Grid Computing: Application Development
|
|
|
- Robyn Baldwin
- 6 years ago
- Views:
Transcription
1 Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis and Computer Science and PDC Royal Institute of Technology Stockholm, Sweden

2 Grids are Hot Courtesy Ken Kennedy
3 Grids: Application Development Courtesy Ken Kennedy
4 Grids: Middleware Development Courtesy Ken Kennedy
5 Grids: Administration Courtesy Ken Kennedy

6 Grid Application Development Courtesy Ken Kennedy
7 PDC Grid Application Development: A Software Grand Challenge Goal: Reliable performance on heterogeneous platforms, under varying load on computation nodes and on communications links Challenges: Presenting a high-level application development interface If programming is hard, its useless Designing and constructing applications for adaptability Mapping applications to dynamically changing configurations Determining when to interrupt execution and remap Application monitors Performance estimators
8 What is Needed Execution infrastructure for reliable performance Automatic resource location and execution initiation dynamic configuration to available resources Performance monitoring and control strategies deep integration across compilers, tools, and runtime systems performance contracts and dynamic reconfiguration Abstract Grid programming models and easy-to-use programming interfaces design of an implementation strategy for those models problem-solving environments Robust reliable numerical and data-structure libraries predictability and robustness of accuracy and performance reproducibility, fault tolerance, and auditability
9 PDC GrADSoft Architecture Goal: reliable performance under varying load Performance Feedback Software Components Performance Problem Real-time Performance Monitor Whole- Program Compiler Source Application Configurable Object Program Service Negotiator Scheduler Negotiation Grid Runtime System Libraries Dynamic Optimizer GrADS Project (NSF NGS): Berman, Chien, Cooper, Dongarra, Foster, Gannon Johnsson, Kennedy, Kesselman, Mellor-Crummey, Reed, Torczon, Wolski
10 PDC GrADSoft Architecture Program Preparation System Execution Environment Performance Feedback Software Components Performance Problem Real-time Performance Monitor Whole- Program Compiler Source Application Configurable Object Program Service Negotiator Scheduler Negotiation Grid Runtime System Libraries Dynamic Optimizer
11 High Level Programming System Built on Libraries Coded by Professionals Included mapping strategies and cost models High level knowledge of integration strategies Integration Produces Configurable Object Program Integrated mapping strategy and cost model Performance enhanced through context-dependent variants Context includes potential execution platform Dynamic Optimizer Performs Final Binding Implements mapping strategy Chooses machine-specific variants Inserts monitoring probes Strategy: move compilation overhead to PSEgeneration time
12 PDC Configurable Object Program Representation of the Application Supporting dynamic reconfiguration and optimization for distributed targets, may include Program intermediate code Annotations from the compiler mapping strategy and performance model Historical information (run profile to now) Mapping strategies Aggregation of data regions (submeshes) or tasks Definition of parameters for algorithm selection Challenge: synthesis of performance models User input, especially associated with libraries Synthesize different components, scale models to problem size
13 PDC Execution Cycle Configurable Object Program is presented Space of feasible resources must be defined Mapping strategy and performance model provided Service Negotiator solicits acceptable resource collections Performance model is used to evaluate each Best match is selected and contracted for Execution begins Dynamic optimizer tailors program to resources Selects mapping strategy Inserts sensors Contract monitoring is conducted during execution Soft violation detection based on fuzzy logic
14 PDC Performance Contracts At the Heart of the GrADS Model Fundamental mechanism for managing mapping and execution What are they? Mappings from resources to performance Mechanisms for determining when to interrupt and reschedule Abstract Definition Random Variable: r(a,i,c,t 0 ) with a probability distribution Challenge A = app, I = input, C = configuration, t 0 = time of initiation Important statistics: lower and upper bounds (95% confidence) When should a contract be (viewed as) violated? Strict adherence balanced against cost of reconfiguration

15 Grids - Performance Courtesy Dan Reed

16 Grids - Performance Courtesy Dan Reed

17 Performance Signatures Courtesy Dan Reed
18 PDC Contract Monitoring Input: Performance model Integrated from a variety of sources: user, compiler, application experience, application signatures Resources contracted for Trigger Registration information from sensors installed in applications Output Inserted by dynamic optimizer or user Rule based contract monitor that decides when contract violation is serious enough to merit reconfiguration Based on information from sensors
19 Grid Computing Core Library Courtesy Jack Dongarra

20 Grid Computing Core Library Courtesy Jack Dongarra

21 Grid Computing Library Use Courtesy Jack Dongarra

22 Grid Computing Library Use Courtesy Jack Dongarra
23 GrADS Library Sequence User Library Routine User makes a sequential call to a numerical library routine. The Library Routine has crafted code which invoke other components. Slide courtesy Jack Dongarra
24 GrADS Library Sequence User Library Routine Resource Selector Slide courtesy Jack Dongarra Library Routine calls a grid based routine to determine which resources are possible for use. The Resource Selector returns a bag of processors (coarse grid) that are available.
25 GrADS Library Sequence User Slide courtesy Jack Dongarra Library Routine Resource Selector The Library Routine calls the Performance Modeler to determine the best set of processors to use for the given problem. May be done by evaluating a formula or running a simulation. May assign a number of processes to a processor. At this point have a fine grid. Performance Model
26 GrADS Library Sequence User Library Routine Resource Selector The Library Routine calls the Contract Development routine to commit the fine grid for this call. A performance guarantee is generated. Contract Development Performance Model Slide courtesy Jack Dongarra
27 GrADS Library Sequence User Library Routine Resource Selector App Launcher Contract Development Performance Model mpirun machinefile fine_grid grid_linear_solve Slide courtesy Jack Dongarra


28 Grids Library Evaluation Courtesy Jack Dongarra
29 Arrays of Values Generated by Resource Selector Clique based UT, UCSD, UIUC Full at the cluster level and the connections (clique leaders) Bandwidth and Latency information looks like this. Linear arrays for CPU and Memory x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x Courtesy Jack Dongarra

30 Grids Performance Models Courtesy Jack Dongarra

31 Grids Library Evaluation Courtesy Jack Dongarra

32 Grids Library Evaluation Courtesy Jack Dongarra

33 Grids Library Evaluation Courtesy Jack Dongarra

34 Sample Application - Cactus Courtesy Ed Seidel

35 Cactus on the Grid Courtesy Ed Seidel

36 Cactus on the Grid Courtesy Ed Seidel

37 Cactus Migration basis Courtesy Ed Seidel, Ian Foster

38 Cactus Job Migration Courtesy Ed Seidel, Ian Foster

39 Cactus Migration Architecture Courtesy Ed Seidel, Ian Foster

40 Courtesy Ed Seidel, Ian Foster Cactus - Migration example

41 Bioimaging

42 Imaging Instruments Molecules Synchrotrons Microscopes Magnetic Resonance Imagers Macromolecular Complexes, Organelles, Cells Organs, Organ Systems, Organisms



43 JEOL300 0-FEG Liquid He stage NSF support No. of Particles Needed for 3-D Reconstruction Resolution B = 100 Å 2 B = 50 Å Å 4.5 Å 6,000 5,000,000 3, , Å 8.5 Å Structure of the HSV-1 Capsid


44

45 EM imaging EMAN Vitrification Robot Particle Selection Power Spectrum Analysis Initial 3D Model Micrographs 4-64 Mpixels, 16-bit (8 128 MB) /day per lab 10 1,000 particles per micrograph EMEN Database Archival Data Mining Management Classify Particles Reproject 3D Model Several TB/yr Project ,000+ micrographs 10,000 10,000,00 particles Align Average Deconvolute Build New 3D Model 10k 1,000k pixels/particle Up to hundreds of PFlops
46 EMAN
47 GrADSoft
48 Grid Application Software Managing Data, Codes and Resources Securely Performance
49 SimDB: A Grid Based Problem Solving Environment

50 Molecular Dynamics Jim Briggs University of Houston
51 Molecular Dynamics Simulations
52 Trajectory Properties Function Result Transport coefficients Scalar Normal modes Set of scalar values Solvent residence times Set of scalar values Average structures 3 x 1D coordinates Animation 3 x 1D coordinates x N frames Radial distribution functions Energy profiles Solvent densities Angles/distances between solute groups Atom-atom distances Dihedral angles Root mean square deviations Simple thermodynamic properties Time correlation functions 1D histogram 1D or 2D histogram 2D or 3D histogram 1D time series 1D time series 1D time series 1D time series 1D time series 1D time series
53 SimDB Workflow

54

55 SimDB Architecture

56

57 SimDB Data Access
58 SimDB Data Generation
59 SimDB Administration

60

61
62 PDC GrADSoft Architecture Program Preparation System Execution Environment Performance Feedback Software Components Performance Problem Real-time Performance Monitor Whole- Program Compiler Source Application Configurable Object Program Service Negotiator Scheduler Negotiation Grid Runtime System Libraries Dynamic Optimizer
63 Adaptive Software
64 Challenges Algorithmic Multiple data structures and their interaction Unfavorable data access pattern (big 2 n strides) High efficiency of the algorithm low floating-point v.s. load/store ratio Additions/multiplications unbalance Version explosion Verification Maintenance
65 PDC Challenges Diversity of execution environments Growing complexity of modern microprocessors. Deep memory hierarchies Out-of-order execution Instruction level parallelism Growing diversity of platform characteristics SMPs Clusters (employing a range of interconnect technologies) Grids (heterogeneity, wide range of characteristics) Wide range of application needs Dimensionality and sizes Data structures and data types Languages and programming paradigms
66 Opportunities Multiple algorithms with comparable numerical properties for many functions Improved software techniques and hardware performance Integrated performance monitors, models and data bases Run-time code construction
67 Approach Automatic algorithm selection polyalgorithmic functions Entirely different algorithms, exploit decomposition of operations, Code generation from high-level descriptions Extensive application independent compile-time analysis Integrated performance modeling and analysis Run-time application and execution environment dependent composition Automated installation process
68 Performance Tuning Methodology Input Parameters System specifics, User options UHFFT Code generator Input Parameters Size, dim., Library of FFT modules Initialization Select best plan Performance database Installation Execution Calculate one or more FFTs Run-time
69 The UHFFT Program preparation at installation (platform dependent) Integrated performance models (in progress) and data bases Algorithm selection at run-time from set defined at installation Automatic multiple precision constant generation Program construction at run-time based on application and performance predictions
70 The Fast Fourier Transform o Application of W n requires O( n ) operations. o Fast algorithms sparse factorizations of 2 W n W n = A 1 A 2 KA k where A o Application of i are sparse ( O(n) operations) and k = log(n). W n can be evaluated in O(nlog(n)) ops. o Sparse factorization is not unique. o Many different ways to factor the same W n.
71 Sparse Factorization Algorithms Rader s Algorithm Prime Factor Algorithm Split-radix Mixed-radix (Cooley-Tukey)
72 Notation Simple way to describe highly structured matrices Tensor (Kronecker) product = B B B B B B B B B B A n n n n n n a a a a a a a a a L M O M M L K blocking matrix matrix, scaling = A = B Direct sum notation: = B 0 0 A B A
73 Prime Factor Algorithm When n = rq, and gcd(r,q) = 1it is possible to reduce the number of operations by using the PFA (no twiddle factor multiplication). W n = = Π Π 1 1 (W (W r r I q )(I q r W )Π W )Π 2, q 2 where Π 1, Π 2 are permutation matrices.
74 Split-radix Algorithm o When n = 2 k the most efficient algorithm. o Two levels of radix-2 splitting. W o When n = 2q = n = (W2 In/2 )D2,n/2(I2 Wn/2 )Πn,2 W B B B Π SR a n m = n,q,2 I B q 4 p we can write SR a = (W = = B 2 B = ( I (W q m I Ω, q q n,p Π W q,2 p 3 n,p ) Π W )Π n,2 p ~ )[Iq (W2 I ~ Ω, W = 2 p n,q,2 )],, (1 i) W 2,
75 Mixed-radix Splitting When n = rq, Wn can be written as W n = (Wr Iq )Dr,q(Ir Wq )Πn,r, where D r, q is a diagonal twiddle factor D Ω r,q n,q = I and is a mod -r Π n,r q Ω = 1 ω n n,q matrix L Ω L ω r 1 n r 1 n,q sort permutation matrix.,,
76 Algorithm Selection Logic if n<=2 DFT else if n is prime use Rader s algorithm else { Chose factor r of n if r and n/r are coprime use PFA else if n is divisible by (r 2 ) and n>r 3 use Split-Radix algorithm else use Mixed-radix algorithm }
77 Example N = 6 FFTPrimeFactor n = 6, r = 3, dir = Forward, rot = 1 FFTRader n = 3, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Inverse, rot = 1 FFTRader n = 3, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Inverse, rot = 1 DFT n = 2, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Forward, rot = 1 DFT n = 2, r = 2, dir = Forward, rot = 1
78 UHFFT Architecture UHFFT Library Library of FFT Modules Initialization Routines Execution Routines Utilities FFT Code Generator Mixed-Radix (Cooly-Tukey) Prime Factor Algorithm Split-Radix Algorithm Rader's Algorithm Unparser Scheduler Key: Optimizer Initializer (Algorithm Abstraction) Fixed library code Generated code Code generator Funded in part by the Alliance (NSF) and LACSI (DoE)
79 Optimization Strategy High level (performed at application initialization) Selection of the optimal factorization using preoptimized codelets Generation of an execution plan Low level Selected set of codelets Selected codelets automaticly generated and highly optimized by a special-purpose compiler
80 The UHFFT: Code Generation Structure Algorithm abstraction Optimization Generation of a DAG Scheduling of instructions Unparsing Implementation Code generator is written in C Speed, portability and installation tuning Highly optimized straight line C code Generates FFT codelets of arbitrary size, direction, and rotation
81 The UHFFT: Code Generation (cont d) Basic structure is an Expression Constant, variable, sum, product, sign change, Basic functions Expression sum, product, assign, sign change, Derived structures Expression vectors, matrices and lists Higher level functions Matrix vector operations FFT specific operations Algorithms currently supported Rader (two versions), PFA, Split-radix, Mixed-radix
82 The UHFFT: Code Generation Mixed-Radix Algorithm Equation: W Is implemented as: n = (Wr Im )Dr,m(Ir Wm )Πn,r /* * FFTMixedRadix() Mixed-radix splitting. * Input: * r radix, * dir, rot direction and rotation of the transform, * u input expression vector. */ ExprVec *FFTMixedRadix(int r, int dir, int rot, ExprVec *u) { int m, n = u->n, *p; } m = n/r; p = ModRSortPermutation(n, r); u = FFTxI(r, m, dir, rot, TwiddleMult(r, m, dir, rot, IxFFT(r, m, dir, rot, PermuteExprVec(u, p)))); free(p); return u;
83 The UHFFT: Performance Modeling Analytic models Cache influence on library codes Performance measuring tools (PCL, PAPI) Prediction of composed code performance Updated from execution experience Data base Library codes. Recorded at installation time Composed codes. Recorded and updated for each execution.
84 The UHFFT: Execution Plan Generation Optimal plan search options Exhaustive Recursive Empirical Algorithms used Rader (FFTW, UHFFT) PFA (UHFFT) Split-radix (UHFFT) Mixed-radix (FFTW, SPIRAL, UHFFT)
85 PDC Characteristics of Some Processors Processor Clock frequency Peak Performance Cache structure Intel Pentium IV 1.8 GHz 1.8 GFlops L1: 8K+8K, L2: 256K AMD Athlon 1.4 GHz 1.4 GFlops L1: 64K+64K, L2: 256K PowerPC G4 867 MHz 867 MFlops L1: 32K+32K L2: 256K, L3: 1-2M Intel Itanium 800 Mhz 3.2 GFlops L1: 16K+16K L2: 92K, L3: 2-4M IBM Power3/4 375 MHz 1.5 GFlops L1: 64K+32K, L2: 1-16M HP PA 8x MHz 3 GFlops L1: 1.5M M Alpha EV67/ MHz 1.66 GFlops L1: 64K+64K, L2: 4M MIPS R1x MHz 1 GFlop L1: 32K+32K, L2: 4M


86 Codelet efficiency Intel PIV 1.8 GHz AMD Athlon 1.4 GHz PowerPC G4 867 MHz
87 Plan Performance, 32- bit Architectures
88 Power3 plan performance MFLOPS Plan MHz 888 Mflops
89 430 IBM Power3 222 MHz Execution Plan Comparison n = 2520 (PFA Plan) "MFLOPS" Plan
 Up to 64 GB of DDR today (256 in the future) AGP 4x today (8x in the future versions) 1-8 I/O adapters supporting PCI,")
90 HP zx1 Chipset 2-way block diagram Features: 2-way and 4-way Low latency connection to the DDR memory (112 ns) Directly (112 ns latency) Through (up to 12 ) scalable memory expanders (+25 ns latency) Up to 64 GB of DDR today (256 in the future) AGP 4x today (8x in the future versions) 1-8 I/O adapters supporting PCI, PCI-X, AGP
91 PDC Itanium.. Processor Clock frequency Peak Performance Cache structure Intel Itanium 800 Mhz 3.2 GFlops Intel Itanium Mhz 3.6 GFlops Intel Itanium Mhz 4 GFlops Sun UltraSparc-III 750 Mhz 1.5 GFlops Sun UltraSparc-III 1050 Mhz 2.1 GFlops L1: 16K+16K (Data+Instruction) L2: 92K, L3: 2-4M (off-die) L1: 16K+16K (Data+Instruction) L2: 256K, L3: 1.5M (on-die) L1: 16K+16K (Data+Instruction) L2: 256K, L3: 3M (on-die) L1: 64K+32K+2K+2K (Data+Instruction+Pre-fetch+Write) L2: up to 8M (off-die) L1: 64K+32K+2K+2K (Data+Instruction+Pre-fetch+Write) L2: up to 8M (off-die) Tested configuration
92 PDC Memory Hierarchy Itanium-2 (McKinley) Itanium L1I and L1D Size: Line size/associativity: Latency: Write Policies: 16KB + 16KB 64B/4-way 1 cycle Write through, No write allocate 16KB + 16KB 32B/4-way 1 cycle Write through, No write allocate Size: 256KB 96K B Unified L2 Line size/associativity: Integer Latency: FP Latency: 128B/8-way Min 5 cycles Min 6 cycles 64B/6-way Min 6 cycles Min 9 cycles Write Policies: Write back, write allocate Write back, write allocate Size: 3MB or 1.5MB on chip 4MB or 2MB off chip Unified L3 Line size/associativity: Integer Latency: FP Latency: 128B/12-way Min 12 cycles Min 13 cycles 64B/4-way Min 21 cycles Min 24 cycles Bandwith: 32B/cycle 16B/cycle

93 UHFFT Codelet Performance

94 UHFFT Codelet Performance

95 UHFFT Codelet Performance


96 Codelet Performance Radix-2



97 Codelet Performance Radix-3



98 Codelet Performance Radix-4

99 Codelet Performance Radix-5


100 Codelet Performance Radix-6
101 Codelet Performance Radix-7

102 Codelet Performance Radix-8

103 Codelet Performance Radix-9
104 Codelet Performance Radix-16

105 Codelet Performance Radix-32

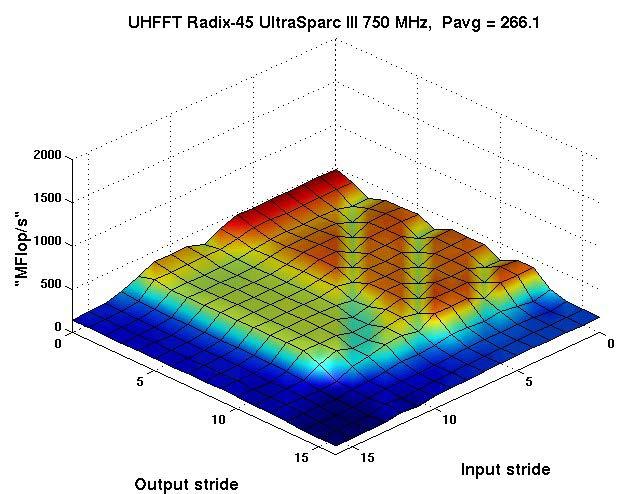
106 Codelet Performance Radix-45
107 Codelet Performance Radix-64
108 GrADS Testbed
109 GrADS Testbed

110 GrADS Testbed Web Interface

111 GrADS Testbed Web Interface
112 GrADS Testbed Services
113 GrADS team Ken Kennedy Ruth Aydt/Celso Mendez Francine Berman/Henry Cassanova Andrew Chien Keith Cooper Jack Dongarra Ian Foster Dennis Gannon Lennart Johnsson Carl Kesselman Dan Reed Richard Wolski Linda Torczon NSF funded under NGS Many students
Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Advanced Computing Research Laboratory. Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Grid Application Development Software
 Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
Grid Application Development Software Department of Computer Science University of Houston, Houston, Texas GrADS Vision Goals Approach Status http://www.hipersoft.cs.rice.edu/grads GrADS Team (PIs) Ken
Research in High-Performance Grid Software
 Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
Research in High-Performance Grid Software Lennart Johnsson NADA, KTH and Department of Computer Science University of Houston EU Project: Neurogenerator Collection and processing of PET and fmri data
An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
Compilers and Run-Time Systems for High-Performance Computing
 Compilers and Run-Time Systems for High-Performance Computing Blurring the Distinction between Compile-Time and Run-Time Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/compilerruntime.pdf
Compilers and Run-Time Systems for High-Performance Computing Blurring the Distinction between Compile-Time and Run-Time Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/compilerruntime.pdf
Input parameters System specifics, user options. Input parameters size, dim,... FFT Code Generator. Initialization Select fastest execution plan
 Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Compiler Technology for Problem Solving on Computational Grids
 Compiler Technology for Problem Solving on Computational Grids An Overview of Programming Support Research in the GrADS Project Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/gridcompilers.pdf
Compiler Technology for Problem Solving on Computational Grids An Overview of Programming Support Research in the GrADS Project Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/gridcompilers.pdf
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Introduction to HPC. Lecture 21
 443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed
Component Architectures
 Component Architectures Rapid Prototyping in a Networked Environment Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/lacsicomponentssv01.pdf Participants Ruth Aydt Bradley Broom Zoran
Component Architectures Rapid Prototyping in a Networked Environment Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/lacsicomponentssv01.pdf Participants Ruth Aydt Bradley Broom Zoran
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
High Performance Computing. Without a Degree in Computer Science
 High Performance Computing Without a Degree in Computer Science Smalley s Top Ten 1. energy 2. water 3. food 4. environment 5. poverty 6. terrorism and war 7. disease 8. education 9. democracy 10. population
High Performance Computing Without a Degree in Computer Science Smalley s Top Ten 1. energy 2. water 3. food 4. environment 5. poverty 6. terrorism and war 7. disease 8. education 9. democracy 10. population
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform
 Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Statistical Evaluation of a Self-Tuning Vectorized Library for the Walsh Hadamard Transform Michael Andrews and Jeremy Johnson Department of Computer Science, Drexel University, Philadelphia, PA USA Abstract.
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
GrADSoft and its Application Manager: An Execution Mechanism for Grid Applications
 GrADSoft and its Application Manager: An Execution Mechanism for Grid Applications Authors Ken Kennedy, Mark Mazina, John Mellor-Crummey, Rice University Ruth Aydt, Celso Mendes, UIUC Holly Dail, Otto
GrADSoft and its Application Manager: An Execution Mechanism for Grid Applications Authors Ken Kennedy, Mark Mazina, John Mellor-Crummey, Rice University Ruth Aydt, Celso Mendes, UIUC Holly Dail, Otto
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms
 Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries
 System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
System Demonstration of Spiral: Generator for High-Performance Linear Transform Libraries Yevgen Voronenko, Franz Franchetti, Frédéric de Mesmay, and Markus Püschel Department of Electrical and Computer
Research Related Activities
 Research Related Activities Lennart Johnsson Research Infrastructure Research Science and Engineering Research Infrastructure Observations Collaborators are increasingly chosen regardless of location Instruments
Research Related Activities Lennart Johnsson Research Infrastructure Research Science and Engineering Research Infrastructure Observations Collaborators are increasingly chosen regardless of location Instruments
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop
: Automatic Performance Tuning Workshop") Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Several Common Compiler Strategies. Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining
 Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Several Common Compiler Strategies Instruction scheduling Loop unrolling Static Branch Prediction Software Pipelining Basic Instruction Scheduling Reschedule the order of the instructions to reduce the
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Toward a Framework for Preparing and Executing Adaptive Grid Programs
 Toward a Framework for Preparing and Executing Adaptive Grid Programs Ken Kennedy α, Mark Mazina, John Mellor-Crummey, Keith Cooper, Linda Torczon Rice University Fran Berman, Andrew Chien, Holly Dail,
Toward a Framework for Preparing and Executing Adaptive Grid Programs Ken Kennedy α, Mark Mazina, John Mellor-Crummey, Keith Cooper, Linda Torczon Rice University Fran Berman, Andrew Chien, Holly Dail,
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Performance Analysis of KDD Applications using Hardware Event Counters. CAP Theme 2.
 Performance Analysis of KDD Applications using Hardware Event Counters CAP Theme 2 http://cap.anu.edu.au/cap/projects/kddmemperf/ Peter Christen and Adam Czezowski Peter.Christen@anu.edu.au Adam.Czezowski@anu.edu.au
Performance Analysis of KDD Applications using Hardware Event Counters CAP Theme 2 http://cap.anu.edu.au/cap/projects/kddmemperf/ Peter Christen and Adam Czezowski Peter.Christen@anu.edu.au Adam.Czezowski@anu.edu.au
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Experiments with Scheduling Using Simulated Annealing in a Grid Environment
 Experiments with Scheduling Using Simulated Annealing in a Grid Environment Asim YarKhan Computer Science Department University of Tennessee yarkhan@cs.utk.edu Jack J. Dongarra Computer Science Department
Experiments with Scheduling Using Simulated Annealing in a Grid Environment Asim YarKhan Computer Science Department University of Tennessee yarkhan@cs.utk.edu Jack J. Dongarra Computer Science Department
Performance Issues and Query Optimization in Monet
 Performance Issues and Query Optimization in Monet Stefan Manegold Stefan.Manegold@cwi.nl 1 Contents Modern Computer Architecture: CPU & Memory system Consequences for DBMS - Data structures: vertical
Performance Issues and Query Optimization in Monet Stefan Manegold Stefan.Manegold@cwi.nl 1 Contents Modern Computer Architecture: CPU & Memory system Consequences for DBMS - Data structures: vertical
Adaptable benchmarks for register blocked sparse matrix-vector multiplication
 Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Numerical Libraries And The Grid: The GrADS Experiments With ScaLAPACK
 UT-CS-01-460 April 28, 2001 Numerical Libraries And The Grid: The GrADS Experiments With ScaLAPACK Antoine Petitet, Susan Blackford, Jack Dongarra, Brett Ellis, Graham Fagg, Kenneth Roche, and Sathish
UT-CS-01-460 April 28, 2001 Numerical Libraries And The Grid: The GrADS Experiments With ScaLAPACK Antoine Petitet, Susan Blackford, Jack Dongarra, Brett Ellis, Graham Fagg, Kenneth Roche, and Sathish
Compilers for High Performance Computer Systems: Do They Have a Future? Ken Kennedy Rice University
 Compilers for High Performance Computer Systems: Do They Have a Future? Ken Kennedy Rice University Collaborators Raj Bandypadhyay Zoran Budimlic Arun Chauhan Daniel Chavarria-Miranda Keith Cooper Jack
Compilers for High Performance Computer Systems: Do They Have a Future? Ken Kennedy Rice University Collaborators Raj Bandypadhyay Zoran Budimlic Arun Chauhan Daniel Chavarria-Miranda Keith Cooper Jack
Formal Loop Merging for Signal Transforms
 Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Why Parallel Architecture
 Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Main Memory. EECC551 - Shaaban. Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors
 Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Cache Justification for Digital Signal Processors
 Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Vector IRAM: A Microprocessor Architecture for Media Processing
 IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
Algorithm and Library Software Design Challenges for Tera, Peta, and Future Exascale Computing
 Algorithm and Library Software Design Challenges for Tera, Peta, and Future Exascale Computing Bo Kågström Department of Computing Science and High Performance Computing Center North (HPC2N) Umeå University,
Algorithm and Library Software Design Challenges for Tera, Peta, and Future Exascale Computing Bo Kågström Department of Computing Science and High Performance Computing Center North (HPC2N) Umeå University,
Biological Sequence Alignment On The Computational Grid Using The Grads Framework
 Biological Sequence Alignment On The Computational Grid Using The Grads Framework Asim YarKhan (yarkhan@cs.utk.edu) Computer Science Department, University of Tennessee Jack J. Dongarra (dongarra@cs.utk.edu)
Biological Sequence Alignment On The Computational Grid Using The Grads Framework Asim YarKhan (yarkhan@cs.utk.edu) Computer Science Department, University of Tennessee Jack J. Dongarra (dongarra@cs.utk.edu)
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
SPIRAL Generated Modular FFTs *
 SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
SPIRAL Generated Modular FFTs * Jeremy Johnson Lingchuan Meng Drexel University * The work is supported by DARPA DESA, NSF, and Intel. Material for SPIRAL overview provided by Franz Francheti, Yevgen Voronenko,,
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
My 2 hours today: 1. Efficient arithmetic in finite fields minute break 3. Elliptic curves. My 2 hours tomorrow:
 My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
My 2 hours today: 1. Efficient arithmetic in finite fields 2. 10-minute break 3. Elliptic curves My 2 hours tomorrow: 4. Efficient arithmetic on elliptic curves 5. 10-minute break 6. Choosing curves Efficient
10th August Part One: Introduction to Parallel Computing
 Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Part One: Introduction to Parallel Computing 10th August 2007 Part 1 - Contents Reasons for parallel computing Goals and limitations Criteria for High Performance Computing Overview of parallel computer
Compiler Architecture for High-Performance Problem Solving
 Compiler Architecture for High-Performance Problem Solving A Quest for High-Level Programming Systems Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/compilerarchitecture.pdf Context
Compiler Architecture for High-Performance Problem Solving A Quest for High-Level Programming Systems Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/compilerarchitecture.pdf Context
Accurate Cache and TLB Characterization Using Hardware Counters
 Accurate Cache and TLB Characterization Using Hardware Counters Jack Dongarra, Shirley Moore, Philip Mucci, Keith Seymour, and Haihang You Innovative Computing Laboratory, University of Tennessee Knoxville,
Accurate Cache and TLB Characterization Using Hardware Counters Jack Dongarra, Shirley Moore, Philip Mucci, Keith Seymour, and Haihang You Innovative Computing Laboratory, University of Tennessee Knoxville,
Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism
 Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism Ching-Bih Liaw and Robert G. Clapp ABSTRACT Many of today s computer architectures are supported for fine-grain, rather than coarse-grain,
Many-core and PSPI: Mixing fine-grain and coarse-grain parallelism Ching-Bih Liaw and Robert G. Clapp ABSTRACT Many of today s computer architectures are supported for fine-grain, rather than coarse-grain,
Scientific Computing. Some slides from James Lambers, Stanford
 Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
The Role of Performance
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Why Performance Models Matter for Grid Computing
 Why Performance Models Matter for Grid Computing Ken Kennedy 1 Rice University ken@rice.edu 1 Introduction Global heterogeneous computing, often referred to as the Grid [5, 6], is a popular emerging computing
Why Performance Models Matter for Grid Computing Ken Kennedy 1 Rice University ken@rice.edu 1 Introduction Global heterogeneous computing, often referred to as the Grid [5, 6], is a popular emerging computing
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
CS Understanding Parallel Computing
 CS 594 001 Understanding Parallel Computing Web page for the course: http://www.cs.utk.edu/~dongarra/web-pages/cs594-2006.htm CS 594 001 Wednesday s 1:30 4:00 Understanding Parallel Computing: From Theory
CS 594 001 Understanding Parallel Computing Web page for the course: http://www.cs.utk.edu/~dongarra/web-pages/cs594-2006.htm CS 594 001 Wednesday s 1:30 4:00 Understanding Parallel Computing: From Theory
Energy Optimizations for FPGA-based 2-D FFT Architecture
 Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Generating Parallel Transforms Using Spiral
 Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
Generating Parallel Transforms Using Spiral Franz Franchetti Yevgen Voronenko Markus Püschel Part of the Spiral Team Electrical and Computer Engineering Carnegie Mellon University Sponsors: DARPA DESA
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Outline. How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III
 Outline How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III Peter Christen and Adam Czezowski CAP Research Group Department of Computer Science,
Outline How Fast is -fast? Performance Analysis of KKD Applications using Hardware Performance Counters on UltraSPARC-III Peter Christen and Adam Czezowski CAP Research Group Department of Computer Science,
Virtual Grids. Today s Readings
 Virtual Grids Last Time» Adaptation by Applications» What do you need to know? To do it well?» Grid Application Development Software (GrADS) Today» Virtual Grids» Virtual Grid Application Development Software
Virtual Grids Last Time» Adaptation by Applications» What do you need to know? To do it well?» Grid Application Development Software (GrADS) Today» Virtual Grids» Virtual Grid Application Development Software
Halfway! Sequoia. A Point of View. Sequoia. First half of the course is over. Now start the second half. CS315B Lecture 9
 Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
Halfway! Sequoia CS315B Lecture 9 First half of the course is over Overview/Philosophy of Regent Now start the second half Lectures on other programming models Comparing/contrasting with Regent Start with
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Latency Hiding by Redundant Processing: A Technique for Grid enabled, Iterative, Synchronous Parallel Programs
 Latency Hiding by Redundant Processing: A Technique for Grid enabled, Iterative, Synchronous Parallel Programs Jeremy F. Villalobos University of North Carolina at Charlote 921 University City Blvd Charlotte,
Latency Hiding by Redundant Processing: A Technique for Grid enabled, Iterative, Synchronous Parallel Programs Jeremy F. Villalobos University of North Carolina at Charlote 921 University City Blvd Charlotte,
Using Cache Models and Empirical Search in Automatic Tuning of Applications. Apan Qasem Ken Kennedy John Mellor-Crummey Rice University Houston, TX
 Using Cache Models and Empirical Search in Automatic Tuning of Applications Apan Qasem Ken Kennedy John Mellor-Crummey Rice University Houston, TX Outline Overview of Framework Fine grain control of transformations
Using Cache Models and Empirical Search in Automatic Tuning of Applications Apan Qasem Ken Kennedy John Mellor-Crummey Rice University Houston, TX Outline Overview of Framework Fine grain control of transformations
How to Write Fast Numerical Code Spring 2011 Lecture 22. Instructor: Markus Püschel TA: Georg Ofenbeck
 How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
How to Write Fast Numerical Code Spring 2011 Lecture 22 Instructor: Markus Püschel TA: Georg Ofenbeck Schedule Today Lecture Project presentations 10 minutes each random order random speaker 10 Final code
Generation of High Performance Domain- Specific Languages from Component Libraries. Ken Kennedy Rice University
 Generation of High Performance Domain- Specific Languages from Component Libraries Ken Kennedy Rice University Collaborators Raj Bandypadhyay Zoran Budimlic Arun Chauhan Daniel Chavarria-Miranda Keith
Generation of High Performance Domain- Specific Languages from Component Libraries Ken Kennedy Rice University Collaborators Raj Bandypadhyay Zoran Budimlic Arun Chauhan Daniel Chavarria-Miranda Keith
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Algorithm Engineering with PRAM Algorithms
 Algorithm Engineering with PRAM Algorithms Bernard M.E. Moret moret@cs.unm.edu Department of Computer Science University of New Mexico Albuquerque, NM 87131 Rome School on Alg. Eng. p.1/29 Measuring and
Algorithm Engineering with PRAM Algorithms Bernard M.E. Moret moret@cs.unm.edu Department of Computer Science University of New Mexico Albuquerque, NM 87131 Rome School on Alg. Eng. p.1/29 Measuring and
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Agenda. What is the Itanium Architecture? Terminology What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division
 What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division thomas.siebold@hp.com Agenda Terminology What is the Itanium Architecture? 1 Terminology Processor Architectures
What is the Itanium Architecture? Thomas Siebold Technology Consultant Alpha Systems Division thomas.siebold@hp.com Agenda Terminology What is the Itanium Architecture? 1 Terminology Processor Architectures
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
DESIGN AND OVERHEAD ANALYSIS OF WORKFLOWS IN GRID
 I J D M S C L Volume 6, o. 1, January-June 2015 DESIG AD OVERHEAD AALYSIS OF WORKFLOWS I GRID S. JAMUA 1, K. REKHA 2, AD R. KAHAVEL 3 ABSRAC Grid workflow execution is approached as a pure best effort
I J D M S C L Volume 6, o. 1, January-June 2015 DESIG AD OVERHEAD AALYSIS OF WORKFLOWS I GRID S. JAMUA 1, K. REKHA 2, AD R. KAHAVEL 3 ABSRAC Grid workflow execution is approached as a pure best effort
All MSEE students are required to take the following two core courses: Linear systems Probability and Random Processes
 MSEE Curriculum All MSEE students are required to take the following two core courses: 3531-571 Linear systems 3531-507 Probability and Random Processes The course requirements for students majoring in
MSEE Curriculum All MSEE students are required to take the following two core courses: 3531-571 Linear systems 3531-507 Probability and Random Processes The course requirements for students majoring in
Energy Efficient Adaptive Beamforming on Sensor Networks
 Energy Efficient Adaptive Beamforming on Sensor Networks Viktor K. Prasanna Bhargava Gundala, Mitali Singh Dept. of EE-Systems University of Southern California email: prasanna@usc.edu http://ceng.usc.edu/~prasanna
Energy Efficient Adaptive Beamforming on Sensor Networks Viktor K. Prasanna Bhargava Gundala, Mitali Singh Dept. of EE-Systems University of Southern California email: prasanna@usc.edu http://ceng.usc.edu/~prasanna
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling)
") 18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
A SEARCH OPTIMIZATION IN FFTW. by Liang Gu
 A SEARCH OPTIMIZATION IN FFTW by Liang Gu A thesis submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Master of Science in Electrical and
A SEARCH OPTIMIZATION IN FFTW by Liang Gu A thesis submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Master of Science in Electrical and
Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]
![Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]](/thumbs/93/113797768.jpg "Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]") Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Sami Saarinen Peter Towers. 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1
 Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Optimizing Cache Performance in Matrix Multiplication. UCSB CS240A, 2017 Modified from Demmel/Yelick s slides
 Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Learning to Construct Fast Signal Processing Implementations
 Journal of Machine Learning Research 3 (2002) 887-919 Submitted 12/01; Published 12/02 Learning to Construct Fast Signal Processing Implementations Bryan Singer Manuela Veloso Department of Computer Science
Journal of Machine Learning Research 3 (2002) 887-919 Submitted 12/01; Published 12/02 Learning to Construct Fast Signal Processing Implementations Bryan Singer Manuela Veloso Department of Computer Science
Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms
 Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms Paolo D Alberto, Franz Franchetti, Peter A. Milder, Aliaksei Sandryhaila, James C. Hoe, José M. F. Moura, Markus
Joint Runtime / Energy Optimization and Hardware / Software Partitioning of Linear Transforms Paolo D Alberto, Franz Franchetti, Peter A. Milder, Aliaksei Sandryhaila, James C. Hoe, José M. F. Moura, Markus
Performance COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
Performance COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals What is Performance? How do we measure the performance of
Cache-oblivious Programming
 Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix