A Simple (?) Exercise: Predicting the Next Word
|
|
|
- Mariah Alison Davidson
- 5 years ago
- Views:
Transcription


1 CS Neural Networks for NLP A Simple (?) Exercise: Predicting the Next Word Graham Neubig Site
2 Are These Sentences OK? Jane went to the store. store to Jane went the. Jane went store. Jane goed to the store. The store went to Jane. The food truck went to Jane.
3 Calculating the Probability of a Sentence IY P (X) = P (x i x 1,...,x i 1 ) i=1 Next Word Context The big problem: How do we predict P (x i x 1,...,x i 1 )?!?!
4 Review: Count-based Language Models
5 Count-based Language Models Count up the frequency and divide: P ML (x i x i n+1,...,x i 1 ):= c(x i n+1,...,x i ) c(x i n+1,...,x i 1 ) Add smoothing, to deal with zero counts: P (x i x i n+1,...,x i 1 )= P ML (x i x i n+1,...,x i 1 ) +(1 )P (x i x 1 n+2,...,x i 1 ) Modified Kneser-Ney smoothing
6 A Refresher on Evaluation Log-likelihood: X LL(E test )= log P (E) E2E test Per-word Log Likelihood: 1 X WLL(E test )= P log P (E) E E2E test E2E test Per-word (Cross) Entropy: 1 X H(E test )= P log 2 P (E) Perplexity: E2E test E E2E test ppl(e test )=2 H(E test) = e WLL(E test)
7 What Can we Do w/ LMs? Score sentences: Jane went to the store. high store to Jane went the. low (same as calculating loss for training) Generate sentences: while didn t choose end-of-sentence symbol: calculate probability sample a new word from the probability distribution
8 Problems and Solutions? Cannot share strength among similar words she bought a car she purchased a car she bought a bicycle she purchased a bicycle solution: class based language models Cannot condition on context with intervening words Dr. Jane Smith Dr. Gertrude Smith solution: skip-gram language models Cannot handle long-distance dependencies for tennis class he wanted to buy his own racquet for programming class he wanted to buy his own computer solution: cache, trigger, topic, syntactic models, etc.
9 An Alternative: Featurized Log-Linear Models
10 An Alternative: Featurized Models Calculate features of the context Based on the features, calculate probabilities Optimize feature weights using gradient descent, etc.
11 Example: Previous words: giving a" a the talk gift b= w1,a= w2,giving= s= hat Words we re predicting How likely are they? How likely are they given prev. word is a? How likely are they given 2nd prev. word is giving? Total score
12 Softmax Convert scores into probabilities by taking the exponent and normalizing (softmax) P (x i x i 1 i 1 i n+1 )= es(x i x P x e s( x i x i 1 i i n+1 ) i n+1 ) s= p=
13 A Computation Graph View giving a lookup2 lookup1 bias scores + + = probs softmax Each vector is size of output vocabulary
14 A Note: Lookup Lookup can be viewed as grabbing a single vector from a big matrix of word embeddings vector size num. words lookup(2) Similarly, can be viewed as multiplying by a onehot vector num. words vector size * Former tends to be faster
15 Training a Model Reminder: to train, we calculate a loss function (a measure of how bad our predictions are), and move the parameters to reduce the loss The most common loss function for probabilistic models is negative log likelihood If element (or zero-indexed, 2) p= log is the correct answer:
16 Parameter Update Back propagation allows us to calculate the derivative of the loss with respect to Simple stochastic gradient descent optimizes parameters according to the
17 Choosing a Vocabulary
18 Unknown Words Necessity for UNK words We won t have all the words in the world in training data Larger vocabularies require more memory and computation time Common ways: Frequency threshold (usually UNK <= 1) Rank threshold
19 Evaluation and Vocabulary Important: the vocabulary must be the same over models you compare Or more accurately, all models must be able to generate the test set (it s OK if they can generate more than the test set, but not less) e.g. Comparing a character-based model to a word-based model is fair, but not vice-versa
20 Let s try it out! (loglin-lm.py)
21 What Problems are Handled? Cannot share strength among similar words she bought a car she purchased a car not solved yet she bought a bicycle she purchased a bicycle Cannot condition on context with intervening words Dr. Jane Smith Dr. Gertrude Smith solved! Cannot handle long-distance dependencies for tennis class he wanted to buy his own racquet for programming class he wanted to buy his own computer not solved yet
22 Beyond Linear Models
23 Linear Models can t Learn Feature Combinations farmers eat steak high farmers eat hay low cows eat steak low cows eat hay high These can t be expressed by linear features What can we do? Remember combinations as features (individual scores for farmers eat, cows eat ) Feature space explosion! Neural nets
24 Neural Language Models giving a (See Bengio et al. 2004) lookup lookup tanh( W1*h + b1) W + = softmax bias scores probs
25 Where is Strength Shared? giving lookup a lookup tanh( W1*h + b1) Similar output words get similar rows in in the softmax matrix Similar contexts get similar hidden states Word embeddings: W + = softmax Similar input words get similar vectors bias scores probs


26 What Problems are Handled? Cannot share strength among similar words she bought a car she purchased a car she bought a bicycle she purchased a bicycle solved, and similar contexts as well! Cannot condition on context with intervening words Dr. Jane Smith Dr. Gertrude Smith solved! Cannot handle long-distance dependencies for tennis class he wanted to buy his own racquet for programming class he wanted to buy his own computer not solved yet
27 Let s Try it Out! (nn-lm.py)
28 Tying Input/Output giving pick row a pick row Embeddings We can share parameters between the input and output embeddings (Press et al. 2016, inter alia) tanh( W1*h + b1) W + = softmax bias scores probs Want to try? Delete the input embeddings, and instead pick a row from the softmax matrix.
29 Training Tricks
30 Shuffling the Training Data Stochastic gradient methods update the parameters a little bit at a time What if we have the sentence I love this sentence so much! at the end of the training data 50 times? To train correctly, we should randomly shuffle the order at each time step
31 Other Optimization Options SGD with Momentum: Remember gradients from past time steps to prevent sudden changes Adagrad: Adapt the learning rate to reduce learning rate for frequently updated parameters (as measured by the variance of the gradient) Adam: Like Adagrad, but keeps a running average of momentum and gradient variance Many others: RMSProp, Adadelta, etc. (See Ruder 2016 reference for more details)
32 Early Stopping, Learning Rate Decay Neural nets have tons of parameters: we want to prevent them from over-fitting We can do this by monitoring our performance on held-out development data and stopping training when it starts to get worse It also sometimes helps to reduce the learning rate and continue training
33 Which One to Use? Adam is usually fast to converge and stable But simple SGD tends to do very will in terms of generalization You should use learning rate decay, (e.g. on Machine translation results by Denkowski & Neubig 2017)
34 Dropout Neural nets have lots of parameters, and are prone to overfitting Dropout: randomly zero-out nodes in the hidden layer with probability p at training time only x Because the number of nodes at training/test is different, scaling is necessary: Standard dropout: scale by p at test time x Inverted dropout: scale by 1/(1-p) at training time
35 Let s Try it Out! (nn-lm-optim.py)
36 Efficiency Tricks: Operation Batching
37 Efficiency Tricks: Mini-batching On modern hardware 10 operations of size 1 is much slower than 1 operation of size 10 Minibatching combines together smaller operations into one big one
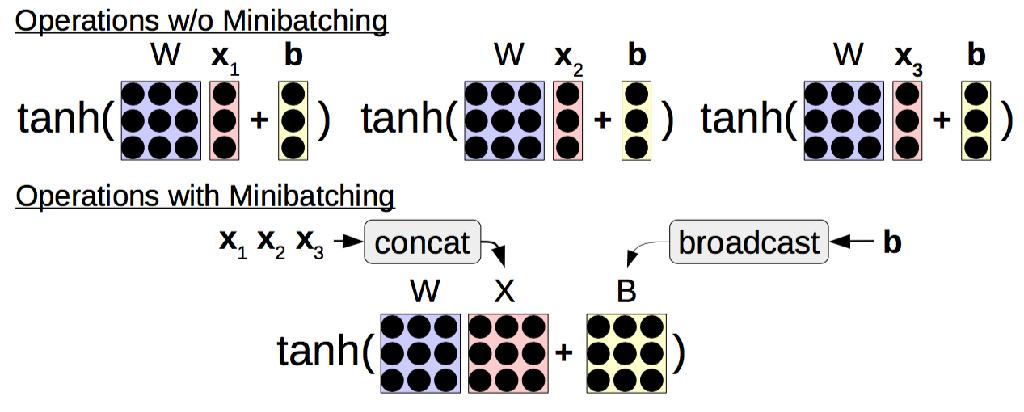
38 Minibatching
39 Manual Mini-batching Group together similar operations (e.g. loss calculations for a single word) and execute them all together In the case of a feed-forward language model, each word prediction in a sentence can be batched For recurrent neural nets, etc., more complicated DyNet has special minibatch operations for lookup and loss functions, everything else automatic
40 Mini-batched Code Example
41 Let s Try it Out! (nn-lm-batch.py)
42 Automatic Mini-batching! (see Neubig et al. 2017) Try it with the dynet-autobatch command line option
43 Autobatching Usage for each minibatch: for each data point in mini-batch: define/add data sum losses forward (autobatch engine does magic!) backward update
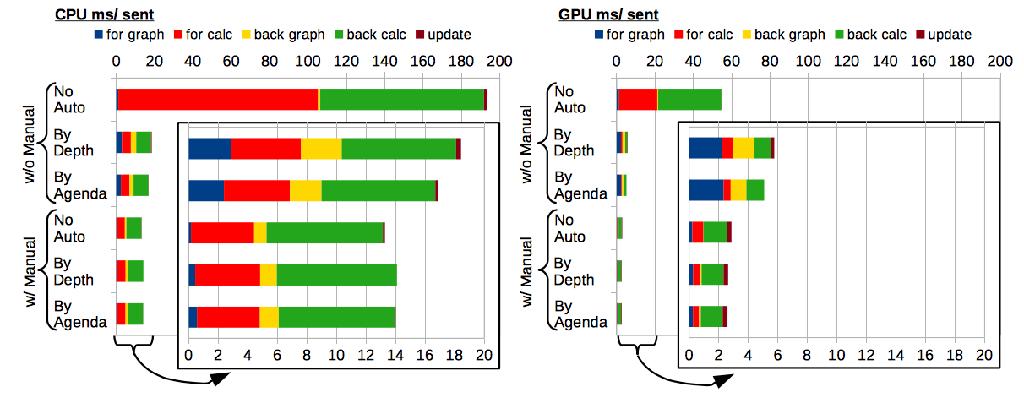
44 Speed Improvements
45 Questions?
Simple and Efficient Learning with Automatic Operation Batching
 Simple and Efficient Learning with Automatic Operation Batching Graham Neubig joint work w/ Yoav Goldberg and Chris Dyer in http://dynet.io/autobatch/ https://github.com/neubig/howtocode-2017 Neural Networks
Simple and Efficient Learning with Automatic Operation Batching Graham Neubig joint work w/ Yoav Goldberg and Chris Dyer in http://dynet.io/autobatch/ https://github.com/neubig/howtocode-2017 Neural Networks
Lecture 20: Neural Networks for NLP. Zubin Pahuja
 Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Lecture 20: Neural Networks for NLP Zubin Pahuja zpahuja2@illinois.edu courses.engr.illinois.edu/cs447 CS447: Natural Language Processing 1 Today s Lecture Feed-forward neural networks as classifiers simple
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Deep Learning. Practical introduction with Keras JORDI TORRES 27/05/2018. Chapter 3 JORDI TORRES
 Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Learning Practical introduction with Keras Chapter 3 27/05/2018 Neuron A neural network is formed by neurons connected to each other; in turn, each connection of one neural network is associated
Deep Neural Networks Optimization
 Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Deep Neural Networks Optimization Creative Commons (cc) by Akritasa http://arxiv.org/pdf/1406.2572.pdf Slides from Geoffrey Hinton CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy
Why is word2vec so fast? Efficiency tricks for neural nets
 CS11-747 Neural Networks for NLP Why is word2vec so fast? Efficiency tricks for neural nets Taylor Berg-Kirkpatrick Site https://phontron.com/class/nn4nlp2017/ Glamorous Life of an AI Scientist Perception
CS11-747 Neural Networks for NLP Why is word2vec so fast? Efficiency tricks for neural nets Taylor Berg-Kirkpatrick Site https://phontron.com/class/nn4nlp2017/ Glamorous Life of an AI Scientist Perception
Efficient Deep Learning Optimization Methods
 11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
11-785/ Spring 2019/ Recitation 3 Efficient Deep Learning Optimization Methods Josh Moavenzadeh, Kai Hu, and Cody Smith Outline 1 Review of optimization 2 Optimization practice 3 Training tips in PyTorch
CPSC 340: Machine Learning and Data Mining. Deep Learning Fall 2016
 CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CPSC 340: Machine Learning and Data Mining Deep Learning Fall 2016 Assignment 5: Due Friday. Assignment 6: Due next Friday. Final: Admin December 12 (8:30am HEBB 100) Covers Assignments 1-6. Final from
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
CS489/698: Intro to ML Lecture 14: Training of Deep NNs Instructor: Sun Sun 1 Outline Activation functions Regularization Gradient-based optimization 2 Examples of activation functions 3 5/28/18 Sun Sun
Gradient Descent. Wed Sept 20th, James McInenrey Adapted from slides by Francisco J. R. Ruiz
 Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Gradient Descent Wed Sept 20th, 2017 James McInenrey Adapted from slides by Francisco J. R. Ruiz Housekeeping A few clarifications of and adjustments to the course schedule: No more breaks at the midpoint
Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018
 INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
INF 5860 Machine learning for image classification Lecture : Training a neural net part I Initialization, activations, normalizations and other practical details Anne Solberg February 28, 2018 Reading
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent
 Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
Gradient Descent Optimization Algorithms for Deep Learning Batch gradient descent Stochastic gradient descent Mini-batch gradient descent Slide credit: http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
Convolutional Networks for Text
 CS11-747 Neural Networks for NLP Convolutional Networks for Text Graham Neubig Site https://phontron.com/class/nn4nlp2017/ An Example Prediction Problem: Sentence Classification I hate this movie very
CS11-747 Neural Networks for NLP Convolutional Networks for Text Graham Neubig Site https://phontron.com/class/nn4nlp2017/ An Example Prediction Problem: Sentence Classification I hate this movie very
Structured Prediction Basics
 CS11-747 Neural Networks for NLP Structured Prediction Basics Graham Neubig Site https://phontron.com/class/nn4nlp2017/ A Prediction Problem I hate this movie I love this movie very good good neutral bad
CS11-747 Neural Networks for NLP Structured Prediction Basics Graham Neubig Site https://phontron.com/class/nn4nlp2017/ A Prediction Problem I hate this movie I love this movie very good good neutral bad
CS 6501: Deep Learning for Computer Graphics. Training Neural Networks II. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
CS 6501: Deep Learning for Computer Graphics Training Neural Networks II Connelly Barnes Overview Preprocessing Initialization Vanishing/exploding gradients problem Batch normalization Dropout Additional
Multinomial Regression and the Softmax Activation Function. Gary Cottrell!
 Multinomial Regression and the Softmax Activation Function Gary Cottrell Notation reminder We have N data points, or patterns, in the training set, with the pattern number as a superscript: {(x 1,t 1 ),
Multinomial Regression and the Softmax Activation Function Gary Cottrell Notation reminder We have N data points, or patterns, in the training set, with the pattern number as a superscript: {(x 1,t 1 ),
Neural Network Optimization and Tuning / Spring 2018 / Recitation 3
 Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
Neural Network Optimization and Tuning 11-785 / Spring 2018 / Recitation 3 1 Logistics You will work through a Jupyter notebook that contains sample and starter code with explanations and comments throughout.
FastText. Jon Koss, Abhishek Jindal
 FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
FastText Jon Koss, Abhishek Jindal FastText FastText is on par with state-of-the-art deep learning classifiers in terms of accuracy But it is way faster: FastText can train on more than one billion words
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah
 Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Improving the way neural networks learn Srikumar Ramalingam School of Computing University of Utah Reference Most of the slides are taken from the third chapter of the online book by Michael Nielson: neuralnetworksanddeeplearning.com
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Sentiment Classification of Food Reviews
 Sentiment Classification of Food Reviews Hua Feng Department of Electrical Engineering Stanford University Stanford, CA 94305 fengh15@stanford.edu Ruixi Lin Department of Electrical Engineering Stanford
Sentiment Classification of Food Reviews Hua Feng Department of Electrical Engineering Stanford University Stanford, CA 94305 fengh15@stanford.edu Ruixi Lin Department of Electrical Engineering Stanford
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
CSC 578 Neural Networks and Deep Learning Fall 2018/19 7. Recurrent Neural Networks (Some figures adapted from NNDL book) 1 Recurrent Neural Networks 1. Recurrent Neural Networks (RNNs) 2. RNN Training
Recurrent Neural Nets II
 Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
Recurrent Neural Nets II Steven Spielberg Pon Kumar, Tingke (Kevin) Shen Machine Learning Reading Group, Fall 2016 9 November, 2016 Outline 1 Introduction 2 Problem Formulations with RNNs 3 LSTM for Optimization
A Neuro Probabilistic Language Model Bengio et. al. 2003
 A Neuro Probabilistic Language Model Bengio et. al. 2003 Class Discussion Notes Scribe: Olivia Winn February 1, 2016 Opening thoughts (or why this paper is interesting): Word embeddings currently have
A Neuro Probabilistic Language Model Bengio et. al. 2003 Class Discussion Notes Scribe: Olivia Winn February 1, 2016 Opening thoughts (or why this paper is interesting): Word embeddings currently have
Cost Functions in Machine Learning
 Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
Cost Functions in Machine Learning Kevin Swingler Motivation Given some data that reflects measurements from the environment We want to build a model that reflects certain statistics about that data Something
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling Authors: Junyoung Chung, Caglar Gulcehre, KyungHyun Cho and Yoshua Bengio Presenter: Yu-Wei Lin Background: Recurrent Neural
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling Authors: Junyoung Chung, Caglar Gulcehre, KyungHyun Cho and Yoshua Bengio Presenter: Yu-Wei Lin Background: Recurrent Neural
EE 511 Neural Networks
 Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Slides adapted from Ali Farhadi, Mari Ostendorf, Pedro Domingos, Carlos Guestrin, and Luke Zettelmoyer, Andrei Karpathy EE 511 Neural Networks Instructor: Hanna Hajishirzi hannaneh@washington.edu Computational
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
Neural Nets & Deep Learning
 Neural Nets & Deep Learning The Inspiration Inputs Outputs Our brains are pretty amazing, what if we could do something similar with computers? Image Source: http://ib.bioninja.com.au/_media/neuron _med.jpeg
Neural Nets & Deep Learning The Inspiration Inputs Outputs Our brains are pretty amazing, what if we could do something similar with computers? Image Source: http://ib.bioninja.com.au/_media/neuron _med.jpeg
How Learning Differs from Optimization. Sargur N. Srihari
 How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
How Learning Differs from Optimization Sargur N. srihari@cedar.buffalo.edu 1 Topics in Optimization Optimization for Training Deep Models: Overview How learning differs from optimization Risk, empirical
Conditioned Generation
 CS11-747 Neural Networks for NLP Conditioned Generation Graham Neubig Site https://phontron.com/class/nn4nlp2017/ Language Models Language models are generative models of text s ~ P(x) The Malfoys! said
CS11-747 Neural Networks for NLP Conditioned Generation Graham Neubig Site https://phontron.com/class/nn4nlp2017/ Language Models Language models are generative models of text s ~ P(x) The Malfoys! said
A Quick Guide on Training a neural network using Keras.
 A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
A Quick Guide on Training a neural network using Keras. TensorFlow and Keras Keras Open source High level, less flexible Easy to learn Perfect for quick implementations Starts by François Chollet from
11. Neural Network Regularization
 11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
11. Neural Network Regularization CS 519 Deep Learning, Winter 2016 Fuxin Li With materials from Andrej Karpathy, Zsolt Kira Preventing overfitting Approach 1: Get more data! Always best if possible! If
Neural Network Neurons
 Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
Neural Networks Neural Network Neurons 1 Receives n inputs (plus a bias term) Multiplies each input by its weight Applies activation function to the sum of results Outputs result Activation Functions Given
An Introduction to NNs using Keras
 An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
An Introduction to NNs using Keras Michela Paganini michela.paganini@cern.ch Yale University 1 Keras Modular, powerful and intuitive Deep Learning python library built on Theano and TensorFlow Minimalist,
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 8: Recurrent Neural Networks Christopher Manning and Richard Socher Organization Extra project office hour today after lecture Overview
Deep Learning Applications
 October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
October 20, 2017 Overview Supervised Learning Feedforward neural network Convolution neural network Recurrent neural network Recursive neural network (Recursive neural tensor network) Unsupervised Learning
CS535 Big Data Fall 2017 Colorado State University 10/10/2017 Sangmi Lee Pallickara Week 8- A.
 CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
CS535 Big Data - Fall 2017 Week 8-A-1 CS535 BIG DATA FAQs Term project proposal New deadline: Tomorrow PA1 demo PART 1. BATCH COMPUTING MODELS FOR BIG DATA ANALYTICS 5. ADVANCED DATA ANALYTICS WITH APACHE
Recurrent Neural Networks
 Recurrent Neural Networks 11-785 / Fall 2018 / Recitation 7 Raphaël Olivier Recap : RNNs are magic They have infinite memory They handle all kinds of series They re the basis of recent NLP : Translation,
Recurrent Neural Networks 11-785 / Fall 2018 / Recitation 7 Raphaël Olivier Recap : RNNs are magic They have infinite memory They handle all kinds of series They re the basis of recent NLP : Translation,
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Sparse Non-negative Matrix Language Modeling
 Sparse Non-negative Matrix Language Modeling Joris Pelemans Noam Shazeer Ciprian Chelba joris@pelemans.be noam@google.com ciprianchelba@google.com 1 Outline Motivation Sparse Non-negative Matrix Language
Sparse Non-negative Matrix Language Modeling Joris Pelemans Noam Shazeer Ciprian Chelba joris@pelemans.be noam@google.com ciprianchelba@google.com 1 Outline Motivation Sparse Non-negative Matrix Language
Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 10, 2017
 INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
INF 5860 Machine learning for image classification Lecture : Neural net: initialization, activations, normalizations and other practical details Anne Solberg March 0, 207 Mandatory exercise Available tonight,
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Dropout. Sargur N. Srihari This is part of lecture slides on Deep Learning:
 Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
Dropout Sargur N. srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties
CPSC 340: Machine Learning and Data Mining. Feature Selection Fall 2016
 CPSC 34: Machine Learning and Data Mining Feature Selection Fall 26 Assignment 3: Admin Solutions will be posted after class Wednesday. Extra office hours Thursday: :3-2 and 4:3-6 in X836. Midterm Friday:
CPSC 34: Machine Learning and Data Mining Feature Selection Fall 26 Assignment 3: Admin Solutions will be posted after class Wednesday. Extra office hours Thursday: :3-2 and 4:3-6 in X836. Midterm Friday:
JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS. Puyang Xu, Ruhi Sarikaya. Microsoft Corporation
 JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS Puyang Xu, Ruhi Sarikaya Microsoft Corporation ABSTRACT We describe a joint model for intent detection and slot filling based
JOINT INTENT DETECTION AND SLOT FILLING USING CONVOLUTIONAL NEURAL NETWORKS Puyang Xu, Ruhi Sarikaya Microsoft Corporation ABSTRACT We describe a joint model for intent detection and slot filling based
A Brief Look at Optimization
 A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
A Brief Look at Optimization CSC 412/2506 Tutorial David Madras January 18, 2018 Slides adapted from last year s version Overview Introduction Classes of optimization problems Linear programming Steepest
Natural Language Processing with Deep Learning CS224N/Ling284. Christopher Manning Lecture 4: Backpropagation and computation graphs
 Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
Natural Language Processing with Deep Learning CS4N/Ling84 Christopher Manning Lecture 4: Backpropagation and computation graphs Lecture Plan Lecture 4: Backpropagation and computation graphs 1. Matrix
COMP6237 Data Mining Data Mining & Machine Learning with Big Data. Jonathon Hare
 COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
COMP6237 Data Mining Data Mining & Machine Learning with Big Data Jonathon Hare jsh2@ecs.soton.ac.uk Contents Going to look at two case-studies looking at how we can make machine-learning algorithms work
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS
 LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Neural Networks Classifier Introduction INPUT: classification data, i.e. it contains an classification (class) attribute. WE also say that the class
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
CPSC 340: Machine Learning and Data Mining. Multi-Class Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
CPSC 340: Machine Learning and Data Mining Multi-Class Classification Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation
Deep Neural Networks Applications in Handwriting Recognition
 Deep Neural Networks Applications in Handwriting Recognition Théodore Bluche theodore.bluche@gmail.com São Paulo Meetup - 9 Mar. 2017 2 Who am I? Théodore Bluche PhD defended
Deep Neural Networks Applications in Handwriting Recognition Théodore Bluche theodore.bluche@gmail.com São Paulo Meetup - 9 Mar. 2017 2 Who am I? Théodore Bluche PhD defended
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /10/2017
 3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
3/0/207 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/0/207 Perceptron as a neural
CS281 Section 3: Practical Optimization
 CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
CS281 Section 3: Practical Optimization David Duvenaud and Dougal Maclaurin Most parameter estimation problems in machine learning cannot be solved in closed form, so we often have to resort to numerical
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset
 LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
LSTM: An Image Classification Model Based on Fashion-MNIST Dataset Kexin Zhang, Research School of Computer Science, Australian National University Kexin Zhang, U6342657@anu.edu.au Abstract. The application
SEMANTIC COMPUTING. Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) TU Dresden, 21 December 2018
 TU Dresden, 21 December 2018") SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
SEMANTIC COMPUTING Lecture 9: Deep Learning: Recurrent Neural Networks (RNNs) Dagmar Gromann International Center For Computational Logic TU Dresden, 21 December 2018 Overview Handling Overfitting Recurrent
Transition-Based Dependency Parsing with Stack Long Short-Term Memory
 Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Transition-Based Dependency Parsing with Stack Long Short-Term Memory Chris Dyer, Miguel Ballesteros, Wang Ling, Austin Matthews, Noah A. Smith Association for Computational Linguistics (ACL), 2015 Presented
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Lecture 2 Notes. Outline. Neural Networks. The Big Idea. Architecture. Instructors: Parth Shah, Riju Pahwa
 Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
Instructors: Parth Shah, Riju Pahwa Lecture 2 Notes Outline 1. Neural Networks The Big Idea Architecture SGD and Backpropagation 2. Convolutional Neural Networks Intuition Architecture 3. Recurrent Neural
The Mathematics Behind Neural Networks
 The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
The Mathematics Behind Neural Networks Pattern Recognition and Machine Learning by Christopher M. Bishop Student: Shivam Agrawal Mentor: Nathaniel Monson Courtesy of xkcd.com The Black Box Training the
Technical University of Munich. Exercise 8: Neural Networks
 Technical University of Munich Chair for Bioinformatics and Computational Biology Protein Prediction I for Computer Scientists SoSe 2018 Prof. B. Rost M. Bernhofer, M. Heinzinger, D. Nechaev, L. Richter
Technical University of Munich Chair for Bioinformatics and Computational Biology Protein Prediction I for Computer Scientists SoSe 2018 Prof. B. Rost M. Bernhofer, M. Heinzinger, D. Nechaev, L. Richter
Deep neural networks II
 Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
Deep neural networks II May 31 st, 2018 Yong Jae Lee UC Davis Many slides from Rob Fergus, Svetlana Lazebnik, Jia-Bin Huang, Derek Hoiem, Adriana Kovashka, Why (convolutional) neural networks? State of
EECS 496 Statistical Language Models. Winter 2018
 EECS 496 Statistical Language Models Winter 2018 Introductions Professor: Doug Downey Course web site: www.cs.northwestern.edu/~ddowney/courses/496_winter2018 (linked off prof. home page) Logistics Grading
EECS 496 Statistical Language Models Winter 2018 Introductions Professor: Doug Downey Course web site: www.cs.northwestern.edu/~ddowney/courses/496_winter2018 (linked off prof. home page) Logistics Grading
Ensemble methods in machine learning. Example. Neural networks. Neural networks
 Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
Ensemble methods in machine learning Bootstrap aggregating (bagging) train an ensemble of models based on randomly resampled versions of the training set, then take a majority vote Example What if you
CS 4510/9010 Applied Machine Learning
 CS 4510/9010 Applied Machine Learning Neural Nets Paula Matuszek Spring, 2015 1 Neural Nets, the very short version A neural net consists of layers of nodes, or neurons, each of which has an activation
CS 4510/9010 Applied Machine Learning Neural Nets Paula Matuszek Spring, 2015 1 Neural Nets, the very short version A neural net consists of layers of nodes, or neurons, each of which has an activation
Knowledge Discovery and Data Mining. Neural Nets. A simple NN as a Mathematical Formula. Notes. Lecture 13 - Neural Nets. Tom Kelsey.
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining
 Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
Knowledge Discovery and Data Mining Lecture 13 - Neural Nets Tom Kelsey School of Computer Science University of St Andrews http://tom.home.cs.st-andrews.ac.uk twk@st-andrews.ac.uk Tom Kelsey ID5059-13-NN
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 43 K-Means Clustering Example: Old Faithful Geyser
K-Means and Gaussian Mixture Models David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 43 K-Means Clustering Example: Old Faithful Geyser
Deep Neural Networks Applications in Handwriting Recognition
 Deep Neural Networks Applications in Handwriting Recognition 2 Who am I? Théodore Bluche PhD defended at Université Paris-Sud last year Deep Neural Networks for Large Vocabulary Handwritten
Deep Neural Networks Applications in Handwriting Recognition 2 Who am I? Théodore Bluche PhD defended at Université Paris-Sud last year Deep Neural Networks for Large Vocabulary Handwritten
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this course
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551 Unless otherwise noted, all material posted for this course
CS 4510/9010 Applied Machine Learning. Neural Nets. Paula Matuszek Fall copyright Paula Matuszek 2016
 CS 4510/9010 Applied Machine Learning 1 Neural Nets Paula Matuszek Fall 2016 Neural Nets, the very short version 2 A neural net consists of layers of nodes, or neurons, each of which has an activation
CS 4510/9010 Applied Machine Learning 1 Neural Nets Paula Matuszek Fall 2016 Neural Nets, the very short version 2 A neural net consists of layers of nodes, or neurons, each of which has an activation
Hyperparameter optimization. CS6787 Lecture 6 Fall 2017
 Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
CSC 2515 Introduction to Machine Learning Assignment 2
 CSC 2515 Introduction to Machine Learning Assignment 2 Zhongtian Qiu(1002274530) Problem 1 See attached scan files for question 1. 2. Neural Network 2.1 Examine the statistics and plots of training error
CSC 2515 Introduction to Machine Learning Assignment 2 Zhongtian Qiu(1002274530) Problem 1 See attached scan files for question 1. 2. Neural Network 2.1 Examine the statistics and plots of training error
Why DNN Works for Speech and How to Make it More Efficient?
 Why DNN Works for Speech and How to Make it More Efficient? Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering, York University, CANADA Joint work with Y.
Why DNN Works for Speech and How to Make it More Efficient? Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering, York University, CANADA Joint work with Y.
CS 224n: Assignment #3
 CS 224n: Assignment #3 Due date: 2/27 11:59 PM PST (You are allowed to use 3 late days maximum for this assignment) These questions require thought, but do not require long answers. Please be as concise
CS 224n: Assignment #3 Due date: 2/27 11:59 PM PST (You are allowed to use 3 late days maximum for this assignment) These questions require thought, but do not require long answers. Please be as concise
SGD: Stochastic Gradient Descent
 Improving SGD Hantao Zhang Deep Learning with Python Reading: http://neuralnetworksanddeeplearning.com/index.html Chapter 2 SGD: Stochastic Gradient Descent Main Idea: Given a set of input/output examples
Improving SGD Hantao Zhang Deep Learning with Python Reading: http://neuralnetworksanddeeplearning.com/index.html Chapter 2 SGD: Stochastic Gradient Descent Main Idea: Given a set of input/output examples
Deep Learning Workshop. Nov. 20, 2015 Andrew Fishberg, Rowan Zellers
 Deep Learning Workshop Nov. 20, 2015 Andrew Fishberg, Rowan Zellers Why deep learning? The ImageNet Challenge Goal: image classification with 1000 categories Top 5 error rate of 15%. Krizhevsky, Alex,
Deep Learning Workshop Nov. 20, 2015 Andrew Fishberg, Rowan Zellers Why deep learning? The ImageNet Challenge Goal: image classification with 1000 categories Top 5 error rate of 15%. Krizhevsky, Alex,
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Sequence Modeling: Recurrent and Recursive Nets. By Pyry Takala 14 Oct 2015
 Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Sequence Modeling: Recurrent and Recursive Nets By Pyry Takala 14 Oct 2015 Agenda Why Recurrent neural networks? Anatomy and basic training of an RNN (10.2, 10.2.1) Properties of RNNs (10.2.2, 8.2.6) Using
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Neural Network Learning. Today s Lecture. Continuation of Neural Networks. Artificial Neural Networks. Lecture 24: Learning 3. Victor R.
 Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
Lecture 24: Learning 3 Victor R. Lesser CMPSCI 683 Fall 2010 Today s Lecture Continuation of Neural Networks Artificial Neural Networks Compose of nodes/units connected by links Each link has a numeric
Memory Bandwidth and Low Precision Computation. CS6787 Lecture 10 Fall 2018
 Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
Memory Bandwidth and Low Precision Computation CS6787 Lecture 10 Fall 2018 Memory as a Bottleneck So far, we ve just been talking about compute e.g. techniques to decrease the amount of compute by decreasing
CS 224d: Assignment #1
 Due date: assignment) 4/19 11:59 PM PST (You are allowed to use three (3) late days maximum for this These questions require thought, but do not require long answers. Please be as concise as possible.
Due date: assignment) 4/19 11:59 PM PST (You are allowed to use three (3) late days maximum for this These questions require thought, but do not require long answers. Please be as concise as possible.
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS294-1 Assignment 2 Report
 CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
CS294-1 Assignment 2 Report Keling Chen and Huasha Zhao February 24, 2012 1 Introduction The goal of this homework is to predict a users numeric rating for a book from the text of the user s review. The
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
CS 179 Lecture 16. Logistic Regression & Parallel SGD
 CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
CS 179 Lecture 16 Logistic Regression & Parallel SGD 1 Outline logistic regression (stochastic) gradient descent parallelizing SGD for neural nets (with emphasis on Google s distributed neural net implementation)
Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné
 An overview by Philip Amortila and Nicolas Gagné") Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné 1 Problem: The usual "black box" story: "Despite their
Opening the black box of Deep Neural Networks via Information (Ravid Shwartz-Ziv and Naftali Tishby) An overview by Philip Amortila and Nicolas Gagné 1 Problem: The usual "black box" story: "Despite their
Machine Learning Basics. Sargur N. Srihari
 Machine Learning Basics Sargur N. srihari@cedar.buffalo.edu 1 Overview Deep learning is a specific type of ML Necessary to have a solid understanding of the basic principles of ML 2 Topics Stochastic Gradient
Machine Learning Basics Sargur N. srihari@cedar.buffalo.edu 1 Overview Deep learning is a specific type of ML Necessary to have a solid understanding of the basic principles of ML 2 Topics Stochastic Gradient
Neural Network Joint Language Model: An Investigation and An Extension With Global Source Context
 Neural Network Joint Language Model: An Investigation and An Extension With Global Source Context Ruizhongtai (Charles) Qi Department of Electrical Engineering, Stanford University rqi@stanford.edu Abstract
Neural Network Joint Language Model: An Investigation and An Extension With Global Source Context Ruizhongtai (Charles) Qi Department of Electrical Engineering, Stanford University rqi@stanford.edu Abstract
CS 124/LING 180/LING 280 From Languages to Information Week 2: Group Exercises on Language Modeling Winter 2018
 CS 124/LING 180/LING 280 From Languages to Information Week 2: Group Exercises on Language Modeling Winter 2018 Dan Jurafsky Tuesday, January 23, 2018 1 Part 1: Group Exercise We are interested in building
CS 124/LING 180/LING 280 From Languages to Information Week 2: Group Exercises on Language Modeling Winter 2018 Dan Jurafsky Tuesday, January 23, 2018 1 Part 1: Group Exercise We are interested in building
MoonRiver: Deep Neural Network in C++
 MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
MoonRiver: Deep Neural Network in C++ Chung-Yi Weng Computer Science & Engineering University of Washington chungyi@cs.washington.edu Abstract Artificial intelligence resurges with its dramatic improvement
Package automl. September 13, 2018
 Type Package Title Deep Learning with Metaheuristic Version 1.0.5 Author Alex Boulangé Package automl September 13, 2018 Maintainer Alex Boulangé Fits from
Type Package Title Deep Learning with Metaheuristic Version 1.0.5 Author Alex Boulangé Package automl September 13, 2018 Maintainer Alex Boulangé Fits from
Perceptron as a graph
 Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 10 th, 2007 2005-2007 Carlos Guestrin 1 Perceptron as a graph 1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0-6 -4-2
Neural Networks. Robot Image Credit: Viktoriya Sukhanova 123RF.com
 Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
Neural Networks These slides were assembled by Eric Eaton, with grateful acknowledgement of the many others who made their course materials freely available online. Feel free to reuse or adapt these slides
LSTM for Language Translation and Image Captioning. Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia
 1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
1 LSTM for Language Translation and Image Captioning Tel Aviv University Deep Learning Seminar Oran Gafni & Noa Yedidia 2 Part I LSTM for Language Translation Motivation Background (RNNs, LSTMs) Model
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right