Image convolution with CUDA
|
|
|
- Joella Gordon
- 6 years ago
- Views:
Transcription

1 Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
2 Convolution (definition) A convolution is an integral that expresses the amount of overlap of one function g as it is shifted over another function f: In discrete terms it can be written as: For two dimensions: /46



3 Convolution in image processing tasks Convolution filtering can be used for a wide range of image processing tasks. Many types of blur filters or edge detectors use convolutions. Original image Blur convolution applied to the original image In the context of image processing a convolution filter is just the scalar product of the filter weights with the input pixels within a window surrounding each of the output pixels /46

 and then the results are")
4 A naive convolution algorithm The scalar product is a parallel operation that is well suited to computation on highly parallel hardware such as the GPU. To process and compute an output pixel (red), a region of the input image (orange) is multiplied element-wise with the filter kernel (purple) and then the results are summed /46

5 A naive convolution algorithm (CPU version) #include <cutil.h> #include <cuda_runtime.h> #include <cutil_inline.h> #include <QtGui/QImage> #include <QtGui/QColor> #include <math.h> #define KERNEL_RADIUS 8 #define KERNEL_LENGTH (2 * KERNEL_RADIUS + 1) #define BLOCK_W 16 #define BLOCK_H /46
; QImage img (filename); Original image int width = img.width(); int height = img.")
![height(); // separate color components float *pr = new float [width * height]; float *pg = new float [width * height]; float *pb = new float [width *](/docs-images/76/73989000/images/6-1.jpg "height]; float *pbuffer = new float [width * height]; bzero(pr, width * height * sizeof (float) ); bzero(pg, width * height * sizeof (float) ); bzero(pb,")
6 A naive convolution algorithm (CPU version) int main(int argc, char **argv){ // read an input image QString filename ("./Lena.png"); QImage img (filename); Original image int width = img.width(); int height = img.height(); // separate color components float *pr = new float [width * height]; float *pg = new float [width * height]; float *pb = new float [width * height]; float *pbuffer = new float [width * height]; bzero(pr, width * height * sizeof (float) ); bzero(pg, width * height * sizeof (float) ); bzero(pb, width * height * sizeof (float) ); bzero(pbuffer, width * height * sizeof (float) ); /46
; *(pr + i*width +j) = (float) qred(rgb); *(pg + i*width +j) = (float) qgreen(rgb); *(pb + i*width +j) = (float)")
7 Original image pr pg pb for(int i = 0; i < height; ++i){ for(int j = 0; j < width; ++j){ QRgb rgb = img.pixel(j,i); *(pr + i*width +j) = (float) qred(rgb); *(pg + i*width +j) = (float) qgreen(rgb); *(pb + i*width +j) = (float) qblue(rgb); } } /46
8 Original image After convolution x the distance from the origin in the horizontal axis σ the standard deviation of the Gaussian distribution Values from the distribution are used to build a convolution matrix which is applied to the original image. Each pixel s new value is set to a weighted average of that pixel s neighborhood. The original pixel s value receives the heaviest weight (having the highest Gaussian value) and neighboring pixels receive smaller weights as their distance to the original pixel increases /46
9 Gaussian convolution kernel is a symmetric function, so the row and column filters are identical. Applying a Gaussian blur has the effect of reducing the image s highfrequency components: a Gaussian blur is thus a low pass filter. // convolution kernel float *pkernel = new float [KERNEL_LENGTH]; bzero(pkernel, KERNEL_LENGTH * sizeof (float) ); // kernel initialization float kernelsum = 0; for(int i = 0; i < KERNEL_LENGTH; ++i){ } float dist = (float)(i - KERNEL_RADIUS) / (float) KERNEL_RADIUS; pkernel[i] = expf(- dist * dist / 2); kernelsum += pkernel[i]; for(int i = 0; i < KERNEL_LENGTH; ++i) pkernel [i] /= kernelsum; /46
10 // run very simple convolution on CPU convolutioncpu(pbuffer, pr, pkernel, width, height); memcpy(pr, pbuffer, width*height*sizeof (float) ); convolutioncpu(pbuffer, pg, pkernel, width, height); memcpy(pg, pbuffer, width*height*sizeof (float) ); convolutioncpu(pbuffer, pb, pkernel, width, height); memcpy(pb, pbuffer, width*height*sizeof (float) ); // build an output image to see the final result QImage out_img(width,height,qimage::format_rgb32); for(int i = 0; i < height; ++i){ for(int j = 0; j < width; ++j){ } } QColor clr((int)*(pr + i*width +j), (int)*(pg + i*width +j), (int)*(pb + i*width +j)); out_img.setpixel(j,i,clr.rgb()); // Free the memory /46
11 void convolutioncpu(float *dst, float *src, float *kernel, int width, int height){ for(int y = 0; y < height; y++){ for(int x = 0; x < width; x++){ float sum = 0; float value = 0; for(int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; ++i){ for(int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; ++j){ int c_y = y + i; int c_x = x + j; if (c_x < 0 c_x > (width-1) c_y < 0 (c_y > (height-1))) value = 0; else value = *(src + c_y*width + c_x); } } sum += value * kernel[kernel_radius + i] * kernel[kernel_radius + j]; } *(dst + y*width + x) = sum; } } /46



12 Device memory spaces CUDA devices use several memory spaces, which have different characteristics that reflect their distinct usage in CUDA applications /46



13 A convolution algorithm (the most naive approach) The most naive approach is to use global memory to send data to device and each thread accesses it to compute convolution kernel. There are no idle threads since total number of threads invoked is the same as total number of pixels /46
14 // run very simple convolution on GPU convolutiongpu(pbuffer, pr, pkernel, width, height); memcpy(pr, pbuffer, width*height*sizeof (float) ); convolutiongpu(pbuffer, pg, pkernel, width, height); memcpy(pg, pbuffer, width*height*sizeof (float) ); convolutiongpu(pbuffer, pb, pkernel, width, height); memcpy(pb, pbuffer, width*height*sizeof (float) ); On the GPU now! /46
15 void convolutiongpu(float *h_data_out, float *h_data_in, float *d_kernel, int w, int h){ float *d_buffer_in = 0; float *d_buffer_out = 0; cudamalloc( (void **)&d_buffer_in, w*h*sizeof(float)); cudamalloc( (void **)&d_buffer_out, w*h*sizeof(float)); // copy convolution kernel to the constant GPU memory cudamemcpytosymbol((const char*)d_kerneldev, d_kernel, int gridy = h / BLOCK_H; int gridx = w / BLOCK_W; dim3 blocks(block_w, BLOCK_H); dim3 grids(gridx, gridy); KERNEL_LENGTH*sizeof(float)); cudamemcpy(d_buffer_in, h_data_in, w*h*sizeof(float), cudamemcpyhosttodevice); unsigned int htimer; cutcreatetimer(&htimer); cutresettimer(htimer); cutstarttimer(htimer); /46
16 convolutiongpu_kernel<<<grids, blocks>>>(d_buffer_out, d_buffer_in, w, h); cudathreadsynchronize(); cutstoptimer(htimer); double gputime = cutgettimervalue(htimer); std::cout << "Simple convolution on GPU, time = " << gputime << " ms" << std::endl; cudamemcpy(h_data_out, d_buffer_out, w*h*sizeof(float), cudamemcpydevicetohost); // Cleanup cudafree(d_buffer_in); cudafree(d_buffer_out); global void convolutiongpu_kernel(float *d_result, float *d_data, int dataw, int datah){ // global memory address of the current thread in the whole grid const int gloc = threadidx.x + blockidx.x * blockdim.x + threadidx.y * dataw + blockidx.y * blockdim.y * dataw; /46
17 // global memory address of the current thread in the whole grid const int gloc = threadidx.x + blockidx.x * blockdim.x + threadidx.y * dataw + blockidx.y * blockdim.y * dataw; blockidx.x threadidx.x blockidx.y blockdim.y blockdim.x threadidx.y gloc dataw /46
18 float sum = 0; float value = 0; // image coordinates of the current thread int x = threadidx.x + blockidx.x * blockdim.x; int y = threadidx.y + blockidx.y * blockdim.y; for(int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; ++i){ for(int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; ++j){ int c_y = y + i; int c_x = x + j; // check boundaries if( c_x < 0 c_x > (dataw-1) c_y < 0 c_y > (datah-1) ) value = 0; else value = *(d_data + c_y*dataw + c_x); } } sum += value * d_kerneldev[kernel_radius + i] * d_kerneldev[kernel_radius + j]; d_result[gloc] = sum; /46


19 Shared memory and the apron For any reasonable kernel size, the pixels at the edge of the shared memory array will depend on pixels not in shared memory. Around the image block within a thread block, there is an apron of pixels of the width of the kernel radius that is required in order to filter the image block. Thus, each thread block must load into shared memory the pixels to be filtered and the apron pixels. The apron of one block overlaps with adjacent blocks /46

20 Avoid idle threads Image block 16 x 16 Radius of the kernel = 16 If one thread is used for each pixel loaded into shared memory, then the threads loading the apron pixels will be idle during the filter computation. As the radius of the filter increases, the percentage of idle threads increases This wastes much of the available parallelism, and with the limited amount of shared memory available, the waste for large radius kernels can be quite high. 1 pixel 4 bytes 1 block 9216 bytes This is more than half of the available 16KB shared memory per multiprocessor on the G80 GPU /46


21 Shared memory Shared memory model for naive approach: each thread in block loads 4 values from the global memory. Therefore, total shared memory size is 4 times bigger than active convolution pixels area /46
22 global void convolutiongpu_shmem_kernel(float *d_result, float *d_data, int dataw, int datah){ // shared memory for the thread (active pixels + apron) shared float s_data[block_w + KERNEL_RADIUS * 2][BLOCK_W + KERNEL_RADIUS * 2]; // thread indices; every thread loads four pixels int tx = threadidx.x; int ty = threadidx.y; // global memory address of the current thread in the whole grid const int gloc = tx + blockidx.x * blockdim.x + ty * dataw + blockidx.y * blockdim.y * dataw; // original image coordinates of the current thread int x0 = tx + blockidx.x * blockdim.x; int y0 = ty + blockidx.y * blockdim.y; // upper left int x = x0 - KERNEL_RADIUS; int y = y0 - KERNEL_RADIUS; /46
23 if( x < 0 y < 0) s_data[ty][tx] = 0; else s_data[ty][tx] = *(d_data + gloc - KERNEL_RADIUS dataw * KERNEL_RADIUS); // upper right x = x0 + KERNEL_RADIUS; y = y0 - KERNEL_RADIUS; if( x > (dataw-1) y < 0) s_data[ty][tx + blockdim.x] = 0; else s_data[ty][tx + blockdim.x] = *(d_data + gloc + KERNEL_RADIUS // lower left x = x0 - KERNEL_RADIUS; y = y0 + KERNEL_RADIUS; dataw * KERNEL_RADIUS); if( x < 0 y > (datah-1) ) s_data[ty + blockdim.y][tx] = 0; else s_data[ty + blockdim.y][tx] = *(d_data + gloc - KERNEL_RADIUS + dataw * KERNEL_RADIUS); /46
24 // lower right x = x0 + KERNEL_RADIUS; y = y0 + KERNEL_RADIUS; if( x > (dataw-1) y > (datah-1) ) s_data[ty + blockdim.y][tx + blockdim.x] = 0; else s_data[ty + blockdim.y][tx + blockdim.x] = *(d_data + gloc + KERNEL_RADIUS + syncthreads(); // convolution itself float sum = 0; // index of the current thread in an active pixels area x = KERNEL_RADIUS + tx; y = KERNEL_RADIUS + ty; dataw * KERNEL_RADIUS); for(int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; ++i) for(int j = -KERNEL_RADIUS; j <= KERNEL_RADIUS; ++j) sum += s_data[y + i][x + j] * d_kerneldev[kernel_radius + i] * d_kerneldev[kernel_radius + j]; } d_result[gloc] = sum; /46
25 Separable filters Generally, a two-dimensional convolution filter requires n*m multiplications for each output pixel, where n and m are the width and height of the filter kernel. Separable filters are a special type of filter that can be expressed as the composition of two onedimensional filters, one on the rows on the image, and one on the columns. Applying to the data is the same as applying Separable filter requires only n+m multiplications for each output pixel. Separable filters have the benefit of offering more flexibility in the implementation and in addition reducing the arithmetic complexity and bandwidth usage of the computation for each data point /46


26 Filter separation Basically two separate convolutions are applied. The first one is row-wise and the second one is column-wise from the first result data (apply column convolution over row-wised filtered data). This also reduces some of conditional statements and total number of apron pixels, since vertical apron in row-convolution kernel and horizontal apron in column-convolution kernel do not need to be considered /46
27 global void convolutionrowgpu_kernel(float *d_result, float *d_data, int dataw, int int ty = threadidx.y; int tx = threadidx.x; datah){ // each thread loads two values from global memory into shared mem shared float s_data[block_h][block_w + 2 * KERNEL_RADIUS]; // global memory address of the current thread in the whole grid const int gloc = tx + blockidx.x * blockdim.x + ty * dataw + blockidx.y * blockdim.y * dataw; // original image based coordinate const int x0 = tx + blockidx.x * blockdim.x; // case1: left int x = x0 - KERNEL_RADIUS; if ( x < 0 ) s_data[ty][tx] = 0; else s_data[ty][tx] = d_data[gloc - KERNEL_RADIUS]; /46
28 // case2: right x = x0 + KERNEL_RADIUS; if ( x > dataw-1 ) s_data[ty][tx + blockdim.x] = 0; else s_data[ty][tx + blockdim.x] = d_data[gloc + KERNEL_RADIUS]; syncthreads(); // convolution float sum = 0; x = KERNEL_RADIUS + tx; for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++) sum += s_data[ty][x+i] * d_kerneldev[kernel_radius + i]; d_result[gloc] = sum; } /46
29 global void convolutioncolgpu_kernel(float *d_result, float *d_data, int dataw, int int ty = threadidx.y; int tx = threadidx.x; datah){ // each thread loads two values from global memory into shared mem shared float s_data[block_h + KERNEL_RADIUS * 2][BLOCK_W]; // global memory address of the current thread in the whole grid const int gloc = tx + blockidx.x * blockdim.x + ty * dataw + blockidx.y * blockdim.y * dataw; // original image based coordinate const int y0 = ty + blockidx.y * blockdim.y; // case1: upper int y = y0 - KERNEL_RADIUS; if ( y < 0 ) s_data[ty][tx] = 0; else s_data[ty][tx] = d_data[gloc dataw * KERNEL_RADIUS]; /46
30 // case2: lower y = y0 + KERNEL_RADIUS; if ( y > datah-1 ) s_data[ty + blockdim.y][tx] = 0; else s_data[ty + blockdim.y][tx] = d_data[gloc + dataw * KERNEL_RADIUS]; syncthreads(); // convolution float sum = 0; y = KERNEL_RADIUS + ty; for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++) sum += s_data[y+i][tx] * d_kerneldev[kernel_radius + i]; d_result[gloc] = sum; } /46

31 Shared memory and Bank conflicts Shared memory is divided into equally sized memory modules (banks) that can be accessed simultaneously. Therefore, any memory load or store of n addresses that spans n distinct memory banks can be serviced simultaneously. However, if multiple addresses of a memory request map to the same memory bank, the accesses are serialized. Access to shared memory should be designed to avoid serializing requests due to bank conflicts /46
 - If n threads (out of 16) access the same bank, n accesses are executed serially 09-03-11")
32 Shared memory and Bank conflicts - 16 banks - Successive 32-bit words belong to different banks - Shared memory accesses are per 16-threads (half-warp) - If n threads (out of 16) access the same bank, n accesses are executed serially /46


33 Reorganize shared memory 1D shared memory access pattern for a row filter. The first four iterations of the convolution computation. Red area is indicating values accessed by half warp threads /46
34 global void convolutionrowgpu_optimized_kernel(float *d_result, float *d_data, int int ty = threadidx.y; int tx = threadidx.x; dataw, int datah){ // shared memory represented here by 1D array // each thread loads two values from global memory into shared mem shared float s_data[block_h * (BLOCK_W + 2 * KERNEL_RADIUS)]; // global memory address of the current thread in the whole grid const int gloc = tx + blockidx.x * blockdim.x + ty * dataw + blockidx.y * blockdim.y * dataw; // original image based coordinate const int x0 = tx + blockidx.x * blockdim.x; const int shift = ty * (BLOCK_W + 2 * KERNEL_RADIUS); // case1: left int x = x0 - KERNEL_RADIUS; if ( x < 0 ) s_data[tx + shift] = 0; else s_data[tx + shift] = d_data[gloc - KERNEL_RADIUS]; /46
35 // case2: right x = x0 + KERNEL_RADIUS; if ( x > dataw-1 ) s_data[tx + blockdim.x + shift] = 0; else s_data[tx + blockdim.x + shift] = d_data[gloc + KERNEL_RADIUS]; syncthreads(); // convolution itself float sum = 0; x = KERNEL_RADIUS + tx; for (int i = -KERNEL_RADIUS; i <= KERNEL_RADIUS; i++) sum += s_data[x + i + shift] * d_kerneldev[kernel_radius + i]; } d_result[gloc] = sum; /46
36 global void convolutioncolgpu_optimized_kernel(float *d_result, float *d_data, int int ty = threadidx.y; int tx = threadidx.x; dataw, int datah){ // shared memory represented here by 1D array // each thread loads two values from global memory into shared mem shared float s_data[block_w * (BLOCK_H + KERNEL_RADIUS * 2)]; // global mem address of this thread const int gloc = tx + blockidx.x * blockdim.x + ty * dataw + blockidx.y * blockdim.y * dataw; // original image based coordinate const int y0 = ty + blockidx.y * blockdim.y; const int shift = ty * (BLOCK_W); // case1: upper int y = y0 - KERNEL_RADIUS; if ( y < 0 ) s_data[tx + shift] = 0; else s_data[tx + shift] = d_data[ gloc dataw * KERNEL_RADIUS]; /46
37 // case2: lower y = y0 + KERNEL_RADIUS; const int shift1 = shift + blockdim.y * BLOCK_W; if ( y > datah-1 ) s_data[tx + shift1] = 0; else s_data[tx + shift1] = d_data[gloc + dataw * KERNEL_RADIUS]; syncthreads(); // convolution float sum = 0; for (int i = 0; i <= KERNEL_RADIUS*2; i++) sum += s_data[tx + (ty + i) * BLOCK_W] * d_kerneldev[i]; d_result[gloc] = sum; } /46
38 Runtime and speedups 400 x 400 pixels 2000 x 2000 pixels Naive version (CPU) Naive version (GPU) Shared memory Separable convolution 91 ms 2330 ms 27 ms (3.3) 693 ms (3.3) 26.9 ms (1.003) 663 ms (1.05) 3 ms (8.9) 72 ms (9.2) Optimized separable convolution 1.6 ms 38 ms (1.8) (1.9) /46

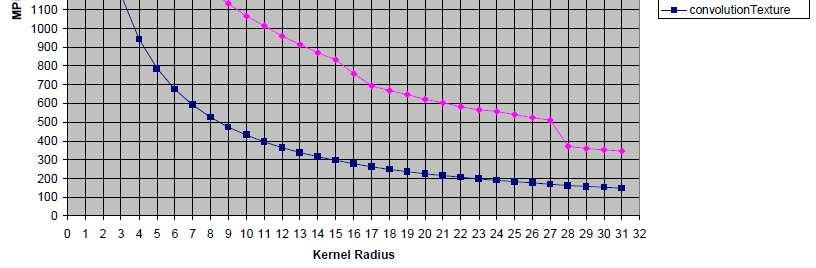
39 Time performance /46

40 Coalesced access to Global memory Global memory access by all threads in the half-warp of a block can be coalesced into efficient memory transactions on a G80 architectures when: - Threads access 32-, 64-, 128-bit data types. - All 16 words of the transaction must lie in the same segment of size equal to the memory transaction size (or twice the memory transaction size when accessing 128-bit words). This implies that the starting address and alignment are important. - Threads must access words in sequence. Coalescing of a half-warp of 32-bit words, such as floats (1.x) /46

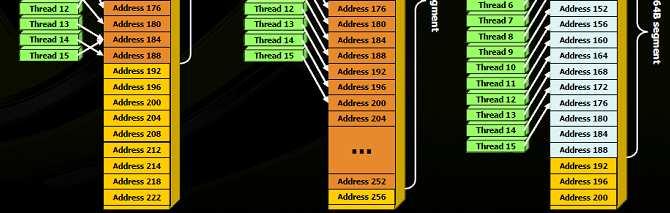
41 /46


42 Coalesced access to Global memory The simplest case of coalescing: the k-th thread accesses the k-th word in a segment. Not all threads need to participate. This access results in a single 64B transaction. Unaligned sequential addresses that fit within a single 128-byte segment /46


43 Coalesced access to Global memory If a half warp accesses memory that is sequential but split across two 128B segments, then two transactions are performed. One 64B transaction and one 32B transaction. A half-warp accessing memory with a stride of /46
44 Unrolling loops By default, the compiler unrolls small loops with a known trip count. The #pragma unroll directive however can be used to control unrolling of any given loop. It must be placed Immediately before the loop and only applies to that loop. It is optionally followed by a number that specifies how many times the loop must be unrolled. # pragma unroll 5 for(int i = 0; i < n; ++i) Fast multiplication mul24(x, y) multiplies two 24-bit integer values x and y. x and y are 32-bit integers but only the low 24 bits are used to perform the multiplication. mul24 should only be used when values in x and y are in the range [-2 23, ], if x and y are signed integers and in the range [0, ], if x and y are unsigned integers. If x and y are not in this range, the multiplication result is implementation-defined. Fast integer functions can be used for optimizing performance of kernels /46
45 Bibliography Wolfram Mathworld, Convolution, WolframMathworld, Normal Distribution, DrDobbs, Victor Podlozhnyuk, Image Convolution with CUDA, NVIDIA CUDA SDK, convolutionseparable document NVIDIA CUDA Programming Guide CUDA C Best Practices Guide /46


46 Thank you for your attention! QUESTIONS? Göttingen,
Example 1: Color-to-Grayscale Image Processing
 GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
GPU Teaching Kit Accelerated Computing Lecture 16: CUDA Parallelism Model Examples Example 1: Color-to-Grayscale Image Processing RGB Color Image Representation Each pixel in an image is an RGB value The
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Information Coding / Computer Graphics, ISY, LiTH. CUDA memory! ! Coalescing!! Constant memory!! Texture memory!! Pinned memory 26(86)
") 26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Module Memory and Data Locality
 GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
GPU Teaching Kit Accelerated Computing Module 4.4 - Memory and Data Locality Tiled Matrix Multiplication Kernel Objective To learn to write a tiled matrix-multiplication kernel Loading and using tiles
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Hardware/Software Co-Design
 1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
Shared Memory. Table of Contents. Shared Memory Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Shared Memory.
 Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
GPU programming basics. Prof. Marco Bertini
 GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
GPU programming basics Prof. Marco Bertini CUDA: atomic operations, privatization, algorithms Atomic operations The basics atomic operation in hardware is something like a read-modify-write operation performed
CUDA Memory Model. Monday, 21 February Some material David Kirk, NVIDIA and Wen-mei W. Hwu, (used with permission)
") CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
CME 213 S PRING 2017 Eric Darve Review Secret behind GPU performance: simple cores but a large number of them; even more threads can exist live on the hardware (10k 20k threads live). Important performance
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPU Computing. Design and Analysis of Parallel Algorithms
 Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Introduction to GPU Computing Design and Analysis of Parallel Algorithms Sources CUDA Programming Guide (3.2) CUDA Best Practices Guide (3.2) CUDA Toolkit Reference Manual (3.2) CUDA SDK Examples Part
Real-time Graphics 9. GPGPU
 Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
Real-time Graphics 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
For personnal use only
 Inverting Large Images Using CUDA Finnbarr P. Murphy (fpm@fpmurphy.com) This is a simple example of how to invert a very large image, stored as a vector using nvidia s CUDA programming environment and
Inverting Large Images Using CUDA Finnbarr P. Murphy (fpm@fpmurphy.com) This is a simple example of how to invert a very large image, stored as a vector using nvidia s CUDA programming environment and
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
2/17/10. Administrative. L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies. Administrative, cont.
 Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Real-time Graphics 9. GPGPU
 9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
9. GPGPU GPGPU GPU (Graphics Processing Unit) Flexible and powerful processor Programmability, precision, power Parallel processing CPU Increasing number of cores Parallel processing GPGPU general-purpose
Advanced CUDA Optimizations
 Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
Advanced CUDA Optimizations General Audience Assumptions General working knowledge of CUDA Want kernels to perform better Profiling Before optimizing, make sure you are spending effort in correct location
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
Lecture 7. Using Shared Memory Performance programming and the memory hierarchy
 Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Histogram calculation in CUDA. Victor Podlozhnyuk
 Histogram calculation in CUDA Victor Podlozhnyuk vpodlozhnyuk@nvidia.com Document Change History Version Date Responsible Reason for Change 1.0 06/15/2007 vpodlozhnyuk First draft of histogram256 whitepaper
Histogram calculation in CUDA Victor Podlozhnyuk vpodlozhnyuk@nvidia.com Document Change History Version Date Responsible Reason for Change 1.0 06/15/2007 vpodlozhnyuk First draft of histogram256 whitepaper
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Class. Windows and CUDA : Shu Guo. Program from last time: Constant memory
 Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
Lab 1 Part 1: Introduction to CUDA
 Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Compiling and Executing CUDA Programs in Emulation Mode. High Performance Scientific Computing II ICSI-541 Spring 2010
 Compiling and Executing CUDA Programs in Emulation Mode High Performance Scientific Computing II ICSI-541 Spring 2010 Topic Overview Overview of compiling and executing CUDA programs in emulation mode
Compiling and Executing CUDA Programs in Emulation Mode High Performance Scientific Computing II ICSI-541 Spring 2010 Topic Overview Overview of compiling and executing CUDA programs in emulation mode
Optimizing Parallel Reduction in CUDA
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf Parallel Reduction Tree-based approach used within each
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Code Optimizations for High Performance GPU Computing
 Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Fast Bilateral Filter GPU implementation
 Fast Bilateral Filter GPU implementation Multi-Core Architectures and Programming Gerhard Mlady, Rafael Bernardelli Hardware/Software Co-Design, University of Erlangen-Nuremberg July 21, 2016 Overview
Fast Bilateral Filter GPU implementation Multi-Core Architectures and Programming Gerhard Mlady, Rafael Bernardelli Hardware/Software Co-Design, University of Erlangen-Nuremberg July 21, 2016 Overview
CUDA Performance Optimization Mark Harris NVIDIA Corporation
 CUDA Performance Optimization Mark Harris NVIDIA Corporation Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary Optimize Algorithms for
CUDA Performance Optimization Mark Harris NVIDIA Corporation Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary Optimize Algorithms for
Lecture 6. Programming with Message Passing Message Passing Interface (MPI)
") Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Global Memory Access Pattern and Control Flow
 Optimization Strategies Global Memory Access Pattern and Control Flow Objectives Optimization Strategies Global Memory Access Pattern (Coalescing) Control Flow (Divergent branch) Global l Memory Access
Optimization Strategies Global Memory Access Pattern and Control Flow Objectives Optimization Strategies Global Memory Access Pattern (Coalescing) Control Flow (Divergent branch) Global l Memory Access
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
$ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x. Enter in the application folder Compile the source code Launch the application
 $ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x Enter in the application folder Compile the source code Launch the application --- General Information for device 0 --- Name: xxxx Compute capability:
$ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x Enter in the application folder Compile the source code Launch the application --- General Information for device 0 --- Name: xxxx Compute capability:
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Module 3: CUDA Execution Model -I. Objective
 ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Optimization Strategies Global Memory Access Pattern and Control Flow
 Global Memory Access Pattern and Control Flow Optimization Strategies Global Memory Access Pattern (Coalescing) Control Flow (Divergent branch) Highest latency instructions: 400-600 clock cycles Likely
Global Memory Access Pattern and Control Flow Optimization Strategies Global Memory Access Pattern (Coalescing) Control Flow (Divergent branch) Highest latency instructions: 400-600 clock cycles Likely
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPU Programming. Parallel Patterns. Miaoqing Huang University of Arkansas 1 / 102
 1 / 102 GPU Programming Parallel Patterns Miaoqing Huang University of Arkansas 2 / 102 Outline Introduction Reduction All-Prefix-Sums Applications Avoiding Bank Conflicts Segmented Scan Sorting 3 / 102
1 / 102 GPU Programming Parallel Patterns Miaoqing Huang University of Arkansas 2 / 102 Outline Introduction Reduction All-Prefix-Sums Applications Avoiding Bank Conflicts Segmented Scan Sorting 3 / 102
GPU Performance Nuggets
 GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
GPU Performance Nuggets Simon Garcia de Gonzalo & Carl Pearson PhD Students, IMPACT Research Group Advised by Professor Wen-mei Hwu Jun. 15, 2016 grcdgnz2@illinois.edu pearson@illinois.edu GPU Performance
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Implementation of Adaptive Coarsening Algorithm on GPU using CUDA
 Implementation of Adaptive Coarsening Algorithm on GPU using CUDA 1. Introduction , In scientific computing today, the high-performance computers grow
Implementation of Adaptive Coarsening Algorithm on GPU using CUDA 1. Introduction , In scientific computing today, the high-performance computers grow
GPU Computing with CUDA
 GPU Computing with CUDA Hands-on: Shared Memory Use (Dot Product, Matrix Multiplication) Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical
GPU Computing with CUDA Hands-on: Shared Memory Use (Dot Product, Matrix Multiplication) Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical
CSE 599 I Accelerated Computing - Programming GPUS. Memory performance
 CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Tiled Matrix Multiplication
 Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
Tiled Matrix Multiplication Basic Matrix Multiplication Kernel global void MatrixMulKernel(int m, m, int n, n, int k, k, float* A, A, float* B, B, float* C) C) { int Row = blockidx.y*blockdim.y+threadidx.y;
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
More CUDA. Advanced programming
 More CUDA 1 Advanced programming Synchronization and atomics Warps and Occupancy Memory coalescing Shared Memory Streams and Asynchronous Execution Bank conflicts Other features 2 Synchronization and Atomics
More CUDA 1 Advanced programming Synchronization and atomics Warps and Occupancy Memory coalescing Shared Memory Streams and Asynchronous Execution Bank conflicts Other features 2 Synchronization and Atomics
GPU Computing with CUDA
 GPU Computing with CUDA Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison Dan Negrut, 2012 UW-Madison Milano
GPU Computing with CUDA Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison Dan Negrut, 2012 UW-Madison Milano
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int