Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation
|
|
|
- Patrick Wheeler
- 6 years ago
- Views:
Transcription





![For example, facial characteristics of actors in realistic movies can be manually edited with facial rigs that are carefully designed for manipulating the expression [42].](/docs-images/73/68754321/images/1-5.jpg "While producing animation movies, tracking the geometry of an actor across multiple frames allows transferring the expression to an animated avatar [14, 8, 7].")
1 Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation Matan Sela Elad Richardson Ron Kimmel Department of Computer Science, Technion - Israel Institute of Technology {matansel,eladrich,ron}@cs.technion.ac.il Figure 1: Results of the proposed method. Reconstructed geometries are shown next to the corresponding input images. Abstract It has been recently shown that neural networks can recover the geometric structure of a face from a single given image. A common denominator of most existing face geometry reconstruction methods is the restriction of the solution space to some low-dimensional subspace. While such a model significantly simplifies the reconstruction problem, it is inherently limited in its expressiveness. As an alternative, we propose an Image-to-Image translation network that jointly maps the input image to a depth image and a facial correspondence map. This explicit pixel-based mapping can then be utilized to provide high quality reconstructions of diverse faces under extreme expressions, using a purely geometric refinement process. In the spirit of recent approaches, the network is trained only with synthetic data, and is then evaluated on in-the-wild facial images. Both qualitative and quantitative analyses demonstrate the accuracy and the robustness of our approach. 1. Introduction Recovering the geometric structure of a face is a fundamental task in computer vision with numerous applications. For example, facial characteristics of actors in realistic movies can be manually edited with facial rigs that are carefully designed for manipulating the expression [42]. While producing animation movies, tracking the geometry of an actor across multiple frames allows transferring the expression to an animated avatar [14, 8, 7]. Image-based face recognition methods deform the recovered geometry for producing a neutralized and frontal version of the input face in a given image, reducing the variations between images of the same subject [49, 19]. As for medical applications, acquiring the structure of a face allows for fine planning of aesthetic operations and plastic surgeries, designing of personalized masks [2, 37] and even bio-printing facial organs. Here, we focus on the recovery of the geometric structure of a face from a single facial image under a wide range of expressions and poses. This problem has been investigated for decades and most existing solutions involve one or more of the following components. Facial landmarks [25, 46, 32, 47] - a set of automatically detected key points on the face such as the tip of the nose and the corners of the eyes, which can guide the reconstruction process [49, 26, 1, 12, 29]. A reference facial model - an average neutral face that is used as an initialization of optical flow or shape from shading procedures [19, 26]. A three-dimensional morphable model - a prior lowdimensional linear subspace of plausible facial geometries which allows an efficient, yet rough, recovery of a facial structure [4, 6, 49, 36, 23, 33, 43], While using these components can simplify the reconstruction problem, they introduce some inherent limitations. Methods that rely only on landmarks are limited to a sparse set of constrained points. Classical techniques that use a 1576



![This network is trained following the Image-to-Image translation framework of [22], where an additional normal-based loss is introduced to enhance the depth result.](/docs-images/73/68754321/images/2-3.jpg "Similar to previous approaches, we use synthetic images for training, where the images are sampled from a wide range of facial identities, poses, expressions, lighting conditions, backgrounds and")


2 Non-Rigid Registration Fine Detail Reconstruction Image-to-Image Network Figure 2: The algorithmic reconstruction pipeline. reference facial model might fail to recover extreme expressions and non-frontal poses, as optical flows restrict the deformation to the image plane. The morphable model, while providing some robustness, limits the reconstruction as it can express only coarse geometries. Integrating some of these components together could mitigate the problems, yet, the underlying limitations are still manifested in the final reconstruction. Alternatively, we propose an unrestricted approach which involves a fully convolutional network that learns to translate an input facial image to a representation containing two maps. The first map is an estimation of a depth image, while the second is an embedding of a facial template mesh in the image domain. This network is trained following the Image-to-Image translation framework of [22], where an additional normal-based loss is introduced to enhance the depth result. Similar to previous approaches, we use synthetic images for training, where the images are sampled from a wide range of facial identities, poses, expressions, lighting conditions, backgrounds and material parameters. Surprisingly, even though the network is still trained with faces that are drawn from a limited generative model, it can generalize and produce structures far and beyond the limited scope of that model. To process the raw network results, an iterative facial deformation procedure is used which combines the representations into a full facial mesh. Finally, a refinement step is applied to produce a detailed reconstruction. This novel blending of neural networks with purely geometric techniques allows us to reconstruct highquality meshes with wrinkles and details at a mesoscopiclevel from only a single image. While using a neural network for face reconstruction was proposed in the past [33, 34, 43, 48, 24], previous methods were still limited by the expressiveness of the linear model. In [34], a second network was proposed to refine the coarse facial reconstruction, yet, it could not compensate for large geometric variations beyond the given subspace. For example, the structure of the nose was still limited by the span of a facial morphable model. By learning the unconstrained geometry directly in the image domain, we overcome this limitation, as demonstrated by both quantitative and qualitative experimental results. To further analyze the potential of the proposed representation we devise an application for translating images from one domain to another. As a case study, we transform synthetic facial images into realistic ones, enforcing our network as a loss function to preserve the geometry throughout the cross domain mapping. The main contributions of this paper are: A novel formulation for predicting a geometric representation of a face from a single image, which is not restricted to a linear model. A purely geometric deformation and refinement procedure that utilizes the network representation to produce high quality facial reconstructions. A novel application of the proposed network which allows translating synthetic facial images into realistic ones, while keeping the geometric structure intact. 1577



3 2. Overview The algorithmic pipeline is presented in Figure 2. The input of the network is a facial image, and the network produces two outputs: The first is an estimated depth map aligned with the input image. The second output is a dense map from each pixel to a corresponding vertex on a reference facial mesh. To bring the results into full vertex correspondence and complete occluded parts of the face, we warp a template mesh in the three-dimensional space by an iterative non-rigid deformation procedure. Finally, a fine detail reconstruction algorithm guided by the input image recovers the subtle geometric structure of the face. Code for evaluation is available at matansel/pix2vertex. 3. Learning the Geometric Representation There are several design choices to consider when working with neural networks. First and foremost is the training data, including the input channels, their labels, and how to gather the samples. Second is the choice of the architecture. A common approach is to start from an existing architecture [27, 39, 40, 20] and to adapt it to the problem at hand. Finally, there is the choice of the training process, including the loss criteria and the optimization technique. Next, we describe our choices for each of these elements The Data and its Representation The purpose of the suggested network is to regress a geometric representation from a given facial image. This representation is composed of the following two components: Depth Image A depth profile of the facial geometry. Indeed, for many facial reconstruction tasks providing only the depth profile is sufficient [18, 26]. Correspondence Map An embedding which allows mapping image pixels to points on a template facial model, given as a triangulated mesh. To compute this signature for any facial geometry, we paint each vertex with the x, y, and z coordinates of the corresponding point on a normalized canonical face. Then, we paint each pixel in the map Figure 3: A reference template face presented alongside the dense correspondence signature from different viewpoints. Figure 4: Training data samples alongside their representations. with the color value of the corresponding projected vertex, see Figure 3. This feature map is a deformation agnostic representation, which is useful for applications such as facial motion capture [44], face normalization [49] and texture mapping [50]. While a similar representation was used in [34, 48] as feedback channel for an iterative network, the facial recovery was still restricted to the span of a facial morphable model. For training the network, we adopt the same synthetic data generation procedure proposed in [33]. Each random face is generated by drawing random mesh coordinates S and texture T from a facial morphable model [4]. In practice, we draw a pair of Gaussian random vectors,α g andα t, and recover the synthetic face as follows S = µ g +A g α g T = µ t +A t α t. where µ g and µ t are the stacked average facial geometry and texture of the model, respectively. A g and A t are matrices whose columns are the bases of low-dimensional linear subspaces spanning plausible facial geometries and textures, respectively. Notice that geometry basis A g is composed to both identity and expression basis elements, as proposed in [10]. Next, we render the random textured meshes under various illumination conditions and poses, generating a dataset of synthetic facial images. As the ground-truth geometry is known for each synthetic image, one readily has the matching depth and correspondence maps to use as labels. Some examples of input images alongside their desired outputs are shown in Figure 4. Working with synthetic data can still present some gaps when generalizing to in-the-wild images [9, 33], however it provides much-needed flexibility in the generation process and ensures a deterministic connection from an image to its label. Alternatively, other methods [16, 43] proposed to generate training data by employing existing reconstruction algorithms and regarding their results as ground-truth 1578
![labels. For example, Güler et al. [16], used a framework similar to that of [48] to match dense correspondence maps to a dataset of facial images, starting from only a sparse set of landmarks.](/docs-images/73/68754321/images/4-0.jpg "These correspondence maps were then used as training labels for their method. Notice that such data can also be used for training our network without requiring any other modification. 3.2.")
![Image to Geometry Translation Pixel-wise prediction requires a proper network architecture [30, 17].](/docs-images/73/68754321/images/4-1.jpg "The proposed structure is inspired by the recent Image-to-Image translation framework proposed in [22], where a network was trained to map the input image to output images of various types.")
![The architecture used there is based on the U-net [35] layout, where skip connections are used between corresponding layers in the encoder and the decoder.](/docs-images/73/68754321/images/4-2.jpg "Additional considerations as to the network implementation are given in the supplementary.")
4 labels. For example, Güler et al. [16], used a framework similar to that of [48] to match dense correspondence maps to a dataset of facial images, starting from only a sparse set of landmarks. These correspondence maps were then used as training labels for their method. Notice that such data can also be used for training our network without requiring any other modification Image to Geometry Translation Pixel-wise prediction requires a proper network architecture [30, 17]. The proposed structure is inspired by the recent Image-to-Image translation framework proposed in [22], where a network was trained to map the input image to output images of various types. The architecture used there is based on the U-net [35] layout, where skip connections are used between corresponding layers in the encoder and the decoder. Additional considerations as to the network implementation are given in the supplementary. While in [22] a combination of L 1 and adversarial loss functions were used, in the proposed framework, we chose to omit the adversarial loss. That is because unlike the problems explored in [22], our setup includes less ambiguity in the mapping. Hence, a distributional loss function is less effective, and mainly introduces artifacts. Still, since the basic L 1 loss function favors sparse errors in the depth prediction and does not account for differences between pixel neighborhoods, it is insufficient for producing fine geometric structures, see Figure 5b. Hence, we propose to augment the loss function with an additional L 1 term, which penalizes the discrepancy between the normals of the reconstructed depth and ground truth. L N (ẑ,z) = n(ẑ) n(z) 1, (1) where ẑ is the recovered depth, and z denotes the groundtruth depth image. During training we set λ L1 = 100 and λ N = 10, whereλ L1 andλ N are the matching loss weights. Note that for the correspondence image only thel 1 loss was applied. Figure 5 demonstrates the contribution of the L N to the quality of the depth reconstruction provided by the network. (a) (b) (c) Figure 5: (a) the input image, (b) the result with only thel 1 loss function and (c) the result with the additional normals loss function. Note the artifacts in (b). 4. From Representations to a Mesh Based on the resulting depth and correspondence we introduce an approach to translate the 2.5D representation to a 3D facial mesh. The procedure is composed of an iterative elastic deformation algorithm (4.1) followed by a fine detail recovery step driven by the input image (4.2). The resulting output is an accurate reconstructed facial mesh with a full vertex correspondence to a template mesh with fixed triangulation. This type of data is helpful for various dynamic facial processing applications, such as facial rigs, which allows creating and editing photo-realistic animations of actors. As a byproduct, this process also corrects the prediction of the network by completing domains in the face which are mistakenly classified as part of the background Non Rigid Registration Next, we describe the iterative deformation-based registration pipeline. First, we turn the depth map from the network into a mesh, by connecting neighboring pixels. Based on the correspondence map from the network, we compute the affine transformation from a template face to the mesh. This operation is done by minimizing the squared Euclidean distances between corresponding vertex pairs. Next, similar to [28], an iterative non-rigid registration process deforms the transformed template, aligning it with the mesh. Note that throughout the registration, only the template is warped, while the target mesh remains fixed. Each iteration involves the following four steps. 1. Each vertex in the template mesh, v i V, is associated with a vertex, c i, on the target mesh, by evaluating the nearest neighbor in the correspondence embedding space. This step is different from the method described in [28], which computes the nearest neighbor in the Euclidean space. As a result, the proposed step allows registering a single template face to different facial identities with arbitrary expressions. 2. Pairs, (v i,c i ), which are physically distant and those whose normal directions disagree are detected and ignored in the next step. 3. The template mesh is deformed by minimizing the following energy E(V,C) = α p2point v i c i 2 2 (v i,c i) J +α p2plane +α memb (v i,c i) J i V v j N(v i) n(c i )(v i c i ) 2 w i,j v i v j 2 2, (2) where, w i,j is the weight corresponding to the biharmonic Laplacian operator (see [21, 5]), n(c i ) is the 1579


5 normal of the corresponding vertex at the target mesh c i,j is the set of the remaining associated vertex pairs (v i,c i ), and N(v i ) is the set 1-ring neighboring vertices about the vertex v i. Notice that the first term above is the sum of squared Euclidean distances between matches. The second term is the distance from the point v i to the tangent plane at the corresponding point of the target mesh. The third term quantifies the stiffness of the mesh. 4. If the motion of the template mesh between the current iteration and the previous one is below a fixed threshold, we divide the weight α memb by two. This relaxes the stiffness term and allows a greater deformation in the next iteration. This iterative process terminates when the stiffness weight is below a given threshold. Further implementation information and parameters of the registration process are provided in the supplementary material. The resulting output of this phase is a deformed template with fixed triangulation, which contains the overall facial structure recovered by the network, yet, is smoother and complete, see the third column of Figure Fine Detail Reconstruction Although the network already recovers some fine geometric details, such as wrinkles and moles, across parts of the face, a geometric approach can reconstruct details at a finer level, on the entire face, independently of the resolution. Here, we propose an approach motivated by the passive-stereo facial reconstruction method suggested in [3]. The underlying assumption here is that subtle geometric structures can be explained by local variations in the image domain. For some skin tissues, such as nevi, this assumption is inaccurate as the intensity variation results from the albedo. In such cases, the geometric structure would be wrongly modified. Still, for most parts of the face, the reconstructed details are consistent with the actual variations in depth. The method begins from an interpolated version of the deformed template. Each vertexv V D is painted with the intensity value of the nearest pixel in the image plane. Since we are interested in recovering small details, only the high spatial frequencies, µ(v), of the texture, τ(v), are taken into consideration in this phase. For computing this frequency band, we subtract the synthesized low frequencies from the original intensity values. This low-pass filtered part can be computed by convolving the texture with a spatially varying Gaussian kernel in the image domain, as originally proposed. In contrast, since this convolution is equivalent to computing the heat distribution upon the shape after time dt, where the initial heat profile is the original texture, we Figure 6: Mesoscopic displacement. From left to right: an input image, the shape after the iterative registration, the high-frequency part of the texture - µ(v), and the final shape. propose to computeµ(v) as µ(v) = τ(v) (I dt g ) 1 τ(v), (3) where I is the identity matrix, g is the cotangent weight discrete Laplacian operator for triangulated meshes [31], and dt is a scalar proportional to the cut-off frequency of the filter. Next, we displace each vertex along its normal direction such that v = v +δ(v) n(v). The step size of the displacement, δ(v), is a combination of a data-driven term, δ µ (v), and a regularization one, δ s (v). The data-driven term is guided by the high-pass filtered part of the texture,µ(v). In practice, we require the local differences in the geometry to be proportional to the local variation in the high frequency band of the texture. For each vertex v, with a normal n(v), and a neighboring vertex v i, the data-driven term is given by δ µ (v) = v i N(v) ( α (v,vi)(µ(v) µ(v i )) α (v,vi) v i N(v) 1 v vi, n(v) v v i where α (v,vi) = exp( v v i ). For further explanation of Equation 4, we refer the reader to the supplementary material of this paper or the implementation details of [3]. Since we move each vertex along the normal direction, triangles could intersect each other, particularly in domains of high curvature. To reduce the probability of such collisions, a regularizing displacement field, δ s (v), is added. This term is proportional to the mean curvature of the original surface, and is equivalent to a single explicit mesh fairing step [11]. The final surface modification is given by ) (4) v = v +(ηδ µ (v)+(1 η)δ s (v)) n(v), (5) for some constantη [0,1]. A demonstration of the results before and after this step is presented in Figure 6 5. Experiments Next, we present evaluations on both the proposed network and the pipeline as a whole, and comparison to different prominent methods of single image based facial reconstruction [26, 49, 34]., 1580


![[45], which contains facial images aligned](/docs-images/73/68754321/images/6-2.jpg "with ground truth depth images.")


























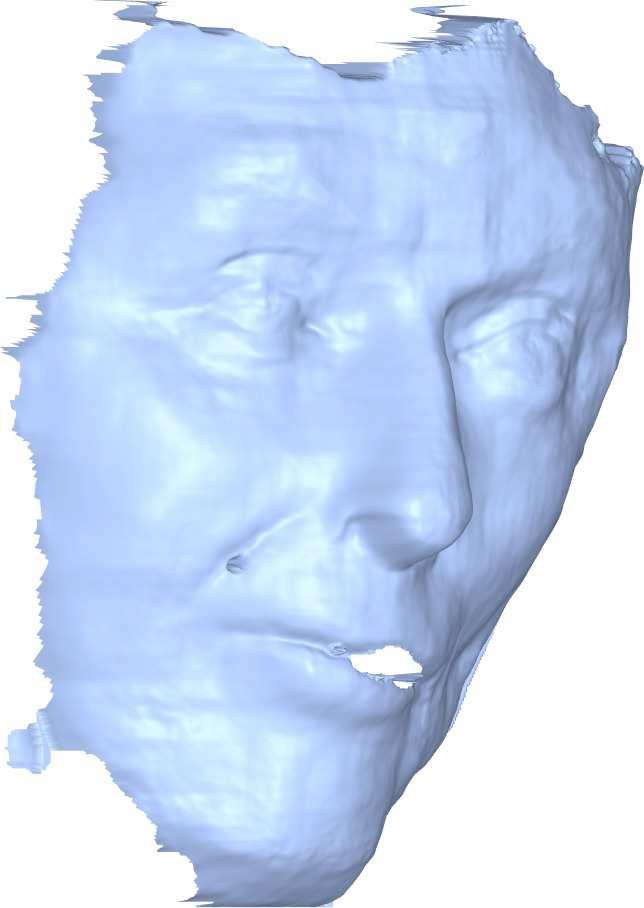


6 5.2. Quantitative Evaluation Figure 7: Network Output. For a quantitative comparison, we used the first 200 subjects from the BU-3DFE dataset [45], which contains facial images aligned with ground truth depth images. Each method provides its own estimation for the depth image alongside a binary mask, representing the valid pixels to be taken into account in the evaluation. Obviously, since the problem of reconstructing depth from a single image is ill-posed, the estimation needs to be judged up to global scaling and transition along the depth axis. Thus, we compute these paramters using the Random Sample Concensus (RANSAC) approach [13], for normalizing the estimation according to the ground truth depth. This significantly reduces the absolute error of each method as the global parameter estimation is robust to outliers. Note that the parameters of the RANSAC were identical for all the methods and samples. The results of this comparison are given in Table 1, where the units are given in terms of the percentile of the ground-truth depth range. As a further analysis of the reconstruction accuracy, we computed the mean absolute error of each method based on expressions, see Table 2. Figure 8: Texture mapping via the embedding Qualitative Evaluation The first component of our algorithm is an Image-to- Image network. In Figure 7, we show samples of output maps produced by the proposed network. Although the network was trained with synthetic data, with simple random backgrounds (see Figure 4), it successfully separates the hair and background from the face itself and learns the corresponding representations. To qualitatively assess the accuracy of the correspondence, we present a visualization where an average facial texture is mapped to the image plane via the predicted embedding, see Figure 8, this shows how the network successfully learns to represent the facial structure. Next, in Figure 9 we show the reconstruction of the network, alongside the registered template and the final shape. Notice how the structural information retrieved by the network is preserved through the geometric stages. Figure 10 shows a qualitative comparison between the proposed method and others. One can see that our method better matches the global structure, as well as the facial details. To better perceive these differences, see Figure 11. Finally, to demonstrate the limited expressiveness of the 3DMM space compared to our method, Figure 12 presents our registered template next to its projection onto the 3DMM space. This clearly shows that our network is able to learn structures which are not spanned by the 3DMM model. Figure 9: The reconstruction stages. From left to right: the input image, the reconstruction of the network, the registered template and the final shape. 1581
![Input Proposed [34] [26] [49]](/docs-images/73/68754321/images/7-0.jpg "Proposed [34] [26] [49] Figure 10:")



![85 3.23 2.93 7.91 [34] 3.61 2.99 2.](/docs-images/73/68754321/images/7-4.jpg "72 6.82 Ours 3.51 2.69 2.65 6.")














![[26] 3.47 4.03 3.94 4.30 3.43 3.](/docs-images/73/68754321/images/7-19.jpg "52 4.19 [49] 4.00 3.93 3.91 3.70 3.")



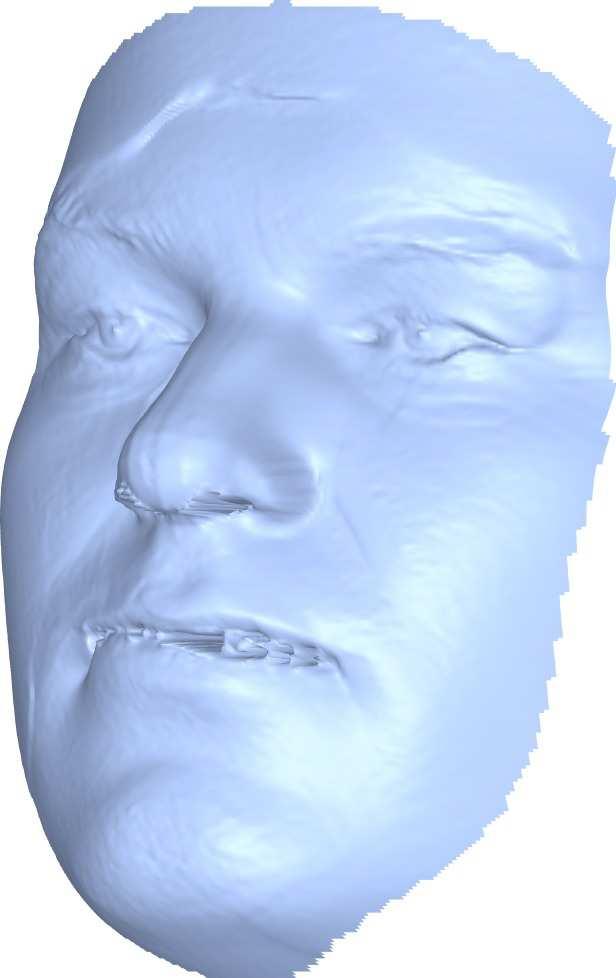
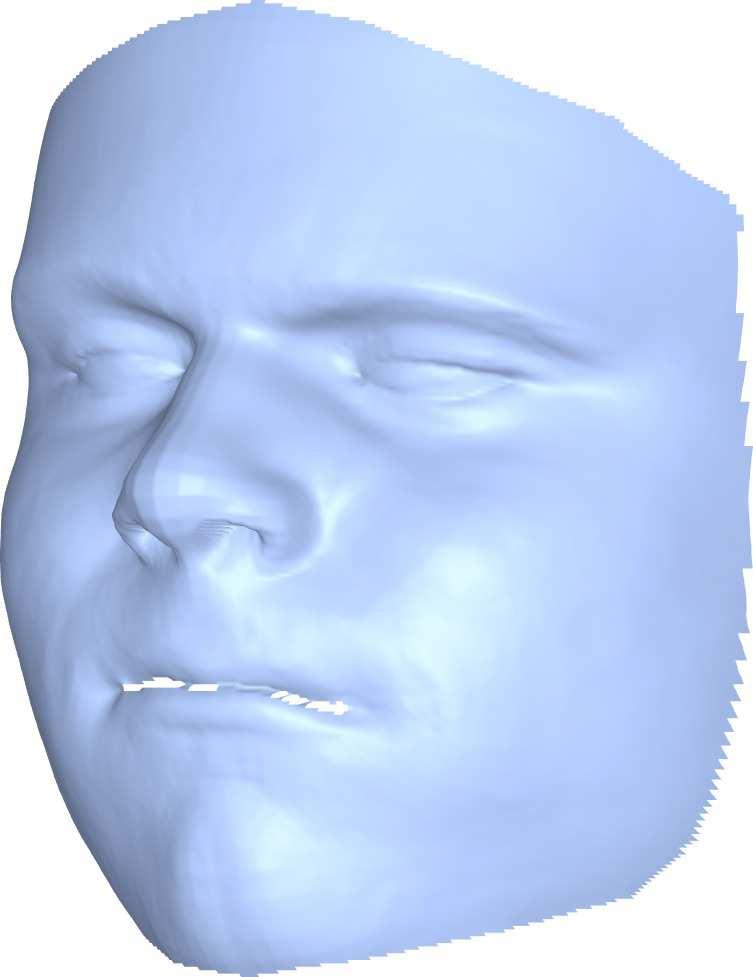
7 Input Proposed [34] [26] [49] Proposed [34] [26] [49] Figure 10: Qualitative comparison. Input images are presented alongside the reconstructions of the different methods. Mean Err. Std Err. Median Err. 90% Err. [26] [49] [34] Ours Table 1: Quantitative evaluation on the BU-3DFE Dataset. From left to right: the absolute depth errors evaluated by mean, standard deviation, median and the average ninety percent largest error. Input Proposed [34] [26] [49] Figure 11: Zoomed qualitative result of first and fourth subjects from Figure The Network as a Geometric Constraint As demonstrated by the results, the proposed network successfully learns both the depth and the embedding representations for a variety of images. This representation is the key part behind the reconstruction pipeline. However, it can also be helpful for other face-related tasks. As an example, we show that the network can be used as a geometric constraint for facial image manipulations, such as transforming synthetic images into realistic ones. This idea AN DI FE HA NE SA SU [26] [49] [34] Ours Table 2: The mean error by expression. From left to right: Anger, Disgust, Fear, Happy, Neutral, Sad, Surprise. is based on recent advances in applying Generative Adversarial Networks (GAN) [15] for domain adaption tasks [41]. In the basic GAN framework, a Generator Network (G) learns to map from the source domain,d S, to the target domain D T, where a Discriminator Network (D) tries to dis- 1582


![following objective min G max D V (D,G) = E y D T [logd(y)] (6) +E x DS [log(1 D(G(x)))].](/docs-images/73/68754321/images/8-2.jpg "Theoretically, this framework could also translate images from the synthetic domain into")



 = Net(x) Net(G(x)) 1, (7) where N et( ) represents the operation of the")



![similarly to [38]. Some successful translations are visualized in Figure 13.](/docs-images/73/68754321/images/8-10.jpg "Notice that the network implicitly learns to add facial hair and teeth, and modify the")









8 Figure 12: 3DMM Projection. From left to right: the input image, the registered template, the projected mesh and the projection error. tinguish between generated images and samples from the target domain, by optimizing the following objective min G max D V (D,G) = E y D T [logd(y)] (6) +E x DS [log(1 D(G(x)))]. Theoretically, this framework could also translate images from the synthetic domain into the realistic one. However, it does not guarantee that the underlying geometry of the synthetic data is preserved throughout that transformation. That is, the generated image might look realistic, but have a completely different facial structure from the synthetic input. To solve that potential inconsistency, we suggest to involve the proposed network as an additional loss function on the output of the generator. L Geom (x) = Net(x) Net(G(x)) 1, (7) where N et( ) represents the operation of the introduced network. Note that this is feasible, thanks to the fact that the proposed network is fully differentiable. The additional geometric fidelity term forces the generator to learn a mapping that makes a synthetic image more realistic while keeping the underlying geometry intact. This translation process could potentially be useful for data generation procedures, similarly to [38]. Some successful translations are visualized in Figure 13. Notice that the network implicitly learns to add facial hair and teeth, and modify the texture the and shading, without changing the facial structure. As demonstrated by this analysis, the proposed network learns a strong representation that has merit not only for reconstruction, but for other tasks as well. 6. Limitations One of the core ideas of this work was a model-free approach, where the solution space is not restricted by a low dimensional subspace. Instead, the Image-to-Image Figure 13: Translation results. From top to bottom: synthetic input images, the correspondence and the depth maps recovered by the network, and the transformed result. network represents the solution in the extremely highdimensional image domain. This structure is learned from synthetic examples, and shown to successfully generalize to in-the-wild images. Still, facial images that significantly deviate from our training domain are challenging, resulting in missing areas and errors inside the representation maps. More specifically, our network has difficulty handling extreme occlusions such as sunglasses, hands or beards, as these were not seen in the training data. Similarly to other methods, reconstructions under strong rotations are also not well handled. Reconstructions under such scenarios are shown in the supplementary material. Another limiting factor of our pipeline is speed. While the suggested network by itself can be applied efficiently, our template registration step is currently not optimized for speed and can take a few minutes to converge. 7. Conclusion We presented an unrestricted approach for recovering the geometric structure of a face from a single image. Our algorithm employs an Image-to-Image network which maps the input image to a pixel-based geometric representation, followed by geometric deformation and refinement steps. The network is trained only by synthetic facial images, yet, is capable of reconstructing real faces. Using the network as a loss function, we propose a framework for translating synthetic facial images into realistic ones while preserving the geometric structure. Acknowledgments We would like to thank Roy Or-El for the helpful discussions and comments. 1583
9 References [1] O. Aldrian and W. A. Smith. A linear approach of 3D face shape and texture recovery using a 3d morphable model. In Proceedings of the British Machine Vision Conference, pages, pages 75 1, [2] I. Amirav, A. S. Luder, A. Halamish, D. Raviv, R. Kimmel, D. Waisman, and M. T. Newhouse. Design of aerosol face masks for children using computerized 3d face analysis. Journal of aerosol medicine and pulmonary drug delivery, 27(4): , [3] T. Beeler, B. Bickel, P. Beardsley, B. Sumner, and M. Gross. High-quality single-shot capture of facial geometry. In ACM SIGGRAPH 2010 Papers, SIGGRAPH 10, pages 40:1 40:9, New York, NY, USA, ACM. [4] V. Blanz and T. Vetter. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, pages ACM Press/Addison-Wesley Publishing Co., [5] M. Botsch and O. Sorkine. On linear variational surface deformation methods. IEEE Transactions on Visualization and Computer Graphics, 14(1): , Jan [6] P. Breuer, K.-I. Kim, W. Kienzle, B. Scholkopf, and V. Blanz. Automatic 3D face reconstruction from single images or video. In Automatic Face & Gesture Recognition, FG 08. 8th IEEE International Conference on, pages 1 8. IEEE, [7] C. Cao, D. Bradley, K. Zhou, and T. Beeler. Real-time highfidelity facial performance capture. ACM Transactions on Graphics (TOG), 34(4):46, [8] C. Cao, Y. Weng, S. Lin, and K. Zhou. 3D shape regression for real-time facial animation. ACM Transactions on Graphics (TOG), 32(4):41, [9] W. Chen, H. Wang, Y. Li, H. Su, D. Lischinsk, D. Cohen-Or, B. Chen, et al. Synthesizing training images for boosting human 3D pose estimation. arxiv preprint arxiv: , [10] B. Chu, S. Romdhani, and L. Chen. 3d-aided face recognition robust to expression and pose variations. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pages IEEE, [11] M. Desbrun, M. Meyer, P. Schröder, and A. H. Barr. Implicit fairing of irregular meshes using diffusion and curvature flow. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIG- GRAPH 99, pages , New York, NY, USA, ACM Press/Addison-Wesley Publishing Co. [12] P. Dou, Y. Wu, S. K. Shah, and I. A. Kakadiaris. Robust 3D face shape reconstruction from single images via two-fold coupled structure learning. In Proc. British Machine Vision Conference, pages 1 13, [13] M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6): , [14] P. Garrido, M. Zollhöfer, D. Casas, L. Valgaerts, K. Varanasi, P. Pérez, and C. Theobalt. Reconstruction of personalized 3D face rigs from monocular video. ACM Transactions on Graphics (TOG), 35(3):28, [15] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, pages , [16] R. A. Güler, G. Trigeorgis, E. Antonakos, P. Snape, S. Zafeiriou, and I. Kokkinos. Densereg: Fully convolutional dense shape regression in-the-wild. arxiv preprint arxiv: , [17] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [18] T. Hassner. Viewing real-world faces in 3d. In Proceedings of the IEEE International Conference on Computer Vision, pages , [19] T. Hassner, S. Harel, E. Paz, and R. Enbar. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [20] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June [21] B. T. Helenbrook. Mesh deformation using the biharmonic operator. International journal for numerical methods in engineering, 56(7): , [22] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Imageto-image translation with conditional adversarial networks. arxiv preprint arxiv: , [23] L. Jiang, J. Zhang, B. Deng, H. Li, and L. Liu. 3d face reconstruction with geometry details from a single image. arxiv preprint arxiv: , [24] A. Jourabloo and X. Liu. Large-pose face alignment via cnn-based dense 3D model fitting. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June [25] V. Kazemi and J. Sullivan. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [26] I. Kemelmacher-Shlizerman and R. Basri. 3D face reconstruction from a single image using a single reference face shape. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(2): , [27] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages , [28] H. Li. Animation Reconstruction of Deformable Surfaces. PhD thesis, ETH Zurich, November [29] F. Liu, D. Zeng, J. Li, and Q. Zhao. Cascaded regressor based 3D face reconstruction from a single arbitrary view image. arxiv preprint arxiv: , [30] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages ,
10 [31] M. Meyer, M. Desbrun, P. Schröder, A. H. Barr, et al. Discrete differential-geometry operators for triangulated 2- manifolds. Visualization and mathematics, 3(2):52 58, [32] S. Ren, X. Cao, Y. Wei, and J. Sun. Face alignment at 3000 fps via regressing local binary features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [33] E. Richardson, M. Sela, and R. Kimmel. 3D face reconstruction by learning from synthetic data. In 3D Vision (3DV), 2016 International Conference on, pages IEEE, [34] E. Richardson, M. Sela, R. Or-El, and R. Kimmel. Learning detailed face reconstruction from a single image. arxiv preprint arxiv: , [35] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages Springer, [36] S. Saito, L. Wei, L. Hu, K. Nagano, and H. Li. Photorealistic facial texture inference using deep neural networks. arxiv preprint arxiv: , [37] M. Sela, N. Toledo, Y. Honen, and R. Kimmel. Customized facial constant positive air pressure (cpap) masks. arxiv preprint arxiv: , [38] A. Shrivastava, T. Pfister, O. Tuzel, J. Susskind, W. Wang, and R. Webb. Learning from simulated and unsupervised images through adversarial training. arxiv preprint arxiv: , [39] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arxiv preprint arxiv: , [40] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1 9, [41] Y. Taigman, A. Polyak, and L. Wolf. Unsupervised crossdomain image generation. arxiv preprint arxiv: , [42] J. Thies, M. Zollhofer, M. Stamminger, C. Theobalt, and M. Nießner. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [43] A. T. Tran, T. Hassner, I. Masi, and G. Medioni. Regressing robust and discriminative 3d morphable models with a very deep neural network. arxiv preprint arxiv: , [44] T. Weise, S. Bouaziz, H. Li, and M. Pauly. Realtime performance-based facial animation. In ACM Transactions on Graphics (TOG), volume 30, page 77. ACM, [45] L. Yin, X. Wei, Y. Sun, J. Wang, and M. J. Rosato. A 3d facial expression database for facial behavior research. In Automatic face and gesture recognition, FGR th international conference on, pages IEEE, [46] Z. Zhang, P. Luo, C. C. Loy, and X. Tang. Facial landmark detection by deep multi-task learning. In European Conference on Computer Vision, pages Springer, [47] E. Zhou, H. Fan, Z. Cao, Y. Jiang, and Q. Yin. Extensive facial landmark localization with coarse-to-fine convolutional network cascade. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages , [48] X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [49] X. Zhu, Z. Lei, J. Yan, D. Yi, and S. Z. Li. High-fidelity pose and expression normalization for face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [50] G. Zigelman, R. Kimmel, and N. Kiryati. Texture mapping using surface flattening via multidimensional scaling. IEEE Transactions on Visualization and Computer Graphics, 8(2): ,
arxiv: v2 [cs.cv] 15 Sep 2017
![arxiv: v2 [cs.cv] 15 Sep 2017](/thumbs/76/73214607.jpg "arxiv: v2 [cs.cv] 15 Sep 2017") Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation Matan Sela Elad Richardson Ron Kimmel Department of Computer Science, Technion - Israel Institute of Technology {matansel,eladrich,ron}@cs.technion.ac.il
Unrestricted Facial Geometry Reconstruction Using Image-to-Image Translation Matan Sela Elad Richardson Ron Kimmel Department of Computer Science, Technion - Israel Institute of Technology {matansel,eladrich,ron}@cs.technion.ac.il
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Synthesizing Realistic Facial Expressions from Photographs
 Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Learning Detailed Face Reconstruction from a Single Image
 Learning Detailed Face Reconstruction from a Single Image Elad Richardson 1 Matan Sela 1 Roy Or-El 2 Ron Kimmel 1 1 Department of Computer Science, Technion - Israel Institute of Technology 2 Department
Learning Detailed Face Reconstruction from a Single Image Elad Richardson 1 Matan Sela 1 Roy Or-El 2 Ron Kimmel 1 1 Department of Computer Science, Technion - Israel Institute of Technology 2 Department
Landmark Weighting for 3DMM Shape Fitting
 Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Morphable Displacement Field Based Image Matching for Face Recognition across Pose
 Morphable Displacement Field Based Image Matching for Face Recognition across Pose Speaker: Iacopo Masi Authors: Shaoxin Li Xin Liu Xiujuan Chai Haihong Zhang Shihong Lao Shiguang Shan Work presented as
Morphable Displacement Field Based Image Matching for Face Recognition across Pose Speaker: Iacopo Masi Authors: Shaoxin Li Xin Liu Xiujuan Chai Haihong Zhang Shihong Lao Shiguang Shan Work presented as
Pix2Face: Direct 3D Face Model Estimation
 Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
De-mark GAN: Removing Dense Watermark With Generative Adversarial Network
 De-mark GAN: Removing Dense Watermark With Generative Adversarial Network Jinlin Wu, Hailin Shi, Shu Zhang, Zhen Lei, Yang Yang, Stan Z. Li Center for Biometrics and Security Research & National Laboratory
De-mark GAN: Removing Dense Watermark With Generative Adversarial Network Jinlin Wu, Hailin Shi, Shu Zhang, Zhen Lei, Yang Yang, Stan Z. Li Center for Biometrics and Security Research & National Laboratory
Supplemental Material for Face Alignment Across Large Poses: A 3D Solution
 Supplemental Material for Face Alignment Across Large Poses: A 3D Solution Xiangyu Zhu 1 Zhen Lei 1 Xiaoming Liu 2 Hailin Shi 1 Stan Z. Li 1 1 Institute of Automation, Chinese Academy of Sciences 2 Department
Supplemental Material for Face Alignment Across Large Poses: A 3D Solution Xiangyu Zhu 1 Zhen Lei 1 Xiaoming Liu 2 Hailin Shi 1 Stan Z. Li 1 1 Institute of Automation, Chinese Academy of Sciences 2 Department
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Supplementary Material for Synthesizing Normalized Faces from Facial Identity Features
 Supplementary Material for Synthesizing Normalized Faces from Facial Identity Features Forrester Cole 1 David Belanger 1,2 Dilip Krishnan 1 Aaron Sarna 1 Inbar Mosseri 1 William T. Freeman 1,3 1 Google,
Supplementary Material for Synthesizing Normalized Faces from Facial Identity Features Forrester Cole 1 David Belanger 1,2 Dilip Krishnan 1 Aaron Sarna 1 Inbar Mosseri 1 William T. Freeman 1,3 1 Google,
arxiv: v1 [cs.cv] 5 Jul 2017
![arxiv: v1 [cs.cv] 5 Jul 2017](/thumbs/95/123923253.jpg "arxiv: v1 [cs.cv] 5 Jul 2017") AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting
 Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
Image Processing Pipeline for Facial Expression Recognition under Variable Lighting Ralph Ma, Amr Mohamed ralphma@stanford.edu, amr1@stanford.edu Abstract Much research has been done in the field of automated
Progress on Generative Adversarial Networks
 Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
From processing to learning on graphs
 From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
From processing to learning on graphs Patrick Pérez Maths and Images in Paris IHP, 2 March 2017 Signals on graphs Natural graph: mesh, network, etc., related to a real structure, various signals can live
arxiv: v1 [cs.cv] 24 Sep 2018
![arxiv: v1 [cs.cv] 24 Sep 2018](/thumbs/92/109456463.jpg "arxiv: v1 [cs.cv] 24 Sep 2018") MobileFace: 3D Face Reconstruction with Efficient CNN Regression Nikolai Chinaev 1, Alexander Chigorin 1, and Ivan Laptev 1,2 arxiv:1809.08809v1 [cs.cv] 24 Sep 2018 1 VisionLabs, Amsterdam, The Netherlands
MobileFace: 3D Face Reconstruction with Efficient CNN Regression Nikolai Chinaev 1, Alexander Chigorin 1, and Ivan Laptev 1,2 arxiv:1809.08809v1 [cs.cv] 24 Sep 2018 1 VisionLabs, Amsterdam, The Netherlands
Face Alignment Across Large Poses: A 3D Solution
 Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images
 Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
Applying Synthetic Images to Learning Grasping Orientation from Single Monocular Images 1 Introduction - Steve Chuang and Eric Shan - Determining object orientation in images is a well-established topic
2D-to-3D Facial Expression Transfer
 2D-to-3D Facial Expression Transfer Gemma Rotger, Felipe Lumbreras, Francesc Moreno-Noguer and Antonio Agudo Computer Vision Center and Dpt. Ciències de la Computació, Universitat Autònoma de Barcelona,
2D-to-3D Facial Expression Transfer Gemma Rotger, Felipe Lumbreras, Francesc Moreno-Noguer and Antonio Agudo Computer Vision Center and Dpt. Ciències de la Computació, Universitat Autònoma de Barcelona,
Abstract We present a system which automatically generates a 3D face model from a single frontal image of a face. Our system consists of two component
 A Fully Automatic System To Model Faces From a Single Image Zicheng Liu Microsoft Research August 2003 Technical Report MSR-TR-2003-55 Microsoft Research Microsoft Corporation One Microsoft Way Redmond,
A Fully Automatic System To Model Faces From a Single Image Zicheng Liu Microsoft Research August 2003 Technical Report MSR-TR-2003-55 Microsoft Research Microsoft Corporation One Microsoft Way Redmond,
Face Transfer with Generative Adversarial Network
 Face Transfer with Generative Adversarial Network Runze Xu, Zhiming Zhou, Weinan Zhang, Yong Yu Shanghai Jiao Tong University We explore the impact of discriminators with different receptive field sizes
Face Transfer with Generative Adversarial Network Runze Xu, Zhiming Zhou, Weinan Zhang, Yong Yu Shanghai Jiao Tong University We explore the impact of discriminators with different receptive field sizes
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Neural Face Editing with Intrinsic Image Disentangling SUPPLEMENTARY MATERIAL
 Neural Face Editing with Intrinsic Image Disentangling SUPPLEMENTARY MATERIAL Zhixin Shu 1 Ersin Yumer 2 Sunil Hadap 2 Kalyan Sunkavalli 2 Eli Shechtman 2 Dimitris Samaras 1,3 1 Stony Brook University
Neural Face Editing with Intrinsic Image Disentangling SUPPLEMENTARY MATERIAL Zhixin Shu 1 Ersin Yumer 2 Sunil Hadap 2 Kalyan Sunkavalli 2 Eli Shechtman 2 Dimitris Samaras 1,3 1 Stony Brook University
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images
 1 3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images Yudong Guo, Juyong Zhang, Jianfei Cai, Boyi Jiang and Jianmin Zheng arxiv:1708.00980v2 [cs.cv] 11 Sep 2017
1 3DFaceNet: Real-time Dense Face Reconstruction via Synthesizing Photo-realistic Face Images Yudong Guo, Juyong Zhang, Jianfei Cai, Boyi Jiang and Jianmin Zheng arxiv:1708.00980v2 [cs.cv] 11 Sep 2017
Light Field Occlusion Removal
 Light Field Occlusion Removal Shannon Kao Stanford University kaos@stanford.edu Figure 1: Occlusion removal pipeline. The input image (left) is part of a focal stack representing a light field. Each image
Light Field Occlusion Removal Shannon Kao Stanford University kaos@stanford.edu Figure 1: Occlusion removal pipeline. The input image (left) is part of a focal stack representing a light field. Each image
Visualization 2D-to-3D Photo Rendering for 3D Displays
 Visualization 2D-to-3D Photo Rendering for 3D Displays Sumit K Chauhan 1, Divyesh R Bajpai 2, Vatsal H Shah 3 1 Information Technology, Birla Vishvakarma mahavidhyalaya,sumitskc51@gmail.com 2 Information
Visualization 2D-to-3D Photo Rendering for 3D Displays Sumit K Chauhan 1, Divyesh R Bajpai 2, Vatsal H Shah 3 1 Information Technology, Birla Vishvakarma mahavidhyalaya,sumitskc51@gmail.com 2 Information
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK
 FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
FACIAL POINT DETECTION USING CONVOLUTIONAL NEURAL NETWORK TRANSFERRED FROM A HETEROGENEOUS TASK Takayoshi Yamashita* Taro Watasue** Yuji Yamauchi* Hironobu Fujiyoshi* *Chubu University, **Tome R&D 1200,
Research Proposal: Computational Geometry with Applications on Medical Images
 Research Proposal: Computational Geometry with Applications on Medical Images MEI-HENG YUEH yueh@nctu.edu.tw National Chiao Tung University 1 Introduction My research mainly focuses on the issues of computational
Research Proposal: Computational Geometry with Applications on Medical Images MEI-HENG YUEH yueh@nctu.edu.tw National Chiao Tung University 1 Introduction My research mainly focuses on the issues of computational
Head Reconstruction from Internet Photos
 Head Reconstruction from Internet Photos Shu Liang, Linda G. Shapiro, Ira Kemelmacher-Shlizerman Computer Science & Engineering Department, University of Washington {liangshu,shapiro,kemelmi}@cs.washington.edu
Head Reconstruction from Internet Photos Shu Liang, Linda G. Shapiro, Ira Kemelmacher-Shlizerman Computer Science & Engineering Department, University of Washington {liangshu,shapiro,kemelmi}@cs.washington.edu
arxiv: v1 [cs.cg] 24 Aug 2018
![arxiv: v1 [cs.cg] 24 Aug 2018](/thumbs/93/113437204.jpg "arxiv: v1 [cs.cg] 24 Aug 2018") High Quality Facial Surface and Texture Synthesis via Generative Adversarial Networks Ron Slossberg 1 *, Gil Shamai 2 *, and Ron Kimmel 1 arxiv:1808.08281v1 [cs.cg] 24 Aug 2018 1 Technion CS department,
High Quality Facial Surface and Texture Synthesis via Generative Adversarial Networks Ron Slossberg 1 *, Gil Shamai 2 *, and Ron Kimmel 1 arxiv:1808.08281v1 [cs.cg] 24 Aug 2018 1 Technion CS department,
Dense 3D Modelling and Monocular Reconstruction of Deformable Objects
 Dense 3D Modelling and Monocular Reconstruction of Deformable Objects Anastasios (Tassos) Roussos Lecturer in Computer Science, University of Exeter Research Associate, Imperial College London Overview
Dense 3D Modelling and Monocular Reconstruction of Deformable Objects Anastasios (Tassos) Roussos Lecturer in Computer Science, University of Exeter Research Associate, Imperial College London Overview
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Deep Learning With Noise
 Deep Learning With Noise Yixin Luo Computer Science Department Carnegie Mellon University yixinluo@cs.cmu.edu Fan Yang Department of Mathematical Sciences Carnegie Mellon University fanyang1@andrew.cmu.edu
Deep Learning With Noise Yixin Luo Computer Science Department Carnegie Mellon University yixinluo@cs.cmu.edu Fan Yang Department of Mathematical Sciences Carnegie Mellon University fanyang1@andrew.cmu.edu
arxiv: v1 [cs.cv] 6 Sep 2018
![arxiv: v1 [cs.cv] 6 Sep 2018](/thumbs/85/92251412.jpg "arxiv: v1 [cs.cv] 6 Sep 2018") arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
Geometric Modeling and Processing
 Geometric Modeling and Processing Tutorial of 3DIM&PVT 2011 (Hangzhou, China) May 16, 2011 4. Geometric Registration 4.1 Rigid Registration Range Scanning: Reconstruction Set of raw scans Reconstructed
Geometric Modeling and Processing Tutorial of 3DIM&PVT 2011 (Hangzhou, China) May 16, 2011 4. Geometric Registration 4.1 Rigid Registration Range Scanning: Reconstruction Set of raw scans Reconstructed
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
arxiv: v2 [cs.cv] 8 Sep 2017
![arxiv: v2 [cs.cv] 8 Sep 2017](/thumbs/73/69323728.jpg "arxiv: v2 [cs.cv] 8 Sep 2017") Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression Aaron S. Jackson 1 Adrian Bulat 1 Vasileios Argyriou 2 Georgios Tzimiropoulos 1 1 The University of Nottingham,
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression Aaron S. Jackson 1 Adrian Bulat 1 Vasileios Argyriou 2 Georgios Tzimiropoulos 1 1 The University of Nottingham,
Deep Learning for Visual Manipulation and Synthesis
 Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Cross-pose Facial Expression Recognition
 Cross-pose Facial Expression Recognition Abstract In real world facial expression recognition (FER) applications, it is not practical for a user to enroll his/her facial expressions under different pose
Cross-pose Facial Expression Recognition Abstract In real world facial expression recognition (FER) applications, it is not practical for a user to enroll his/her facial expressions under different pose
Chapter 7. Conclusions and Future Work
 Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
Chapter 7 Conclusions and Future Work In this dissertation, we have presented a new way of analyzing a basic building block in computer graphics rendering algorithms the computational interaction between
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
arxiv: v1 [cs.cv] 17 Apr 2017
![arxiv: v1 [cs.cv] 17 Apr 2017](/thumbs/90/101630360.jpg "arxiv: v1 [cs.cv] 17 Apr 2017") End-to-end 3D face reconstruction with deep neural networks arxiv:1704.05020v1 [cs.cv] 17 Apr 2017 Pengfei Dou, Shishir K. Shah, and Ioannis A. Kakadiaris Computational Biomedicine Lab University of Houston
End-to-end 3D face reconstruction with deep neural networks arxiv:1704.05020v1 [cs.cv] 17 Apr 2017 Pengfei Dou, Shishir K. Shah, and Ioannis A. Kakadiaris Computational Biomedicine Lab University of Houston
A Morphable Model for the Synthesis of 3D Faces
 A Morphable Model for the Synthesis of 3D Faces Marco Nef Volker Blanz, Thomas Vetter SIGGRAPH 99, Los Angeles Presentation overview Motivation Introduction Database Morphable 3D Face Model Matching a
A Morphable Model for the Synthesis of 3D Faces Marco Nef Volker Blanz, Thomas Vetter SIGGRAPH 99, Los Angeles Presentation overview Motivation Introduction Database Morphable 3D Face Model Matching a
DCGANs for image super-resolution, denoising and debluring
 DCGANs for image super-resolution, denoising and debluring Qiaojing Yan Stanford University Electrical Engineering qiaojing@stanford.edu Wei Wang Stanford University Electrical Engineering wwang23@stanford.edu
DCGANs for image super-resolution, denoising and debluring Qiaojing Yan Stanford University Electrical Engineering qiaojing@stanford.edu Wei Wang Stanford University Electrical Engineering wwang23@stanford.edu
3D Active Appearance Model for Aligning Faces in 2D Images
 3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
Algorithm research of 3D point cloud registration based on iterative closest point 1
 Acta Technica 62, No. 3B/2017, 189 196 c 2017 Institute of Thermomechanics CAS, v.v.i. Algorithm research of 3D point cloud registration based on iterative closest point 1 Qian Gao 2, Yujian Wang 2,3,
Acta Technica 62, No. 3B/2017, 189 196 c 2017 Institute of Thermomechanics CAS, v.v.i. Algorithm research of 3D point cloud registration based on iterative closest point 1 Qian Gao 2, Yujian Wang 2,3,
Visual Recommender System with Adversarial Generator-Encoder Networks
 Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Deep Learning for Virtual Shopping. Dr. Jürgen Sturm Group Leader RGB-D
 Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
Deep Learning for Virtual Shopping Dr. Jürgen Sturm Group Leader RGB-D metaio GmbH Augmented Reality with the Metaio SDK: IKEA Catalogue App Metaio: Augmented Reality Metaio SDK for ios, Android and Windows
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE. Chubu University 1200, Matsumoto-cho, Kasugai, AICHI
 FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
FACIAL POINT DETECTION BASED ON A CONVOLUTIONAL NEURAL NETWORK WITH OPTIMAL MINI-BATCH PROCEDURE Masatoshi Kimura Takayoshi Yamashita Yu Yamauchi Hironobu Fuyoshi* Chubu University 1200, Matsumoto-cho,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
Facial Expression Analysis
 Facial Expression Analysis Jeff Cohn Fernando De la Torre Human Sensing Laboratory Tutorial Looking @ People June 2012 Facial Expression Analysis F. De la Torre/J. Cohn Looking @ People (CVPR-12) 1 Outline
Facial Expression Analysis Jeff Cohn Fernando De la Torre Human Sensing Laboratory Tutorial Looking @ People June 2012 Facial Expression Analysis F. De la Torre/J. Cohn Looking @ People (CVPR-12) 1 Outline
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition
 Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition Feng Liu 1, Ronghang Zhu 1,DanZeng 1, Qijun Zhao 1,, and Xiaoming Liu 2 1 College of Computer Science, Sichuan University
Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition Feng Liu 1, Ronghang Zhu 1,DanZeng 1, Qijun Zhao 1,, and Xiaoming Liu 2 1 College of Computer Science, Sichuan University
An efficient face recognition algorithm based on multi-kernel regularization learning
 Acta Technica 61, No. 4A/2016, 75 84 c 2017 Institute of Thermomechanics CAS, v.v.i. An efficient face recognition algorithm based on multi-kernel regularization learning Bi Rongrong 1 Abstract. A novel
Acta Technica 61, No. 4A/2016, 75 84 c 2017 Institute of Thermomechanics CAS, v.v.i. An efficient face recognition algorithm based on multi-kernel regularization learning Bi Rongrong 1 Abstract. A novel
Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature
 0/19.. Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature Usman Tariq, Jianchao Yang, Thomas S. Huang Department of Electrical and Computer Engineering Beckman Institute
0/19.. Multi-view Facial Expression Recognition Analysis with Generic Sparse Coding Feature Usman Tariq, Jianchao Yang, Thomas S. Huang Department of Electrical and Computer Engineering Beckman Institute
Intensity-Depth Face Alignment Using Cascade Shape Regression
 Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
FaceNet. Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana
 FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
FaceNet Florian Schroff, Dmitry Kalenichenko, James Philbin Google Inc. Presentation by Ignacio Aranguren and Rahul Rana Introduction FaceNet learns a mapping from face images to a compact Euclidean Space
Hybrid Textons: Modeling Surfaces with Reflectance and Geometry
 Hybrid Textons: Modeling Surfaces with Reflectance and Geometry Jing Wang and Kristin J. Dana Electrical and Computer Engineering Department Rutgers University Piscataway, NJ, USA {jingwang,kdana}@caip.rutgers.edu
Hybrid Textons: Modeling Surfaces with Reflectance and Geometry Jing Wang and Kristin J. Dana Electrical and Computer Engineering Department Rutgers University Piscataway, NJ, USA {jingwang,kdana}@caip.rutgers.edu
High-Fidelity Facial and Speech Animation for VR HMDs
 High-Fidelity Facial and Speech Animation for VR HMDs Institute of Computer Graphics and Algorithms Vienna University of Technology Forecast facial recognition with Head-Mounted Display (HMD) two small
High-Fidelity Facial and Speech Animation for VR HMDs Institute of Computer Graphics and Algorithms Vienna University of Technology Forecast facial recognition with Head-Mounted Display (HMD) two small
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Digital Makeup Face Generation
 Digital Makeup Face Generation Wut Yee Oo Mechanical Engineering Stanford University wutyee@stanford.edu Abstract Make up applications offer photoshop tools to get users inputs in generating a make up
Digital Makeup Face Generation Wut Yee Oo Mechanical Engineering Stanford University wutyee@stanford.edu Abstract Make up applications offer photoshop tools to get users inputs in generating a make up
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
3D Face Modelling Under Unconstrained Pose & Illumination
 David Bryan Ottawa-Carleton Institute for Biomedical Engineering Department of Systems and Computer Engineering Carleton University January 12, 2009 Agenda Problem Overview 3D Morphable Model Fitting Model
David Bryan Ottawa-Carleton Institute for Biomedical Engineering Department of Systems and Computer Engineering Carleton University January 12, 2009 Agenda Problem Overview 3D Morphable Model Fitting Model
Motion Tracking and Event Understanding in Video Sequences
 Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Motion Tracking and Event Understanding in Video Sequences Isaac Cohen Elaine Kang, Jinman Kang Institute for Robotics and Intelligent Systems University of Southern California Los Angeles, CA Objectives!
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Face Tracking. Synonyms. Definition. Main Body Text. Amit K. Roy-Chowdhury and Yilei Xu. Facial Motion Estimation
 Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Alignment Under Various Poses and Expressions
 Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
GAN Related Works. CVPR 2018 & Selective Works in ICML and NIPS. Zhifei Zhang
 GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
In Between 3D Active Appearance Models and 3D Morphable Models
 In Between 3D Active Appearance Models and 3D Morphable Models Jingu Heo and Marios Savvides Biometrics Lab, CyLab Carnegie Mellon University Pittsburgh, PA 15213 jheo@cmu.edu, msavvid@ri.cmu.edu Abstract
In Between 3D Active Appearance Models and 3D Morphable Models Jingu Heo and Marios Savvides Biometrics Lab, CyLab Carnegie Mellon University Pittsburgh, PA 15213 jheo@cmu.edu, msavvid@ri.cmu.edu Abstract
arxiv: v3 [cs.cv] 26 Aug 2018 Abstract
![arxiv: v3 [cs.cv] 26 Aug 2018 Abstract](/thumbs/89/98797295.jpg "arxiv: v3 [cs.cv] 26 Aug 2018 Abstract") Nonlinear 3D Face Morphable Model Luan Tran, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {tranluan, liuxm}@msu.edu arxiv:1804.03786v3 [cs.cv]
Nonlinear 3D Face Morphable Model Luan Tran, Xiaoming Liu Department of Computer Science and Engineering Michigan State University, East Lansing MI 48824 {tranluan, liuxm}@msu.edu arxiv:1804.03786v3 [cs.cv]
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
A Global Laplacian Smoothing Approach with Feature Preservation
 A Global Laplacian Smoothing Approach with Feature Preservation hongping Ji Ligang Liu Guojin Wang Department of Mathematics State Key Lab of CAD&CG hejiang University Hangzhou, 310027 P.R. China jzpboy@yahoo.com.cn,
A Global Laplacian Smoothing Approach with Feature Preservation hongping Ji Ligang Liu Guojin Wang Department of Mathematics State Key Lab of CAD&CG hejiang University Hangzhou, 310027 P.R. China jzpboy@yahoo.com.cn,
Stereo and Epipolar geometry
 Previously Image Primitives (feature points, lines, contours) Today: Stereo and Epipolar geometry How to match primitives between two (multiple) views) Goals: 3D reconstruction, recognition Jana Kosecka
Previously Image Primitives (feature points, lines, contours) Today: Stereo and Epipolar geometry How to match primitives between two (multiple) views) Goals: 3D reconstruction, recognition Jana Kosecka
A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation
 , pp.162-167 http://dx.doi.org/10.14257/astl.2016.138.33 A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation Liqiang Hu, Chaofeng He Shijiazhuang Tiedao University,
, pp.162-167 http://dx.doi.org/10.14257/astl.2016.138.33 A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation Liqiang Hu, Chaofeng He Shijiazhuang Tiedao University,
Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition
 Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
Robust Articulated ICP for Real-Time Hand Tracking
 Robust Articulated-ICP for Real-Time Hand Tracking Andrea Tagliasacchi* Sofien Bouaziz Matthias Schröder* Mario Botsch Anastasia Tkach Mark Pauly * equal contribution 1/36 Real-Time Tracking Setup Data
Robust Articulated-ICP for Real-Time Hand Tracking Andrea Tagliasacchi* Sofien Bouaziz Matthias Schröder* Mario Botsch Anastasia Tkach Mark Pauly * equal contribution 1/36 Real-Time Tracking Setup Data
Dynamic 2D/3D Registration for the Kinect
 Dynamic 2D/3D Registration for the Kinect Sofien Bouaziz Mark Pauly École Polytechnique Fédérale de Lausanne Abstract Image and geometry registration algorithms are an essential component of many computer
Dynamic 2D/3D Registration for the Kinect Sofien Bouaziz Mark Pauly École Polytechnique Fédérale de Lausanne Abstract Image and geometry registration algorithms are an essential component of many computer
PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO
 Stefan Krauß, Juliane Hüttl SE, SoSe 2011, HU-Berlin PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO 1 Uses of Motion/Performance Capture movies games, virtual environments biomechanics, sports science,
Stefan Krauß, Juliane Hüttl SE, SoSe 2011, HU-Berlin PERFORMANCE CAPTURE FROM SPARSE MULTI-VIEW VIDEO 1 Uses of Motion/Performance Capture movies games, virtual environments biomechanics, sports science,
The correspondence problem. A classic problem. A classic problem. Deformation-Drive Shape Correspondence. Fundamental to geometry processing
 The correspondence problem Deformation-Drive Shape Correspondence Hao (Richard) Zhang 1, Alla Sheffer 2, Daniel Cohen-Or 3, Qingnan Zhou 2, Oliver van Kaick 1, and Andrea Tagliasacchi 1 July 3, 2008 1
The correspondence problem Deformation-Drive Shape Correspondence Hao (Richard) Zhang 1, Alla Sheffer 2, Daniel Cohen-Or 3, Qingnan Zhou 2, Oliver van Kaick 1, and Andrea Tagliasacchi 1 July 3, 2008 1
DA Progress report 2 Multi-view facial expression. classification Nikolas Hesse
 DA Progress report 2 Multi-view facial expression classification 16.12.2010 Nikolas Hesse Motivation Facial expressions (FE) play an important role in interpersonal communication FE recognition can help
DA Progress report 2 Multi-view facial expression classification 16.12.2010 Nikolas Hesse Motivation Facial expressions (FE) play an important role in interpersonal communication FE recognition can help