GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
|
|
|
- Cory Bailey
- 5 years ago
- Views:
Transcription


1 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA





2 GeForce Quadro Tegra Tesla 2






3 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency, lowemision engines. Predictive calculations for thermonuclear and core-collapse supernovae, allowing confirmation of theoretical models. Comprehensive Earth System Model at 1KM scale, enabling modeling of cloud convection and ocean eddies. Coupled simulation of entire cells at molecular, genetic, chemical and biological levels. 3
4 Power Crisis in Supercomputing Exaflop 25,000,000 Watts Petaflop Teraflop 850,000 Watts 8,200,000 Watts Titan K- ORNL Computer 12,600,000 Watts 60,000 Watts Gigaflop


5 Multi-core CPUs Industry has gone multi-core as a first response to power issues Performance through parallelism, not frequency But CPUs are fundamentally designed for single thread performance rather than energy efficiency Fast clock rates with deep pipelines Data and instruction caches optimized for latency Superscalar issue with out-of-order execution Lots of predictions and speculative execution Lots of instruction overhead per operation Less than 2% of chip power today goes to flops. 5


6 Accelerated Computing Add GPUs: Accelerate Applications CPUs: designed to run a few tasks quickly. GPUs: designed to run many tasks efficiently. 6

7 Fixed function hardware Transistors are primarily devoted to data processing Less leaky cache SIMT thread execution Groups of threads formed into warps which always executing same instruction Cooperative sharing of units with SIMT eg. fetch instruction on behalf of several threads or read memory location and broadcast to several registers Lack of speculation reduces overhead Minimal Overhead Energy efficient GPU Performance = Throughput Hardware managed parallel thread execution and handling of divergence 7


8 Supercomputing Weather / Climate Modeling Molecular Dynamics Computational Physics Life Sciences Biochemistry Bioinformatics Material Science Tesla K20/K20X Kepler GK110 Manufacturing Structural Mechanics Comp Fluid Dynamics (CFD) Electromagnetics Defense / Govt Oil and Gas Signal Processing Image Processing Video Analytics Reverse Time Migration Kirchoff Time Migration Tesla K10 Kepler GK104 8

 177.")
9 Tesla K10: 3072 Power-Efficient Cores Product Name M2090 K10 GPU Architecture Fermi Kepler GK104 # of GPUs 1 2 Per GPU Board Single Precision Flops 1.3 TF 2.29 TF 4.58 TF Double Precision Flops 0.66 TF TF TF # CUDA Cores Memory size 6 GB 4GB 8 GB Memory BW (ECC off) GB/s 160GB/s 320 GB/s PCI-Express Gen 2: 8 GB/s Gen 3: 16 GB/s 9


10 Tesla K20X/K20: Same Power, 3x DP Perf of Fermi Product Name M2090 K20 K20X Peak Single Precision Peak SGEMM 1.3 Tflops 0.87 TF 3.52 TF 2.99 TF 3.95 TF 3.35 TF Peak Double Precision Peak DGEMM 0.66 Tflops 0.43 TF 1.17 TF 1.0 TF 1.32 TF 1.12 TF Memory size 6 GB 5 GB 6 GB Memory BW (ECC off) New CUDA Features ECC Features GB/s 208 GB/s 250 GB/s - DRAM, Caches & Reg Files GPUDirect w/ RDMA, Hyper-Q, Dynamic Parallelism DRAM, Caches & Reg Files # CUDA Cores Total Board Power 225W 225W 225W 3x Double Precision Hyper-Q, Dynamic Parallelism CFD, FEA, Finance, Physics 10


11 Kepler GK110 Block Diagram 7.1B Transistors 15 SMX units 1.3 TFLOP FP MB L2 Cache 384-bit GDDR5 PCI Express Gen3 compliant 11
 2x threadblocks (16) & 1.")
12 Kepler GK110 SMX vs Fermi SM 3x sustained perf/w Ground up redesign for perf/w 6x the SP FP units 4x the DP FP units Slower FU clocks ~4x the overall instruction throughput 2x register file size (64K regs) 2x threadblocks (16) & 1.33x threads (2K) 12



13 Speedup vs. Dual CPU FERMI 1 Work Queue Hyper-Q Easier Speedup of Legacy MPI Apps 20x CP2K- Quantum Chemistry Strong Scaling: 864 water molecules 15x 10x 2.5x KEPLER 32 Concurrent Work Queues 5x 0x Number of GPUs K20 with Hyper-Q 16 MPI ranks per node K20 without Hyper-Q 1 MPI rank per node 13
14 What is Dynamic Parallelism? The ability to launch new kernels from the GPU Dynamically - based on run-time data Simultaneously - from multiple threads at once Independently - each thread can launch a different grid CPU GPU CPU GPU Fermi: Only CPU can generate GPU work Kepler: GPU can generate work for itself

15 NVIDIA GPUDirect Support for RDMA Direct Communication Between GPUs and PCIe devices System Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory System Memory CPU GPU1 GPU2 GPU1 GPU2 CPU PCI-e PCI-e Network Card Network Network Card Node 1 Node 2 15



16 Minimum Change, Big Speed-up Application Code GPU Compute-Intensive Functions Rest of Sequential CPU Code CPU + 16
17 Ways to Accelerate Applications Applications Libraries Directives (OpenACC) Programming Languages (CUDA,..) High Level Languages (Matlab,..) CUDA Libraries are interoperable with OpenACC CUDA Language is interoperable with OpenACC Easiest Approach Maximum Performance No Need for Programming Expertise 17


 GPU features")
18 MATLAB Parallel Computing On-ramp to GPU Computing Most popular math functions on GPUs Random number generation FFT Matrix multiplications Solvers Convolutions Min/max SVD Cholesky and LU factorization MATLAB Compiler support (GPU acceleration without MATLAB installed) GPU features in Communications Systems Toolbox 18


19 Wide Adoption of Tesla GPUs Oil and gas Edu/Research Government Life Sciences Finance Manufacturing Reverse Time Migration Kirchoff Time Migration Reservoir Sim Astrophysics Lattice QCD Molecular Dynamics Weather / Climate Modeling Signal Processing Satellite Imaging Video Analytics Synthetic Aperture Radar Bio-chemistry Bio-informatics Material Science Sequence Analysis Genomics Risk Analytics Monte Carlo Options Pricing Insurance modeling Structural Mechanics Computational Fluid Dynamics Machine Vision Electromagnetics 19
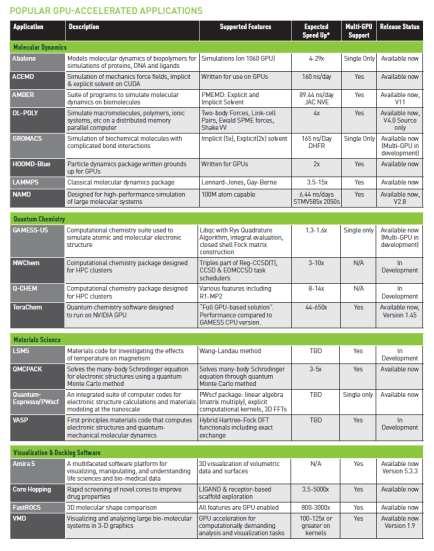
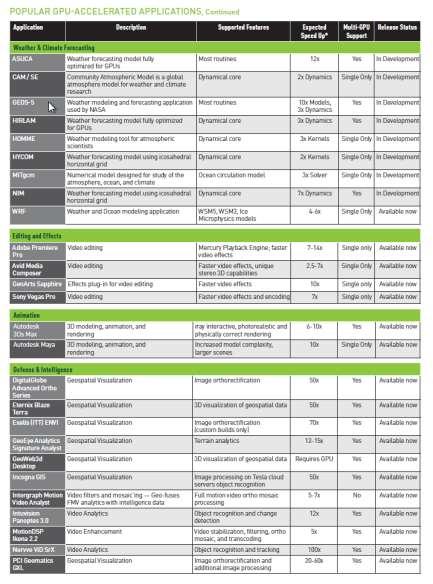
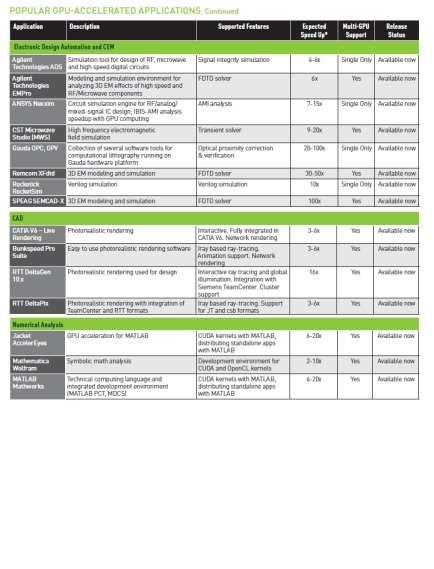
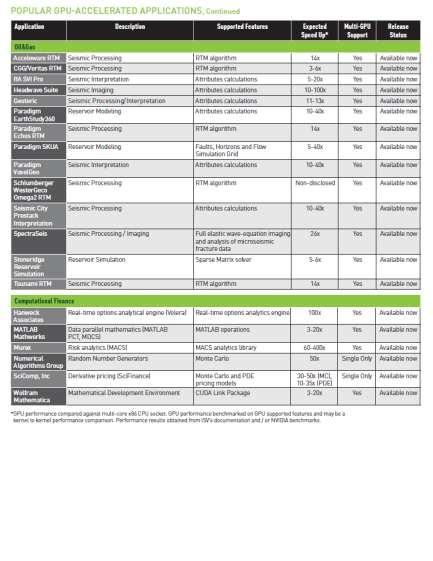
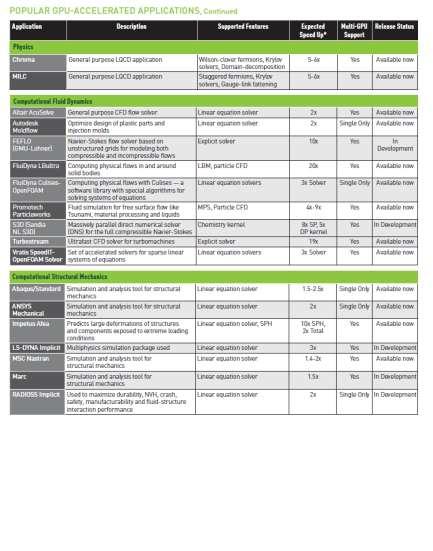
20 Over 200 GPU-Accelerated Applications 20
21 ANSYS and NVIDIA Collaboration Roadmap Release ANSYS Mechanical ANSYS Fluent 13.0 Dec Dec Nov 2012 SMP, Single GPU, Sparse and PCG/JCG Solvers + Distributed ANSYS; + Multi-node Support + Multi-GPU Support; + Hybrid PCG; + Kepler GPU Support Radiation Heat Transfer (beta) + Radiation HT; + GPU AMG Solver (beta), Single GPU 15.0 Q CUDA 5 Kepler Tuning + Multi-GPU AMG Solver; + CUDA 5 Kepler Tuning 21

 Distributed")
22 ANSYS Mechanical Number of Jobs Per Day ANSYS Mechanical 14.5 GPU Acceleration Results for Distributed ANSYS 14.5 with 8-Core CPUs and single GPUs CPU + GPU CPU Only Higher is Better 394 V14sp-5 Model Fermi 1.9x Acceleration 163 Westmere Xeon X GHz 8 Cores + Tesla C2075 Kepler 1.9x Acceleration 213 Sandy Bridge Xeon E5-2687W 3.10 GHz 8 Cores + Tesla K20 Turbine geometry 2,100,000 DOF SOLID187 FEs Static, nonlinear One iteration (final solution requires 25) Distributed ANSYS 14.5 Direct sparse solver Results from Supermicro X9DR3-F, 64GB memory 22
23 ANSYS Fluent 15.0 Multi-GPU Demonstration Multi-GPU Acceleration of a 16-Core ANSYS Fluent Simulation of External Aero 2.9X Solver Speedup Xeon E CPUs + Tesla K20X GPUs CPU Configuration CPU + GPU Configuration 16-Core Server Node 8-Cores 8-Cores G1 G2 G3 G4 23
 2.51 1.50 2 CPUs + 2 GPUs (Westmere, 12 cores + 2 Tesla) 2.21 1.21 1 CPU + 1 GPU (SB, 8 cores + 1 Tesla) 2.86 1.")
24 Factors Gain Over 1 Westmere CPU, 6 cores Abaqus 6.12 Solution Performance/Cost Westmere & Sandy Bridge CPUs w/ Tesla M Performance Speed-up Solution Cost (h/w + gpus + s/w tokens) CPU + 1 GPU (Westmere, 6 cores + 1 Tesla) CPUs + 2 GPUs (Westmere, 12 cores + 2 Tesla) CPU + 1 GPU (SB, 8 cores + 1 Tesla) CPUs + 2 GPUs (SB, 16 cores + 2 Tesla) Solution Cost Basis - Abaqus License Tokens (Base: 5 Tokens for 1 CPU core, 1 Additional Token unlocks 1 additional CPU core or an entire GPU) - $8K for Server node cost - $2K for 1x Tesla 20-series Performance Basis s4b Engine Block model - 5M DOF - Solid FEs - Static, nonlinear - Five iterations - Direct sparse solver Baseline performance (1x) corresponds to 1 CPU (6 cores of Westmere x5670, 2.93GHz) Baseline hardware costs corresponds to 2x CPUs, 64GB memory; (1.0x) (Same cost used for Westmere & SB CPUs) 24
25 Factors Gain Over Base License Results Nastran Solution Price-Performance Gain NOTE: Based on MSC Nastran 2013 Alpha Results from PSG cluster node, 2x Westmere 2.93GHz, 96GB memory, Linux/RHEL 6.2; 2x Tesla M2090, CUDA 4.2 CPU Speed-up GPU Speed-up Solution Cost 1.0 Nastran SMP License 1 Core Nastran SMP 4 Cores Nastran DMP 8 Cores Nastran SMP + GPU License 4 Core + 1 GPU 9.9 Nastran DMP + GPU License 8 Cores + 2 GPUs Extra 15% cost yields ~200% performance (over 8 cores) Solution Cost Basis - Structures Package (Base SMP license) - Exterior Acoustics Package - Implicit HPC Package (DMP Network License) - GPU License - $10K for System cost - $4K for 2x Tesla 20-series Performance Basis SOL108 Model: M DOF - NVH analysis - Trimmed Car Body * * 1 year lease for SW pricing 25
 plus 1x NVIDIA K20 GPUs 15.00 10.00 6.50 6.56 7.28 5.00 1.00 2.66 0.")
26 Speedup Compared to CPU Only AMBER: K20 Accelerates Simulations of All Sizes Running AMBER 12 GPU Support Revision 12.1 SPFP with CUDA ECC Off The blue node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) Each green node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) plus 1x NVIDIA K20 GPUs CPU All Molecules TRPcage GB JAC NVE PME Factor IX NVE PME Cellulose NVE PME Myoglobin GB Nucleosome GB Gain 28x throughput/performance by adding just one K20 GPU when compared to dual CPU performance Nucleosome 26

27 AMBER: Replace 8 Nodes with 1 K20 GPU $32, Running AMBER 12 GPU Support Revision 12.1 SPFP with CUDA ECC Off The eight (8) blue nodes each contain 2x Intel E5-2687W CPUs (8 Cores, $2000 per CPU) Each green node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) plus 1x NVIDIA K20 GPU ($2500 per GPU) $6, Nanoseconds/Day Cost Cut down simulation costs to ¼ and gain higher performance DHFR 27
 Each green node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) plus 1x NVIDIA K20 GPUs 1.5 1 1 0.")
28 Speedup Compared to CPU Only NAMD: Accelerates Simulations of All Sizes Running NAMD 2.9 with CUDA 4.0 ECC Off The blue node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) Each green node contains 2x Intel E5-2687W CPUs (8 Cores per CPU) plus 1x NVIDIA K20 GPUs CPU All Molecules ApoA1 F1-ATPase STMV Gain ~2.5x throughput/performance by adding just 1 GPU when compared to dual CPU performance Apolipoprotein A1 28
29 Energy Expended (kj) NAMD: Twice The Science Per Watt With K Energy Used in Simulating 1 Nanosecond of ApoA1 Lower is better Running NAMD version 2.9 Each blue node contains Dual E5-2687W CPUs (95W, 4 Cores per CPU). Each green node contains 2x Intel Xeon X5550 CPUs (95W, 4 Cores per CPU) and 2x NVIDIA K20 GPUs (225W per GPU) Energy Expended = Power x Time Node 1 Node + 2x K20 Cut down energy usage by ½ with GPUs 29

30 Titan: World s Fastest Supercomputer 18,688 Tesla K20X Accelerators 27 Petaflops Peak: 90% of Performance from GPUs Petaflops Sustained Performance on Linpack 30
31 Power is the main HPC constraint Summary Vast majority of work must be done by cores designed for efficiency GPU computing has a sustainable model Aligned with technology trends, supported by consumer markets Increasing number of Open Source Community and Commercial ISV applications are already implemented Good speedup compared to CPU only runs Better Total Cost of Ownership (TCO) Cut down energy consumption 31



32 GPU Technology Conference 2013 March San Jose, CA The one event you can t afford to miss Learn about leading-edge advances in GPU computing Explore the research as well as the commercial applications Discover advances in computational visualization Take a deep dive into parallel programming Ways to participate Speak share your work and gain exposure as a thought leader Register learn from the experts and network with your peers Exhibit/Sponsor promote your company as a key player in the GPU ecosystem 32


33 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA
GPU Computing. Axel Koehler Sr. Solution Architect HPC
 GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
GPU Computing Axel Koehler Sr. Solution Architect HPC 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro, Tesla ARM SoCs: Tegra VGX 2 Continued Demand for Ever Faster Supercomputers First-principles
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA
 Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
GPUs as better MPI Citizens
 s as better MPI Citizens Author: Dale Southard, NVIDIA Date: 4/6/2011 www.openfabrics.org 1 Technology Conference 2011 October 11-14 San Jose, CA The one event you can t afford to miss Learn about leading-edge
s as better MPI Citizens Author: Dale Southard, NVIDIA Date: 4/6/2011 www.openfabrics.org 1 Technology Conference 2011 October 11-14 San Jose, CA The one event you can t afford to miss Learn about leading-edge
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs. Baskar Rajagopalan Accelerated Computing, NVIDIA
 Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY. Peter Messmer
 NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen
 Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
Selecting the right Tesla/GTX GPU from a Drunken Baker's Dozen GPU Computing Applications Here's what Nvidia says its Tesla K20(X) card excels at doing - Seismic processing, CFD, CAE, Financial computing,
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
The Visual Computing Company
 The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
GPU-Acceleration of CAE Simulations. Bhushan Desam NVIDIA Corporation
 GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Technologies and application performance. Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017
 Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Technologies and application performance Marc Mendez-Bermond HPC Solutions Expert - Dell Technologies September 2017 The landscape is changing We are no longer in the general purpose era the argument of
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
HIGH-PERFORMANCE COMPUTING
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Game-changing Extreme GPU computing with The Dell PowerEdge C4130
 Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
GPU ACCELERATED COMPUTING. 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation
 GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
Peter Messmer Developer Technology Group Stan Posey HPC Industry and Applications
 Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
TESLA V100 PERFORMANCE GUIDE May 2018
 TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
TESLA V100 PERFORMANCE GUIDE May 2018 TESLA V100 The Fastest and Most Productive GPU for AI and HPC Volta Architecture Tensor Core Improved NVLink & HBM2 Volta MPS Improved SIMT Model Most Productive GPU
GPU Computing Ecosystem
 GPU Computing Ecosystem CUDA 5 Enterprise level GPU Development GPU Development Paths Libraries, Directives, Languages GPU Tools Tools, libraries and plug-ins for GPU codes Tesla K10 Kepler! Tesla K20
GPU Computing Ecosystem CUDA 5 Enterprise level GPU Development GPU Development Paths Libraries, Directives, Languages GPU Tools Tools, libraries and plug-ins for GPU codes Tesla K10 Kepler! Tesla K20
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
ACCELERATED COMPUTING: THE PATH FORWARD. Jensen Huang, Founder & CEO SC17 Nov. 13, 2017
 ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
ACCELERATED COMPUTING: THE PATH FORWARD Jensen Huang, Founder & CEO SC17 Nov. 13, 2017 COMPUTING AFTER MOORE S LAW Tech Walker 40 Years of CPU Trend Data 10 7 GPU-Accelerated Computing 10 5 1.1X per year
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Recent Advances in ANSYS Toward RDO Practices Using optislang. Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH
 Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
ENDURING DIFFERENTIATION Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING GPU-ACCELERATED PERFORMANCE 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 10 3 10 2 Single-threaded perf
ENDURING DIFFERENTIATION. Timothy Lanfear
 ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
ENDURING DIFFERENTIATION Timothy Lanfear WHERE ARE WE? 2 LIFE AFTER DENNARD SCALING 10 7 40 Years of Microprocessor Trend Data 10 6 10 5 10 4 Transistors (thousands) 1.1X per year 10 3 10 2 Single-threaded
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms. Dr. Jeffrey Layton Enterprise Technologist HPC
 Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms Dr. Jeffrey Layton Enterprise Technologist HPC Why GPUs? GPUs have very high peak compute capability! 6-9X CPU Challenges
Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms Dr. Jeffrey Layton Enterprise Technologist HPC Why GPUs? GPUs have very high peak compute capability! 6-9X CPU Challenges
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
HPC Enabling R&D at Philip Morris International
 HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
HPC Enabling R&D at Philip Morris International Jim Geuther*, Filipe Bonjour, Bruce O Neel, Didier Bouttefeux, Sylvain Gubian, Stephane Cano, and Brian Suomela * Philip Morris International IT Service
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Trends in systems and how to get efficient performance
 Trends in systems and how to get efficient performance Martin Hilgeman HPC Consultant martin.hilgeman@dell.com The landscape is changing We are no longer in the general purpose era the argument of tuning
Trends in systems and how to get efficient performance Martin Hilgeman HPC Consultant martin.hilgeman@dell.com The landscape is changing We are no longer in the general purpose era the argument of tuning
Kepler Overview Mark Ebersole
 Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs
 Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Iterative Solvers Numerical Results Conclusion and outlook 1/18 Matrix-free multi-gpu Implementation of Elliptic Solvers for strongly anisotropic PDEs Eike Hermann Müller, Robert Scheichl, Eero Vainikko
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS. Chris Butler NVIDIA
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Chris Butler NVIDIA Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of Chromatophores Chromatophore
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Chris Butler NVIDIA Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of Chromatophores Chromatophore
The Future of GPU Computing
 The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
The Future of GPU Computing Bill Dally Chief Scientist & Sr. VP of Research, NVIDIA Bell Professor of Engineering, Stanford University November 18, 2009 The Future of Computing Bill Dally Chief Scientist
AXEL KOEHLER GPU Computing Update
 AXEL KOEHLER GPU Computing Update Agenda Introduction GPU Computing Introduction into GPU Programming Kepler GPU Architecture GPU Applications Future Developments 2 NVIDIA: Parallel Computing Company GPUs:
AXEL KOEHLER GPU Computing Update Agenda Introduction GPU Computing Introduction into GPU Programming Kepler GPU Architecture GPU Applications Future Developments 2 NVIDIA: Parallel Computing Company GPUs:
Introduction to High Performance Computing. Shaohao Chen Research Computing Services (RCS) Boston University
 Boston University") Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
Introduction to High Performance Computing Shaohao Chen Research Computing Services (RCS) Boston University Outline What is HPC? Why computer cluster? Basic structure of a computer cluster Computer performance
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
CUDA Update: Present & Future. Mark Ebersole, NVIDIA CUDA Educator
 CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
ENABLING NEW SCIENCE GPU SOLUTIONS
 ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
ENABLING NEW SCIENCE TESLA BIO Workbench The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Motivation Goal Idea Proposition for users Study
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan Computer and Information Science University of Oregon 23 November 2015 Overview Motivation:
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control