CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
|
|
|
- Alannah Daniel
- 5 years ago
- Views:
Transcription
1 CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
2 Administrivia PS5 is out PS4 due on Wednesday Lab 4 Quiz 4 on Monday April 11th 2
3 Vector Programming Model Scalar Registers r15 v15 Vector Registers r0 v0 [0] [1] [2] [VLRMAX-1] Vector Arithmetic Instructions ADDV v3, v1, v2 v1 v2 v3 Vector Length Register VLR [0] [1] [VLR-1] Vector Load and Store Instructions LV v1, r1, r2 v1 Vector Register Base, r1 Stride, r2 Memory 3
4 Vector Stripmining Problem: Vector registers have finite length Solution: Break loops into pieces that fit in registers, Stripmining for (i=0; i<n; i++) C[i] = A[i]+B[i]; A B C + Remainder + 64 elements + 4
5 Vector Conditional Execution Problem: Want to vectorize loops with conditional code: for (i=0; i<n; i++) if (A[i]>0) then A[i] = B[i]; Solution: Add vector mask (or flag) registers vector version of predicate registers, 1 bit per element and maskable vector instructions vector operation becomes bubble ( NOP ) at elements where mask bit is clear Code example: CVM LV va, ra # Turn on all elements # Load entire A vector SGTVS.D va, F0 # Set bits in mask register where A>0 LV va, rb SV va, ra # Load B vector into A under mask # Store A back to memory under mask 5
6 Masked Vector Instructions Simple Implementation execute all N operations, turn off result writeback according to mask Density-Time Implementation scan mask vector and only execute elements with non-zero masks M[7]=1 A[7] B[7] M[7]=1 M[6]=0 M[5]=1 A[6] A[5] B[6] B[5] M[6]=0 M[5]=1 A[7] B[7] M[4]=1 M[3]=0 A[4] A[3] B[4] B[3] M[4]=1 M[3]=0 C[5] M[2]=0 C[4] M[2]=0 M[1]=1 C[2] C[1] M[1]=1 M[0]=0 C[1] Write data port M[0]=0 C[0] Write Enable Write data port 6
7 Vector Reductions Problem: Loop-carried dependence on reduction variables sum = 0; for (i=0; i<n; i++) sum += A[i]; # Loop-carried dependence on sum Solution: Re-associate operations if possible, use binary tree to perform reduction # Rearrange as: sum[0:vl-1] = 0 # Vector of VL partial sums for(i=0; i<n; i+=vl) # Stripmine VL-sized chunks sum[0:vl-1] += A[i:i+VL-1]; # Vector sum # Now have VL partial sums in one vector register do { VL = VL/2; # Halve vector length sum[0:vl-1] += sum[vl:2*vl-1] # Halve no. of partials } while (VL>1) 7
8 Vector Scatter/Gather Want to vectorize loops with indirect accesses: for (i=0; i<n; i++) A[i] = B[i] + C[D[i]] Indexed load instruction (Gather) LV vd, rd # Load indices in D vector LVI vc, rc, vd # Load indirect from rc base LV vb, rb # Load B vector ADDV.D va,vb,vc # Do add SV va, ra # Store result 8
9 Multimedia Extensions (aka SIMD extensions) 32b 64b 32b 16b 16b 16b 16b 8b 8b 8b 8b 8b 8b 8b 8b Very short vectors added to existing ISAs for microprocessors Use existing 64-bit registers split into 2x32b or 4x16b or 8x8b Lincoln Labs TX-2 from 1957 had 36b datapath split into 2x18b or 4x9b Newer designs have wider registers 128b for PowerPC Altivec, Intel SSE2/3/4 256b for Intel AVX Single instruction operates on all elements within register 16b 16b 16b 16b 16b 16b 16b 16b 4x16b adds b 16b 16b 16b 11
10 Multimedia Extensions versus Vectors Limited instruction set: no vector length control no strided load/store or scatter/gather unit-stride loads must be aligned to 64/128-bit boundary Limited vector register length: requires superscalar dispatch to keep multiply/add/load units busy loop unrolling to hide latencies increases register pressure Trend towards fuller vector support in microprocessors Better support for misaligned memory accesses Support of double-precision (64-bit floating-point) New Intel AVX spec (announced April 2008), 256b vector registers (expandable up to 1024b) 12

11 Degree of Vectorization MIPS processor with vector coprocessor Compilers are good at finding data-level parallelism 13
12 Types of Parallelism Instruction-Level Parallelism (ILP) Execute independent instructions from one instruction stream in parallel (pipelining, superscalar, VLIW) Thread-Level Parallelism (TLP) Execute independent instruction streams in parallel (multithreading, multiple cores) Data-Level Parallelism (DLP) Execute multiple operations of the same type in parallel (vector/simd execution) Which is easiest to program? Which is most flexible form of parallelism? i.e., can be used in more situations Which is most efficient? i.e., greatest tasks/second/area, lowest energy/task 15
 are most efficient way to execute these algorithms")
13 Resurgence of DLP Convergence of application demands and technology constraints drives architecture choice New applications, such as graphics, machine vision, speech recognition, machine learning, etc. all require large numerical computations that are often trivially data parallel SIMD-based architectures (vector-simd, subword-simd, SIMT/GPUs) are most efficient way to execute these algorithms 16
14 DLP important for conventional CPUs too Prediction for x86 processors, from Hennessy & Patterson, 5 th edition Note: Educated guess, not Intel product plans! TLP: 2+ cores / 2 years DLP: 2x width / 4 years DLP will account for more mainstream parallelism growth than TLP in next decade. SIMD single-instruction multiple-data (DLP) MIMD- multiple-instruction multiple-data (TLP) 17
15 Graphics Processing Units (GPUs) Original GPUs were dedicated fixed-function devices for generating 3D graphics (mid-late 1990s) including highperformance floating-point units Provide workstation-like graphics for PCs User could configure graphics pipeline, but not really program it Over time, more programmability added ( ) E.g., New language Cg for writing small programs run on each vertex or each pixel, also Windows DirectX variants Massively parallel (millions of vertices or pixels per frame) but very constrained programming model Some users noticed they could do general-purpose computation by mapping input and output data to images, and computation to vertex and pixel shading computations Incredibly difficult programming model as had to use graphics pipeline model for general computation 18
16 General-Purpose GPUs (GP-GPUs) In 2006, Nvidia introduced GeForce 8800 GPU supporting a new programming language: CUDA Compute Unified Device Architecture Subsequently, broader industry pushing for OpenCL, a vendor-neutral version of same ideas. Idea: Take advantage of GPU computational performance and memory bandwidth to accelerate some kernels for generalpurpose computing Attached processor model: Host CPU issues data-parallel kernels to GP-GPU for execution This lecture has a simplified version of Nvidia CUDA-style model and only considers GPU execution for computational kernels, not graphics Would probably need another course to describe graphics processing 19
17 Simplified CUDA Programming Model Computation performed by a very large number of independent small scalar threads (CUDA threads or microthreads) grouped into thread blocks. // C version of DAXPY loop. void daxpy(int n, double a, double*x, double*y) { for (int i=0; i<n; i++) y[i] = a*x[i] + y[i]; } // CUDA version. host // Piece run on host processor. int nblocks = (n+255)/256; // 256 CUDA threads/block daxpy<<<nblocks,256>>>(n,2.0,x,y); device // Piece run on GP-GPU. void daxpy(int n, double a, double*x, double*y) { int i = blockidx.x*blockdim.x + threadid.x; if (i<n) y[i]=a*x[i]+y[i]; } 20
18 Programmer s View of Execution blockidx 0 threadid 0 threadid 1 threadid 255 blockdim = 256 (programmer can choose) Create enough blocks to cover input vector blockidx 1 threadid 0 threadid 1 threadid 255 (Nvidia calls this ensemble of blocks a Grid, can be 2-dimensional) blockidx (n+255/256) threadid 0 threadid 1 threadid 255 Conditional (i<n) turns off unused threads in last block 21
19 Hardware Execution Model CPU Lane 0 Lane 1 Lane 0 Lane 1 Lane 0 Lane 1 CPU Memory Lane 15 Core 0 Lane 15 Core 1 GPU Lane 15 Core 15 GPU Memory GPU is built from multiple parallel cores, each core contains a multithreaded SIMD processor with multiple lanes but with no scalar processor CPU sends whole grid over to GPU, which distributes thread blocks among cores (each thread block executes on one core) Programmer unaware of number of cores 22
20 Single Instruction, Multiple Thread GPUs use a SIMT model (SIMD with multithreading) Individual scalar instruction streams for each CUDA thread are grouped together for SIMD execution (each thread executes the same instruction each cycle) on hardware (Nvidia groups 32 CUDA threads into a warp). Threads are independent from each other Scalar instruction stream ld x mul a ld y add st y µt0 µt1 µt2 µt3 µt4 µt5 µt6 µt7 SIMD execution across warp 23
21 Implications of SIMT Model All vector loads and stores are scatter-gather, as individual µthreads perform scalar loads and stores GPU adds hardware to dynamically coalesce individual µthread loads and stores to mimic vector loads and stores Every µthread has to perform stripmining calculations redundantly ( am I active? ) as there is no scalar processor equivalent 24
22 Conditionals in SIMT model Simple if-then-else are compiled into predicated execution, equivalent to vector masking More complex control flow compiled into branches How to execute a vector of branches? Scalar instruction stream tid=threadid If (tid >= n) skip Call func1 add st y skip: µt0 µt1 µt2 µt3 µt4 µt5 µt6 µt7 SIMD execution across warp 25

23 Branch divergence Hardware tracks which µthreads take or don t take branch If all go the same way, then keep going in SIMD fashion If not, create mask vector indicating taken/not-taken Keep executing not-taken path under mask, push taken branch PC+mask onto a hardware stack and execute later When can execution of µthreads in warp reconverge? 26
 A single thread block can contain multiple warps (up to 512 µt max in CUDA), all mapped to single core Can have multiple blocks executing on one core [Nvidia, 2010]")
24 Warps are multithreaded on core One warp of 32 µthreads is a single thread in the hardware Multiple warp threads are interleaved in execution on a single core to hide latencies (memory and functional unit) A single thread block can contain multiple warps (up to 512 µt max in CUDA), all mapped to single core Can have multiple blocks executing on one core [Nvidia, 2010] 27

25 GPU Memory Hierarchy [ Nvidia, 2010] 28
26 SIMT Illusion of many independent threads Threads inside a warp execute in a SIMD fashion But for efficiency, programmer must try and keep µthreads aligned in a SIMD fashion Try and do unit-stride loads and store so memory coalescing kicks in Avoid branch divergence so most instruction slots execute useful work and are not masked off 29

27 Nvidia Fermi GF100 GPU [Nvidia, 2010] 30

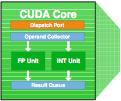
28 Fermi Streaming Multiprocessor Core 31

29 GPU Versus CPU 35
30 Why? Need to understand the difference Latency intolerance versus latency tolerance Task parallelism versus data parallelism Multithreaded cores versus SIMT cores 10s of threads versus thousands of threads CPUs: low latency, low throughput GPUs: high latency, high throughput GPUs are designed for tasks that tolerate latency 36

31 What About Caches? GPUs can have more ALUs in the same area and therefore run more threads of computation 37
32 GPU Future High-end desktops have separate GPU chip, but trend towards integrating GPU on same die as CPU (already in laptops, tablets and smartphones) Advantage is shared memory with CPU, no need to transfer data Disadvantage is reduced memory bandwidth compared to dedicated smaller-capacity specialized memory system Graphics DRAM (GDDR) versus regular DRAM (DDR3) Will GP-GPU survive? Or will improvements in CPU DLP make GP-GPU redundant? On same die, CPU and GPU should have same memory bandwidth GPU might have more FLOPS as needed for graphics anyway 38
33 Acknowledgements These slides contain material developed and copyright by: Krste Asanovic (UCB) Mohamed Zahran (NYU) An introduction to modern GPU architecture. Ashu Rege. NVIDIA. 39
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs)
") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering. Lecture 16: Graphics Processing Units (GPUs) John Wawrzynek. EECS, University of California at Berkeley
 John Wawrzynek. EECS, University of California at Berkeley") CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia Lab
CS 152 Computer Architecture and Engineering Lecture 16: Graphics Processing Units (GPUs) John Wawrzynek EECS, University of California at Berkeley http://inst.eecs.berkeley.edu/~cs152 Administrivia Lab
Vector Processors and Graphics Processing Units (GPUs)
") Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
Vector Processors and Graphics Processing Units (GPUs) Many slides from: Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley TA Evaluations Please fill out your
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher
 Lecture 30: GP-GPU Programming. Lecturer: Alan Christopher") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 30: GP-GPU Programming Lecturer: Alan Christopher Overview GP-GPU: What and why OpenCL, CUDA, and programming GPUs GPU Performance
Programmer's View of Execution Teminology Summary
 CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 152 Computer Architecture and Engineering. Lecture 17: Vector Computers
 CS 152 Computer Architecture and Engineering Lecture 17: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 17: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 252 Graduate Computer Architecture. Lecture 7: Vector Computers
 CS 252 Graduate Computer Architecture Lecture 7: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
CS 252 Graduate Computer Architecture Lecture 7: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste http://inst.cs.berkeley.edu/~cs252
Asanovic/Devadas Spring Vector Computers. Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology
 Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Flynn s Classification (1966)
") COEN-4730 Computer Architecture Lecture 9 Intro to Graphics Processing Units (GPUs) Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
COEN-4730 Computer Architecture Lecture 9 Intro to Graphics Processing Units (GPUs) Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15: Dataflow
Computer Architecture: SIMD and GPUs (Part I) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 15: Dataflow
Motivation: Who Cares About I/O? Historical Perspective. Hard Disk Drives. CS252 Graduate Computer Architecture Lecture 25
 CS252 Graduate Computer Architecture Lecture 25 Disks and Queueing Theory GPUs April 25 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley Motivation:
CS252 Graduate Computer Architecture Lecture 25 Disks and Queueing Theory GPUs April 25 th, 2011 John Kubiatowicz Electrical Engineering and Computer Sciences University of California, Berkeley Motivation:
Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors)
") 18-447 Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors) Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/24/2014 Lab 4 Reminder Lab 4a out Branch handling and branch
18-447 Computer Architecture Lecture 16: SIMD Processing (Vector and Array Processors) Prof. Onur Mutlu Carnegie Mellon University Spring 2014, 2/24/2014 Lab 4 Reminder Lab 4a out Branch handling and branch
Computer Architecture and Engineering. CS152 Quiz #5. April 23rd, Professor Krste Asanovic. Name: Answer Key
 Computer Architecture and Engineering CS152 Quiz #5 April 23rd, 2009 Professor Krste Asanovic Name: Answer Key Notes: This is a closed book, closed notes exam. 80 Minutes 8 Pages Not all questions are
Computer Architecture and Engineering CS152 Quiz #5 April 23rd, 2009 Professor Krste Asanovic Name: Answer Key Notes: This is a closed book, closed notes exam. 80 Minutes 8 Pages Not all questions are
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Computer Architecture: SIMD and GPUs (Part II) Prof. Onur Mutlu Carnegie Mellon University
 Prof. Onur Mutlu Carnegie Mellon University") Computer Architecture: SIMD and GPUs (Part II) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 19: SIMD
Computer Architecture: SIMD and GPUs (Part II) Prof. Onur Mutlu Carnegie Mellon University A Note on This Lecture These slides are partly from 18-447 Spring 2013, Computer Architecture, Lecture 19: SIMD
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. Lecture 15 Vectors
 CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 15 Vectors Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering CS252 Graduate Computer Architecture Lecture 15 Vectors Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
Arquitetura e Organização de Computadores 2
 Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
Arquitetura e Organização de Computadores 2 Paralelismo em Nível de Dados Graphical Processing Units - GPUs Graphical Processing Units Given the hardware invested to do graphics well, how can be supplement
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES
 UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
UNIT III DATA-LEVEL PARALLELISM IN VECTOR, SIMD, AND GPU ARCHITECTURES Flynn s Taxonomy Single instruction stream, single data stream (SISD) Single instruction stream, multiple data streams (SIMD) o Vector
Chapter 4 Data-Level Parallelism
 CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
06-2 EE Lecture Transparency. Formatted 14:50, 4 December 1998 from lsli
 06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Static Compiler Optimization Techniques
 Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
CS252 Graduate Computer Architecture Spring 2014 Lecture 8: Vector Supercomputers
 CS252 Graduate Computer Architecture Spring 2014 Lecture 8: Vector Supercomputers Krste Asanovic krste@eecs.berkeley.edu http://inst.eecs.berkeley.edu/~cs252/sp14 Last Time in Lecture 6 Overcoming the
CS252 Graduate Computer Architecture Spring 2014 Lecture 8: Vector Supercomputers Krste Asanovic krste@eecs.berkeley.edu http://inst.eecs.berkeley.edu/~cs252/sp14 Last Time in Lecture 6 Overcoming the
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 5B: Data Level Parallelism Avinash Kodi, kodi@ohio.edu Thanks to Morgan Kauffman and Krtse Asanovic Agenda 2 Flynn s Classification Data Level Parallelism Vector
Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model
 Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
Lecture 21: Data Level Parallelism -- SIMD ISA Extensions for Multimedia and Roofline Performance Model CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong
Design of Digital Circuits Lecture 20: SIMD Processors. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 20: SIMD Processors Prof. Onur Mutlu ETH Zurich Spring 2017 11 May 2017 Agenda for Today & Next Few Lectures! Single-cycle Microarchitectures! Multi-cycle and Microprogrammed
Design of Digital Circuits Lecture 20: SIMD Processors Prof. Onur Mutlu ETH Zurich Spring 2017 11 May 2017 Agenda for Today & Next Few Lectures! Single-cycle Microarchitectures! Multi-cycle and Microprogrammed
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
ESE 545 Computer Architecture. Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing
, Vector Processing and Single-Instruction Multiple Data (SIMD) Computing") Computer Architecture ESE 545 Computer Architecture Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing 1 Supercomputers Definition of a supercomputer:
Computer Architecture ESE 545 Computer Architecture Data Level Parallelism (DLP), Vector Processing and Single-Instruction Multiple Data (SIMD) Computing 1 Supercomputers Definition of a supercomputer:
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
CS 152 Computer Architecture and Engineering. Lecture 16: Vector Computers
 CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Data-Level Parallelism in SIMD and Vector Architectures. Advanced Computer Architectures, Laura Pozzi & Cristina Silvano
 Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
Data-Level Parallelism in SIMD and Vector Architectures Advanced Computer Architectures, Laura Pozzi & Cristina Silvano 1 Current Trends in Architecture Cannot continue to leverage Instruction-Level parallelism
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. Parallel Processors from Client to Cloud Part 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 1 Parallel Processor Architecture: SMT, VECTOR, SIMD Performance beyond
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Part 1 Parallel Processor Architecture: SMT, VECTOR, SIMD Performance beyond
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović
 Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions are
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2011 Professor Krste Asanović Name: This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions are
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
GPUs have enormous power that is enormously difficult to use
 524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Data-Parallel Architectures
 Data-Parallel Architectures Nima Honarmand Overview Data-Level Parallelism (DLP) vs. Thread-Level Parallelism (TLP) In DLP, parallelism arises from independent execution of the same code on a large number
Data-Parallel Architectures Nima Honarmand Overview Data-Level Parallelism (DLP) vs. Thread-Level Parallelism (TLP) In DLP, parallelism arises from independent execution of the same code on a large number
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
COSC 6385 Computer Architecture. - Vector Processors
 COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
COSC 6385 Computer Architecture - Vector Processors Spring 011 Vector Processors Chapter F of the 4 th edition (Chapter G of the 3 rd edition) Available in CD attached to the book Anybody having problems
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
Fundamentals of Computers Design
 Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
ILP Limit: Perfect/Infinite Hardware. Chapter 3: Limits of Instr Level Parallelism. ILP Limit: see Figure in book. Narrow Window Size
 Chapter 3: Limits of Instr Level Parallelism Ultimately, how much instruction level parallelism is there? Consider study by Wall (summarized in H & P) First, assume perfect/infinite hardware Then successively
Chapter 3: Limits of Instr Level Parallelism Ultimately, how much instruction level parallelism is there? Consider study by Wall (summarized in H & P) First, assume perfect/infinite hardware Then successively
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
CE 431 Parallel Computer Architecture Spring Graphics Processor Units (GPU) Architecture
 Architecture") CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
CE 431 Parallel Computer Architecture Spring 2017 Graphics Processor Units (GPU) Architecture Nikos Bellas Computer and Communications Engineering Department University of Thessaly Some slides borrowed
Handout 3. HSAIL and A SIMT GPU Simulator
 Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
332 Advanced Computer Architecture Chapter 7
 332 Advanced Computer Architecture Chapter 7 Data-Level Parallelism Architectures and Programs March 2017 Luigi Nardi These lecture notes are partly based on: lecture slides from Paul H. J. Kelly (CO332/2013-2014)
332 Advanced Computer Architecture Chapter 7 Data-Level Parallelism Architectures and Programs March 2017 Luigi Nardi These lecture notes are partly based on: lecture slides from Paul H. J. Kelly (CO332/2013-2014)
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
CS 152, Spring 2011 Section 10
 CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
CS 152, Spring 2011 Section 10 Christopher Celio University of California, Berkeley Agenda Stuff (Quiz 4 Prep) http://3dimensionaljigsaw.wordpress.com/2008/06/18/physics-based-games-the-new-genre/ Intel
Data-Level Parallelism
 Fall 2015 :: CSE 610 Parallel Computer Architectures Data-Level Parallelism Nima Honarmand Fall 2015 :: CSE 610 Parallel Computer Architectures Overview Data Parallelism vs. Control Parallelism Data Parallelism:
Fall 2015 :: CSE 610 Parallel Computer Architectures Data-Level Parallelism Nima Honarmand Fall 2015 :: CSE 610 Parallel Computer Architectures Overview Data Parallelism vs. Control Parallelism Data Parallelism:
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
! An alternate classification. Introduction. ! Vector architectures (slides 5 to 18) ! SIMD & extensions (slides 19 to 23)
 ! SIMD & extensions (slides 19 to 23)") Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
Master Informatics Eng. Advanced Architectures 2015/16 A.J.Proença Data Parallelism 1 (vector, SIMD ext., GPU) (most slides are borrowed) Instruction and Data Streams An alternate classification Instruction
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2012 Professor Krste Asanović
 Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2012 Professor Krste Asanović Name: ANSWER SOLUTIONS This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions
Computer Architecture and Engineering CS152 Quiz #4 April 11th, 2012 Professor Krste Asanović Name: ANSWER SOLUTIONS This is a closed book, closed notes exam. 80 Minutes 17 Pages Notes: Not all questions
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Parallel Processing SIMD, Vector and GPU s
 Parallel Processing SIMD, Vector and GPU s EECS4201 Fall 2016 York University 1 Introduction Vector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating on Single Data
Parallel Processing SIMD, Vector and GPU s EECS4201 Fall 2016 York University 1 Introduction Vector and array processors Chaining GPU 2 Flynn s taxonomy SISD: Single instruction operating on Single Data
CS 152 Computer Architecture and Engineering. Lecture 7 - Memory Hierarchy-II
 CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 7 - Memory Hierarchy-II Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley http://www.eecs.berkeley.edu/~krste
CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines Assigned April 7 Problem Set #5 Due April 21 http://inst.eecs.berkeley.edu/~cs152/sp09 The problem sets are intended
CS152 Computer Architecture and Engineering VLIW, Vector, and Multithreaded Machines Assigned April 7 Problem Set #5 Due April 21 http://inst.eecs.berkeley.edu/~cs152/sp09 The problem sets are intended
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 152 Computer Architecture and Engineering. Lecture 12 - Advanced Out-of-Order Superscalars
 CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 152 Computer Architecture and Engineering Lecture 12 - Advanced Out-of-Order Superscalars Dr. George Michelogiannakis EECS, University of California at Berkeley CRD, Lawrence Berkeley National Laboratory
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Vector Processors. Kavitha Chandrasekar Sreesudhan Ramkumar
 Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007
 CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
CS 352H Computer Systems Architecture Exam #1 - Prof. Keckler October 11, 2007 Name: Solutions (please print) 1-3. 11 points 4. 7 points 5. 7 points 6. 20 points 7. 30 points 8. 25 points Total (105 pts):
GPU Microarchitecture Note Set 2 Cores
 2 co 1 2 co 1 GPU Microarchitecture Note Set 2 Cores Quick Assembly Language Review Pipelined Floating-Point Functional Unit (FP FU) Typical CPU Statically Scheduled Scalar Core Typical CPU Statically
2 co 1 2 co 1 GPU Microarchitecture Note Set 2 Cores Quick Assembly Language Review Pipelined Floating-Point Functional Unit (FP FU) Typical CPU Statically Scheduled Scalar Core Typical CPU Statically
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8