6 Experiments We apply multipath reconstructive sparse code transfer to two pixel labeling tasks: contour detection on the Berkeley segmentation dataset (BSDS) [12], and semantic labeling of human faces (into skin, hair, and background) on the part subset [14] of the Labeled Faces in the Wild (LFW) dataset [13]. We use the network structure in Figure 2 in both sets of experiments, with the only difference being that we apply a zero-mean transform to patch channels prior to encoding in the BSDS experiments. This choice was simply made to increase dictionary efficiency in the case of contour detection, where absolute color is likely less important. For experiments on the LFW dataset, we directly encode raw patches. 6.1 Contour Detection Figure 4 shows contour detection results on example images from the test set of the 500 image version [8] of the BSDS [12]. Figure 5 shows the precisionrecall curve for our contour detector as benchmarked against human-drawn ground-truth. Performance is comparable to the heavily-engineered state-of-theart global Pb (gpb) detector [8]. Note that both gpb and SCG [15] apply a spectral clustering procedure on top of their detector output in order to generate a cleaner globally consistent result. In both cases, this extra step provides a performance boost. Table 1 displays a more nuanced comparison of our contour detection performance with that of SCG before globalization. Our detector performs comparably to (local) SCG. We expect that inclusion of a sophisticated spectral integration step [25] will further boost our contour detection performance, but leave the proof to future work. It is also worth emphasizing that our system is the only method in Table 1 that relies on neither hand-crafted filters (global Pb, SCG) nor hand-crafted features (global Pb, Structured Edges). Our system is learned entirely from data and even relies on a generatively trained representation as a critical component. Additional analysis of our results yields the interesting observation that the second layer of our multipath network appears crucial to texture understanding. Figure 6 shows a comparison of contour detection results when our system is restricted to use only layer 1 versus results when the system uses the sparse representation from both layers 1 and 2. Inclusion of the second layer (deep sparse coding) essentially allows the classification stage to learn an off switch for texture edges.































































10 10 Maire, Yu, Perona Fig. 4: Contour detection results on BSDS500. We show images and corresponding contours produced via reconstructive sparse code transfer. Contours are displayed prior to applying non-maximal suppression and thinning for benchmarking purposes.
11 Reconstructive Sparse Code Transfer 11 1 Sparse Code Transfer vs Local Methods iso F 1 Sparse Code Transfer vs Global Methods iso F Precision Precision [F = 0.80] Human [F = 0.74] Structured Edges [F = 0.72] local SCG (color) 0.3 [F = 0.71] Sparse Code Transfer Layers [F = 0.69] Sparse Code Transfer Layer [F = 0.69] multiscale Pb [F = 0.60] Canny Edge Detector Recall [F = 0.80] Human [F = 0.74] global SCG (color) 0.3 [F = 0.73] global Pb + UCM 0.1 [F = 0.71] global Pb 0.2 [F = 0.71] Sparse Code Transfer Layers 1+2 [F = 0.69] Sparse Code Transfer Layer Recall Fig. 5: Contour detection performance on BSDS500. Our contour detector (solid 2 P recision Recall red curve) achieves a maximum F-measure ( ) of 0.71, similar to other P recision+recall leading approaches. Table 1 elaborates with more performance metrics. Left: We show full precision-recall curves for algorithms that, like ours, predict boundary strength directly from local image patches. Of these algorithms, sparse code transfer is the only one free of reliance on hand-designed features or filters. Note that addition of the second layer improves our system s performance, as seen in the jump from the blue to red curve. Right: Post-processing steps that perform global reasoning on top of locally detected contours can further boost performance. Application of spectral clustering to multiscale Pb and local SCG yields superior results shown as global Pb and global SCG, respectively. Further transforming global Pb via an Ultrametric Contour Map (UCM) [26] yields an additional boost. Without any such post-processing, our local detector offers performance equivalent to that of global Pb. 0.5 Performance Metric Hand-Designed Spectral ODS F OIS F AP Features? Filters? Globalization? Human Structured Edges [16] yes no no local SCG (color) [15] no yes no Sparse Code Transfer Layers no no no Sparse Code Transfer Layer no no no local SCG (gray) [15] no yes no multiscale Pb [8] yes yes no Canny Edge Detector [27] yes yes no global SCG (color) [15] yes yes yes global Pb + UCM [8] yes yes yes + UCM global Pb [8] yes yes yes Table 1: Contour benchmarks on BSDS500. Performance of our sparse code transfer technique is competitive with the current best performing contour detection systems [8,15,16]. Shown are the detector F-measures when choosing an optimal threshold for the entire dataset (ODS) or per image (OIS), as well as the average precision (AP). The upper block of the table reports scores prior to application of spectral globalization, while the lower block reports improved results of some systems afterwards. Note that our system is the only approach in which both the feature representation and classifier are entirely learned.














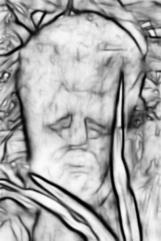
12 12 Maire, Yu, Perona Layer 1 Layers 1+2 Layer 1 Layers 1+2 Fig. 6: Texture understanding and network depth. From left to right, we display an image, the contours detected using only the sparse representation from the layer 1 dictionaries in Figure 2, and the contours detected using the representation from both layers 1 and 2. Inclusion of the second layer is crucial to enabling the system to suppress undesirable fine-scale texture edges. 6.2 Semantic Labeling of Faces Figure 7 shows example results for semantic segmentation of skin, hair, and background classes on the LFW parts dataset using reconstructive sparse code transfer. All results are for our two-layer multipath network. As the default split of the LFW parts dataset allowed images of the same individual to appear in both training and test sets, we randomly re-split the dataset with the constraint that images of a particular individual were either all in the training set or all in the test set, with no overlap. All examples in Figure 7 are from our test set after this more stringent split. Note that while faces are centered in the LFW part dataset images, we directly apply our algorithm and make no attempt to take advantage of this additional information. Hence, for several examples in Figure 7 our learned skin and hair detectors fire on both primary and secondary subjects appearing in the photograph. 7 Conclusion We demonstrate that sparse coding, combined with a reconstructive transfer learning framework, produces results competitive with the state-of-the-art for contour detection. Varying the target of the transfer learning stage allows one to port a common sparse representation to multiple end tasks. We highlight semantic labeling of faces as an additional example. Our approach is entirely data-driven and relies on no hand-crafted features. Sparse representations similar to the one we consider also arise naturally in the context of deep networks for image recognition. We conjecture that multipath sparse networks [6] can produce

















































































13 Reconstructive Sparse Code Transfer 13 Fig. 7: Part labeling results on LFW. Left: Image. Middle: Ground-truth. Semantic classes are skin (green), hair (red), and background (blue). Right: Semantic labeling predicted via reconstructive sparse code transfer.
14 14 Maire, Yu, Perona shared representations useful for many vision tasks and view this as a promising direction for future research. Acknowledgments. ARO/JPL-NASA Stennis NAS supported Michael Maire s work. References 1. Le, Q.V., Ranzato, M., Monga, R., Devin, M., Chen, K., Corrado, G.S., Dean, J., Ng, A.Y.: Building high-level features using large scale unsupervised learning. ICML (2012) 2. LeCun, Y., Kavukcuoglu, K., Farabet, C.: Convolutional networks and applications in vision. ISCAS (2010) 3. Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. NIPS (2012) 4. Zeiler, M.D., Taylor, G.W., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. ICCV (2011) 5. Yu, K., Lin, Y., Lafferty, J.: Learning image representations from the pixel level via hierarchical sparse coding. CVPR (2011) 6. Bo, L., Ren, X., Fox, D.: Multipath sparse coding using hierarchical matching pursuit. CVPR (2013) 7. Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networks. ECCV (2014) 8. Arbeláez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. PAMI (2011) 9. Elad, M., Aharon, M.: Image denoising via sparse and redundant representations over learned dictionaries. IEEE Transactions on Image Processing (2006) 10. Pati, Y.C., Rezaiifar, R., Krishnaprasad, P.S.: Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. Asilomar Conference on Signals, Systems and Computers (1993) 11. Rubinstein, R., Zibulevsky, M., Elad, M.: Efficient implementation of the K-SVD algorithm using batch orthogonal matching pursuit. (2008) 12. Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. ICCV (2001) 13. Huang, G.B., Ramesh, M., Berg, T., Learned-Miller, E.: Labeled faces in the wild: A database for studying face recognition in unconstrained environments. (2007) 14. Kae, A., Sohn, K., Lee, H., Learned-Miller, E.: Augmenting CRFs with Boltzmann machine shape priors for image labeling. CVPR (2013) 15. Ren, X., Bo, L.: Discriminatively trained sparse code gradients for contour detection. NIPS (2012) 16. Dollár, P., Zitnick, C.L.: Structured forests for fast edge detection. ICCV (2013) 17. Martin, D., Fowlkes, C., Malik, J.: Learning to detect natural image boundaries using local brightness, color and texture cues. PAMI (2004) 18. Shi, J., Malik, J.: Normalized cuts and image segmentation. PAMI (2000) 19. Malik, J., Belongie, S., Leung, T., Shi, J.: Contour and texture analysis for image segmentation. IJCV (2001) 20. Ren, X., Fowlkes, C., Malik, J.: Figure/ground assignment in natural images. ECCV (2006)
15 Reconstructive Sparse Code Transfer Lim, J., Zitnick, C.L., Dollár, P.: Sketch tokens: A learned mid-level representation for contour and object detection. CVPR (2013) 22. Mairal, J., Leordeanu, M., Bach, F., Hebert, M., Ponce, J.: Discriminative sparse image models for class-specific edge detection and image interpretation. ECCV (2008) 23. Yang, J., Wang, Z., Lin, Z., Shu, X., Huang, T.: Bilevel sparse coding for coupled feature spaces. CVPR (2012) 24. Aharon, M., Elad, M., Bruckstein, A.: K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Transactions on Signal Processing (2006) 25. Maire, M., Yu, S.X., Perona, P.: Progressive multigrid eigensolvers for multiscale spectral segmentation. ICCV (2013) 26. Arbeláez, P.: Boundary extraction in natural images using ultrametric contour maps. POCV (2006) 27. Canny, J.: A computational approach to edge detection. PAMI (1986)
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling
 Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Reconstructive Sparse Code Transfer for Contour Detection and Semantic Labeling Michael Maire 1,2 Stella X. Yu 3 Pietro Perona 2 1 TTI Chicago 2 California Institute of Technology 3 University of California
Edge Detection Using Convolutional Neural Network
 Edge Detection Using Convolutional Neural Network Ruohui Wang (B) Department of Information Engineering, The Chinese University of Hong Kong, Hong Kong, China wr013@ie.cuhk.edu.hk Abstract. In this work,
Edge Detection Using Convolutional Neural Network Ruohui Wang (B) Department of Information Engineering, The Chinese University of Hong Kong, Hong Kong, China wr013@ie.cuhk.edu.hk Abstract. In this work,
Hierarchical Matching Pursuit for Image Classification: Architecture and Fast Algorithms
 Hierarchical Matching Pursuit for Image Classification: Architecture and Fast Algorithms Liefeng Bo University of Washington Seattle WA 98195, USA Xiaofeng Ren ISTC-Pervasive Computing Intel Labs Seattle
Hierarchical Matching Pursuit for Image Classification: Architecture and Fast Algorithms Liefeng Bo University of Washington Seattle WA 98195, USA Xiaofeng Ren ISTC-Pervasive Computing Intel Labs Seattle
IMAGE SUPER-RESOLUTION BASED ON DICTIONARY LEARNING AND ANCHORED NEIGHBORHOOD REGRESSION WITH MUTUAL INCOHERENCE
 IMAGE SUPER-RESOLUTION BASED ON DICTIONARY LEARNING AND ANCHORED NEIGHBORHOOD REGRESSION WITH MUTUAL INCOHERENCE Yulun Zhang 1, Kaiyu Gu 2, Yongbing Zhang 1, Jian Zhang 3, and Qionghai Dai 1,4 1 Shenzhen
IMAGE SUPER-RESOLUTION BASED ON DICTIONARY LEARNING AND ANCHORED NEIGHBORHOOD REGRESSION WITH MUTUAL INCOHERENCE Yulun Zhang 1, Kaiyu Gu 2, Yongbing Zhang 1, Jian Zhang 3, and Qionghai Dai 1,4 1 Shenzhen
Multipath Sparse Coding Using Hierarchical Matching Pursuit
 Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo, Xiaofeng Ren ISTC Pervasive Computing, Intel Labs Seattle WA 98195, USA {liefeng.bo,xiaofeng.ren}@intel.com Dieter Fox University
Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo, Xiaofeng Ren ISTC Pervasive Computing, Intel Labs Seattle WA 98195, USA {liefeng.bo,xiaofeng.ren}@intel.com Dieter Fox University
Multipath Sparse Coding Using Hierarchical Matching Pursuit
 Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo ISTC-PC Intel Labs liefeng.bo@intel.com Xiaofeng Ren ISTC-PC Intel Labs xren@cs.washington.edu Dieter Fox University of Washington
Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo ISTC-PC Intel Labs liefeng.bo@intel.com Xiaofeng Ren ISTC-PC Intel Labs xren@cs.washington.edu Dieter Fox University of Washington
Multipath Sparse Coding Using Hierarchical Matching Pursuit
 2013 IEEE Conference on Computer Vision and Pattern Recognition Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo ISTC-PC Intel Labs liefeng.bo@intel.com Xiaofeng Ren ISTC-PC Intel
2013 IEEE Conference on Computer Vision and Pattern Recognition Multipath Sparse Coding Using Hierarchical Matching Pursuit Liefeng Bo ISTC-PC Intel Labs liefeng.bo@intel.com Xiaofeng Ren ISTC-PC Intel
arxiv: v1 [cs.lg] 20 Dec 2013
![arxiv: v1 [cs.lg] 20 Dec 2013](/thumbs/89/99594013.jpg "arxiv: v1 [cs.lg] 20 Dec 2013") Unsupervised Feature Learning by Deep Sparse Coding Yunlong He Koray Kavukcuoglu Yun Wang Arthur Szlam Yanjun Qi arxiv:1312.5783v1 [cs.lg] 20 Dec 2013 Abstract In this paper, we propose a new unsupervised
Unsupervised Feature Learning by Deep Sparse Coding Yunlong He Koray Kavukcuoglu Yun Wang Arthur Szlam Yanjun Qi arxiv:1312.5783v1 [cs.lg] 20 Dec 2013 Abstract In this paper, we propose a new unsupervised
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
Edge and Texture. CS 554 Computer Vision Pinar Duygulu Bilkent University
 Edge and Texture CS 554 Computer Vision Pinar Duygulu Bilkent University Filters for features Previously, thinking of filtering as a way to remove or reduce noise Now, consider how filters will allow us
Edge and Texture CS 554 Computer Vision Pinar Duygulu Bilkent University Filters for features Previously, thinking of filtering as a way to remove or reduce noise Now, consider how filters will allow us
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Supervised texture detection in images
 Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Boundaries and Sketches
 Boundaries and Sketches Szeliski 4.2 Computer Vision James Hays Many slides from Michael Maire, Jitendra Malek Today s lecture Segmentation vs Boundary Detection Why boundaries / Grouping? Recap: Canny
Boundaries and Sketches Szeliski 4.2 Computer Vision James Hays Many slides from Michael Maire, Jitendra Malek Today s lecture Segmentation vs Boundary Detection Why boundaries / Grouping? Recap: Canny
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Extended Dictionary Learning : Convolutional and Multiple Feature Spaces
 Extended Dictionary Learning : Convolutional and Multiple Feature Spaces Konstantina Fotiadou, Greg Tsagkatakis & Panagiotis Tsakalides kfot@ics.forth.gr, greg@ics.forth.gr, tsakalid@ics.forth.gr ICS-
Extended Dictionary Learning : Convolutional and Multiple Feature Spaces Konstantina Fotiadou, Greg Tsagkatakis & Panagiotis Tsakalides kfot@ics.forth.gr, greg@ics.forth.gr, tsakalid@ics.forth.gr ICS-
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Fast Edge Detection Using Structured Forests
 Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction
Fast Edge Detection Using Structured Forests Piotr Dollár, C. Lawrence Zitnick [1] Zhihao Li (zhihaol@andrew.cmu.edu) Computer Science Department Carnegie Mellon University Table of contents 1. Introduction
Edge Detection. Computer Vision Shiv Ram Dubey, IIIT Sri City
 Edge Detection Computer Vision Shiv Ram Dubey, IIIT Sri City Previous two classes: Image Filtering Spatial domain Smoothing, sharpening, measuring texture * = FFT FFT Inverse FFT = Frequency domain Denoising,
Edge Detection Computer Vision Shiv Ram Dubey, IIIT Sri City Previous two classes: Image Filtering Spatial domain Smoothing, sharpening, measuring texture * = FFT FFT Inverse FFT = Frequency domain Denoising,
A Simplified Texture Gradient Method for Improved Image Segmentation
 A Simplified Texture Gradient Method for Improved Image Segmentation Qi Wang & M. W. Spratling Department of Informatics, King s College London, London, WC2R 2LS qi.1.wang@kcl.ac.uk Michael.Spratling@kcl.ac.uk
A Simplified Texture Gradient Method for Improved Image Segmentation Qi Wang & M. W. Spratling Department of Informatics, King s College London, London, WC2R 2LS qi.1.wang@kcl.ac.uk Michael.Spratling@kcl.ac.uk
Global Probability of Boundary
 Global Probability of Boundary Learning to Detect Natural Image Boundaries Using Local Brightness, Color, and Texture Cues Martin, Fowlkes, Malik Using Contours to Detect and Localize Junctions in Natural
Global Probability of Boundary Learning to Detect Natural Image Boundaries Using Local Brightness, Color, and Texture Cues Martin, Fowlkes, Malik Using Contours to Detect and Localize Junctions in Natural
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Sparse Coding and Dictionary Learning for Image Analysis
 Sparse Coding and Dictionary Learning for Image Analysis Part IV: Recent Advances in Computer Vision and New Models Francis Bach, Julien Mairal, Jean Ponce and Guillermo Sapiro CVPR 10 tutorial, San Francisco,
Sparse Coding and Dictionary Learning for Image Analysis Part IV: Recent Advances in Computer Vision and New Models Francis Bach, Julien Mairal, Jean Ponce and Guillermo Sapiro CVPR 10 tutorial, San Francisco,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Image Restoration and Background Separation Using Sparse Representation Framework
 Image Restoration and Background Separation Using Sparse Representation Framework Liu, Shikun Abstract In this paper, we introduce patch-based PCA denoising and k-svd dictionary learning method for the
Image Restoration and Background Separation Using Sparse Representation Framework Liu, Shikun Abstract In this paper, we introduce patch-based PCA denoising and k-svd dictionary learning method for the
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A GRAPH-CUT APPROACH TO IMAGE SEGMENTATION USING AN AFFINITY GRAPH BASED ON l 0 SPARSE REPRESENTATION OF FEATURES
 A GRAPH-CUT APPROACH TO IMAGE SEGMENTATION USING AN AFFINITY GRAPH BASED ON l 0 SPARSE REPRESENTATION OF FEATURES Xiaofang Wang Huibin Li Charles-Edmond Bichot Simon Masnou Liming Chen Ecole Centrale de
A GRAPH-CUT APPROACH TO IMAGE SEGMENTATION USING AN AFFINITY GRAPH BASED ON l 0 SPARSE REPRESENTATION OF FEATURES Xiaofang Wang Huibin Li Charles-Edmond Bichot Simon Masnou Liming Chen Ecole Centrale de
DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection
 DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection Gedas Bertasius University of Pennsylvania gberta@seas.upenn.edu Jianbo Shi University of Pennsylvania jshi@seas.upenn.edu
DeepEdge: A Multi-Scale Bifurcated Deep Network for Top-Down Contour Detection Gedas Bertasius University of Pennsylvania gberta@seas.upenn.edu Jianbo Shi University of Pennsylvania jshi@seas.upenn.edu
Contour Detection and Hierarchical Image Segmentation Some Experiments
 Contour Detection and Hierarchical Image Segmentation Some Experiments CS395T Visual Recognition Presented by Elad Liebman Overview Understanding the method better: The importance of thresholding the ouput
Contour Detection and Hierarchical Image Segmentation Some Experiments CS395T Visual Recognition Presented by Elad Liebman Overview Understanding the method better: The importance of thresholding the ouput
CS 534: Computer Vision Segmentation and Perceptual Grouping
 CS 534: Computer Vision Segmentation and Perceptual Grouping Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Outlines Mid-level vision What is segmentation Perceptual Grouping Segmentation
CS 534: Computer Vision Segmentation and Perceptual Grouping Ahmed Elgammal Dept of Computer Science CS 534 Segmentation - 1 Outlines Mid-level vision What is segmentation Perceptual Grouping Segmentation
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
arxiv: v1 [cs.mm] 12 Jan 2016
![arxiv: v1 [cs.mm] 12 Jan 2016](/thumbs/73/69424856.jpg "arxiv: v1 [cs.mm] 12 Jan 2016") Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Learning-based Methods in Vision
 Learning-based Methods in Vision 16-824 Sparsity and Deep Learning Motivation Multitude of hand-designed features currently in use in vision - SIFT, HoG, LBP, MSER, etc. Even the best approaches, just
Learning-based Methods in Vision 16-824 Sparsity and Deep Learning Motivation Multitude of hand-designed features currently in use in vision - SIFT, HoG, LBP, MSER, etc. Even the best approaches, just
CS 2770: Computer Vision. Edges and Segments. Prof. Adriana Kovashka University of Pittsburgh February 21, 2017
 CS 2770: Computer Vision Edges and Segments Prof. Adriana Kovashka University of Pittsburgh February 21, 2017 Edges vs Segments Figure adapted from J. Hays Edges vs Segments Edges More low-level Don t
CS 2770: Computer Vision Edges and Segments Prof. Adriana Kovashka University of Pittsburgh February 21, 2017 Edges vs Segments Figure adapted from J. Hays Edges vs Segments Edges More low-level Don t
Robust Zero Watermarking for Still and Similar Images Using a Learning Based Contour Detection
 Robust Zero Watermarking for Still and Similar Images Using a Learning Based Contour Detection Shahryar Ehsaee and Mansour Jamzad (&) Department of Computer Engineering, Sharif University of Technology,
Robust Zero Watermarking for Still and Similar Images Using a Learning Based Contour Detection Shahryar Ehsaee and Mansour Jamzad (&) Department of Computer Engineering, Sharif University of Technology,
Learning to Recognize Faces in Realistic Conditions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
CS 534: Computer Vision Texture
 CS 534: Computer Vision Texture Ahmed Elgammal Dept of Computer Science CS 534 Texture - 1 Outlines Finding templates by convolution What is Texture Co-occurrence matrices for texture Spatial Filtering
CS 534: Computer Vision Texture Ahmed Elgammal Dept of Computer Science CS 534 Texture - 1 Outlines Finding templates by convolution What is Texture Co-occurrence matrices for texture Spatial Filtering
Detection of a Single Hand Shape in the Foreground of Still Images
 CS229 Project Final Report Detection of a Single Hand Shape in the Foreground of Still Images Toan Tran (dtoan@stanford.edu) 1. Introduction This paper is about an image detection system that can detect
CS229 Project Final Report Detection of a Single Hand Shape in the Foreground of Still Images Toan Tran (dtoan@stanford.edu) 1. Introduction This paper is about an image detection system that can detect
Learning Visual Semantics: Models, Massive Computation, and Innovative Applications
 Learning Visual Semantics: Models, Massive Computation, and Innovative Applications Part II: Visual Features and Representations Liangliang Cao, IBM Watson Research Center Evolvement of Visual Features
Learning Visual Semantics: Models, Massive Computation, and Innovative Applications Part II: Visual Features and Representations Liangliang Cao, IBM Watson Research Center Evolvement of Visual Features
Discriminative sparse model and dictionary learning for object category recognition
 Discriative sparse model and dictionary learning for object category recognition Xiao Deng and Donghui Wang Institute of Artificial Intelligence, Zhejiang University Hangzhou, China, 31007 {yellowxiao,dhwang}@zju.edu.cn
Discriative sparse model and dictionary learning for object category recognition Xiao Deng and Donghui Wang Institute of Artificial Intelligence, Zhejiang University Hangzhou, China, 31007 {yellowxiao,dhwang}@zju.edu.cn
Unsupervised learning in Vision
 Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Chapter 7 Unsupervised learning in Vision The fields of Computer Vision and Machine Learning complement each other in a very natural way: the aim of the former is to extract useful information from visual
Computer Vision I. Announcement. Corners. Edges. Numerical Derivatives f(x) Edge and Corner Detection. CSE252A Lecture 11
 Edge and Corner Detection. CSE252A Lecture 11") Announcement Edge and Corner Detection Slides are posted HW due Friday CSE5A Lecture 11 Edges Corners Edge is Where Change Occurs: 1-D Change is measured by derivative in 1D Numerical Derivatives f(x)
Announcement Edge and Corner Detection Slides are posted HW due Friday CSE5A Lecture 11 Edges Corners Edge is Where Change Occurs: 1-D Change is measured by derivative in 1D Numerical Derivatives f(x)
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Patterns and Computer Vision
 Patterns and Computer Vision Michael Anderson, Bryan Catanzaro, Jike Chong, Katya Gonina, Kurt Keutzer, Tim Mattson, Mark Murphy, David Sheffield, Bor-Yiing Su, Narayanan Sundaram and the rest of the PALLAS
Patterns and Computer Vision Michael Anderson, Bryan Catanzaro, Jike Chong, Katya Gonina, Kurt Keutzer, Tim Mattson, Mark Murphy, David Sheffield, Bor-Yiing Su, Narayanan Sundaram and the rest of the PALLAS
Department of Electronics and Communication KMP College of Engineering, Perumbavoor, Kerala, India 1 2
 Vol.3, Issue 3, 2015, Page.1115-1021 Effect of Anti-Forensics and Dic.TV Method for Reducing Artifact in JPEG Decompression 1 Deepthy Mohan, 2 Sreejith.H 1 PG Scholar, 2 Assistant Professor Department
Vol.3, Issue 3, 2015, Page.1115-1021 Effect of Anti-Forensics and Dic.TV Method for Reducing Artifact in JPEG Decompression 1 Deepthy Mohan, 2 Sreejith.H 1 PG Scholar, 2 Assistant Professor Department
3 October, 2013 MVA ENS Cachan. Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos
 Machine Learning for Computer Vision 1 3 October, 2013 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Department of Applied Mathematics Ecole Centrale
Machine Learning for Computer Vision 1 3 October, 2013 MVA ENS Cachan Lecture 2: Logistic regression & intro to MIL Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Department of Applied Mathematics Ecole Centrale
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Image Segmentation. Lecture14: Image Segmentation. Sample Segmentation Results. Use of Image Segmentation
 Image Segmentation CSED441:Introduction to Computer Vision (2015S) Lecture14: Image Segmentation What is image segmentation? Process of partitioning an image into multiple homogeneous segments Process
Image Segmentation CSED441:Introduction to Computer Vision (2015S) Lecture14: Image Segmentation What is image segmentation? Process of partitioning an image into multiple homogeneous segments Process
Learning the Ecological Statistics of Perceptual Organization
 Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
Learning the Ecological Statistics of Perceptual Organization Charless Fowlkes work with David Martin, Xiaofeng Ren and Jitendra Malik at University of California at Berkeley 1 How do ideas from perceptual
REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY. Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin
 REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin Univ. Grenoble Alpes, GIPSA-Lab, F-38000 Grenoble, France ABSTRACT
REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin Univ. Grenoble Alpes, GIPSA-Lab, F-38000 Grenoble, France ABSTRACT
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
CS6716 Pattern Recognition
 CS6716 Pattern Recognition Aaron Bobick School of Interactive Computing Administrivia PS3 is out now, due April 8. Today chapter 12 of the Hastie book. Slides (and entertainment) from Moataz Al-Haj Three
CS6716 Pattern Recognition Aaron Bobick School of Interactive Computing Administrivia PS3 is out now, due April 8. Today chapter 12 of the Hastie book. Slides (and entertainment) from Moataz Al-Haj Three
Selection of Scale-Invariant Parts for Object Class Recognition
 Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Unsupervised Feature Learning for RGB-D Based Object Recognition
 Unsupervised Feature Learning for RGB-D Based Object Recognition Liefeng Bo 1, Xiaofeng Ren 2, and Dieter Fox 1 1 University of Washington, Seattle, USA {lfb,fox}@cs.washington.edu 2 ISTC-Pervasive Computing
Unsupervised Feature Learning for RGB-D Based Object Recognition Liefeng Bo 1, Xiaofeng Ren 2, and Dieter Fox 1 1 University of Washington, Seattle, USA {lfb,fox}@cs.washington.edu 2 ISTC-Pervasive Computing
Feature Selection for fmri Classification
 Feature Selection for fmri Classification Chuang Wu Program of Computational Biology Carnegie Mellon University Pittsburgh, PA 15213 chuangw@andrew.cmu.edu Abstract The functional Magnetic Resonance Imaging
Feature Selection for fmri Classification Chuang Wu Program of Computational Biology Carnegie Mellon University Pittsburgh, PA 15213 chuangw@andrew.cmu.edu Abstract The functional Magnetic Resonance Imaging
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Discrete-Continuous Gradient Orientation Estimation for Faster Image Segmentation
 Discrete-Continuous Gradient Orientation Estimation for Faster Image Segmentation Michael Donoser and Dieter Schmalstieg Institute for Computer Graphics and Vision Graz University of Technology {donoser,schmalstieg}@icg.tugraz.at
Discrete-Continuous Gradient Orientation Estimation for Faster Image Segmentation Michael Donoser and Dieter Schmalstieg Institute for Computer Graphics and Vision Graz University of Technology {donoser,schmalstieg}@icg.tugraz.at
Learning Dictionaries of Discriminative Image Patches
 Downloaded from orbit.dtu.dk on: Nov 22, 2018 Learning Dictionaries of Discriminative Image Patches Dahl, Anders Bjorholm; Larsen, Rasmus Published in: Proceedings of the British Machine Vision Conference
Downloaded from orbit.dtu.dk on: Nov 22, 2018 Learning Dictionaries of Discriminative Image Patches Dahl, Anders Bjorholm; Larsen, Rasmus Published in: Proceedings of the British Machine Vision Conference
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
 Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING. Nandita M. Nayak, Amit K. Roy-Chowdhury. University of California, Riverside
 LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING Nandita M. Nayak, Amit K. Roy-Chowdhury University of California, Riverside ABSTRACT We present an approach which incorporates spatiotemporal
LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING Nandita M. Nayak, Amit K. Roy-Chowdhury University of California, Riverside ABSTRACT We present an approach which incorporates spatiotemporal
Deep Learning for Generic Object Recognition
 Deep Learning for Generic Object Recognition, Computational and Biological Learning Lab The Courant Institute of Mathematical Sciences New York University Collaborators: Marc'Aurelio Ranzato, Fu Jie Huang,
Deep Learning for Generic Object Recognition, Computational and Biological Learning Lab The Courant Institute of Mathematical Sciences New York University Collaborators: Marc'Aurelio Ranzato, Fu Jie Huang,
arxiv: v1 [cs.cv] 17 May 2016
![arxiv: v1 [cs.cv] 17 May 2016](/thumbs/74/70278059.jpg "arxiv: v1 [cs.cv] 17 May 2016") SemiContour: A Semi-supervised Learning Approach for Contour Detection Zizhao Zhang, Fuyong Xing, Xiaoshuang Shi, Lin Yang University of Florida, Gainesville, FL 32611, USA zizhao@cise.ufl.edu, {f.xing,xsshi2015}@ufl.edu,
SemiContour: A Semi-supervised Learning Approach for Contour Detection Zizhao Zhang, Fuyong Xing, Xiaoshuang Shi, Lin Yang University of Florida, Gainesville, FL 32611, USA zizhao@cise.ufl.edu, {f.xing,xsshi2015}@ufl.edu,
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Bilevel Sparse Coding
 Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Boosting face recognition via neural Super-Resolution
 Boosting face recognition via neural Super-Resolution Guillaume Berger, Cle ment Peyrard and Moez Baccouche Orange Labs - 4 rue du Clos Courtel, 35510 Cesson-Se vigne - France Abstract. We propose a two-step
Boosting face recognition via neural Super-Resolution Guillaume Berger, Cle ment Peyrard and Moez Baccouche Orange Labs - 4 rue du Clos Courtel, 35510 Cesson-Se vigne - France Abstract. We propose a two-step
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
A HMAX with LLC for Visual Recognition
 A HMAX with LLC for Visual Recognition Kean Hong Lau, Yong Haur Tay, Fook Loong Lo Centre for Computing and Intelligent System Universiti Tunku Abdul Rahman, Kuala Lumpur, Malaysia {laukh,tayyh,lofl}@utar.edu.my
A HMAX with LLC for Visual Recognition Kean Hong Lau, Yong Haur Tay, Fook Loong Lo Centre for Computing and Intelligent System Universiti Tunku Abdul Rahman, Kuala Lumpur, Malaysia {laukh,tayyh,lofl}@utar.edu.my
ANALYSIS SPARSE CODING MODELS FOR IMAGE-BASED CLASSIFICATION. Sumit Shekhar, Vishal M. Patel and Rama Chellappa
 ANALYSIS SPARSE CODING MODELS FOR IMAGE-BASED CLASSIFICATION Sumit Shekhar, Vishal M. Patel and Rama Chellappa Center for Automation Research, University of Maryland, College Park, MD 20742 {sshekha, pvishalm,
ANALYSIS SPARSE CODING MODELS FOR IMAGE-BASED CLASSIFICATION Sumit Shekhar, Vishal M. Patel and Rama Chellappa Center for Automation Research, University of Maryland, College Park, MD 20742 {sshekha, pvishalm,
Unsupervised Feature Learning for RGB-D Based Object Recognition
 Unsupervised Feature Learning for RGB-D Based Object Recognition Liefeng Bo, Xiaofeng Ren, and Dieter Fox Abstract Recently introduced RGB-D cameras are capable of providing high quality synchronized videos
Unsupervised Feature Learning for RGB-D Based Object Recognition Liefeng Bo, Xiaofeng Ren, and Dieter Fox Abstract Recently introduced RGB-D cameras are capable of providing high quality synchronized videos
Histograms of Sparse Codes for Object Detection
 Histograms of Sparse Codes for Object Detection Xiaofeng Ren (Amazon), Deva Ramanan (UC Irvine) Presented by Hossein Azizpour What does the paper do? (learning) a new representation local histograms of
Histograms of Sparse Codes for Object Detection Xiaofeng Ren (Amazon), Deva Ramanan (UC Irvine) Presented by Hossein Azizpour What does the paper do? (learning) a new representation local histograms of
Structured Forests for Fast Edge Detection
 2013 IEEE International Conference on Computer Vision Structured Forests for Fast Edge Detection Piotr Dollár Microsoft Research pdollar@microsoft.com C. Lawrence Zitnick Microsoft Research larryz@microsoft.com
2013 IEEE International Conference on Computer Vision Structured Forests for Fast Edge Detection Piotr Dollár Microsoft Research pdollar@microsoft.com C. Lawrence Zitnick Microsoft Research larryz@microsoft.com
Edge detection. Winter in Kraków photographed by Marcin Ryczek
 Edge detection Winter in Kraków photographed by Marcin Ryczek Edge detection Goal: Identify sudden changes (discontinuities) in an image Intuitively, most semantic and shape information from the image
Edge detection Winter in Kraków photographed by Marcin Ryczek Edge detection Goal: Identify sudden changes (discontinuities) in an image Intuitively, most semantic and shape information from the image
Part III: Affinity Functions for Image Segmentation
 Part III: Affinity Functions for Image Segmentation Charless Fowlkes joint work with David Martin and Jitendra Malik at University of California at Berkeley 1 Q: What measurements should we use for constructing
Part III: Affinity Functions for Image Segmentation Charless Fowlkes joint work with David Martin and Jitendra Malik at University of California at Berkeley 1 Q: What measurements should we use for constructing
The goals of segmentation
 Image segmentation The goals of segmentation Group together similar-looking pixels for efficiency of further processing Bottom-up process Unsupervised superpixels X. Ren and J. Malik. Learning a classification
Image segmentation The goals of segmentation Group together similar-looking pixels for efficiency of further processing Bottom-up process Unsupervised superpixels X. Ren and J. Malik. Learning a classification
Edge Detection. CSC320: Introduction to Visual Computing Michael Guerzhoy. René Magritte, Decalcomania. Many slides from Derek Hoiem, Robert Collins
 Edge Detection René Magritte, Decalcomania Many slides from Derek Hoiem, Robert Collins CSC320: Introduction to Visual Computing Michael Guerzhoy Discontinuities in Intensity Source: Robert Collins Origin
Edge Detection René Magritte, Decalcomania Many slides from Derek Hoiem, Robert Collins CSC320: Introduction to Visual Computing Michael Guerzhoy Discontinuities in Intensity Source: Robert Collins Origin
Stacked Multiscale Feature Learning for Domain Independent Medical Image Segmentation
 Stacked Multiscale Feature Learning for Domain Independent Medical Image Segmentation Ryan Kiros, Karteek Popuri, Dana Cobzas, and Martin Jagersand University of Alberta, Canada Abstract. In this work
Stacked Multiscale Feature Learning for Domain Independent Medical Image Segmentation Ryan Kiros, Karteek Popuri, Dana Cobzas, and Martin Jagersand University of Alberta, Canada Abstract. In this work
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Color Image Segmentation
 Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
Edge Detection CSC 767
 Edge Detection CSC 767 Edge detection Goal: Identify sudden changes (discontinuities) in an image Most semantic and shape information from the image can be encoded in the edges More compact than pixels
Edge Detection CSC 767 Edge detection Goal: Identify sudden changes (discontinuities) in an image Most semantic and shape information from the image can be encoded in the edges More compact than pixels
Edge detection. Winter in Kraków photographed by Marcin Ryczek
 Edge detection Winter in Kraków photographed by Marcin Ryczek Edge detection Goal: Identify sudden changes (discontinuities) in an image Intuitively, edges carry most of the semantic and shape information
Edge detection Winter in Kraków photographed by Marcin Ryczek Edge detection Goal: Identify sudden changes (discontinuities) in an image Intuitively, edges carry most of the semantic and shape information
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Recap from Monday. Visualizing Networks Caffe overview Slides are now online
 Recap from Monday Visualizing Networks Caffe overview Slides are now online Today Edges and Regions, GPB Fast Edge Detection Using Structured Forests Zhihao Li Holistically-Nested Edge Detection Yuxin
Recap from Monday Visualizing Networks Caffe overview Slides are now online Today Edges and Regions, GPB Fast Edge Detection Using Structured Forests Zhihao Li Holistically-Nested Edge Detection Yuxin
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
CS 664 Segmentation. Daniel Huttenlocher
 CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
CS 664 Segmentation Daniel Huttenlocher Grouping Perceptual Organization Structural relationships between tokens Parallelism, symmetry, alignment Similarity of token properties Often strong psychophysical
Learning Feature Hierarchies for Object Recognition
 Learning Feature Hierarchies for Object Recognition Koray Kavukcuoglu Computer Science Department Courant Institute of Mathematical Sciences New York University Marc Aurelio Ranzato, Kevin Jarrett, Pierre
Learning Feature Hierarchies for Object Recognition Koray Kavukcuoglu Computer Science Department Courant Institute of Mathematical Sciences New York University Marc Aurelio Ranzato, Kevin Jarrett, Pierre
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Computer Vision I. Announcements. Fourier Tansform. Efficient Implementation. Edge and Corner Detection. CSE252A Lecture 13.
 Announcements Edge and Corner Detection HW3 assigned CSE252A Lecture 13 Efficient Implementation Both, the Box filter and the Gaussian filter are separable: First convolve each row of input image I with
Announcements Edge and Corner Detection HW3 assigned CSE252A Lecture 13 Efficient Implementation Both, the Box filter and the Gaussian filter are separable: First convolve each row of input image I with
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,