Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words
|
|
|
- Daniela Gibson
- 5 years ago
- Views:
Transcription
1 1 Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words Juan Carlos Niebles 1,2, Hongcheng Wang 1, Li Fei-Fei 1 1 University of Illinois at Urbana-Champaign, Urbana, IL 61801, USA 2 Universidad del Norte, Barranquilla, Colombia {jnieble2,hwang13,feifeili}@uiuc.edu Abstract We present a novel unsupervised learning method for human action categories. A video sequence is represented as a collection of spatial-temporal words by extracting space-time interest points. The algorithm automatically learns the probability distributions of the spatial-temporal words and intermediate topics corresponding to human action categories. This is achieved by using a probabilistic Latent Semantic Analysis (plsa) model. Given a novel video sequence, the model can categorize and localize the human action(s) contained in the video. We test our algorithm on two challenging datasets: the KTH human action dataset and a recent dataset of figure skating actions. Our results are on par or slightly better than the best reported results. In addition, our algorithm can recognize and localize multiple actions in long and complex video sequences containing multiple motions. 1 Introduction Imagine a video taken on a sunny beach, can a computer automatically tell what is happening in the scene? Can it identify different human activities in the video, such as water surfing, beach volleyballs, or people taking a walk along the beach? To automatically categorize or localize different actions in video sequences is very useful for a variety of tasks, such as video surveillance, object-level video summarization, video indexing, digital library organization, etc. However, it remains a challenging task for computers to achieve robust action recognition due to cluttered background, camera motion, occlusion, and geometric and photometric variances of objects. For example, in a live video of a skating competition, the skater moves rapidly across the rink, and the camera also moves to follow the skater. With moving cameras, non-stationary background, and moving target, few vision algorithms could identify, categorize and localize such motions well (Figure 1(b)). In addition, the challenge is even greater when there are multiple activities in a complex video sequence (Figure 1(d)). In this paper, we will present an algorithm that aims to account for both of these scenarios. A lot of previous work has been presented to address these questions. One popular approach is to apply tracked motion trajectories of body parts to action recognition [15, 21, 1]. This is done with much human supervision and the robustness of the algorithm is highly dependent on the tracking system. Ke et al. [13] apply spatio-temporal volumetric feature that efficiently scan video sequences in space and time. Another approach is to use local space-time patches of videos [8]. Laptev et al. present a space-time BMVC 2006 doi: /c
 KTH dataset; (b) Figure skating dataset; (c) Caltech dataset; (d) Our own complex video sequence.")
![interest point detector based on the idea of the Harris and Förstner [14] interest point operators.](/docs-images/86/93955464/images/2-1.jpg "They detect local structures in space-time where the image values have significant local variations in both dimensions.")
![The representation has been successfully applied to human action recognition combined with an SVM classifier [17]. Dollár et al.](/docs-images/86/93955464/images/2-2.jpg "[7] propose an alternative approach to detect sparse space-time interest points based on separable linear filters for behavior recognition.")

![While these representations indicate good potentials, the modeling and learning frameworks are rather simple in the previous work [17, 7], posing a](/docs-images/86/93955464/images/2-4.jpg "problem toward handling more challenging situations such as multiple action recognition.")
![Another category of work is based on a probabilistic graphical model framework in action categorization/recognition. Song et al. [19] and Fanti et al.](/docs-images/86/93955464/images/2-5.jpg "[9] represent the human action model as a triangulated graph.")

![Boiman and Irani [4] recently propose to extract ensemble of local video patches to localize irregular action behavior in videos.](/docs-images/86/93955464/images/2-7.jpg "Dense sampling of the patches is necessary in their approach and therefore the algorithm is very time-consuming.")


2 2 walking boxing sit-spin (c) hand waving running camel-spin jogging hand clapping stand-spin (a) (b) (d) Figure 1: Example images from video sequences (a) KTH dataset; (b) Figure skating dataset; (c) Caltech dataset; (d) Our own complex video sequence. interest point detector based on the idea of the Harris and Förstner [14] interest point operators. They detect local structures in space-time where the image values have significant local variations in both dimensions. The representation has been successfully applied to human action recognition combined with an SVM classifier [17]. Dollár et al. [7] propose an alternative approach to detect sparse space-time interest points based on separable linear filters for behavior recognition. Local space-time patches, therefore, have been proven useful to provide semantic meaning of video events by providing a compact and abstract representation of patterns. While these representations indicate good potentials, the modeling and learning frameworks are rather simple in the previous work [17, 7], posing a problem toward handling more challenging situations such as multiple action recognition. Another category of work is based on a probabilistic graphical model framework in action categorization/recognition. Song et al. [19] and Fanti et al. [9] represent the human action model as a triangulated graph. Multiple cues such as position, velocities and appearance have been considered in learning and detection phases. Their idea is to map the human body parts in a frame-by-frame manner instead of utilizing space-time cubes for action recognition. Boiman and Irani [4] recently propose to extract ensemble of local video patches to localize irregular action behavior in videos. Dense sampling of the patches is necessary in their approach and therefore the algorithm is very time-consuming. It is not suitable for action recognition purpose due to the large amount of video data commonly presented in these settings. Another work named video epitomes is proposed by Cheung et al. [5]. They model the space-time cubes from a specific video by a generative model. The learned model is a compact representation of the original video, therefore this approach is suitable for video super-resolution and video interpolation, but not for recognition. In this paper, we propose a generative graphical model approach to learn and recognize human actions in video, taking advantage of the robust representation of spatial temporal words and an unsupervised approach during learning. Our method is motivated by the recent success of object detection/classification [18, 6] or scene categorization [10] from unlabeled static images. Two related models are generally used, i.e., probabilistic Latent Semantic Analysis (plsa) by Hofmann [12] and Latent Dirichlet Allocation (LDA) by Blei et al. [3]. In this paper, we choose to build a plsa model for video analysis by taking the advantages of the powerful representation and the great flexibility of the generative graphical model. The contributions of this work are as follows:
3 3 Input video sequences Feature extraction and description Feature extraction Form Codebook Represent each sequence as a bag of video words Learning Learn a model for each class Model 1 Class 1 Class Model N Class N Class N New sequence Feature extraction and description Decide on best model Recognition Figure 2: Flowchart of our approach. To represent motion patterns we first extract local space-time regions using the space-time interest points detector [7]. These local regions are then clustered into a set of video codewords, called codebook. Probability distributions and intermediate topics are learned automatically using a plsa graphical model. Unsupervised learning of actions using video words representation. We apply a plsa model with bag of video words representation for video analysis; Multiple action localization and categorization. Our approach is not only able to categorize different actions, but also to localize different actions simultaneously in a novel and complex video sequence. The rest of the paper is organized in the following way. In Section 2, we describe our approach in more details, including spatial-temporal feature representation, brief overview of the plsa model in our context, and the specifics of the learning and recognition procedures. In Section 3, we present the experimental results on human action recognition using real datasets, and also compare our performance with other methods. Multiple action recognition and localization results are presented to validate the learned model. Finally, Section 4 concludes the paper. 2 Our Approach Given a collection of unlabeled videos, our goal is to automatically learn different classes of actions present in the data, and apply the learned model to action categorization and localization in the new video sequences. Our approach is illustrated in Figure Feature Representation from Space-Time Interest Points As Figure 2 illustrates, we represent each video sequence as a collection of spatialtemporal words by extracting space-time interest points. There is a variety of methods for interest points detection in images [16]. But less work has been done on space-time interest point detection in videos. Blank et al. [2] represent actions as space-time shapes and extracted space-time features such as local space-time saliency, action dynamics, shape structures and orientation for action recognition. Laptev and Lindeberg [14] propose an extended version of the interest points detection in the spatial domain [11] into space-time
4 4 domain by requiring image values in space-time to have large variations in both dimensions. As noticed in [7] and from our experience, the interest points detected using the generalized space-time interest point detector are too sparse to characterize many complex videos such as figure skating sequences in our experiments. Therefore, we use the separable linear filter method in [7]. Here we give a brief review of this method. Assuming a stationary camera or a process that can account for camera motion, separable linear filters are applied to the video to obtain the response function as follows: R = (I g h ev ) 2 + (I g h od ) 2 (1) where g(x,y;σ) is the 2D Gaussian smoothing kernel, applied only along the spatial dimensions (x,y), and h ev and h od are a quadrature pair of 1D Gabor filters applied temporally, which are defined as h ev (t;τ,ω) = cos(2πtω)e t2 /τ 2 and h od (t;τ,ω) = sin(2πtω)e t2 /τ 2. The two parameters σ and τ correspond to the spatial and temporal scales of the detector respectively. In all cases we use ω = 4/τ, effectively giving the response function R. To handle multiple scales, one must run the detector over a set of spatial and temporal scales. For simplicity, we run the detector using only one scale and rely on the codebook to encode the few changes in scale that are observed in the dataset. It was noted in [7] that any region with spatially distinguishing characteristics undergoing a complex motion can induce a strong response. However, regions undergoing pure translational motion, or without spatially distinguishing features will not induce a strong response. The space-time interest points are extracted around the local maxima of the response function. Each patch contains the volume contributed to the response function, i.e., its size is approximately six times the scales along each dimension. To obtain a descriptor for each spatial-temporal cube, we calculate the brightness gradient and concatenate it to form a vector. This descriptor is then projected to a lower dimensional space using PCA. In [7], different descriptors have been used, such as normalized pixel values, brightness gradient and windowed optical flow. We found that both the gradient descriptor and the optical flow descriptor are equally effective in describing the motion information. For the rest of the paper, we will employ results obtained with gradient descriptors. 2.2 Learning the Action Models: Latent Topic Discovery In this section, we will describe the plsa graphical model in the context of video modeling. We follow the conventions introduced in [12, 18]. Suppose we have N( j = 1,,N) video sequences containing video words from a vocabulary of size M(i = 1,,M). The corpus of videos is summarized in an M by N co-occurrence table N, where n(w i,d j ) stores the number of occurrences of a word w i in video d j. In addition, there is a latent topic variable z k associated with each occurrence of a word w i in a video d i. Each topic corresponds to a motion category. The joint probability P(w i,d j,z k ) is assumed to have the form of the graphical model shown in Figure 3. P(d j,w i ) = P(d j )P(w i d j ) (2) Given that the observation pairs (d j,w i ) are assumed to be generated independently, we can marginalize over topics z k to obtain the conditional probability P(w i d j ): P(w i d j ) = K k=1 P(z k d j )P(w i z k ) (3) where P(z k d j ) is the probability of topic z k occurring in video d j ; and P(w i z k ) is the probability of video word w i occurring in a particular action category z k. K is the total number of latent topics, hence the number of action categories in our case.
5 5 walking, running, jogging... N W d P(d) d P(z d) z P(w z) w Figure 3: plsa graphical model. Nodes are random variables. Shaded ones are observed and unshaded ones are unobserved. The plates indicate repetitions. Intuitively, this model expresses each video sequence as a convex combination of K action category vectors, i.e., the video-specific word distributions P(w i d j ) are obtained by a convex combination of the aspects or action category vectors P(w i z k ). Videos are characterized by a specific mixture of factors with weights P(z k d j ). This amounts to a matrix decomposition with the constraint that both the vectors and mixture coefficients are normalized to make them probability distributions. Essentially, each video is modeled as a mixture of action categories - the histogram for a particular video being composed from a mixture of the histograms corresponding to each action category. We then fit the model by determining the action category vectors which are common to all videos and the mixture coefficients which are specific to each video. In order to determine the model that gives the high probability to the video words that appear in the corpus, a maximum likelihood estimation of the parameters is obtained by maximizing the objective function using an Expectation Maximization (EM) algorithm: M N i=1 j=1 P(w i d j ) n(w i,d j ) where P(w i d j ) is given by Equation Categorization and Localization of Actions in a Testing Video Our goal is to categorize new video sequences using learned action category models. We have obtained the action category specific video word distributions P(w z) from a different set of training sequences. When given a new video, the unseen video is projected on the simplex spanned by the learned P(w z). We need to find the mixing coefficients P(z k d test ) such that the KL divergence between the measured empirical distribution P(w d test ) and P(w d test ) = K k=1 P(z k d test )P(w z k ) is minimized [12, 18]. Similarly to the learning scenario, we apply an EM algorithm to find the solution. Furthermore, we are also interested in localizing multiple actions in a single video sequence. Though our bag-of-video-words model itself does not explicitly represent spatial relationship of local video regions, it is sufficiently discriminative to localize different motions within each video. This is similar to the approximate object segmentation case in [18]. The plsa model models the posteriors P(z k w i,d j ) = P(w i z k )P(z k d j ) K l=1 P(w i z l )P(z l d j ) For the video word around each interest point, we can label the topics for each word by finding the maximum posteriors P(z k w i,d j ). Then we can localize multiple actions (4) (5)
6 6 Table 1: Comparison of different methods methods recognition accuracy (%) learning multiple actions Our method unlabeled Yes Dollár et al. [7] labeled No Schuldt et al. [17] labeled No Ke et al. [13] labeled No corresponding to different action categories. 3 Experimental Results We test our algorithm using two datasets: KTH human motion dataset [17], and figure skating dataset [20]. These datasets contain videos of cluttered background, moving cameras, and multiple actions. We can handle the noisy feature points arisen from dynamic background and moving cameras by utilizing the probabilistic graphical model (plsa), as long as the background does not amount to an overwhelming number of feature points. In addition, we demonstrate multiple actions categorization and localization in a set of new videos collected by the authors. We present the datasets and experimental results in the following sections. 3.1 Recognition and Localization of Single Actions Human Action Recognition and Localization Using KTH data KTH human motion dataset is the largest available video sequence dataset of human actions [17]. Each video has only one action. The dataset contains six types of human actions (walking, jogging, running, boxing, hand waving and hand clapping) performed several times by 25 subjects in different scenarios of outdoor and indoor environment with scale change. It contains 598 sequences. Some sample images are shown in Figure 1. We build video codewords from two videos of each action from three subjects. Because the number of space-time patches used to extract the video codewords is usually very large, we randomly select a smaller number of space-time patches (around 60,000) to accommodate the requirements of memory. We perform leave-one-out cross-validation to test the efficacy of our approach in recognition, i.e., for each run we learn a model from the videos of 24 subjects (except those used to build codewords), and test the videos of the remaining subject. The three subjects used for forming the codebook are excluded from the testing. The result is reported as the average of 25 runs. The confusion matrix for a six-class model for the KTH dataset is given in Figure 4(a) using 500 codewords. It shows large confusion between running and jogging, as well as handclapping and boxing. This is consistent with our intuition that similar actions are more easily confused with each other, such as those involving hand motions or leg motions. We test the effect of the number of video codewords on recognition accuracy, as illustrated in Figure 4(b). As the size of codebook increases, the classification rate peaks at around 500. We also compare our results with the best results from [7]) (performance average = 81.17%) using Support Vector Machine (SVM) with the same experimental settings. Our results by unsupervised learning are on par with the current state-of-theart results obtained by fully supervised training. The comparison of different methods is listed in Table 1. We also test the LDA model [3] on this dataset, and find that plsa is slightly better than LDA in recognition performance with the same number of codewords. We apply the learned model to localize the actions for test videos in KTH dataset in Figure 5. We also test our action localization using the same model for the Caltech
 85 80 75 70 standspin sitspin.83.00.17.33.67.00.00.08.92 65.00.00.00.00.00 1.")

 confusion matrix for the figure skating dataset using 1200 codewords (performance average = 80.")

![human motion dataset [19] as shown in Figure 6(a). Most of the action sequences from this dataset can be correctly recognized.](/docs-images/86/93955464/images/7-4.jpg "For the clarity of presentation, we only draw the video words of the most probable topic with their corresponding color. 3.1.")
![2 Recognition and Localization of Figure Skating Actions We use the figure skating dataset in [20] 1.](/docs-images/86/93955464/images/7-5.jpg "We adapt 32 video sequences of 7 people each with three actions: stand-spin, camel-spin and sit-spin, as shown in Figure 1.")


7 7 walking running jogging camelspin handwaving hand clapping accuracy (%) standspin sitspin boxing walking running jogging hw hc boxing number of video codewords (a) (b) (c) stand-spin sit-spin camel-spin Figure 4: (a) confusion matrix for the KTH dataset using 500 codewords (performance average = 81.50%); horizontal lines are ground truth, and vertical columns are model results; (b) classification accuracy vs. codebook size for the KTH dataset; (c) confusion matrix for the figure skating dataset using 1200 codewords (performance average = 80.67%) walking boxing running hand clapping jogging hand waving Figure 5: The action categories are embedded into video frames using different colors. Most spatial-temporal words are labeled by the corresponding action color for each video. The figure is best viewed in color and with PDF magnification. human motion dataset [19] as shown in Figure 6(a). Most of the action sequences from this dataset can be correctly recognized. For the clarity of presentation, we only draw the video words of the most probable topic with their corresponding color Recognition and Localization of Figure Skating Actions We use the figure skating dataset in [20] 1. We adapt 32 video sequences of 7 people each with three actions: stand-spin, camel-spin and sit-spin, as shown in Figure 1. We build video codewords from the videos of six persons. We again perform leaveone-out cross-validation to test the efficacy of our approach in recognition, i.e., for each run we learn a model from the videos of six subjects, and test those of the remaining subject. The result is reported as the average of seven runs. The confusion matrix for a three-class model for the figure skating dataset is shown in Figure 4(c) using 1200 codewords. The larger size of codewords is useful to avoid overfitting of the generative model. The learned 3-class model is also used for action localization as shown in Figure 6(b). 3.2 Recognition and Localization of Multiple Actions in a Long Video Sequence One of the main goals of our work is to test how well our algorithm could identify multiple actions within a video sequence. For this purpose, we test several long figure skating sequences as well as our own complex video sequences. 1 This work addresses the problem of motion recognition from still images. There is much other work to model motion in still images, which is out of the scope of this paper.
 Examples from figure skating dataset with color-coded actions.")
.")






8 8 (a) Caltech Data walking running jogging boxing clapping waving (b) Figure Skating Data stand-spin sit-spin camel-spin Figure 6: (a) Examples from Caltech dataset with color-coded actions; (b) Examples from figure skating dataset with color-coded actions. The figure is best viewed in color and with PDF magnification. For multiple actions in a single sequence, we first identify how many action categories are significantly induced by P(z k w i,d j ). Then we apply K-means to find that number of clusters. By counting the number of video words within each cluster with respect to the action categories, we recognize the actions within that video. The bounding box is plotted according to the principle axis and eigen-values induced by the spatial distribution of video words in each cluster. Figure 7 illustrates examples of multiple actions recognition and localization in one video sequence using the learned six-class model. For the long skating video sequences, we extract a windowed sequence around each frame and identify significant actions using the learned three-class model. Then that frame is labeled as the identified action category. Figure 7 shows examples of action recognition in a long figure skating sequence. The three actions, i.e., stand-spin, camel-spin and sitspin, are correctly recognized and labeled using different colors. (Please refer to the link of video demo: 4 Conclusion In this paper, we have presented an unsupervised learning approach, i.e., a bag-of-videowords model combined with a space-time interest points detector, for human action categorization and localization. Using two challenging datasets, our experiments validate the proposed model in classification performance. Our algorithm can also localize multiple actions in complex motion sequences containing multiple actions. The results are promising, though we acknowledge the lack of large and challenging video datasets to thoroughly test our algorithm, which poses an interesting topic for future investigation. References [1] Ankur Agarwal and Bill Triggs. Learning to track 3d human motion from silhouettes. In International Conference on Machine Learning, pages 9 16, Banff, July [2] Moshe Blank, Lena Gorelick, Eli Shechtman, Michal Irani, and Ronen Basri. Actions as space-time shapes. In ICCV, pages , 2005.
9 9 [3] David M. Blei, Andrew Y. Ng, and Michael I. Jordan. Latent dirichlet allocation. Journal of Machine Learning Research, (3): , [4] Oren Boiman and Michal Irani. Detecting irregularities in images and in video. In Proceedings of International Conference on Computer Vision, volume 1, pages , [5] Vincent Cheung, Brendan J. Frey, and Nebojsa Jojic. Video epitomes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 1, pages 42 49, [6] Chris Dance, Jutta Willamowski, Lixin Fan, Cedric Bray, and Gabriela Csurka. Visual categorization with bags of keypoints. In ECCV International Workshop on Statistical Learning in Computer Vision, [7] Piotr Dollár, Vincent Rabaud, Garrison Cottrell, and Serge Belongie. Behavior recognition via sparse spatio-temporal features. In VS-PETS 2005, pages 65 72, [8] Alexei A. Efros, Alexander C. Berg, Greg Mori, and Jitendra Malik. Recognizing action at a distance. In IEEE International Conference on Computer Vision, pages , Nice, France, [9] Claudio Fanti, Lihi Zelnik-Manor, and Pietro Perona. Hybrid models for human motion recognition. In ICCV, volume 1, pages , [10] Li Fei-Fei and Pietro Perona. A bayesian hierarchical model for learning natural scene categories. In Proceedings of Computer Vision and Pattern Recognition, pages , [11] Chris Harris and Mike Stephens. A combined corner and edge detector. In Alvey Vision Conferences, pages , [12] Thomas Hofmann. Probabilistic latent semantic indexing. In SIGIR, pages 50 57, August [13] Yan Ke, Rahul Sukthankar, and Martial Hebert. Efficient visual event detection using volumetric features. In International Conference on Computer Vision, pages , [14] Ivan Laptev and Tony Lindeberg. Space-time interest points. In Proceedings of the ninth IEEE International Conference on Computer Vision, volume 1, pages , [15] Deva Ramanan and David A. Forsyth. Automatic annotation of everyday movements. In Sebastian Thrun, Lawrence Saul, and Bernhard Schölkopf, editors, Advances in Neural Information Processing Systems 16. MIT Press, Cambridge, MA, [16] Cordelia Schmid, Roger Mohr, and Christian Bauckhage. Evaluation of interest point detectors. International Journal of Computer Vision, 2(37): , [17] Christian Schuldt, Ivan Laptev, and Barbara Caputo. Recognizing human actions: A local svm approach. In ICPR, pages 32 36, [18] Josef Sivic, Bryan C. Russell, Alexei A. Efros, Andrew Zisserman, and William T. Freeman. Discovering objects and their location in images. In International Conference on Computer Vision (ICCV), pages , October [19] Yang Song, Luis Goncalves, and Pietro Perona. Unsupervised learning of human motion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(25):1 14, [20] Yang Wang, Hao Jiang, Mark S. Drew, Ze-Nian Li, and Greg Mori. Unsupervised discovery of action classes. In CVPR, [21] Alper Yilmaz and Mubarak Shah. Recognizing human actions in videos acquired by uncalibrated moving cameras. In IEEE International Conf. on Computer Vision (ICCV), volume 1, pages , 2005.


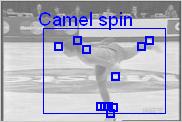

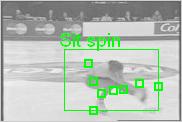





10 10 Figure 7: Multiple action recognition and localization in long and complex video sequences. The figure is best viewed in color and with PDF magnification.
Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words
 DOI 10.1007/s11263-007-0122-4 Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words Juan Carlos Niebles Hongcheng Wang Li Fei-Fei Received: 16 March 2007 / Accepted: 26 December
DOI 10.1007/s11263-007-0122-4 Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words Juan Carlos Niebles Hongcheng Wang Li Fei-Fei Received: 16 March 2007 / Accepted: 26 December
Spatial-Temporal correlatons for unsupervised action classification
 Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
A Hierarchical Model of Shape and Appearance for Human Action Classification
 A Hierarchical Model of Shape and Appearance for Human Action Classification Juan Carlos Niebles Universidad del Norte, Colombia University of Illinois at Urbana-Champaign, USA jnieble2@uiuc.edu Li Fei-Fei
A Hierarchical Model of Shape and Appearance for Human Action Classification Juan Carlos Niebles Universidad del Norte, Colombia University of Illinois at Urbana-Champaign, USA jnieble2@uiuc.edu Li Fei-Fei
Action Recognition & Categories via Spatial-Temporal Features
 Action Recognition & Categories via Spatial-Temporal Features 华俊豪, 11331007 huajh7@gmail.com 2014/4/9 Talk at Image & Video Analysis taught by Huimin Yu. Outline Introduction Frameworks Feature extraction
Action Recognition & Categories via Spatial-Temporal Features 华俊豪, 11331007 huajh7@gmail.com 2014/4/9 Talk at Image & Video Analysis taught by Huimin Yu. Outline Introduction Frameworks Feature extraction
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions
 Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Evaluation of Local Space-time Descriptors based on Cuboid Detector in Human Action Recognition
 International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
A Probabilistic Framework for Recognizing Similar Actions using Spatio-Temporal Features
 A Probabilistic Framework for Recognizing Similar Actions using Spatio-Temporal Features Alonso Patron-Perez, Ian Reid Department of Engineering Science, University of Oxford OX1 3PJ, Oxford, UK {alonso,ian}@robots.ox.ac.uk
A Probabilistic Framework for Recognizing Similar Actions using Spatio-Temporal Features Alonso Patron-Perez, Ian Reid Department of Engineering Science, University of Oxford OX1 3PJ, Oxford, UK {alonso,ian}@robots.ox.ac.uk
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Learning Human Motion Models from Unsegmented Videos
 In IEEE International Conference on Pattern Recognition (CVPR), pages 1-7, Alaska, June 2008. Learning Human Motion Models from Unsegmented Videos Roman Filipovych Eraldo Ribeiro Computer Vision and Bio-Inspired
In IEEE International Conference on Pattern Recognition (CVPR), pages 1-7, Alaska, June 2008. Learning Human Motion Models from Unsegmented Videos Roman Filipovych Eraldo Ribeiro Computer Vision and Bio-Inspired
Action Recognition using Randomised Ferns
 Action Recognition using Randomised Ferns Olusegun Oshin Andrew Gilbert John Illingworth Richard Bowden Centre for Vision, Speech and Signal Processing, University of Surrey Guildford, Surrey United Kingdom
Action Recognition using Randomised Ferns Olusegun Oshin Andrew Gilbert John Illingworth Richard Bowden Centre for Vision, Speech and Signal Processing, University of Surrey Guildford, Surrey United Kingdom
Learning Human Actions with an Adaptive Codebook
 Learning Human Actions with an Adaptive Codebook Yu Kong, Xiaoqin Zhang, Weiming Hu and Yunde Jia Beijing Laboratory of Intelligent Information Technology School of Computer Science, Beijing Institute
Learning Human Actions with an Adaptive Codebook Yu Kong, Xiaoqin Zhang, Weiming Hu and Yunde Jia Beijing Laboratory of Intelligent Information Technology School of Computer Science, Beijing Institute
 5*4%),-
5*4%),- Spatial Latent Dirichlet Allocation
 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Human Action Classification
 Human Action Classification M. G. Pallewar & M. M. Sardeshmukh E & TC Department, SAE Kondhwa, Pune, India E-mail : msyannawar@gmail.com & manojsar@rediffmail.com Abstract - Human action analysis is a
Human Action Classification M. G. Pallewar & M. M. Sardeshmukh E & TC Department, SAE Kondhwa, Pune, India E-mail : msyannawar@gmail.com & manojsar@rediffmail.com Abstract - Human action analysis is a
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Visual Object Recognition
 Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Discovering Primitive Action Categories by Leveraging Relevant Visual Context
 Discovering Primitive Action Categories by Leveraging Relevant Visual Context Kris M. Kitani, Takahiro Okabe, Yoichi Sato The University of Tokyo Institute of Industrial Science Tokyo 158-8505, Japan {kitani,
Discovering Primitive Action Categories by Leveraging Relevant Visual Context Kris M. Kitani, Takahiro Okabe, Yoichi Sato The University of Tokyo Institute of Industrial Science Tokyo 158-8505, Japan {kitani,
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Velocity adaptation of space-time interest points
 Velocity adaptation of space-time interest points Ivan Laptev and Tony Lindeberg Computational Vision and Active Perception Laboratory (CVAP) Dept. of Numerical Analysis and Computer Science KTH, SE-1
Velocity adaptation of space-time interest points Ivan Laptev and Tony Lindeberg Computational Vision and Active Perception Laboratory (CVAP) Dept. of Numerical Analysis and Computer Science KTH, SE-1
Comparing Local Feature Descriptors in plsa-based Image Models
 Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
Comparing Local Feature Descriptors in plsa-based Image Models Eva Hörster 1,ThomasGreif 1, Rainer Lienhart 1, and Malcolm Slaney 2 1 Multimedia Computing Lab, University of Augsburg, Germany {hoerster,lienhart}@informatik.uni-augsburg.de
Learning Human Actions via Information Maximization
 Learning Human Actions via Information Maximization Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu Mubarak Shah Computer Vision Lab University of Central Florida shah@cs.ucf.edu
Learning Human Actions via Information Maximization Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu Mubarak Shah Computer Vision Lab University of Central Florida shah@cs.ucf.edu
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Bag of Optical Flow Volumes for Image Sequence Recognition 1
 RIEMENSCHNEIDER, DONOSER, BISCHOF: BAG OF OPTICAL FLOW VOLUMES 1 Bag of Optical Flow Volumes for Image Sequence Recognition 1 Hayko Riemenschneider http://www.icg.tugraz.at/members/hayko Michael Donoser
RIEMENSCHNEIDER, DONOSER, BISCHOF: BAG OF OPTICAL FLOW VOLUMES 1 Bag of Optical Flow Volumes for Image Sequence Recognition 1 Hayko Riemenschneider http://www.icg.tugraz.at/members/hayko Michael Donoser
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Fast Realistic Multi-Action Recognition using Mined Dense Spatio-temporal Features
 Fast Realistic Multi-Action Recognition using Mined Dense Spatio-temporal Features Andrew Gilbert, John Illingworth and Richard Bowden CVSSP, University of Surrey, Guildford, Surrey GU2 7XH United Kingdom
Fast Realistic Multi-Action Recognition using Mined Dense Spatio-temporal Features Andrew Gilbert, John Illingworth and Richard Bowden CVSSP, University of Surrey, Guildford, Surrey GU2 7XH United Kingdom
Action Recognition from a Small Number of Frames
 Computer Vision Winter Workshop 2009, Adrian Ion and Walter G. Kropatsch (eds.) Eibiswald, Austria, February 4 6 Publisher: PRIP, Vienna University of Technology, Austria Action Recognition from a Small
Computer Vision Winter Workshop 2009, Adrian Ion and Walter G. Kropatsch (eds.) Eibiswald, Austria, February 4 6 Publisher: PRIP, Vienna University of Technology, Austria Action Recognition from a Small
Human Activity Recognition Using a Dynamic Texture Based Method
 Human Activity Recognition Using a Dynamic Texture Based Method Vili Kellokumpu, Guoying Zhao and Matti Pietikäinen Machine Vision Group University of Oulu, P.O. Box 4500, Finland {kello,gyzhao,mkp}@ee.oulu.fi
Human Activity Recognition Using a Dynamic Texture Based Method Vili Kellokumpu, Guoying Zhao and Matti Pietikäinen Machine Vision Group University of Oulu, P.O. Box 4500, Finland {kello,gyzhao,mkp}@ee.oulu.fi
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
Spatio-temporal Shape and Flow Correlation for Action Recognition
 Spatio-temporal Shape and Flow Correlation for Action Recognition Yan Ke 1, Rahul Sukthankar 2,1, Martial Hebert 1 1 School of Computer Science, Carnegie Mellon; 2 Intel Research Pittsburgh {yke,rahuls,hebert}@cs.cmu.edu
Spatio-temporal Shape and Flow Correlation for Action Recognition Yan Ke 1, Rahul Sukthankar 2,1, Martial Hebert 1 1 School of Computer Science, Carnegie Mellon; 2 Intel Research Pittsburgh {yke,rahuls,hebert}@cs.cmu.edu
Human activity recognition in the semantic simplex of elementary actions
 STUDENT, PROF, COLLABORATOR: BMVC AUTHOR GUIDELINES 1 Human activity recognition in the semantic simplex of elementary actions Beaudry Cyrille cyrille.beaudry@univ-lr.fr Péteri Renaud renaud.peteri@univ-lr.fr
STUDENT, PROF, COLLABORATOR: BMVC AUTHOR GUIDELINES 1 Human activity recognition in the semantic simplex of elementary actions Beaudry Cyrille cyrille.beaudry@univ-lr.fr Péteri Renaud renaud.peteri@univ-lr.fr
Vision and Image Processing Lab., CRV Tutorial day- May 30, 2010 Ottawa, Canada
 Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Evaluation of local descriptors for action recognition in videos
 Evaluation of local descriptors for action recognition in videos Piotr Bilinski and Francois Bremond INRIA Sophia Antipolis - PULSAR group 2004 route des Lucioles - BP 93 06902 Sophia Antipolis Cedex,
Evaluation of local descriptors for action recognition in videos Piotr Bilinski and Francois Bremond INRIA Sophia Antipolis - PULSAR group 2004 route des Lucioles - BP 93 06902 Sophia Antipolis Cedex,
CS395T Visual Recogni5on and Search. Gautam S. Muralidhar
 CS395T Visual Recogni5on and Search Gautam S. Muralidhar Today s Theme Unsupervised discovery of images Main mo5va5on behind unsupervised discovery is that supervision is expensive Common tasks include
CS395T Visual Recogni5on and Search Gautam S. Muralidhar Today s Theme Unsupervised discovery of images Main mo5va5on behind unsupervised discovery is that supervision is expensive Common tasks include
Behavior Recognition in Video with Extended Models of Feature Velocity Dynamics
 Behavior Recognition in Video with Extended Models of Feature Velocity Dynamics Ross Messing 1 1 Department of Computer Science University of Rochester Rochester, NY, 14627, USA {rmessing, cpal}@cs.rochester.edu
Behavior Recognition in Video with Extended Models of Feature Velocity Dynamics Ross Messing 1 1 Department of Computer Science University of Rochester Rochester, NY, 14627, USA {rmessing, cpal}@cs.rochester.edu
Selection of Scale-Invariant Parts for Object Class Recognition
 Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
HIGH spatial resolution Earth Observation (EO) images
 images") JOURNAL OF L A TEX CLASS FILES, VOL. 6, NO., JANUARY 7 A Comparative Study of Bag-of-Words and Bag-of-Topics Models of EO Image Patches Reza Bahmanyar, Shiyong Cui, and Mihai Datcu, Fellow, IEEE Abstract
JOURNAL OF L A TEX CLASS FILES, VOL. 6, NO., JANUARY 7 A Comparative Study of Bag-of-Words and Bag-of-Topics Models of EO Image Patches Reza Bahmanyar, Shiyong Cui, and Mihai Datcu, Fellow, IEEE Abstract
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Evaluation of local spatio-temporal features for action recognition
 Evaluation of local spatio-temporal features for action recognition Heng Wang, Muhammad Muneeb Ullah, Alexander Klaser, Ivan Laptev, Cordelia Schmid To cite this version: Heng Wang, Muhammad Muneeb Ullah,
Evaluation of local spatio-temporal features for action recognition Heng Wang, Muhammad Muneeb Ullah, Alexander Klaser, Ivan Laptev, Cordelia Schmid To cite this version: Heng Wang, Muhammad Muneeb Ullah,
EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION. Ing. Lorenzo Seidenari
 EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it What is an Event? Dictionary.com definition: something that occurs in a certain place during a particular
EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it What is an Event? Dictionary.com definition: something that occurs in a certain place during a particular
Learning Realistic Human Actions from Movies
 Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition
 Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor
 EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor Xiaodong Yang and YingLi Tian Department of Electrical Engineering The City College of New York, CUNY {xyang02, ytian}@ccny.cuny.edu
EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor Xiaodong Yang and YingLi Tian Department of Electrical Engineering The City College of New York, CUNY {xyang02, ytian}@ccny.cuny.edu
Human Action Recognition in Videos Using Hybrid Motion Features
 Human Action Recognition in Videos Using Hybrid Motion Features Si Liu 1,2, Jing Liu 1,TianzhuZhang 1, and Hanqing Lu 1 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
Human Action Recognition in Videos Using Hybrid Motion Features Si Liu 1,2, Jing Liu 1,TianzhuZhang 1, and Hanqing Lu 1 1 National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
Cross-View Action Recognition via a Transferable Dictionary Pair
 ZHENG et al:: CROSS-VIEW ACTION RECOGNITION 1 Cross-View Action Recognition via a Transferable Dictionary Pair Jingjing Zheng 1 zjngjng@umiacs.umd.edu Zhuolin Jiang 2 zhuolin@umiacs.umd.edu P. Jonathon
ZHENG et al:: CROSS-VIEW ACTION RECOGNITION 1 Cross-View Action Recognition via a Transferable Dictionary Pair Jingjing Zheng 1 zjngjng@umiacs.umd.edu Zhuolin Jiang 2 zhuolin@umiacs.umd.edu P. Jonathon
MoSIFT: Recognizing Human Actions in Surveillance Videos
 MoSIFT: Recognizing Human Actions in Surveillance Videos CMU-CS-09-161 Ming-yu Chen and Alex Hauptmann School of Computer Science Carnegie Mellon University Pittsburgh PA 15213 September 24, 2009 Copyright
MoSIFT: Recognizing Human Actions in Surveillance Videos CMU-CS-09-161 Ming-yu Chen and Alex Hauptmann School of Computer Science Carnegie Mellon University Pittsburgh PA 15213 September 24, 2009 Copyright
Space-Time Shapelets for Action Recognition
 Space-Time Shapelets for Action Recognition Dhruv Batra 1 Tsuhan Chen 1 Rahul Sukthankar 2,1 batradhruv@cmu.edu tsuhan@cmu.edu rahuls@cs.cmu.edu 1 Carnegie Mellon University 2 Intel Research Pittsburgh
Space-Time Shapelets for Action Recognition Dhruv Batra 1 Tsuhan Chen 1 Rahul Sukthankar 2,1 batradhruv@cmu.edu tsuhan@cmu.edu rahuls@cs.cmu.edu 1 Carnegie Mellon University 2 Intel Research Pittsburgh
Incremental Action Recognition Using Feature-Tree
 Incremental Action Recognition Using Feature-Tree Kishore K Reddy Computer Vision Lab University of Central Florida kreddy@cs.ucf.edu Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu
Incremental Action Recognition Using Feature-Tree Kishore K Reddy Computer Vision Lab University of Central Florida kreddy@cs.ucf.edu Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu
Person Action Recognition/Detection
 Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
How to find interesting locations in video: a spatiotemporal interest point detector learned from human eye movements
 How to find interesting locations in video: a spatiotemporal interest point detector learned from human eye movements Wolf Kienzle 1, Bernhard Schölkopf 1, Felix A. Wichmann 2,3, and Matthias O. Franz
How to find interesting locations in video: a spatiotemporal interest point detector learned from human eye movements Wolf Kienzle 1, Bernhard Schölkopf 1, Felix A. Wichmann 2,3, and Matthias O. Franz
Spatio-Temporal Optical Flow Statistics (STOFS) for Activity Classification
 for Activity Classification") Spatio-Temporal Optical Flow Statistics (STOFS) for Activity Classification Vignesh Jagadeesh University of California Santa Barbara, CA-93106 vignesh@ece.ucsb.edu S. Karthikeyan B.S. Manjunath University
Spatio-Temporal Optical Flow Statistics (STOFS) for Activity Classification Vignesh Jagadeesh University of California Santa Barbara, CA-93106 vignesh@ece.ucsb.edu S. Karthikeyan B.S. Manjunath University
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi
 Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Discovering Visual Hierarchy through Unsupervised Learning Haider Razvi hrazvi@stanford.edu 1 Introduction: We present a method for discovering visual hierarchy in a set of images. Automatically grouping
Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover
 Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover Devi Parikh and Tsuhan Chen Carnegie Mellon University {dparikh,tsuhan}@cmu.edu Abstract. Given a collection of
Unsupervised Identification of Multiple Objects of Interest from Multiple Images: discover Devi Parikh and Tsuhan Chen Carnegie Mellon University {dparikh,tsuhan}@cmu.edu Abstract. Given a collection of
ACTION RECOGNITION USING INTEREST POINTS CAPTURING DIFFERENTIAL MOTION INFORMATION
 ACTION RECOGNITION USING INTEREST POINTS CAPTURING DIFFERENTIAL MOTION INFORMATION Gaurav Kumar Yadav, Prakhar Shukla, Amit Sethi Department of Electronics and Electrical Engineering, IIT Guwahati Department
ACTION RECOGNITION USING INTEREST POINTS CAPTURING DIFFERENTIAL MOTION INFORMATION Gaurav Kumar Yadav, Prakhar Shukla, Amit Sethi Department of Electronics and Electrical Engineering, IIT Guwahati Department
Probabilistic Generative Models for Machine Vision
 Probabilistic Generative Models for Machine Vision bacciu@di.unipi.it Dipartimento di Informatica Università di Pisa Corso di Intelligenza Artificiale Prof. Alessandro Sperduti Università degli Studi di
Probabilistic Generative Models for Machine Vision bacciu@di.unipi.it Dipartimento di Informatica Università di Pisa Corso di Intelligenza Artificiale Prof. Alessandro Sperduti Università degli Studi di
Artistic ideation based on computer vision methods
 Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Basic Problem Addressed. The Approach I: Training. Main Idea. The Approach II: Testing. Why a set of vocabularies?
 Visual Categorization With Bags of Keypoints. ECCV,. G. Csurka, C. Bray, C. Dance, and L. Fan. Shilpa Gulati //7 Basic Problem Addressed Find a method for Generic Visual Categorization Visual Categorization:
Visual Categorization With Bags of Keypoints. ECCV,. G. Csurka, C. Bray, C. Dance, and L. Fan. Shilpa Gulati //7 Basic Problem Addressed Find a method for Generic Visual Categorization Visual Categorization:
Action Recognition in Low Quality Videos by Jointly Using Shape, Motion and Texture Features
 Action Recognition in Low Quality Videos by Jointly Using Shape, Motion and Texture Features Saimunur Rahman, John See, Chiung Ching Ho Centre of Visual Computing, Faculty of Computing and Informatics
Action Recognition in Low Quality Videos by Jointly Using Shape, Motion and Texture Features Saimunur Rahman, John See, Chiung Ching Ho Centre of Visual Computing, Faculty of Computing and Informatics
Harris-SIFT Descriptor for Video Event Detection based on a Machine Learning Approach
 Harris-SIFT Descriptor for Video Event Detection based on a Machine Learning Approach Guillermo Cámara-Chávez Computer Science Department Federal University of Ouro Preto Campus Universitário - Morro do
Harris-SIFT Descriptor for Video Event Detection based on a Machine Learning Approach Guillermo Cámara-Chávez Computer Science Department Federal University of Ouro Preto Campus Universitário - Morro do
Continuous Visual Vocabulary Models for plsa-based Scene Recognition
 Continuous Visual Vocabulary Models for plsa-based Scene Recognition Eva Hörster Multimedia Computing Lab University of Augsburg Augsburg, Germany hoerster@informatik.uniaugsburg.de Rainer Lienhart Multimedia
Continuous Visual Vocabulary Models for plsa-based Scene Recognition Eva Hörster Multimedia Computing Lab University of Augsburg Augsburg, Germany hoerster@informatik.uniaugsburg.de Rainer Lienhart Multimedia
Fast Motion Consistency through Matrix Quantization
 Fast Motion Consistency through Matrix Quantization Pyry Matikainen 1 ; Rahul Sukthankar,1 ; Martial Hebert 1 ; Yan Ke 1 The Robotics Institute, Carnegie Mellon University Intel Research Pittsburgh Microsoft
Fast Motion Consistency through Matrix Quantization Pyry Matikainen 1 ; Rahul Sukthankar,1 ; Martial Hebert 1 ; Yan Ke 1 The Robotics Institute, Carnegie Mellon University Intel Research Pittsburgh Microsoft
Fast Motion Consistency through Matrix Quantization
 Fast Motion Consistency through Matrix Quantization Pyry Matikainen; Rahul Sukthankar; Martial Hebert; Yan Ke Robotics Institute Carnegie Mellon University Pittsburgh, Pennsylvania, USA {pmatikai, rahuls}@cs.cmu.edu;
Fast Motion Consistency through Matrix Quantization Pyry Matikainen; Rahul Sukthankar; Martial Hebert; Yan Ke Robotics Institute Carnegie Mellon University Pittsburgh, Pennsylvania, USA {pmatikai, rahuls}@cs.cmu.edu;
Human Motion Detection and Tracking for Video Surveillance
 Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Action Snippets: How many frames does human action recognition require?
 Action Snippets: How many frames does human action recognition require? Konrad Schindler BIWI, ETH Zürich, Switzerland konrads@vision.ee.ethz.ch Luc van Gool, ESAT, KU Leuven, Belgium vangool@vision.ee.ethz.ch
Action Snippets: How many frames does human action recognition require? Konrad Schindler BIWI, ETH Zürich, Switzerland konrads@vision.ee.ethz.ch Luc van Gool, ESAT, KU Leuven, Belgium vangool@vision.ee.ethz.ch
Patch Descriptors. CSE 455 Linda Shapiro
 Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Part-based models. Lecture 10
 Part-based models Lecture 10 Overview Representation Location Appearance Generative interpretation Learning Distance transforms Other approaches using parts Felzenszwalb, Girshick, McAllester, Ramanan
Part-based models Lecture 10 Overview Representation Location Appearance Generative interpretation Learning Distance transforms Other approaches using parts Felzenszwalb, Girshick, McAllester, Ramanan
Unusual Activity Analysis using Video Epitomes and plsa
 Unusual Activity Analysis using Video Epitomes and plsa Ayesha Choudhary 1 Manish Pal 1 Subhashis Banerjee 1 Santanu Chaudhury 2 1 Dept. of Computer Science and Engineering, 2 Dept. of Electrical Engineering
Unusual Activity Analysis using Video Epitomes and plsa Ayesha Choudhary 1 Manish Pal 1 Subhashis Banerjee 1 Santanu Chaudhury 2 1 Dept. of Computer Science and Engineering, 2 Dept. of Electrical Engineering
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
Object Classification for Video Surveillance
 Object Classification for Video Surveillance Rogerio Feris IBM TJ Watson Research Center rsferis@us.ibm.com http://rogerioferis.com 1 Outline Part I: Object Classification in Far-field Video Part II: Large
Object Classification for Video Surveillance Rogerio Feris IBM TJ Watson Research Center rsferis@us.ibm.com http://rogerioferis.com 1 Outline Part I: Object Classification in Far-field Video Part II: Large
Class 5: Attributes and Semantic Features
 Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Efficient Kernels for Identifying Unbounded-Order Spatial Features
 Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Action Recognition with HOG-OF Features
 Action Recognition with HOG-OF Features Florian Baumann Institut für Informationsverarbeitung, Leibniz Universität Hannover, {last name}@tnt.uni-hannover.de Abstract. In this paper a simple and efficient
Action Recognition with HOG-OF Features Florian Baumann Institut für Informationsverarbeitung, Leibniz Universität Hannover, {last name}@tnt.uni-hannover.de Abstract. In this paper a simple and efficient
Using Geometric Blur for Point Correspondence
 1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels
 Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels Kai Guo, Prakash Ishwar, and Janusz Konrad Department of Electrical & Computer Engineering Motivation
Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels Kai Guo, Prakash Ishwar, and Janusz Konrad Department of Electrical & Computer Engineering Motivation
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
Dynamic Human Shape Description and Characterization
 Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
Recognition with Bag-ofWords. (Borrowing heavily from Tutorial Slides by Li Fei-fei)
") Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
Optical flow and tracking
 EECS 442 Computer vision Optical flow and tracking Intro Optical flow and feature tracking Lucas-Kanade algorithm Motion segmentation Segments of this lectures are courtesy of Profs S. Lazebnik S. Seitz,
EECS 442 Computer vision Optical flow and tracking Intro Optical flow and feature tracking Lucas-Kanade algorithm Motion segmentation Segments of this lectures are courtesy of Profs S. Lazebnik S. Seitz,
Distributed and Lightweight Multi-Camera Human Activity Classification
 Distributed and Lightweight Multi-Camera Human Activity Classification Gaurav Srivastava, Hidekazu Iwaki, Johnny Park and Avinash C. Kak School of Electrical and Computer Engineering Purdue University,
Distributed and Lightweight Multi-Camera Human Activity Classification Gaurav Srivastava, Hidekazu Iwaki, Johnny Park and Avinash C. Kak School of Electrical and Computer Engineering Purdue University,
Action Recognition by Learning Mid-level Motion Features
 Action Recognition by Learning Mid-level Motion Features Alireza Fathi and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {alirezaf,mori}@cs.sfu.ca Abstract This paper
Action Recognition by Learning Mid-level Motion Features Alireza Fathi and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {alirezaf,mori}@cs.sfu.ca Abstract This paper
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach
 Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Announcements. Recognition I. Gradient Space (p,q) What is the reflectance map?
 What is the reflectance map?") Announcements I HW 3 due 12 noon, tomorrow. HW 4 to be posted soon recognition Lecture plan recognition for next two lectures, then video and motion. Introduction to Computer Vision CSE 152 Lecture 17
Announcements I HW 3 due 12 noon, tomorrow. HW 4 to be posted soon recognition Lecture plan recognition for next two lectures, then video and motion. Introduction to Computer Vision CSE 152 Lecture 17
Patch-Based Image Classification Using Image Epitomes
 Patch-Based Image Classification Using Image Epitomes David Andrzejewski CS 766 - Final Project December 19, 2005 Abstract Automatic image classification has many practical applications, including photo
Patch-Based Image Classification Using Image Epitomes David Andrzejewski CS 766 - Final Project December 19, 2005 Abstract Automatic image classification has many practical applications, including photo
Using Multiple Segmentations to Discover Objects and their Extent in Image Collections
 Using Multiple Segmentations to Discover Objects and their Extent in Image Collections Bryan C. Russell 1 Alexei A. Efros 2 Josef Sivic 3 William T. Freeman 1 Andrew Zisserman 3 1 CS and AI Laboratory
Using Multiple Segmentations to Discover Objects and their Extent in Image Collections Bryan C. Russell 1 Alexei A. Efros 2 Josef Sivic 3 William T. Freeman 1 Andrew Zisserman 3 1 CS and AI Laboratory
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
A bipartite graph model for associating images and text
 A bipartite graph model for associating images and text S H Srinivasan Technology Research Group Yahoo, Bangalore, India. shs@yahoo-inc.com Malcolm Slaney Yahoo Research Lab Yahoo, Sunnyvale, USA. malcolm@ieee.org
A bipartite graph model for associating images and text S H Srinivasan Technology Research Group Yahoo, Bangalore, India. shs@yahoo-inc.com Malcolm Slaney Yahoo Research Lab Yahoo, Sunnyvale, USA. malcolm@ieee.org
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid Representation
 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) November 3-7, 2013. Tokyo, Japan An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid
2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) November 3-7, 2013. Tokyo, Japan An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid
1126 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 4, APRIL 2011
 1126 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 4, APRIL 2011 Spatiotemporal Localization and Categorization of Human Actions in Unsegmented Image Sequences Antonios Oikonomopoulos, Member, IEEE,
1126 IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 20, NO. 4, APRIL 2011 Spatiotemporal Localization and Categorization of Human Actions in Unsegmented Image Sequences Antonios Oikonomopoulos, Member, IEEE,
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task
 QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk