$ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x. Enter in the application folder Compile the source code Launch the application
|
|
|
- Jody Waters
- 6 years ago
- Views:
Transcription


1
2
3
4 $ cd ex $ cd 1.Enumerate_GPUs $ make $./enum_gpu.x Enter in the application folder Compile the source code Launch the application
5 --- General Information for device Name: xxxx Compute capability: xxxx Clock rate: xxxx Device copy overlap: xxxx Kernel execution timeout : xxxx --- Memory Information for device Total global mem: xxxx Total constant Mem: xxxx Max mem pitch: xxxx Texture Alignment: xxxx --- MP Information for device Multiprocessor count: xxxx Shared mem per mp: xxxx Registers per mp: xxxx Threads in warp: xxxx Max threads per block: xxxx Max thread dimensions: (xxxx, xxxx, xxxx) Max grid dimensions: (xxxx, xxxx, xxxx)
6
7
8 $ cd.. $ cd 2.Hello_World $ make
9 int main(void) { printf("hello World!\n"); return 0; } $./hello_world.x
10 global void kernel(void) { } $./simple_kernel.x int main(void) { kernel<<<1,1>>>(); printf("hello World!\n"); return 0; }




11
12 global void add(int *a, int *b, int *c) { *c = *a + *b; }
13
14 int main(void) { int a, b, c; int *d_a, *d_b, *d_c; int size = sizeof(int); // host copies of a, b, c // device copies of a, b, c // Allocate space for device copies of a, b, c cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Setup input values a = 2; b = 7;
15 // Copy inputs to device cudamemcpy(d_a, &a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, &b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU add<<<1,1>>>(d_a, d_b, d_c); // Copy result back to host cudamemcpy(&c, d_c, size, cudamemcpydevicetohost); } // Cleanup cudafree(d_a); cudafree(d_b); cudafree(d_c); return 0;
16 add<<< 1, 1 >>>(); add<<< N, 1 >>>();
17 global void add(int *a, int *b, int *c) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; }

18 global void add(int *a, int *b, int *c) { c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; }
19 #define N 512 int main(void) { int *a, *b, *c; int *dev_a, *dev_b, *dev_c; int size = N * sizeof(int);. // host copies of a, b, c // device copies of a, b, c // Alloc space for device copies of a, b, c cudamalloc((void **)&dev_a, size); cudamalloc((void **)&dev_b, size); cudamalloc((void **)&dev_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
20 // Copy inputs to device cudamemcpy(dev_a, a, size, cudamemcpyhosttodevice); cudamemcpy(dev_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU with N blocks add<<<n,1>>>(dev_a, dev_b, dev_c); // Copy result back to host cudamemcpy(c, dev_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(dev_a); cudafree(dev_b); cudafree(dev_c); return 0;
21
22 global void add(int *a, int *b, int *c) { c[threadidx.x] = a[threadidx.x] + b[threadidx.x]; }
23 #define N 512 int main(void) { int *a, *b, *c; int *dev_a, *dev_b, *dev_c; int size = N * sizeof(int); // host copies of a, b, c // device copies of a, b, c // Alloc space for device copies of a, b, c cudamalloc((void **)&dev_a, size); cudamalloc((void **)&dev_b, size); cudamalloc((void **)&dev_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
24 // Copy inputs to device cudamemcpy(dev_a, a, size, cudamemcpyhosttodevice); cudamemcpy(dev_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU with N threads add<<<1,n>>>(dev_a, dev_b, dev_c); // Copy result back to host cudamemcpy(c, dev_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(dev_a); cudafree(dev_b); cudafree(dev_c); return 0;
25







26 int index = threadidx.x + blockidx.x * M;

27 int index = threadidx.x + blockidx.x * M; = * 8; = 21;
28 int index = threadidx.x + blockidx.x * blockdim.x; global void add(int *a, int *b, int *c) { int index = threadidx.x + blockidx.x * blockdim.x; c[index] = a[index] + b[index]; }
29 #define N 512 int main(void) { int *a, *b, *c; int *dev_a, *dev_b, *dev_c; int size = N * sizeof(int); // host copies of a, b, c // device copies of a, b, c // Alloc space for device copies of a, b, c cudamalloc((void **)&dev_a, size); cudamalloc((void **)&dev_b, size); cudamalloc((void **)&dev_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
30 // Copy inputs to device cudamemcpy(dev_a, a, size, cudamemcpyhosttodevice); cudamemcpy(dev_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU add<<<n/threads_per_block,threads_per_block>>>(dev_a, dev_b, dev_c); // Copy result back to host cudamemcpy(c, dev_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(dev_a); cudafree(dev_b); cudafree(dev_c); return 0;
31 global void add(int *a, int *b, int *c, int n) { int index = threadidx.x + blockidx.x * blockdim.x; if (index < n) c[index] = a[index] + b[index]; } add<<<(n + M-1) / M,M>>>(d_a, d_b, d_c, N);
32
33 radius radius
34
35 shared
36 halo on left halo on right blockdim.x output elements
37 Question? global void stencil_1d(int *in, int *out) { shared int temp[/* WHAT SIZE? */]; int gindex = threadidx.x + blockidx.x * blockdim.x; int lindex = threadidx.x + RADIUS; Find the right vector size and complete the code // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { temp[lindex - RADIUS] = in[gindex - RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; }
38 // Apply the stencil int result = 0; for (int offset = -RADIUS ; offset <= RADIUS ; offset++) result += temp[lindex + offset]; } // Store the result out[gindex-radius] = result;
39 The stencil example will not work Suppose thread 15 reads the halo before thread 0 has fetched it temp[lindex] = in[gindex]; Store at temp[18] if (threadidx.x < RADIUS) { temp[lindex RADIUS = in[gindex RADIUS]; Skipped, threadidx > RADIUS temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; } int result = 0; result += temp[lindex + 1]; Load from temp[19]
40 void syncthreads(); syncthreads()


41 global void matmatmulgpu( double *a, double *b, double *c, int lda ){ unsigned int tid = blockidx.x*blockdim.x + threadidx.x; // assign one thread per output - row major over whole matrix int row = /* WHAT INDEX? */ ; int col = /* WHAT INDEX? */ ; double sum = 0.0; } for ( int k=0; k<lda; k++ ) { sum += a[row*lda+k] * b[k*lda+col]; } c[tid] = sum; return;
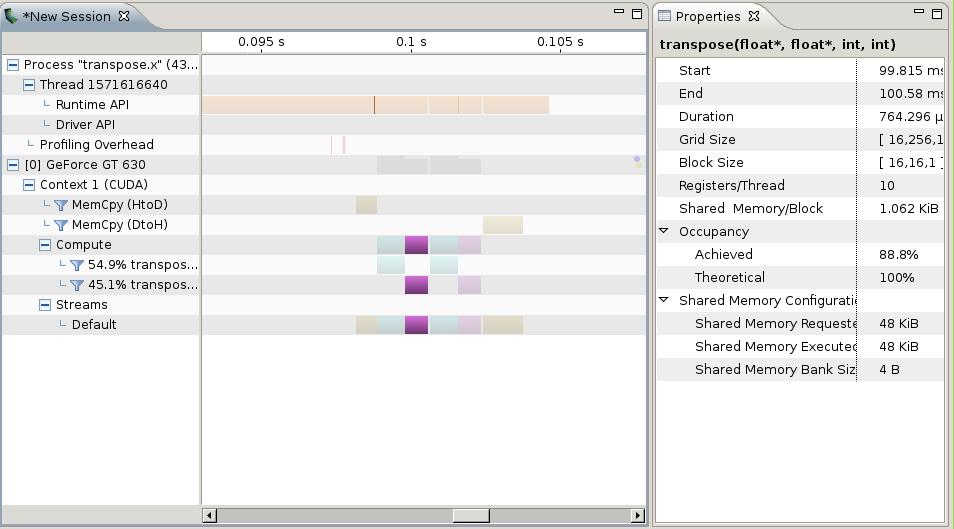
42 // This kernel is optimized to ensure all global reads and writes are coalesced, // and to avoid bank conflicts in shared memory. This kernel is up to 11x faster // than the naive kernel below. Note that the shared memory array is sized to // (BLOCK_DIM+1)*BLOCK_DIM. This pads each row of the 2D block in shared memory // so that bank conflicts do not occur when threads address the array column-wise. global void transpose(float *odata, float *idata, int width, int height){ shared float block[block_dim][block_dim+1]; } // read the matrix tile into shared memory // load one element per thread from device memory (idata) and store it // in transposed order in block[][] unsigned int xindex = /* COMPLETE */ ; unsigned int yindex = /* COMPLETE */ ; if((xindex < width) && (yindex < height)) { unsigned int index_in = /* COMPLETE */; block[threadidx.y][threadidx.x] = /* COMPLETE */; } // synchronise to ensure all writes to block[][] have completed /* COMPLETE */ ; // write the transposed matrix tile to global memory (odata) in linear order xindex = /* COMPLETE */ ; yindex = /* COMPLETE */ ; if((xindex < height) && (yindex < width)) { unsigned int index_out = /* COMPLETE */ ; odata[index_out] = /* COMPLETE */ ;}




43
CUDA Exercises. CUDA Programming Model Lukas Cavigelli ETZ E 9 / ETZ D Integrated Systems Laboratory
 CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
CUDA Exercises CUDA Programming Model 05.05.2015 Lukas Cavigelli ETZ E 9 / ETZ D 61.1 Integrated Systems Laboratory Exercises 1. Enumerate GPUs 2. Hello World CUDA kernel 3. Vectors Addition Threads and
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation
 CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
CUDA C/C++ Basics GTC 2012 Justin Luitjens, NVIDIA Corporation What is CUDA? CUDA Platform Expose GPU computing for general purpose Retain performance CUDA C/C++ Based on industry-standard C/C++ Small
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
Lecture 6b Introduction of CUDA programming
 CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
CS075 1896 1920 1987 2006 Lecture 6b Introduction of CUDA programming 0 1 0, What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU Programming Introduction
 GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
CUDA Programming. Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna.
 Università di Bologna.") Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Copyright 2014, 2017, 2018 Moreno Marzolla, Università di Bologna, Italy http://www.moreno.marzolla.name/teaching/hpc/
Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Copyright 2014, 2017, 2018 Moreno Marzolla, Università di Bologna, Italy http://www.moreno.marzolla.name/teaching/hpc/
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
CUDA. More on threads, shared memory, synchronization. cuprintf
 CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CUDA More on threads, shared memory, synchronization cuprintf Library function for CUDA Developers Copy the files from /opt/cuprintf into your source code folder #include cuprintf.cu global void testkernel(int
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
Information Coding / Computer Graphics, ISY, LiTH. CUDA memory! ! Coalescing!! Constant memory!! Texture memory!! Pinned memory 26(86)
") 26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
26(86) Information Coding / Computer Graphics, ISY, LiTH CUDA memory Coalescing Constant memory Texture memory Pinned memory 26(86) CUDA memory We already know... Global memory is slow. Shared memory is
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 29 GPU Programming II Rutgers University Review: Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing
Introduction to CUDA C QCon 2011 Cyril Zeller, NVIDIA Corporation
 Introduction to CUDA C QCon 2011 Cyril Zeller, NVIDIA Corporation Welcome Goal: an introduction to GPU programming CUDA = NVIDIA s architecture for GPU computing What will you learn in this session? Start
Introduction to CUDA C QCon 2011 Cyril Zeller, NVIDIA Corporation Welcome Goal: an introduction to GPU programming CUDA = NVIDIA s architecture for GPU computing What will you learn in this session? Start
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Introduction to CUDA C
 Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to CUDA C
 NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
COSC 462. CUDA Basics: Blocks, Grids, and Threads. Piotr Luszczek. November 1, /10
 COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
COSC 462 CUDA Basics: Blocks, Grids, and Threads Piotr Luszczek November 1, 2017 1/10 Minimal CUDA Code Example global void sum(double x, double y, double *z) { *z = x + y; } int main(void) { double *device_z,
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
An Introduction to GPU Programming
 An Introduction to GPU Programming Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org Louisiana State University Baton Rouge October 22, 2014 GPU Computing History The first GPU (Graphics Processing
An Introduction to GPU Programming Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org Louisiana State University Baton Rouge October 22, 2014 GPU Computing History The first GPU (Graphics Processing
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs)
") MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs) CUDA API Klaus Mueller, Ziyi Zheng, Eric Papenhausen Stony Brook University Function Qualifiers Device Global,
MIC-GPU: High-Performance Computing for Medical Imaging on Programmable Graphics Hardware (GPUs) CUDA API Klaus Mueller, Ziyi Zheng, Eric Papenhausen Stony Brook University Function Qualifiers Device Global,
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
2/17/10. Administrative. L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies. Administrative, cont.
 Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
CUDA Performance Optimization Mark Harris NVIDIA Corporation
 CUDA Performance Optimization Mark Harris NVIDIA Corporation Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary Optimize Algorithms for
CUDA Performance Optimization Mark Harris NVIDIA Corporation Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary Optimize Algorithms for
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Linear Algebra on the GPU. Pawel Pomorski, HPC Software Analyst SHARCNET, University of Waterloo
 Linear Algebra on the GPU, HPC Software Analyst SHARCNET, University of Waterloo Overview Brief introduction to GPUs CUBLAS and MAGMA libraries Developing efficient linear algebra code for the GPU - case
Linear Algebra on the GPU, HPC Software Analyst SHARCNET, University of Waterloo Overview Brief introduction to GPUs CUBLAS and MAGMA libraries Developing efficient linear algebra code for the GPU - case
Assignment 7. CUDA Programming Assignment
 Assignment 7 CUDA Programming Assignment B. Wilkinson, April 17a, 2016 The purpose of this assignment is to become familiar with writing, compiling, and executing CUDA programs. We will use cci-grid08,
Assignment 7 CUDA Programming Assignment B. Wilkinson, April 17a, 2016 The purpose of this assignment is to become familiar with writing, compiling, and executing CUDA programs. We will use cci-grid08,
GPU programming: CUDA. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
Basic unified GPU architecture
 Basic unified GPU architecture SM=streaming multiprocessor TPC = Texture Processing Cluster SFU = special function unit ROP = raster operations pipeline 78 Note: The following slides are extracted from
Basic unified GPU architecture SM=streaming multiprocessor TPC = Texture Processing Cluster SFU = special function unit ROP = raster operations pipeline 78 Note: The following slides are extracted from
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
GPU applications within HEP
 GPU applications within HEP Liang Sun Wuhan University 2018-07-20 The 5th International Summer School on TeV Experimental Physics (istep), Wuhan Outline Basic concepts GPU, CUDA, Thrust GooFit introduction
GPU applications within HEP Liang Sun Wuhan University 2018-07-20 The 5th International Summer School on TeV Experimental Physics (istep), Wuhan Outline Basic concepts GPU, CUDA, Thrust GooFit introduction
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
COSC 462 Parallel Programming
 November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo
 Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo 31 August, 2015 Goals Running CUDA code on CPUs. Why? Performance portability! A major challenge faced
Automatic translation from CUDA to C++ Luca Atzori, Vincenzo Innocente, Felice Pantaleo, Danilo Piparo 31 August, 2015 Goals Running CUDA code on CPUs. Why? Performance portability! A major challenge faced
CS671 Parallel Programming in the Many-Core Era
 CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
CS671 Parallel Programming in the Many-Core Era Lecture 3: GPU Programming - Reduce, Scan & Sort Zheng Zhang Rutgers University Review: Programming with CUDA An Example in C Add vector A and vector B to
Programming GPUs with CUDA. Prerequisites for this tutorial. Commercial models available for Kepler: GeForce vs. Tesla. I.
 Programming GPUs with CUDA Tutorial at 1th IEEE CSE 15 and 13th IEEE EUC 15 conferences Prerequisites for this tutorial Porto (Portugal). October, 20th, 2015 You (probably) need experience with C. You
Programming GPUs with CUDA Tutorial at 1th IEEE CSE 15 and 13th IEEE EUC 15 conferences Prerequisites for this tutorial Porto (Portugal). October, 20th, 2015 You (probably) need experience with C. You
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
PPAR: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique PPAR
 PPAR: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 This lecture: CUDA programming We have seen some GPU architecture
PPAR: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr http://www.irisa.fr/alf/collange/ PPAR - 2018 This lecture: CUDA programming We have seen some GPU architecture
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
Plan. CS : High-Performance Computing with CUDA. Matrix Transpose Characteristics (1/2) Plan
 Plan") Plan CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 1 2 Performance Optimization 3 4 Parallel Scan 5 Exercises
Plan CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 1 2 Performance Optimization 3 4 Parallel Scan 5 Exercises
Linear Algebra on the GPU. Pawel Pomorski, HPC Software Analyst SHARCNET, University of Waterloo
 Linear Algebra on the GPU, HPC Software Analyst SHARCNET, University of Waterloo Overview Brief introduction to GPUs CUBLAS, CULA and MAGMA libraries Developing efficient linear algebra code for the GPU
Linear Algebra on the GPU, HPC Software Analyst SHARCNET, University of Waterloo Overview Brief introduction to GPUs CUBLAS, CULA and MAGMA libraries Developing efficient linear algebra code for the GPU
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
CS377P Programming for Performance GPU Programming - I
 CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS377P Programming for Performance GPU Programming - I Sreepathi Pai UTCS November 9, 2015 Outline 1 Introduction to CUDA 2 Basic Performance 3 Memory Performance Outline 1 Introduction to CUDA 2 Basic
CS : High-Performance Computing with CUDA
 CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 CS4402-9535: High-Performance Computing with CUDA UWO-CS4402-CS9535
CS4402-9535: High-Performance Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 CS4402-9535: High-Performance Computing with CUDA UWO-CS4402-CS9535
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
Programming with CUDA and OpenCL. Dana Schaa and Byunghyun Jang Northeastern University
 Programming with CUDA and OpenCL Dana Schaa and Byunghyun Jang Northeastern University Tutorial Overview CUDA - Architecture and programming model - Strengths and limitations of the GPU - Example applications
Programming with CUDA and OpenCL Dana Schaa and Byunghyun Jang Northeastern University Tutorial Overview CUDA - Architecture and programming model - Strengths and limitations of the GPU - Example applications
GPU Programming with CUDA. Pedro Velho
 GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
Hardware/Software Co-Design
 1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
1 / 13 Hardware/Software Co-Design Review so far Miaoqing Huang University of Arkansas Fall 2011 2 / 13 Problem I A student mentioned that he was able to multiply two 1,024 1,024 matrices using a tiled
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary
 Optimizing CUDA Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary NVIDIA Corporation 2009 2 Optimize Algorithms for the GPU Maximize
Optimizing CUDA Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary NVIDIA Corporation 2009 2 Optimize Algorithms for the GPU Maximize
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science 2018 Workshop
 Jongsoo Kim Korea Astronomy and Space Science 2018 Workshop") Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science Institute @COMAC 2018 Workshop www.top500.org Summit #1, Linpack: 122.3 Pflos/s 4356
Introduction to CUDA Programming (Compute Unified Device Architecture) Jongsoo Kim Korea Astronomy and Space Science Institute @COMAC 2018 Workshop www.top500.org Summit #1, Linpack: 122.3 Pflos/s 4356
GPU Computing with CUDA
 GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication
 Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication") Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Shared Memory. Table of Contents. Shared Memory Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Shared Memory.
 Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Zero-copy. Table of Contents. Multi-GPU Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Zero-copy. Multigpu.
 Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
Table of Contents Multi-GPU Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes 2 Zero-copy Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Basics of CADA Programming - CUDA 4.0 and newer
 Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Image convolution with CUDA
 Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
Image convolution with CUDA Lecture Alexey Abramov abramov _at_ physik3.gwdg.de Georg-August University, Bernstein Center for Computational Neuroscience, III Physikalisches Institut, Göttingen, Germany
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
Introduc)on to CUDA. T.V. Singh Ins)tute for Digital Research and Educa)on UCLA
on to CUDA. T.V. Singh Ins)tute for Digital Research and Educa)on UCLA") Introduc)on to CUDA T.V. Singh Ins)tute for Digital Research and Educa)on UCLA tvsingh@ucla.edu GPU and GPGPU Graphics Processing Unit A specialized device on computer to accelerate building of images
Introduc)on to CUDA T.V. Singh Ins)tute for Digital Research and Educa)on UCLA tvsingh@ucla.edu GPU and GPGPU Graphics Processing Unit A specialized device on computer to accelerate building of images
CSE 599 I Accelerated Computing Programming GPUS. Intro to CUDA C
 CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
04. CUDA Data Transfer
 04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
Hands-on CUDA. Prof. Esteban Walter Gonzalez Clua, Dr. Cuda Fellow Computer Science Department Universidade Federal Fluminense Brazil
 Hands-on CUDA Prof. Esteban Walter Gonzalez Clua, Dr. Cuda Fellow Computer Science Department Universidade Federal Fluminense Brazil Universidade Federal Fluminense Rio de Janeiro - Brasil Porque CUDA?
Hands-on CUDA Prof. Esteban Walter Gonzalez Clua, Dr. Cuda Fellow Computer Science Department Universidade Federal Fluminense Brazil Universidade Federal Fluminense Rio de Janeiro - Brasil Porque CUDA?
Class. Windows and CUDA : Shu Guo. Program from last time: Constant memory
 Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
Class Windows and CUDA : Shu Guo Program from last time: Constant memory Windows on CUDA Reference: NVIDIA CUDA Getting Started Guide for Microsoft Windows Whiting School has Visual Studio Cuda 5.5 Installer
Optimizing CUDA NVIDIA Corporation 2009 U. Melbourne GPU Computing Workshop 27/5/2009 1
 Optimizing CUDA 1 Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary 2 Optimize Algorithms for the GPU Maximize independent parallelism
Optimizing CUDA 1 Outline Overview Hardware Memory Optimizations Execution Configuration Optimizations Instruction Optimizations Summary 2 Optimize Algorithms for the GPU Maximize independent parallelism
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Supercomputing on your desktop:
 IAP09 CUDA@MIT / 6.963 Supercomputing on your desktop: Programming the next generation of cheap and massively parallel hardware using CUDA Lecture 07 Nicolas Pinto (MIT) CUDA - Advanced #2 During this
IAP09 CUDA@MIT / 6.963 Supercomputing on your desktop: Programming the next generation of cheap and massively parallel hardware using CUDA Lecture 07 Nicolas Pinto (MIT) CUDA - Advanced #2 During this
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed