Wrong Path Events and Their Application to Early Misprediction Detection and Recovery
|
|
|
- Shanna Franklin
- 5 years ago
- Views:
Transcription
1 Wrong Path Events and Their Application to Early Misprediction Detection and Recovery David N. Armstrong Hyesoon Kim Onur Mutlu Yale N. Patt University of Texas at Austin
2 Motivation Branch predictors are not perfect. Branch misprediction penalty causes significant performance degradation. We would like to reduce the misprediction penalty by detecting the misprediction and initiating recovery before the mispredicted branch is resolved.

3 Branch Misprediction Resolution Latency

4 Performance Potential of Early Misprediction Recovery
5 An Observation and A Question In an out-of-order processor, some instructions are executed on the mispredicted path (wrong-path instructions). Is the behavior of wrong-path instructions different from the behavior of correct-path instructions? If so, we can use the difference in behavior for early misprediction detection and recovery.
6 Talk Outline Concept of Wrong Path Events Types of Wrong Path Events Experimental Evaluation Realistic Early Misprediction Recovery Shortcomings and Future Research Conclusions
7 What is a Wrong Path Event? An instance of illegal or unusual behavior that is more likely to occur on the wrong path than on the correct path. Wrong Path Event = WPE Probability (wrong path WPE) ~ 1
8 Why Does a WPE Occur? A wrong-path instruction may be executed before the mispredicted branch is executed. Because the mispredicted branch may be dependent on a long-latency instruction. The wrong-path instruction may consume a data value that is not properly initialized.
9 WPE Example from eon: NULL pointer dereference!"# $%%&&& '( )(
10 Beginning of the loop Array boundary i = 0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
11 First iteration Array boundary i = 0 ptr = x8abcd0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
12 First iteration Array boundary i = 0 ptr = x8abcd0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0 * ptr!"# $%%&&& '( )(
13 Loop branch correctly predicted Array boundary i = 1 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
14 Second iteration Array boundary i = 1 ptr = xeff8b0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
15 Second iteration Array boundary i = 1 ptr = xeff8b0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0 * ptr!"# $%%&&& '( )(
16 Loop exit branch mispredicted Array boundary i = 2 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
17 Third iteration on wrong path Array boundary i = 2 ptr = 0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0!"# $%%&&& '( )(
18 Wrong Path Event Array boundary i = 2 ptr = 0 Array of pointers to structs x8abcd0 xeff8b0 x0 x0 * ptr!"# $%%&&& '( )( NULL pointer dereference!
19 Types of WPEs Due to memory instructions NULL pointer dereference Write to read-only page Unaligned access (illegal in the Alpha ISA) Access to an address out of segment range Data access to code segment Multiple concurrent TLB misses
20 Types of WPEs (continued) Due to control-flow instructions Misprediction under misprediction If three branches are executed and resolved as mispredicts while there are older unresolved branches in the processor, it is almost certain that one of the older unresolved branches is mispredicted. Return address stack underflow Unaligned instruction fetch address (illegal in Alpha) Due to arithmetic instructions Some arithmetic exceptions e.g. Divide by zero
21 Experimental Evaluation
22 Two Empirical Questions 1. How often do WPEs occur? 2. When do WPEs occur on the wrong path?
23 Simulation Methodology Execution-driven Alpha ISA simulator Faithful modeling of wrong-path execution and wrong-path misprediction recoveries 8-wide out-of-order processor 256-entry instruction window Large and accurate branch predictors 64K-entry gshare and 64K-entry PAs hybrid 64K-entry target cache for indirect branches 64-entry return address stack Minimum 30-cycle branch misprediction penalty Minimum 500-cycle memory latency, 1 MB L2 cache SPEC 2000 integer benchmarks

24 Mispredictions Resulting in WPEs
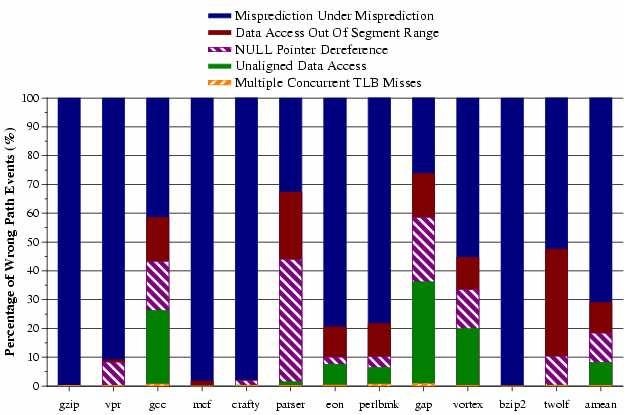
25 Distribution of WPEs

26 When do WPEs Occur?
27 Early Misprediction Recovery Using WPEs
28 Early Misprediction Recovery Once a WPE is detected, there may be: no older unresolved branch in the window Do nothing (false alarm) one older unresolved branch in the window The processor initiates early recovery for that branch, guessing that it is mispredicted. multiple older unresolved branches in the window May be different instances of the same static branch. To initiate early misprediction recovery, we need a mechanism that decides which branch is the oldest mispredicted branch in the window.
29 A Realistic Recovery Mechanism The distance in the instruction window between the WPE-generating instruction and the oldest mispredicted branch is predictable. The first time a WPE is encountered, the processor records the distance between the WPE-generating instruction and the mispredicted branch. The next time the same instruction generates a WPE, the processor predicts that the branch that has the same distance to the WPE-generating instruction is mispredicted.
30 Ld C Generates a WPE Instr. SeqNo PC Br A1 10 PC A Br A2 20 PC A Ld C 40 PC C NULL pointer dereference
31 WPE is Recorded Instr. SeqNo PC Br A1 10 PC A Br A2 20 PC A WPE Record SeqNo PC Ld C 40 PC C 40 PC C
32 Br A1 Resolves as a Mispredict Instr. SeqNo PC Br A1 10 PC A Misprediction Br A2 20 PC A WPE Record SeqNo PC Ld C 40 PC C 40 PC C
33 Distance is Recorded in a Table Valid Distance PC C XOR 1 30 Global History
34 Ld C Again Generates a WPE Instr. SeqNo PC Br A1 25 PC A Br A2 35 PC A Ld C 55 PC C NULL pointer dereference
35 Distance Table is Accessed Valid Distance PC C Global History XOR 1 30
36 Br A1 is Predicted To Be a Mispredict Instr. SeqNo PC Br A1 25 PC A Br A2 35 PC A Distance = 30 Ld C 55 PC C
37 Three Issues in Realistic Recovery Recovery may be initiated for a correctly-predicted correct-path branch. Happens for 3.8% of WPE detections. A WPE may occur on the correct path! Happens rarely (0.05% of all WPEs). We see no recovery initiated in this case. Early recovery for indirect branches The processor needs to predict a new target address. Target addresses can also be recorded in the distance prediction table.
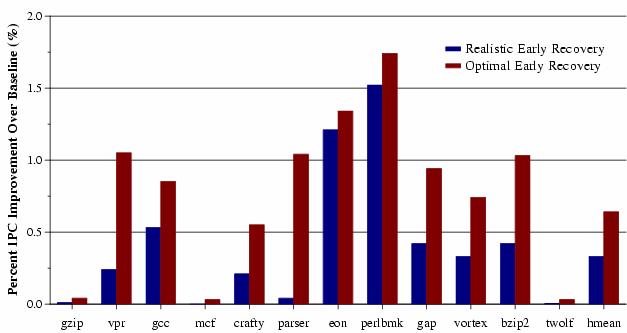
38 IPC Improvement
39 Shortcomings 1. WPEs do not occur frequently. Their coverage of mispredicted branches is low. 2. WPEs do not occur early enough. 3. Staying on the wrong path a few more cycles is sometimes more beneficial for performance than recovering early.
40 Future Research Directions Finding/generating new types of WPEs Can the compiler help? Better understanding of the differences between wrong path and correct path needed. Identifying what makes a particular wrong-path episode beneficial for performance Understanding the trade-offs related to the wrong path would be useful in deciding when to initiate early recovery. What else can WPEs be used for? Other kinds of speculation? Energy savings?
41 Conclusions Wrong-path instructions sometimes exhibit illegal and unusual behavior, called wrong path events (WPEs). WPEs can be used to guess that the processor is on the wrong path and to initiate early misprediction recovery. A realistic and accurate early misprediction recovery mechanism is described. Shortcomings of WPEs are discussed. Future research should focus on finding new WPEs.
42 Backup Slides
43 Related Work Glew proposed the use of bad memory addresses and illegal instructions as strong indicators of branch mispredictions [Wisc 00]. Jacobsen et al. explored branch confidence estimation to predict the likelihood that a branch is mispredicted [ISCA 96]. Manne et al. used branch confidence to gate the pipeline when there is a high likelihood that the processor is on the wrong path [ISCA 98]. Jiménez et al. proposed an overriding predictor scheme, where a more accurate slow predictor overrides the prediction made by a less accurate fast predictor [MICRO 00]. Falcón et al. proposed the use of predictions made for younger branches to re-evaluate the prediction made for an older branch [ISCA 04].
44 Contributions 1. A new idea in branch prediction. 2. We observe that wrong-path instructions exhibit illegal and unusual behavior, called wrong path events (WPEs). 3. We describe a novel mechanism to trigger early misprediction detection and recovery using WPEs. 4. We analyze and discuss the shortcomings of WPEs and propose new research areas to address these shortcomings.
45 Distribution of Cycles Between WPE and Branch Resolution

46 Distance Predictor Accuracy
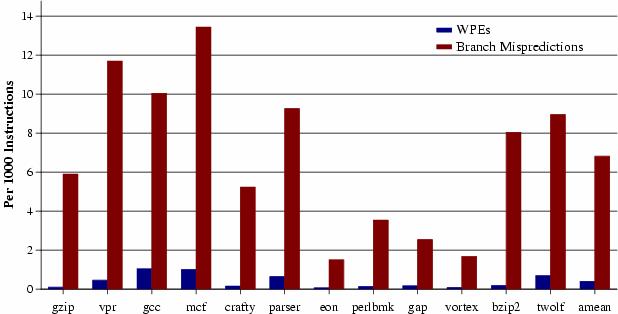
47 WPE and Misprediction Rate
Understanding The Effects of Wrong-path Memory References on Processor Performance
 Understanding The Effects of Wrong-path Memory References on Processor Performance Onur Mutlu Hyesoon Kim David N. Armstrong Yale N. Patt The University of Texas at Austin 2 Motivation Processors spend
Understanding The Effects of Wrong-path Memory References on Processor Performance Onur Mutlu Hyesoon Kim David N. Armstrong Yale N. Patt The University of Texas at Austin 2 Motivation Processors spend
An Analysis of the Performance Impact of Wrong-Path Memory References on Out-of-Order and Runahead Execution Processors
 An Analysis of the Performance Impact of Wrong-Path Memory References on Out-of-Order and Runahead Execution Processors Onur Mutlu Hyesoon Kim David N. Armstrong Yale N. Patt High Performance Systems Group
An Analysis of the Performance Impact of Wrong-Path Memory References on Out-of-Order and Runahead Execution Processors Onur Mutlu Hyesoon Kim David N. Armstrong Yale N. Patt High Performance Systems Group
Techniques for Efficient Processing in Runahead Execution Engines
 Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Techniques for Efficient Processing in Runahead Execution Engines Onur Mutlu Hyesoon Kim Yale N. Patt Depment of Electrical and Computer Engineering University of Texas at Austin {onur,hyesoon,patt}@ece.utexas.edu
Performance-Aware Speculation Control Using Wrong Path Usefulness Prediction. Chang Joo Lee Hyesoon Kim Onur Mutlu Yale N. Patt
 Performance-Aware Speculation Control Using Wrong Path Usefulness Prediction Chang Joo Lee Hyesoon Kim Onur Mutlu Yale N. Patt High Performance Systems Group Department of Electrical and Computer Engineering
Performance-Aware Speculation Control Using Wrong Path Usefulness Prediction Chang Joo Lee Hyesoon Kim Onur Mutlu Yale N. Patt High Performance Systems Group Department of Electrical and Computer Engineering
Wish Branch: A New Control Flow Instruction Combining Conditional Branching and Predicated Execution
 Wish Branch: A New Control Flow Instruction Combining Conditional Branching and Predicated Execution Hyesoon Kim Onur Mutlu Jared Stark David N. Armstrong Yale N. Patt High Performance Systems Group Department
Wish Branch: A New Control Flow Instruction Combining Conditional Branching and Predicated Execution Hyesoon Kim Onur Mutlu Jared Stark David N. Armstrong Yale N. Patt High Performance Systems Group Department
Branch statistics. 66% forward (i.e., slightly over 50% of total branches). Most often Not Taken 33% backward. Almost all Taken
. Most often Not Taken 33% backward. Almost all Taken") Branch statistics Branches occur every 4-7 instructions on average in integer programs, commercial and desktop applications; somewhat less frequently in scientific ones Unconditional branches : 20% (of
Branch statistics Branches occur every 4-7 instructions on average in integer programs, commercial and desktop applications; somewhat less frequently in scientific ones Unconditional branches : 20% (of
Computer Architecture: Branch Prediction. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Branch Prediction Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 11: Branch Prediction
Computer Architecture: Branch Prediction Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 11: Branch Prediction
Execution-based Prediction Using Speculative Slices
 Execution-based Prediction Using Speculative Slices Craig Zilles and Guri Sohi University of Wisconsin - Madison International Symposium on Computer Architecture July, 2001 The Problem Two major barriers
Execution-based Prediction Using Speculative Slices Craig Zilles and Guri Sohi University of Wisconsin - Madison International Symposium on Computer Architecture July, 2001 The Problem Two major barriers
Performance-Aware Speculation Control using Wrong Path Usefulness Prediction
 Performance-Aware Speculation Control using Wrong Path Usefulness Prediction Chang Joo Lee Hyesoon Kim Onur Mutlu Yale N. Patt Department of Electrical and Computer Engineering The University of Texas
Performance-Aware Speculation Control using Wrong Path Usefulness Prediction Chang Joo Lee Hyesoon Kim Onur Mutlu Yale N. Patt Department of Electrical and Computer Engineering The University of Texas
 1 cycle per instruction I
1 cycle per instruction I 18-447: Computer Architecture Lecture 23: Tolerating Memory Latency II. Prof. Onur Mutlu Carnegie Mellon University Spring 2012, 4/18/2012
 18-447: Computer Architecture Lecture 23: Tolerating Memory Latency II Prof. Onur Mutlu Carnegie Mellon University Spring 2012, 4/18/2012 Reminder: Lab Assignments Lab Assignment 6 Implementing a more
18-447: Computer Architecture Lecture 23: Tolerating Memory Latency II Prof. Onur Mutlu Carnegie Mellon University Spring 2012, 4/18/2012 Reminder: Lab Assignments Lab Assignment 6 Implementing a more
Instruction Level Parallelism (Branch Prediction)
") Instruction Level Parallelism (Branch Prediction) Branch Types Type Direction at fetch time Number of possible next fetch addresses? When is next fetch address resolved? Conditional Unknown 2 Execution
Instruction Level Parallelism (Branch Prediction) Branch Types Type Direction at fetch time Number of possible next fetch addresses? When is next fetch address resolved? Conditional Unknown 2 Execution
Looking for Instruction Level Parallelism (ILP) Branch Prediction. Branch Prediction. Importance of Branch Prediction
 Branch Prediction. Branch Prediction. Importance of Branch Prediction") Looking for Instruction Level Parallelism (ILP) Branch Prediction We want to identify and exploit ILP instructions that can potentially be executed at the same time. Branches are 15-20% of instructions
Looking for Instruction Level Parallelism (ILP) Branch Prediction We want to identify and exploit ILP instructions that can potentially be executed at the same time. Branches are 15-20% of instructions
Branch Prediction & Speculative Execution. Branch Penalties in Modern Pipelines
 6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
6.823, L15--1 Branch Prediction & Speculative Execution Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 6.823, L15--2 Branch Penalties in Modern Pipelines UltraSPARC-III
Looking for Instruction Level Parallelism (ILP) Branch Prediction. Branch Prediction. Importance of Branch Prediction
 Branch Prediction. Branch Prediction. Importance of Branch Prediction") Looking for Instruction Level Parallelism (ILP) Branch Prediction We want to identify and exploit ILP instructions that can potentially be executed at the same time. Branches are 5-20% of instructions
Looking for Instruction Level Parallelism (ILP) Branch Prediction We want to identify and exploit ILP instructions that can potentially be executed at the same time. Branches are 5-20% of instructions
15-740/ Computer Architecture Lecture 5: Precise Exceptions. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 5: Precise Exceptions Prof. Onur Mutlu Carnegie Mellon University Last Time Performance Metrics Amdahl s Law Single-cycle, multi-cycle machines Pipelining Stalls
15-740/18-740 Computer Architecture Lecture 5: Precise Exceptions Prof. Onur Mutlu Carnegie Mellon University Last Time Performance Metrics Amdahl s Law Single-cycle, multi-cycle machines Pipelining Stalls
15-740/ Computer Architecture Lecture 10: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/3/2011
 5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
5-740/8-740 Computer Architecture Lecture 0: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Fall 20, 0/3/20 Review: Solutions to Enable Precise Exceptions Reorder buffer History buffer
Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling)
") 18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
18-447 Computer Architecture Lecture 12: Out-of-Order Execution (Dynamic Instruction Scheduling) Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 2/13/2015 Agenda for Today & Next Few Lectures
15-740/ Computer Architecture Lecture 29: Control Flow II. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/30/11
 15-740/18-740 Computer Architecture Lecture 29: Control Flow II Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/30/11 Announcements for This Week December 2: Midterm II Comprehensive 2 letter-sized
15-740/18-740 Computer Architecture Lecture 29: Control Flow II Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/30/11 Announcements for This Week December 2: Midterm II Comprehensive 2 letter-sized
15-740/ Computer Architecture Lecture 28: Prefetching III and Control Flow. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/28/11
 15-740/18-740 Computer Architecture Lecture 28: Prefetching III and Control Flow Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/28/11 Announcements for This Week December 2: Midterm II Comprehensive
15-740/18-740 Computer Architecture Lecture 28: Prefetching III and Control Flow Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 11/28/11 Announcements for This Week December 2: Midterm II Comprehensive
High Performance Systems Group Department of Electrical and Computer Engineering The University of Texas at Austin Austin, Texas
 Diverge-Merge Processor (DMP): Dynamic Predicated Execution of Complex Control-Flow Graphs Based on Frequently Executed Paths yesoon Kim José. Joao Onur Mutlu Yale N. Patt igh Performance Systems Group
Diverge-Merge Processor (DMP): Dynamic Predicated Execution of Complex Control-Flow Graphs Based on Frequently Executed Paths yesoon Kim José. Joao Onur Mutlu Yale N. Patt igh Performance Systems Group
15-740/ Computer Architecture Lecture 16: Prefetching Wrap-up. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 16: Prefetching Wrap-up Prof. Onur Mutlu Carnegie Mellon University Announcements Exam solutions online Pick up your exams Feedback forms 2 Feedback Survey Results
15-740/18-740 Computer Architecture Lecture 16: Prefetching Wrap-up Prof. Onur Mutlu Carnegie Mellon University Announcements Exam solutions online Pick up your exams Feedback forms 2 Feedback Survey Results
15-740/ Computer Architecture Lecture 14: Runahead Execution. Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/12/2011
 15-740/18-740 Computer Architecture Lecture 14: Runahead Execution Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/12/2011 Reviews Due Today Chrysos and Emer, Memory Dependence Prediction Using
15-740/18-740 Computer Architecture Lecture 14: Runahead Execution Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/12/2011 Reviews Due Today Chrysos and Emer, Memory Dependence Prediction Using
Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars Krste Asanovic Electrical Engineering and Computer
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 12 Branch Prediction and Advanced Out-of-Order Superscalars Krste Asanovic Electrical Engineering and Computer
Wide Instruction Fetch
 Wide Instruction Fetch Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 edu/courses/eecs470 block_ids Trace Table pre-collapse trace_id History Br. Hash hist. Rename Fill Table
Wide Instruction Fetch Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 edu/courses/eecs470 block_ids Trace Table pre-collapse trace_id History Br. Hash hist. Rename Fill Table
15-740/ Computer Architecture Lecture 10: Runahead and MLP. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 10: Runahead and MLP Prof. Onur Mutlu Carnegie Mellon University Last Time Issues in Out-of-order execution Buffer decoupling Register alias tables Physical
15-740/18-740 Computer Architecture Lecture 10: Runahead and MLP Prof. Onur Mutlu Carnegie Mellon University Last Time Issues in Out-of-order execution Buffer decoupling Register alias tables Physical
Design of Digital Circuits Lecture 18: Branch Prediction. Prof. Onur Mutlu ETH Zurich Spring May 2018
 Design of Digital Circuits Lecture 18: Branch Prediction Prof. Onur Mutlu ETH Zurich Spring 2018 3 May 2018 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed
Design of Digital Circuits Lecture 18: Branch Prediction Prof. Onur Mutlu ETH Zurich Spring 2018 3 May 2018 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed
Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction
 Stalls with Dynamic Branch Prediction") ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
ISA Support Needed By CPU Reduction of Control Hazards (Branch) Stalls with Dynamic Branch Prediction So far we have dealt with control hazards in instruction pipelines by: 1 2 3 4 Assuming that the branch
Dynamic Memory Dependence Predication
 Dynamic Memory Dependence Predication Zhaoxiang Jin and Soner Önder ISCA-2018, Los Angeles Background 1. Store instructions do not update the cache until they are retired (too late). 2. Store queue is
Dynamic Memory Dependence Predication Zhaoxiang Jin and Soner Önder ISCA-2018, Los Angeles Background 1. Store instructions do not update the cache until they are retired (too late). 2. Store queue is
Feedback Directed Prefetching: Improving the Performance and Bandwidth-Efficiency of Hardware Prefetchers
 Feedback Directed Prefetching: Improving the Performance and Bandwidth-Efficiency of Hardware Prefetchers Microsoft ssri@microsoft.com Santhosh Srinath Onur Mutlu Hyesoon Kim Yale N. Patt Microsoft Research
Feedback Directed Prefetching: Improving the Performance and Bandwidth-Efficiency of Hardware Prefetchers Microsoft ssri@microsoft.com Santhosh Srinath Onur Mutlu Hyesoon Kim Yale N. Patt Microsoft Research
Use-Based Register Caching with Decoupled Indexing
 Use-Based Register Caching with Decoupled Indexing J. Adam Butts and Guri Sohi University of Wisconsin Madison {butts,sohi}@cs.wisc.edu ISCA-31 München, Germany June 23, 2004 Motivation Need large register
Use-Based Register Caching with Decoupled Indexing J. Adam Butts and Guri Sohi University of Wisconsin Madison {butts,sohi}@cs.wisc.edu ISCA-31 München, Germany June 23, 2004 Motivation Need large register
Lecture 8: Instruction Fetch, ILP Limits. Today: advanced branch prediction, limits of ILP (Sections , )
") Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
Address-Value Delta (AVD) Prediction: A Hardware Technique for Efficiently Parallelizing Dependent Cache Misses. Onur Mutlu Hyesoon Kim Yale N.
 Prediction: A Hardware Technique for Efficiently Parallelizing Dependent Cache Misses. Onur Mutlu Hyesoon Kim Yale N.") Address-Value Delta (AVD) Prediction: A Hardware Technique for Efficiently Parallelizing Dependent Cache Misses Onur Mutlu Hyesoon Kim Yale N. Patt High Performance Systems Group Department of Electrical
Address-Value Delta (AVD) Prediction: A Hardware Technique for Efficiently Parallelizing Dependent Cache Misses Onur Mutlu Hyesoon Kim Yale N. Patt High Performance Systems Group Department of Electrical
Computer Architecture Lecture 15: Load/Store Handling and Data Flow. Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014
 18-447 Computer Architecture Lecture 15: Load/Store Handling and Data Flow Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014 Lab 4 Heads Up Lab 4a out Branch handling and branch predictors
18-447 Computer Architecture Lecture 15: Load/Store Handling and Data Flow Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/21/2014 Lab 4 Heads Up Lab 4a out Branch handling and branch predictors
Fall 2011 Prof. Hyesoon Kim
 Fall 2011 Prof. Hyesoon Kim 1 1.. 1 0 2bc 2bc BHR XOR index 2bc 0x809000 PC 2bc McFarling 93 Predictor size: 2^(history length)*2bit predict_func(pc, actual_dir) { index = pc xor BHR taken = 2bit_counters[index]
Fall 2011 Prof. Hyesoon Kim 1 1.. 1 0 2bc 2bc BHR XOR index 2bc 0x809000 PC 2bc McFarling 93 Predictor size: 2^(history length)*2bit predict_func(pc, actual_dir) { index = pc xor BHR taken = 2bit_counters[index]
Architectures for Instruction-Level Parallelism
 Low Power VLSI System Design Lecture : Low Power Microprocessor Design Prof. R. Iris Bahar October 0, 07 The HW/SW Interface Seminar Series Jointly sponsored by Engineering and Computer Science Hardware-Software
Low Power VLSI System Design Lecture : Low Power Microprocessor Design Prof. R. Iris Bahar October 0, 07 The HW/SW Interface Seminar Series Jointly sponsored by Engineering and Computer Science Hardware-Software
Computer Architecture Lecture 14: Out-of-Order Execution. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013
 18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
18-447 Computer Architecture Lecture 14: Out-of-Order Execution Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/18/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
Computer Architecture: Multithreading (III) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: Multithreading (III) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 13:
Computer Architecture: Multithreading (III) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-742 Fall 2012, Parallel Computer Architecture, Lecture 13:
Donn Morrison Department of Computer Science. TDT4255 ILP and speculation
 TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
TDT4255 Lecture 9: ILP and speculation Donn Morrison Department of Computer Science 2 Outline Textbook: Computer Architecture: A Quantitative Approach, 4th ed Section 2.6: Speculation Section 2.7: Multiple
Computer Architecture Lecture 13: State Maintenance and Recovery. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/15/2013
 18-447 Computer Architecture Lecture 13: State Maintenance and Recovery Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/15/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
18-447 Computer Architecture Lecture 13: State Maintenance and Recovery Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 2/15/2013 Reminder: Homework 3 Homework 3 Due Feb 25 REP MOVS in Microprogrammed
A Mechanism for Verifying Data Speculation
 A Mechanism for Verifying Data Speculation Enric Morancho, José María Llabería, and Àngel Olivé Computer Architecture Department, Universitat Politècnica de Catalunya (Spain), {enricm, llaberia, angel}@ac.upc.es
A Mechanism for Verifying Data Speculation Enric Morancho, José María Llabería, and Àngel Olivé Computer Architecture Department, Universitat Politècnica de Catalunya (Spain), {enricm, llaberia, angel}@ac.upc.es
1993. (BP-2) (BP-5, BP-10) (BP-6, BP-10) (BP-7, BP-10) YAGS (BP-10) EECC722
 (BP-5, BP-10) (BP-6, BP-10) (BP-7, BP-10) YAGS (BP-10) EECC722") Dynamic Branch Prediction Dynamic branch prediction schemes run-time behavior of branches to make predictions. Usually information about outcomes of previous occurrences of branches are used to predict
Dynamic Branch Prediction Dynamic branch prediction schemes run-time behavior of branches to make predictions. Usually information about outcomes of previous occurrences of branches are used to predict
An Efficient Indirect Branch Predictor
 An Efficient Indirect ranch Predictor Yul Chu and M. R. Ito 2 Electrical and Computer Engineering Department, Mississippi State University, ox 957, Mississippi State, MS 39762, USA chu@ece.msstate.edu
An Efficient Indirect ranch Predictor Yul Chu and M. R. Ito 2 Electrical and Computer Engineering Department, Mississippi State University, ox 957, Mississippi State, MS 39762, USA chu@ece.msstate.edu
Lecture 13: Branch Prediction
 S 09 L13-1 18-447 Lecture 13: Branch Prediction James C. Hoe Dept of ECE, CMU March 4, 2009 Announcements: Spring break!! Spring break next week!! Project 2 due the week after spring break HW3 due Monday
S 09 L13-1 18-447 Lecture 13: Branch Prediction James C. Hoe Dept of ECE, CMU March 4, 2009 Announcements: Spring break!! Spring break next week!! Project 2 due the week after spring break HW3 due Monday
COSC 6385 Computer Architecture Dynamic Branch Prediction
 COSC 6385 Computer Architecture Dynamic Branch Prediction Edgar Gabriel Spring 208 Pipelining Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution of
COSC 6385 Computer Architecture Dynamic Branch Prediction Edgar Gabriel Spring 208 Pipelining Pipelining allows for overlapping the execution of instructions Limitations on the (pipelined) execution of
Lecture 7: Static ILP and branch prediction. Topics: static speculation and branch prediction (Appendix G, Section 2.3)
") Lecture 7: Static ILP and branch prediction Topics: static speculation and branch prediction (Appendix G, Section 2.3) 1 Support for Speculation In general, when we re-order instructions, register renaming
Lecture 7: Static ILP and branch prediction Topics: static speculation and branch prediction (Appendix G, Section 2.3) 1 Support for Speculation In general, when we re-order instructions, register renaming
Eric Rotenberg Karthik Sundaramoorthy, Zach Purser
 Karthik Sundaramoorthy, Zach Purser Dept. of Electrical and Computer Engineering North Carolina State University http://www.tinker.ncsu.edu/ericro ericro@ece.ncsu.edu Many means to an end Program is merely
Karthik Sundaramoorthy, Zach Purser Dept. of Electrical and Computer Engineering North Carolina State University http://www.tinker.ncsu.edu/ericro ericro@ece.ncsu.edu Many means to an end Program is merely
Static Branch Prediction
 Static Branch Prediction Branch prediction schemes can be classified into static and dynamic schemes. Static methods are usually carried out by the compiler. They are static because the prediction is already
Static Branch Prediction Branch prediction schemes can be classified into static and dynamic schemes. Static methods are usually carried out by the compiler. They are static because the prediction is already
Performance of tournament predictors In the last lecture, we saw the design of the tournament predictor used by the Alpha
 Performance of tournament predictors In the last lecture, we saw the design of the tournament predictor used by the Alpha 21264. The Alpha s predictor is very successful. On the SPECfp 95 benchmarks, there
Performance of tournament predictors In the last lecture, we saw the design of the tournament predictor used by the Alpha 21264. The Alpha s predictor is very successful. On the SPECfp 95 benchmarks, there
Chapter 3 (CONT) Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,2013 1
 Instructor: Josep Torrellas CS433. Copyright J. Torrellas 1999,2001,2002,2007,2013 1") Chapter 3 (CONT) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007,2013 1 Dynamic Hardware Branch Prediction Control hazards are sources of losses, especially for processors
Chapter 3 (CONT) Instructor: Josep Torrellas CS433 Copyright J. Torrellas 1999,2001,2002,2007,2013 1 Dynamic Hardware Branch Prediction Control hazards are sources of losses, especially for processors
Computer Architecture, Fall 2010 Midterm Exam I
 15740-18740 Computer Architecture, Fall 2010 Midterm Exam I Instructor: Onur Mutlu Teaching Assistants: Evangelos Vlachos, Lavanya Subramanian, Vivek Seshadri Date: October 11, 2010 Instructions: Name:
15740-18740 Computer Architecture, Fall 2010 Midterm Exam I Instructor: Onur Mutlu Teaching Assistants: Evangelos Vlachos, Lavanya Subramanian, Vivek Seshadri Date: October 11, 2010 Instructions: Name:
For this problem, consider the following architecture specifications: Functional Unit Type Cycles in EX Number of Functional Units
 CS333: Computer Architecture Spring 006 Homework 3 Total Points: 49 Points (undergrad), 57 Points (graduate) Due Date: Feb. 8, 006 by 1:30 pm (See course information handout for more details on late submissions)
CS333: Computer Architecture Spring 006 Homework 3 Total Points: 49 Points (undergrad), 57 Points (graduate) Due Date: Feb. 8, 006 by 1:30 pm (See course information handout for more details on late submissions)
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25
 CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
CS152 Computer Architecture and Engineering March 13, 2008 Out of Order Execution and Branch Prediction Assigned March 13 Problem Set #4 Due March 25 http://inst.eecs.berkeley.edu/~cs152/sp08 The problem
Computer Architecture: Out-of-Order Execution II. Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Out-of-Order Execution II Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15 Video
Computer Architecture: Out-of-Order Execution II Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15 Video
Bottleneck Identification and Scheduling in Multithreaded Applications. José A. Joao M. Aater Suleman Onur Mutlu Yale N. Patt
 Bottleneck Identification and Scheduling in Multithreaded Applications José A. Joao M. Aater Suleman Onur Mutlu Yale N. Patt Executive Summary Problem: Performance and scalability of multithreaded applications
Bottleneck Identification and Scheduling in Multithreaded Applications José A. Joao M. Aater Suleman Onur Mutlu Yale N. Patt Executive Summary Problem: Performance and scalability of multithreaded applications
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
Static Branch Prediction
 Announcements EE382A Lecture 5: Branch Prediction Project proposal due on Mo 10/14 List the group members Describe the topic including why it is important and your thesis Describe the methodology you will
Announcements EE382A Lecture 5: Branch Prediction Project proposal due on Mo 10/14 List the group members Describe the topic including why it is important and your thesis Describe the methodology you will
Lecture 7: Static ILP, Branch prediction. Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections )
") Lecture 7: Static ILP, Branch prediction Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections 2.2-2.6) 1 Predication A branch within a loop can be problematic to schedule Control
Lecture 7: Static ILP, Branch prediction Topics: static ILP wrap-up, bimodal, global, local branch prediction (Sections 2.2-2.6) 1 Predication A branch within a loop can be problematic to schedule Control
Computer Architecture Area Fall 2009 PhD Qualifier Exam October 20 th 2008
 Computer Architecture Area Fall 2009 PhD Qualifier Exam October 20 th 2008 This exam has nine (9) problems. You should submit your answers to six (6) of these nine problems. You should not submit answers
Computer Architecture Area Fall 2009 PhD Qualifier Exam October 20 th 2008 This exam has nine (9) problems. You should submit your answers to six (6) of these nine problems. You should not submit answers
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Instruction Fetching based on Branch Predictor Confidence. Kai Da Zhao Younggyun Cho Han Lin 2014 Fall, CS752 Final Project
 Instruction Fetching based on Branch Predictor Confidence Kai Da Zhao Younggyun Cho Han Lin 2014 Fall, CS752 Final Project Outline Motivation Project Goals Related Works Proposed Confidence Assignment
Instruction Fetching based on Branch Predictor Confidence Kai Da Zhao Younggyun Cho Han Lin 2014 Fall, CS752 Final Project Outline Motivation Project Goals Related Works Proposed Confidence Assignment
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
CS252 Spring 2017 Graduate Computer Architecture. Lecture 8: Advanced Out-of-Order Superscalar Designs Part II
 CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
CS252 Spring 2017 Graduate Computer Architecture Lecture 8: Advanced Out-of-Order Superscalar Designs Part II Lisa Wu, Krste Asanovic http://inst.eecs.berkeley.edu/~cs252/sp17 WU UCB CS252 SP17 Last Time
15-740/ Computer Architecture
 15-740/18-740 Computer Architecture Lecture 16: Runahead and OoO Wrap-Up Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/17/2011 Review Set 9 Due this Wednesday (October 19) Wilkes, Slave Memories
15-740/18-740 Computer Architecture Lecture 16: Runahead and OoO Wrap-Up Prof. Onur Mutlu Carnegie Mellon University Fall 2011, 10/17/2011 Review Set 9 Due this Wednesday (October 19) Wilkes, Slave Memories
EE382A Lecture 5: Branch Prediction. Department of Electrical Engineering Stanford University
 EE382A Lecture 5: Branch Prediction Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 5-1 Announcements Project proposal due on Mo 10/14 List the group
EE382A Lecture 5: Branch Prediction Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 5-1 Announcements Project proposal due on Mo 10/14 List the group
2D-Profiling: Detecting Input-Dependent Branches with a Single Input Data Set
 2D-Profiling: Detecting Input-Dependent Branches with a Single Input Data Set Hyesoon Kim M. Aater Suleman Onur Mutlu Yale N. Patt Department of Electrical and Computer Engineering University of Texas
2D-Profiling: Detecting Input-Dependent Branches with a Single Input Data Set Hyesoon Kim M. Aater Suleman Onur Mutlu Yale N. Patt Department of Electrical and Computer Engineering University of Texas
15-740/ Computer Architecture Lecture 8: Issues in Out-of-order Execution. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 8: Issues in Out-of-order Execution Prof. Onur Mutlu Carnegie Mellon University Readings General introduction and basic concepts Smith and Sohi, The Microarchitecture
15-740/18-740 Computer Architecture Lecture 8: Issues in Out-of-order Execution Prof. Onur Mutlu Carnegie Mellon University Readings General introduction and basic concepts Smith and Sohi, The Microarchitecture
ECE473 Computer Architecture and Organization. Pipeline: Control Hazard
 Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Computer Architecture and Organization Pipeline: Control Hazard Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 15.1 Pipelining Outline Introduction
Old formulation of branch paths w/o prediction. bne $2,$3,foo subu $3,.. ld $2,..
 Old formulation of branch paths w/o prediction bne $2,$3,foo subu $3,.. ld $2,.. Cleaner formulation of Branching Front End Back End Instr Cache Guess PC Instr PC dequeue!= dcache arch. PC branch resolution
Old formulation of branch paths w/o prediction bne $2,$3,foo subu $3,.. ld $2,.. Cleaner formulation of Branching Front End Back End Instr Cache Guess PC Instr PC dequeue!= dcache arch. PC branch resolution
Microarchitecture-Based Introspection: A Technique for Transient-Fault Tolerance in Microprocessors. Moinuddin K. Qureshi Onur Mutlu Yale N.
 Microarchitecture-Based Introspection: A Technique for Transient-Fault Tolerance in Microprocessors Moinuddin K. Qureshi Onur Mutlu Yale N. Patt High Performance Systems Group Department of Electrical
Microarchitecture-Based Introspection: A Technique for Transient-Fault Tolerance in Microprocessors Moinuddin K. Qureshi Onur Mutlu Yale N. Patt High Performance Systems Group Department of Electrical
HANDLING MEMORY OPS. Dynamically Scheduling Memory Ops. Loads and Stores. Loads and Stores. Loads and Stores. Memory Forwarding
 HANDLING MEMORY OPS 9 Dynamically Scheduling Memory Ops Compilers must schedule memory ops conservatively Options for hardware: Hold loads until all prior stores execute (conservative) Execute loads as
HANDLING MEMORY OPS 9 Dynamically Scheduling Memory Ops Compilers must schedule memory ops conservatively Options for hardware: Hold loads until all prior stores execute (conservative) Execute loads as
DIVERGE-MERGE PROCESSOR: GENERALIZED AND ENERGY-EFFICIENT DYNAMIC PREDICATION
 ... DIVERGE-MERGE PROCESSOR: GENERALIZED AND ENERGY-EFFICIENT DYNAMIC PREDICATION... THE BRANCH MISPREDICTION PENALTY IS A MAJOR PERFORMANCE LIMITER AND A MAJOR CAUSE OF WASTED ENERGY IN HIGH-PERFORMANCE
... DIVERGE-MERGE PROCESSOR: GENERALIZED AND ENERGY-EFFICIENT DYNAMIC PREDICATION... THE BRANCH MISPREDICTION PENALTY IS A MAJOR PERFORMANCE LIMITER AND A MAJOR CAUSE OF WASTED ENERGY IN HIGH-PERFORMANCE
Instruction-Level Parallelism Dynamic Branch Prediction. Reducing Branch Penalties
 Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Dynamic Branch Prediction
 #1 lec # 6 Fall 2002 9-25-2002 Dynamic Branch Prediction Dynamic branch prediction schemes are different from static mechanisms because they use the run-time behavior of branches to make predictions. Usually
#1 lec # 6 Fall 2002 9-25-2002 Dynamic Branch Prediction Dynamic branch prediction schemes are different from static mechanisms because they use the run-time behavior of branches to make predictions. Usually
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
ECE 571 Advanced Microprocessor-Based Design Lecture 7
 ECE 571 Advanced Microprocessor-Based Design Lecture 7 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 9 February 2016 HW2 Grades Ready Announcements HW3 Posted be careful when
ECE 571 Advanced Microprocessor-Based Design Lecture 7 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 9 February 2016 HW2 Grades Ready Announcements HW3 Posted be careful when
Simultaneous Multithreading Processor
 Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
Simultaneous Multithreading Processor Paper presented: Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor James Lue Some slides are modified from http://hassan.shojania.com/pdf/smt_presentation.pdf
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science ! CPI = (1-branch%) * non-branch CPI + branch% *
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science ! CPI = (1-branch%) * non-branch CPI + branch% *
Achieving Out-of-Order Performance with Almost In-Order Complexity
 Achieving Out-of-Order Performance with Almost In-Order Complexity Comprehensive Examination Part II By Raj Parihar Background Info: About the Paper Title Achieving Out-of-Order Performance with Almost
Achieving Out-of-Order Performance with Almost In-Order Complexity Comprehensive Examination Part II By Raj Parihar Background Info: About the Paper Title Achieving Out-of-Order Performance with Almost
ECE 571 Advanced Microprocessor-Based Design Lecture 8
 ECE 571 Advanced Microprocessor-Based Design Lecture 8 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 16 February 2017 Announcements HW4 Due HW5 will be posted 1 HW#3 Review Energy
ECE 571 Advanced Microprocessor-Based Design Lecture 8 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 16 February 2017 Announcements HW4 Due HW5 will be posted 1 HW#3 Review Energy
UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation.
 UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation. July 14) (June 2013) (June 2015)(Jan 2016)(June 2016) H/W Support : Conditional Execution Also known
UNIT 8 1. Explain in detail the hardware support for preserving exception behavior during Speculation. July 14) (June 2013) (June 2015)(Jan 2016)(June 2016) H/W Support : Conditional Execution Also known
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
18-740/640 Computer Architecture Lecture 5: Advanced Branch Prediction. Prof. Onur Mutlu Carnegie Mellon University Fall 2015, 9/16/2015
 18-740/640 Computer Architecture Lecture 5: Advanced Branch Prediction Prof. Onur Mutlu Carnegie Mellon University Fall 2015, 9/16/2015 Required Readings Required Reading Assignment: Chapter 5 of Shen
18-740/640 Computer Architecture Lecture 5: Advanced Branch Prediction Prof. Onur Mutlu Carnegie Mellon University Fall 2015, 9/16/2015 Required Readings Required Reading Assignment: Chapter 5 of Shen
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
EE482: Advanced Computer Organization Lecture #3 Processor Architecture Stanford University Monday, 8 May Branch Prediction
 EE482: Advanced Computer Organization Lecture #3 Processor Architecture Stanford University Monday, 8 May 2000 Lecture #3: Wednesday, 5 April 2000 Lecturer: Mattan Erez Scribe: Mahesh Madhav Branch Prediction
EE482: Advanced Computer Organization Lecture #3 Processor Architecture Stanford University Monday, 8 May 2000 Lecture #3: Wednesday, 5 April 2000 Lecturer: Mattan Erez Scribe: Mahesh Madhav Branch Prediction
Appendix A.2 (pg. A-21 A-26), Section 4.2, Section 3.4. Performance of Branch Prediction Schemes
, Section 4.2, Section 3.4. Performance of Branch Prediction Schemes") Module: Branch Prediction Krishna V. Palem, Weng Fai Wong, and Sudhakar Yalamanchili, Georgia Institute of Technology (slides contributed by Prof. Weng Fai Wong were prepared while visiting, and employed
Module: Branch Prediction Krishna V. Palem, Weng Fai Wong, and Sudhakar Yalamanchili, Georgia Institute of Technology (slides contributed by Prof. Weng Fai Wong were prepared while visiting, and employed
Bloom Filtering Cache Misses for Accurate Data Speculation and Prefetching
 Bloom Filtering Cache Misses for Accurate Data Speculation and Prefetching Jih-Kwon Peir, Shih-Chang Lai, Shih-Lien Lu, Jared Stark, Konrad Lai peir@cise.ufl.edu Computer & Information Science and Engineering
Bloom Filtering Cache Misses for Accurate Data Speculation and Prefetching Jih-Kwon Peir, Shih-Chang Lai, Shih-Lien Lu, Jared Stark, Konrad Lai peir@cise.ufl.edu Computer & Information Science and Engineering
15-740/ Computer Architecture Lecture 22: Superscalar Processing (II) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") 15-740/18-740 Computer Architecture Lecture 22: Superscalar Processing (II) Prof. Onur Mutlu Carnegie Mellon University Announcements Project Milestone 2 Due Today Homework 4 Out today Due November 15
15-740/18-740 Computer Architecture Lecture 22: Superscalar Processing (II) Prof. Onur Mutlu Carnegie Mellon University Announcements Project Milestone 2 Due Today Homework 4 Out today Due November 15
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window
 Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Dual-Core Execution: Building A Highly Scalable Single-Thread Instruction Window Huiyang Zhou School of Computer Science University of Central Florida New Challenges in Billion-Transistor Processor Era
Towards a More Efficient Trace Cache
 Towards a More Efficient Trace Cache Rajnish Kumar, Amit Kumar Saha, Jerry T. Yen Department of Computer Science and Electrical Engineering George R. Brown School of Engineering, Rice University {rajnish,
Towards a More Efficient Trace Cache Rajnish Kumar, Amit Kumar Saha, Jerry T. Yen Department of Computer Science and Electrical Engineering George R. Brown School of Engineering, Rice University {rajnish,