UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss
|
|
|
- Verity Dennis
- 5 years ago
- Views:
Transcription
1 UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss AAAI 2018, New Orleans, USA Simon Meister, Junhwa Hur, and Stefan Roth Department of Computer Science, TU Darmstadt



2 2 Deep Networks for Optical Flow Deep CNNs for flow e.g. FlowNet: Encoder-Decoder network Given two images, outputs dense flow Real-time inference with high accuracy Supervision from synthetic datasets Fischer et al. (2015), "FlowNet: Learning Optical Flow with Convolutional Networks"







3 3 Domain Mismatch Training domains Domains of interest
 Design proxy loss")
4 4 Training with Realistic Data Unsupervised deep learning for optical flow Train on the target domain No ground truth flow Unlabeled frame pairs (e.g. from video) Design proxy loss
5 5 Unsupervised Loss (Baseline) Use classical optical flow constraints [Yu et al.] Backward-warp II 2 (using ww ff ) with Bilinear sampling [Jaderberg et al.] of II 2 at ww ff (xx) Data loss EE DD : brightness difference of II 1 and backward-warped II 2 First order smoothness loss EE SS : difference of neighboring flows II 1 Backward warp ww ff II 2 (xx + ww ff ) Smoothness loss EE SS Data loss EE DD II 2 Brightness constancy: II 1 (xx) II 2 xx + ww ff (xx) Jaderberg et al. (2015), "Spatial Transformer Networks" Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"
6 6 Unsupervised Loss (Baseline) Issues with this most basic loss Lighting changes brightness constancy violated Occlusions can t compare II 1 (xx) and II 2 xx + ww ff First-order smoothness may be limiting II 1 Backward warp ww ff II 2 (xx + ww ff ) Smoothness loss EE SS Data loss EE DD II 2 Brightness constancy: II 1 (xx) II 2 xx + ww ff (xx)
 ww ff oo ff Forward-backward consistency ww bb oo bb II 2 Smoothness loss EE SS Consistency loss EE CC Data loss EE DD II 1 (xx + ww")
7 7 UnFlow Apply advanced ideas from classical optical flow to deep learning Robustness to lighting changes (census transform) Occlusion handling (bidirectional flow) Second-order smoothness II 1 Backward warp II 2 (xx + ww ff ) ww ff oo ff Forward-backward consistency ww bb oo bb II 2 Smoothness loss EE SS Consistency loss EE CC Data loss EE DD II 1 (xx + ww bb )
 with CNN FlowNetC")


8 8 UnFlow Compute bidirectional flow (ww ff, ww bb ) with CNN FlowNetC (or any other optical flow network) First image II 1 Forward flow ww ff (II 1, II 2 ) Second image II 2 Shared weights Backward flow ww bb (II 2, II 1 )
9 9 UnFlow Given bidirectional flow Forward-backward check [Sundaram et al.]: compare ww ff (xx) and ww bb Should be inverse to each other for non-occluded xx Threshold Occlusion flag oo ff (swap f/b for oo bb ) Below? Consistency loss EE CC for difference xx + ww ff xx II 1 ww ff oo ff Forward-backward consistency ww bb oo bb II 2 Consistency loss EE CC Sundaram et al. (2010), Dense point trajectories by GPU-accelerated large displacement optical flow"
10 10 UnFlow Bidirectional image-based loss Compare II 1 and backward-warped II 2 (using ww ff ) Bilinear sampling [Jaderberg et al.] at ww ff (xx) Compare II 2 and backward-warped II 1 (using ww bb ) II 1 Backward warp ww ff II 2 (xx + ww ff ) II 2 ww bb II 1 (xx + ww bb ) Jaderberg et al. (2015), "Spatial Transformer Networks"
11 11 UnFlow Data loss EE DD Census transform [Stein] of II 1 and II 2 xx + ww ff Invariant to many changes due to lighting Only at non-occluded pixels (oo ff = 0) Same for II 2 and II 1 (xx + ww bb ) x II 1 Backward warp II 2 (xx + ww ff ) ww ff oo ff Forward-backward consistency ww bb oo bb II 2 Consistency loss EE CC Data loss EE DD II 1 (xx + ww bb ) Stein (2004), "Efficient computation of optical flow using the census transform"
12 12 UnFlow Smoothness loss EE SS Second-order regularizer [Trobin et al.] Penalizes large second derivatives of the flow ww ff (or ww bb ) Encourages collinear neighbors The only loss at occluded pixels (oo ff = 1) II 1 Backward warp II 2 (xx + ww ff ) ww ff oo ff Forward-backward consistency ww bb oo bb II 2 Smoothness loss EE SS Consistency loss EE CC Data loss EE DD II 1 (xx + ww bb ) Trobin et al. (2008), An unbiased second-order prior for high-accuracy motion estimation"
13 13 Iterative refinement Network stacking [Ilg et al.] FlowNetC FlowNetS Input first flow estimates and warped images First network Second network (not shared) ww ff II 2 (xx + ww ff ) ww ff,2 II 1 II 2 ww bb II 1 (xx + ww bb ) UnFlow-C UnFlow-CS ww bb,2 Ilg et al. (2017), "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks"

14 14 Training Schedule Curriculum (100% unsupervised) 1. SYNTHIA pre-training Large synthetic dataset with simple lighting 2. KITTI raw Large real-world driving dataset Excluding small number of frames with ground truth flow No need for specifically generated synthetic optical flow datasets FlyingChairs, FlyingThings3D,
15 Results 15
16 16 Metrics Average Endpoint Error (AEE) Average euclidean distance of prediction to ground truth flow vectors KITTI Outliers Ratio of pixels where flow estimate is wrong by both 3 pixels and 5% (at least)
17 17 Loss Ablation KITTI 2012 Comparing Baseline [Yu et al.] vs. UnFlow-C Brightness constancy census loss Reduces AEE by 35% Data loss Smoothness Occlusion AEE (All) Outliers (All) Brightness 1st-order % Census 1st-order % Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"
18 18 Loss Ablation KITTI 2012 Comparing Baseline [Yu et al.] vs. UnFlow-C 1st 2nd order smoothness Reduces AEE by 5% and outliers by 17% Data loss Smoothness Occlusion AEE (All) Outliers (All) Brightness 1st-order % Census 1st-order % Census 2nd-order % Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"
19 19 Loss Ablation KITTI 2012 Comparing Baseline [Yu et al.] vs. UnFlow-C Forward-backward mechanisms (occlusion masking & consistency) Reduces AEE by 14% Data loss Smoothness Occlusion AEE (All) Outliers (All) Brightness 1st-order % Census 1st-order % Census 2nd-order % Census 2nd-order Forward-backward check % Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"
20 20 Loss Ablation KITTI 2012 Comparing Baseline [Yu et al.] vs. UnFlow-C UnFlow reduces AEE and outliers by 48% Similar observations on KITTI 2015 Data loss Smoothness Occlusion AEE (All) Outliers (All) Brightness 1st-order % Census 1st-order % Census 2nd-order % Census 2nd-order Forward-backward check % Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"
 Input images Ground truth flow Baseline Predicted flow UnFlow Predicted")
21 21 Baseline vs. UnFlow (KITTI 2015) Input images Ground truth flow Baseline Predicted flow UnFlow Predicted flow Flow error (red = high, blue = low) Flow error (red = high, blue = low)
22 22 Benchmarks (KITTI) non-finetuned Comparing supervised networks vs. UnFlow Similar networks trained on synthetic domains UnFlow reduces AEE by up to 49% (FlowNetS, 2012) Method AEE (All) 2012 train FlowNetS+ft [Dosovitskiy et al.] 7.5 AEE (All) 2015 train FlowNet2-C [Ilg et al.] UnFlow-C [ours] Dosovitsky et al. (2015), "FlowNet: Learning optical flow with convolutional networks" Ilg et al. (2017), "FlowNet 2.0: Evolution of optical flow estimation with deep networks"
23 23 Benchmarks (KITTI) non-finetuned Comparing supervised networks vs. UnFlow UnFlow even performs slightly better on off-domain data Method AEE (All) 2012 train AEE (All) 2015 train AEE (All) Middlebury FlowNetS+ft [Dosovitskiy et al.] FlowNet2-C [Ilg et al.] UnFlow-C [ours] Dosovitsky et al. (2015), "FlowNet: Learning optical flow with convolutional networks"
24 24 Conclusion UnFlow Comprehensive unsupervised proxy loss 48% improvement over brightness constancy baseline Outperforms synthetic off-domain supervision Code open-sourced at
25 Supplementary slides 25
 Supervised fine-tuning KITTI 2012 & 2015 train Method AEE (All) 2012 test Outliers 2015 test")
![FlowNet2-ft-kitti [Ilg et al.] 1.8 10.41% Ground truth flow UnFlow-CSS-ft 1.7 11.](/docs-images/89/98111371/images/26-1.jpg "11% Competetive fine-tuning performance without pre-training with special synthetic datasets Ilg et al.")
26 26 Supervised Fine-tuning Input images 1. Unsupervised training 2. (optional) Supervised fine-tuning KITTI 2012 & 2015 train Method AEE (All) 2012 test Outliers 2015 test FlowNet2-ft-kitti [Ilg et al.] % Ground truth flow UnFlow-CSS-ft % Competetive fine-tuning performance without pre-training with special synthetic datasets Ilg et al. (2017), "FlowNet 2.0: Evolution of optical flow estimation with deep networks"
27 27 Benchmarks (KITTI) non-finetuned Comparing previous unsupervised networks vs. UnFlow Similar networks & training schedules UnFlow reduces AEE by up to 66% Method AEE (All) 2012 train UnsupFlownet [Yu et al.] 11.3 DSTFlow [Ren et al.] UnFlow-C [ours] 3.78 Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness" Ren et al. (2017), "Unsupervised deep learning for optical flow estimation"
28 28 Loss Ablation KITTI 2012 Comparing Baseline [Yu et al.] vs. UnFlow Training on SYNTHIA instead of FlyingChairs slightly improves AEE Our baseline re-implementation is more accurate than the results reported by Yu et al. (AEE of 11.3 vs. our 8.26) Data loss Smoothness Occlusion AEE (All) Outliers (All) Brightness 1st-order 8.26 Brightness 1st-order % Census 1st-order % Census 2nd-order % Census 2nd-order Forward-backward check % Yu et al. (2016), "Unsupervised learning of optical flow via brightness constancy and motion smoothness"



29 29 FlowNetS / UnsupFlownet / UnFlow-CSS FlowNetS - KITTI 2012 flow error (white = high,black = low) Occluded sections are red FlowNetS - predicted flow UnsupFlownet - KITTI 2012 flow error UnsupFlowNet - predicted flow UnFlow-CSS - KITTI 2012 flow error UnFlow-CSS - predicted flow
")


 Flow blue")
30 30 Baseline vs. UnFlow (KITTI 2015) Input images Ground truth flow Baseline Predicted flow UnFlow Predicted flow Flow error (red = high, blue = low) Flow error (red = high, blue = low)


31 UnFlow-CSS-ft (KITTI 2015 test) 31
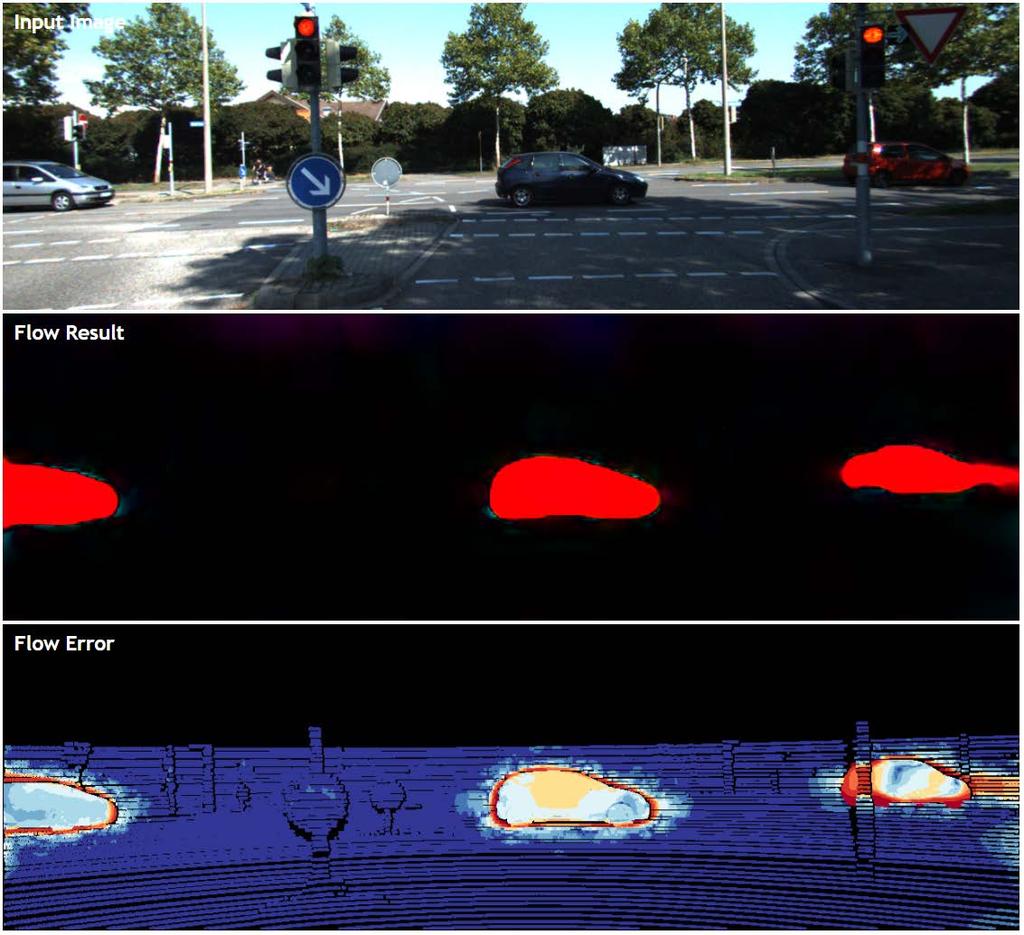

32 UnFlow-CSS-ft (KITTI 2015 test) 32
 Flow error (red = high, blue = low)")
33 33 Baseline vs. UnFlow (KITTI 2015) Flow error (red = high, blue = low) Baseline Flow error (red = high, blue = low) UnFlow
34 34 Baseline vs. UnFlow (KITTI 2015) Flow error (red = high, blue = low) Baseline Flow error (red = high, blue = low) UnFlow
arxiv: v1 [cs.cv] 7 May 2018
![arxiv: v1 [cs.cv] 7 May 2018](/thumbs/79/78829573.jpg "arxiv: v1 [cs.cv] 7 May 2018") LEARNING OPTICAL FLOW VIA DILATED NETWORKS AND OCCLUSION REASONING Yi Zhu and Shawn Newsam University of California, Merced 5200 N Lake Rd, Merced, CA, US {yzhu25, snewsam}@ucmerced.edu arxiv:1805.02733v1
LEARNING OPTICAL FLOW VIA DILATED NETWORKS AND OCCLUSION REASONING Yi Zhu and Shawn Newsam University of California, Merced 5200 N Lake Rd, Merced, CA, US {yzhu25, snewsam}@ucmerced.edu arxiv:1805.02733v1
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Models Matter, So Does Training: An Empirical Study of CNNs for Optical Flow Estimation
 1 Models Matter, So Does Training: An Empirical Study of CNNs for Optical Flow Estimation Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz arxiv:1809.05571v1 [cs.cv] 14 Sep 2018 Abstract We investigate
1 Models Matter, So Does Training: An Empirical Study of CNNs for Optical Flow Estimation Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz arxiv:1809.05571v1 [cs.cv] 14 Sep 2018 Abstract We investigate
Semi-Supervised Learning for Optical Flow with Generative Adversarial Networks
 Semi-Supervised Learning for Optical Flow with Generative Adversarial Networks Wei-Sheng Lai 1 Jia-Bin Huang 2 Ming-Hsuan Yang 1,3 1 University of California, Merced 2 Virginia Tech 3 Nvidia Research 1
Semi-Supervised Learning for Optical Flow with Generative Adversarial Networks Wei-Sheng Lai 1 Jia-Bin Huang 2 Ming-Hsuan Yang 1,3 1 University of California, Merced 2 Virginia Tech 3 Nvidia Research 1
Supplementary Material for "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks"
 Supplementary Material for "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks" Architecture Datasets S short S long S fine FlowNetS FlowNetC Chairs 15.58 - - Chairs - 14.60 14.28 Things3D
Supplementary Material for "FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks" Architecture Datasets S short S long S fine FlowNetS FlowNetC Chairs 15.58 - - Chairs - 14.60 14.28 Things3D
arxiv: v2 [cs.cv] 4 Apr 2018
![arxiv: v2 [cs.cv] 4 Apr 2018](/thumbs/82/84891090.jpg "arxiv: v2 [cs.cv] 4 Apr 2018") Occlusion Aware Unsupervised Learning of Optical Flow Yang Wang 1 Yi Yang 1 Zhenheng Yang 2 Liang Zhao 1 Peng Wang 1 Wei Xu 1,3 1 Baidu Research 2 University of Southern California 3 National Engineering
Occlusion Aware Unsupervised Learning of Optical Flow Yang Wang 1 Yi Yang 1 Zhenheng Yang 2 Liang Zhao 1 Peng Wang 1 Wei Xu 1,3 1 Baidu Research 2 University of Southern California 3 National Engineering
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
Optical flow. Cordelia Schmid
 Optical flow Cordelia Schmid Motion field The motion field is the projection of the 3D scene motion into the image Optical flow Definition: optical flow is the apparent motion of brightness patterns in
Optical flow Cordelia Schmid Motion field The motion field is the projection of the 3D scene motion into the image Optical flow Definition: optical flow is the apparent motion of brightness patterns in
Optical flow. Cordelia Schmid
 Optical flow Cordelia Schmid Motion field The motion field is the projection of the 3D scene motion into the image Optical flow Definition: optical flow is the apparent motion of brightness patterns in
Optical flow Cordelia Schmid Motion field The motion field is the projection of the 3D scene motion into the image Optical flow Definition: optical flow is the apparent motion of brightness patterns in
arxiv: v1 [cs.cv] 25 Feb 2019
![arxiv: v1 [cs.cv] 25 Feb 2019](/thumbs/94/120600417.jpg "arxiv: v1 [cs.cv] 25 Feb 2019") DD: Learning Optical with Unlabeled Data Distillation Pengpeng Liu, Irwin King, Michael R. Lyu, Jia Xu The Chinese University of Hong Kong, Shatin, N.T., Hong Kong Tencent AI Lab, Shenzhen, China {ppliu,
DD: Learning Optical with Unlabeled Data Distillation Pengpeng Liu, Irwin King, Michael R. Lyu, Jia Xu The Chinese University of Hong Kong, Shatin, N.T., Hong Kong Tencent AI Lab, Shenzhen, China {ppliu,
arxiv: v1 [cs.cv] 22 Jan 2016
![arxiv: v1 [cs.cv] 22 Jan 2016](/thumbs/76/73216866.jpg "arxiv: v1 [cs.cv] 22 Jan 2016") UNSUPERVISED CONVOLUTIONAL NEURAL NETWORKS FOR MOTION ESTIMATION Aria Ahmadi, Ioannis Patras School of Electronic Engineering and Computer Science Queen Mary University of London Mile End road, E1 4NS,
UNSUPERVISED CONVOLUTIONAL NEURAL NETWORKS FOR MOTION ESTIMATION Aria Ahmadi, Ioannis Patras School of Electronic Engineering and Computer Science Queen Mary University of London Mile End road, E1 4NS,
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 19: Optical flow http://en.wikipedia.org/wiki/barberpole_illusion Readings Szeliski, Chapter 8.4-8.5 Announcements Project 2b due Tuesday, Nov 2 Please sign
CS6670: Computer Vision Noah Snavely Lecture 19: Optical flow http://en.wikipedia.org/wiki/barberpole_illusion Readings Szeliski, Chapter 8.4-8.5 Announcements Project 2b due Tuesday, Nov 2 Please sign
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos
 Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos Yang Wang 1 Zhenheng Yang 2 Peng Wang 1 Yi Yang 1 Chenxu Luo 3 Wei Xu 1 1 Baidu Research 2 University of Southern California
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos Yang Wang 1 Zhenheng Yang 2 Peng Wang 1 Yi Yang 1 Chenxu Luo 3 Wei Xu 1 1 Baidu Research 2 University of Southern California
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 11 140311 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Motion Analysis Motivation Differential Motion Optical
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 11 140311 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Motion Analysis Motivation Differential Motion Optical
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation
 Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation Osama Makansi, Eddy Ilg, and Thomas Brox Department of Computer Science, University of Freiburg 1 Computation
Supplemental Material for End-to-End Learning of Video Super-Resolution with Motion Compensation Osama Makansi, Eddy Ilg, and Thomas Brox Department of Computer Science, University of Freiburg 1 Computation
arxiv: v1 [cs.cv] 9 May 2018
![arxiv: v1 [cs.cv] 9 May 2018](/thumbs/89/97538145.jpg "arxiv: v1 [cs.cv] 9 May 2018") Layered Optical Flow Estimation Using a Deep Neural Network with a Soft Mask Xi Zhang, Di Ma, Xu Ouyang, Shanshan Jiang, Lin Gan, Gady Agam, Computer Science Department, Illinois Institute of Technology
Layered Optical Flow Estimation Using a Deep Neural Network with a Soft Mask Xi Zhang, Di Ma, Xu Ouyang, Shanshan Jiang, Lin Gan, Gady Agam, Computer Science Department, Illinois Institute of Technology
EE795: Computer Vision and Intelligent Systems
 EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
EE795: Computer Vision and Intelligent Systems Spring 2012 TTh 17:30-18:45 FDH 204 Lecture 14 130307 http://www.ee.unlv.edu/~b1morris/ecg795/ 2 Outline Review Stereo Dense Motion Estimation Translational
arxiv: v1 [cs.cv] 6 Dec 2016
![arxiv: v1 [cs.cv] 6 Dec 2016](/thumbs/73/69202460.jpg "arxiv: v1 [cs.cv] 6 Dec 2016") FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, Thomas Brox University of Freiburg, Germany arxiv:1612.01925v1
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, Thomas Brox University of Freiburg, Germany arxiv:1612.01925v1
PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume
 : CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz NVIDIA Abstract We present a compact but effective CNN model for optical flow, called.
: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz NVIDIA Abstract We present a compact but effective CNN model for optical flow, called.
Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation
 Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation Eddy Ilg *, Tonmoy Saikia *, Margret Keuper, and Thomas Brox University of Freiburg,
Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation Eddy Ilg *, Tonmoy Saikia *, Margret Keuper, and Thomas Brox University of Freiburg,
Deep Learning For Image Registration
 Deep Learning For Image Registration Yiping Lu School Of Mathmatical Science Peking university. luyiping9712@pku.edu.cn Abstract Image registration is an important task in computer vision and image processing
Deep Learning For Image Registration Yiping Lu School Of Mathmatical Science Peking university. luyiping9712@pku.edu.cn Abstract Image registration is an important task in computer vision and image processing
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Evaluating optical flow vectors through collision points of object trajectories in varying computergenerated snow intensities for autonomous vehicles
 Eingebettete Systeme Evaluating optical flow vectors through collision points of object trajectories in varying computergenerated snow intensities for autonomous vehicles 25/6/2018, Vikas Agrawal, Marcel
Eingebettete Systeme Evaluating optical flow vectors through collision points of object trajectories in varying computergenerated snow intensities for autonomous vehicles 25/6/2018, Vikas Agrawal, Marcel
Ninio, J. and Stevens, K. A. (2000) Variations on the Hermann grid: an extinction illusion. Perception, 29,
 Variations on the Hermann grid: an extinction illusion. Perception, 29,") Ninio, J. and Stevens, K. A. (2000) Variations on the Hermann grid: an extinction illusion. Perception, 29, 1209-1217. CS 4495 Computer Vision A. Bobick Sparse to Dense Correspodence Building Rome in
Ninio, J. and Stevens, K. A. (2000) Variations on the Hermann grid: an extinction illusion. Perception, 29, 1209-1217. CS 4495 Computer Vision A. Bobick Sparse to Dense Correspodence Building Rome in
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
Peripheral drift illusion
 Peripheral drift illusion Does it work on other animals? Computer Vision Motion and Optical Flow Many slides adapted from J. Hays, S. Seitz, R. Szeliski, M. Pollefeys, K. Grauman and others Video A video
Peripheral drift illusion Does it work on other animals? Computer Vision Motion and Optical Flow Many slides adapted from J. Hays, S. Seitz, R. Szeliski, M. Pollefeys, K. Grauman and others Video A video
arxiv: v1 [cs.cv] 21 Sep 2018
![arxiv: v1 [cs.cv] 21 Sep 2018](/thumbs/87/95557631.jpg "arxiv: v1 [cs.cv] 21 Sep 2018") Temporal Interpolation as an Unsupervised Pretraining Task for Optical Flow Estimation Jonas Wulff 1,2 Michael J. Black 1 arxiv:1809.08317v1 [cs.cv] 21 Sep 2018 1 Max-Planck Institute for Intelligent Systems,
Temporal Interpolation as an Unsupervised Pretraining Task for Optical Flow Estimation Jonas Wulff 1,2 Michael J. Black 1 arxiv:1809.08317v1 [cs.cv] 21 Sep 2018 1 Max-Planck Institute for Intelligent Systems,
S7348: Deep Learning in Ford's Autonomous Vehicles. Bryan Goodman Argo AI 9 May 2017
 S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
S7348: Deep Learning in Ford's Autonomous Vehicles Bryan Goodman Argo AI 9 May 2017 1 Ford s 12 Year History in Autonomous Driving Today: examples from Stereo image processing Object detection Using RNN
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Dense Image-based Motion Estimation Algorithms & Optical Flow
 Dense mage-based Motion Estimation Algorithms & Optical Flow Video A video is a sequence of frames captured at different times The video data is a function of v time (t) v space (x,y) ntroduction to motion
Dense mage-based Motion Estimation Algorithms & Optical Flow Video A video is a sequence of frames captured at different times The video data is a function of v time (t) v space (x,y) ntroduction to motion
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
 Net 2.0: Evolution of Optical Estimation with Deep Networks Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, Thomas Brox University of Freiburg, Germany {ilg,mayern,saikiat,keuper,dosovits,brox}@cs.uni-freiburg.de
Net 2.0: Evolution of Optical Estimation with Deep Networks Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, Thomas Brox University of Freiburg, Germany {ilg,mayern,saikiat,keuper,dosovits,brox}@cs.uni-freiburg.de
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features
 Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
Camera-based Vehicle Velocity Estimation using Spatiotemporal Depth and Motion Features Moritz Kampelmuehler* kampelmuehler@student.tugraz.at Michael Mueller* michael.g.mueller@student.tugraz.at Christoph
arxiv: v2 [cs.cv] 7 Oct 2018
![arxiv: v2 [cs.cv] 7 Oct 2018](/thumbs/92/110264683.jpg "arxiv: v2 [cs.cv] 7 Oct 2018") Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation Anurag Ranjan 1 Varun Jampani 2 arxiv:1805.09806v2 [cs.cv] 7 Oct 2018 Kihwan Kim 2 Deqing
Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation Anurag Ranjan 1 Varun Jampani 2 arxiv:1805.09806v2 [cs.cv] 7 Oct 2018 Kihwan Kim 2 Deqing
Visual Object Tracking. Jianan Wu Megvii (Face++) Researcher Dec 2017
 Researcher Dec 2017") Visual Object Tracking Jianan Wu Megvii (Face++) Researcher wjn@megvii.com Dec 2017 Applications From image to video: Augmented Reality Motion Capture Surveillance Sports Analysis Wait. What is visual
Visual Object Tracking Jianan Wu Megvii (Face++) Researcher wjn@megvii.com Dec 2017 Applications From image to video: Augmented Reality Motion Capture Surveillance Sports Analysis Wait. What is visual
Training models for road scene understanding with automated ground truth Dan Levi
 Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Training models for road scene understanding with automated ground truth Dan Levi With: Noa Garnett, Ethan Fetaya, Shai Silberstein, Rafi Cohen, Shaul Oron, Uri Verner, Ariel Ayash, Kobi Horn, Vlad Golder,
Introduction to Deep Learning
 ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
ENEE698A : Machine Learning Seminar Introduction to Deep Learning Raviteja Vemulapalli Image credit: [LeCun 1998] Resources Unsupervised feature learning and deep learning (UFLDL) tutorial (http://ufldl.stanford.edu/wiki/index.php/ufldl_tutorial)
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601
 with Facial KeyPoints using Spatial Fusion Convolutional Network. Nathan Sun CIS601") Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Disguised Face Identification (DFI) with Facial KeyPoints using Spatial Fusion Convolutional Network Nathan Sun CIS601 Introduction Face ID is complicated by alterations to an individual s appearance Beard,
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
A Deep Learning Framework for Authorship Classification of Paintings
 A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
A Deep Learning Framework for Authorship Classification of Paintings Kai-Lung Hua ( 花凱龍 ) Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology Taipei,
Two-Stream Convolutional Networks for Action Recognition in Videos
 Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
Two-Stream Convolutional Networks for Action Recognition in Videos Karen Simonyan Andrew Zisserman Cemil Zalluhoğlu Introduction Aim Extend deep Convolution Networks to action recognition in video. Motivation
EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES
 EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES J. Liu 1, S. Ji 1,*, C. Zhang 1, Z. Qin 1 1 School of Remote Sensing and Information Engineering, Wuhan University,
EVALUATION OF DEEP LEARNING BASED STEREO MATCHING METHODS: FROM GROUND TO AERIAL IMAGES J. Liu 1, S. Ji 1,*, C. Zhang 1, Z. Qin 1 1 School of Remote Sensing and Information Engineering, Wuhan University,
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Motion and Optical Flow. Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi
 Motion and Optical Flow Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Motion and Optical Flow Slides from Ce Liu, Steve Seitz, Larry Zitnick, Ali Farhadi We live in a moving world Perceiving, understanding and predicting motion is an important part of our daily lives Motion
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Filter Flow: Supplemental Material
 Filter Flow: Supplemental Material Steven M. Seitz University of Washington Simon Baker Microsoft Research We include larger images and a number of additional results obtained using Filter Flow [5]. 1
Filter Flow: Supplemental Material Steven M. Seitz University of Washington Simon Baker Microsoft Research We include larger images and a number of additional results obtained using Filter Flow [5]. 1
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Scene Text Recognition for Augmented Reality. Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science
 Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Scene Text Recognition for Augmented Reality Sagar G V Adviser: Prof. Bharadwaj Amrutur Indian Institute Of Science Outline Research area and motivation Finding text in natural scenes Prior art Improving
Comparison of stereo inspired optical flow estimation techniques
 Comparison of stereo inspired optical flow estimation techniques ABSTRACT The similarity of the correspondence problems in optical flow estimation and disparity estimation techniques enables methods to
Comparison of stereo inspired optical flow estimation techniques ABSTRACT The similarity of the correspondence problems in optical flow estimation and disparity estimation techniques enables methods to
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
arxiv: v1 [cs.cv] 30 Nov 2017
![arxiv: v1 [cs.cv] 30 Nov 2017](/thumbs/75/71644976.jpg "arxiv: v1 [cs.cv] 30 Nov 2017") Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation Huaizu Jiang 1 Deqing Sun 2 Varun Jampani 2 Ming-Hsuan Yang 3,2 Erik Learned-Miller 1 Jan Kautz 2 1 UMass Amherst
Super SloMo: High Quality Estimation of Multiple Intermediate Frames for Video Interpolation Huaizu Jiang 1 Deqing Sun 2 Varun Jampani 2 Ming-Hsuan Yang 3,2 Erik Learned-Miller 1 Jan Kautz 2 1 UMass Amherst
Conditional Prior Networks for Optical Flow
 Conditional Prior Networks for Optical Flow Yanchao Yang Stefano Soatto UCLA Vision Lab University of California, Los Angeles, CA 90095 {yanchao.yang, soatto}@cs.ucla.edu Abstract. Classical computation
Conditional Prior Networks for Optical Flow Yanchao Yang Stefano Soatto UCLA Vision Lab University of California, Los Angeles, CA 90095 {yanchao.yang, soatto}@cs.ucla.edu Abstract. Classical computation
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Deep Optical Flow Estimation Via Multi-Scale Correspondence Structure Learning
 Deep Optical Flow Estimation Via Multi-Scale Correspondence Structure Learning Shanshan Zhao 1, Xi Li 1,2,, Omar El Farouk Bourahla 1 1 Zhejiang University, Hangzhou, China 2 Alibaba-Zhejiang University
Deep Optical Flow Estimation Via Multi-Scale Correspondence Structure Learning Shanshan Zhao 1, Xi Li 1,2,, Omar El Farouk Bourahla 1 1 Zhejiang University, Hangzhou, China 2 Alibaba-Zhejiang University
Unsupervised Learning of Stereo Matching
 Unsupervised Learning of Stereo Matching Chao Zhou 1 Hong Zhang 1 Xiaoyong Shen 2 Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Youtu Lab, Tencent {zhouc, zhangh}@cse.cuhk.edu.hk dylanshen@tencent.com
Unsupervised Learning of Stereo Matching Chao Zhou 1 Hong Zhang 1 Xiaoyong Shen 2 Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Youtu Lab, Tencent {zhouc, zhangh}@cse.cuhk.edu.hk dylanshen@tencent.com
Spatio-Temporal Transformer Network for Video Restoration
 Spatio-Temporal Transformer Network for Video Restoration Tae Hyun Kim 1,2, Mehdi S. M. Sajjadi 1,3, Michael Hirsch 1,4, Bernhard Schölkopf 1 1 Max Planck Institute for Intelligent Systems, Tübingen, Germany
Spatio-Temporal Transformer Network for Video Restoration Tae Hyun Kim 1,2, Mehdi S. M. Sajjadi 1,3, Michael Hirsch 1,4, Bernhard Schölkopf 1 1 Max Planck Institute for Intelligent Systems, Tübingen, Germany
Unsupervised Learning of Spatiotemporally Coherent Metrics
 Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
Unsupervised Learning of Spatiotemporally Coherent Metrics Ross Goroshin, Joan Bruna, Jonathan Tompson, David Eigen, Yann LeCun arxiv 2015. Presented by Jackie Chu Contributions Insight between slow feature
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection
 MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
MCMOT: Multi-Class Multi-Object Tracking using Changing Point Detection ILSVRC 2016 Object Detection from Video Byungjae Lee¹, Songguo Jin¹, Enkhbayar Erdenee¹, Mi Young Nam², Young Gui Jung², Phill Kyu
Real-Time Simultaneous 3D Reconstruction and Optical Flow Estimation
 Real-Time Simultaneous 3D Reconstruction and Optical Flow Estimation Menandro Roxas Takeshi Oishi Institute of Industrial Science, The University of Tokyo roxas, oishi @cvl.iis.u-tokyo.ac.jp Abstract We
Real-Time Simultaneous 3D Reconstruction and Optical Flow Estimation Menandro Roxas Takeshi Oishi Institute of Industrial Science, The University of Tokyo roxas, oishi @cvl.iis.u-tokyo.ac.jp Abstract We
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
arxiv: v1 [cs.cv] 14 Dec 2016
![arxiv: v1 [cs.cv] 14 Dec 2016](/thumbs/88/115095109.jpg "arxiv: v1 [cs.cv] 14 Dec 2016") Detect, Replace, Refine: Deep Structured Prediction For Pixel Wise Labeling arxiv:1612.04770v1 [cs.cv] 14 Dec 2016 Spyros Gidaris University Paris-Est, LIGM Ecole des Ponts ParisTech spyros.gidaris@imagine.enpc.fr
Detect, Replace, Refine: Deep Structured Prediction For Pixel Wise Labeling arxiv:1612.04770v1 [cs.cv] 14 Dec 2016 Spyros Gidaris University Paris-Est, LIGM Ecole des Ponts ParisTech spyros.gidaris@imagine.enpc.fr
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Motion Estimation using Block Overlap Minimization
 Motion Estimation using Block Overlap Minimization Michael Santoro, Ghassan AlRegib, Yucel Altunbasak School of Electrical and Computer Engineering, Georgia Institute of Technology Atlanta, GA 30332 USA
Motion Estimation using Block Overlap Minimization Michael Santoro, Ghassan AlRegib, Yucel Altunbasak School of Electrical and Computer Engineering, Georgia Institute of Technology Atlanta, GA 30332 USA
Lecture 20: Tracking. Tuesday, Nov 27
 Lecture 20: Tracking Tuesday, Nov 27 Paper reviews Thorough summary in your own words Main contribution Strengths? Weaknesses? How convincing are the experiments? Suggestions to improve them? Extensions?
Lecture 20: Tracking Tuesday, Nov 27 Paper reviews Thorough summary in your own words Main contribution Strengths? Weaknesses? How convincing are the experiments? Suggestions to improve them? Extensions?
CS4495/6495 Introduction to Computer Vision. 3B-L3 Stereo correspondence
 CS4495/6495 Introduction to Computer Vision 3B-L3 Stereo correspondence For now assume parallel image planes Assume parallel (co-planar) image planes Assume same focal lengths Assume epipolar lines are
CS4495/6495 Introduction to Computer Vision 3B-L3 Stereo correspondence For now assume parallel image planes Assume parallel (co-planar) image planes Assume same focal lengths Assume epipolar lines are
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION
 LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
LEARNING RIGIDITY IN DYNAMIC SCENES FOR SCENE FLOW ESTIMATION Kihwan Kim, Senior Research Scientist Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, Jan Kautz CORRESPENDECES IN COMPUTER
A Fusion Approach for Multi-Frame Optical Flow Estimation
 A Fusion Approach for Multi-Frame Optical Estimation Zhile Ren Orazio Gallo Deqing Sun Ming-Hsuan Yang Erik B. Sudderth Jan Kautz Georgia Tech NVIDIA UC Merced UC Irvine NVIDIA Abstract To date, top-performing
A Fusion Approach for Multi-Frame Optical Estimation Zhile Ren Orazio Gallo Deqing Sun Ming-Hsuan Yang Erik B. Sudderth Jan Kautz Georgia Tech NVIDIA UC Merced UC Irvine NVIDIA Abstract To date, top-performing
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
Segmentation Based Stereo. Michael Bleyer LVA Stereo Vision
 Segmentation Based Stereo Michael Bleyer LVA Stereo Vision What happened last time? Once again, we have looked at our energy function: E ( D) = m( p, dp) + p I < p, q > We have investigated the matching
Segmentation Based Stereo Michael Bleyer LVA Stereo Vision What happened last time? Once again, we have looked at our energy function: E ( D) = m( p, dp) + p I < p, q > We have investigated the matching
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
ACCURATE estimation of optical flow is a useful but challenging. Pyramidal Gradient Matching for Optical Flow Estimation
 1 Pyramidal Gradient Matching for Optical Flow Estimation Yuanwei Li arxiv:1704.03217v1 [cs.cv] 11 Apr 2017 Abstract Initializing optical flow field by either sparse descriptor matching or dense patch
1 Pyramidal Gradient Matching for Optical Flow Estimation Yuanwei Li arxiv:1704.03217v1 [cs.cv] 11 Apr 2017 Abstract Initializing optical flow field by either sparse descriptor matching or dense patch
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Robust Optical Flow Computation Under Varying Illumination Using Rank Transform
 Sensors & Transducers Vol. 69 Issue 4 April 04 pp. 84-90 Sensors & Transducers 04 by IFSA Publishing S. L. http://www.sensorsportal.com Robust Optical Flow Computation Under Varying Illumination Using
Sensors & Transducers Vol. 69 Issue 4 April 04 pp. 84-90 Sensors & Transducers 04 by IFSA Publishing S. L. http://www.sensorsportal.com Robust Optical Flow Computation Under Varying Illumination Using
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Multi-stable Perception. Necker Cube
 Multi-stable Perception Necker Cube Spinning dancer illusion, Nobuyuki Kayahara Multiple view geometry Stereo vision Epipolar geometry Lowe Hartley and Zisserman Depth map extraction Essential matrix
Multi-stable Perception Necker Cube Spinning dancer illusion, Nobuyuki Kayahara Multiple view geometry Stereo vision Epipolar geometry Lowe Hartley and Zisserman Depth map extraction Essential matrix
Optical Flow CS 637. Fuxin Li. With materials from Kristen Grauman, Richard Szeliski, S. Narasimhan, Deqing Sun
 Optical Flow CS 637 Fuxin Li With materials from Kristen Grauman, Richard Szeliski, S. Narasimhan, Deqing Sun Motion and perceptual organization Sometimes, motion is the only cue Motion and perceptual
Optical Flow CS 637 Fuxin Li With materials from Kristen Grauman, Richard Szeliski, S. Narasimhan, Deqing Sun Motion and perceptual organization Sometimes, motion is the only cue Motion and perceptual
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching
 Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching Jiahao Pang Wenxiu Sun Jimmy SJ. Ren Chengxi Yang Qiong Yan SenseTime Group Limited {pangjiahao, sunwenxiu, rensijie,
Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching Jiahao Pang Wenxiu Sun Jimmy SJ. Ren Chengxi Yang Qiong Yan SenseTime Group Limited {pangjiahao, sunwenxiu, rensijie,
What have we leaned so far?
 What have we leaned so far? Camera structure Eye structure Project 1: High Dynamic Range Imaging What have we learned so far? Image Filtering Image Warping Camera Projection Model Project 2: Panoramic
What have we leaned so far? Camera structure Eye structure Project 1: High Dynamic Range Imaging What have we learned so far? Image Filtering Image Warping Camera Projection Model Project 2: Panoramic
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Regionlet Object Detector with Hand-crafted and CNN Feature
 Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
Regionlet Object Detector with Hand-crafted and CNN Feature Xiaoyu Wang Research Xiaoyu Wang Research Ming Yang Horizon Robotics Shenghuo Zhu Alibaba Group Yuanqing Lin Baidu Overview of this section Regionlet
arxiv: v3 [cs.cv] 22 Mar 2018
![arxiv: v3 [cs.cv] 22 Mar 2018](/thumbs/78/77458096.jpg "arxiv: v3 [cs.cv] 22 Mar 2018") IJCV VISI manuscript No. (will be inserted by the editor) What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation? Nikolaus Mayer Eddy Ilg Philipp Fischer Caner Hazirbas
IJCV VISI manuscript No. (will be inserted by the editor) What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation? Nikolaus Mayer Eddy Ilg Philipp Fischer Caner Hazirbas
Convolutional Neural Network Implementation of Superresolution Video
 Convolutional Neural Network Implementation of Superresolution Video David Zeng Stanford University Stanford, CA dyzeng@stanford.edu Abstract This project implements Enhancing and Experiencing Spacetime
Convolutional Neural Network Implementation of Superresolution Video David Zeng Stanford University Stanford, CA dyzeng@stanford.edu Abstract This project implements Enhancing and Experiencing Spacetime
arxiv: v1 [cs.cv] 20 Sep 2017
![arxiv: v1 [cs.cv] 20 Sep 2017](/thumbs/76/74170999.jpg "arxiv: v1 [cs.cv] 20 Sep 2017") SegFlow: Joint Learning for Video Object Segmentation and Optical Flow Jingchun Cheng 1,2 Yi-Hsuan Tsai 2 Shengjin Wang 1 Ming-Hsuan Yang 2 1 Tsinghua University 2 University of California, Merced 1 chengjingchun@gmail.com,
SegFlow: Joint Learning for Video Object Segmentation and Optical Flow Jingchun Cheng 1,2 Yi-Hsuan Tsai 2 Shengjin Wang 1 Ming-Hsuan Yang 2 1 Tsinghua University 2 University of California, Merced 1 chengjingchun@gmail.com,
CUDA GPGPU. Ivo Ihrke Tobias Ritschel Mario Fritz
 CUDA GPGPU Ivo Ihrke Tobias Ritschel Mario Fritz Today 3 Topics Intro to CUDA (NVIDIA slides) How is the GPU hardware organized? What is the programming model? Simple Kernels Hello World Gaussian Filtering
CUDA GPGPU Ivo Ihrke Tobias Ritschel Mario Fritz Today 3 Topics Intro to CUDA (NVIDIA slides) How is the GPU hardware organized? What is the programming model? Simple Kernels Hello World Gaussian Filtering
arxiv: v1 [cs.cv] 13 Dec 2018
![arxiv: v1 [cs.cv] 13 Dec 2018](/thumbs/92/108764739.jpg "arxiv: v1 [cs.cv] 13 Dec 2018") Frame u Frame t Frame s SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception Yue Meng 1 Yongxi Lu 1 Aman Raj 1 Samuel Sunarjo 1 Rui Guo 2 Tara Javidi 1 Gaurav Bansal 2 Dinesh Bharadia 1
Frame u Frame t Frame s SIGNet: Semantic Instance Aided Unsupervised 3D Geometry Perception Yue Meng 1 Yongxi Lu 1 Aman Raj 1 Samuel Sunarjo 1 Rui Guo 2 Tara Javidi 1 Gaurav Bansal 2 Dinesh Bharadia 1
Lucas-Kanade Motion Estimation. Thanks to Steve Seitz, Simon Baker, Takeo Kanade, and anyone else who helped develop these slides.
 Lucas-Kanade Motion Estimation Thanks to Steve Seitz, Simon Baker, Takeo Kanade, and anyone else who helped develop these slides. 1 Why estimate motion? We live in a 4-D world Wide applications Object
Lucas-Kanade Motion Estimation Thanks to Steve Seitz, Simon Baker, Takeo Kanade, and anyone else who helped develop these slides. 1 Why estimate motion? We live in a 4-D world Wide applications Object
Part II: Modeling Aspects
 Yosemite test sequence Illumination changes Motion discontinuities Variational Optical Flow Estimation Part II: Modeling Aspects Discontinuity Di ti it preserving i smoothness th tterms Robust data terms
Yosemite test sequence Illumination changes Motion discontinuities Variational Optical Flow Estimation Part II: Modeling Aspects Discontinuity Di ti it preserving i smoothness th tterms Robust data terms
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter