A PGAS implementation by co-design of the ECMWF Integrated Forecasting System. George Mozdzynski, ECMWF
|
|
|
- Prosper Hampton
- 5 years ago
- Views:
Transcription


1 A PGAS implementation by co-design of the ECMWF Integrated Forecasting System George Mozdzynski, ECMWF
")
2 Acknowledgements Mats Hamrud Nils Wedi Jens Doleschal Harvey Richardson ECMWF ECMWF Technische Universität Dresden Cray Research UK And my other partners in the CRESTA Project The CRESTA project has received funding from the EU Seventh Framework Programme (ICT )
3 What is CRESTA - see Collaborative Research into Exascale Systemware, Tools and Applications EU funded project, 3 years (year 1 just completed), ~ 50 scientists Six co-design vehicles (aka applications) ELMFIRE (CSC, ABO,UEDIN) - fusion plasma GROMACS (KTH) - molecular dynamics HEMELB (UCL) - biomedical IFS (ECMWF) - weather NEK5000 (KTH) & OPENFOAM (USTUTT, UEDIN) - comp. fluid dynamics Two tool suppliers ALLINEA (ddt : debugger ) & TUD (vampir : performance analysis ) Technology and system supplier CRAY UK Many Others (mostly universities) ABO, CRSA, CSC, DLR, JYU, KTH, UCL, UEDIN-EPCC, USTUTT-HRLS
4 IFS model: current and planned model resolutions IFS model resolution Envisaged Operational Implementation Grid point spacing (km) Time-step (seconds) Estimated number of cores 1 T1279 H (L91) 2012 (L137) T2047 H K T3999 NH K T7999 NH M 1 - a gross estimate for the number of Power7 equivalent cores needed to achieve a 10 day model forecast in under 1 hour (~240 FD/D), system size would normally be 10 times this number. 2 Hydrostatic Dynamics 3 Non-Hydrostatic Dynamics
5 Compute Total Thank you to Nils Wedi for providing this figure % cost of Spectral Transforms on IBM Power L91 (H) 2047 L91 (H) 2047 L L L L40
6 Planned IFS optimisations for [Tera,Peta,Exa]scale trgtol FTDIR Grid-point space -semi-lagrangian advection -physics -radiation -GP dynamics trltog FTINV Fourier space trltom LTDIR Spectral space -horizontal gradients -semi-implicit calculations -horizontal diffusion Fourier space LTINV trmtol
7 Semi-Lagrangian Transport Computation of a trajectory from each grid-point backwards in time, and Interpolation of various quantities at the departure and at the mid-point of the trajectory arrival Ÿ Ÿ Ÿ Ÿ x Ÿ mid-point Slide 7 Ÿ Ÿ x Ÿ Ÿ MPI task partition departure
 during a 10 day forecast starting 15 Oct 2004")
8 Semi-Lagrangian Transport: T799 model, 256 tasks Task 11 encountered the highest wind speed of 120 m/s (268 mph) during a 10 day forecast starting 15 Oct 2004 Slide 8
 from neighbour tasks to determine departure and mid-point of trajectory")
9 blue: halo area Halo width assumes a maximum wind speed of 400 m/s x 720 s T799 time-step (288 km) Get u,v,w wind vector variables (3) from neighbour tasks to determine departure and mid-point of trajectory Slide 9
10 red: halo points actually used Get rest of the variables (26) from the red halo area and perform interpolations Note that volume of halo data communicated is dependent on wind speed and direction in locality of each task Slide 10
11 IFS Optimisations for ExaScale & Co-design All currently planned IFS optimisations in the CRESTA project Involve use of Fortran2008 coarrays (CAF) Used within context of OpenMP parallel regions Overlap Legendre transforms with associated transpositions Overlap Fourier transforms with associated transpositions Rework semi-lagrangian communications To substantially reduce communicated halo data To overlap halo communications with SL interpolations CAF co-design team ECMWF optimise IFS as described above CRAY optimize DMAPP to be thread safe TUD visualize CAF operations in IFS with vampir ALLINEA debug IFS at scale with ddt (MPI/OMP/CAF)
12 Overlap Legendre transforms with associated transpositions LTINV TRMTOL (MPI_alltoallv) OLD LTINV + coarray puts NEW time
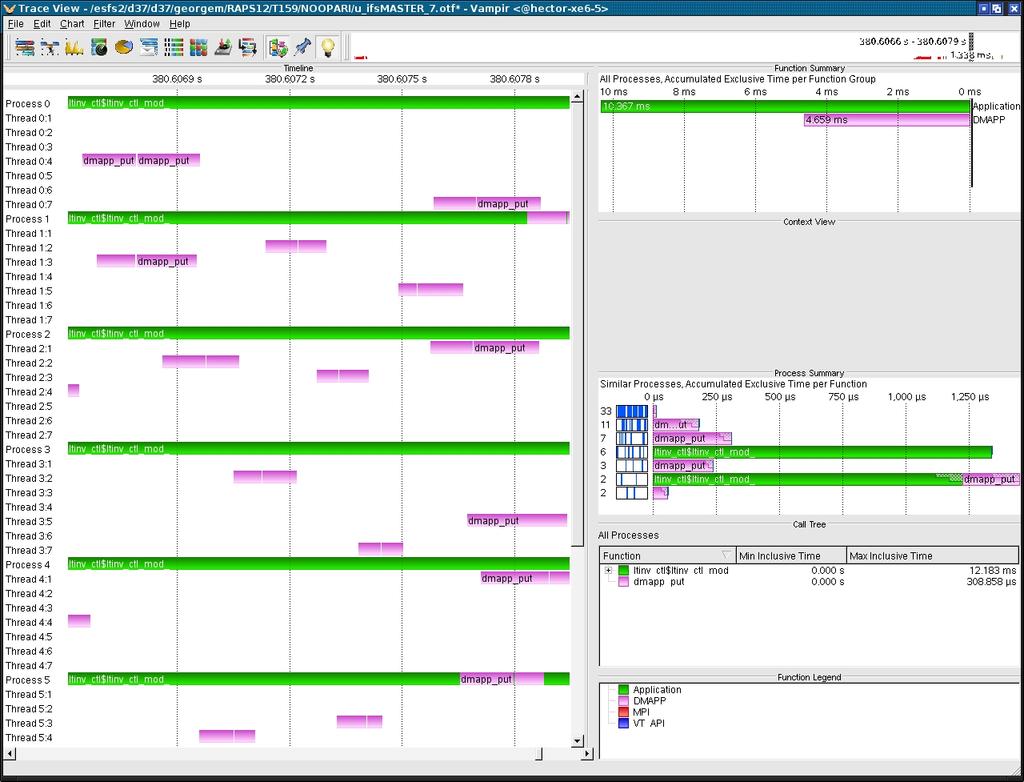
13 Overlap Legendre transforms with associated transpositions/3 (LTINV + coarray puts) Expectation is that compute (LTINV-blue) and communication (coarray puts-yellow) overlap in time. We should be able to see this in the future with an extension to vampir being developed in CRESTA
 and associated overhead.")
14 Semi-Lagrangian coarray implementation red: only the halo points that are used are communicated Note no more blue area (max wind halo) and associated overhead. Also, halo coarray transfers take place in same OpenMP loop as the interpolations.
15 T2047L137 model performance on HECToR (CRAY XE6) RAPS12 IFS (CY37R3), cce= APRIL Forecast Days / Day Ideal CRESTA ORIGINAL Number of Cores Operational performance requirement
16 T2047L137 model performance on HECToR (CRAY XE6) RAPS12 IFS (CY37R3), cce= hflex_mp=intolerant 700 SEPT Forecast Days / Day Ideal LCOARRAYS=T LCOARRAYS=F 100 Operational performance requirement Number of Cores
17 25% T2047L137 IFS model performance improvment by using Fortran2008 coarrays on HECToR (CRAY XE6) SEPT % Performance Improvement 15% 10% 5% 0% Number of Cores
18 100% T2047L137 model Efficiency on HECToR (CRAY XE6) RAPS12 IFS (CY37R3) 90% 80% 70% Efficiency 60% 50% 40% LCOARRAYS=T LCOARRAYS=F Original 30% 20% 10% 0% Number of Cores

19
20 Schedule for IFS optimisations in CRESTA When Activity 4Q2011-1Q2012 Coarray Kernel 1Q2012 IFS CY37R3 port to HECToR Run T2047 model at scale and analyze performance 2Q2012 3Q2012 Scalability improvements arising from T2047 analyses ( low hanging fruit ) Overlap Legendre transform computations with associated TRMTOL & TRLTOM transpositions Semi-Lagrangian optimisation Overlap TRGTOL & TRLTOG transpositions with associated Fourier transforms 4Q2012 RAPS13 IFS CY38R2 port to HECToR (contains Fast Legendre Transform) T3999 model runs on HECToR Test with IBM F2008 coarray technology preview compiler on Power7 at ECMWF 1Q2013 Use coarrays to optimise TRMTOS/TRSTOM transpositions Initial use of GPUs for IFS (targeting LTDIR/LTDIR dgemm s) Other IFS scalability optimisations (transpose SL data, physics load balancing, +++) Development & testing of a future solver for IFS (Plan B) Following closely developments in GungHO! project (MetOffice, NERC, STFC) GungHO=Globally Uniform Next Generation Highly Optimised

21 Thank you for your attention QUESTIONS? Slide 21
22 IFS model coarray developments Compile with DCOARRAYS for compilers that support Fortran2008 coarray syntax Run with, &NAMPAR1 LCOARRAYS=true, to use coarray optimizations &NAMPAR1 LCOARRAYS=false, to use original MPI implementation
23 Motivation T2047 and T3999 costs on IBM Power7 (percentage of wall clock time) T2047(%) T3999(%) LTINV_CTL - INVERSE LEGENDRE TRANSFORM LTINV_CTL - M TO L TRANSPOSITION LTDIR_CTL - DIRECT LEGENDRE TRANSFORM LTDIR_CTL - L TO M TRANSPOSITION FTDIR_CTL - DIRECT FOURIER TRANSFORM FTDIR_CTL - G TO L TRANSPOSITION FTINV_CTL - INVERSE FOURIER TRANSFORM FTINV_CTL - L TO G TRANSPOSITION SUM(%) L137/LT L91/FLT 4224Tx8t 1024Tx16t 528 Nodes 256 Nodes 470 FD/D 28 FD/D
24 Compute Total L91 (H) 2047 L91 (H) 2047 L L L L40 Relative computational cost of the spherical harmonics transforms plus the spectral computations (solving the Helmholtz equation) as a percentage of the overall model cost for various configurations. Red bars indicate the total cost including the global communications involved. Percentages have been derived considering all gridpoint dynamics and physics computations but without considering IO, synchronization costs (barriers), and any other ancillary costs. All runs are non-hydrostatic unless indicated with (H). All runs further show that the communications cost is less than or equal to the compute cost on the IBM Power7 and have good potential for hiding this overhead. However, communication cost is likely to increase with the number of cores.
25 Planned IFS optimisations for [Tera,Peta,Exa]scale trgtol FTDIR Grid-point space -semi-lagrangian advection -physics -radiation -GP dynamics trltog FTINV Fourier space trltom LTDIR Spectral space -horizontal gradients -semi-implicit calculations -horizontal diffusion Fourier space LTINV trmtol

26

27
28
29
30

31
32 Other Fortran 2008 compilers License finally agreed with IBM ECMWF will install xlf v14 compiler on Power7 Only took 1 year from first inquiry (pre-cresta) Subject to non-disclosure Am sure we will be granted permission to present and publish results if they are good Plan is first to test IFS RAPS12 with this compiler Promoting need for Fortran 2008 to vendors is important Intel? Fujitsu? gfortran? PGI?
33 Using HECToR Moved IFS from cce=8.0.3 to cce=8.0.6 To pick up fix to random hangs at start of job Job would run to cp time limit without executing a single application statement Refunded lost KAu s also fixed a couple of random coarray runtime failures Thanks to CRAY for providing a good compiler release Multiple aprun s in high core count jobs (10K to 64K cores) To improve overall system resource utilization Small, medium and large batched jobs Some waste due to unused cores in each job Promise of refund (more KAus) at some time in future
34 Hybrid runtime support - IFS Initial IFS MPI implementation Hybrid MPI/OpenMP implementation ~1999 OpenMP implementation at highest level Single parallel regions for each of physics, radiation scheme, dynamics, Legendre transforms, Fourier transforms and Fourier space computations Schedule dynamic used in most parallel regions OpenMP for IFS T1279L91 model on IBM Power6 (~2009) Hybrid implementation benefits About 20 percent performance improvement at scale Huge memory savings, memory use reduces linearly with number of OpenMP threads Next evolutionary step: use of Fortran 2008 coarrays to Overlap computation with communication in transpositions Fourier space <-> Spectral space comms, overlapped with Legendre transforms grid point space <-> Fourier space comms, overlapped with FFTs and Fourier space computations Reduce total halo communication in semi-lagrangian scheme Dominant coarray communications in OpenMP parallel regions Speed-up threads 8 threads 16 threads Nodes
35 OpenMP for IFS T1279L91 model on IBM Power6 (~2009) Speed-up threads 8 threads 16 threads Nodes

36 ECMWF An independent intergovernmental organisation established in 1975 with 19 Member States 15 Co-operating States
37 IFS model speedup on IBM Power6 (~2010) Speedup ideal T2047 T Operational performance requirement (10 day forecast in under one hour) User Threads (cores*2)







38 HPC in Meteorology workshop, 1-5 October 2012
39 Overlap Legendre transforms with associated transpositions/2 TRLTOM(MPI_alltoallv) LTDIR OLD coarray gets + LTDIR NEW time


40 IFS grid point space: EQ_REGIONS partitioning for 1024 MPI tasks Each MPI task has an equal number of grid points Slide 40
41 LTINV recoding COMPUTE COMMUNICATION!$OMP PARALLEL DO SCHEDULE(DYNAMIC,1) PRIVATE(JM,IM) DO JM=1,D%NUMP IM = D%MYMS(JM) CALL LTINV(IM,JM,KF_OUT_LT,KF_UV,KF_SCALARS,KF_SCDERS,ILEI2,IDIM1,& & PSPVOR,PSPDIV,PSPSCALAR,& & PSPSC3A,PSPSC3B,PSPSC2, & & KFLDPTRUV,KFLDPTRSC,FSPGL_PROC) ENDDO!$OMP END PARALLEL DO DO J=1,NPRTRW ILENS(J) = D%NLTSFTB(J)*IFIELD IOFFS(J) = D%NSTAGT0B(J)*IFIELD ILENR(J) = D%NLTSGTB(J)*IFIELD IOFFR(J) = D%NSTAGT0B(D%MSTABF(J))*IFIELD ENDDO ORIGINAL code CALL MPL_ALLTOALLV(PSENDBUF=FOUBUF_IN,KSENDCOUNTS=ILENS,& & PRECVBUF=FOUBUF,KRECVCOUNTS=ILENR,& & KSENDDISPL=IOFFS,KRECVDISPL=IOFFR,& & KCOMM=MPL_ALL_MS_COMM,CDSTRING='TRMTOL:')!$OMP PARALLEL DO SCHEDULE(DYNAMIC,1) PRIVATE(JM,IM,JW,IPE,ILEN,ILENS,IOFFS,IOFFR) DO JM=1,D%NUMP IM = D%MYMS(JM) CALL LTINV(IM,JM,KF_OUT_LT,KF_UV,KF_SCALARS,KF_SCDERS,ILEI2,IDIM1,& & PSPVOR,PSPDIV,PSPSCALAR,& & PSPSC3A,PSPSC3B,PSPSC2, & & KFLDPTRUV,KFLDPTRSC,FSPGL_PROC) DO JW=1,NPRTRW CALL SET2PE(IPE,0,0,JW,MYSETV) ILEN = D%NLEN_M(JW,1,JM)*IFIELD IF( ILEN > 0 )THEN IOFFS = (D%NSTAGT0B(JW)+D%NOFF_M(JW,1,JM))*IFIELD IOFFR = (D%NSTAGT0BW(JW,MYSETW)+D%NOFF_M(JW,1,JM))*IFIELD FOUBUF_C(IOFFR+1:IOFFR+ILEN)[IPE]=FOUBUF_IN(IOFFS+1:IOFFS+ILEN) ENDIF ILENS = D%NLEN_M(JW,2,JM)*IFIELD IF( ILENS > 0 )THEN IOFFS = (D%NSTAGT0B(JW)+D%NOFF_M(JW,2,JM))*IFIELD IOFFR = (D%NSTAGT0BW(JW,MYSETW)+D%NOFF_M(JW,2,JM))*IFIELD FOUBUF_C(IOFFR+1:IOFFR+ILENS)[IPE]=FOUBUF_IN(IOFFS+1:IOFFS+ILENS) ENDIF ENDDO ENDDO!$OMP END PARALLEL DO SYNC IMAGES(D%NMYSETW) FOUBUF(1:IBLEN)=FOUBUF_C(1:IBLEN)[MYPROC] NEW code
42 T159 model scaling: small model with large number of user threads (4 threads per task) Speedup ideal T Slide User Threads
43 IFS Semi-Lagrangian Comms SL comms scaling limited by - constant width halo for u,v,w ( 400 m/s x time step) - Halo volume communicated, which is a function of wind speed and direction in locality of each task Halo-lite approach tested (2010) - Only get (using MPI) grid columns from neighbouring tasks that your task needs, i.e. only the red points - Requires more MPI communication steps (e.g. mid-point, departure point) - No faster than original approach due to overheads of above CRESTA optimisation using F2008 coarrays (2012) - Only get grid columns from neighbouring tasks that your task needs, i.e. only the red points - Do the above in the context of an OpenMP parallel Slide 43 region; overlapping interpolations for determining the departure point & mid-point and interpolations at these points

44 wind plot Slide 44
 during a 10 day forecast starting 17 Oct 2010 Slide")
45 T159 model task 37 of 256 tasks Task encountering the highest wind speed of 138 m/s (309 mph) during a 10 day forecast starting 17 Oct 2010 Slide 45
46 T159 model task 128 of 1024 tasks Slide 46
47 T159 model task 462 of 4096 tasks Slide 47
48 Computational Cost at T2047 and T3999 GP_DYN SP_DYN TRANS Physics WAM other Hydrostatic T L 2047 Non-Hydrostatic T L 3999 Tstep=450s, 5.8s/Tstep With 256x16 ibm_power6 Tstep=240s, 13.6s/Tstep With 512x16 ibm_power6
49 Breakdown of TRANS cost: Computations vs. Communications Comms Comps H T L 2047 ~2015 NH T L 3999 ~2020 Data sent/received: 117.8GB/s Data sent/received: 289.6GB/s
50 IFS Introduction A history Resolution increases of the deterministic 10-day medium-range Integrated Forecast System (IFS) over ~25 years at ECMWF: : T 106 (~125km) : T 213 (~63km) : T L 319 (~63km) : T L 511 (~39km) : T L 799 (~25km) : T L 1279 (~16km) Slide 50
51 Introduction A history Resolution increases of the deterministic 10-day medium-range Integrated Forecast System (IFS) over ~25 years at ECMWF: : T 106 (~125km) : T 213 (~63km) : T L 319 (~63km) : T L 511 (~39km) : T L 799 (~25km) : T L 1279 (~16km) ?: T L 2047 (~10km) ???: (~1-10km) Non-hydrostatic, cloud-permitting, substantially different cloud-microphysics and turbulence parametrization, substantially different dynamics-physics interaction? Slide 51
52 The Gaussian grid About 30% reduction in number of points Full grid Slide 52 Reduced grid Reduction in the number of Fourier points at high latitudes is possible because associated Legendre functions are very small near the poles for large m.
53 (Adaptive) Mesh Refinement The IFS model is inherently based on a fixed structured mesh due to the link between the spectral representation and the position of the grid-points (zero s of the ordinary Legendre polynomials), which makes selective mesh refinement (adaptive or not) difficult to achieve. AMR possibilities: coexisting global multigrids, physics/ dynamics on different grids, wavelet-collocation methods, : Costly investment both in RD and computational cost Hence it is of strategic importance to understand the added-value of adaptive or static mesh refinement for multiscale global NWP and climate prediction! Slide 53
54 Nonhydrostatic IFS (NH-IFS) Bubnovă et al. (1995); Bénard et al. (2004), Bénard et al. (2005), Bénard et al. (2010), Wedi et al. (2009), Yessad and Wedi (2011) Arpégé/ALADIN/Arome/HIRLAM/ECMWF nonhydrostatic dynamical core, which was developed by Météo-France and their ALADIN partners and later incorporated into the ECMWF model and also adopted by HIRLAM. Slide 54
55 Numerical solution Two-time-level, semi-implicit, semi-lagrangian. Semi-implicit procedure with two reference states, with respect to gravity and acoustic waves, respectively. The resulting Helmholtz equation can be solved (subject to some constraints on the vertical discretization) with a direct spectral method, that is, a mathematical separation of the horizontal and vertical part of the linear problem in spectral space, with the remainder representing at most a pentadiagonal problem of dimension NLEV 2. Non-linear residuals are treated explicitly (or iteratively implicitly)! (Robert, 1972; Bénard Slide 55 et al 2004,2005,2010)
56 The spectral transform method Eliasen et. al (1970), Orszaag (1970) Applied at ECMWF for the last 30 years Spectral semi-lagrangian semi-implicit (compressible) a viable option? -Computational efficiency on future MPP architectures? -Accuracy at cloud-resolving scales? -Suitability for the likely mixture of medium and high resolution ensembles and ultra-high resolution forecasts? Slide 56
57 The Gaussian grid About 30% reduction in number of points Full grid Reduced grid Reduction in the number of Fourier points at high latitudes is possible because associated Legendre polynomials are very small near the poles for large m. Slide 57 Note: number of points nearly equivalent to quasi-uniform icosahedral grid cells of the ICON model.
58 Cost of the spectral transform method FFT can be computed as C*N*log(N) where C is a small positive number and N is the cut-off wave number in the triangular truncation. Ordinary Legendre transform is O(N 2 ) but can be combined with the fields/levels such that the arising matrix-matrix multiplies make use of the highly optimized BLAS routine DGEMM. But overall cost is O(N 3 ) for both memory and CPU time requirements. Desire to use a fast Legendre transform where the cost is proportional to C*N*log(N) with C << N and thus overall cost N 2 *log(n) Slide 58
59 Fast Legendre Transform (FLT) The algorithm proposed in (Tygert, 2008,2010) suitably fits into the IFS transform library by simply replacing the matrix-matrix multiply DGEMM call with a BUTTERFLY_MATRIX_MULT call plus slightly more expensive pre-computations. (1) Instead of the recursive Cuppen divide-and-conquer algorithm (Tygert, 2008) we use the so called butterfly algorithm (O Neil et al, 2009; Tygert, 2010) based on a matrix compression technique via rank reduction with a specified accuracy to accelerate the arising matrix-vector/matrix multiplies (sub-problems still use DGEMM). (2) We apply the matrix compression directly on the matrix of the associated polynomials, which reduces the required precomputations and eliminates the need to apply FMM (fast multipole method) accelerated interpolations. Notably, the latter were an essential part of the proposed FLT in Suda and Takami (2001). Slide 59
60 The butterfly compression (O Neil, Woolfe, Rokhlin, 2009; Tygert 2010) With each level l, double the columns and half the rows l=0 l=2 l=1 l=3 Slide 60


61 Floating point operations per time-step in Gflop Inverse transform of single field/level control butterfly Wallclock time in seconds dgemm inverse transform of 10 fields, offline test environment 2 Slide 61 butterfly
62 Selected projects to prepare for exascale computing in Meteorology (NWP) ICOMEX ICOsahedral grid Models for EXascale Earth system simulations ( ) Gung-Ho Development of the Next Generation Dynamical Core for the UK MetOffice (2 phases, , ) CRESTA Collaborative Research into Exascale Systemware, Tools & Applications ( ) Slide 62
63 T3999 6h forecast - inverse transforms: CPU time vs. wave number Slide 63
64 T3999 6h forecast - inverse transforms: Floating point operations vs. wave number Slide 64
65 Why is Matrix Multiply (DGEMM) so efficient? VECTOR SCALAR / CACHE 1 n V L is vector register length V L FMA s (V L + 1) LD s (m * n) + (m + n) < # registers m * n FMA s m + n LD s V L m FMA s ~= LD s FMA s >> LD s
Introduction to Parallel Computing
 Introduction to Parallel Computing Iain Miller Iain.miller@ecmwf.int Slides adapted from those of George Mozdzynski ECMWF January 22, 2016 Outline Parallel computing? Types of computer Parallel Computers
Introduction to Parallel Computing Iain Miller Iain.miller@ecmwf.int Slides adapted from those of George Mozdzynski ECMWF January 22, 2016 Outline Parallel computing? Types of computer Parallel Computers
IFS migrates from IBM to Cray CPU, Comms and I/O
 IFS migrates from IBM to Cray CPU, Comms and I/O Deborah Salmond & Peter Towers Research Department Computing Department Thanks to Sylvie Malardel, Philippe Marguinaud, Alan Geer & John Hague and many
IFS migrates from IBM to Cray CPU, Comms and I/O Deborah Salmond & Peter Towers Research Department Computing Department Thanks to Sylvie Malardel, Philippe Marguinaud, Alan Geer & John Hague and many
PGAS languages. The facts, the myths and the requirements. Dr Michèle Weiland Monday, 1 October 12
 PGAS languages The facts, the myths and the requirements Dr Michèle Weiland m.weiland@epcc.ed.ac.uk What is PGAS? a model, not a language! based on principle of partitioned global address space many different
PGAS languages The facts, the myths and the requirements Dr Michèle Weiland m.weiland@epcc.ed.ac.uk What is PGAS? a model, not a language! based on principle of partitioned global address space many different
Computer Architectures and Aspects of NWP models
 Computer Architectures and Aspects of NWP models Deborah Salmond ECMWF Shinfield Park, Reading, UK Abstract: This paper describes the supercomputers used in operational NWP together with the computer aspects
Computer Architectures and Aspects of NWP models Deborah Salmond ECMWF Shinfield Park, Reading, UK Abstract: This paper describes the supercomputers used in operational NWP together with the computer aspects
Exascale Challenges and Applications Initiatives for Earth System Modeling
 Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Dr.-Ing. Achim Basermann DLR, Simulation and Software Technology (SC)
") www.dlr.de Chart 1 > HPC@SC > Achim Basermann 20131125_HPCatSC_Basermann.pptx > 25.11.2013 HPC@SC Dr.-Ing. Achim Basermann DLR, Simulation and Software Technology (SC) www.dlr.de Chart 2 > HPC@SC > Achim
www.dlr.de Chart 1 > HPC@SC > Achim Basermann 20131125_HPCatSC_Basermann.pptx > 25.11.2013 HPC@SC Dr.-Ing. Achim Basermann DLR, Simulation and Software Technology (SC) www.dlr.de Chart 2 > HPC@SC > Achim
The ECMWF forecast model, quo vadis?
 The forecast model, quo vadis? by Nils Wedi European Centre for Medium-Range Weather Forecasts wedi@ecmwf.int contributors: Piotr Smolarkiewicz, Mats Hamrud, George Mozdzynski, Sylvie Malardel, Christian
The forecast model, quo vadis? by Nils Wedi European Centre for Medium-Range Weather Forecasts wedi@ecmwf.int contributors: Piotr Smolarkiewicz, Mats Hamrud, George Mozdzynski, Sylvie Malardel, Christian
Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems
 Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems Alistair Hart Cray Exascale Research Initiative Europe T-Systems HPCN workshop DLR Braunschweig 26.May.11 ahart@cray.com
Hybrid multicore supercomputing and GPU acceleration with next-generation Cray systems Alistair Hart Cray Exascale Research Initiative Europe T-Systems HPCN workshop DLR Braunschweig 26.May.11 ahart@cray.com
Unified Model Performance on the NEC SX-6
 Unified Model Performance on the NEC SX-6 Paul Selwood Crown copyright 2004 Page 1 Introduction The Met Office National Weather Service Global and Local Area Climate Prediction (Hadley Centre) Operational
Unified Model Performance on the NEC SX-6 Paul Selwood Crown copyright 2004 Page 1 Introduction The Met Office National Weather Service Global and Local Area Climate Prediction (Hadley Centre) Operational
The Icosahedral Nonhydrostatic (ICON) Model
 Model") The Icosahedral Nonhydrostatic (ICON) Model Scalability on Massively Parallel Computer Architectures Florian Prill, DWD + the ICON team 15th ECMWF Workshop on HPC in Meteorology October 2, 2012 ICON =
The Icosahedral Nonhydrostatic (ICON) Model Scalability on Massively Parallel Computer Architectures Florian Prill, DWD + the ICON team 15th ECMWF Workshop on HPC in Meteorology October 2, 2012 ICON =
Porting and Optimizing the COSMOS coupled model on Power6
 Porting and Optimizing the COSMOS coupled model on Power6 Luis Kornblueh Max Planck Institute for Meteorology November 5, 2008 L. Kornblueh, MPIM () echam5 November 5, 2008 1 / 21 Outline 1 Introduction
Porting and Optimizing the COSMOS coupled model on Power6 Luis Kornblueh Max Planck Institute for Meteorology November 5, 2008 L. Kornblueh, MPIM () echam5 November 5, 2008 1 / 21 Outline 1 Introduction
HPC Performance Advances for Existing US Navy NWP Systems
 HPC Performance Advances for Existing US Navy NWP Systems Timothy Whitcomb, Kevin Viner Naval Research Laboratory Marine Meteorology Division Monterey, CA Matthew Turner DeVine Consulting, Monterey, CA
HPC Performance Advances for Existing US Navy NWP Systems Timothy Whitcomb, Kevin Viner Naval Research Laboratory Marine Meteorology Division Monterey, CA Matthew Turner DeVine Consulting, Monterey, CA
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation
 Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Sami Saarinen Peter Towers. 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1
 Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Regional Cooperation for Limited Area Modeling in Central Europe. Dynamics in LACE. Petra Smolíková thanks to many colleagues
 Dynamics in LACE Petra Smolíková thanks to many colleagues Outline 1 1. VFE NH Design of vertical finite elements scheme for NH version of the model 2. SL scheme Application of ENO technique to SL interpolations
Dynamics in LACE Petra Smolíková thanks to many colleagues Outline 1 1. VFE NH Design of vertical finite elements scheme for NH version of the model 2. SL scheme Application of ENO technique to SL interpolations
A mass-conservative version of the semi- Lagrangian semi-implicit HIRLAM using Lagrangian vertical coordinates
 A mass-conservative version of the semi- Lagrangian semi-implicit HIRLAM using Lagrangian vertical coordinates Peter Hjort Lauritzen Atmospheric Modeling & Predictability Section National Center for Atmospheric
A mass-conservative version of the semi- Lagrangian semi-implicit HIRLAM using Lagrangian vertical coordinates Peter Hjort Lauritzen Atmospheric Modeling & Predictability Section National Center for Atmospheric
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
GPU Developments for the NEMO Model. Stan Posey, HPC Program Manager, ESM Domain, NVIDIA (HQ), Santa Clara, CA, USA
, Santa Clara, CA, USA") GPU Developments for the NEMO Model Stan Posey, HPC Program Manager, ESM Domain, NVIDIA (HQ), Santa Clara, CA, USA NVIDIA HPC AND ESM UPDATE TOPICS OF DISCUSSION GPU PROGRESS ON NEMO MODEL 2 NVIDIA GPU
GPU Developments for the NEMO Model Stan Posey, HPC Program Manager, ESM Domain, NVIDIA (HQ), Santa Clara, CA, USA NVIDIA HPC AND ESM UPDATE TOPICS OF DISCUSSION GPU PROGRESS ON NEMO MODEL 2 NVIDIA GPU
Evaluating the Performance and Energy Efficiency of the COSMO-ART Model System
 Evaluating the Performance and Energy Efficiency of the COSMO-ART Model System Joseph Charles & William Sawyer (CSCS), Manuel F. Dolz (UHAM), Sandra Catalán (UJI) EnA-HPC, Dresden September 1-2, 2014 1
Evaluating the Performance and Energy Efficiency of the COSMO-ART Model System Joseph Charles & William Sawyer (CSCS), Manuel F. Dolz (UHAM), Sandra Catalán (UJI) EnA-HPC, Dresden September 1-2, 2014 1
Porting and Optimisation of UM on ARCHER. Karthee Sivalingam, NCAS-CMS. HPC Workshop ECMWF JWCRP
 Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
Porting and Optimisation of UM on ARCHER Karthee Sivalingam, NCAS-CMS HPC Workshop ECMWF JWCRP Acknowledgements! NCAS-CMS Bryan Lawrence Jeffrey Cole Rosalyn Hatcher Andrew Heaps David Hassell Grenville
Running HARMONIE on Xeon Phi Coprocessors
 Running HARMONIE on Xeon Phi Coprocessors Enda O Brien Irish Centre for High-End Computing Disclosure Intel is funding ICHEC to port & optimize some applications, including HARMONIE, to Xeon Phi coprocessors.
Running HARMONIE on Xeon Phi Coprocessors Enda O Brien Irish Centre for High-End Computing Disclosure Intel is funding ICHEC to port & optimize some applications, including HARMONIE, to Xeon Phi coprocessors.
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Dynamical Exascale Entry Platform
 DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Global Numerical Weather Predictions and the semi-lagrangian semi-implicit dynamical 1 / 27. ECMWF forecast model
 Global Numerical Weather Predictions and the semi-lagrangian semi-implicit dynamical core of the ECMWF forecast model Michail Diamantakis ECMWF Symposium on Modelling and Computations in Atmospheric Sciences
Global Numerical Weather Predictions and the semi-lagrangian semi-implicit dynamical core of the ECMWF forecast model Michail Diamantakis ECMWF Symposium on Modelling and Computations in Atmospheric Sciences
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs
 Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms
 To Hybrid GPU Platforms") Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms http://www.scidacreview.org/0902/images/esg13.jpg Matthew Norman Jeffrey Larkin Richard Archibald Valentine Anantharaj
Porting The Spectral Element Community Atmosphere Model (CAM-SE) To Hybrid GPU Platforms http://www.scidacreview.org/0902/images/esg13.jpg Matthew Norman Jeffrey Larkin Richard Archibald Valentine Anantharaj
Porting COSMO to Hybrid Architectures
 Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Porting COSMO to Hybrid Architectures T. Gysi 1, O. Fuhrer 2, C. Osuna 3, X. Lapillonne 3, T. Diamanti 3, B. Cumming 4, T. Schroeder 5, P. Messmer 5, T. Schulthess 4,6,7 [1] Supercomputing Systems AG,
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Porting the ICON Non-hydrostatic Dynamics and Physics to GPUs
 Porting the ICON Non-hydrostatic Dynamics and Physics to GPUs William Sawyer (CSCS/ETH), Christian Conti (ETH), Xavier Lapillonne (C2SM/ETH) Programming weather, climate, and earth-system models on heterogeneous
Porting the ICON Non-hydrostatic Dynamics and Physics to GPUs William Sawyer (CSCS/ETH), Christian Conti (ETH), Xavier Lapillonne (C2SM/ETH) Programming weather, climate, and earth-system models on heterogeneous
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Performance Prediction for Parallel Local Weather Forecast Programs
 Performance Prediction for Parallel Local Weather Forecast Programs W. Joppich and H. Mierendorff GMD German National Research Center for Information Technology Institute for Algorithms and Scientific
Performance Prediction for Parallel Local Weather Forecast Programs W. Joppich and H. Mierendorff GMD German National Research Center for Information Technology Institute for Algorithms and Scientific
Scalability of Elliptic Solvers in NWP. Weather and Climate- Prediction
 Background Scaling results Tensor product geometric multigrid Summary and Outlook 1/21 Scalability of Elliptic Solvers in Numerical Weather and Climate- Prediction Eike Hermann Müller, Robert Scheichl
Background Scaling results Tensor product geometric multigrid Summary and Outlook 1/21 Scalability of Elliptic Solvers in Numerical Weather and Climate- Prediction Eike Hermann Müller, Robert Scheichl
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model
 www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
www.bsc.es Optimizing an Earth Science Atmospheric Application with the OmpSs Programming Model HPC Knowledge Meeting'15 George S. Markomanolis, Jesus Labarta, Oriol Jorba University of Barcelona, Barcelona,
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Accelerating Extreme-Scale Numerical Weather Prediction
 Accelerating Extreme-Scale Numerical Weather Prediction Willem Deconinck (B), Mats Hamrud, Christian Kühnlein, George Mozdzynski, Piotr K. Smolarkiewicz, Joanna Szmelter 2, and Nils P. Wedi European Centre
Accelerating Extreme-Scale Numerical Weather Prediction Willem Deconinck (B), Mats Hamrud, Christian Kühnlein, George Mozdzynski, Piotr K. Smolarkiewicz, Joanna Szmelter 2, and Nils P. Wedi European Centre
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture. Alexander Berreth. Markus Bühler, Benedikt Anlauf
 PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
PADC Anual Workshop 20 Performance of the 3D-Combustion Simulation Code RECOM-AIOLOS on IBM POWER8 Architecture Alexander Berreth RECOM Services GmbH, Stuttgart Markus Bühler, Benedikt Anlauf IBM Deutschland
AllScale Pilots Applications AmDaDos Adaptive Meshing and Data Assimilation for the Deepwater Horizon Oil Spill
 This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No. 671603 An Exascale Programming, Multi-objective Optimisation and Resilience
This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No. 671603 An Exascale Programming, Multi-objective Optimisation and Resilience
Deutscher Wetterdienst
 Porting Operational Models to Multi- and Many-Core Architectures Ulrich Schättler Deutscher Wetterdienst Oliver Fuhrer MeteoSchweiz Xavier Lapillonne MeteoSchweiz Contents Strong Scalability of the Operational
Porting Operational Models to Multi- and Many-Core Architectures Ulrich Schättler Deutscher Wetterdienst Oliver Fuhrer MeteoSchweiz Xavier Lapillonne MeteoSchweiz Contents Strong Scalability of the Operational
Using OpenACC in IFS Physics Cloud Scheme (CLOUDSC) Sami Saarinen ECMWF Basic GPU Training Sept 16-17, 2015
 Sami Saarinen ECMWF Basic GPU Training Sept 16-17, 2015") Using OpenACC in IFS Physics Cloud Scheme (CLOUDSC) Sami Saarinen ECMWF Basic GPU Training Sept 16-17, 2015 Slide 1 Background Back in 2014 : Adaptation of IFS physics cloud scheme (CLOUDSC) to new architectures
Using OpenACC in IFS Physics Cloud Scheme (CLOUDSC) Sami Saarinen ECMWF Basic GPU Training Sept 16-17, 2015 Slide 1 Background Back in 2014 : Adaptation of IFS physics cloud scheme (CLOUDSC) to new architectures
Towards Exascale Computing with Fortran 2015
 Towards Exascale Computing with Fortran 2015 Alessandro Fanfarillo National Center for Atmospheric Research Damian Rouson Sourcery Institute Outline Parallelism in Fortran 2008 SPMD PGAS Exascale challenges
Towards Exascale Computing with Fortran 2015 Alessandro Fanfarillo National Center for Atmospheric Research Damian Rouson Sourcery Institute Outline Parallelism in Fortran 2008 SPMD PGAS Exascale challenges
ECMWF's Next Generation IO for the IFS Model and Product Generation
 ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
How to run OpenIFS as a shallow water model
 How to run OpenIFS as a shallow water model OpenIFS includes a number of idealised configurations. In this article we explain how to: setup and run a shallow-water model set idealized (e.g. Rossby-Haurwitz
How to run OpenIFS as a shallow water model OpenIFS includes a number of idealised configurations. In this article we explain how to: setup and run a shallow-water model set idealized (e.g. Rossby-Haurwitz
Chapter 6. Semi-Lagrangian Methods
 Chapter 6. Semi-Lagrangian Methods References: Durran Chapter 6. Review article by Staniford and Cote (1991) MWR, 119, 2206-2223. 6.1. Introduction Semi-Lagrangian (S-L for short) methods, also called
Chapter 6. Semi-Lagrangian Methods References: Durran Chapter 6. Review article by Staniford and Cote (1991) MWR, 119, 2206-2223. 6.1. Introduction Semi-Lagrangian (S-L for short) methods, also called
The new ECMWF interpolation package MIR
 from Newsletter Number 152 Summer 2017 COMPUTING The new ECMWF interpolation package MIR Hurricane Patricia off the coast of Mexico on 23 October 2015 ( 2015 EUMETSAT) doi:10.21957/h20rz8 This article
from Newsletter Number 152 Summer 2017 COMPUTING The new ECMWF interpolation package MIR Hurricane Patricia off the coast of Mexico on 23 October 2015 ( 2015 EUMETSAT) doi:10.21957/h20rz8 This article
Deutscher Wetterdienst
 Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
Accelerating Work at DWD Ulrich Schättler Deutscher Wetterdienst Roadmap Porting operational models: revisited Preparations for enabling practical work at DWD My first steps with the COSMO on a GPU First
Scalable Dynamic Load Balancing of Detailed Cloud Physics with FD4
 Center for Information Services and High Performance Computing (ZIH) Scalable Dynamic Load Balancing of Detailed Cloud Physics with FD4 Minisymposium on Advances in Numerics and Physical Modeling for Geophysical
Center for Information Services and High Performance Computing (ZIH) Scalable Dynamic Load Balancing of Detailed Cloud Physics with FD4 Minisymposium on Advances in Numerics and Physical Modeling for Geophysical
MIR. ECMWF s New Interpolation Package. P. Maciel, T. Quintino, B. Raoult, M. Fuentes, S. Villaume ECMWF. ECMWF March 9, 2016
 MIR ECMWF s New Interpolation Package P. Maciel, T. Quintino, B. Raoult, M. Fuentes, S. Villaume ECMWF mars-admins@ecmwf.int ECMWF March 9, 2016 Upgrading the Interpolation Package Interpolation is pervasive:
MIR ECMWF s New Interpolation Package P. Maciel, T. Quintino, B. Raoult, M. Fuentes, S. Villaume ECMWF mars-admins@ecmwf.int ECMWF March 9, 2016 Upgrading the Interpolation Package Interpolation is pervasive:
EULAG: high-resolution computational model for research of multi-scale geophysical fluid dynamics
 Zbigniew P. Piotrowski *,** EULAG: high-resolution computational model for research of multi-scale geophysical fluid dynamics *Geophysical Turbulence Program, National Center for Atmospheric Research,
Zbigniew P. Piotrowski *,** EULAG: high-resolution computational model for research of multi-scale geophysical fluid dynamics *Geophysical Turbulence Program, National Center for Atmospheric Research,
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH
 Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH 1 Exascale Programming Models With the evolution of HPC architecture towards exascale, new approaches for programming these machines
Towards Exascale Programming Models HPC Summit, Prague Erwin Laure, KTH 1 Exascale Programming Models With the evolution of HPC architecture towards exascale, new approaches for programming these machines
GPU Implementation of Elliptic Solvers in NWP. Numerical Weather- and Climate- Prediction
 1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
1/8 GPU Implementation of Elliptic Solvers in Numerical Weather- and Climate- Prediction Eike Hermann Müller, Robert Scheichl Department of Mathematical Sciences EHM, Xu Guo, Sinan Shi and RS: http://arxiv.org/abs/1302.7193
Approaches to I/O Scalability Challenges in the ECMWF Forecasting System
 Approaches to I/O Scalability Challenges in the ECMWF Forecasting System PASC 16, June 9 2016 Florian Rathgeber, Simon Smart, Tiago Quintino, Baudouin Raoult, Stephan Siemen, Peter Bauer Development Section,
Approaches to I/O Scalability Challenges in the ECMWF Forecasting System PASC 16, June 9 2016 Florian Rathgeber, Simon Smart, Tiago Quintino, Baudouin Raoult, Stephan Siemen, Peter Bauer Development Section,
Multi-Domain Pattern. I. Problem. II. Driving Forces. III. Solution
 Multi-Domain Pattern I. Problem The problem represents computations characterized by an underlying system of mathematical equations, often simulating behaviors of physical objects through discrete time
Multi-Domain Pattern I. Problem The problem represents computations characterized by an underlying system of mathematical equations, often simulating behaviors of physical objects through discrete time
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
An Introduction to the LFRic Project
 An Introduction to the LFRic Project Mike Hobson Acknowledgements: LFRic Project Met Office: Sam Adams, Tommaso Benacchio, Matthew Hambley, Mike Hobson, Chris Maynard, Tom Melvin, Steve Mullerworth, Stephen
An Introduction to the LFRic Project Mike Hobson Acknowledgements: LFRic Project Met Office: Sam Adams, Tommaso Benacchio, Matthew Hambley, Mike Hobson, Chris Maynard, Tom Melvin, Steve Mullerworth, Stephen
Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs
 Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Performance Analysis for Large Scale Simulation Codes with Periscope
 Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
Performance Analysis for Large Scale Simulation Codes with Periscope M. Gerndt, Y. Oleynik, C. Pospiech, D. Gudu Technische Universität München IBM Deutschland GmbH May 2011 Outline Motivation Periscope
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES. Cliff Woolley, NVIDIA
 HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
HARNESSING IRREGULAR PARALLELISM: A CASE STUDY ON UNSTRUCTURED MESHES Cliff Woolley, NVIDIA PREFACE This talk presents a case study of extracting parallelism in the UMT2013 benchmark for 3D unstructured-mesh
First Experiences with Application Development with Fortran Damian Rouson
 First Experiences with Application Development with Fortran 2018 Damian Rouson Overview Fortran 2018 in a Nutshell ICAR & Coarray ICAR WRF-Hydro Results Conclusions www.yourwebsite.com Overview Fortran
First Experiences with Application Development with Fortran 2018 Damian Rouson Overview Fortran 2018 in a Nutshell ICAR & Coarray ICAR WRF-Hydro Results Conclusions www.yourwebsite.com Overview Fortran
ICON for HD(CP) 2. High Definition Clouds and Precipitation for Advancing Climate Prediction
 2. High Definition Clouds and Precipitation for Advancing Climate Prediction") ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
ICON for HD(CP) 2 High Definition Clouds and Precipitation for Advancing Climate Prediction High Definition Clouds and Precipitation for Advancing Climate Prediction ICON 2 years ago Parameterize shallow
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster
 First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
First Steps of YALES2 Code Towards GPU Acceleration on Standard and Prototype Cluster YALES2: Semi-industrial code for turbulent combustion and flows Jean-Matthieu Etancelin, ROMEO, NVIDIA GPU Application
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
GPU Developments in Atmospheric Sciences
 GPU Developments in Atmospheric Sciences Stan Posey, HPC Program Manager, ESM Domain, NVIDIA (HQ), Santa Clara, CA, USA David Hall, Ph.D., Sr. Solutions Architect, NVIDIA, Boulder, CO, USA NVIDIA HPC UPDATE
GPU Developments in Atmospheric Sciences Stan Posey, HPC Program Manager, ESM Domain, NVIDIA (HQ), Santa Clara, CA, USA David Hall, Ph.D., Sr. Solutions Architect, NVIDIA, Boulder, CO, USA NVIDIA HPC UPDATE
Profiling Arpege, Aladin and Arome and Alaro! R. El Khatib with contributions from CHMI
 Profiling Arpege, Aladin and Arome and Alaro! R. El Khatib with contributions from CHMI Aladin workshop & Hirlam all staff meeting Utrecht, 12-15 May 2009 Outlines What's new regarding computational performances
Profiling Arpege, Aladin and Arome and Alaro! R. El Khatib with contributions from CHMI Aladin workshop & Hirlam all staff meeting Utrecht, 12-15 May 2009 Outlines What's new regarding computational performances
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran. G. Ruetsch, M. Fatica, E. Phillips, N.
 GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Deutscher Wetterdienst. Ulrich Schättler Deutscher Wetterdienst Research and Development
 Deutscher Wetterdienst COSMO, ICON and Computers Ulrich Schättler Deutscher Wetterdienst Research and Development Contents Problems of the COSMO-Model on HPC architectures POMPA and The ICON Model Outlook
Deutscher Wetterdienst COSMO, ICON and Computers Ulrich Schättler Deutscher Wetterdienst Research and Development Contents Problems of the COSMO-Model on HPC architectures POMPA and The ICON Model Outlook
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor
 IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
IFS RAPS14 benchmark on 2 nd generation Intel Xeon Phi processor D.Sc. Mikko Byckling 17th Workshop on High Performance Computing in Meteorology October 24 th 2016, Reading, UK Legal Disclaimer & Optimization
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace
 Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Determining Optimal MPI Process Placement for Large- Scale Meteorology Simulations with SGI MPIplace James Southern, Jim Tuccillo SGI 25 October 2016 0 Motivation Trend in HPC continues to be towards more
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core
 Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
Progress on GPU Parallelization of the NIM Prototype Numerical Weather Prediction Dynamical Core Tom Henderson NOAA/OAR/ESRL/GSD/ACE Thomas.B.Henderson@noaa.gov Mark Govett, Jacques Middlecoff Paul Madden,
Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark
 Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark Mike Ashworth, Rupert Ford and Andrew Porter Scientific Computing Department and STFC Hartree Centre STFC Daresbury Laboratory United
Performance Analysis of the PSyKAl Approach for a NEMO-based Benchmark Mike Ashworth, Rupert Ford and Andrew Porter Scientific Computing Department and STFC Hartree Centre STFC Daresbury Laboratory United
CloverLeaf: Preparing Hydrodynamics Codes for Exascale
 CloverLeaf: Preparing Hydrodynamics Codes for Exascale Andrew Mallinson Andy.Mallinson@awe.co.uk www.awe.co.uk British Crown Owned Copyright [2013]/AWE Agenda AWE & Uni. of Warwick introduction Problem
CloverLeaf: Preparing Hydrodynamics Codes for Exascale Andrew Mallinson Andy.Mallinson@awe.co.uk www.awe.co.uk British Crown Owned Copyright [2013]/AWE Agenda AWE & Uni. of Warwick introduction Problem
Dynamic Load Balancing for Weather Models via AMPI
 Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Asynchronous OpenCL/MPI numerical simulations of conservation laws
 Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
Data Assimilation on future computer architectures
 Data Assimilation on future computer architectures Lars Isaksen ECMWF Acknowledgements to ECMWF colleagues: Deborah Salmond, George Mozdzynski, Mats Hamrud, Mike Fisher, Yannick Trémolet, Jean-Noël Thepaut,
Data Assimilation on future computer architectures Lars Isaksen ECMWF Acknowledgements to ECMWF colleagues: Deborah Salmond, George Mozdzynski, Mats Hamrud, Mike Fisher, Yannick Trémolet, Jean-Noël Thepaut,
Transport Simulations beyond Petascale. Jing Fu (ANL)
") Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
Transport Simulations beyond Petascale Jing Fu (ANL) A) Project Overview The project: Peta- and exascale algorithms and software development (petascalable codes: Nek5000, NekCEM, NekLBM) Science goals:
Experience in creating orography ancillary files
 Experience in creating orography ancillary files Nils Wedi European Centre for Medium-Range Weather Forecasts (ECMWF) Thanks to many colleagues at ECMWF and in particular Anton Beljaars, Geir Austad, Sinisa
Experience in creating orography ancillary files Nils Wedi European Centre for Medium-Range Weather Forecasts (ECMWF) Thanks to many colleagues at ECMWF and in particular Anton Beljaars, Geir Austad, Sinisa
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Porting Scientific Research Codes to GPUs with CUDA Fortran: Incompressible Fluid Dynamics using the Immersed Boundary Method
 Porting Scientific Research Codes to GPUs with CUDA Fortran: Incompressible Fluid Dynamics using the Immersed Boundary Method Josh Romero, Massimiliano Fatica - NVIDIA Vamsi Spandan, Roberto Verzicco -
Porting Scientific Research Codes to GPUs with CUDA Fortran: Incompressible Fluid Dynamics using the Immersed Boundary Method Josh Romero, Massimiliano Fatica - NVIDIA Vamsi Spandan, Roberto Verzicco -
Findings from real petascale computer systems with meteorological applications
 15 th ECMWF Workshop Findings from real petascale computer systems with meteorological applications Toshiyuki Shimizu Next Generation Technical Computing Unit FUJITSU LIMITED October 2nd, 2012 Outline
15 th ECMWF Workshop Findings from real petascale computer systems with meteorological applications Toshiyuki Shimizu Next Generation Technical Computing Unit FUJITSU LIMITED October 2nd, 2012 Outline
The Arm Technology Ecosystem: Current Products and Future Outlook
 The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
The Arm Technology Ecosystem: Current Products and Future Outlook Dan Ernst, PhD Advanced Technology Cray, Inc. Why is an Ecosystem Important? An Ecosystem is a collection of common material Developed
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC
 A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
Running the NIM Next-Generation Weather Model on GPUs
 Running the NIM Next-Generation Weather Model on GPUs M.Govett 1, J.Middlecoff 2 and T.Henderson 2 1 NOAA Earth System Research Laboratory, Boulder, CO, USA 2 Cooperative Institute for Research in the
Running the NIM Next-Generation Weather Model on GPUs M.Govett 1, J.Middlecoff 2 and T.Henderson 2 1 NOAA Earth System Research Laboratory, Boulder, CO, USA 2 Cooperative Institute for Research in the
Acknowledgments. Amdahl s Law. Contents. Programming with MPI Parallel programming. 1 speedup = (1 P )+ P N. Type to enter text
+ P N. Type to enter text") Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Lecture V: Introduction to parallel programming with Fortran coarrays
 Lecture V: Introduction to parallel programming with Fortran coarrays What is parallel computing? Serial computing Single processing unit (core) is used for solving a problem One task processed at a time
Lecture V: Introduction to parallel programming with Fortran coarrays What is parallel computing? Serial computing Single processing unit (core) is used for solving a problem One task processed at a time
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about