Quantum Chemistry (QC) on GPUs. Dec. 19, 2016
|
|
|
- Bennett Walton
- 6 years ago
- Views:
Transcription
 on GPUs Dec.")
1 Quantum Chemistry (QC) on GPUs Dec. 19, 2016


2 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large # of GPU nodes ACEMD*, AMBER (PMEMD)*, BAND, CHARMM, DESMOND, ESPResso, Folding@Home, GPUgrid.net, GROMACS, HALMD, HOOMD-Blue*, LAMMPS, Lattice Microbes*, mdcore, MELD, minimd, NAMD, OpenMM, PolyFTS, SOP-GPU* & more QC: All key codes are ported or optimizing Focus on using GPU-accelerated math libraries, OpenACC directives GPU-accelerated and available today: ABINIT, ACES III, ADF, BigDFT, CP2K, GAMESS, GAMESS- UK, GPAW, LATTE, LSDalton, LSMS, MOLCAS, MOPAC2012, NWChem, OCTOPUS*, PEtot, QUICK, Q-Chem, QMCPack, Quantum Espresso/PWscf, QUICK, TeraChem* Active GPU acceleration projects: green* = application where >90% of the workload is on GPU CASTEP, GAMESS, Gaussian, ONETEP, Quantum Supercharger Library*, VASP & more 2
3 MD vs. QC on GPUs Classical Molecular Dynamics Simulates positions of atoms over time; chemical-biological or chemical-material behaviors Forces calculated from simple empirical formulas (bond rearrangement generally forbidden) Up to millions of atoms Solvent included without difficulty Single precision dominated Uses cublas, cufft, CUDA Geforce (Accademics), Tesla (Servers) ECC off Quantum Chemistry (MO, PW, DFT, Semi-Emp) Calculates electronic properties; ground state, excited states, spectral properties, making/breaking bonds, physical properties Forces derived from electron wave function (bond rearrangement OK, e.g., bond energies) Up to a few thousand atoms Generally in a vacuum but if needed, solvent treated classically (QM/MM) or using implicit methods Double precision is important Uses cublas, cufft, OpenACC Tesla recommended ECC on 3


4 Accelerating Discoveries Using a supercomputer powered by the Tesla Platform with over 3,000 Tesla accelerators, University of Illinois scientists performed the first all-atom simulation of the HIV virus and discovered the chemical structure of its capsid the perfect target for fighting the infection. Without gpu, the supercomputer would need to be 5x larger for similar performance. 4
5 GPU-Accelerated Quantum Chemistry Apps Green Lettering Indicates Performance Slides Included Abinit ACES III Gaussian GPAW Octopus ONETEP Quantum SuperCharger Library ADF LATTE Petot RMG BigDFT LSDalton Q-Chem TeraChem CP2K MOLCAS QMCPACK UNM GAMESS-US Mopac2012 NWChem Quantum Espresso VASP WL-LSMS GPU Perf compared against dual multi-core x86 CPU socket. 5
6 ABINIT
7 ABINIT on GPUS Speed in the parallel version: For ground-state calculations, GPUs can be used. This is based on CUDA+MAGMA For ground-state calculations, the wavelet part of ABINIT (which is BigDFT) is also very well parallelized : MPI band parallelism, combined with GPUs
8 BigDFT

9 Courtesy of BigDFT CEA
10 Courtesy of BigDFT CEA

11 Courtesy of BigDFT CEA

12 Courtesy of BigDFT CEA

13 Courtesy of BigDFT CEA
14 Courtesy of BigDFT CEA
15 Gaussian
16 Gaussian ACS Fall 2011 press release Joint collaboration between Gaussian, NVDA and PGI for GPU acceleration: No such press release exists for Intel MIC or AMD GPUs Mike Frisch quote from press release: Calculations using Gaussian are limited primarily by the available computing resources, said Dr. Michael Frisch, president of Gaussian, Inc. By coordinating the development of hardware, compiler technology and application software among the three companies, the new application will bring the speed and cost-effectiveness of GPUs to the challenging problems and applications that Gaussian s customers need to address.

, Giovanni Scalmani (Gaussian, Inc.")
17 April 4-7, 2016 Silicon Valley ENABLING THE ELECTRONIC STRUCTURE PROGRAM GAUSSIAN ON GPGPUS USING OPENACC Roberto Gomperts (NVIDIA), Michael Frisch (Gaussian, Inc.), Giovanni Scalmani (Gaussian, Inc.), Brent Leback (NVIDIA/PGI)
18 PREVIOUSLY Earlier Presentations GRC Poster 2012 ACS Spring 2014 GTC Spring 2014 ( recording at ) WATOC Fall 2014 GTC Spring 2016 (this full recording at requires registration) 18
19 Gaussian: Design Guidelines, Parallelism and Memory Model Implementation: Top-Down/Bottom-Up TOPICS OpenACC: Extensions, Hints & Tricks Early Performance Closing Remarks 19
20 GAUSSIAN A Computational Chemistry Package that provides state-of-the-art capabilities for electronic structure modeling Gaussian 09 is licensed for a wide variety of computer systems All versions of Gaussian 09 contain virtually every scientific/modeling feature, and none imposes any artificial limitations on calculations other than computational resources and time constraints Researchers use Gaussian to, among others, study molecules and reactions; predict and interpret spectra; explore thermochemistry, photochemistry and other excited states; include solvent effects, and many more 12/19/
21 DESIGN GUIDELINES General Establish a Framework for the GPU-enabling of Gaussian Code Maintainability (Code Unification) Leverage Existing code/algorithms, including Parallelism and Memory Model Simplifies Resolving Problems Simplifies Improvement on existing code Simplifies Adding New Code 12/19/
22 DESIGN GUIDELINES Accelerate Gaussian for Relevant and Appropriate Theories and Methods Relevant: many users of Gaussian Appropriate: time consuming and good mapping to GPUs Resource Utilization Ensure efficient use of all available Computational Resources CPU cores and memory Available GPUs and memory 12/19/
23 CURRENT STATUS Single Node Implemented Energies for Closed and Open Shell HF and DFT (less than a handful of XC-functionals missing) First derivatives for the same as above Second derivatives for the same as above Using only OpenACC CUDA library calls (BLAS) 12/19/





24 IMPLEMENTATION MODEL Application Code Compute-Intensive Functions GPU Small Fraction of the Code Large Fraction of Execution time Rest of Sequential CPU Code CPU + 24
25 GAUSSIAN PARALLELISM MODEL CPU Cluster CPU Node GPU OpenMP OpenACC 25



26 GAUSSIAN: MEMORY MODEL CPU Cluster CPU Node GPU OpenMP OpenACC 26
27 CLOSING REMARKS Significant Progress has been made in enabling Gaussian on GPUs with OpenACC OpenACC is increasingly becoming more versatile Significant work lies ahead to improve performance Expand feature set: PBC, Solvation, MP2, ONIOM, triples-corrections 27
28 ACKNOWLEDGEMENTS Development is taking place with: Hewlett-Packard (HP) Series SL2500 Servers (Intel Xeon E v2 (2.8GHz/10- core/25mb/8.0gt-s QPI/115W, DDR3-1866) NVIDIA Tesla GPUs (K40 and later) PGI Accelerator Compilers (16.x) with OpenACC (2.5 standard) 12/19/
29 GPAW
30 Speedup Compared to CPU Only Increase Performance with Kepler 3.5 Running GPAW The blue nodes contain 1x E5-2687W CPU (8 Cores per CPU). The green nodes contain 1x E5-2687W CPU (8 Cores per CPU) and 1x or 2x NVIDIA K20X for the GPU Silicon K=1 Silicon K=2 Silicon K=3
31 Speedup Compared to CPU Only Increase Performance with Kepler x Running GPAW The blue nodes contain 1x E5-2687W CPU (8 Cores per CPU). The green nodes contain 1x E5-2687W CPUs (8 Cores per CPU) and 2x NVIDIA K20 or K20X for the GPU x 1 1.7x Silicon K=1 Silicon K=2 Silicon K=3
 and 2x NVIDIA K20 or K20X for the GPU. 0.6 1.3x 0.4 0.2 0 Silicon K=1 Silicon K=2 Silicon K=3")
32 Speedup Compared to CPU Only Increase Performance with Kepler 1.6 Running GPAW The blue nodes contain 2x E5-2687W CPUs (8 Cores per CPU) x 1.4x The green nodes contain 2x E5-2687W CPUs (8 Cores per CPU) and 2x NVIDIA K20 or K20X for the GPU x Silicon K=1 Silicon K=2 Silicon K=3

33 Used with permission from Samuli Hakala

34

35
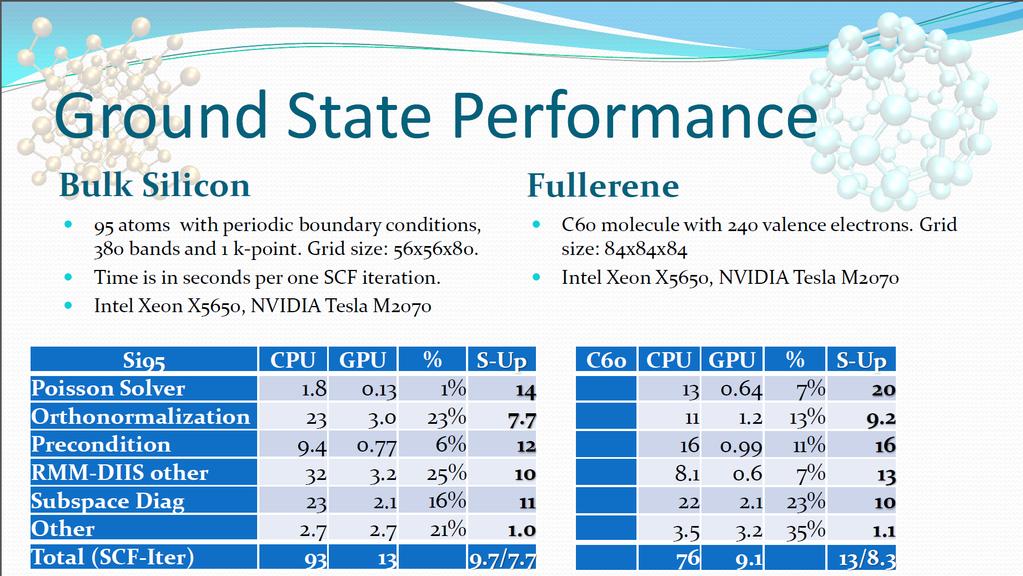
36

37 37

38 38

39 39

40 40

41 41

42 42
43 NWChem
44 NWChem 6.3 Release with GPU Acceleration Addresses large complex and challenging molecular-scale scientific problems in the areas of catalysis, materials, geochemistry and biochemistry on highly scalable, parallel computing platforms to obtain the fastest time-to-solution Researchers can for the first time be able to perform large scale coupled cluster with perturbative triples calculations utilizing the NVIDIA GPU technology. A highly scalable multi-reference coupled cluster capability will also be available in NWChem 6.3. The software, released under the Educational Community License 2.0, can be downloaded from the NWChem website at
45 NWChem - Speedup of the non-iterative calculation for various configurations/tile sizes System: cluster consisting of dual-socket nodes constructed from: 8-core AMD Interlagos processors 64 GB of memory Tesla M2090 (Fermi) GPUs The nodes are connected using a high-performance QDR Infiniband interconnect Courtesy of Kowolski, K., Bhaskaran-Nair, at PNNL, JCTC (submitted)
 180 160 165 Uracil 140 120 100 80 81 60 54 40 20")

46 Time to Solution (seconds) Kepler, Faster Performance (NWChem) Uracil CPU Only CPU + 1x K20X CPU + 2x K20X Uracil Molecule Performance improves by 2x with one GPU and by 3.1x with 2 GPUs
47 Quantum Espresso December 2016
48 seconds AUSURF112 on K80s AUSURF112 *Lower is better 580 Running Quantum Espresso version X The blue node contains Dual Intel Xeon E [3.5GHz Turbo] (Broadwell) CPUs The green node contains Dual Intel Xeon E [3.5GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs Broadwell node 1 node + 4x K80 per node 48
49 seconds AUSURF112 on P100s PCIe AUSURF1120 *Lower is better X 1.2X Running Quantum Espresso version The blue node contains Dual Intel Xeon E [3.5GHz Turbo] (Broadwell) CPUs 200 The green nodes contain Dual Intel Xeon E [3.5GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs Broadwell node 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node 49
50 TeraChem 1.5K Speaker, Date
51 TERACHEM 1.5K; TRIPCAGE ON TESLA K40S TeraChem 1.5K; TripCage on Tesla K40s & IVB CPUs (Total Processing Time in Seconds) x Xeon E v2@2.70ghz + 1 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 2 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 4 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 8 x Tesla K40@875Mhz (1 node) 51
52 TERACHEM 1.5K; TRIPCAGE ON TESLA K40S & HASWELL CPUS 200 TeraChem 1.5K; TripCage on Tesla K40s & Haswell CPUs (Total Processing Time in Seconds) x Xeon E v3@2.30ghz + 1 x Tesla K40@875Mhz (1 node) 2 x Xeon E v3@2.30ghz + 2 x Tesla K40@875Mhz (1 node) 2 x Xeon E v3@2.30ghz + 4 x Tesla K40@875Mhz (1 node) 52
53 TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & IVB CPUS 120 TeraChem 1.5K; TripCage on Tesla K80s & IVB CPUs (Total Processing Time in Seconds) x Xeon E v2@2.70ghz + 1 x Tesla K80 board (1 node) 2 x Xeon E v2@2.70ghz + 2 x Tesla K80 boards 2 x Xeon E v2@2.70ghz + 4 x Tesla K80 boards (1 node) (1 node) 53
54 TERACHEM 1.5K; TRIPCAGE ON TESLA K80S & HASWELL CPUS 120 TeraChem 1.5K; TripCage on Tesla K80s & Haswell CPUs (Total Processing Time in Seconds) x Xeon E v3@2.30ghz + 1 x Tesla K80 board (1 node) 2 x Xeon E v3@2.30ghz + 2 x Tesla K80 boards (1 node) 2 x Xeon E v3@2.30ghz + 4 x Tesla K80 boards (1 node) 54
55 TERACHEM 1.5K; BPTI ON TESLA K40S & IVB CPUS TeraChem 1.5K; BPTI on Tesla K40s & IVB CPUs (Total Processing Time in Seconds) x Xeon E v2@2.70ghz + 1 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 2 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 4 x Tesla K40@875Mhz (1 node) 2 x Xeon E v2@2.70ghz + 8 x Tesla K40@875Mhz (1 node) 55
56 TERACHEM 1.5K; BPTI ON TESLA K80S & IVB CPUS 8000 TeraChem 1.5K; BPTI on Tesla K80s & IVB CPUs (Total Processing Time in Seconds) x Xeon E v2@2.70ghz + 1 x Tesla K80 board (1 node) 2 x Xeon E v2@2.70ghz + 2 x Tesla K80 boards (1 node) 2 x Xeon E v2@2.70ghz + 4 x Tesla K80 boards (1 node) 56
57 TERACHEM 1.5K; BPTI ON TESLA K40S & HASWELL CPUS TeraChem 1.5K; BPTI on Tesla K40s & Haswell CPUs (Total Processing Time in Seconds) x Xeon E v3@2.30ghz + 1 x Tesla K40@875Mhz (1 node) 2 x Xeon E v3@2.30ghz + 2 x Tesla K40@875Mhz (1 node) 2 x Xeon E v3@2.30ghz + 4 x Tesla K40@875Mhz (1 node) 57
 4000 2000 0 2 x Xeon E5-2698 v3@2.30ghz + 1 x Tesla K80 board (1 node) 2 x Xeon E5-2698 v3@2.")
58 TERACHEM 1.5K; BPTI ON TESLA K80S & HASWELL CPUS 6000 TeraChem 1.5K; BPTI on Tesla K80s & Haswell CPUs (Total Processing Time in Seconds) x Xeon E v3@2.30ghz + 1 x Tesla K80 board (1 node) 2 x Xeon E v3@2.30ghz + 2 x Tesla K80 boards (1 node) 2 x Xeon E v3@2.30ghz + 4 x Tesla K80 boards (1 node) 58
59 Time (Seconds) TeraChem Supercomputer Speeds on GPUs Time for SCF Step TeraChem running on 8 C2050s on 1 node NWChem running on 4096 Quad Core CPUs In the Chinook Supercomputer Giant Fullerene C240 Molecule Quad Core CPUs ($19,000,000) 8 C2050 ($31,000) Similar performance from just a handful of GPUs

60 Price/Performance relative to Supercomputer TeraChem Bang for the Buck Performance/Price 493 TeraChem running on 8 C2050s on 1 node NWChem running on 4096 Quad Core CPUs In the Chinook Supercomputer Giant Fullerene C240 Molecule Note: Typical CPU and GPU node pricing used. Pricing may vary depending on node configuration. Contact your preferred HW vendor for actual pricing Quad Core CPUs ($19,000,000) 8 C2050 ($31,000) Dollars spent on GPUs do 500x more science than those spent on CPUs
 TeraChem running on C2050 and K20C 700 600 1800 1600 1400")

61 Seconds Seconds Kepler s Even Better 800 Olestra BLYP 453 Atoms 2000 B3LYP/6-31G(d) TeraChem running on C2050 and K20C First graph is of BLYP/G-31(d) Second is B3LYP/6-31G(d) C2050 K20C 0 C2050 K20C Kepler performs 2x faster than Tesla
62 VASP November 2016
63 1/seconds Interface on K80s Interface Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs X X X The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs 1x K80 is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water molecules) (468 ions) Broadwell node 1 node + 1x K80 per node 1 node + 2x K80 per node 1 node + 4x K80 per node 1256 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 63
64 elapsed time (s) Interface on P100s PCIe X 1 Broadwell node 1 node + 1x P100 PCIe per node Interface X 1 node + 2x P100 PCIe per node X 1 node + 4x P100 PCIe per node *Lower is better X 1 node + 8x P100 PCIe per node Running VASP version The blue node contains Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water molecules) (468 ions) 1256 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 64
65 elapsed time (s) Silica IFPEN on K80s X Silica IFPEN *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs X X The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs 1x K80 is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Broadwell node 1 node + 1x K80 per node 1 node + 2x K80 per node 1 node + 4x K80 per node 240 ions, cristobalite (high) bulk 720 bands? plane waves ALGO = Very Fast (RMM-DIIS) 65
66 elapsed time (s) Silica IFPEN on P100s PCIe Silica IFPEN *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs X 1 Broadwell node 1 node + 1x P100 PCIe per node X 1 node + 2x P100 PCIe per node X 1 node + 4x P100 PCIe per node X 1 node + 8x P100 PCIe per node The green nodes contain Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 240 ions, cristobalite (high) bulk 720 bands? plane waves ALGO = Very Fast (RMM-DIIS) 66
67 elapsed time (s) Si-Huge on K80s X 1 Broadwell node 1 node + 1x K80 per node Si-Huge X 1 node + 2x K80 per node *Lower is better X 1 node + 4x K80 per node Running VASP version The blue node contains Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs 1x K80 is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 512 Si atoms 1282 bands Plane Waves Algo = Normal (blocked Davidson) 67
68 elapsed time (s) Si-Huge on P100s PCIe X Si-Huge X *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 0 1 Broadwell node 1 node + 1x P100 PCIe per node 1 node + 2x P100 PCIe per node 3.1X 3.9X 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node 512 Si atoms 1282 bands Plane Waves Algo = Normal (blocked Davidson) 68
69 elapsed time (s) SupportedSystems on K80s 300 SupportedSystems Running VASP version X X *Lower is better X The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs 1x K80 is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Broadwell node 1 node + 1x K80 per node 1 node + 2x K80 per node 1 node + 4x K80 per node 267 ions 788 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 69
70 elapsed time (s) SupportedSystems on P100s PCIe SupportedSystems *Lower is better X X X 1.9X Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Broadwell node 1 node + 1x P100 PCIe per node 1 node + 2x P100 PCIe per node 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node 267 ions 788 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 70
71 elapsed time (s) NiAl-MD on K80s NiAl-MD X X *Lower is better X Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla K80 (autoboost) GPUs 1x K80 is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) Broadwell node 1 node + 1x K80 per node 1 node + 2x K80 per node 1 node + 4x K80 per node 500 ions 3200 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 71
72 elapsed time (s) NiAl-MD on P100s PCIe NiAl-MD *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs X 1 Broadwell node 1 node + 1x P100 PCIe per node X 1 node + 2x P100 PCIe per node X 2.7X 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node The green nodes contain Dual Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 500 ions 3200 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 72
73 elapsed time (s) B.hR105 on P100s PCIe B.hR105 *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs X 1 Broadwell node 1 node + 1x P100 PCIe per node X 6.2X 7.8X 1 node + 2x P100 PCIe per node 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 105 Boron atoms (β-rhombohedral structure) 216 bands plane waves Hybrid Functional with blocked Davicson (ALGO=Normal) LHFCALC=.True. (Exact Exchange) 73
74 elapsed time (s) B.aP107 on P100s PCIe B.aP107 *Lower is better Running VASP version The blue node contains Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs The green nodes contain Dual Intel Xeon E [3.6GHz Turbo] (Broadwell) CPUs + Tesla P100 PCIe GPUs Broadwell node 1 node + 1x P100 PCIe per node X 7.5X X 14.9X 1 node + 2x P100 PCIe per node 1 node + 4x P100 PCIe per node 1 node + 8x P100 PCIe per node 1x P100 PCIe is paired with Single Intel Xeon E v4@2.2ghz [3.6GHz Turbo] (Broadwell) 107 Boron atoms (symmetry broken 107-atom β variant) 216 bands plane waves Hybrid functional calculation (exact exchange) with blocked Davidson. No KPoint parallelization. Hybrid Functional with blocked Davidson (ALGO=Normal) LHFCALC=.True. (Exact Exchange) 74
75 VASP w/ Patch#1 March 2016
76 Speedup Vs Dual-Socket Broadwell CPU VASP Speedup Vs Dual-Socket CPU Server 3.0x VASP Quantum Chemistry Package for performing ab-initio quantummechanical molecular dynamics (MD) simulations 2.5x 2.0x 1.5x 1.0x 0.5x Accelerated Features Metric Scalability RMM-DIIS, Blocked Davidson, K-points and exact-exchange Elapsed Time (seconds) Multi-GPU, multi-node 0.0x 2X Tesla K80 4X Tesla K80 2X P100 PCIe 4X P100 PCIe 8X P100 PCIe 2X P100 SXM2 4X P100 SXM2 CPU Servers: Dual Xeon E (22-core CPU) GPU Servers: Dual Xeon E (20-core CPU) with Tesla P100s SXM2 or Dual Xeon E (22-core CPU) with Tesla K80s or P100s PCIe CUDA Version: CUDA Dataset: Silica IFPEN 76 8X P100 SXM2
77 Elapsed time (s) VASP Interface Benchmark Interface *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs X X X X The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) Interface between a platinum slab Pt(111) (108 atoms) and liquid water (120 water molecules) (468 ions) 0 1 Node 1 Node + 1x K80 per node 1 Node + 2x K80 per node [Old Data] 1 Node + 2x K80 per node 1 Node + 4x K80 per node 1256 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 77
78 Elapsed time (s) VASP Silica IFPEN Benchmark Silica IFPEN *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs X X X The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) Node 1 Node + 1x K80 per node 1 Node + 2x K80 per node [Old Data] 1 Node + 2x K80 per node 2.6X 1 Node + 4x K80 per node 240 ions, cristobalite (high) bulk 720 bands? plane waves ALGO = Very Fast (RMM-DIIS) 78
79 Elapsed time (s) VASP Si-Huge Benchmark Si-Huge *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs X The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs X 2.3X [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) Node 1 Node + 1x K80 per node 1 Node + 2x K80 per node [Old Data] 1 Node + 2x K80 per node 3.3X 1 Node + 4x K80 per node 512 Si atoms 1282 bands Plane Waves Algo = Normal (blocked Davidson) 79
80 Elapsed time (s) VASP SupportedSystems Benchmark SupportedSystems Running VASP version X X *Lower is better The blue node contains Dual Intel Xeon E (Haswell) CPUs The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs X X [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) Node 1 Node + 1x K80 per node 1 Node + 2x K80 per node [Old Data] 1 Node + 2x K80 per node 1 Node + 4x Tesla K80 per node 267 ions 788 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 80
81 Elapsed time (s) VASP NiAl-MD Benchmark NiAl-MD *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs X 1 Node 1 Node + 1x K80 per node Node + 2x K80 per node [Old Data] Node + 2x K80 per node X 3.9X 5.1X 1 Node + 4x K80 per node [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) 500 ions 3200 bands plane waves ALGO = Fast (Davidson + RMM-DIIS) 81
82 Elapsed time (s) VASP B.hR105 Benchmark B.hR X *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) X 3.5X 1 Node 1 Node + 1x K80 per 1 Node + 2x K80 per node node [Old Data] 1 Node + 2x K80 per node X 1 Node + 4x K80 per node 105 Boron atoms (β-rhombohedral structure) 216 bands plane waves Hybrid Functional with blocked Davicson (ALGO=Normal) LHFCALC=.True. (Exact Exchange) 82
83 Elapsed time (s) VASP B.aP107 Benchmark B.aP107 *Lower is better Running VASP version The blue node contains Dual Intel Xeon E (Haswell) CPUs The green nodes contain Dual Intel Xeon E (Haswell) CPUs + Tesla K80 (autoboost) GPUs [Old Data] = pre-bugfix: patch #1 for vasp feb15 which yield up to 2.7X faster calculations. (patch #1 available at VASP.at) Boron atoms (symmetry broken 107-atom β variant) X 3.7X X 6.2X 216 bands plane waves Hybrid functional calculation (exact exchange) with blocked Davidson. No KPoint parallelization. 0 1 Node 1 Node + 1x K80 per node 1 Node + 2x K80 per node [Old Data] 1 Node + 2x K80 per node 1 Node + 4x K80 per node Hybrid Functional with blocked Davidson (ALGO=Normal) LHFCALC=.True. (Exact Exchange) 83
84 Quantum Chemistry (QC) on GPUs Dec, 19, 2016
Quantum Chemistry (QC) on GPUs. Feb. 2, 2017
 on GPUs. Feb. 2, 2017") Quantum Chemistry (QC) on GPUs Feb. 2, 2017 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large
Quantum Chemistry (QC) on GPUs Feb. 2, 2017 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large
Quantum Chemistry (QC) on GPUs. October 2017
 on GPUs. October 2017") Quantum Chemistry (QC) on GPUs October 2017 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large
Quantum Chemistry (QC) on GPUs October 2017 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large
Quantum Chemistry (QC) on GPUs. March 2018
 on GPUs. March 2018") Quantum Chemistry (QC) on GPUs March 2018 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large #
Quantum Chemistry (QC) on GPUs March 2018 Overview of Life & Material Accelerated Apps MD: All key codes are GPU-accelerated Great multi-gpu performance Focus on dense (up to 16) GPU nodes &/or large #
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS
 CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
TESLA ACCELERATED COMPUTING. Mike Wang Solutions Architect NVIDIA Australia & NZ
 TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC. Stefan Maintz, Dr. Markus Wetzstein
 STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing
STRATEGIES TO ACCELERATE VASP WITH GPUS USING OPENACC Stefan Maintz, Dr. Markus Wetzstein smaintz@nvidia.com; mwetzstein@nvidia.com Companies Academia VASP USERS AND USAGE 12-25% of CPU cycles @ supercomputing
ENABLING NEW SCIENCE GPU SOLUTIONS
 ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
An Innovative Massively Parallelized Molecular Dynamic Software
 Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources An Innovative Massively Parallelized Molecular Dynamic Software Mohamed Hacene, Ani Anciaux,
Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources An Innovative Massively Parallelized Molecular Dynamic Software Mohamed Hacene, Ani Anciaux,
GPU ACCELERATED COMPUTING. 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation
 GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems
 Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
TESLA V100 PERFORMANCE GUIDE May 2018
 TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies
 Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology
Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology
CALMIP : HIGH PERFORMANCE COMPUTING
 CALMIP : HIGH PERFORMANCE COMPUTING Nicolas.renon@univ-tlse3.fr Emmanuel.courcelle@inp-toulouse.fr CALMIP (UMS 3667) Espace Clément Ader www.calmip.univ-toulouse.fr CALMIP :Toulouse University Computing
CALMIP : HIGH PERFORMANCE COMPUTING Nicolas.renon@univ-tlse3.fr Emmanuel.courcelle@inp-toulouse.fr CALMIP (UMS 3667) Espace Clément Ader www.calmip.univ-toulouse.fr CALMIP :Toulouse University Computing
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
GROMACS Performance Benchmark and Profiling. August 2011
 GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling August 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
SOLUTIONS BRIEF: Transformation of Modern Healthcare
 SOLUTIONS BRIEF: Transformation of Modern Healthcare Healthcare & The Intel Xeon Scalable Processor Intel is committed to bringing the best of our manufacturing, design and partner networks to enable our
SOLUTIONS BRIEF: Transformation of Modern Healthcare Healthcare & The Intel Xeon Scalable Processor Intel is committed to bringing the best of our manufacturing, design and partner networks to enable our
Game-changing Extreme GPU computing with The Dell PowerEdge C4130
 Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
The State of Accelerated Applications. Michael Feldman
 The State of Accelerated Applications Michael Feldman Accelerator Market in HPC Nearly half of all new HPC systems deployed incorporate accelerators Accelerator hardware performance has been advancing
The State of Accelerated Applications Michael Feldman Accelerator Market in HPC Nearly half of all new HPC systems deployed incorporate accelerators Accelerator hardware performance has been advancing
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Table of Contents: The Accelerated Data Center Optimizing Data Center Productivity Same Throughput with Fewer Server Nodes
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
AMBER 11 Performance Benchmark and Profiling. July 2011
 AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GPU computing at RZG overview & some early performance results. Markus Rampp
 GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
GPU computing at RZG overview & some early performance results Markus Rampp Introduction Outline Hydra configuration overview GPU software environment Benchmarking and porting activities Team Renate Dohmen
Approaches to acceleration: GPUs vs Intel MIC. Fabio AFFINITO SCAI department
 Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Approaches to acceleration: GPUs vs Intel MIC Fabio AFFINITO SCAI department Single core Multi core Many core GPU Intel MIC 61 cores 512bit-SIMD units from http://www.karlrupp.net/ from http://www.karlrupp.net/
Quantum ESPRESSO on GPU accelerated systems
 Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Quantum ESPRESSO on GPU accelerated systems Massimiliano Fatica, Everett Phillips, Josh Romero - NVIDIA Filippo Spiga - University of Cambridge/ARM (UK) MaX International Conference, Trieste, Italy, January
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications
 for Bio-Science Applications") Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
Scheduling Strategies for HPC as a Service (HPCaaS) for Bio-Science Applications Sep 2009 Gilad Shainer, Tong Liu (Mellanox); Jeffrey Layton (Dell); Joshua Mora (AMD) High Performance Interconnects for
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Porting Scalable Parallel CFD Application HiFUN on NVIDIA GPU
 Porting Scalable Parallel CFD Application NVIDIA D. V., N. Munikrishna, Nikhil Vijay Shende 1 N. Balakrishnan 2 Thejaswi Rao 3 1. S & I Engineering Solutions Pvt. Ltd., Bangalore, India 2. Aerospace Engineering,
Porting Scalable Parallel CFD Application NVIDIA D. V., N. Munikrishna, Nikhil Vijay Shende 1 N. Balakrishnan 2 Thejaswi Rao 3 1. S & I Engineering Solutions Pvt. Ltd., Bangalore, India 2. Aerospace Engineering,
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
Comparative Benchmarking of the First Generation of HPC-Optimised Arm Processors on Isambard
 Prof Simon McIntosh-Smith Isambard PI University of Bristol / GW4 Alliance Comparative Benchmarking of the First Generation of HPC-Optimised Arm Processors on Isambard Isambard system specification 10,000+
Prof Simon McIntosh-Smith Isambard PI University of Bristol / GW4 Alliance Comparative Benchmarking of the First Generation of HPC-Optimised Arm Processors on Isambard Isambard system specification 10,000+
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
HPC Issues for DFT Calculations. Adrian Jackson EPCC
 HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
GROMACS Performance Benchmark and Profiling. September 2012
 GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud
 Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud Summarized by: Michael Riera 9/17/2011 University of Central Florida CDA5532 Agenda
Amazon Web Services: Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud Summarized by: Michael Riera 9/17/2011 University of Central Florida CDA5532 Agenda
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Development of Intel MIC Codes in NWChem. Edoardo Aprà Pacific Northwest National Laboratory
 Development of Intel MIC Codes in NWChem Edoardo Aprà Pacific Northwest National Laboratory Acknowledgements! Karol Kowalski (PNNL)! Michael Klemm (Intel)! Kiran Bhaskaran-Nair (LSU)! Wenjing Ma (Chinese
Development of Intel MIC Codes in NWChem Edoardo Aprà Pacific Northwest National Laboratory Acknowledgements! Karol Kowalski (PNNL)! Michael Klemm (Intel)! Kiran Bhaskaran-Nair (LSU)! Wenjing Ma (Chinese
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
Accelerating Insights In the Technical Computing Transformation
 Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
Accelerating Insights In the Technical Computing Transformation Dr. Rajeeb Hazra Vice President, Data Center Group General Manager, Technical Computing Group June 2014 TOP500 Highlights Intel Xeon Phi
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor
 Simulations on the Intel Xeon Phi Processor") * Some names and brands may be claimed as the property of others. Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor E.J. Bylaska 1, M. Jacquelin
* Some names and brands may be claimed as the property of others. Performance Evaluation of NWChem Ab-Initio Molecular Dynamics (AIMD) Simulations on the Intel Xeon Phi Processor E.J. Bylaska 1, M. Jacquelin
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015
 HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
Introduction to High Performance Computing. Shaohao Chen Research Computing Services (RCS) Boston University
 Boston University") Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Fast Quantum Molecular Dynamics on Multi-GPU Architectures in LATTE
 Fast Quantum Molecular Dynamics on Multi-GPU Architectures in LATTE S. Mniszewski*, M. Cawkwell, A. Niklasson GPU Technology Conference San Jose, California March 18-21, 2013 *smm@lanl.gov Slide 1 Background:
Fast Quantum Molecular Dynamics on Multi-GPU Architectures in LATTE S. Mniszewski*, M. Cawkwell, A. Niklasson GPU Technology Conference San Jose, California March 18-21, 2013 *smm@lanl.gov Slide 1 Background:
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
LAMMPS Performance Benchmark and Profiling. July 2012
 LAMMPS Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
LAMMPS Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
IT4Innovations national supercomputing center. Branislav Jansík
 IT4Innovations national supercomputing center Branislav Jansík branislav.jansik@vsb.cz Anselm Salomon Data center infrastructure Anselm and Salomon Anselm Intel Sandy Bridge E5-2665 2x8 cores 64GB RAM
IT4Innovations national supercomputing center Branislav Jansík branislav.jansik@vsb.cz Anselm Salomon Data center infrastructure Anselm and Salomon Anselm Intel Sandy Bridge E5-2665 2x8 cores 64GB RAM
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
HECToR. UK National Supercomputing Service. Andy Turner & Chris Johnson
 HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Headline in Arial Bold 30pt. Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008
 Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem
Headline in Arial Bold 30pt Visualisation using the Grid Jeff Adie Principal Systems Engineer, SAPK July 2008 Agenda Visualisation Today User Trends Technology Trends Grid Viz Nodes Software Ecosystem
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Accelerating molecular docking on multi- and manycore computer architectures
 Accelerating molecular docking on multi- and manycore computer architectures Simon McIntosh-Smith University of Bristol, UK simonm@cs.bris.ac.uk 1 ! Power-limited regimes Processor power consumption now
Accelerating molecular docking on multi- and manycore computer architectures Simon McIntosh-Smith University of Bristol, UK simonm@cs.bris.ac.uk 1 ! Power-limited regimes Processor power consumption now
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS. Chris Butler NVIDIA
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Chris Butler NVIDIA Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of Chromatophores Chromatophore
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Chris Butler NVIDIA Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of Chromatophores Chromatophore
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Molecular Dynamics and Quantum Mechanics Applications
 Understanding the Performance of Molecular Dynamics and Quantum Mechanics Applications on Dell HPC Clusters High-performance computing (HPC) clusters are proving to be suitable environments for running
Understanding the Performance of Molecular Dynamics and Quantum Mechanics Applications on Dell HPC Clusters High-performance computing (HPC) clusters are proving to be suitable environments for running
Porting CASTEP to GPGPUs. Adrian Jackson, Toni Collis, EPCC, University of Edinburgh Graeme Ackland University of Edinburgh
 Porting CASTEP to GPGPUs Adrian Jackson, Toni Collis, EPCC, University of Edinburgh Graeme Ackland University of Edinburgh CASTEP Density Functional Theory Plane-wave basis set with pseudo potentials Heavy
Porting CASTEP to GPGPUs Adrian Jackson, Toni Collis, EPCC, University of Edinburgh Graeme Ackland University of Edinburgh CASTEP Density Functional Theory Plane-wave basis set with pseudo potentials Heavy