The Visual Computing Company
|
|
|
- Geoffrey Robertson
- 5 years ago
- Views:
Transcription

1 The Visual Computing Company Update NVIDIA GPU Ecosystem Axel Koehler, Senior Solutions Architect HPC, NVIDIA
2 Outline Tesla K40 and GPU Boost Jetson TK-1 Development Board for Embedded HPC Pascal GPU 3D Memory NVLINK CUDA 6.0 Unified memory Extended Library Interfaces GPU Direct RDMA with OpenMPI and beyond

3 Tesla K40 FASTER 1.4 TF 2880 Cores 288 GB/s ns/day 5 AMBER Benchmark LARGER 2x Memory Enables More Apps SMARTER Unlock Extra Performance Using Power Headroom 4 3 6GB 2 1 Fluid Dynamics Seismic Analysis Rendering 0 CPU K20X K40 12GB AMBER Benchmark: SPFP-Nucleosome CPU: Dual 3.10GHz, 64GB System Memory, CentOS 6.2, GPU systems: Single Tesla K20X or Single Tesla K40
4 Board Power (Watts) Average GPU Power in Watts 180 Avg GPU Power in Watts for Real Applications on K20X AMBER ANSYS Black Scholes Chroma GROMACS GTC LAMMPS LSMS NAMD Nbody QMCPACK RTM SPECFEM3D
5 GPU Boost on Tesla K40 Convert Power Headroom to Higher Performance Boost Clock #2 875Mhz Boost Clock #1 810Mhz Base Clock 745Mhz 235W 235W 235W Workload # 1 Worst case Reference App Workload # 2 E.g. AMBER Workload # 3 E.g. ANSYS Fluent 5
6 Compute Workload Behavior with GPU Boost Non-Tesla Tesla K40 Boost Clock # 2 Boost Clock # 1 GPU Clock Base Clock # 1 Automatic clock switching Deterministic Clocks Default Boost Base Preset Options Lock to base clock 3 Levels: Base, Boost1 or Boost2 Boost Interface Target duration for boost clocks Control Panel ~50% of run-time NV-SMI, NVML nvidia-smi -q d CLOCK,SUPPORTED_CLOCKS nvidia-smi -ac <MEM clock, Graphics clock> 100% of workload run time Must-have for HPC workload
 HW support New packaging allows much denser solutions (one-third (one-third the size of current PCIe")
7 Pascal GPU Optimized for double precision FP Very high bandwidth, large capacity 3D memory on package NVLINK for high bandwidth CPU GPU and GPU GPU interconnect Unified Memory (UM) HW support New packaging allows much denser solutions (one-third (one-third the size of current PCIe boards)

8 Stacked Memory 3D chip on wafer integration Multiple layers of DRAM components will be integrated vertically on the package along with the GPU Compared to GDDR5 memory 4x Higher Bandwidth 3x Larger Capacity 4x More Energy Efficient per bit
9 NVLINK CPU GPU communication limited by low bandwidth connection via PCI-e NVLINK is a high speed interconnect between CPU GPU and GPU GPU Basic building block is a 8-lane, differential, dual simplex bidirectional link Multiple links can be aggregated to increase BW of a connection NVLink will provide between 80 and 200 GB/s of bandwidth Cache coherency provided with NVLINK 2.0 Preserves the PCIe programming model CPU-initiated transactions such as control and configuration over a PCIe connection GPU-initiated transactions use NVLink Allowing the GPU full-bandwidth access to the CPU s memory system NVLink is more than twice as energy efficient as a PCIe 3.0 connection
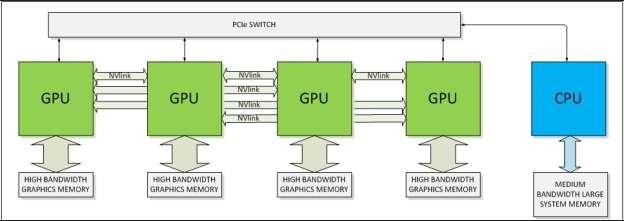
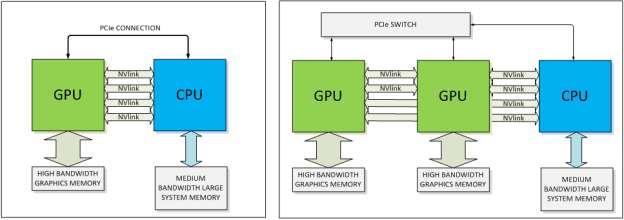
10 NVLINK
 4 Plus 1 Quad core ARM Cortex A15 CPU 2 GB Memory, 16 GB emmc memory IO options minipci-e slot, GigE, HDMI, SD/MMC connector, USB 3.0, SATA data port,. CUDA Toolkit 6.0, OpenGL 4.4, OpenGL ES 3.")
11 JETSON TK1 THE WORLD S 1st EMBEDDED SUPERCOMPUTER Development Platform for Embedded Computer Vision, Robotics, Medical,... Tegra K1 SOC Kepler GPU with 192 Cores (Compute Capability 3.2) 4 Plus 1 Quad core ARM Cortex A15 CPU 2 GB Memory, 16 GB emmc memory IO options minipci-e slot, GigE, HDMI, SD/MMC connector, USB 3.0, SATA data port,. CUDA Toolkit 6.0, OpenGL 4.4, OpenGL ES 3.0 Runs 32-bit Ubuntu Linux for Tegra (L4T) 326 GFLOPS, 5 Watts



12 IBM Partners with NVIDIA to Build Next- Generation Supercomputers + Tesla GPU POWER 8 CPU GPU-Accelerated POWER-Based Systems Available in
13 Three ISAs, One Programming Model CUDA Ecosystem (Libraries, Directives, Languages) x86 ARM POWER


14 Integration of Compute and Visualisation New GPU Operation Mode was introduced with Kepler GK110 based K20/K20X/K40 (not on C-Class) All on mode enables graphics capabilities nvidia-smi --gom=0
15 Unified Memory Dramatically Lower Developer Effort Developer View Today Developer View With Unified Memory System Memory GPU Memory Unified Memory 15
malloc(n); fread(data, 1, N, fp); qsort(data, N, 1, compare); use_data(data); CPU Code CUDA 6 Code with")
; qsort<<<.")
16 Super Simplified Memory Management Code void sortfile(file *fp, int N) { char *data; data = (char *)malloc(n); fread(data, 1, N, fp); qsort(data, N, 1, compare); use_data(data); CPU Code CUDA 6 Code with Unified Memory void sortfile(file *fp, int N) { char *data; cudamallocmanaged(&data, N); fread(data, 1, N, fp); qsort<<<...>>>(data,n,1,compare); cudadevicesynchronize(); use_data(data); } free(data); } cudafree(data); 16
17 Unified Memory Delivers 1. Simpler Programming & Memory Model Single pointer to data, accessible anywhere Tight language integration Greatly simplifies code porting 2. Performance Through Data Locality Migrate data to accessing processor Guarantee global coherency Still allows cudamemcpyasync() hand tuning 17




18 Unified Memory Roadmap CUDA 6: Ease of Use Next: Optimizations Single Pointer to Data Future GPUs No Memcopy Required launch & sync Shared C/C++ Data Structures Prefetching Migration Hints Additional OS Support Finer Grain Migration Not Limited to GPU Memory Size Learn More:



19 Kepler Enables Full NVIDIA GPUDirect RDMA System Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory GDDR5 Memory System Memory CPU GPU1 GPU2 GPU2 GPU1 CPU Server 1 PCI-e Network Card Network Network Card PCI-e Server 2 19
20 Mellanox Infiniband with GPUDirect RDMA Mellanox GPUDirect (GDR) MLNX_OFED driver is available Beta release works with CUDA 5.5 ( ) Final release will be based on CUDA 6.0 Supported on any ConnectX adapter that use the MLX4 driver MVAPICH2-GDR release can be used with this IB driver release
21 GPU Direct RDMA with OpenMPI Starting with CUDA 6 OpenMPI also supports GPU Direct RDMA Kepler class GPUs (K10, K20, K20X, K40) Mellanox ConnectX-3, ConnectX-3 Pro, Connect-IB CUDA 6.0 (EA, RC, Final), Open MPI and Mellanox OFED 2.1 drivers. GPU Direct RDMA enabling software
22 GPU Direct RDMA with OpenMPI OpenMPI Compilation: configure --with-cuda Support is configured in if CUDA 6.0 cuda.h header file is detected. To check: > ompi_info --all grep btl_openib_have_cuda_gdr MCA btl: informational "btl_openib_have_cuda_gdr" (current value: "true", data source: default, level: 4 tuner/basic, type: bool) > ompi_info -all grep btl_openib_have_driver_gdr MCA btl: informational "btl_openib_have_driver_gdr" (current value: "true", data source: default, level: 4 tuner/basic, type: bool) Enable GPU Direct RDMA usage (off by default) --mca btl_openib_want_cuda_gdr 1 Adjust when we switch to pipeline transfers through host memory. Current default is 30,000 bytes --mca btl_openib_cuda_rdma_limit 60000

23 GPU Direct RDMA with OpenMPI Chipset implementation limits bandwidth at larger message sizes Still use pipelining with host memory staging for large messages (hybrid version utilizes asynchronous copies)

 http://www.hpcadvisorycouncil.com/pdf/hoomdblue_analysis_and_profiling.pdf")
24 GPU Direct RDMA with OpenMPI HOOMD-blue (git master 28Jan14), Lennard-Jones Liquid dataset (16K, 512K Particles) Higher is better Higher is better 102% 20% Dual-Socket Intel E GHz CPUs, 64GB memory, RHEL 6.2, MLNX_OFED , Mellanox FDR 1 x Tesla K40 per node, Driver , Open MPI 1.7.4rc1, GPUDirect RDMA (nvidia_peer_memory tar.gz) Dual-Socket Intel E GHz CPUs, 64GB memory, Scientific Linux 6.4, MLNX_OFED , Mellanox FDR 2 x Tesla K20 per node, Driver , Open MPI 1.7.4rc1, GPUDirect RDMA (nvidia_peer_memory tar.gz)
25 Extended (XT) Library Interfaces Automatic Scaling to multiple GPUs per node cufft 2D/3D & cublas level 3 Operate directly on large datasets that reside in CPU memory developer.nvidia.com/cublasxt 6.0 TFLOPS 4.2 TFLOPS 2.2 TFLOPS 7.9 TFLOPS x K10 2 x K10 3 x K10 4 x K10 16K x 16K SGEMM on Tesla K10
26 fp64 GFlops/s New Drop-in NVBLAS Library Drop-in replacement for CPU-only BLAS Automatically route BLAS3 calls to cublas Matrix-Matrix Multiplication in R 3000 Example: Drop-in Speedup for R > LD_PRELOAD=/usr/local/cuda/lib64/libnvblas.so R > A <- matrix(rnorm(4096*4096), nrow=4096, ncol=4096) > B <- matrix(rnorm(4096*4096), nrow=4096, ncol=4096) > system.time(c <- A %*% B) user system elapsed Use in any app that uses standard BLAS3 Octave, Scilab, etc nvblas, 4x K20X GPUs MKL, 6-core Xeon E CPU matrix dimension









27 Remote Development with Nsight Eclipse Edition Local IDE, remote application Edit locally, build & run remotely Automatic sync via ssh Cross-compilation to ARM Full debugging & profiling via remote connection Edit sync Build Run Debug Profile
28 Goals for the CUDA Platform Simplicity Learn, adopt, & use parallelism with ease Productivity Quickly achieve feature & performance goals Portability Write code that can execute on all targets Performance High absolute performance and scalability

29 Simpler Heterogeneous Applications We want: homogeneous programs, heterogeneous execution Unified programming model includes parallelism in language Abstract heterogeneous execution via Runtime or Virtual Machine Hybrid Program Single Program parallel serial Homogeneous Programming Model parallel + serial GPU CPU GPU CPU Current Ideal




30 Parallelism in Mainstream Languages Enable more programmers to write parallel software Give programmers the choice of language to use GPU support in key languages C
, f); // explicitly sequential loop std::for_each(std::seq, vec.begin(), vec.end(), f); // permitting parallel execution std::for_each(std::par, vec.")

31 C++ Parallel Algorithms Library Progress std::vector<int> vec =... // previous standard sequential loop std::for_each(vec.begin(), vec.end(), f); // explicitly sequential loop std::for_each(std::seq, vec.begin(), vec.end(), f); // permitting parallel execution std::for_each(std::par, vec.begin(), vec.end(), f); Complete set of parallel primitives: for_each, sort, reduce, scan, etc. ISO C++ committee voted unanimously to accept as official tech. specification working draft N3960 Technical Specification Working Draft: Prototype:

 )")
 out[i] = a * x[i] + y[i] # Launch saxpy kernel")
32 Numba Python Compiler Free and open source compiler for array-oriented Python NEW numba.cuda module integrates CUDA directly into void(float32[:], float32, float32[:], float32[:]) ) def saxpy(out, a, x, y): i = cuda.grid(1) out[i] = a * x[i] + y[i] # Launch saxpy kernel saxpy[griddim, blockdim](out, a, x, y)

33 34

34 GPU-Accelerated Hadoop Extract insights from customer data Data Analytics using clustering algorithms Developed using CUDA-accelerated IBM Java
![Compile Java for GPUs Approach: apply a closure to a set of arrays // vector addition float[] X = {1.0, 2.0, 3.0, 4.0, }; float[] Y = {9.0, 8.](/docs-images/85/92591387/images/35-0.jpg "1, 7.2, 6.3, }; float[] Z = {0.0, 0.0, 0.0, 0.0, }; jog.")

35 Compile Java for GPUs Approach: apply a closure to a set of arrays // vector addition float[] X = {1.0, 2.0, 3.0, 4.0, }; float[] Y = {9.0, 8.1, 7.2, 6.3, }; float[] Z = {0.0, 0.0, 0.0, 0.0, }; jog.foreach(x, Y, Z, new jogcontext(), new jogclosureret<jogcontext>() { public float execute(float x, float y) { return x + y; } } ); Java Black-Scholes Options Pricing Speedup Speedup vs. Sequential Java Millions of Options foreach iterations parallelized over GPU threads Threads run closure execute() method



36 GPUs are Going Beyond Scientific & Technical Computing GPUs Accelerate Machine Learning & Data Analytics Auto Tagging in Creative Cloud Speech/Image Recognition Analyzing Twitter Hadoop-based Clustering Recommendation Engine Visual Shopping Searching Audio Real Time Video Delivery Database Queries Search Ranking
37 The Massively Parallel Programming Blog Technical posts on GPUs, CUDA, OpenACC, Libraries, C/C++/Python and more In-depth articles and regular series: CUDACasts: instructive videos CUDA Pro Tips: useful techniques CUDA Spotlight Interviews Join the conversation by subscribing to or RSS updates today!
38 The Visual Computing Company Axel Koehler NVIDIA, the NVIDIA logo, GeForce, Quadro, Tegra, Tesla, GeForce Experience, GRID, GTX, Kepler, ShadowPlay, GameStream, SHIELD, and The Way It s Meant To Be Played are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries. Other company and product names may be trademarks of the respective companies with which they are associated NVIDIA Corporation. All rights reserved.
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS
 NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
NEW FEATURES IN CUDA 6 MAKE GPU ACCELERATION EASIER MARK HARRIS 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries GPUDirect RDMA in MPI 4 Developer Tools 1 Unified Memory CUDA 6 2 3 XT and Drop-in Libraries
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY. Peter Messmer
 NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
NOVEL GPU FEATURES: PERFORMANCE AND PRODUCTIVITY Peter Messmer pmessmer@nvidia.com COMPUTATIONAL CHALLENGES IN HEP Low-Level Trigger High-Level Trigger Monte Carlo Analysis Lattice QCD 2 COMPUTATIONAL
OPEN MPI WITH RDMA SUPPORT AND CUDA. Rolf vandevaart, NVIDIA
 OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
OPEN MPI WITH RDMA SUPPORT AND CUDA Rolf vandevaart, NVIDIA OVERVIEW What is CUDA-aware History of CUDA-aware support in Open MPI GPU Direct RDMA support Tuning parameters Application example Future work
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA
 EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
EXTENDING THE REACH OF PARALLEL COMPUTING WITH CUDA Mark Harris, NVIDIA @harrism #NVSC14 EXTENDING THE REACH OF CUDA 1 Machine Learning 2 Higher Performance 3 New Platforms 4 New Languages 2 GPUS: THE
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
NVIDIA GPU TECHNOLOGY UPDATE
 NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
NVIDIA GPU TECHNOLOGY UPDATE May 2015 Axel Koehler Senior Solutions Architect, NVIDIA NVIDIA: The VISUAL Computing Company GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
LECTURE ON PASCAL GPU ARCHITECTURE. Jiri Kraus, November 14 th 2016
 LECTURE ON PASCAL GPU ARCHITECTURE Jiri Kraus, November 14 th 2016 ACCELERATED COMPUTING CPU Optimized for Serial Tasks GPU Accelerator Optimized for Parallel Tasks 2 ACCELERATED COMPUTING CPU Optimized
LECTURE ON PASCAL GPU ARCHITECTURE Jiri Kraus, November 14 th 2016 ACCELERATED COMPUTING CPU Optimized for Serial Tasks GPU Accelerator Optimized for Parallel Tasks 2 ACCELERATED COMPUTING CPU Optimized
April 4-7, 2016 Silicon Valley INSIDE PASCAL. Mark Harris, October 27,
 April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
April 4-7, 2016 Silicon Valley INSIDE PASCAL Mark Harris, October 27, 2016 @harrism INTRODUCING TESLA P100 New GPU Architecture CPU to CPUEnable the World s Fastest Compute Node PCIe Switch PCIe Switch
THE LEADER IN VISUAL COMPUTING
 MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
MOBILE EMBEDDED THE LEADER IN VISUAL COMPUTING 2 TAKING OUR VISION TO REALITY HPC DESIGN and VISUALIZATION AUTO GAMING 3 BEST DEVELOPER EXPERIENCE Tools for Fast Development Debug and Performance Tuning
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Future Directions for CUDA Presented by Robert Strzodka
 Future Directions for CUDA Presented by Robert Strzodka Authored by Mark Harris NVIDIA Corporation Platform for Parallel Computing Platform The CUDA Platform is a foundation that supports a diverse parallel
Future Directions for CUDA Presented by Robert Strzodka Authored by Mark Harris NVIDIA Corporation Platform for Parallel Computing Platform The CUDA Platform is a foundation that supports a diverse parallel
Unified memory. GPGPU 2015: High Performance Computing with CUDA University of Cape Town (South Africa), April, 20th-24th, 2015
, April, 20th-24th, 2015") Unified memory GPGPU 2015: High Performance Computing with CUDA University of Cape Town (South Africa), April, 20th-24th, 2015 Manuel Ujaldón Associate Professor @ Univ. of Malaga (Spain) Conjoint Senior
Unified memory GPGPU 2015: High Performance Computing with CUDA University of Cape Town (South Africa), April, 20th-24th, 2015 Manuel Ujaldón Associate Professor @ Univ. of Malaga (Spain) Conjoint Senior
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
Unified Memory. Notes on GPU Data Transfers. Andreas Herten, Forschungszentrum Jülich, 24 April Member of the Helmholtz Association
 Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester
 NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
NVIDIA GPU Computing A Revolution in High Performance Computing GPUs and the Future of Accelerated Computing Emerging Technology Conference 2014 University of Manchester John Ashley Senior Solutions Architect
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
TESLA P100 PERFORMANCE GUIDE. HPC and Deep Learning Applications
 TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE HPC and Deep Learning Applications MAY 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè. ARM64 and GPGPU
 E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
E4-ARKA: ARM64+GPU+IB is Now Here Piero Altoè ARM64 and GPGPU 1 E4 Computer Engineering Company E4 Computer Engineering S.p.A. specializes in the manufacturing of high performance IT systems of medium
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015
 HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
HPC with the NVIDIA Accelerated Computing Toolkit Mark Harris, November 16, 2015 Accelerators Surge in World s Top Supercomputers 125 100 75 Top500: # of Accelerated Supercomputers 100+ accelerated systems
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
NVIDIA S VISION FOR EXASCALE. Cyril Zeller, Director, Developer Technology
 NVIDIA S VISION FOR EXASCALE Cyril Zeller, Director, Developer Technology EXASCALE COMPUTING An industry target of 1 ExaFlops within 20 MW by 2020 1 ExaFlops: a necessity to advance science and technology
NVIDIA S VISION FOR EXASCALE Cyril Zeller, Director, Developer Technology EXASCALE COMPUTING An industry target of 1 ExaFlops within 20 MW by 2020 1 ExaFlops: a necessity to advance science and technology
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
CUDA 6.0. Manuel Ujaldón Associate Professor, Univ. of Malaga (Spain) Conjoint Senior Lecturer, Univ. of Newcastle (Australia) Nvidia CUDA Fellow
 Conjoint Senior Lecturer, Univ. of Newcastle (Australia) Nvidia CUDA Fellow") CUDA 6.0 Manuel Ujaldón Associate Professor, Univ. of Malaga (Spain) Conjoint Senior Lecturer, Univ. of Newcastle (Australia) Nvidia CUDA Fellow 1 Acknowledgements To the great Nvidia people, for sharing
CUDA 6.0 Manuel Ujaldón Associate Professor, Univ. of Malaga (Spain) Conjoint Senior Lecturer, Univ. of Newcastle (Australia) Nvidia CUDA Fellow 1 Acknowledgements To the great Nvidia people, for sharing
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR
 Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
Exploiting Full Potential of GPU Clusters with InfiniBand using MVAPICH2-GDR Presentation at Mellanox Theater () Dhabaleswar K. (DK) Panda - The Ohio State University panda@cse.ohio-state.edu Outline Communication
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA. NVIDIA Corporation 2012
 Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
Scalable Cluster Computing with NVIDIA GPUs Axel Koehler NVIDIA Outline Introduction to Multi-GPU Programming Communication for Single Host, Multiple GPUs Communication for Multiple Hosts, Multiple GPUs
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Timothy Lanfear, NVIDIA HPC
 GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
GPU COMPUTING AND THE Timothy Lanfear, NVIDIA FUTURE OF HPC Exascale Computing will Enable Transformational Science Results First-principles simulation of combustion for new high-efficiency, lowemision
S THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE. Presenter: Louis Capps, Solution Architect, NVIDIA,
 S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
S7750 - THE MAKING OF DGX SATURNV: BREAKING THE BARRIERS TO AI SCALE Presenter: Louis Capps, Solution Architect, NVIDIA, lcapps@nvidia.com A TALE OF ENLIGHTENMENT Basic OK List 10 for x = 1 to 3 20 print
Nvidia Jetson TX2 and its Software Toolset. João Fernandes 2017/2018
 Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
VSC Users Day 2018 Start to GPU Ehsan Moravveji
 Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
Outline A brief intro Available GPUs at VSC GPU architecture Benchmarking tests General Purpose GPU Programming Models VSC Users Day 2018 Start to GPU Ehsan Moravveji Image courtesy of Nvidia.com Generally
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS. Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016
 TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016 MULTI GPU PROGRAMMING Node 0 Node 1 Node N-1 MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM
TECHNOLOGIES FOR IMPROVED SCALING ON GPU CLUSTERS Jiri Kraus, Davide Rossetti, Sreeram Potluri, June 23 rd 2016 MULTI GPU PROGRAMMING Node 0 Node 1 Node N-1 MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM MEM
An Evaluation of Unified Memory Technology on NVIDIA GPUs
 An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Mellanox GPUDirect RDMA User Manual
 Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
Mellanox GPUDirect RDMA User Manual Rev 1.2 www.mellanox.com NOTE: THIS HARDWARE, SOFTWARE OR TEST SUITE PRODUCT ( PRODUCT(S) ) AND ITS RELATED DOCUMENTATION ARE PROVIDED BY MELLANOX TECHNOLOGIES AS-IS
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Deep Learning: Transforming Engineering and Science The MathWorks, Inc.
 Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Deep Learning: Transforming Engineering and Science 1 2015 The MathWorks, Inc. DEEP LEARNING: TRANSFORMING ENGINEERING AND SCIENCE A THE NEW RISE ERA OF OF GPU COMPUTING 3 NVIDIA A IS NEW THE WORLD S ERA
Manycore and GPU Channelisers. Seth Hall High Performance Computing Lab, AUT
 Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
Manycore and GPU Channelisers Seth Hall High Performance Computing Lab, AUT GPU Accelerated Computing GPU-accelerated computing is the use of a graphics processing unit (GPU) together with a CPU to accelerate
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA GPUS
 SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
SYNERGIE VON HPC UND DEEP LEARNING MIT NVIDIA S Axel Koehler, Principal Solution Architect HPCN%Workshop%Goettingen,%14.%Mai%2018 NVIDIA - AI COMPUTING COMPANY Computer Graphics Computing Artificial Intelligence
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
CUDA 5 and Beyond. Mark Ebersole. Original Slides: Mark Harris 2012 NVIDIA
 CUDA 5 and Beyond Mark Ebersole Original Slides: Mark Harris The Soul of CUDA The Platform for High Performance Parallel Computing Accessible High Performance Enable Computing Ecosystem Introducing CUDA
CUDA 5 and Beyond Mark Ebersole Original Slides: Mark Harris The Soul of CUDA The Platform for High Performance Parallel Computing Accessible High Performance Enable Computing Ecosystem Introducing CUDA
Game-changing Extreme GPU computing with The Dell PowerEdge C4130
 Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
Game-changing Extreme GPU computing with The Dell PowerEdge C4130 A Dell Technical White Paper This white paper describes the system architecture and performance characterization of the PowerEdge C4130.
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
CUDA Update: Present & Future. Mark Ebersole, NVIDIA CUDA Educator
 CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
CUDA Update: Present & Future Mark Ebersole, NVIDIA CUDA Educator Recent CUDA News Kepler K20 & K20X Kepler GPU Architecture: Streaming Multiprocessor (SMX) 192 SP CUDA Cores per SMX 64 DP CUDA Cores per
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
OpenPOWER Innovations for HPC. IBM Research. IWOPH workshop, ISC, Germany June 21, Christoph Hagleitner,
 IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
IWOPH workshop, ISC, Germany June 21, 2017 OpenPOWER Innovations for HPC IBM Research Christoph Hagleitner, hle@zurich.ibm.com IBM Research - Zurich Lab IBM Research - Zurich Established in 1956 45+ different
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
NAMD GPU Performance Benchmark. March 2011
 NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
NAMD GPU Performance Benchmark March 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
HOKUSAI System. Figure 0-1 System diagram
 HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand
 Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Latest Advances in MVAPICH2 MPI Library for NVIDIA GPU Clusters with InfiniBand Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Kepler Overview Mark Ebersole
 Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
Kepler Overview Mark Ebersole TFLOPS TFLOPS 3x Performance in a Single Generation 3.5 3 2.5 2 1.5 1 0.5 0 1.25 1 Single Precision FLOPS (SGEMM) 2.90 TFLOPS.89 TFLOPS.36 TFLOPS Xeon E5-2690 Tesla M2090
NVIDIA GRID. Jared Cowart, Sr. Solution Architect
 NVIDIA GRID Jared Cowart, Sr. Solution Architect AGENDA 1 Importance of GPUs in VDI 2 Desktop Virtualization 3 VDI with NVIDIA GRID GPUs 3 WORLD LEADER IN VISUAL COMPUTING HPC and DATA CENTERS DESIGN and
NVIDIA GRID Jared Cowart, Sr. Solution Architect AGENDA 1 Importance of GPUs in VDI 2 Desktop Virtualization 3 VDI with NVIDIA GRID GPUs 3 WORLD LEADER IN VISUAL COMPUTING HPC and DATA CENTERS DESIGN and
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU. Peng Wang HPC Developer Technology
 ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
ADVANCES IN EXTREME-SCALE APPLICATIONS ON GPU Peng Wang HPC Developer Technology NVIDIA SuperPhones to SuperComputers Computers no longer get faster, just wider Architectural Features Common to All Processors
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Real-Time Support for GPU. GPU Management Heechul Yun
 Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
Real-Time Support for GPU GPU Management Heechul Yun 1 This Week Topic: Real-Time Support for General Purpose Graphic Processing Unit (GPGPU) Today Background Challenges Real-Time GPU Management Frameworks
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
The Rise of Open Programming Frameworks. JC BARATAULT IWOCL May 2015
 The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket 2 TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA
The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket 2 TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA
May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND. Mark Harris, May 10, 2017
 May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
May 8-11, 2017 Silicon Valley CUDA 9 AND BEYOND Mark Harris, May 10, 2017 INTRODUCING CUDA 9 BUILT FOR VOLTA FASTER LIBRARIES Tesla V100 New GPU Architecture Tensor Cores NVLink Independent Thread Scheduling
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General