rcuda: an approach to provide remote access to GPU computational power
|
|
|
- Eileen Wilkinson
- 6 years ago
- Views:
Transcription
 HPC Advisory Council")
1 rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop
2 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (2 of 60) HPC Advisory Council Workshop
3 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (3 of 60) HPC Advisory Council Workshop


























4 computing Will be the near future in HPC in fact, it is already here!!!!
5 computing It is massively parallel For the right kind of code the use of the use of computing brings huge benefits. Development tools and libraries facilitate the use of the. (5 of 60) HPC Advisory Council Workshop



















6 computing Two approaches in computing: CUDA: nvidia propietary OpenCL: open standard
7 computing Basically OpenCL and CUDA have the same work scheme: Compilation Separate CPU code Running: and code ( kernel) Data transfers: CPU and memory spaces Before kernel execution: data from CPU memory space to memory space Computation: Kernel execution After kernel execution: results from memory space to CPU memory space. (7 of 60) HPC Advisory Council Workshop
8 CPU computing Not all algorithms take profit of power. In some cases only part of a program must be run on a. Depending on the algorithms, the can be idle for long periods. (8 of 60) HPC Advisory Council Workshop
9 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (9 of 60) HPC Advisory Council Workshop
10 computing cost Tesla s2050 near 900 Watts (TDP manufacturer specification) Usage: 75% of time, so 25% idle time. Then each node misses: 160 Kwh/month 2 Mwh/year It could be several hundreds of Kg CO 2 /year (10 of 60) HPC Advisory Council Workshop
11 computing You can find two different scenarios: Scenario 1 If all your programs are going to use the for long periods Add a to each node You don't need our tool (11 of 60) HPC Advisory Council Workshop
















12 computing You can find two different scenarios: Scenario 2 You could think in adding a, only to some nodes OUR TOOL CAN HELP YOU!!! (12 of 60) HPC Advisory Council Workshop
13 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (13 of 60) HPC Advisory Council Workshop














14 rcuda












15 rcuda















16 rcuda
17 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (17 of 60) HPC Advisory Council Workshop



















18 rcuda structure CUDA application























19 rcuda structure Client side Server side
























20 rcuda structure Client side Server side Application




















21 rcuda functionality
22 rcuda functionallity Supported CUDA 4.0 Runtime Functions Module Functions Supported Device Management Error handling 3 3 Event management 7 7 Execution control 7 7 Memory management Peer device memory access 5 4 Stream management 2 2 Suface reference management 8 8 Texture refefence managemet 6 6 Thread management 6 6 Version managemet 2 2 (22 of 60) HPC Advisory Council Workshop
23 rcuda functionallity NOT YET Supported CUDA 4.0 Runtime Functions Module Functions Supported Unified addressing 11 0 Peer Device Memory Access 3 0 OpenGL Interoperability 3 0 Direct3D 9 Interoperability 5 0 Direct3D 10 Interoperability 5 0 Direct3D 11 Interoperability 5 0 VDPAU Interoperability 4 0 Graphics Interoperability 6 0 (23 of 60) HPC Advisory Council Workshop
24 rcuda functionallity Supported CUBLAS Functions Module Functions Supported Helper function reference BLAS BLAS BLAS (24 of 60) HPC Advisory Council Workshop
25 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (25 of 60) HPC Advisory Council Workshop

















26 rcuda: basic TCP/IP version







27 rcuda: basic TCP/IP version Example of rcuda interaction rcuda initialization













28 rcuda: basic TCP/IP version Example of rcuda interaction CudaMemcpy(..., cudamemcpyhosttodevice);
29 rcuda: basic TCP/IP version Main problem: data movement overhead On CUDA this overhead is due to: PCIe transfer On rcuda this overhead is due to: Network transfer PCIe transfer (but this appears in CUDA) (29 of 60) HPC Advisory Council Workshop
30 rcuda: basic TCP/IP version Data transfer time for matrix multiplication (2 from client to remote ) (1 from remote to client) Time (sec) rcuda CUDA Matrix dimension (30 of 60) HPC Advisory Council Workshop
31 rcuda: basic TCP/IP version Execution time for matrix multiplication Tesla c1060 Intel Xeon E5410 2'33 GHz 70 Time (sec) CPU rcuda kernel rcuda data transfer 10 0 rcuda misc Matrix dimension (31 of 60) HPC Advisory Council Workshop
32 rcuda: basic TCP/IP version Estimated execution time for matrix multiplication, including data transfers for some HPC networks Time (sec) CPU 10Gbit Ethernet 10Gbit InfiniBand 40Gbit InfiniBand Matrix dimension (32 of 60) HPC Advisory Council Workshop
33 rcuda: basic TCP/IP version We have shown the functionality As we decrease the network overhead, our solution will have a performance close to the CUDA solution (33 of 60) HPC Advisory Council Workshop









34 rcuda: InfiniBand version


















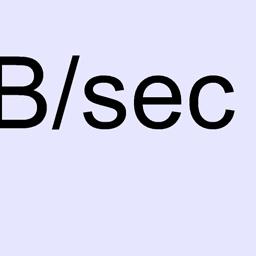




35 rcuda: InfiniBand version




















36 rcuda: InfiniBand version
37 rcuda: InfiniBand Verbs implementation Same user level functionallity. Use of Direct Use of pipelined transfers. Client to/from remote bandwidth near the peak of InfiniBand network performance. (37 of 60) HPC Advisory Council Workshop
38 rcuda: Direct Without direct 1.- to Main Memory 2.- Main Memory to Main Memory 3.- Main Memory to Network CPU Main memory InfiniBand chipset memory (38 of 60) HPC Advisory Council Workshop
39 rcuda: Direct Without direct 1.- to Main Memory 2.- Main Memory to Main Memory 3.- Main Memory to Network CPU Main memory InfiniBand chipset memory (39 of 60) HPC Advisory Council Workshop
40 rcuda: Direct Without direct 1.- to Main Memory 2.- Main Memory to Main Memory 3.- Main Memory to Network CPU Main memory InfiniBand chipset memory (40 of 60) HPC Advisory Council Workshop
41 rcuda: Direct Without direct 1.- to Main Memory 2.- Main Memory to Main Memory 3.- Main Memory to Network CPU Main memory InfiniBand chipset memory (41 of 60) HPC Advisory Council Workshop
42 rcuda: Direct WITH direct 1.- to Main Memory 2.- Main Memory to Network CPU Main memory InfiniBand chipset memory (42 of 60) HPC Advisory Council Workshop
43 rcuda: Direct WITH direct 1.- to Main Memory 2.- Main Memory to Network CPU Main memory InfiniBand chipset memory (43 of 60) HPC Advisory Council Workshop
44 rcuda: Direct WITH direct 1.- to Main Memory 2.- Main Memory to Network CPU Main memory InfiniBand chipset memory A memory copy is avoided (44 of 60) HPC Advisory Council Workshop
45 rcuda: Pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Network Server (45 of 60) HPC Advisory Council Workshop
46 rcuda: Pipelined transfers Without pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Network Server (46 of 60) HPC Advisory Council Workshop
47 rcuda: Pipelined transfers Without pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Network Data transfer Server (47 of 60) HPC Advisory Council Workshop
48 rcuda: Pipelined transfers Without pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Network Data transfer Server Copy to (48 of 60) HPC Advisory Council Workshop
49 rcuda: Pipelined transfers CLIENT NODE WITH pipelined transfers SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Network Copy to network buffers Server (49 of 60) HPC Advisory Council Workshop
50 rcuda: Pipelined transfers WITH pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Network Server Copy to network buffers Copy to network buffers Data transfer (50 of 60) HPC Advisory Council Workshop
51 rcuda: Pipelined transfers WITH pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Copy to network buffers Copy to network buffers Network Data transfer Data transfer Server Copy to (51 of 60) HPC Advisory Council Workshop
52 rcuda: Pipelined transfers WITH pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Copy to network buffers Copy to network buffers Network Data transfer Data transfer Data transfer Server Copy to Copy to (52 of 60) HPC Advisory Council Workshop
53 rcuda: Pipelined transfers WITH pipelined transfers CLIENT NODE SERVER NODE Main memory CPU CPU Main memory chipset InfiniBand InfiniBand chipset memory Client Copy to network buffers Copy to network buffers Copy to network buffers Network Data transfer Data transfer Data transfer Server Copy to Copy to Copy to (53 of 60) HPC Advisory Council Workshop
54 rcuda: optimized InfiniBand version Bandwidth for GEMM 13824x13824 Bandwidth (MB/sec) rcuda GigaE rcuda IPoIB rcuda IBVerbs CUDA (54 of 60) HPC Advisory Council Workshop
55 rcuda: optimized InfiniBand version Time for GEMM 4096x4096 2,50 2,00 2,28 Time (sec) 1,50 1,00 1,30 0,70 0,65 0,62 0,50 0,00 rcuda GigaE rcuda IpoIB rcuda IBVerbs CUDA CPU (MKL) Intel Xeon E5645 (55 of 60) HPC Advisory Council Workshop
56 Outline computing Cost of a node rcuda goals rcuda structure rcuda implementations rcuda current status (56 of 60) HPC Advisory Council Workshop
57 rcuda: work in progress rcuda port to Microsoft rcuda thread safe rcuda support to CUDA 4.0 Support to CUDA C extensions ropencl (57 of 60) HPC Advisory Council Workshop
58 rcuda: near future Dynamic remote scheduling. Workload balance. Remote data cache. Remote kernels cache (58 of 60) HPC Advisory Council Workshop
59 rcuda: more information virtualization in high performance clusters J. Duato, F. Igual, R. Mayo, A. Peña, E. S. Quintana, F. Silla. 4th Workshop on Virtualization and High-Performance Cloud Computing, VHPC'09. rcuda: reducing the number of -based accelerators in high performance clusters. J. Duato, A. Peña, F. Silla, R. Mayo, E. S. Quintana. Workshop on Optimization Issues in Energy Efficient Distributed Systems, OPTIM Performance of CUDA virtualized remote s in high performance clusters. J. Duato, R. Mayo, A. Peña, E. S. Quintana, F. Silla. International Conference on Parallel Processing, ICPP 2011 (accepted). (59 of 60) HPC Advisory Council Workshop
60 rcuda: credits Parallel Architectures Group Technical University of València High Performance Computing and Architectures Group University Jaume I of Castelló (60 of 60) HPC Advisory Council Workshop
computational power computational
 rcuda: rcuda: an an approach approach to to provide provide remote remote access access to to computational computational power power Rafael Mayo Gual Universitat Jaume I Spain (1 of 59) HPC Advisory Council
rcuda: rcuda: an an approach approach to to provide provide remote remote access access to to computational computational power power Rafael Mayo Gual Universitat Jaume I Spain (1 of 59) HPC Advisory Council
An approach to provide remote access to GPU computational power
 An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
An approach to provide remote access to computational power University Jaume I, Spain Joint research effort 1/84 Outline computing computing scenarios Introduction to rcuda rcuda structure rcuda functionality
Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators
 Remote CUDA (rcuda) Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators Better performance-watt, performance-cost
Remote CUDA (rcuda) Why? High performance clusters: Fast interconnects Hundreds of nodes, with multiple cores per node Large storage systems Hardware accelerators Better performance-watt, performance-cost
Exploiting Task-Parallelism on GPU Clusters via OmpSs and rcuda Virtualization
 Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
rcuda: towards energy-efficiency in GPU computing by leveraging low-power processors and InfiniBand interconnects
 rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Carlos Reaño Universitat Politècnica de València (Spain) HPC Advisory Council Switzerland Conference April 3, Lugano (Switzerland)
 HPC Advisory Council Switzerland Conference April 3, Lugano (Switzerland)") Carlos Reaño Universitat Politècnica de València (Spain) Switzerland Conference April 3, 2014 - Lugano (Switzerland) What is rcuda? Installing and using rcuda rcuda over HPC networks InfiniBand How taking
Carlos Reaño Universitat Politècnica de València (Spain) Switzerland Conference April 3, 2014 - Lugano (Switzerland) What is rcuda? Installing and using rcuda rcuda over HPC networks InfiniBand How taking
Framework of rcuda: An Overview
 Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
Framework of rcuda: An Overview Mohamed Hussain 1, M.B.Potdar 2, Third Viraj Choksi 3 11 Research scholar, VLSI & Embedded Systems, Gujarat Technological University, Ahmedabad, India 2 Project Director,
Opportunities of the rcuda remote GPU virtualization middleware. Federico Silla Universitat Politècnica de València Spain
 Opportunities of the rcuda remote virtualization middleware Federico Silla Universitat Politècnica de València Spain st Outline What is rcuda? HPC Advisory Council China Conference 2017 2/45 s are the
Opportunities of the rcuda remote virtualization middleware Federico Silla Universitat Politècnica de València Spain st Outline What is rcuda? HPC Advisory Council China Conference 2017 2/45 s are the
rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU
 rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU Federico Silla Universitat Politècnica de València HPC ADMINTECH 2018 rcuda: from virtual machines to hybrid CPU-GPU clusters Federico Silla Universitat
rcuda: desde máquinas virtuales a clústers mixtos CPU-GPU Federico Silla Universitat Politècnica de València HPC ADMINTECH 2018 rcuda: from virtual machines to hybrid CPU-GPU clusters Federico Silla Universitat
Remote GPU virtualization: pros and cons of a recent technology. Federico Silla Technical University of Valencia Spain
 Remote virtualization: pros and cons of a recent technology Federico Silla Technical University of Valencia Spain The scope of this talk HPC Advisory Council Brazil Conference 2015 2/43 st Outline What
Remote virtualization: pros and cons of a recent technology Federico Silla Technical University of Valencia Spain The scope of this talk HPC Advisory Council Brazil Conference 2015 2/43 st Outline What
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs
 An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
An Extension of the StarSs Programming Model for Platforms with Multiple GPUs Eduard Ayguadé 2 Rosa M. Badia 2 Francisco Igual 1 Jesús Labarta 2 Rafael Mayo 1 Enrique S. Quintana-Ortí 1 1 Departamento
Is remote GPU virtualization useful? Federico Silla Technical University of Valencia Spain
 Is remote virtualization useful? Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC Advisory Council Spain Conference 2015 2/57 We deal with s, obviously!
Is remote virtualization useful? Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC Advisory Council Spain Conference 2015 2/57 We deal with s, obviously!
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
The rcuda technology: an inexpensive way to improve the performance of GPU-based clusters Federico Silla
 The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Document downloaded from:
 Document downloaded from: http://hdl.handle.net/10251/70225 This paper must be cited as: Reaño González, C.; Silla Jiménez, F. (2015). On the Deployment and Characterization of CUDA Teaching Laboratories.
Document downloaded from: http://hdl.handle.net/10251/70225 This paper must be cited as: Reaño González, C.; Silla Jiménez, F. (2015). On the Deployment and Characterization of CUDA Teaching Laboratories.
On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications
 On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications A. Castelló, J. Duato, R. Mayo, A. J. Peña, E. S. Quintana-Ortí, V. Roca, F. Silla Universitat Politècnica
On the Use of Remote GPUs and Low-Power Processors for the Acceleration of Scientific Applications A. Castelló, J. Duato, R. Mayo, A. J. Peña, E. S. Quintana-Ortí, V. Roca, F. Silla Universitat Politècnica
Increasing the efficiency of your GPU-enabled cluster with rcuda. Federico Silla Technical University of Valencia Spain
 Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
Speeding up the execution of numerical computations and simulations with rcuda José Duato
 Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
Speeding up the execution of numerical computations and simulations with rcuda José Duato Universidad Politécnica de Valencia Spain Outline 1. Introduction to GPU computing 2. What is remote GPU virtualization?
Deploying remote GPU virtualization with rcuda. Federico Silla Technical University of Valencia Spain
 Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand
 Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
Multi-Threaded UPC Runtime for GPU to GPU communication over InfiniBand Miao Luo, Hao Wang, & D. K. Panda Network- Based Compu2ng Laboratory Department of Computer Science and Engineering The Ohio State
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Matrix Computations on GPUs, multiple GPUs and clusters of GPUs
 Matrix Computations on GPUs, multiple GPUs and clusters of GPUs Francisco D. Igual Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón (Spain). Matrix Computations on
Matrix Computations on GPUs, multiple GPUs and clusters of GPUs Francisco D. Igual Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón (Spain). Matrix Computations on
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators
 Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Solving Dense Linear Systems on Platforms with Multiple Hardware Accelerators Francisco D. Igual Enrique S. Quintana-Ortí Gregorio Quintana-Ortí Universidad Jaime I de Castellón (Spain) Robert A. van de
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.
, Ruyman Reyes, Mehdi Goli (Codeplay Software) 2017 Codeplay Software Ltd.") SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
SYCL-BLAS: LeveragingSYCL-BLAS Expression Trees for Linear Algebra Jose Aliaga (Universitat Jaume I, Castellon, Spain), Ruyman Reyes, Mehdi Goli (Codeplay Software) 1 About me... Phd in Compilers and Parallel
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
rcuda: hybrid CPU-GPU clusters Federico Silla Technical University of Valencia Spain
 rcuda: hybrid - clusters Federico Silla Technical University of Valencia Spain Outline 1. Hybrid - clusters 2. Concerns with hybrid clusters 3. One possible solution: virtualize s! 4. rcuda what s that?
rcuda: hybrid - clusters Federico Silla Technical University of Valencia Spain Outline 1. Hybrid - clusters 2. Concerns with hybrid clusters 3. One possible solution: virtualize s! 4. rcuda what s that?
Improving overall performance and energy consumption of your cluster with remote GPU virtualization
 Improving overall performance and energy consumption of your cluster with remote GPU virtualization Federico Silla & Carlos Reaño Technical University of Valencia Spain Tutorial Agenda 9.00-10.00 SESSION
Improving overall performance and energy consumption of your cluster with remote GPU virtualization Federico Silla & Carlos Reaño Technical University of Valencia Spain Tutorial Agenda 9.00-10.00 SESSION
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Automatic Development of Linear Algebra Libraries for the Tesla Series
 Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Automatic Development of Linear Algebra Libraries for the Tesla Series Enrique S. Quintana-Ortí quintana@icc.uji.es Universidad Jaime I de Castellón (Spain) Dense Linear Algebra Major problems: Source
Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes
 www.bsc.es Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es BSC/UPC CUDA Centre of Excellence (CCOE) Training
www.bsc.es Exploiting CUDA Dynamic Parallelism for low power ARM based prototypes Vishal Mehta Engineer, Barcelona Supercomputing Center vishal.mehta@bsc.es BSC/UPC CUDA Centre of Excellence (CCOE) Training
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies
 Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
Shadowfax: Scaling in Heterogeneous Cluster Systems via GPGPU Assemblies Alexander Merritt, Vishakha Gupta, Abhishek Verma, Ada Gavrilovska, Karsten Schwan {merritt.alex,abhishek.verma}@gatech.edu {vishakha,ada,schwan}@cc.gtaech.edu
A Multi-Tiered Optimization Framework for Heterogeneous Computing
 A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
Distributed In-GPU Data Cache for Document-Oriented Data Store via PCIe over 10Gbit Ethernet
 Distributed In-GPU Data Cache for Document-Oriented Data Store via PCIe over 10Gbit Ethernet Shin Morishima 1 and Hiroki Matsutani 1,2,3 1 Keio University, 3-14-1 Hiyoshi, Kohoku-ku, Yokohama, Japan 223-8522
Distributed In-GPU Data Cache for Document-Oriented Data Store via PCIe over 10Gbit Ethernet Shin Morishima 1 and Hiroki Matsutani 1,2,3 1 Keio University, 3-14-1 Hiyoshi, Kohoku-ku, Yokohama, Japan 223-8522
NVIDIA GPUDirect Technology. NVIDIA Corporation 2011
 NVIDIA GPUDirect Technology NVIDIA GPUDirect : Eliminating CPU Overhead Accelerated Communication with Network and Storage Devices Peer-to-Peer Communication Between GPUs Direct access to CUDA memory for
NVIDIA GPUDirect Technology NVIDIA GPUDirect : Eliminating CPU Overhead Accelerated Communication with Network and Storage Devices Peer-to-Peer Communication Between GPUs Direct access to CUDA memory for
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
GPUs as better MPI Citizens
 s as better MPI Citizens Author: Dale Southard, NVIDIA Date: 4/6/2011 www.openfabrics.org 1 Technology Conference 2011 October 11-14 San Jose, CA The one event you can t afford to miss Learn about leading-edge
s as better MPI Citizens Author: Dale Southard, NVIDIA Date: 4/6/2011 www.openfabrics.org 1 Technology Conference 2011 October 11-14 San Jose, CA The one event you can t afford to miss Learn about leading-edge
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor
 Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Experiences with the Sparse Matrix-Vector Multiplication on a Many-core Processor Juan C. Pichel Centro de Investigación en Tecnoloxías da Información (CITIUS) Universidade de Santiago de Compostela, Spain
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters
 Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA. NVIDIA Corporation 2012
 Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
Hierarchical DAG Scheduling for Hybrid Distributed Systems
 June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
June 16, 2015 Hierarchical DAG Scheduling for Hybrid Distributed Systems Wei Wu, Aurelien Bouteiller, George Bosilca, Mathieu Faverge, Jack Dongarra IPDPS 2015 Outline! Introduction & Motivation! Hierarchical
Outline 1 Motivation 2 Theory of a non-blocking benchmark 3 The benchmark and results 4 Future work
 Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Using Non-blocking Operations in HPC to Reduce Execution Times David Buettner, Julian Kunkel, Thomas Ludwig Euro PVM/MPI September 8th, 2009 Outline 1 Motivation 2 Theory of a non-blocking benchmark 3
Accelerating Spark RDD Operations with Local and Remote GPU Devices
 Accelerating Spark RDD Operations with Local and Remote GPU Devices Yasuhiro Ohno, Shin Morishima, and Hiroki Matsutani Dept.ofICS,KeioUniversity, 3-14-1 Hiyoshi, Kohoku, Yokohama, Japan 223-8522 Email:
Accelerating Spark RDD Operations with Local and Remote GPU Devices Yasuhiro Ohno, Shin Morishima, and Hiroki Matsutani Dept.ofICS,KeioUniversity, 3-14-1 Hiyoshi, Kohoku, Yokohama, Japan 223-8522 Email:
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Exploiting InfiniBand and GPUDirect Technology for High Performance Collectives on GPU Clusters
 Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Exploiting InfiniBand and Direct Technology for High Performance Collectives on Clusters Ching-Hsiang Chu chu.368@osu.edu Department of Computer Science and Engineering The Ohio State University OSU Booth
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Motivation Hardware Overview Programming model. GPU computing. Part 1: General introduction. Ch. Hoelbling. Wuppertal University
 Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
GETTING STARTED WITH CUDA SDK SAMPLES
 GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE
 HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
HETEROGENEOUS SYSTEM ARCHITECTURE: PLATFORM FOR THE FUTURE Haibo Xie, Ph.D. Chief HSA Evangelist AMD China OUTLINE: The Challenges with Computing Today Introducing Heterogeneous System Architecture (HSA)
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Distributed-Shared CUDA: Virtualization of Large-Scale GPU Systems for Programmability and Reliability
 Distributed-Shared CUDA: Virtualization of Large-Scale GPU Systems for Programmability and Reliability Atsushi Kawai, Kenji Yasuoka Department of Mechanical Engineering, Keio University Yokohama, Japan
Distributed-Shared CUDA: Virtualization of Large-Scale GPU Systems for Programmability and Reliability Atsushi Kawai, Kenji Yasuoka Department of Mechanical Engineering, Keio University Yokohama, Japan
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms
 Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Analysis and Optimization of Power Consumption in the Iterative Solution of Sparse Linear Systems on Multi-core and Many-core Platforms H. Anzt, V. Heuveline Karlsruhe Institute of Technology, Germany
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
"On the Capability and Achievable Performance of FPGAs for HPC Applications"
 "On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
"On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
Manuel F. Dolz, Juan C. Fernández, Rafael Mayo, Enrique S. Quintana-Ortí. High Performance Computing & Architectures (HPCA)
") EnergySaving Cluster Roll: Power Saving System for Clusters Manuel F. Dolz, Juan C. Fernández, Rafael Mayo, Enrique S. Quintana-Ortí High Performance Computing & Architectures (HPCA) University Jaume I
EnergySaving Cluster Roll: Power Saving System for Clusters Manuel F. Dolz, Juan C. Fernández, Rafael Mayo, Enrique S. Quintana-Ortí High Performance Computing & Architectures (HPCA) University Jaume I
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures
 A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
A Proposal to Extend the OpenMP Tasking Model for Heterogeneous Architectures E. Ayguade 1,2, R.M. Badia 2,4, D. Cabrera 2, A. Duran 2, M. Gonzalez 1,2, F. Igual 3, D. Jimenez 1, J. Labarta 1,2, X. Martorell
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
GPU Clusters for High- Performance Computing Jeremy Enos Innovative Systems Laboratory
 GPU Clusters for High- Performance Computing Jeremy Enos Innovative Systems Laboratory National Center for Supercomputing Applications University of Illinois at Urbana-Champaign Presentation Outline NVIDIA
GPU Clusters for High- Performance Computing Jeremy Enos Innovative Systems Laboratory National Center for Supercomputing Applications University of Illinois at Urbana-Champaign Presentation Outline NVIDIA
GPU ARCHITECTURE Chris Schultz, June 2017
 Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink
 Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Optimizing Out-of-Core Nearest Neighbor Problems on Multi-GPU Systems Using NVLink Rajesh Bordawekar IBM T. J. Watson Research Center bordaw@us.ibm.com Pidad D Souza IBM Systems pidsouza@in.ibm.com 1 Outline
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU