Dense 3D Modelling and Monocular Reconstruction of Deformable Objects
|
|
|
- Gwenda Dean
- 5 years ago
- Views:
Transcription

1 Dense 3D Modelling and Monocular Reconstruction of Deformable Objects Anastasios (Tassos) Roussos Lecturer in Computer Science, University of Exeter Research Associate, Imperial College London Overview of Recent & Ongoing Research March
2 Presentation Outline 1 Introduction 2 Model-free Dense 3D Reconstruction from Videos 3 Model-based Dense 3D Reconstruction from Videos 4 Craniofacial Surgery Applications 5 Conclusions 2




3 3D Computer Vision Inference of 3D information from 2D images Wide variety of real-world applications Match Moving Kinect Photo Tourism, Photosynth Dense 3D models of buildings 3




4 3D Computer Vision Inference of 3D information from 2D images Wide variety of real-world applications Faceshift software Avatar motion capture MPI & 3dMD 4D scanner The Digital Emily Project 3

5 3D Computer Vision (Thies et al., Face2Face: Real-time Face Capture and Reenactment of RGB Videos, CVPR 16). 4
6 3D Computer Vision: Limitations Assumption of rigidity: input 2D images: different viewpoints of exactly the same 3D scene Multi-camera systems: equivalent to single camera capturing a rigid scene expensive acquisition setups Active sensors: limitations in the acquisition conditions Specific class of objects: unrealistic shape model priors 5





7 3D Computer Vision: Overcoming the Limitations Core questions: How can we make detailed 3D reconstruction work in any real-world scene? How can we minimise the acquisition requirements? Vision: robust and fast systems that: work under almost any condition use practical, low cost acquisition devices 6






8 3D Computer Vision: Overcoming the Limitations Core questions: How can we make detailed 3D reconstruction work in any real-world scene? How can we minimise the acquisition requirements? Vision: robust and fast systems that: work under almost any condition use practical, low cost acquisition devices Applications: 6
9 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
 model-based: object-specific prior shape")
10 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
 model-based: object-specific prior shape")
11 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
 model-based: object-specific prior shape")
12 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
13 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
 model-based: object-specific prior shape")
14 Dense 3D Reconstruction from Monocular Sequences Input: monocular sequence of non-rigid scene Goal: estimation of 3D location of every pixel at every frame Approaches: model-free: no prior knowledge about the scene object(s) model-based: object-specific prior shape models 7
15 Presentation Outline 1 Introduction 2 Model-free Dense 3D Reconstruction from Videos 3 Model-based Dense 3D Reconstruction from Videos 4 Craniofacial Surgery Applications 5 Conclusions 8
 Leap from sparse to")
 (Garg,Roussos,Agapito, CVPR")
16 Model-free: Non-rigid Structure from Motion (NRSfM) Leap from sparse to dense NRSfM Sparse Dense (Dai,Li,He, CVPR 12) (Garg,Roussos,Agapito, CVPR 13) 9
17 Our Pipeline (Roussos, Russell, Garg, Agapito, IEEE ISMAR 2012) (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013) 10
18 Our Pipeline Step 1: Dense Video Registration (Roussos, Russell, Garg, Agapito, IEEE ISMAR 2012) (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013) 10
 (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013)")
19 Our Pipeline Step 1: Dense Video Registration Step 2: Dense Shape Inference (Roussos, Russell, Garg, Agapito, IEEE ISMAR 2012) (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013) 10
20 Our Pipeline Step 1: Dense Video Registration Priors Step 2: Dense Shape Inference (Roussos, Russell, Garg, Agapito, IEEE ISMAR 2012) (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013) 10
21 Our Pipeline Step 1: Dense Video Registration Low rank. Spatial smoothness. Step 2: Dense Shape Inference (Roussos, Russell, Garg, Agapito, IEEE ISMAR 2012) (Garg, Roussos, Agapito, International Journal of Computer Vision 2013) (Garg, Roussos, Agapito, IEEE CVPR 2013) 10
 Robust")



22 Multi-frame Subspace Flow (MFSF) Robust Subspace Constraints for Video Registration The code is now publicly available at: 11


, : the unknown")

23 Model-Free Dense 3D Reconstruction from Videos : input dense 2D tracks, computed with (Garg,Roussos,Agapito, IJCV 13), : the unknown rotations and shapes per frame = (Garg, Roussos, Agapito, IEEE CVPR 2013) 12

24 Model-Free Dense 3D Reconstruction from Videos (Garg, Roussos, Agapito, IEEE CVPR 2013) 12
25 Model-Free Dense 3D Reconstruction from Videos (Garg, Roussos, Agapito, IEEE CVPR 2013) 12

26 Model-Free Dense 3D Reconstruction from Videos (Garg, Roussos, Agapito, IEEE CVPR 2013) 12


27 Model-Free Dense 3D Reconstruction from Videos (Garg, Roussos, Agapito, IEEE CVPR 2013) 12
28 Energy Minimisation Approach to NRSfM Formulation of a single unified energy to estimate: Orthographic projection matrices 3D shapes for all the frames E (, ) ( ) = λ Edata, ) + E reg ( ) + τ E trace ( reprojection error over all frames spatial smoothness prior on 3D shapes low rank prior on 3D shapes 13
29 Reprojection Error E ( ) ( ) ( ) ( ), = λedata, + Ereg + τetrace E data (, ) = 2 F 14
30 Spatial Smoothness Prior E ( ) ( ) ( ) ( ), = λedata, + Ereg + τetrace E reg ( ) = i TV(S i ) Without regularisation With regularisation 15

31 Low Rank Prior E ( ) ( ) ( ) ( ), = λedata, + Ereg + τetrace E trace ( ) = = i σ i ( ) lies in span K F Angst et al. ECCV 12, Dai et al. CVPR 12, Angst et al. ICCV 11, Dai et al. ECCV 10 16
32 Minimisation of E (, ) min, λ 2 F }{{} Reprojection error + i TV(S i ) }{{} Smoothness prior + τ }{{} Low rank prior 17
33 Minimisation of E (, ) min, λ 2 F }{{} Reprojection error + i TV(S i ) }{{} Smoothness prior + τ }{{} Low rank prior Our Algorithm Initialize and using rigid factorisation. Minimize energy via alternation: Step 1: Rotation estimation. Step 2: Shape estimation. Efficient and highly parallelizable algorithm GPU-friendly 17
34 Minimisation of E (, ) minλ 2 F } {{ } Reprojection error Step 1: Rotation estimation Robust estimation by using dense data. Solved via Levenberg-Marquardt algorithm. Rotations are parametrised as quaternions. 17
35 Minimisation of E (, ) minλ 2 F } {{ } Reprojection error + i TV(S i ) }{{} Smoothness prior + τ }{{} Low rank prior Step 2: Shape estimation Convex sub-problem. Optimisation via alternation between: Per frame shape refinement: using primal dual algorithm Enforcing low rank: using soft impute algorithm. 17

36 Results on real sequences 18
 Non-smooth rotations 4.50% 5.13% 2.60% 3.32% Smooth rotations 6.61% 5.")

37 Quantitative Evaluation Average RMS 3D reconstruction errors. Sequence TB MP Ours Ours(τ = 0) Non-smooth rotations 4.50% 5.13% 2.60% 3.32% Smooth rotations 6.61% 5.81% 2.81% 3.89% - TB: Akhter et al., Trajectory space: A dual representation for NRSfM, PAMI MP: Paladini et al., Optimal metric projections for deformable and articulated SfM, IJCV Synthetic data generated using (Vlasic et al., SIGGRAPH 05). 19
38 Presentation Outline 1 Introduction 2 Model-free Dense 3D Reconstruction from Videos 3 Model-based Dense 3D Reconstruction from Videos 4 Craniofacial Surgery Applications 5 Conclusions 20

39 But what about In-the-wild Videos? Addressing the challenges of unconstrained, everyday-life videos Focusing on human faces 21
 (Booth,")
 (Booth, Roussos, et al.")
40 Our Pipeline Step 1: Dense Video Registration + Face-specific priors Step 2: Dense Shape Inference (Snape, Roussos, Panagakis, Zafeiriou, IEEE ICCV 2015) (Booth, Roussos, Zafeiriou, Ponniah, Dunaway, IEEE CVPR 2016) (Booth, Roussos, Ponniah, Dunaway, Zafeiriou, IJCV 2017, under minor revision) (Booth, Roussos, et al., T-PAMI 2017, submitted) 22

41 Constructing Detailed 3D Face Models: Identity Variation Synthetic faces generated by our LSFM model High-resolution 3D statistical model Automatically built from 10,000 3D scans Largest-scale Morphable Model ever constructed (Booth, Roussos, Zafeiriou, Ponniah, Dunaway, IEEE CVPR 2016) 23













42 Constructing Detailed 3D Face Models: Identity Variation 3D GLOBAL PCA MODEL (INITIAL ESTIMATION) 2D Automatic pruning 3D Auto landmarking NICP dense correspondence LSM-GLOBAL PCA LSM-BESPOKE PCA Fully automatic pipeline State-of-the-art image localisation on synthetic views Natively 3D approach to dense mesh correspondence Building global model but also models tailored by age/gender/ethnicity (Booth, Roussos, Zafeiriou, Ponniah, Dunaway, IEEE CVPR 2016) 24
: extended evaluation added texture model source code for construction pipeline is now available: https://github.")
43 Constructing Detailed 3D Face Models: Identity Variation Update: (Booth, Roussos, Ponniah, Dunaway, Zafeiriou, Large scale 3D Morphable Models, IJCV, under minor revision): extended evaluation added texture model source code for construction pipeline is now available: shape models will be available very soon: 25



44 Evaluation of Model Fitting on 3D Scans BFM: Basel Face Model (Paysan et al. AVSS 09) - Brunton et al.: PCA model of (Brunton et al., CVIU 14) : Proposed LSM, built with varying size of training set ( faces) 26

45 Adding Expression to LSFM models Overall model of identity & expression by effectively combining: identity variation from our LSFM models, with expression variation from (Cao et al., IEEE T-VG 2014) S(p id,p exp ) = µ+u id p id +U exp p exp Synthetised faces, with random identity and expression 27
46 Adding Expression to LSFM models 28
 with first 4 expression coefficients 29")
47 Adding Expression to LSFM models LSFM-bespoke for (White ; over 50 years) with first 4 expression coefficients 29
48 Adding Expression to LSFM models LSFM-bespoke for (Black) with first 4 expression coefficients 30
49 Face Flow: Face-Specific Video Registration (Snape, Roussos, Panagakis, Zafeiriou, IEEE ICCV 2015) 31







50 Face Flow: Face-Specific Video Registration Evaluation on synthetic videos with challenging conditions: (Snape, Roussos, Panagakis, Zafeiriou, IEEE ICCV 2015) 31

51 3DMM Fitting In-The-Wild (ITW) Fitting on single images, under unconstrained conditions 3D shape model of identity + expression Texture models for in-the-wild images 32
52 3DMM Fitting In-The-Wild (ITW) Dense image features Simplified fitting: no need to estimate lighting Robust to illumination changes, occlusions, etc. 33


53 3DMM Fitting In-The-Wild (ITW) Robust PCA with missing values: 33
54 3DMM Fitting In-The-Wild (ITW) Fitting on images: Fast algorithm, AAM-style Source code will be available 34
 Results on 300W:")
55 3DMM Fitting In-The-Wild (ITW) Results on 300W: 35
 Results on 300W:")
56 3DMM Fitting In-The-Wild (ITW) Results on 300W: 35

57 3DMM Fitting In-The-Wild (ITW) New benchmark: Quantitative comparisons: 36

58 3DMM Fitting on In-The-Wild Videos Robust facial landmark tracking Valuable for: initialisation constraints on the dense solution 37
59 3DMM Fitting on In-The-Wild Videos Initialisation via fitting on the sparse tracks: formulate cost function that combines: reprojection error temporal smoothness over expression quadratic priors on identity & expression coefficients minimise wrt camera, identity and expression coefficients simultaneous estimation over all frames automatic fine-tuning of balancing weights of the cost function 38


60 3DMM Fitting on In-The-Wild Videos Initialisation via fitting on the sparse tracks: estimation of camera parameters via rigid Structure from Motion large-scale quadratic optimisation for identity & expression coefficients 39


61 3DMM Fitting on In-The-Wild Videos Results on 300VW database: 40
62 3DMM Fitting on In-The-Wild Videos Using LSFM-bespoke models: 41

63 Presentation Outline 1 Introduction 2 Model-free Dense 3D Reconstruction from Videos 3 Model-based Dense 3D Reconstruction from Videos 4 Craniofacial Surgery Applications 5 Conclusions 42














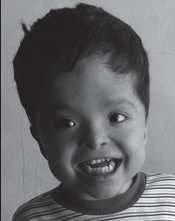
64 Craniofacial Applications Synthetic faces generated by our LSM model Useful for: craniofacial surgery planning and assessment before surgery after surgery 43


65 Comparing Facial Morphology Representations Representations of facial morphology: dense modelling sparse anthropometry Ideally: different shapes different parameters similar shapes similar parameters 44
66 Facial Manifold Visualisation Including syndromic faces 46 scans of patients, including manually annotated landmarks 45

67 Presentation Outline 1 Introduction 2 Model-free Dense 3D Reconstruction from Videos 3 Model-based Dense 3D Reconstruction from Videos 4 Craniofacial Surgery Applications 5 Conclusions 46
68 Conclusions Pioneering methodologies for dense 3D reconstruction from non-rigid videos Non-rigid videos contain extremely rich information most existing methods exploit only part of it 47
69 Conclusions Pioneering methodologies for dense 3D reconstruction from non-rigid videos Non-rigid videos contain extremely rich information most existing methods exploit only part of it Using monocular input only, our methods yield state-of-the-art results on estimating: multiframe optical flow dense dynamic 3D shape joint dense multibody segmentation, tracking and 3D reconstruction 47


70 Conclusions Pioneering methodologies for dense 3D reconstruction from non-rigid videos Non-rigid videos contain extremely rich information most existing methods exploit only part of it Key components: dense variational methods robust penalisers and low-rank matrix priors efficient optimisation approaches highly-detailed and realistic shape priors 47

71 Conclusions Dense 3D face modelling with unprecedented quality large-scale datasets are extremely valuable fully-automated construction pipeline far more diverse than existing models 48
Computer Vision in a Non-Rigid World
 2 nd Tutorial on Computer Vision in a Non-Rigid World Dr. Lourdes Agapito Prof. Adrien Bartoli Dr. Alessio Del Bue Non-rigid Structure from Motion Non-rigid structure from motion To extract non-rigid 3D
2 nd Tutorial on Computer Vision in a Non-Rigid World Dr. Lourdes Agapito Prof. Adrien Bartoli Dr. Alessio Del Bue Non-rigid Structure from Motion Non-rigid structure from motion To extract non-rigid 3D
Supplementary Material Estimating Correspondences of Deformable Objects In-the-wild
 Supplementary Material Estimating Correspondences of Deformable Objects In-the-wild Yuxiang Zhou Epameinondas Antonakos Joan Alabort-i-Medina Anastasios Roussos Stefanos Zafeiriou, Department of Computing,
Supplementary Material Estimating Correspondences of Deformable Objects In-the-wild Yuxiang Zhou Epameinondas Antonakos Joan Alabort-i-Medina Anastasios Roussos Stefanos Zafeiriou, Department of Computing,
A 3D Morphable Model learnt from 10,000 faces
 A 3D Morphable Model learnt from 10,000 faces James Booth Anastasios Roussos Stefanos Zafeiriou, Allan Ponniah David Dunaway Imperial College London, UK Great Ormond Street Hospital, UK Center for Machine
A 3D Morphable Model learnt from 10,000 faces James Booth Anastasios Roussos Stefanos Zafeiriou, Allan Ponniah David Dunaway Imperial College London, UK Great Ormond Street Hospital, UK Center for Machine
Large Scale 3D Morphable Models
 DOI 10.1007/s11263-017-1009-7 Large Scale 3D Morphable Models James Booth 1 Anastasios Roussos 1,3 Allan Ponniah 2 David Dunaway 2 Stefanos Zafeiriou 1 Received: 15 March 2016 / Accepted: 24 March 2017
DOI 10.1007/s11263-017-1009-7 Large Scale 3D Morphable Models James Booth 1 Anastasios Roussos 1,3 Allan Ponniah 2 David Dunaway 2 Stefanos Zafeiriou 1 Received: 15 March 2016 / Accepted: 24 March 2017
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
 MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction Ayush Tewari Michael Zollhofer Hyeongwoo Kim Pablo Garrido Florian Bernard Patrick Perez Christian Theobalt
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Face Flow. Abstract. 1. Introduction
 Face Flow Patrick Snape Anastasios Roussos Yannis Panagakis Stefanos Zafeiriou Department of Computing, Imperial College London 180 Queens Gate, SW7 2AZ, London, U.K {p.snape,troussos,i.panagakis,s.zafeiriou}@imperial.ac.uk
Face Flow Patrick Snape Anastasios Roussos Yannis Panagakis Stefanos Zafeiriou Department of Computing, Imperial College London 180 Queens Gate, SW7 2AZ, London, U.K {p.snape,troussos,i.panagakis,s.zafeiriou}@imperial.ac.uk
Robust Trajectory-Space TV-L1 Optical Flow for Non-rigid Sequences
 Robust Trajectory-Space TV-L1 Optical Flow for Non-rigid Sequences Ravi Garg, Anastasios Roussos, and Lourdes Agapito Queen Mary University of London, Mile End Road, London E1 4NS, UK Abstract. This paper
Robust Trajectory-Space TV-L1 Optical Flow for Non-rigid Sequences Ravi Garg, Anastasios Roussos, and Lourdes Agapito Queen Mary University of London, Mile End Road, London E1 4NS, UK Abstract. This paper
Monocular Tracking and Reconstruction in Non-Rigid Environments
 Monocular Tracking and Reconstruction in Non-Rigid Environments Kick-Off Presentation, M.Sc. Thesis Supervisors: Federico Tombari, Ph.D; Benjamin Busam, M.Sc. Patrick Ruhkamp 13.01.2017 Introduction Motivation:
Monocular Tracking and Reconstruction in Non-Rigid Environments Kick-Off Presentation, M.Sc. Thesis Supervisors: Federico Tombari, Ph.D; Benjamin Busam, M.Sc. Patrick Ruhkamp 13.01.2017 Introduction Motivation:
Piecewise Quadratic Reconstruction of Non-Rigid Surfaces from Monocular Sequences
 Piecewise Quadratic Reconstruction of Non-Rigid Surfaces from Monocular Sequences João Fayad 1, Lourdes Agapito 1, and Alessio Del Bue 2 1 Queen Mary University of London. Mile End Road, London E1 4NS,
Piecewise Quadratic Reconstruction of Non-Rigid Surfaces from Monocular Sequences João Fayad 1, Lourdes Agapito 1, and Alessio Del Bue 2 1 Queen Mary University of London. Mile End Road, London E1 4NS,
Step-by-Step Model Buidling
 Step-by-Step Model Buidling Review Feature selection Feature selection Feature correspondence Camera Calibration Euclidean Reconstruction Landing Augmented Reality Vision Based Control Sparse Structure
Step-by-Step Model Buidling Review Feature selection Feature selection Feature correspondence Camera Calibration Euclidean Reconstruction Landing Augmented Reality Vision Based Control Sparse Structure
Direct-from-Video: Unsupervised NRSf M
 This paper was published at the ECCV workshop on Recovering 6D Object Pose, University of Amsterdam, 9 October 2016. Direct-from-Video: Unsupervised NRSf M Karel Lebeda, Simon Hadfield, Richard Bowden
This paper was published at the ECCV workshop on Recovering 6D Object Pose, University of Amsterdam, 9 October 2016. Direct-from-Video: Unsupervised NRSf M Karel Lebeda, Simon Hadfield, Richard Bowden
Pix2Face: Direct 3D Face Model Estimation
 Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
Pix2Face: Direct 3D Face Model Estimation Daniel Crispell Maxim Bazik Vision Systems, Inc Providence, RI USA danielcrispell, maximbazik@visionsystemsinccom Abstract An efficient, fully automatic method
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting
 Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting R. Maier 1,2, K. Kim 1, D. Cremers 2, J. Kautz 1, M. Nießner 2,3 Fusion Ours 1
DEFORMABLE MOTION 3D RECONSTRUCTION BY UNION OF REGULARIZED SUBSPACES
 DEFORMABLE MOTION 3D RECONSTRUCTION BY UNION OF REGULARIZED SUBSPACES Antonio Agudo Francesc Moreno-Noguer Institut de Robòtica i Informàtica Industrial, CSIC-UPC, 828, Barcelona, Spain ABSTRACT This paper
DEFORMABLE MOTION 3D RECONSTRUCTION BY UNION OF REGULARIZED SUBSPACES Antonio Agudo Francesc Moreno-Noguer Institut de Robòtica i Informàtica Industrial, CSIC-UPC, 828, Barcelona, Spain ABSTRACT This paper
A Factorization Method for Structure from Planar Motion
 A Factorization Method for Structure from Planar Motion Jian Li and Rama Chellappa Center for Automation Research (CfAR) and Department of Electrical and Computer Engineering University of Maryland, College
A Factorization Method for Structure from Planar Motion Jian Li and Rama Chellappa Center for Automation Research (CfAR) and Department of Electrical and Computer Engineering University of Maryland, College
Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model
 Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model Marco Paladini 1, Adrien Bartoli 2, and Lourdes Agapito 1 1 Queen Mary University of London, Mile End Road, E1 4NS London,
Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model Marco Paladini 1, Adrien Bartoli 2, and Lourdes Agapito 1 1 Queen Mary University of London, Mile End Road, E1 4NS London,
Structured light 3D reconstruction
 Structured light 3D reconstruction Reconstruction pipeline and industrial applications rodola@dsi.unive.it 11/05/2010 3D Reconstruction 3D reconstruction is the process of capturing the shape and appearance
Structured light 3D reconstruction Reconstruction pipeline and industrial applications rodola@dsi.unive.it 11/05/2010 3D Reconstruction 3D reconstruction is the process of capturing the shape and appearance
Project Updates Short lecture Volumetric Modeling +2 papers
 Volumetric Modeling Schedule (tentative) Feb 20 Feb 27 Mar 5 Introduction Lecture: Geometry, Camera Model, Calibration Lecture: Features, Tracking/Matching Mar 12 Mar 19 Mar 26 Apr 2 Apr 9 Apr 16 Apr 23
Volumetric Modeling Schedule (tentative) Feb 20 Feb 27 Mar 5 Introduction Lecture: Geometry, Camera Model, Calibration Lecture: Features, Tracking/Matching Mar 12 Mar 19 Mar 26 Apr 2 Apr 9 Apr 16 Apr 23
Dense Tracking and Mapping for Autonomous Quadrocopters. Jürgen Sturm
 Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
3D Motion Segmentation Using Intensity Trajectory
 3D Motion Segmentation Using Intensity Trajectory Paper ID: 323 Abstract. Motion segmentation is a fundamental aspect of tracking in a scene with multiple moving objects. In this paper we present a novel
3D Motion Segmentation Using Intensity Trajectory Paper ID: 323 Abstract. Motion segmentation is a fundamental aspect of tracking in a scene with multiple moving objects. In this paper we present a novel
Learning a generic 3D face model from 2D image databases using incremental structure from motion
 Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
Body Trunk Shape Estimation from Silhouettes by Using Homologous Human Body Model
 Body Trunk Shape Estimation from Silhouettes by Using Homologous Human Body Model Shunta Saito* a, Makiko Kochi b, Masaaki Mochimaru b, Yoshimitsu Aoki a a Keio University, Yokohama, Kanagawa, Japan; b
Body Trunk Shape Estimation from Silhouettes by Using Homologous Human Body Model Shunta Saito* a, Makiko Kochi b, Masaaki Mochimaru b, Yoshimitsu Aoki a a Keio University, Yokohama, Kanagawa, Japan; b
Photo Tourism: Exploring Photo Collections in 3D
 Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Photo Tourism: Exploring Photo Collections in 3D SIGGRAPH 2006 Noah Snavely Steven M. Seitz University of Washington Richard Szeliski Microsoft Research 2006 2006 Noah Snavely Noah Snavely Reproduced with
Overview. Augmented reality and applications Marker-based augmented reality. Camera model. Binary markers Textured planar markers
 Augmented reality Overview Augmented reality and applications Marker-based augmented reality Binary markers Textured planar markers Camera model Homography Direct Linear Transformation What is augmented
Augmented reality Overview Augmented reality and applications Marker-based augmented reality Binary markers Textured planar markers Camera model Homography Direct Linear Transformation What is augmented
Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model
 Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model Marco Paladini 1, Adrien Bartoli 2, and Lourdes Agapito 1 1 Queen Mary University of London, Mile End Road, E1 4NS London,
Sequential Non-Rigid Structure-from-Motion with the 3D-Implicit Low-Rank Shape Model Marco Paladini 1, Adrien Bartoli 2, and Lourdes Agapito 1 1 Queen Mary University of London, Mile End Road, E1 4NS London,
Anastasios Roussos Curriculum Vitae (3 July 2018)
") University of Exeter Department of Computer Science Exeter, UK, EX4 4QF Anastasios Roussos Curriculum Vitae (3 July 2018) Imperial College London Department of Computing London, UK, SW7 2AZ email: troussos@imperial.ac.uk
University of Exeter Department of Computer Science Exeter, UK, EX4 4QF Anastasios Roussos Curriculum Vitae (3 July 2018) Imperial College London Department of Computing London, UK, SW7 2AZ email: troussos@imperial.ac.uk
Synthesizing Realistic Facial Expressions from Photographs
 Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
Robust Model-Free Tracking of Non-Rigid Shape. Abstract
 Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
arxiv: v1 [cs.cv] 15 Jul 2016
![arxiv: v1 [cs.cv] 15 Jul 2016](/thumbs/87/95898946.jpg "arxiv: v1 [cs.cv] 15 Jul 2016") arxiv:1607.04515v1 [cs.cv] 15 Jul 2016 Multi-body Non-rigid Structure-from-Motion Suryansh Kumar 1, Yuchao Dai 1, and Hongdong Li 1,2 1 Research School of Engineering, the Australian National University
arxiv:1607.04515v1 [cs.cv] 15 Jul 2016 Multi-body Non-rigid Structure-from-Motion Suryansh Kumar 1, Yuchao Dai 1, and Hongdong Li 1,2 1 Research School of Engineering, the Australian National University
Nonrigid Structure from Motion in Trajectory Space
 Nonrigid Structure from Motion in Trajectory Space Ijaz Akhter LUMS School of Science and Engineering Lahore, Pakistan akhter@lumsedupk Sohaib Khan LUMS School of Science and Engineering Lahore, Pakistan
Nonrigid Structure from Motion in Trajectory Space Ijaz Akhter LUMS School of Science and Engineering Lahore, Pakistan akhter@lumsedupk Sohaib Khan LUMS School of Science and Engineering Lahore, Pakistan
Modeling 3D Human Poses from Uncalibrated Monocular Images
 Modeling 3D Human Poses from Uncalibrated Monocular Images Xiaolin K. Wei Texas A&M University xwei@cse.tamu.edu Jinxiang Chai Texas A&M University jchai@cse.tamu.edu Abstract This paper introduces an
Modeling 3D Human Poses from Uncalibrated Monocular Images Xiaolin K. Wei Texas A&M University xwei@cse.tamu.edu Jinxiang Chai Texas A&M University jchai@cse.tamu.edu Abstract This paper introduces an
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction
 Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
3D Scanning. Qixing Huang Feb. 9 th Slide Credit: Yasutaka Furukawa
 3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Multi-view stereo. Many slides adapted from S. Seitz
 Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Multi-view stereo Many slides adapted from S. Seitz Beyond two-view stereo The third eye can be used for verification Multiple-baseline stereo Pick a reference image, and slide the corresponding window
Non-Rigid Structure from Motion with Complementary Rank-3 Spaces
 Non-Rigid Structure from Motion with Complementary Rank-3 Spaces Paulo FU Gotardo and Aleix M Martinez Department of Electrical and Computer Engineering The Ohio State University, Columbus, OH 43210, USA
Non-Rigid Structure from Motion with Complementary Rank-3 Spaces Paulo FU Gotardo and Aleix M Martinez Department of Electrical and Computer Engineering The Ohio State University, Columbus, OH 43210, USA
Registration of Expressions Data using a 3D Morphable Model
 Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions
 Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions Vladislav Golyanik Torben Fetzer Didier Stricker Department of Computer Science, University of Kaiserslautern
Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions Vladislav Golyanik Torben Fetzer Didier Stricker Department of Computer Science, University of Kaiserslautern
An Evaluation of Volumetric Interest Points
 An Evaluation of Volumetric Interest Points Tsz-Ho YU Oliver WOODFORD Roberto CIPOLLA Machine Intelligence Lab Department of Engineering, University of Cambridge About this project We conducted the first
An Evaluation of Volumetric Interest Points Tsz-Ho YU Oliver WOODFORD Roberto CIPOLLA Machine Intelligence Lab Department of Engineering, University of Cambridge About this project We conducted the first
A New Representation for Video Inspection. Fabio Viola
 A New Representation for Video Inspection Fabio Viola Outline Brief introduction to the topic and definition of long term goal. Description of the proposed research project. Identification of a short term
A New Representation for Video Inspection Fabio Viola Outline Brief introduction to the topic and definition of long term goal. Description of the proposed research project. Identification of a short term
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Intensity-Depth Face Alignment Using Cascade Shape Regression
 Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Reconstruction, Motion Estimation and SLAM from Events
 Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
Reconstruction, Motion Estimation and SLAM from Events Andrew Davison Robot Vision Group and Dyson Robotics Laboratory Department of Computing Imperial College London www.google.com/+andrewdavison June
Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera
 1 Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera Yudong Guo, Juyong Zhang, Lin Cai, Jianfei Cai and Jianmin Zheng arxiv:1808.05323v2 [cs.cv] 17 Aug 2018 Abstract
1 Self-supervised CNN for Unconstrained 3D Facial Performance Capture from an RGB-D Camera Yudong Guo, Juyong Zhang, Lin Cai, Jianfei Cai and Jianmin Zheng arxiv:1808.05323v2 [cs.cv] 17 Aug 2018 Abstract
Learning Algorithms for Medical Image Analysis. Matteo Santoro slipguru
 Learning Algorithms for Medical Image Analysis Matteo Santoro slipguru santoro@disi.unige.it June 8, 2010 Outline 1. learning-based strategies for quantitative image analysis 2. automatic annotation of
Learning Algorithms for Medical Image Analysis Matteo Santoro slipguru santoro@disi.unige.it June 8, 2010 Outline 1. learning-based strategies for quantitative image analysis 2. automatic annotation of
Landmark Weighting for 3DMM Shape Fitting
 Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Landmark Weighting for 3DMM Shape Fitting Yu Yang a, Xiao-Jun Wu a, and Josef Kittler b a School of Internet of Things Engineering, Jiangnan University, Wuxi 214122, China b CVSSP, University of Surrey,
Lecture 8.2 Structure from Motion. Thomas Opsahl
 Lecture 8.2 Structure from Motion Thomas Opsahl More-than-two-view geometry Correspondences (matching) More views enables us to reveal and remove more mismatches than we can do in the two-view case More
Lecture 8.2 Structure from Motion Thomas Opsahl More-than-two-view geometry Correspondences (matching) More views enables us to reveal and remove more mismatches than we can do in the two-view case More
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Lecture 10 Dense 3D Reconstruction
 Institute of Informatics Institute of Neuroinformatics Lecture 10 Dense 3D Reconstruction Davide Scaramuzza 1 REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time M. Pizzoli, C. Forster,
Institute of Informatics Institute of Neuroinformatics Lecture 10 Dense 3D Reconstruction Davide Scaramuzza 1 REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time M. Pizzoli, C. Forster,
Image Based Reconstruction II
 Image Based Reconstruction II Qixing Huang Feb. 2 th 2017 Slide Credit: Yasutaka Furukawa Image-Based Geometry Reconstruction Pipeline Last Lecture: Multi-View SFM Multi-View SFM This Lecture: Multi-View
Image Based Reconstruction II Qixing Huang Feb. 2 th 2017 Slide Credit: Yasutaka Furukawa Image-Based Geometry Reconstruction Pipeline Last Lecture: Multi-View SFM Multi-View SFM This Lecture: Multi-View
Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes
 1 Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes Rui Yu, Chris Russell, and Lourdes Agapito Abstract Consider a video sequence captured by a single camera observing a complex dynamic scene
1 Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes Rui Yu, Chris Russell, and Lourdes Agapito Abstract Consider a video sequence captured by a single camera observing a complex dynamic scene
Dynamic Shape Tracking via Region Matching
 Dynamic Shape Tracking via Region Matching Ganesh Sundaramoorthi Asst. Professor of EE and AMCS KAUST (Joint work with Yanchao Yang) The Problem: Shape Tracking Given: exact object segmentation in frame1
Dynamic Shape Tracking via Region Matching Ganesh Sundaramoorthi Asst. Professor of EE and AMCS KAUST (Joint work with Yanchao Yang) The Problem: Shape Tracking Given: exact object segmentation in frame1
Continuous and Discrete Optimization Methods in Computer Vision. Daniel Cremers Department of Computer Science University of Bonn
 Continuous and Discrete Optimization Methods in Computer Vision Daniel Cremers Department of Computer Science University of Bonn Oxford, August 16 2007 Segmentation by Energy Minimization Given an image,
Continuous and Discrete Optimization Methods in Computer Vision Daniel Cremers Department of Computer Science University of Bonn Oxford, August 16 2007 Segmentation by Energy Minimization Given an image,
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza
 Davide Scaramuzza") Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
Lecture 10 Multi-view Stereo (3D Dense Reconstruction) Davide Scaramuzza REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time, ICRA 14, by Pizzoli, Forster, Scaramuzza [M. Pizzoli, C. Forster,
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
Occlusion-Aware Video Registration for Highly Non-Rigid Objects Supplementary Material
 Occlusion-Aware Video Registration for Highly Non-Rigid Objects Supplementary Material Bertram Taetz 1,, Gabriele Bleser 1,, Vladislav Golyanik 1, and Didier Stricker 1, 1 German Research Center for Artificial
Occlusion-Aware Video Registration for Highly Non-Rigid Objects Supplementary Material Bertram Taetz 1,, Gabriele Bleser 1,, Vladislav Golyanik 1, and Didier Stricker 1, 1 German Research Center for Artificial
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation
 A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
A Low Power, High Throughput, Fully Event-Based Stereo System: Supplementary Documentation Alexander Andreopoulos, Hirak J. Kashyap, Tapan K. Nayak, Arnon Amir, Myron D. Flickner IBM Research March 25,
Monocular Template-based Reconstruction of Inextensible Surfaces
 Monocular Template-based Reconstruction of Inextensible Surfaces Mathieu Perriollat 1 Richard Hartley 2 Adrien Bartoli 1 1 LASMEA, CNRS / UBP, Clermont-Ferrand, France 2 RSISE, ANU, Canberra, Australia
Monocular Template-based Reconstruction of Inextensible Surfaces Mathieu Perriollat 1 Richard Hartley 2 Adrien Bartoli 1 1 LASMEA, CNRS / UBP, Clermont-Ferrand, France 2 RSISE, ANU, Canberra, Australia
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/91/106305353.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Extrinsic camera calibration method and its performance evaluation Jacek Komorowski 1 and Przemyslaw Rokita 2 arxiv:1809.11073v1 [cs.cv] 28 Sep 2018 1 Maria Curie Sklodowska University Lublin, Poland jacek.komorowski@gmail.com
Extrinsic camera calibration method and its performance evaluation Jacek Komorowski 1 and Przemyslaw Rokita 2 arxiv:1809.11073v1 [cs.cv] 28 Sep 2018 1 Maria Curie Sklodowska University Lublin, Poland jacek.komorowski@gmail.com
Image Coding with Active Appearance Models
 Image Coding with Active Appearance Models Simon Baker, Iain Matthews, and Jeff Schneider CMU-RI-TR-03-13 The Robotics Institute Carnegie Mellon University Abstract Image coding is the task of representing
Image Coding with Active Appearance Models Simon Baker, Iain Matthews, and Jeff Schneider CMU-RI-TR-03-13 The Robotics Institute Carnegie Mellon University Abstract Image coding is the task of representing
Face2Face Comparing faces with applications Patrick Pérez. Inria, Rennes 2 Oct. 2014
 Face2Face Comparing faces with applications Patrick Pérez Inria, Rennes 2 Oct. 2014 Outline Metric learning for face comparison Expandable parts model and occlusions Face sets comparison Identity-based
Face2Face Comparing faces with applications Patrick Pérez Inria, Rennes 2 Oct. 2014 Outline Metric learning for face comparison Expandable parts model and occlusions Face sets comparison Identity-based
Multiframe Scene Flow with Piecewise Rigid Motion. Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz
 Multiframe Scene Flow with Piecewise Rigid Motion Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz Scene Flow. 2 Scene Flow. 3 Scene Flow. Scene Flow Estimation:
Multiframe Scene Flow with Piecewise Rigid Motion Vladislav Golyanik,, Kihwan Kim, Robert Maier, Mathias Nießner, Didier Stricker and Jan Kautz Scene Flow. 2 Scene Flow. 3 Scene Flow. Scene Flow Estimation:
CS 565 Computer Vision. Nazar Khan PUCIT Lectures 15 and 16: Optic Flow
 CS 565 Computer Vision Nazar Khan PUCIT Lectures 15 and 16: Optic Flow Introduction Basic Problem given: image sequence f(x, y, z), where (x, y) specifies the location and z denotes time wanted: displacement
CS 565 Computer Vision Nazar Khan PUCIT Lectures 15 and 16: Optic Flow Introduction Basic Problem given: image sequence f(x, y, z), where (x, y) specifies the location and z denotes time wanted: displacement
Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes
 Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes Chris Russell, Rui Yu, and Lourdes Agapito University College London [c.russell,r.yu,l.agapito]@cs.ucl.ac.uk Abstract. Consider a video sequence
Video Pop-up: Monocular 3D Reconstruction of Dynamic Scenes Chris Russell, Rui Yu, and Lourdes Agapito University College London [c.russell,r.yu,l.agapito]@cs.ucl.ac.uk Abstract. Consider a video sequence
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA
 TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
Fast Guided Global Interpolation for Depth and. Yu Li, Dongbo Min, Minh N. Do, Jiangbo Lu
 Fast Guided Global Interpolation for Depth and Yu Li, Dongbo Min, Minh N. Do, Jiangbo Lu Introduction Depth upsampling and motion interpolation are often required to generate a dense, high-quality, and
Fast Guided Global Interpolation for Depth and Yu Li, Dongbo Min, Minh N. Do, Jiangbo Lu Introduction Depth upsampling and motion interpolation are often required to generate a dense, high-quality, and
On the Dimensionality of Deformable Face Models
 On the Dimensionality of Deformable Face Models CMU-RI-TR-06-12 Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA 15213 Abstract
On the Dimensionality of Deformable Face Models CMU-RI-TR-06-12 Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA 15213 Abstract
Learning-based Localization
 Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning-based Localization Eric Brachmann ECCV 2018 Tutorial on Visual Localization - Feature-based vs. Learned Approaches Torsten Sattler, Eric Brachmann Roadmap Machine Learning Basics [10min] Convolutional
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Articulated Structure from Motion through Ellipsoid Fitting
 Int'l Conf. IP, Comp. Vision, and Pattern Recognition IPCV'15 179 Articulated Structure from Motion through Ellipsoid Fitting Peter Boyi Zhang, and Yeung Sam Hung Department of Electrical and Electronic
Int'l Conf. IP, Comp. Vision, and Pattern Recognition IPCV'15 179 Articulated Structure from Motion through Ellipsoid Fitting Peter Boyi Zhang, and Yeung Sam Hung Department of Electrical and Electronic
Structure from motion
 Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t R 2 3,t 3 Camera 1 Camera
Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t R 2 3,t 3 Camera 1 Camera
Using Subspace Constraints to Improve Feature Tracking Presented by Bryan Poling. Based on work by Bryan Poling, Gilad Lerman, and Arthur Szlam
 Presented by Based on work by, Gilad Lerman, and Arthur Szlam What is Tracking? Broad Definition Tracking, or Object tracking, is a general term for following some thing through multiple frames of a video
Presented by Based on work by, Gilad Lerman, and Arthur Szlam What is Tracking? Broad Definition Tracking, or Object tracking, is a general term for following some thing through multiple frames of a video
Image correspondences and structure from motion
 Image correspondences and structure from motion http://graphics.cs.cmu.edu/courses/15-463 15-463, 15-663, 15-862 Computational Photography Fall 2017, Lecture 20 Course announcements Homework 5 posted.
Image correspondences and structure from motion http://graphics.cs.cmu.edu/courses/15-463 15-463, 15-663, 15-862 Computational Photography Fall 2017, Lecture 20 Course announcements Homework 5 posted.
22 October, 2012 MVA ENS Cachan. Lecture 5: Introduction to generative models Iasonas Kokkinos
 Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering
 AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
Data Acquisition, Leica Scan Station 2, Park Avenue and 70 th Street, NY
 Automated registration of 3D-range with 2D-color images: an overview 44 th Annual Conference on Information Sciences and Systems Invited Session: 3D Data Acquisition and Analysis March 19 th 2010 Ioannis
Automated registration of 3D-range with 2D-color images: an overview 44 th Annual Conference on Information Sciences and Systems Invited Session: 3D Data Acquisition and Analysis March 19 th 2010 Ioannis
Feature Tracking and Optical Flow
 Feature Tracking and Optical Flow Prof. D. Stricker Doz. G. Bleser Many slides adapted from James Hays, Derek Hoeim, Lana Lazebnik, Silvio Saverse, who 1 in turn adapted slides from Steve Seitz, Rick Szeliski,
Feature Tracking and Optical Flow Prof. D. Stricker Doz. G. Bleser Many slides adapted from James Hays, Derek Hoeim, Lana Lazebnik, Silvio Saverse, who 1 in turn adapted slides from Steve Seitz, Rick Szeliski,
Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging
 Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging Florin C. Ghesu 1, Thomas Köhler 1,2, Sven Haase 1, Joachim Hornegger 1,2 04.09.2014 1 Pattern
Guided Image Super-Resolution: A New Technique for Photogeometric Super-Resolution in Hybrid 3-D Range Imaging Florin C. Ghesu 1, Thomas Köhler 1,2, Sven Haase 1, Joachim Hornegger 1,2 04.09.2014 1 Pattern
Video Georegistration: Key Challenges. Steve Blask Harris Corporation GCSD Melbourne, FL 32934
 Video Georegistration: Key Challenges Steve Blask sblask@harris.com Harris Corporation GCSD Melbourne, FL 32934 Definitions Registration: image to image alignment Find pixel-to-pixel correspondences between
Video Georegistration: Key Challenges Steve Blask sblask@harris.com Harris Corporation GCSD Melbourne, FL 32934 Definitions Registration: image to image alignment Find pixel-to-pixel correspondences between
Learning a Manifold as an Atlas Supplementary Material
 Learning a Manifold as an Atlas Supplementary Material Nikolaos Pitelis Chris Russell School of EECS, Queen Mary, University of London [nikolaos.pitelis,chrisr,lourdes]@eecs.qmul.ac.uk Lourdes Agapito
Learning a Manifold as an Atlas Supplementary Material Nikolaos Pitelis Chris Russell School of EECS, Queen Mary, University of London [nikolaos.pitelis,chrisr,lourdes]@eecs.qmul.ac.uk Lourdes Agapito
Realistic Texture Extraction for 3D Face Models Robust to Self-Occlusion
 Realistic Texture Extraction for 3D Face Models Robust to Self-Occlusion Chengchao Qu 1,2 Eduardo Monari 2 Tobias Schuchert 2 Jürgen Beyerer 2,1 1 Vision and Fusion Laboratory, Karlsruhe Institute of Technology
Realistic Texture Extraction for 3D Face Models Robust to Self-Occlusion Chengchao Qu 1,2 Eduardo Monari 2 Tobias Schuchert 2 Jürgen Beyerer 2,1 1 Vision and Fusion Laboratory, Karlsruhe Institute of Technology
BIL Computer Vision Apr 16, 2014
 BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
The SIFT (Scale Invariant Feature
 The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
Active Wavelet Networks for Face Alignment
 Active Wavelet Networks for Face Alignment Changbo Hu, Rogerio Feris, Matthew Turk Dept. Computer Science, University of California, Santa Barbara {cbhu,rferis,mturk}@cs.ucsb.edu Abstract The active appearance
Active Wavelet Networks for Face Alignment Changbo Hu, Rogerio Feris, Matthew Turk Dept. Computer Science, University of California, Santa Barbara {cbhu,rferis,mturk}@cs.ucsb.edu Abstract The active appearance
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION
 LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
A Systems View of Large- Scale 3D Reconstruction
 Lecture 23: A Systems View of Large- Scale 3D Reconstruction Visual Computing Systems Goals and motivation Construct a detailed 3D model of the world from unstructured photographs (e.g., Flickr, Facebook)
Lecture 23: A Systems View of Large- Scale 3D Reconstruction Visual Computing Systems Goals and motivation Construct a detailed 3D model of the world from unstructured photographs (e.g., Flickr, Facebook)
Motion and Tracking. Andrea Torsello DAIS Università Ca Foscari via Torino 155, Mestre (VE)
") Motion and Tracking Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Motion Segmentation Segment the video into multiple coherently moving objects Motion and Perceptual Organization
Motion and Tracking Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Motion Segmentation Segment the video into multiple coherently moving objects Motion and Perceptual Organization
Using temporal seeding to constrain the disparity search range in stereo matching
 Using temporal seeding to constrain the disparity search range in stereo matching Thulani Ndhlovu Mobile Intelligent Autonomous Systems CSIR South Africa Email: tndhlovu@csir.co.za Fred Nicolls Department
Using temporal seeding to constrain the disparity search range in stereo matching Thulani Ndhlovu Mobile Intelligent Autonomous Systems CSIR South Africa Email: tndhlovu@csir.co.za Fred Nicolls Department
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
A GEOMETRIC SEGMENTATION APPROACH FOR THE 3D RECONSTRUCTION OF DYNAMIC SCENES IN 2D VIDEO SEQUENCES
 A GEOMETRIC SEGMENTATION APPROACH FOR THE 3D RECONSTRUCTION OF DYNAMIC SCENES IN 2D VIDEO SEQUENCES Sebastian Knorr, Evren mre, A. Aydın Alatan, and Thomas Sikora Communication Systems Group Technische
A GEOMETRIC SEGMENTATION APPROACH FOR THE 3D RECONSTRUCTION OF DYNAMIC SCENES IN 2D VIDEO SEQUENCES Sebastian Knorr, Evren mre, A. Aydın Alatan, and Thomas Sikora Communication Systems Group Technische
Multi-View AAM Fitting and Camera Calibration
 To appear in the IEEE International Conference on Computer Vision Multi-View AAM Fitting and Camera Calibration Seth Koterba, Simon Baker, Iain Matthews, Changbo Hu, Jing Xiao, Jeffrey Cohn, and Takeo
To appear in the IEEE International Conference on Computer Vision Multi-View AAM Fitting and Camera Calibration Seth Koterba, Simon Baker, Iain Matthews, Changbo Hu, Jing Xiao, Jeffrey Cohn, and Takeo
Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild
 Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild Zhen-Hua Feng 1 Patrik Huber 1 Josef Kittler 1 Peter Hancock 2 Xiao-Jun Wu 3 Qijun Zhao 4 Paul Koppen 1 Matthias Rätsch 5 1 Centre
Evaluation of Dense 3D Reconstruction from 2D Face Images in the Wild Zhen-Hua Feng 1 Patrik Huber 1 Josef Kittler 1 Peter Hancock 2 Xiao-Jun Wu 3 Qijun Zhao 4 Paul Koppen 1 Matthias Rätsch 5 1 Centre
L2 Data Acquisition. Mechanical measurement (CMM) Structured light Range images Shape from shading Other methods
 Structured light Range images Shape from shading Other methods") L2 Data Acquisition Mechanical measurement (CMM) Structured light Range images Shape from shading Other methods 1 Coordinate Measurement Machine Touch based Slow Sparse Data Complex planning Accurate 2
L2 Data Acquisition Mechanical measurement (CMM) Structured light Range images Shape from shading Other methods 1 Coordinate Measurement Machine Touch based Slow Sparse Data Complex planning Accurate 2
Structure from Motion CSC 767
 Structure from Motion CSC 767 Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R,t R 2,t 2 R 3,t 3 Camera??
Structure from Motion CSC 767 Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R,t R 2,t 2 R 3,t 3 Camera??
Volumetric Scene Reconstruction from Multiple Views
 Volumetric Scene Reconstruction from Multiple Views Chuck Dyer University of Wisconsin dyer@cs cs.wisc.edu www.cs cs.wisc.edu/~dyer Image-Based Scene Reconstruction Goal Automatic construction of photo-realistic
Volumetric Scene Reconstruction from Multiple Views Chuck Dyer University of Wisconsin dyer@cs cs.wisc.edu www.cs cs.wisc.edu/~dyer Image-Based Scene Reconstruction Goal Automatic construction of photo-realistic
Registration of Dynamic Range Images
 Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
DTU Technical Report: ARTTS
 DTU Technical Report: ARTTS Title: Author: Project: Face pose tracking and recognition and 3D cameras Rasmus Larsen ARTTS Date: February 10 th, 2006 Contents Contents...2 Introduction...2 State-of-the
DTU Technical Report: ARTTS Title: Author: Project: Face pose tracking and recognition and 3D cameras Rasmus Larsen ARTTS Date: February 10 th, 2006 Contents Contents...2 Introduction...2 State-of-the