Introduction to HPC. Lecture 21
|
|
|
- Horace Gibson
- 6 years ago
- Views:
Transcription
1 443 Introduction to HPC Lecture Dept of Computer Science 443 Fast Fourier Transform




2 443 FFT followed by Inverse FFT DIF DIT Use inverse twiddles for the inverse FFT No bitreversal necessary! 443 FFT followed by Inverse FFT DIT DIF Use inverse twiddles for the inverse FFT No bitreversal necessary! Twiddle allocation for forward and inverse the same!!
3 FFT followed by Inverse FFT 443 DIF followed by DIT, or DIT followed by DFT have same twiddle allocation which is important in parallel computation DIT followed by DIT or DFT followed by DFT have different twiddle allocation for forward and inverse FFT. Problem in parallel computation (more twiddle storage than necessary) We illustrated this for normal input order. Same is true for bitreversed input order Since bitreversal is its own inverse, no explicit bitreversal necessary to restore input order for forward followed by inverse FFT FFT: arithmetic and memory ops 443 Butterflies Arithmetic Operations Storage References FFT Add/Sub Mult Total Data Twiddles Total Radix Radix Radix FFT Arithmetic Operations Storage References FFT Add/Sub Mult Total Data Twiddles Total Radix 3Pp Pp 5Pp 4Pp Pp 5Pp Radix4 (/8)Pp (/8)Pp (7/4)Pp (6/8)Pp (6/8)Pp (/4)Pp Radix8 (66/4)Pp (3/4)Pp (49/)Pp (3/4)Pp (4/4)Pp (3/)Pp 3
4 Higher radix FFTs 443 For modern architectures the most significant benefit is the reduced memory load Ideal radix is the largest possible for each level of the memory hierarchy, i.e. in the innermost loop use the radix such that the maximum use is made of the register file, then radix for max use of L for the next loop, etc. 443 Parallel FFT Data allocation Example: Poweroftwo data set, poweroftwo processors Consecutive data allocation Cyclic data allocation P P P P 3 P 4 P 5 P 6 P P P P P 3 P 4 P 5 P 6 P Communication Input order Consecutive Cyclic Normal First n stages Last n stages Bitreversed Last n stages First n stages 4
5 443 Permutation based FFT FFT computations carried out from msb to lsb in data index, always To make all computations local the number of permutations depend on data allocation (and if the FFT is self sorting) Exchanges affect memory access strides both in carrying out permutations, and in carrying out butterfly computations 443 Parallel unordered FFT communication requirements 5
6 Twiddle factor allocation 443 Four step FFT Constructing the four step FFT (assumes fewer processors than N ) Factorize N in two equal (palindrome) factors. Compute first rank, N FFTs of size N. Multiply with twiddle factors 3. Transpose N Nmatrix 4. Compute last rank, N FFTs of size N 443 N N N FFT4 FFT4 FFT4 FFT4 FFT4 FFT4 FFT4 FFT4 6


7 443 Square Transpose (c) 443 Square Transpose Xeon Clovertown Opteron 85 Memory.6 GB/s, 88 cycles Memory 6.4 GB/s, 5 cycles L Cache 3K/core, 64B, 8way, 3 cycles L Cache 64K/core, 64B, way, 3 cycles L Cache 8M/dual, 64B, 6way, 4 cycles L Cache M/core, 64B, 6way, cycles 7
8 8 443 Parallel FFT on Binary ncube 443 Pipelined FFT on ncube The first four steps of a pipelined, inplace, FFT on a 3cube Time step Time step Time step Time step Memory location Processor The Table entry is network dimension starting with the dimension corresponding to the msb of the paddr)
9 9 443 Pipelined Bisection FFT on ncube The first four steps of a pipelined, inplace, FFT on a 3cube Time step Time step Time step Time step Memory location Processor Pipelined, D, inplace, FFT on cube Performance of a pipelined, onedimensional, inplace, radix, FFT on a cube as a function of data allocation (mesh shape of the cube)
10 443 Pipelined, D, inplace, FFT on cube Performance of a pipelined, twodimensional, inplace, radix, FFT on a cube as a function of data allocation (mesh shape of the cube) FFT on Binary cube 443 Conclusion. By pipelining the communication for successive FFT stages communication time only depends on data volume, essentially (log P becomes additive factor instead of multiplicative for transforms of size P)
11 443 Some node performance results 443 Stride has a big impact on performance Impact depends on cache size and cache replacement policy Maximum efficiency is architecture dependent Codelet performance highly variable
12 443 Characteristics of Target Architectures Processor Clock frequency Peak Performance Intel Pentium IV AMD Athlon.4 GHz.4 GFlops PowerPC G4 Cache structure.8 GHz.8 GFlops L: 8K+8K, L: 56K 867 MHz 867 MFlops Intel Itanium 8 Mhz 3. GFlops IBM Power3/4 375 MHz.5 GFlops L: 64K+64K, L: 56K L: 3K+3K L: 56K, L3: M L: 6K+6K L: 9K, L3: 4M L: 64K+3K, L: 6M HP PA 8x 75 MHz 3 GFlops L:.5M +.75M Alpha EV67/ MHz.66 GGlops L: 64K+64K, L: 4M MIPS Rx 5 MHz GFlop L: 3K+3K, L: 4M 443 Intel PIV.8 GHz Intel Pentium 4.8 GHz Gb RDRAM Bus speed: 4 MHz OS: Red Hat Linux 7. Compiler: gcc version.96 Compiler options: O3 maligndouble fomitframepointer Complex tocomplex, outofplace, double precision transforms Codelet sizes: 6, 3, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the processor) Peak performance:.8 GFLOPS

13 443 Intel PIV.8 GHz Codelet Performance Theoretical Peak Performance.8 GF Caches: L: 8K+8K, 4way assoc., least recently used, writeback/writethough, CL 64B, 6 cycle latency L: 56K, 8way assoc., least recently used, writeback, CL8B, 7 cycle latency of Pentium Intel PIV.8 GHz Codelet Efficiency Efficiency (fraction of peak) Caches: L: 8K+8K, 4way assoc., least recently used, writeback/writethough, CL 64B, 6 cycle latency L: 56K, 8way assoc., least recently used, writeback, CL8B, 7 cycle latency of Pentium 4 3
14 443 Intel PIV.8 GHz Codelet Performance 443 Intel PIV.8 GHz Codelet Efficiency Best/Worst>5 Radix8/Radix ~4 Compare with matrixmult.: DGEMM typically 9+%! Efficiency How good is 6x% of peak? 4

![sizes: 6, 3, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the](/docs-images/76/74279666/images/15-1.jpg "processor) Peak performance:.4 GFLOPS 443 AMD Athlon.4 GHz Codelet Performance Theoretical Peak Performance.")
15 443 AMD Athlon.4 GHz AMD Athlon.4 GHz 5 MB DDR RAM Bus speed: 66 MHz OS: Red Hat Linux 7. Compiler: gcc version.96 Compiler options: O3 maligndouble fomitframepointer Complex tocomplex, outofplace, double precision transforms Codelet sizes: 6, 3, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the processor) Peak performance:.4 GFLOPS 443 AMD Athlon.4 GHz Codelet Performance Theoretical Peak Performance.4 GF Caches: L: 64K+64K, way assoc. L: 56K 5
16 443 AMD Athlon.4 GHz Codelet Efficiency Efficiency (fraction of peak) Caches: L: 64K+64K, L: 56K 443 AMD Athlon.4 GHz Codelet Performance 6

17 443 AMD Athlon.4 GHz Codelet Efficiency Best/Worst >7 ~ Radix8/Radix ~4 Efficiency 443 Apple Power PC G4 867 MHz PowerPC G4 867 MHz. GB SDRAM Bus speed: 33 MHz OS: Mac OS X Version..4 Compiler: Apple Computer, Inc. version gcc96 Compiler options: O3 fomitframepointer Complex tocomplex, outofplace, double precision transforms Codelet sizes: 5, 3, 36, 45, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the processor) Peak performance: 867 MFLOPS 7

18 443 Apple PowerPC G4 867 MHz Codelet Performance Theoretical Peak Performance.867 GF Caches: L: 3K+3K L: 56K, L3: M Apple PowerPC G4 867 MHz Codelet Efficiency 443 Efficiency (fraction of peak) Caches: L: 3K+3K L: 56K, L3: M 8

19 Apple PowerPC G4 867 MHz Codelet Efficiency 443 Radix4/Radix ~ Best/Worst < 5 ~ Efficiency 443 Radix4 Codelet Efficiencies 3bit Intel PIV.8 GHz AMD Athlon.4 GHz PowerPC G4 867 MHz 9


20 443 Radix8 Codelet Efficiencies 3bit Intel PIV.8 GHz AMD Athlon.4 GHz PowerPC G4 867 MHz 443 UHFFT 3bit Performance
21 443 IA3 architecture comparison Best Performing Codelet Best/worst for max performance (codlet) Best/worst for a codlet (stride imp.) Pentium IV Radix8 ~4 >5.67 Athlon Radix8 ~4 >7.85 PowerPC Radix4 ~3 ~5.9 Best efficiency bit Architecture Experiences
22 443 Intel Itanium 8 MHz Intel Itanium 8 MHz GB SDRAM Bus speed: 33 MHz OS: HPUnix i version.5 Compiler: gcc version.96 Compiler options: O fomitframepointer funrollallloops Complex tocomplex, outofplace, double precision transforms Codelet sizes: 5, 3, 36, 45, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the processor) Peak performance: 3. GFLOPS 443 Intel Itanium 8 MHz Inherent parallelism in IA64 Multiple FPUs with fused multiplyadd instructions Large number of registers provide good support for ILP Relatively small L cache Large codelets do not perform very well Complex scheduling problem Cache reuse and parallelism have opposite requirements

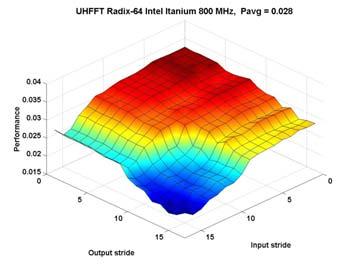
23 443 Intel Itanium 8 MHz Codelet Performance Best and worst codelets 443 Intel Itanium 8 MHz Codelet Performance Best and worst codelets 3


 Min performance (")
24 Intel Itanium 8 MHz codelet efficiency 443 Radix6/Radix ~ 6 Best/Worst ~ Minimum 443 UHFFT Codelet Performance Stride impact on performance Itanium size 3 FFT UltraSparc III A factor of 3+ A factor of 5+ Max performance ( best stride) Min performance ( worst stride) 4

25 443 UHFFT Codelet Performance Comparison Radix Itanium 8 MHz Radix Itanium 9 MHz Radix UltraSparc III 75 MHz Radixi Itanium 8 MHz Radixi Itanium 9 MHz Radixi UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix3 Itanium 8 MHz Radix3 Itanium 9 MHz Radix3 UltraSparc III 75 MHz Radix3i Itanium 8 MHz Radix3i Itanium 9 MHz Radix3i UltraSparc III 75 MHz 5
26 443 UHFFT Codelet Performance Comparison Radix4 Itanium 8 MHz Radix4 Itanium 9 MHz Radix4 UltraSparc III 75 MHz Radix4i Itanium 8 MHz Radix4i Itanium 9 MHz Radix4i UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix5 Itanium 8 MHz Radix5 Itanium 9 MHz Radix5 UltraSparc III 75 MHz Radix5i Itanium 8 MHz Radix5i Itanium 9 MHz Radix5i UltraSparc III 75 MHz 6
27 443 UHFFT Codelet Performance Comparison Radix6 Itanium 8 MHz Radix6 Itanium 9 MHz Radix6 UltraSparc III 75 MHz Radix6i Itanium 8 MHz Radix6i Itanium 9 MHz Radix6i UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix7 Itanium 8 MHz Radix7 Itanium 9 MHz Radix7 UltraSparc III 75 MHz Radix7i Itanium 8 MHz Radix7i Itanium 9 MHz Radix7i UltraSparc III 75 MHz 7
28 443 UHFFT Codelet Performance Comparison Radix8 Itanium 8 MHz Radix8 Itanium 9 MHz Radix8 UltraSparc III 75 MHz Radix8i Itanium 8 MHz Radix8i Itanium 9 MHz Radix8i UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix9 Itanium 8 MHz Radix9 Itanium 9 MHz Radix9 UltraSparc III 75 MHz Radix9i Itanium 8 MHz Radix9i Itanium 9 MHz Radix9i UltraSparc III 75 MHz 8

29 443 UHFFT Codelet Performance Comparison Radix Itanium 8 MHz Radix Itanium 9 MHz Radix UltraSparc III 75 MHz Radixi Itanium 8 MHz Radixi Itanium 9 MHz Radixi UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix Itanium 8 MHz Radix Itanium 9 MHz Radix UltraSparc III 75 MHz Radixi Itanium 8 MHz Radixi Itanium 9 MHz Radixi UltraSparc III 75 MHz 9
30 443 UHFFT Codelet Performance Comparison Radix3 Itanium 8 MHz Radix3 Itanium 9 MHz Radix3 UltraSparc III 75 MHz Radix3i Itanium 8 MHz Radix3i Itanium 9 MHz Radix3i UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix6 Itanium 8 MHz Radix6 Itanium 9 MHz Radix6 UltraSparc III 75 MHz Radix6i Itanium 8 MHz Radix6i Itanium 9 MHz Radix6i UltraSparc III 75 MHz 3

31 443 UHFFT Codelet Performance Comparison Radix3 Itanium 8 MHz Radix3 Itanium 9 MHz Radix3 UltraSparc III 75 MHz Radix3i Itanium 8 MHz Radix3i Itanium 9 MHz Radix3i UltraSparc III 75 MHz 443 UHFFT Codelet Performance Comparison Radix64 Itanium 8 MHz Radix64 Itanium 9 MHz Radix64 UltraSparc III 75 MHz Radix64i Itanium 8 MHz Radix64i Itanium 9 MHz Radix64i UltraSparc III 75 MHz 3
32 Compaq Alpha 833 MHz 443 Compaq Alpha 833 MHz GB SDRAM Bus speed: 33 MHz OS: True64 Unix Compiler: gcc version.96 Compiler options: O fomitframepointer funrollallloops Complex tocomplex, outofplace, double precision transforms Codelet sizes: 5, 3, 36, 45, 64 Strides: [6] Performance: Absolute: 5*n*log(n)/t CPU in FLOPS Relative: Absolute/(Peak performance of the processor) Peak performance:.66 GFLOPS Compaq Alpha 833 MHz Codelet Performance 443 3

33 443 IBM Power3 MHz Codelet Performance L: 8way set associative data and instruction caches L: Direct mapped, very vulnerable to cache trashing IBM Power3 MHz Execution Plan Comparison Example: Size 6 5 MFLOPS Plan 33
34 443 IBM Power3 MHz Execution Plan Comparison 43 4 n = 5 (PFA Plan) 4 4 "MFLOPS" Plan 443 IBM Power3 MHz PFA Performance PFA sizes 8 Mflops peak 34

35 443 IBM Power3 MHz Performance Powerof sizes 8 Mflops peak 443 IBM Power3 MHz Performance 8 Mflops peak 35

36 443 Compaq Alpha 833 MHz Performance.66 Gflops peak 443 HP PA 8, 8 MHz One level, MB, direct mapped cache The performance drops when 36

37 443 HP PA 8, 8 MHz Radix8, Forward FFT, Codelet Performance 443 HP PA 8, 8 MHz Radix6, Forward FFT, Codelet Performance 37
38 443 HP PA 8, 8 MHz Codelet Performance 7 Mflops peak 443 HP PA8, 8 MHz Execution Plan Performance Rank Plan CPU Time MFLOPS Relative 6.87E E E E E E E E
39 443 HP PA8, 8 MHz Execution Plan Performance MFLOPS HP PA 8, 8 MHz Execution Plan Performance 39
40 443 DFT on real sequences real FFT The transform X k of a real sequence x k is conjugate symmetric, i.e., X k = X Pk Transformation of pairs of real sequences: y k and z k Form x k = y k + iz k, then compute X, the transform of x. Let Y be the transform of y and Z the transform of z Then, X = Y+iZ, since the DFT is linear. Hence, X k = Y k +iz k and X Pk = Y Pk +iz Pk and X Pk = Y Pk iz Pk or X Pk = Y k iz k Then, Y k = (X k + X Pk )/ and Z k = (X k X Pk )/(i) Complex FFT + one post processing step involving an index reversal operation for transformation of two real sequences 443 DFT on real sequences real FFT Transform a single real sequence X m = X m = P Σ ω mj P x j = j= P/ P/ Σω mk P x k + k= Σω mk P/ x k + k= Thus, X m = Y m + ω m P Z m P/ ω m P P/ Σω m(k+) P x k+ k= Σω mk P/ x k+ k= V m [,P], ω P = e πi P Form v k = x k + ix k+, then compute V, the transform of v. Let Y be the transform of x k and Z the transform of x k+ Then, V = Y+iZ, since the DFT is linear. Note, V is of size P/. 4
41 443 DFT on real sequences real FFT Transform a single real sequence (cont d) We have V m = Y m +iz m and V P/m = Y P/m +iz P/m and V P/m = Y P/m iz P/m = Y m iz m Then, Y m = (V m + V P/m )/ and Z m = (V m V P/m )/(i) and, X m = (V m + V P/m )/ + ω Pm (V m + V P/m )/(i) V m X P/m = (V m + V P/m )/ + ω Pm (V m + V P/m )/(i) V m [,P/4], [,P/4], 443 DFT on real sequences real FFT Transform a single real sequence (cont d) Note that X = Y + Z = Re{V }+Im{V } and X P/ = Re{V }Im{V } The remaining values are computed by X m = (V m + V P/m )/ + ω Pm (V m + V P/m )/(i) V m X P/m = (V m + V P/m )/ + ω Pm (V m + V P/m )/(i) V m Complex FFT of half size sequence with odd indexed values treated as the imaginary part of a complex number, followed by one post processing step [,P/4], [,P/4], 4
42 443 DFT on real sequences Real FFT Remark: The described algorithms reduces memory and the number of arithmetic operations almost by a factor of for real sequences, but adds one communication step involving an index reversal. This step may significantly reduce the benefit of Real FFTs on some parallel platforms. 443 DFT on real sequences real FFT Transform of a single sequence, Edson s algorithm Let X m = P/ Σω mk P/ x k + k= P/ X P/+m = Σ ωp/ mk x k k= For x real we have P/ ω m P Σω mk P/ x k+ k= P/ ω m P Σω mk P/ x k+ k= P/ V m V m [,P/], [,P/], P/ X P/m = Σ ωp/ mk x k ω mσω mk P P/ x k+ V m [,P/], k= k= These are the same values as the first equation, thus the index range for the computations can be reduced to half. 4
43 443 DFT on real sequences real FFT Transform of a single sequence, Edson s algorithm Thus, we get the splitting formula X m = Y m + ω m P Z m X P/m = Y m ω m P Z m V m V m [,P/4], [,P/4], With the first splitting formula computing X P/4 X and X P/ are both real numbers as noted before and X P/4 = Y P/4 iz P/4, since both Y P/4 and Z P/4 are real 43
Advanced Computing Research Laboratory. Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries and Texas Learning and Computation Center and Department of Computer Science University of Houston Challenges Diversity of execution environments Growing complexity
Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
An Adaptive Framework for Scientific Software Libraries. Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston
 An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
An Adaptive Framework for Scientific Software Libraries Ayaz Ali Lennart Johnsson Dept of Computer Science University of Houston Diversity of execution environments Growing complexity of modern microprocessors.
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 14 th Lecture Feb. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Course Evaluation Email sent out
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
COMP4300/8300: Overview of Parallel Hardware. Alistair Rendell. COMP4300/8300 Lecture 2-1 Copyright c 2015 The Australian National University
 COMP4300/8300: Overview of Parallel Hardware Alistair Rendell COMP4300/8300 Lecture 2-1 Copyright c 2015 The Australian National University 2.1 Lecture Outline Review of Single Processor Design So we talk
COMP4300/8300: Overview of Parallel Hardware Alistair Rendell COMP4300/8300 Lecture 2-1 Copyright c 2015 The Australian National University 2.1 Lecture Outline Review of Single Processor Design So we talk
COMP4300/8300: Overview of Parallel Hardware. Alistair Rendell
 COMP4300/8300: Overview of Parallel Hardware Alistair Rendell COMP4300/8300 Lecture 2-1 Copyright c 2015 The Australian National University 2.2 The Performs: Floating point operations (FLOPS) - add, mult,
COMP4300/8300: Overview of Parallel Hardware Alistair Rendell COMP4300/8300 Lecture 2-1 Copyright c 2015 The Australian National University 2.2 The Performs: Floating point operations (FLOPS) - add, mult,
ENT 315 Medical Signal Processing CHAPTER 3 FAST FOURIER TRANSFORM. Dr. Lim Chee Chin
 ENT 315 Medical Signal Processing CHAPTER 3 FAST FOURIER TRANSFORM Dr. Lim Chee Chin Outline Definition and Introduction FFT Properties of FFT Algorithm of FFT Decimate in Time (DIT) FFT Steps for radix
ENT 315 Medical Signal Processing CHAPTER 3 FAST FOURIER TRANSFORM Dr. Lim Chee Chin Outline Definition and Introduction FFT Properties of FFT Algorithm of FFT Decimate in Time (DIT) FFT Steps for radix
Intel released new technology call P6P
 P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
P6 and IA-64 8086 released on 1978 Pentium release on 1993 8086 has upgrade by Pipeline, Super scalar, Clock frequency, Cache and so on But 8086 has limit, Hard to improve efficiency Intel released new
Using a Scalable Parallel 2D FFT for Image Enhancement
 Introduction Using a Scalable Parallel 2D FFT for Image Enhancement Yaniv Sapir Adapteva, Inc. Email: yaniv@adapteva.com Frequency domain operations on spatial or time data are often used as a means for
Introduction Using a Scalable Parallel 2D FFT for Image Enhancement Yaniv Sapir Adapteva, Inc. Email: yaniv@adapteva.com Frequency domain operations on spatial or time data are often used as a means for
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Computer Architecture. Introduction. Lynn Choi Korea University
 Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Computer Architecture Introduction Lynn Choi Korea University Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, 공학관 411, lchoi@korea.ac.kr, TA: 윤창현 / 신동욱, 3290-3896,
Node Hardware. Performance Convergence
 Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Node Hardware Improved microprocessor performance means availability of desktop PCs with performance of workstations (and of supercomputers of 10 years ago) at significanty lower cost Parallel supercomputers
Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units
 Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units Abstract: Split-radix fast Fourier transform (SRFFT) is an ideal candidate for the implementation of a lowpower FFT processor, because
Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units Abstract: Split-radix fast Fourier transform (SRFFT) is an ideal candidate for the implementation of a lowpower FFT processor, because
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
FFTSS Library Version 3.0 User s Guide
 Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Chapter 2. OS Overview
 Operating System Chapter 2. OS Overview Lynn Choi School of Electrical Engineering Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, Kong-Hak-Kwan 411, lchoi@korea.ac.kr,
Operating System Chapter 2. OS Overview Lynn Choi School of Electrical Engineering Class Information Lecturer Prof. Lynn Choi, School of Electrical Eng. Phone: 3290-3249, Kong-Hak-Kwan 411, lchoi@korea.ac.kr,
Automatic Performance Tuning. Jeremy Johnson Dept. of Computer Science Drexel University
 Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Automatic Performance Tuning Jeremy Johnson Dept. of Computer Science Drexel University Outline Scientific Computation Kernels Matrix Multiplication Fast Fourier Transform (FFT) Automated Performance Tuning
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 22 nd lecture Mar. 31, 2005 Instructor: Markus Pueschel Guest instructor: Franz Franchetti TA: Srinivas Chellappa
Parallelism in Spiral
 Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
Parallelism in Spiral Franz Franchetti and the Spiral team (only part shown) Electrical and Computer Engineering Carnegie Mellon University Joint work with Yevgen Voronenko Markus Püschel This work was
PERFORMANCE MEASUREMENT
 Administrivia CMSC 411 Computer Systems Architecture Lecture 3 Performance Measurement and Reliability Homework problems for Unit 1 posted today due next Thursday, 2/12 Start reading Appendix C Basic Pipelining
Administrivia CMSC 411 Computer Systems Architecture Lecture 3 Performance Measurement and Reliability Homework problems for Unit 1 posted today due next Thursday, 2/12 Start reading Appendix C Basic Pipelining
7/28/ Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc Prentice-Hall, Inc.
 Technology in Action Technology in Action Chapter 9 Behind the Scenes: A Closer Look a System Hardware Chapter Topics Computer switches Binary number system Inside the CPU Cache memory Types of RAM Computer
Technology in Action Technology in Action Chapter 9 Behind the Scenes: A Closer Look a System Hardware Chapter Topics Computer switches Binary number system Inside the CPU Cache memory Types of RAM Computer
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
Effect of memory latency
 CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
CACHE AWARENESS Effect of memory latency Consider a processor operating at 1 GHz (1 ns clock) connected to a DRAM with a latency of 100 ns. Assume that the processor has two ALU units and it is capable
Input parameters System specifics, user options. Input parameters size, dim,... FFT Code Generator. Initialization Select fastest execution plan
 Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Automatic Performance Tuning in the UHFFT Library Dragan Mirković 1 and S. Lennart Johnsson 1 Department of Computer Science University of Houston Houston, TX 7724 mirkovic@cs.uh.edu, johnsson@cs.uh.edu
Decimation-in-Frequency (DIF) Radix-2 FFT *
 Radix-2 FFT *") OpenStax-CX module: m1018 1 Decimation-in-Frequency (DIF) Radix- FFT * Douglas L. Jones This work is produced by OpenStax-CX and licensed under the Creative Commons Attribution License 1.0 The radix- decimation-in-frequency
OpenStax-CX module: m1018 1 Decimation-in-Frequency (DIF) Radix- FFT * Douglas L. Jones This work is produced by OpenStax-CX and licensed under the Creative Commons Attribution License 1.0 The radix- decimation-in-frequency
Advanced Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Computer Organization and Design THE HARDWARE/SOFTWARE INTERFACE
 T H I R D E D I T I O N R E V I S E D Computer Organization and Design THE HARDWARE/SOFTWARE INTERFACE Contents v Contents Preface C H A P T E R S Computer Abstractions and Technology 2 1.1 Introduction
T H I R D E D I T I O N R E V I S E D Computer Organization and Design THE HARDWARE/SOFTWARE INTERFACE Contents v Contents Preface C H A P T E R S Computer Abstractions and Technology 2 1.1 Introduction
Grid Computing: Application Development
 Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
Grid Computing: Application Development Lennart Johnsson Department of Computer Science and the Texas Learning and Computation Center University of Houston Houston, TX Department of Numerical Analysis
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
TOPICS PIPELINE IMPLEMENTATIONS OF THE FAST FOURIER TRANSFORM (FFT) DISCRETE FOURIER TRANSFORM (DFT) INVERSE DFT (IDFT) Consulted work:
 DISCRETE FOURIER TRANSFORM (DFT) INVERSE DFT (IDFT) Consulted work:") 1 PIPELINE IMPLEMENTATIONS OF THE FAST FOURIER TRANSFORM (FFT) Consulted work: Chiueh, T.D. and P.Y. Tsai, OFDM Baseband Receiver Design for Wireless Communications, John Wiley and Sons Asia, (2007). Second
1 PIPELINE IMPLEMENTATIONS OF THE FAST FOURIER TRANSFORM (FFT) Consulted work: Chiueh, T.D. and P.Y. Tsai, OFDM Baseband Receiver Design for Wireless Communications, John Wiley and Sons Asia, (2007). Second
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
Fused Floating Point Arithmetic Unit for Radix 2 FFT Implementation
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 6, Issue 2, Ver. I (Mar. -Apr. 2016), PP 58-65 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org Fused Floating Point Arithmetic
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 6, Issue 2, Ver. I (Mar. -Apr. 2016), PP 58-65 e-issn: 2319 4200, p-issn No. : 2319 4197 www.iosrjournals.org Fused Floating Point Arithmetic
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2007 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2007 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
Cache-oblivious Programming
 Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
Cache-oblivious Programming Story so far We have studied cache optimizations for array programs Main transformations: loop interchange, loop tiling Loop tiling converts matrix computations into block matrix
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
Advanced Processor Architecture
 Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
c 2013 Alexander Jih-Hing Yee
 c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
c 2013 Alexander Jih-Hing Yee A FASTER FFT IN THE MID-WEST BY ALEXANDER JIH-HING YEE THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 18, 2005 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Structure of Computer Systems
 Structure of Computer Systems Structure of Computer Systems Baruch Zoltan Francisc Technical University of Cluj-Napoca Computer Science Department U. T. PRES Cluj-Napoca, 2002 CONTENTS PREFACE... xiii
Structure of Computer Systems Structure of Computer Systems Baruch Zoltan Francisc Technical University of Cluj-Napoca Computer Science Department U. T. PRES Cluj-Napoca, 2002 CONTENTS PREFACE... xiii
Algorithms of Scientific Computing
 Algorithms of Scientific Computing Fast Fourier Transform (FFT) Michael Bader Technical University of Munich Summer 2018 The Pair DFT/IDFT as Matrix-Vector Product DFT and IDFT may be computed in the form
Algorithms of Scientific Computing Fast Fourier Transform (FFT) Michael Bader Technical University of Munich Summer 2018 The Pair DFT/IDFT as Matrix-Vector Product DFT and IDFT may be computed in the form
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Chapter 2. Parallel Hardware and Parallel Software. An Introduction to Parallel Programming. The Von Neuman Architecture
 An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
An Introduction to Parallel Programming Peter Pacheco Chapter 2 Parallel Hardware and Parallel Software 1 The Von Neuman Architecture Control unit: responsible for deciding which instruction in a program
Digital Signal Processing. Soma Biswas
 Digital Signal Processing Soma Biswas 2017 Partial credit for slides: Dr. Manojit Pramanik Outline What is FFT? Types of FFT covered in this lecture Decimation in Time (DIT) Decimation in Frequency (DIF)
Digital Signal Processing Soma Biswas 2017 Partial credit for slides: Dr. Manojit Pramanik Outline What is FFT? Types of FFT covered in this lecture Decimation in Time (DIT) Decimation in Frequency (DIF)
Calendar Description
 ECE212 B1: Introduction to Microprocessors Lecture 1 Calendar Description Microcomputer architecture, assembly language programming, memory and input/output system, interrupts All the instructions are
ECE212 B1: Introduction to Microprocessors Lecture 1 Calendar Description Microcomputer architecture, assembly language programming, memory and input/output system, interrupts All the instructions are
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
XT Node Architecture
 XT Node Architecture Let s Review: Dual Core v. Quad Core Core Dual Core 2.6Ghz clock frequency SSE SIMD FPU (2flops/cycle = 5.2GF peak) Cache Hierarchy L1 Dcache/Icache: 64k/core L2 D/I cache: 1M/core
XT Node Architecture Let s Review: Dual Core v. Quad Core Core Dual Core 2.6Ghz clock frequency SSE SIMD FPU (2flops/cycle = 5.2GF peak) Cache Hierarchy L1 Dcache/Icache: 64k/core L2 D/I cache: 1M/core
Algorithms and Computation in Signal Processing
 Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
Algorithms and Computation in Signal Processing special topic course 18-799B spring 2005 20 th Lecture Mar. 24, 2005 Instructor: Markus Pueschel TA: Srinivas Chellappa Assignment 3 - Feedback Peak Performance
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 4: MIPS Instructions Adapted from Computer Organization and Design, Patterson & Hennessy, UCB From Last Time Two values enter from the left (A and B) Need
ECE232: Hardware Organization and Design Lecture 4: MIPS Instructions Adapted from Computer Organization and Design, Patterson & Hennessy, UCB From Last Time Two values enter from the left (A and B) Need
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES
 FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
FFT ALGORITHMS FOR MULTIPLY-ADD ARCHITECTURES FRANCHETTI Franz, (AUT), KALTENBERGER Florian, (AUT), UEBERHUBER Christoph W. (AUT) Abstract. FFTs are the single most important algorithms in science and
Vector IRAM: A Microprocessor Architecture for Media Processing
 IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
DESIGN METHODOLOGY. 5.1 General
 87 5 FFT DESIGN METHODOLOGY 5.1 General The fast Fourier transform is used to deliver a fast approach for the processing of data in the wireless transmission. The Fast Fourier Transform is one of the methods
87 5 FFT DESIGN METHODOLOGY 5.1 General The fast Fourier transform is used to deliver a fast approach for the processing of data in the wireless transmission. The Fast Fourier Transform is one of the methods
Computer Architecture
 BASICS Hardware components Computer Architecture Computer Organization The von Neumann architecture Same storage device for both instructions and data Processor components Arithmetic Logic Unit Control
BASICS Hardware components Computer Architecture Computer Organization The von Neumann architecture Same storage device for both instructions and data Processor components Arithmetic Logic Unit Control
Microarchitecture Overview. Performance
 Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
Microarchitecture Overview Prof. Scott Rixner Duncan Hall 3028 rixner@rice.edu January 15, 2007 Performance 4 Make operations faster Process improvements Circuit improvements Use more transistors to make
High Performance Computing Lecture 26. Matthew Jacob Indian Institute of Science
 High Performance Computing Lecture 26 Matthew Jacob Indian Institute of Science Agenda 1. Program execution: Compilation, Object files, Function call and return, Address space, Data & its representation
High Performance Computing Lecture 26 Matthew Jacob Indian Institute of Science Agenda 1. Program execution: Compilation, Object files, Function call and return, Address space, Data & its representation
The Design and Implementation of FFTW3
 The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
The Design and Implementation of FFTW3 MATTEO FRIGO AND STEVEN G. JOHNSON Invited Paper FFTW is an implementation of the discrete Fourier transform (DFT) that adapts to the hardware in order to maximize
Microprocessors. Microprocessors and rpeanut. Memory. Eric McCreath
 Microprocessors Microprocessors and rpeanut Eric McCreath There are many well known microprocessors: Intel x86 series, Pentium, Celeron, Xeon, etc. AMD Opteron, Intel Itanium, Motorola 680xx series, PowerPC,
Microprocessors Microprocessors and rpeanut Eric McCreath There are many well known microprocessors: Intel x86 series, Pentium, Celeron, Xeon, etc. AMD Opteron, Intel Itanium, Motorola 680xx series, PowerPC,
Computer Architecture
 Computer components CPU - Central Processor Unit (e.g., G3, Pentium III, RISC) RAM - Random Access Memory (generally lost when power cycled) VRAM - Video RAM (amount sets screen size and color depth) ROM
Computer components CPU - Central Processor Unit (e.g., G3, Pentium III, RISC) RAM - Random Access Memory (generally lost when power cycled) VRAM - Video RAM (amount sets screen size and color depth) ROM
Microprocessors and rpeanut. Eric McCreath
 Microprocessors and rpeanut Eric McCreath Microprocessors There are many well known microprocessors: Intel x86 series, Pentium, Celeron, Xeon, etc. AMD Opteron, Intel Itanium, Motorola 680xx series, PowerPC,
Microprocessors and rpeanut Eric McCreath Microprocessors There are many well known microprocessors: Intel x86 series, Pentium, Celeron, Xeon, etc. AMD Opteron, Intel Itanium, Motorola 680xx series, PowerPC,
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms
 Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Empirical Auto-tuning Code Generator for FFT and Trigonometric Transforms Ayaz Ali and Lennart Johnsson Texas Learning and Computation Center University of Houston, Texas {ayaz,johnsson}@cs.uh.edu Dragan
Application Performance on Dual Processor Cluster Nodes
 Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Application Performance on Dual Processor Cluster Nodes by Kent Milfeld milfeld@tacc.utexas.edu edu Avijit Purkayastha, Kent Milfeld, Chona Guiang, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER Thanks Newisys
Benchmarking CPU Performance. Benchmarking CPU Performance
 Cluster Computing Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance,
Cluster Computing Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance,
Commodity Cluster Computing
 Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
The Role of Performance
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Role of Performance What is performance? A set of metrics that allow us to compare two different hardware
Lecture 3: Evaluating Computer Architectures. How to design something:
 Lecture 3: Evaluating Computer Architectures Announcements - (none) Last Time constraints imposed by technology Computer elements Circuits and timing Today Performance analysis Amdahl s Law Performance
Lecture 3: Evaluating Computer Architectures Announcements - (none) Last Time constraints imposed by technology Computer elements Circuits and timing Today Performance analysis Amdahl s Law Performance
LogiCORE IP Fast Fourier Transform v7.1
 LogiCORE IP Fast Fourier Transform v7.1 DS260 April 19, 2010 Introduction The Xilinx LogiCORE IP Fast Fourier Transform (FFT) implements the Cooley-Tukey FFT algorithm, a computationally efficient method
LogiCORE IP Fast Fourier Transform v7.1 DS260 April 19, 2010 Introduction The Xilinx LogiCORE IP Fast Fourier Transform (FFT) implements the Cooley-Tukey FFT algorithm, a computationally efficient method
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
1.3 Data processing; data storage; data movement; and control.
 CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
Computer Architecture. Fall Dongkun Shin, SKKU
 Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Chapter 6 Caches. Computer System. Alpha Chip Photo. Topics. Memory Hierarchy Locality of Reference SRAM Caches Direct Mapped Associative
 Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Chapter 6 s Topics Memory Hierarchy Locality of Reference SRAM s Direct Mapped Associative Computer System Processor interrupt On-chip cache s s Memory-I/O bus bus Net cache Row cache Disk cache Memory
Fast Quadruple Precision Arithmetic Library on Parallel Computer SR11000/J2
 Fast Quadruple Precision Arithmetic Library on Parallel Computer SR11000/J2 Takahiro Nagai 1, Hitoshi Yoshida 1,HisayasuKuroda 1,2, and Yasumasa Kanada 1,2 1 Dept. of Frontier Informatics, The University
Fast Quadruple Precision Arithmetic Library on Parallel Computer SR11000/J2 Takahiro Nagai 1, Hitoshi Yoshida 1,HisayasuKuroda 1,2, and Yasumasa Kanada 1,2 1 Dept. of Frontier Informatics, The University
CS650 Computer Architecture. Lecture 9 Memory Hierarchy - Main Memory
 CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
Cache Memories October 8, 2007
 15-213 Topics Cache Memories October 8, 27 Generic cache memory organization Direct mapped caches Set associative caches Impact of caches on performance The memory mountain class12.ppt Cache Memories Cache
15-213 Topics Cache Memories October 8, 27 Generic cache memory organization Direct mapped caches Set associative caches Impact of caches on performance The memory mountain class12.ppt Cache Memories Cache
EC 413 Computer Organization
 EC 413 Computer Organization Review I Prof. Michel A. Kinsy Computing: The Art of Abstraction Application Algorithm Programming Language Operating System/Virtual Machine Instruction Set Architecture (ISA)
EC 413 Computer Organization Review I Prof. Michel A. Kinsy Computing: The Art of Abstraction Application Algorithm Programming Language Operating System/Virtual Machine Instruction Set Architecture (ISA)
EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture
 EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Instruction Set Principles The Role of Compilers MIPS 2 Main Content Computer
EITF20: Computer Architecture Part2.1.1: Instruction Set Architecture Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Instruction Set Principles The Role of Compilers MIPS 2 Main Content Computer
IMPLEMENTATION OF THE. Alexander J. Yee University of Illinois Urbana-Champaign
 SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
SINGLE-TRANSPOSE IMPLEMENTATION OF THE OUT-OF-ORDER 3D-FFT Alexander J. Yee University of Illinois Urbana-Champaign The Problem FFTs are extremely memory-intensive. Completely bound by memory access. Memory
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
CENG3420 Lecture 03 Review
 CENG3420 Lecture 03 Review Bei Yu byu@cse.cuhk.edu.hk 2017 Spring 1 / 38 CISC vs. RISC Complex Instruction Set Computer (CISC) Lots of instructions of variable size, very memory optimal, typically less
CENG3420 Lecture 03 Review Bei Yu byu@cse.cuhk.edu.hk 2017 Spring 1 / 38 CISC vs. RISC Complex Instruction Set Computer (CISC) Lots of instructions of variable size, very memory optimal, typically less
Main Memory (Fig. 7.13) Main Memory
 Main Memory") Main Memory (Fig. 7.13) CPU CPU CPU Cache Multiplexor Cache Cache Bus Bus Bus Memory Memory bank 0 Memory bank 1 Memory bank 2 Memory bank 3 Memory b. Wide memory organization c. Interleaved memory organization
Main Memory (Fig. 7.13) CPU CPU CPU Cache Multiplexor Cache Cache Bus Bus Bus Memory Memory bank 0 Memory bank 1 Memory bank 2 Memory bank 3 Memory b. Wide memory organization c. Interleaved memory organization
Benchmarking CPU Performance
 Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Lecture Topics. Principle #1: Exploit Parallelism ECE 486/586. Computer Architecture. Lecture # 5. Key Principles of Computer Architecture
 Lecture Topics ECE 486/586 Computer Architecture Lecture # 5 Spring 2015 Portland State University Quantitative Principles of Computer Design Fallacies and Pitfalls Instruction Set Principles Introduction
Lecture Topics ECE 486/586 Computer Architecture Lecture # 5 Spring 2015 Portland State University Quantitative Principles of Computer Design Fallacies and Pitfalls Instruction Set Principles Introduction
Advance CPU Design. MMX technology. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ. ! Basic concepts
 Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
Computer Architectures Advance CPU Design Tien-Fu Chen National Chung Cheng Univ. Adv CPU-0 MMX technology! Basic concepts " small native data types " compute-intensive operations " a lot of inherent parallelism
Chapter 8 Memory Management
 Chapter 8 Memory Management Da-Wei Chang CSIE.NCKU Source: Abraham Silberschatz, Peter B. Galvin, and Greg Gagne, "Operating System Concepts", 9th Edition, Wiley. 1 Outline Background Swapping Contiguous
Chapter 8 Memory Management Da-Wei Chang CSIE.NCKU Source: Abraham Silberschatz, Peter B. Galvin, and Greg Gagne, "Operating System Concepts", 9th Edition, Wiley. 1 Outline Background Swapping Contiguous
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 2: Hardware/Software Interface Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Basic computer components How does a microprocessor
ECE232: Hardware Organization and Design Lecture 2: Hardware/Software Interface Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Overview Basic computer components How does a microprocessor
MINIMUM HARDWARE AND OS SPECIFICATIONS File Stream Document Management Software - System Requirements for V4.2
 MINIMUM HARDWARE AND OS SPECIFICATIONS File Stream Document Management Software - System Requirements for V4.2 NB: please read this page carefully, as it contains 4 separate specifications for a Workstation
MINIMUM HARDWARE AND OS SPECIFICATIONS File Stream Document Management Software - System Requirements for V4.2 NB: please read this page carefully, as it contains 4 separate specifications for a Workstation
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
High Performance Computing
 High Performance Computing CS701 and IS860 Basavaraj Talawar basavaraj@nitk.edu.in Course Syllabus Definition, RISC ISA, RISC Pipeline, Performance Quantification Instruction Level Parallelism Pipeline
High Performance Computing CS701 and IS860 Basavaraj Talawar basavaraj@nitk.edu.in Course Syllabus Definition, RISC ISA, RISC Pipeline, Performance Quantification Instruction Level Parallelism Pipeline
Improving Cache Performance
 Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Improving Cache Performance Computer Organization Architectures for Embedded Computing Tuesday 28 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition,
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Computed Tomography (CT) Scan Image Reconstruction on the SRC-7 David Pointer SRC Computers, Inc.
 Scan Image Reconstruction on the SRC-7 David Pointer SRC Computers, Inc.") Computed Tomography (CT) Scan Image Reconstruction on the SRC-7 David Pointer SRC Computers, Inc. CT Image Reconstruction Herman Head Sinogram Herman Head Reconstruction CT Image Reconstruction for all
Computed Tomography (CT) Scan Image Reconstruction on the SRC-7 David Pointer SRC Computers, Inc. CT Image Reconstruction Herman Head Sinogram Herman Head Reconstruction CT Image Reconstruction for all
Cluster Computing Paul A. Farrell 9/15/2011. Dept of Computer Science Kent State University 1. Benchmarking CPU Performance
 Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed to defeat any effort to
Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed to defeat any effort to