Les dernières générations chez NVIDIA :
|
|
|
- Kimberly Dorsey
- 5 years ago
- Views:
Transcription

1 Les dernières générations chez NVIDIA : NVIDIA Tesla Update Supercomputing 12 Journée cartes graphiques et calcul Sumit Gupta intensif Observatoire Midi-Pyrénées General Manager Tesla Accelerated Computing TOULOUSE 17 avril 2013 Accélérateurs Tesla K20 et K20X. François Courteille, NVIDIA, Paris, France (fcourteille@nvidia.com) 1

2 François Courteille Solutions Nvidia since address : fcourteille@nvidia.com 33 years of experience in HPC Experience Summary NEC CONVEX EVANS & SUTHERLAND CONTROL DATA - ETA
3 OUTLINE NVIDIA and GPU Computing GTC 2013 & Roadmaps Inside Kepler Architecture SXM Hyper-Q Dynamic Parallelism Programming GPUs The Software Ecosystem OpenACC Libraries Languages and Frameworks CUDA 5 Nsight for Linux & Mac GPU Direct RDMA Library Object Linking (separate compilation & linking) 3





4 NVIDIA - Core Technologies and Brands GPU Mobile Cloud GeForce Quadro, Tesla Founded 1993 Tegra Invented GPU 1999 Computer Graphics VGX GeForce GRID 4

5 In 2013 GTC did expand GTC 2013 Developer / Compute HPC / Supercomputing Graphics Life Science Oil & Gas Finance Manufacturing CAE / CAD / Styling / Design Large Venue Visualization M&E Animation / Editing / Rendering Cloud Graphics Mobile App & Game Development PC Game Development 5

6 GTC 2013 Announcements GPU Roadmap NV Blog ZDNet Kayla: ARM + CUDA Platform NV Blog AnandTech Big Data Analytics NV Press Release The Register CUDA Python NV Press Release AnandTech OpenACC 2.0 Draft Spec HPCWire CSCS Supercomputer NV Blog HPCWire 6

7 DP GFLOPS per Watt Tesla CUDA Architecture Roadmap Kepler Dynamic Parallelism Maxwell Unified Virtual Memory Volta Stacked DRAM 2 Fermi FP Tesla CUDA
8 Performance 100 Tegra Roadmap Parker Denver CPU Maxwell GPU FinFET 10 Tegra 4 1st LTE SDR Modem Computational Camera Logan Kepler GPU CUDA OpenGL 4.3 Tegra 3 1st Quad A9 1st Power-Saver Core 1 1st Dual A9 Tegra





9 9

10 Kepler GPU Fastest, Most Efficient HPC Architecture Ever SMX 3x Performance per Watt Hyper-Q Dynamic Parallelism Easy Speed-up for Legacy MPI Apps Parallel Programming Made Easier than Ever 10


 CFD, FEA, Finance,")
11 Tesla K10 Tesla K20 3x Single Precision 3x Double Precision 1.8x Memory Bandwidth Hyper-Q, Dynamic Parallelism Image, Signal, Seismic, Life Sci (MD) CFD, FEA, Finance, Physics 11
 1.")

12 TFLOPS Tesla K20 Family: 3x Faster Than Fermi Tesla K20X Tesla K20X Tesla K20 # CUDA Cores Peak Double Precision Peak DGEMM 1.32 TF 1.22 TF 1.17 TF 1.10 TF 1.25 Double Precision FLOPS (DGEMM) 1.22 TFLOPS Peak Single Precision Peak SGEMM 3.95 TF 2.90 TF 3.52 TF 2.61 TF TFLOPS.43 TFLOPS Xeon E Tesla M2090 Tesla K20X Memory Bandwidth 250 GB/s 208 GB/s Memory size 6 GB 5 GB Total Board Power 235W 225W 12

13 Up to 10x on Leading Applications Speedup vs. Dual Socket CPUs 20.0x Performance Across Science Domains 15.0x 10.0x 5.0x 0.0x WL-LSMS- Material Science Chroma- Physics SPECFEM3D- Earth Sciences AMBER- Molecular Dynamics 1xCPU + 1xM2090 1xCPU + 1xK20X CPU: E5-2687w 3.10 GHz Sandy 13 Bridge

14 Titan: World s Fastest Supercomputer 18,688 Tesla K20X GPUs 27 Petaflops Peak: 90% of Performance from GPUs Petaflops Sustained Performance on Linpack 14




15 GPU Test Drive Double your Fermi Performance with Kepler GPUs
16 Tesla K20/K20X Details 16


17 Whitepaper: 17

18 Kepler GK110 Block Diagram Architecture 7.1B Transistors 15 SMX units > 1 TFLOP FP MB L2 Cache 384-bit GDDR5 PCI Express Gen2/Gen3 18


19 Kepler GK110 SMX vs Fermi SM 19
20 SMX Balance of Resources Resource Kepler GK110 vs Fermi Floating point throughput 2-3x Max Blocks per SMX 2x Max Threads per SMX 1.3x Register File Bandwidth Register File Capacity Shared Memory Bandwidth Shared Memory Capacity 2x 2x 2x 1x 20
21 Hyper-Q CPU Cores Simultaneously Run Tasks on Kepler FERMI 1 MPI Task at a Time KEPLER 32 Simultaneous MPI Tasks 21
22 GPU Utilization % GPU Utilization % Hyper-Q Max GPU Utilization, Slashes CPU Idle Time Time 0 Time 22
23 Example: Hyper-Q/Proxy for CP2K 23
24 Dynamic Parallelism GPU Adapts to Data, Dynamically Launches New Threads CPU Fermi GPU CPU Kepler GPU 24
25 CUDA Dynamic Parallelism Kernel launches grids Identical syntax as host CUDA runtime function in cudadevrt library global void childkernel() { printf("hello %d", threadidx.x); } global void parentkernel() { childkernel<<<1,10>>>(); cudadevicesynchronize(); printf("world!\n"); } int main(int argc, char *argv[]) { parentkernel<<<1,1>>>(); cudadevicesynchronize(); return 0; } 25
26 CUDA Dynamic Parallelism and Programmer Productivity 26

27 Dynamic Work Generation Fixed Grid Statically assign conservative worst-case grid Dynamically assign performance where accuracy is required Initial Grid Dynamic Grid 27
28 Nested Parallelism Made Possible Serial Program for i = 1 to N for j = 1 to x[i] convolution(i, j) next j next i CUDA Program global void convolution(int x[]) { for j = 1 to x[blockidx] kernel<<<... >>>(blockidx, j) } N convolution<<< N, 1 >>>(x); Now Possible: Dynamic Parallelism 28
29 GPU Management: nvidia-smi Multi-GPU systems are widely available Different systems are set up differently Want to get quick information on - Approximate GPU utilization - Approximate memory footprint - Number of GPUs - ECC state - Driver version Thu Nov 1 09:10: NVIDIA-SMI Driver Version: GPU Name Bus-Id Disp. Volatile Uncorr. ECC Fan Temp Perf Pwr:Usage/Cap Memory-Usage GPU-Util Compute M. ===============================+======================+====================== 0 Tesla K20X 0000:03:00.0 Off Off N/A 30C P8 28W / 235W 0% 12MB / 6143MB 0% Default Tesla K20X 0000:85:00.0 Off Off N/A 28C P8 26W / 235W 0% 12MB / 6143MB 0% Default Compute processes: GPU Memory GPU PID Process name Usage ============================================================================= No running compute processes found Inspect and modify GPU state 29

30 OpenGL and Tesla Tesla K20/K20X for high performance Compute Tesla K20/K20X for Graphics and Compute Use interop to mix OpenGL and Compute Tesla K20 / K20X 30


31 CUDA Accelerating Key Apps # of Apps % Increase 61% Increase Top Supercomputing Apps Computational Chemistry Material Science Climate & Weather Physics CAE AMBER CHARMM GROMACS QMCPACK Quantum Espresso GAMESS COSMO GEOS-5 Chroma Denovo GTC ANSYS Mechanical MSC Nastran SIMULIA Abaqus Accelerated, In Development LAMMPS NAMD DL_POLY Gaussian NWChem VASP CAM-SE NIM WRF GTS ENZO MILC ANSYS Fluent OpenFOAM LS-DYNA 31
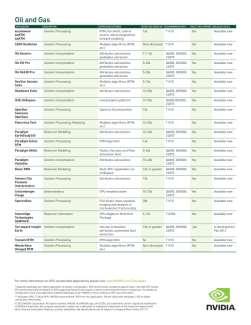

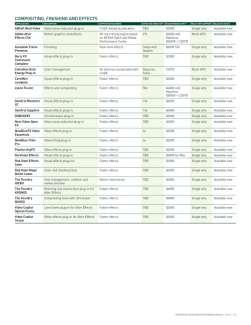
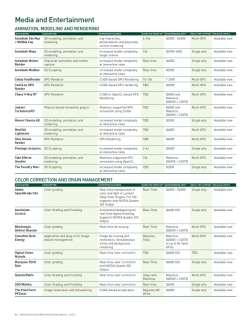
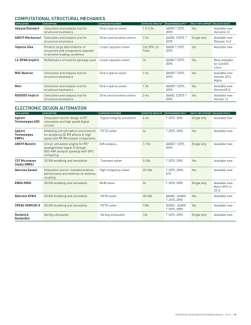
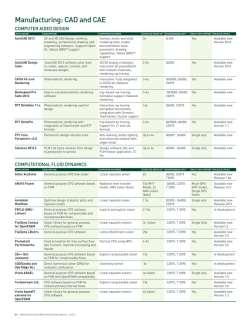
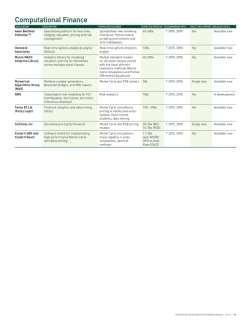





32 200+ GPU-Accelerated Applications 32
33 33




34 Accelerated Computing 10x Performance, 5x Energy Efficiency CPU Optimized for Serial Tasks GPU Accelerator Optimized for Many Parallel Tasks 34

35 Small Changes, Big Speed-up Application Code GPU Compute-Intensive Functions Use GPU to Parallelize Rest of Sequential CPU Code CPU + 35
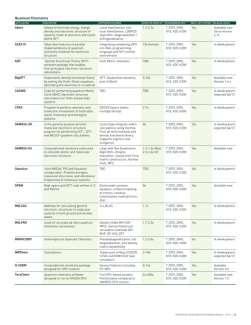
36 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives (OpenACC) Directives Programming Languages (CUDA,..) High Level Languages (Matlab,..) CUDA Libraries are interoperable with OpenACC CUDA Language is interoperable with OpenACC Easiest Approach Maximum Performance No Need for Programming Expertise 36



37 OpenACC Directives CPU GPU Simple Compiler hints Program myscience... serial code...!$acc kernels do k = 1,n1 do i = 1,n2... parallel code... enddo enddo!$acc end kernels... Your original End Program myscience Fortran or C code OpenACC Compiler Hint Compiler Parallelizes code Works on many-core GPUs & multicore CPUs 37

38 OpenACC The Standard for GPU Directives Easy: Directives are the easy path to accelerate compute intensive applications Open: OpenACC is an open GPU directives standard, making GPU programming straightforward and portable across parallel and multi-core processors Powerful: GPU Directives allow complete access to the massive parallel power of a GPU 38
39 Familiar to OpenMP Programmers OpenMP OpenACC CPU CPU GPU main() { double pi = 0.0; long i; main() { double pi = 0.0; long i; #pragma omp parallel for reduction(+:pi) for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); } printf( pi = %f\n, pi/n); } #pragma acc kernels for (i=0; i<n; i++) { double t = (double)((i+0.05)/n); pi += 4.0/(1.0+t*t); } printf( pi = %f\n, pi/n); } 39

40 Small Effort. Real Impact. Large Oil Company Univ. of Houston Uni. Of Melbourne Ufa State Aviation GAMESS-UK Prof. M.A. Kayali Prof. Kerry Black Prof. Arthur Dr. Wilkinson, 3x in 7 days 20x in 2 days 65x in 2 days Yuldashev Prof. Naidoo Solving billions of equations iteratively for oil production at world s largest petroleum reservoirs Studying magnetic systems for innovations in magnetic storage media and memory, field sensors, and Better understand complex reasons by lifecycles of snapper fish in Port Phillip Bay 7x in 4 Weeks Generating stochastic geological models of oilfield reservoirs with borehole data 10x Used for various fields such as investigating biofuel production and molecular sensors. 40
41 Example: Jacobi Iteration Iteratively converges to correct value (e.g. Temperature), by computing new values at each point from the average of neighboring points. Common, useful algorithm Example: Solve Laplace equation in 2D: 2 f(x, y) = 0 A(i,j+1) A(i-1,j) A(i,j) A(i+1,j) A k+1 i, j = A k(i 1, j) + A k i + 1, j + A k i, j 1 + A k i, j A(i,j-1) 41
42 Jacobi Iteration Fortran Code do while ( err > tol.and. iter < iter_max ) err=0._fp_kind Iterate until converged do j=1,m do i=1,n Anew(i,j) =.25_fp_kind * (A(i+1, j ) + A(i-1, j ) + & A(i, j-1) + A(i, j+1)) err = max(err, Anew(i,j) - A(i,j)) end do end do do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do iter = iter +1 end do Iterate across matrix elements Calculate new value from neighbors Compute max error for convergence Swap input/output arrays 42
 =.25_fp_kind * (A(i+1, j ) + A(i-1, j ) + & A(i, j-1) + A(i, j+1)) err = max(err, Anew(i,j) - A(i,j)) end do end do!")
43 Jacobi Iteration: OpenACC Fortran Code!$acc data copy(a), create(anew) do while ( err > tol.and. iter < iter_max ) err=0._fp_kind Copy A in at beginning of loop, out at end. Allocate Anew on accelerator!$acc kernels do j=1,m do i=1,n Anew(i,j) =.25_fp_kind * (A(i+1, j ) + A(i-1, j ) + & A(i, j-1) + A(i, j+1)) err = max(err, Anew(i,j) - A(i,j)) end do end do!$acc end kernels... iter = iter +1 end do!$acc end data 43
44 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration Easily Accelerate Applications Maximum Flexibility 44
45 Libraries: Easy, High-Quality Acceleration Ease of use: Drop-in : Quality: Performance: Using libraries enables GPU acceleration without in-depth knowledge of GPU programming Many GPU-accelerated libraries follow standard APIs, thus enabling acceleration with minimal code changes Libraries offer high-quality implementations of functions encountered in a broad range of applications NVIDIA libraries are tuned by experts 45


46 Some GPU-accelerated Libraries NVIDIA cublas NVIDIA curand NVIDIA cusparse NVIDIA NPP Vector Signal Image Processing GPU Accelerated Linear Algebra Matrix Algebra on GPU and Multicore NVIDIA cufft IMSL Library ArrayFire Building-block Matrix Algorithms Computations for CUDA Sparse Linear Algebra C++ STL Features for CUDA 46

47 Explore the CUDA (Libraries) Ecosystem CUDA Tools and Ecosystem described in detail on NVIDIA Developer Zone: developer.nvidia.com/cuda-toolsecosystem 47
48 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration Easily Accelerate Applications Maximum Flexibility 48
49 GPU Programming Languages Numerical analytics MATLAB, Mathematica, LabVIEW Fortran OpenACC, CUDA Fortran C OpenACC, CUDA C C++ Thrust, CUDA C++ Python C# PyCUDA, Copperhead, NumbaPro (Continuum Analytics) GPU.NET, Hybridizer(AltiMesh) 49
50 Advanced MRI Reconstruction Cartesian Scan Data ky Gridding kx ky (b) Spiral Scan Data ky kx (a) (b) kx (c) FFT Spiral scan data + Iterative reconstruction Reconstruction requires a lot of computation Iterative Reconstruction 50
51 Advanced MRI Reconstruction ( F H H F W W) F H d Acquire Data Compute Q More than 99.5% of time Compute F H d Find ρ Haldar, et al, Anatomically-constrained reconstruction from noisy data, MR in Medicine. 51
52 Code CPU for (p = 0; p < nump; p++) { for (d = 0; d < numd; d++) { exp = 2*PI*(kx[d] * x[p] + ky[d] * y[p] + kz[d] * z[p]); carg = cos(exp); sarg = sin(exp); rfhd[p] += rrho[d]*carg irho[d]*sarg; ifhd[p] += irho[d]*carg + rrho[d]*sarg; } } global void cmpfhd(float* gx, gy, gz, grfhd, gifhd) { int p = blockidx.x * THREADS_PB + threadidx.x; } GPU // register allocate image-space inputs & outputs x = gx[p]; y = gy[p]; z = gz[p]; rfhd = grfhd[p]; ifhd = gifhd[p]; for (int d = 0; d < SCAN_PTS_PER_TILE; d++) { // s (scan data) is held in constant memory float exp = 2 * PI * (s[d].kx * x + s[d].ky * y + s[d].kz * z); carg = cos(exp); sarg = sin(exp); rfhd += s[d].rrho*carg s[d].irho*sarg; ifhd += s[d].irho*carg + s[d].rrho*sarg; } grfhd[p] = rfhd; gifhd[p] = ifhd; 52
53 S.S. Stone, et al, Accelerating Advanced MRI Reconstruction using GPUs, ACM Computing Frontier Conference 2008, Italy, May
54 Get Started Today These languages are supported on all CUDA-capable GPUs. You might already have a CUDA-capable GPU in your laptop or desktop PC! CUDA C/C++ GPU.NET Thrust C++ Template Library CUDA Fortran PyCUDA (Python) MATLAB matlab-gpu.html Mathematica -in-8/cuda-and-opencl-support/ 54

55 Easiest Way to Learn CUDA 50k Enrolled 127 Countries Learn from the Best Prof. John Owens UC Davis Dr. David Luebke NVIDIA Research Prof. Wen-mei W. Hwu U of Illinois Heterogeneous Parallel Programming Anywhere, Any Time Online Worldwide Self Paced $$ It s Free! No Tuition No Hardware No Books Introduction to Parallel Programming Engage with an Active Community Forums and Meetups Hands-on Projects 55
![Where to find additional information CUDA documentation [1] - Best Practice Guide [2] - Kepler Tuning Guide [3] Kepler whitepaper [4] [1] http://docs.nvidia.](/docs-images/87/96002917/images/56-2.jpg "com [2] http://docs.nvidia.com/cuda/cuda-c-best-practices-guide [3] http://docs.nvidia.com/cuda/kepler-tuning-guide [4] http://www.nvidia.com/object/nvidia-kepler.")
56 Where to find additional information CUDA documentation [1] - Best Practice Guide [2] - Kepler Tuning Guide [3] Kepler whitepaper [4] [1] [2] [3] [4] 56
57 57
58 CUDA Progress Compiler Tool Chain NVCC Templates Inheritance Recursion Function pointers LLVM C++ new/delete Virtual functions Device Code Linking Programming Languages C Fortran (PGI) C++ UVA OpenACC Dynamic Parallelism Platform Libraries cublas cufft NVPP GPUDirect cusparse curand Thrust GPU-Aware MPI new NVPP functions cublas Device API Developer Tools Command- Line Profiler cuda-gdb Visual Profiler cuda-memcheck nvidia-smi Nsight IDE New Visual Profiler Nsight Eclipse Ed. Detect Shared Memory Hazards
59 CUDA 5 Nsight for Linux & Mac NVIDIA GPUDirect Library Object Linking 59



")
60 NVIDIA Nsight for Linux & Mac (and Windows of course) 60


61 Kepler Enables Full NVIDIA GPUDirect System Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory System Memory CPU GPU1 GPU2 GPU2 GPU1 CPU PCI-e Network Card Network Network Card PCI-e Server 1 Server 2 61

62 GPUDirect enables GPU-aware MPI GPU-GPU transfer across NIC Without CPU participation Unified Virtual addresses allows to detect location of buffer pointed to 62
63 GPUDirect enables GPU-aware MPI cudamemcpy(s_buf_h,s_buf_d,size,cudamemcpydevicetohost); MPI_Send(s_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD); MPI_Recv(r_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD); cudamemcpy(r_buf_h,r_buf_d,size,cudamemcpyhosttodevice); Simplifies to MPI_Send(s_buf,size,MPI_CHAR,1,100,MPI_COMM_WORLD); MPI_Recv(r_buf,size,MPI_CHAR,1,100,MPI_COMM_WORLD); (for CPU and GPU buffers) 63

64 3 rd Party GPU Library Object Linking Rest of C Application CUDA C/C++ Code Library Vendor CUDA C/C++ Library Code CPU Object Files CUDA Object Files CUDA Library CPU-GPU Executable GPU Code 3rd Party Library Code 64





65 The Era of Accelerated Computing is Here Era of Accelerated Computing Era of Vector Computing Era of Distributed Computing


66 Making a Difference


67 MATLAB Life Sciences R&D MATLAB PCT & MDCS 67
68 MATLAB Parallel Computing Toolbox Industry standard high-level language for algorithm development & data analysis GPU Value Allows practical analysis of large datasets for the first time Scales from GPU workstations (Parallel Computing Toolbox) up to GPU clusters (MATLAB Distributed Computing Server) Significant acceleration for spectral analysis, linear algebra, and stochastic simulations, etc. Highlights GPU accelerated native MATLAB operations Integration with user CUDA kernels in MATLAB MATLAB Compiler support (GPU acceleration without MATLAB) 68



69 MATLAB Parallel Computing On-ramp to GPU Computing MATLAB R2012b Over 200 of the most popular MATLAB functions on GPUs Including: Random number generation FFT Matrix multiplications Solvers Convolutions Min/max SVD Cholesky and LU factorization MATLAB Compiler support (GPU acceleration without MATLAB) GPU features in Communications Systems Toolbox Performance enhancements 69

 3x")


 4x speedup in wave equation solving")
70 GPU-Accelerated MATLAB Results 10x speedup in data clustering via K- means clustering algorithm 14x speedup in template matching routine (part of cancer cell image analysis) 3x speedup in estimating 7.6 million contract prices using Black-Scholes model 17x speedup in simulating the movement of 3072 celestial objects 4x speedup in adaptive filtering routine (part of acoustic tracking algorithm) 4x speedup in wave equation solving (part of seismic data processing algorithm) 70


71 GPU Value in MATLAB Bigger is Better Tesla C2075 GeForce GTX 580 GeForce GTX 560 Host CPU Double precision MTimes performance as measured by GPUBench available from MATLAB Central File Exchange 71
NVIDIA : FLOP WARS, ÉPISODE III François Courteille Ecole Polytechnique 4-June-13
 NVIDIA : FLOP WARS, ÉPISODE III François Courteille fcourteille@nvidia.com Ecole Polytechnique 4-June-13 1 OUTLINE NVIDIA and GPU Computing Roadmap Inside Kepler Architecture SXM Hyper-Q Dynamic Parallelism
NVIDIA : FLOP WARS, ÉPISODE III François Courteille fcourteille@nvidia.com Ecole Polytechnique 4-June-13 1 OUTLINE NVIDIA and GPU Computing Roadmap Inside Kepler Architecture SXM Hyper-Q Dynamic Parallelism
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA
 OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
Introduction to GPU Computing. 周国峰 Wuhan University 2017/10/13
 Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
Introduction to GPU Computing chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 GPU and Its Application 3 Ways to Develop Your GPU APP An Example to Show the Developments Add GPUs: Accelerate Science
GPU Computing. Axel Koehler Sr. Solution Architect HPC
 GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator What is CUDA? Programming language? Compiler? Classic car? Beer? Coffee? CUDA Parallel Computing Platform www.nvidia.com/getcuda Programming
Introduction to CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator What is CUDA? Programming language? Compiler? Classic car? Beer? Coffee? CUDA Parallel Computing Platform www.nvidia.com/getcuda Programming
Future Directions for CUDA Presented by Robert Strzodka
 Future Directions for CUDA Presented by Robert Strzodka Authored by Mark Harris NVIDIA Corporation Platform for Parallel Computing Platform The CUDA Platform is a foundation that supports a diverse parallel
Future Directions for CUDA Presented by Robert Strzodka Authored by Mark Harris NVIDIA Corporation Platform for Parallel Computing Platform The CUDA Platform is a foundation that supports a diverse parallel
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing Ecosystem
 GPU Computing Ecosystem CUDA 5 Enterprise level GPU Development GPU Development Paths Libraries, Directives, Languages GPU Tools Tools, libraries and plug-ins for GPU codes Tesla K10 Kepler! Tesla K20
GPU Computing Ecosystem CUDA 5 Enterprise level GPU Development GPU Development Paths Libraries, Directives, Languages GPU Tools Tools, libraries and plug-ins for GPU codes Tesla K10 Kepler! Tesla K20
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
CUDA Update: Present & Future. Mark Ebersole, NVIDIA CUDA Educator
 CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
Kepler Overview Mark Ebersole
 Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
APPROACHES. TO GPU COMPUTING Libraries, OpenACC Directives, and Languages
 APPROACHES TO GPU COMPUTING Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois,
APPROACHES TO GPU COMPUTING Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Science Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois,
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY. Peter Messmer
 NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
OpenACC Course Lecture 1: Introduction to OpenACC September 2015
 OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
OpenACC Course Lecture 1: Introduction to OpenACC September 2015 Course Objective: Enable you to accelerate your applications with OpenACC. 2 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15:
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
CUDA 5 and Beyond. Mark Ebersole. Original Slides: Mark Harris 2012 NVIDIA
 CUDA 5 and Beyond Mark Ebersole Original Slides: Mark Harris The Soul of CUDA The Platform for High Performance Parallel Computing Accessible High Performance Enable Computing Ecosystem Introducing CUDA
CUDA 5 and Beyond Mark Ebersole Original Slides: Mark Harris The Soul of CUDA The Platform for High Performance Parallel Computing Accessible High Performance Enable Computing Ecosystem Introducing CUDA
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC. Jeff Larkin, NVIDIA Developer Technologies
 INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Programming paradigms for GPU devices
 Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC. Authored by Mark Harris NVIDIA Corporation
 GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
GPU ACCELERATED COMPUTING. 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation
 GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
ACCELERATED COMPUTING: THE PATH FORWARD. Jensen Huang, Founder & CEO SC17 Nov. 13, 2017
 ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
NVIDIA TECHNOLOGY Mark Ebersole
 NVIDIA TECHNOLOGY Mark Ebersole ACM Learning Center http://learning.acm.org 1,350+ trusted technical books and videos by leading publishers including O Reilly, Morgan Kaufmann, others Online courses with
NVIDIA TECHNOLOGY Mark Ebersole ACM Learning Center http://learning.acm.org 1,350+ trusted technical books and videos by leading publishers including O Reilly, Morgan Kaufmann, others Online courses with
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies
 Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology
Scaling in a Heterogeneous Environment with GPUs: GPU Architecture, Concepts, and Strategies John E. Stone Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator
 Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
Getting Started with CUDA C/C++ Mark Ebersole, NVIDIA CUDA Educator Heterogeneous Computing CPU GPU Once upon a time Past Massively Parallel Supercomputers Goodyear MPP Thinking Machine MasPar Cray 2 1.31
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU. Peng Wang HPC Developer Technology
 ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
TESLA ACCELERATED COMPUTING. Mike Wang Solutions Architect NVIDIA Australia & NZ
 TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
TESLA ACCELERATED COMPUTING Mike Wang Solutions Architect NVIDIA Australia & NZ mikewang@nvidia.com GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER
Accelerate your Application with Kepler. Peter Messmer
 Accelerate your Application with Kepler Peter Messmer Goals How to analyze/optimize an existing application for GPUs What to consider when designing new GPU applications How to optimize performance with
Accelerate your Application with Kepler Peter Messmer Goals How to analyze/optimize an existing application for GPUs What to consider when designing new GPU applications How to optimize performance with
AXEL KOEHLER GPU Computing Update
 AXEL KOEHLER GPU Computing Update Agenda Introduction GPU Computing Introduction into GPU Programming Kepler GPU Architecture GPU Applications Future Developments 2 NVIDIA: Parallel Computing Company GPUs:
AXEL KOEHLER GPU Computing Update Agenda Introduction GPU Computing Introduction into GPU Programming Kepler GPU Architecture GPU Applications Future Developments 2 NVIDIA: Parallel Computing Company GPUs:
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
High-Productivity CUDA Programming. Levi Barnes, Developer Technology Engineer, NVIDIA
 High-Productivity CUDA Programming Levi Barnes, Developer Technology Engineer, NVIDIA MORE RESOURCES How to learn more GTC -- March 2014 San Jose, CA gputechconf.com Video archives, too Qwiklabs nvlabs.qwiklabs.com
High-Productivity CUDA Programming Levi Barnes, Developer Technology Engineer, NVIDIA MORE RESOURCES How to learn more GTC -- March 2014 San Jose, CA gputechconf.com Video archives, too Qwiklabs nvlabs.qwiklabs.com
High-Productivity CUDA Programming. Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA
 High-Productivity CUDA Programming Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA HIGH-PRODUCTIVITY PROGRAMMING High-Productivity Programming What does this mean? What s the goal? Do Less Work
High-Productivity CUDA Programming Cliff Woolley, Sr. Developer Technology Engineer, NVIDIA HIGH-PRODUCTIVITY PROGRAMMING High-Productivity Programming What does this mean? What s the goal? Do Less Work
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC
 INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
NVIDIA GPUs in Earth System Modelling Thomas Bradley
 NVIDIA GPUs in Earth System Modelling Thomas Bradley Agenda: GPU Developments for CWO Motivation for GPUs in CWO Parallelisation Considerations GPU Technology Roadmap MOTIVATION FOR GPUS IN CWO NVIDIA
NVIDIA GPUs in Earth System Modelling Thomas Bradley Agenda: GPU Developments for CWO Motivation for GPUs in CWO Parallelisation Considerations GPU Technology Roadmap MOTIVATION FOR GPUS IN CWO NVIDIA
NVIDIA GPU Computing Séminaire Calcul Hybride Aristote 25 Mars 2010
 NVIDIA GPU Computing 2010 Séminaire Calcul Hybride Aristote 25 Mars 2010 NVIDIA GPU Computing 2010 Tesla 3 rd generation Full OEM coverage Ecosystem focus Value Propositions per segments Card System Module
NVIDIA GPU Computing 2010 Séminaire Calcul Hybride Aristote 25 Mars 2010 NVIDIA GPU Computing 2010 Tesla 3 rd generation Full OEM coverage Ecosystem focus Value Propositions per segments Card System Module
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
GPU Computing with OpenACC Directives Presented by Bob Crovella. Authored by Mark Harris NVIDIA Corporation
 GPU Computing with OpenACC Directives Presented by Bob Crovella Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities
GPU Computing with OpenACC Directives Presented by Bob Crovella Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
An Introduction to OpenACC - Part 1
 An Introduction to OpenACC - Part 1 Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 01-03, 2015 Outline of today
An Introduction to OpenACC - Part 1 Feng Chen HPC User Services LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 01-03, 2015 Outline of today
OpenACC Fundamentals. Steve Abbott November 13, 2016
 OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC and hyperscale customers deploy accelerated
CSC573: TSHA Introduction to Accelerators
 CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
Introduction to OpenACC. 16 May 2013
 Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Stan Posey, NVIDIA, Santa Clara, CA, USA
 Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
Stan Posey, sposey@nvidia.com NVIDIA, Santa Clara, CA, USA NVIDIA Strategy for CWO Modeling (Since 2010) Initial focus: CUDA applied to climate models and NWP research Opportunities to refactor code with
CUDA 7.5 OVERVIEW WEBINAR 7/23/15
 CUDA 7.5 OVERVIEW WEBINAR 7/23/15 CUDA 7.5 https://developer.nvidia.com/cuda-toolkit 16-bit Floating-Point Storage 2x larger datasets in GPU memory Great for Deep Learning cusparse Dense Matrix * Sparse
CUDA 7.5 OVERVIEW WEBINAR 7/23/15 CUDA 7.5 https://developer.nvidia.com/cuda-toolkit 16-bit Floating-Point Storage 2x larger datasets in GPU memory Great for Deep Learning cusparse Dense Matrix * Sparse
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
The Visual Computing Company
 The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015
 HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Introduction to OpenACC. Shaohao Chen Research Computing Services Information Services and Technology Boston University
 Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPU Programming Introduction
 GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
GPU Programming Introduction DR. CHRISTOPH ANGERER, NVIDIA AGENDA Introduction to Heterogeneous Computing Using Accelerated Libraries GPU Programming Languages Introduction to CUDA Lunch What is Heterogeneous
OpenACC Fundamentals. Steve Abbott November 15, 2017
 OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
GPU ARCHITECTURE Chris Schultz, June 2017
 Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE Problems Solved Over Time versus Why are they different? Complex
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Peter Messmer Developer Technology Group Stan Posey HPC Industry and Applications
 Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
S CUDA on Xavier
 S8868 - CUDA on Xavier Anshuman Bhat CUDA Product Manager Saikat Dasadhikari CUDA Engineering 29 th March 2018 1 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000
S8868 - CUDA on Xavier Anshuman Bhat CUDA Product Manager Saikat Dasadhikari CUDA Engineering 29 th March 2018 1 CUDA ECOSYSTEM 2018 CUDA DOWNLOADS IN 2017 3,500,000 CUDA REGISTERED DEVELOPERS 800,000
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS
 NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
Turing Architecture and CUDA 10 New Features. Minseok Lee, Developer Technology Engineer, NVIDIA
 Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
GPU A rchitectures Architectures Patrick Neill May
 GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
GPU Architectures Patrick Neill May 30, 2014 Outline CPU versus GPU CUDA GPU Why are they different? Terminology Kepler/Maxwell Graphics Tiled deferred rendering Opportunities What skills you should know
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Approaches to GPU Computing. Libraries, OpenACC Directives, and Languages
 Approaches to GPU Computing Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana
Approaches to GPU Computing Libraries, OpenACC Directives, and Languages Add GPUs: Accelerate Applications CPU GPU 146X 36X 18X 50X 100X Medical Imaging U of Utah Molecular Dynamics U of Illinois, Urbana
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Languages, Libraries and Development Tools for GPU Computing
 Languages, Libraries and Development Tools for GPU Computing CPU GPU GPUs have evolved to the point where many real-world applications are easily implemented on them and run significantly faster than on
Languages, Libraries and Development Tools for GPU Computing CPU GPU GPUs have evolved to the point where many real-world applications are easily implemented on them and run significantly faster than on