Cell Programming Tips & Techniques
|
|
|
- Kelly Rogers
- 5 years ago
- Views:
Transcription
1 Cell Programming Tips & Techniques Course Code: L3T2H1-58 Cell Ecosystem Solutions Enablement 1
2 Class Objectives Things you will learn Key programming techniques to exploit cell hardware organization and language features for SPU SIMD 2
3 Class Agenda Review relevant SPE Features SPU Programming Tips Level of Programming (Assembler, Intrinsics, Auto-Vectorization) Overlap DMA with computation (double, multiple buffering) Dual Issue rate (Instruction Scheduling) Design for limited local store Branch hints or elimination Loop unrolling and pipelining Integer multiplies (avoid 32-bit integer multiplies) Shuffle byte instructions for table look-ups Avoid scalar code Choose the right SIMD strategy Load / Store only by quadword SIMD Programming Tips 3
4 Review Cell Architecture 4

5 Cell Processor 5

6 Course Agenda Cell Blade Products Cell Blade Family of Servers Cell Blade Architecture Cell Blade Overview Critical signals, link speed and bandwidth Power consumption Hardware components Blade and blade center assembly Example of a cell blade with maximum interconnection capability Options - Infiniband References: Dan Brokenshire, BE Programming Tips Trademarks: Cell Broadband Engine is a trademark of Sony Computer Entertainment, Inc. 6

7 Key SPE Features 7

8 SPE Single-Ported Local Memory 8
9 SPU Programming Tips 9
10 SPU Programming Tips Level of Programming (Assembler, Intrinsics, Auto-Vectorization) Overlap DMA with computation (double, multiple buffering) Dual Issue rate (Instruction Scheduling) Design for limited local store Branch hints or elimination Loop unrolling and pipelining Integer multiplies (avoid 32-bit integer multiplies) Shuffle byte instructions for table look-ups Avoid scalar code Choose the right SIMD strategy Load / Store only by quadword 10
11 Programming Levels on Cell BE Trade-Off Performance vs. Effort Expert level Assembler, high performance, high efforts More ease of programming C compiler, vector data types, intrinsics, compiler schedules instructions + allocates registers Auto-SIMDization for scalar loops, user should support by alignment directives, compiler provides feedback about SIMDization Highest degree of ease of use user-guided parallelization necessary, Cell BE looks like a single processor Requirements for Compiler increasing with each level 11

12 Overlap DMA with computation Double or multi-buffer code or (typically) data Example for double bufferign n+1 data blcoks: Use multiple buffers in local store Use unique DMA tag ID for each buffer Use fence commands to order DMAs within a tag group Use barrier commands to ordr DMAs within a queue 12
13 Start DMAs from SPU Use SPE-initiated DMA transfers rather than PPEinitiated DMA transfers, because there are more SPEs than the one PPE the PPE can enqueue only eight DMA requests whereas each SPE can enqueue 16 13

14 Instruction Scheduling 14
15 Instruction Starvation Situation Dual-Issue Dual-Issue Instruction Instruction Logic Logic There are 2 instruction buffers up to 64 ops along the fall-through path First buffer is half-empty can initiate refill initiate refill after half empty instruction buffers When port is continuously used starvation occurs (no ops left in buffers) 15
16 Instruction Starvation Prevention initiate refill after half empty Dual-Issue Dual-Issue Instruction Instruction Logic Logic instruction buffer before it is too late to hide latency SPE has an explicit IFETCH op which initiates an instruction fetch Scheduler monitors starvation situation when port is continuously used insert IFETCH op within the (red) window refill IFETCH latency Compiler design scheduler must keep track of code layout 16
17 Design for Limited Local Store The Local Store holds up to 256 KB for the program, stack, local data structures, and DMA buffers. Most performance optimizations put pressure on local store (e.g. multiple DMA buffers) Use plug-ins (runtime download program kernels) to build complex function servers in the LS. 17
18 Branch Optimizations SPE Heavily pipelined high penalty for branch misses (18 cycles) Hardware policy: assume all branches are not taken Advantage Reduced hardware complexity Faster clock cycles Increased predictability Solution approaches If-conversions: compare and select operations Predications/code re-org: compiler analysis, user directives Branch hint instruction (hbr, 11 cycles before branch) 18
19 Branches 19
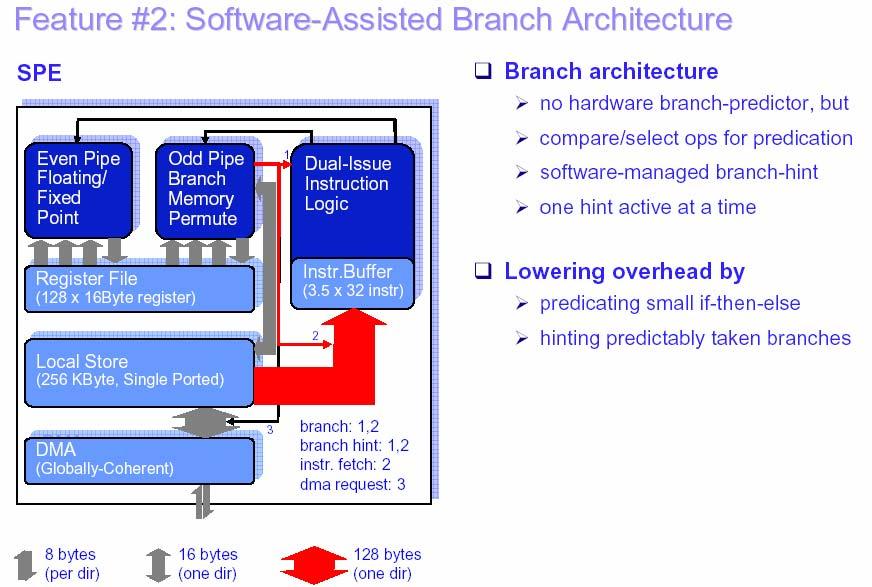
20 20
21 Hinting Branches & Instruction Starvation Prevention Dual-Issue Dual-Issue Instruction Instruction Logic Logic instruction buffers HINT buffer SPE provides a HINT operation fetches the branch target into HINT buffer no penalty for correctly predicted branches IFETCH window refill latency BRANCH if true HINT br, target fetches ops from target; needs a min of 15 cycles and 8 intervening ops target compiler inserts hints when beneficial Impact on instruction starvation after a correctly hinted branch, IFETCH window is smaller 21
22 Loop Unrolling Unroll loops to reduce dependencies increase dual-issue rates This exploits the large SPU register file. Compiler auto-unrolling is not perfect, but pretty good. 22
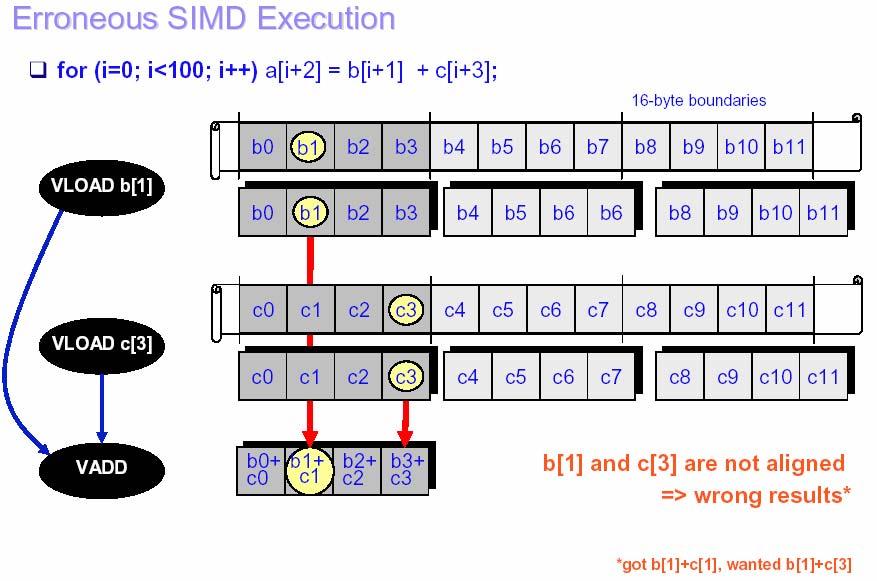
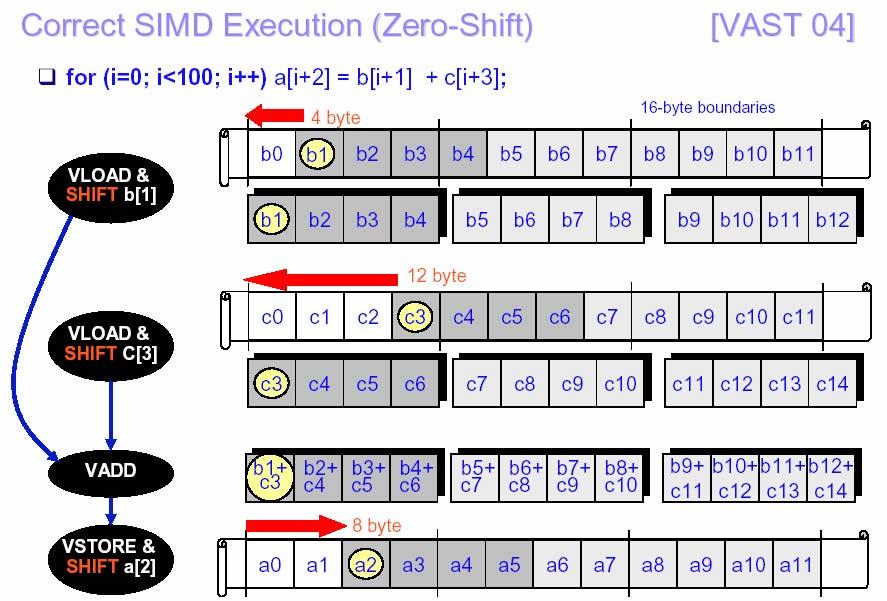
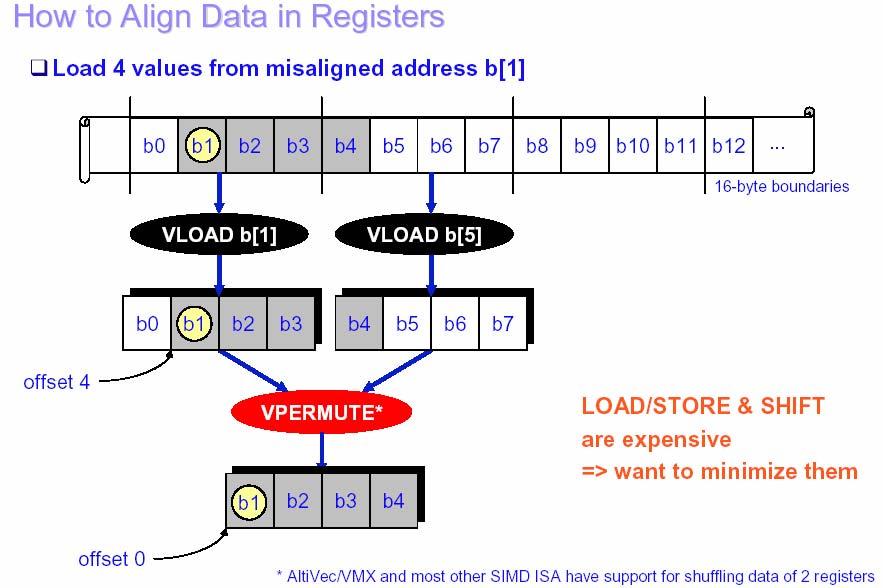
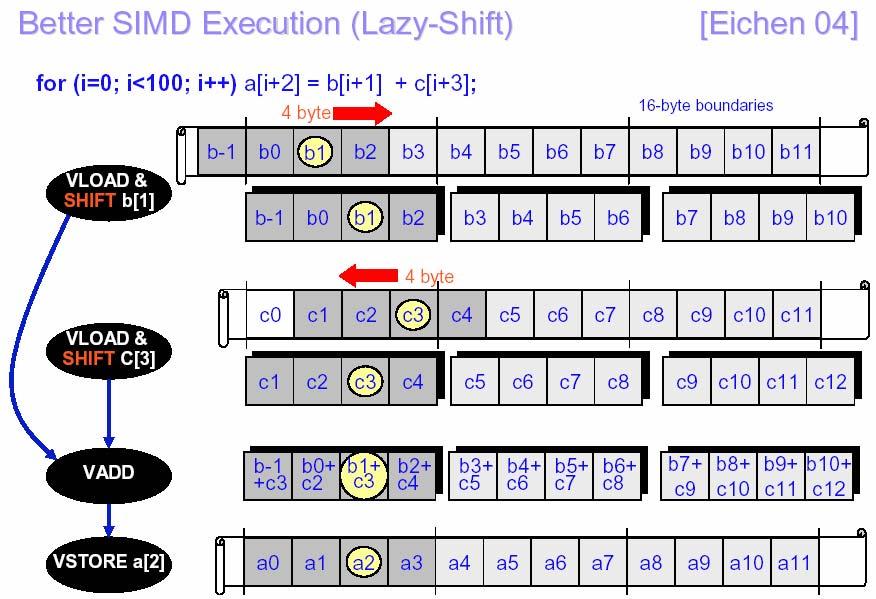
23 Loop Unrolling - Examples j=n; For(i=1, i<n, i++) { a[i] = (b[i] + b[j]) / 2; j = i; } a[1] = (b[1] + b[n]) / 2; For(i=2, i<n, i++) { a[i] = (b[i] + b[i-1]) / 2; } For(i=1, i<100, i++) { } a[i] = b[i+2] * c[i-1]; For(i=1, i<99, i+=2) { a[i] = b[i+2] * c[i-1]; a[i+1] = b[i+3] * c[i]; } 23
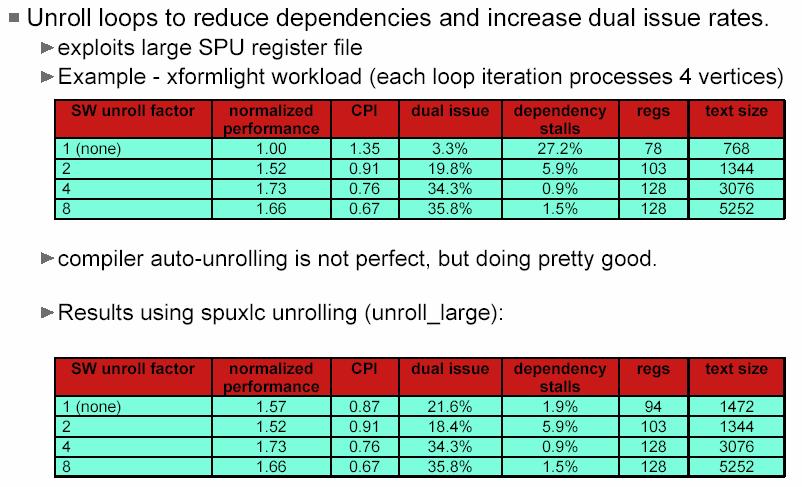
24 SPU 24

25 SPU Software Pipeline 25
26 Integer Multiplies Avoid integer multiplies on operands greater than 16 bits SPU supports only a 16-bit x16-bit multiply 32-bit multiply requires five instructions (three 16-bit multiplies and two adds) Keep array elements sized to a power-of-2 to avoid multiplies when indexing. Cast operands to unsigned short prior to multiplying. Constants are of type int and also require casting. Use a macro to explicitly perform 16-bit multiplies. This can avoid inadvertent introduction of signed extends and masks due to casting. #define MULTIPLY(a, b)\ (spu_extract(spu_mulo((vector unsigned short)spu_promote(a,0),\ (vector unsigned short)spu_promote(b, 0)),0)) 26

27 Avoid Scalar Code 27
28 Choose an SIMD strategy appropriate for your algorithm Evaluate array-of-structure (AOS) organization For graphics vertices, this organization (also called or vector-across) can have more-efficient code size and simpler DMA needs, but less-efficient computation unless the code is unrolled. Evaluate structure-of-arrays (SOA) organization. For graphics vertices, this organization (also called parallel-array) can be easier to SIMDize, but the data must be maintained in separate arrays or the SPU must shuffle AOS data into an SOA form. 28

29 Choose SIMD strategy appropriate for algorithm vec-across More efficient code size Typically less efficient code/computation unless code is unrolled Typically simpler DMA needs parallel-array Easy to SIMD program as if scalar, operating on 4 independent objects at a time Data must be maintained in separate arrays or SPU must shuffle vecacross data into a parallel array form Consider unrolling affects when picking SIMD strategy 29

30 SIMD Example 30
31 Load / Store by Quadword Scalar loads and stores are slow, with long latency. SPUs only support quadword loads and stores. Consider making scalars into quadword integer vectors. Load or store scalar arrays as quadwords, and perform your own extraction and insertion to eliminate load and store instructions. 31
32 SIMD Programming Tips 32
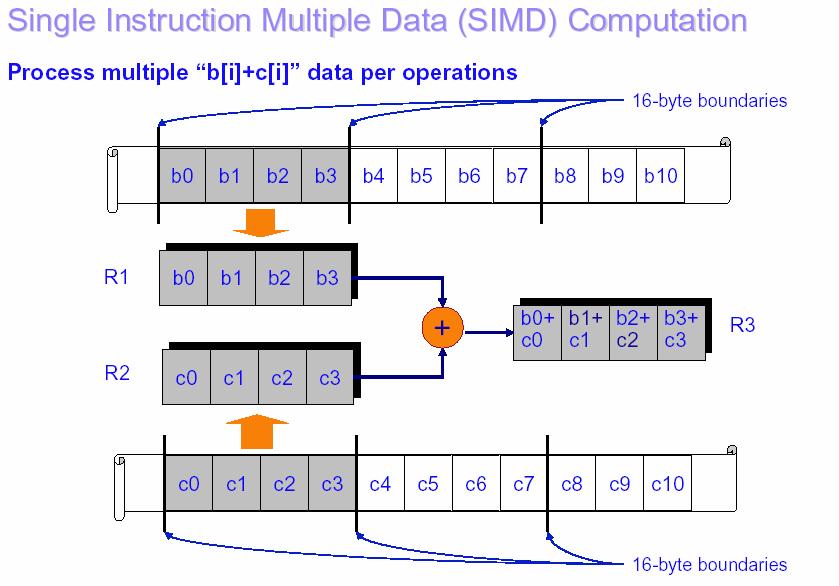
33 33
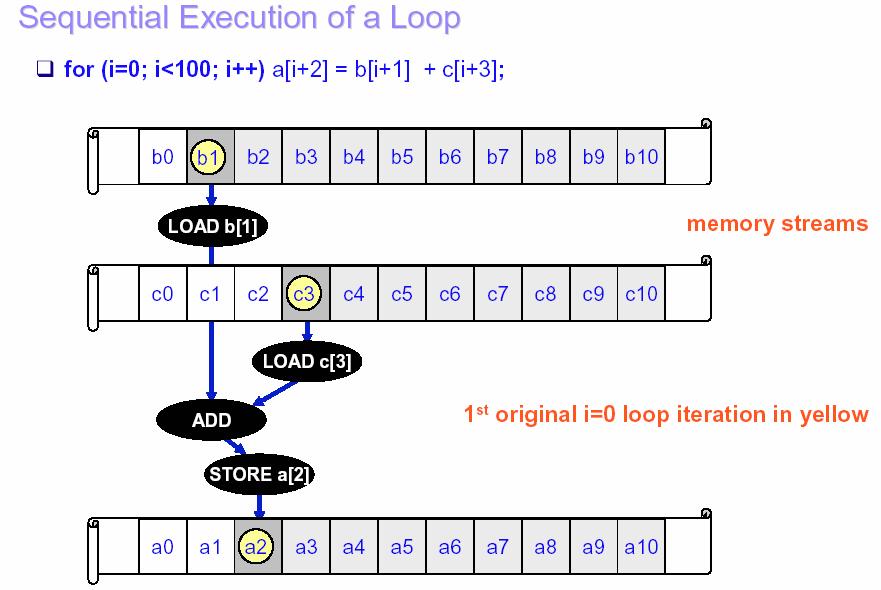
34 34
35 35
36 36
37 37
38 38
39 39
40 40
41 Use Offset Pointer Use the PPE s load/store with update instructions. These allow sequential indexing through an array without the need of additional instructions to increment the array pointer. For the SPEs (which do not support load/store with update instructions), use the d-form instructions to specify an immediate offset from a base array pointer For example, consider the following PPE code that exploits the PowerPC store with update instruction: #define FILL_VEC_FLOAT(_q, _data) *(vector float)(_q++) = _data; FILL_VEC_FLOAT(q, x); FILL_VEC_FLOAT(q, y); FILL_VEC_FLOAT(q, z); FILL_VEC_FLOAT(q, w); The same code can be modified for SPU execution as follows: #define FILL_VEC_FLOAT(_q, _offset, _data) *(vector float)(_q+(_offset)) = _data; FILL_VEC_FLOAT(q, 0, x); FILL_VEC_FLOAT(q, 1, y); FILL_VEC_FLOAT(q, 2, z); FILL_VEC_FLOAT(q, 3, w); q += 4; 41
42 Shuffle byte instructions for table look-ups 42
43 (c) Copyright International Business Machines Corporation All Rights Reserved. Printed in the United Sates September The following are trademarks of International Business Machines Corporation in the United States, or other countries, or both. IBM IBM Logo Power Architecture Other company, product and service names may be trademarks or service marks of others. All information contained in this document is subject to change without notice. The products described in this document are NOT intended for use in applications such as implantation, life support, or other hazardous uses where malfunction could result in death, bodily injury, or catastrophic property damage. The information contained in this document does not affect or change IBM product specifications or warranties. Nothing in this document shall operate as an express or implied license or indemnity under the intellectual property rights of IBM or third parties. All information contained in this document was obtained in specific environments, and is presented as an illustration. The results obtained in other operating environments may vary. While the information contained herein is believed to be accurate, such information is preliminary, and should not be relied upon for accuracy or completeness, and no representations or warranties of accuracy or completeness are made. THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN "AS IS" BASIS. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained in this document. IBM Microelectronics Division The IBM home page is Route 52, Bldg. 504 The IBM Microelectronics Division home page is Hopewell Junction, NY
Developing Code for Cell - Mailboxes
 Developing Code for Cell - Mailboxes Course Code: L3T2H1-55 Cell Ecosystem Solutions Enablement 1 Course Objectives Things you will learn Cell communication mechanisms mailboxes (this course) and DMA (another
Developing Code for Cell - Mailboxes Course Code: L3T2H1-55 Cell Ecosystem Solutions Enablement 1 Course Objectives Things you will learn Cell communication mechanisms mailboxes (this course) and DMA (another
Exercise Euler Particle System Simulation
 Exercise Euler Particle System Simulation Course Code: L3T2H1-57 Cell Ecosystem Solutions Enablement 1 Course Objectives The student should get ideas of how to get in welldefined steps from scalar code
Exercise Euler Particle System Simulation Course Code: L3T2H1-57 Cell Ecosystem Solutions Enablement 1 Course Objectives The student should get ideas of how to get in welldefined steps from scalar code
After a Cell Broadband Engine program executes without errors on the PPE and the SPEs, optimization through parameter-tuning can begin.
 Performance Main topics: Performance analysis Performance issues Static analysis of SPE threads Dynamic analysis of SPE threads Optimizations Static analysis of optimization Dynamic analysis of optimizations
Performance Main topics: Performance analysis Performance issues Static analysis of SPE threads Dynamic analysis of SPE threads Optimizations Static analysis of optimization Dynamic analysis of optimizations
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors
 PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
Hands-on - DMA Transfer Using Control Block
 IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using Control Block Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class Objectives
IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using Control Block Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class Objectives
Hello World! Course Code: L2T2H1-10 Cell Ecosystem Solutions Enablement. Systems and Technology Group
 Hello World! Course Code: L2T2H1-10 Cell Ecosystem Solutions Enablement 1 Course Objectives You will learn how to write, build and run Hello World! on the Cell System Simulator. There are three different
Hello World! Course Code: L2T2H1-10 Cell Ecosystem Solutions Enablement 1 Course Objectives You will learn how to write, build and run Hello World! on the Cell System Simulator. There are three different
Programming for Performance on the Cell BE processor & Experiences at SSSU. Sri Sathya Sai University
 Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Programming for Performance on the Cell BE processor & Experiences at SSSU Sri Sathya Sai University THE STI CELL PROCESSOR The Inevitable Shift to the era of Multi-Core Computing The 9-core Cell Microprocessor
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP
 Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Optimizing Data Sharing and Address Translation for the Cell BE Heterogeneous CMP Michael Gschwind IBM T.J. Watson Research Center Cell Design Goals Provide the platform for the future of computing 10
Cell Broadband Engine Architecture. Version 1.02
 Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005, 2007 All Rights Reserved Printed in the United States
Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005, 2007 All Rights Reserved Printed in the United States
A Transport Kernel on the Cell Broadband Engine
 A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
A Transport Kernel on the Cell Broadband Engine Paul Henning Los Alamos National Laboratory LA-UR 06-7280 Cell Chip Overview Cell Broadband Engine * (Cell BE) Developed under Sony-Toshiba-IBM efforts Current
The network interface configuration property screens can be accessed by double clicking the network icon in the Windows Control Panel.
 Introduction The complete instructions for setting up the PowerPC 750FX Evaluation Kit are provided in the PowerPC 750FX Evaluation Board User's Manual which can be found on the 750FX Evaluation Kit CD.
Introduction The complete instructions for setting up the PowerPC 750FX Evaluation Kit are provided in the PowerPC 750FX Evaluation Board User's Manual which can be found on the 750FX Evaluation Kit CD.
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Crypto On the Playstation 3
 Crypto On the Playstation 3 Neil Costigan School of Computing, DCU. neil.costigan@computing.dcu.ie +353.1.700.6916 PhD student / 2 nd year of research. Supervisor : - Dr Michael Scott. IRCSET funded. Playstation
Crypto On the Playstation 3 Neil Costigan School of Computing, DCU. neil.costigan@computing.dcu.ie +353.1.700.6916 PhD student / 2 nd year of research. Supervisor : - Dr Michael Scott. IRCSET funded. Playstation
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Cell Broadband Engine Architecture. Version 1.0
 Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005 All Rights Reserved Printed in the United States of America
Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005 All Rights Reserved Printed in the United States of America
CISC 879 Software Support for Multicore Architectures Spring Student Presentation 6: April 8. Presenter: Pujan Kafle, Deephan Mohan
 CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
Concurrent Programming with the Cell Processor. Dietmar Kühl Bloomberg L.P.
 Concurrent Programming with the Cell Processor Dietmar Kühl Bloomberg L.P. dietmar.kuehl@gmail.com Copyright Notice 2009 Bloomberg L.P. Permission is granted to copy, distribute, and display this material,
Concurrent Programming with the Cell Processor Dietmar Kühl Bloomberg L.P. dietmar.kuehl@gmail.com Copyright Notice 2009 Bloomberg L.P. Permission is granted to copy, distribute, and display this material,
Introduction to PCI Express Positioning Information
 Introduction to PCI Express Positioning Information Main PCI Express is the latest development in PCI to support adapters and devices. The technology is aimed at multiple market segments, meaning that
Introduction to PCI Express Positioning Information Main PCI Express is the latest development in PCI to support adapters and devices. The technology is aimed at multiple market segments, meaning that
Cell SDK and Best Practices
 Cell SDK and Best Practices Stefan Lutz Florian Braune Hardware-Software-Co-Design Universität Erlangen-Nürnberg siflbrau@mb.stud.uni-erlangen.de Stefan.b.lutz@mb.stud.uni-erlangen.de 1 Overview - Introduction
Cell SDK and Best Practices Stefan Lutz Florian Braune Hardware-Software-Co-Design Universität Erlangen-Nürnberg siflbrau@mb.stud.uni-erlangen.de Stefan.b.lutz@mb.stud.uni-erlangen.de 1 Overview - Introduction
Chapter 13 Reduced Instruction Set Computers
 Chapter 13 Reduced Instruction Set Computers Contents Instruction execution characteristics Use of a large register file Compiler-based register optimization Reduced instruction set architecture RISC pipelining
Chapter 13 Reduced Instruction Set Computers Contents Instruction execution characteristics Use of a large register file Compiler-based register optimization Reduced instruction set architecture RISC pipelining
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Cell Programming Tutorial JHD
 Cell Programming Tutorial Jeff Derby, Senior Technical Staff Member, IBM Corporation Outline 2 Program structure PPE code and SPE code SIMD and vectorization Communication between processing elements DMA,
Cell Programming Tutorial Jeff Derby, Senior Technical Staff Member, IBM Corporation Outline 2 Program structure PPE code and SPE code SIMD and vectorization Communication between processing elements DMA,
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Hands-on - DMA Transfer Using get and put Buffer
 IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using get and put Buffer Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class
IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using get and put Buffer Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class
RISC & Superscalar. COMP 212 Computer Organization & Architecture. COMP 212 Fall Lecture 12. Instruction Pipeline no hazard.
 COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
OpenMP on the IBM Cell BE PRACE Barcelona Supercomputing Center (BSC) 21-23 October 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software Cache transformations
Cell Broadband Engine Overview
 Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
Cell Broadband Engine Overview Course Code: L1T1H1-02 Cell Ecosystem Solutions Enablement 1 Class Objectives Things you will learn An overview of Cell history Cell microprocessor highlights Hardware architecture
Hands-on - DMA Transfer Using get Buffer
 IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using get Buffer Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class Objectives
IBM Systems & Technology Group Cell/Quasar Ecosystem & Solutions Enablement Hands-on - DMA Transfer Using get Buffer Cell Programming Workshop Cell/Quasar Ecosystem & Solutions Enablement 1 Class Objectives
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II John Wawrzynek Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~johnw
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
Synergistic Processor Unit Instruction Set Architecture. Title Page. Version 1.0
 Instruction Set Architecture Title Page Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005 All Rights Reserved
Instruction Set Architecture Title Page Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2005 All Rights Reserved
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007
 CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
Chapter 11. Instruction Sets: Addressing Modes and Formats. Yonsei University
 Chapter 11 Instruction Sets: Addressing Modes and Formats Contents Addressing Pentium and PowerPC Addressing Modes Instruction Formats Pentium and PowerPC Instruction Formats 11-2 Common Addressing Techniques
Chapter 11 Instruction Sets: Addressing Modes and Formats Contents Addressing Pentium and PowerPC Addressing Modes Instruction Formats Pentium and PowerPC Instruction Formats 11-2 Common Addressing Techniques
Synergistic Processor Unit Instruction Set Architecture. Title Page. Version 1.2
 Instruction Set Architecture Title Page Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2006, 2007 All Rights
Instruction Set Architecture Title Page Copyright and Disclaimer Copyright International Business Machines Corporation, Sony Computer Entertainment Incorporated, Toshiba Corporation 2006, 2007 All Rights
CS450/650 Notes Winter 2013 A Morton. Superscalar Pipelines
 CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
CS450/650 Notes Winter 2013 A Morton Superscalar Pipelines 1 Scalar Pipeline Limitations (Shen + Lipasti 4.1) 1. Bounded Performance P = 1 T = IC CPI 1 cycletime = IPC frequency IC IPC = instructions per
GM8126 I2C. User Guide Rev.: 1.0 Issue Date: December 2010
 GM8126 I2C User Guide Rev.: 1.0 Issue Date: December 2010 REVISION HISTORY Date Rev. From To Dec. 2010 1.0 - Original Copyright 2010 Grain Media, Inc. All Rights Reserved. Printed in Taiwan 2010 Grain
GM8126 I2C User Guide Rev.: 1.0 Issue Date: December 2010 REVISION HISTORY Date Rev. From To Dec. 2010 1.0 - Original Copyright 2010 Grain Media, Inc. All Rights Reserved. Printed in Taiwan 2010 Grain
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
IBM Research Report. Optimizing the Use of Static Buffers for DMA on a CELL Chip
 RC2421 (W68-35) August 8, 26 Computer Science IBM Research Report Optimizing the Use of Static Buffers for DMA on a CELL Chip Tong Chen, Zehra Sura, Kathryn O'Brien, Kevin O'Brien IBM Research Division
RC2421 (W68-35) August 8, 26 Computer Science IBM Research Report Optimizing the Use of Static Buffers for DMA on a CELL Chip Tong Chen, Zehra Sura, Kathryn O'Brien, Kevin O'Brien IBM Research Division
Computer and Hardware Architecture I. Benny Thörnberg Associate Professor in Electronics
 Computer and Hardware Architecture I Benny Thörnberg Associate Professor in Electronics Hardware architecture Computer architecture The functionality of a modern computer is so complex that no human can
Computer and Hardware Architecture I Benny Thörnberg Associate Professor in Electronics Hardware architecture Computer architecture The functionality of a modern computer is so complex that no human can
Computer System Architecture Final Examination Spring 2002
 Computer System Architecture 6.823 Final Examination Spring 2002 Name: This is an open book, open notes exam. 180 Minutes 22 Pages Notes: Not all questions are of equal difficulty, so look over the entire
Computer System Architecture 6.823 Final Examination Spring 2002 Name: This is an open book, open notes exam. 180 Minutes 22 Pages Notes: Not all questions are of equal difficulty, so look over the entire
High Performance Computing: Tools and Applications
 High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 8 Processor-level SIMD SIMD instructions can perform
High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 8 Processor-level SIMD SIMD instructions can perform
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Floating Point/Multicycle Pipelining in DLX
 Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
( ZIH ) Center for Information Services and High Performance Computing. Overvi ew over the x86 Processor Architecture
 Center for Information Services and High Performance Computing. Overvi ew over the x86 Processor Architecture") ( ZIH ) Center for Information Services and High Performance Computing Overvi ew over the x86 Processor Architecture Daniel Molka Ulf Markwardt Daniel.Molka@tu-dresden.de ulf.markwardt@tu-dresden.de Outline
( ZIH ) Center for Information Services and High Performance Computing Overvi ew over the x86 Processor Architecture Daniel Molka Ulf Markwardt Daniel.Molka@tu-dresden.de ulf.markwardt@tu-dresden.de Outline
04 - DSP Architecture and Microarchitecture
 September 11, 2015 Memory indirect addressing (continued from last lecture) ; Reality check: Data hazards! ; Assembler code v3: repeat 256,endloop load r0,dm1[dm0[ptr0++]] store DM0[ptr1++],r0 endloop:
September 11, 2015 Memory indirect addressing (continued from last lecture) ; Reality check: Data hazards! ; Assembler code v3: repeat 256,endloop load r0,dm1[dm0[ptr0++]] store DM0[ptr1++],r0 endloop:
MIT OpenCourseWare Multicore Programming Primer, January (IAP) Please use the following citation format:
 Please use the following citation format:") MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: David Zhang, 6.189 Multicore Programming Primer, January (IAP) 2007.
MIT OpenCourseWare http://ocw.mit.edu 6.189 Multicore Programming Primer, January (IAP) 2007 Please use the following citation format: David Zhang, 6.189 Multicore Programming Primer, January (IAP) 2007.
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
AMD Opteron TM & PGI: Enabling the Worlds Fastest LS-DYNA Performance
 3. LS-DY Anwenderforum, Bamberg 2004 CAE / IT II AMD Opteron TM & PGI: Enabling the Worlds Fastest LS-DY Performance Tim Wilkens Ph.D. Member of Technical Staff tim.wilkens@amd.com October 4, 2004 Computation
3. LS-DY Anwenderforum, Bamberg 2004 CAE / IT II AMD Opteron TM & PGI: Enabling the Worlds Fastest LS-DY Performance Tim Wilkens Ph.D. Member of Technical Staff tim.wilkens@amd.com October 4, 2004 Computation
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
Multi-core processors are here, but how do you resolve data bottlenecks in native code?
 Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
Multi-core processors are here, but how do you resolve data bottlenecks in native code? hint: it s all about locality Michael Wall October, 2008 part I of II: System memory 2 PDC 2008 October 2008 Session
DK2. Handel-C code optimization
 DK2 Handel-C code optimization Celoxica, the Celoxica logo and Handel-C are trademarks of Celoxica Limited. All other products or services mentioned herein may be trademarks of their respective owners.
DK2 Handel-C code optimization Celoxica, the Celoxica logo and Handel-C are trademarks of Celoxica Limited. All other products or services mentioned herein may be trademarks of their respective owners.
Evaluating the Portability of UPC to the Cell Broadband Engine
 Evaluating the Portability of UPC to the Cell Broadband Engine Dipl. Inform. Ruben Niederhagen JSC Cell Meeting CHAIR FOR OPERATING SYSTEMS Outline Introduction UPC Cell UPC on Cell Mapping Compiler and
Evaluating the Portability of UPC to the Cell Broadband Engine Dipl. Inform. Ruben Niederhagen JSC Cell Meeting CHAIR FOR OPERATING SYSTEMS Outline Introduction UPC Cell UPC on Cell Mapping Compiler and
SUPERSCALAR AND VLIW PROCESSORS
 Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
Datorarkitektur I Fö 10-1 Datorarkitektur I Fö 10-2 What is a Superscalar Architecture? SUPERSCALAR AND VLIW PROCESSORS A superscalar architecture is one in which several instructions can be initiated
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 13 Memory Part 2
 ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ECE 552 / CPS 550 Advanced Computer Architecture I Lecture 13 Memory Part 2 Benjamin Lee Electrical and Computer Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Computer Architecture and Organization. Instruction Sets: Addressing Modes and Formats
 Computer Architecture and Organization Instruction Sets: Addressing Modes and Formats Addressing Modes Immediate Direct Indirect Register Register Indirect Displacement (Indexed) Stack Immediate Addressing
Computer Architecture and Organization Instruction Sets: Addressing Modes and Formats Addressing Modes Immediate Direct Indirect Register Register Indirect Displacement (Indexed) Stack Immediate Addressing
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
SIMD Exploitation in (JIT) Compilers
 Compilers") SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
1. PowerPC 970MP Overview
 1. The IBM PowerPC 970MP reduced instruction set computer (RISC) microprocessor is an implementation of the PowerPC Architecture. This chapter provides an overview of the features of the 970MP microprocessor
1. The IBM PowerPC 970MP reduced instruction set computer (RISC) microprocessor is an implementation of the PowerPC Architecture. This chapter provides an overview of the features of the 970MP microprocessor
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Lecture 10: Static ILP Basics. Topics: loop unrolling, static branch prediction, VLIW (Sections )
") Lecture 10: Static ILP Basics Topics: loop unrolling, static branch prediction, VLIW (Sections 4.1 4.4) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
Lecture 10: Static ILP Basics Topics: loop unrolling, static branch prediction, VLIW (Sections 4.1 4.4) 1 Static vs Dynamic Scheduling Arguments against dynamic scheduling: requires complex structures
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
COSC 6385 Computer Architecture - Memory Hierarchy Design (III)
") COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
PS3 programming basics. Week 1. SIMD programming on PPE Materials are adapted from the textbook
 PS3 programming basics Week 1. SIMD programming on PPE Materials are adapted from the textbook Overview of the Cell Architecture XIO: Rambus Extreme Data Rate (XDR) I/O (XIO) memory channels The PowerPC
PS3 programming basics Week 1. SIMD programming on PPE Materials are adapted from the textbook Overview of the Cell Architecture XIO: Rambus Extreme Data Rate (XDR) I/O (XIO) memory channels The PowerPC
Compilation for Heterogeneous Platforms
 Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Compilation for Heterogeneous Platforms Grid in a Box and on a Chip Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/heterogeneous.pdf Senior Researchers Ken Kennedy John Mellor-Crummey
Cache Memory COE 403. Computer Architecture Prof. Muhamed Mudawar. Computer Engineering Department King Fahd University of Petroleum and Minerals
 Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Cache Memory COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline The Need for Cache Memory The Basics
Topics to be covered. EEC 581 Computer Architecture. Virtual Memory. Memory Hierarchy Design (II)
") EEC 581 Computer Architecture Memory Hierarchy Design (II) Department of Electrical Engineering and Computer Science Cleveland State University Topics to be covered Cache Penalty Reduction Techniques Victim
EEC 581 Computer Architecture Memory Hierarchy Design (II) Department of Electrical Engineering and Computer Science Cleveland State University Topics to be covered Cache Penalty Reduction Techniques Victim
Computer Architecture and Engineering. CS152 Quiz #5. April 23rd, Professor Krste Asanovic. Name: Answer Key
 Computer Architecture and Engineering CS152 Quiz #5 April 23rd, 2009 Professor Krste Asanovic Name: Answer Key Notes: This is a closed book, closed notes exam. 80 Minutes 8 Pages Not all questions are
Computer Architecture and Engineering CS152 Quiz #5 April 23rd, 2009 Professor Krste Asanovic Name: Answer Key Notes: This is a closed book, closed notes exam. 80 Minutes 8 Pages Not all questions are
This section covers the MIPS instruction set.
 This section covers the MIPS instruction set. 1 + I am going to break down the instructions into two types. + a machine instruction which is directly defined in the MIPS architecture and has a one to one
This section covers the MIPS instruction set. 1 + I am going to break down the instructions into two types. + a machine instruction which is directly defined in the MIPS architecture and has a one to one
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Advanced optimizations of cache performance ( 2.2)
") Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 14 Instruction Level Parallelism and Superscalar Processors
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
William Stallings Computer Organization and Architecture 8 th Edition Chapter 14 Instruction Level Parallelism and Superscalar Processors What is Superscalar? Common instructions (arithmetic, load/store,
Software Development Kit for Multicore Acceleration Version 3.0
 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Software Development Kit for Multicore Acceleration Version 3.0 Programming Tutorial SC33-8410-00 Note
OpenMP on the IBM Cell BE
 OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
OpenMP on the IBM Cell BE 15th meeting of ScicomP Barcelona Supercomputing Center (BSC) May 18-22 2009 Marc Gonzalez Tallada Index OpenMP programming and code transformations Tiling and Software cache
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
HY425 Lecture 09: Software to exploit ILP
 HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 ILP techniques Hardware Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit
HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 ILP techniques Hardware Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
CS 152 Computer Architecture and Engineering. Lecture 8 - Memory Hierarchy-III
 CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 8 - Memory Hierarchy-III Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
William Stallings Computer Organization and Architecture 8 th Edition. Chapter 11 Instruction Sets: Addressing Modes and Formats
 William Stallings Computer Organization and Architecture 8 th Edition Chapter 11 Instruction Sets: Addressing Modes and Formats Addressing Modes Immediate Direct Indirect Register Register Indirect Displacement
William Stallings Computer Organization and Architecture 8 th Edition Chapter 11 Instruction Sets: Addressing Modes and Formats Addressing Modes Immediate Direct Indirect Register Register Indirect Displacement
Why memory hierarchy? Memory hierarchy. Memory hierarchy goals. CS2410: Computer Architecture. L1 cache design. Sangyeun Cho
 Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
Why memory hierarchy? L1 cache design Sangyeun Cho Computer Science Department Memory hierarchy Memory hierarchy goals Smaller Faster More expensive per byte CPU Regs L1 cache L2 cache SRAM SRAM To provide
HY425 Lecture 09: Software to exploit ILP
 HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit ILP 1 / 44 ILP techniques
HY425 Lecture 09: Software to exploit ILP Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS November 4, 2010 Dimitrios S. Nikolopoulos HY425 Lecture 09: Software to exploit ILP 1 / 44 ILP techniques
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer