L0 L1 L2 L3 T0 T1 T2 T3. Eth1-4. Eth1-4. Eth1-2 Eth1-2 Eth1-2 Eth Eth3-4 Eth3-4 Eth3-4 Eth3-4.
|
|
|
- Cathleen Hunter
- 5 years ago
- Views:
Transcription



1 Click! N P






2 Eth33 Eth1-4 Eth1-4 C0 C1 Eth1-2 Eth1-2 Eth1-2 Eth Eth3-4 Eth3-4 Eth3-4 Eth3-4 L0 L1 L2 L3 Eth24-25 Eth1-24 Eth24-25 Eth24-25 Eth24-25 Eth1-24 Eth1-24 Eth1-24 T0 T1 T2 T3 2
3 Network function Implementation 1500B 40 Gbps (normal case) NVGRE tunnel encapsulation Hyper-V virtual switch Firewall (8K rules) Linux iptables B 40 Gbps (worst-case estimate) 3
4 Network function Implementation 1500B 40 Gbps (normal case) NVGRE tunnel encapsulation Hyper-V virtual switch Firewall (8K rules) Linux iptables B 40 Gbps (worst-case estimate) 4
5 5
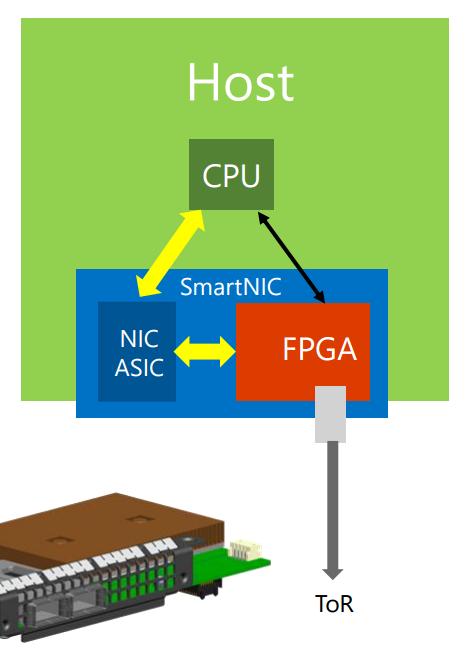

6 6

7 88 h68656c6c6f20776f726c64 Ahhhhhhhhhhhh! 7
8 Click! N P language fully programmable using high-level Click abstractions familiar to software developers; easy code reuse high throughput; microsecond-scale latency FPGA is no panacea; fine-grained processing separation 8
9 A B C 9
10 (reg/mem) (I/O) (main thread) (I/O) (ISR) (interrupt) 10
11 Element A (FPGA) Element B (CPU) PCIe I/O channel 11
12 Verilog code (.v) 12
13 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 13
14 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 14
15 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 15
16 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 16
17 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 17
18 ClickNP host process Mgr thrd Worker thrd ClickNP elements ClickNP library PCIe I/O channel vendor libs ClickNP host mgr ClickNP script Host FPGA Catapult PCIe Driver Catapult shell ClickNP vendor specific runtime ClickNP compiler C compiler vendor HLS Cross-platform toolchain Altera OpenCL / Vivado HLS Visual Studio / GCC 18
19 CPU logger ClickNP Configuration: 19
20 Count element: CPU logger ClickNP Configuration: 20
21 21
22 22
23 Input pkt Input Output s += pkt[0] s += pkt[1] s += pkt[2] Output s Input Output Input Output Input Output Input Output 23
24 Read input Read Inc Write Read Inc Write Read mem Read Inc Write Increment Write mem Read read write write Write out 24
25 Read input Read input Memory read and write can operate in parallel: Read in.addr, Write buf.addr Different memory addresses! Read mem Increment Read buf in.addr = buf.addr? Read mem Write mem Write mem Write out Increment Write buf Write out Delayed write: Buffer new data in a register Delay memory write until next read 25
26 Read Cache Hit? Cache Read DRAM Output Cache Read DRAM Output Cache Read Read DRAM Output 26
27 Read Cache Read Cache From fast path Hit? Read DRAM Hit? To slow path From slow path Read DRAM To fast path Output Output 27
28 Cache Output Cache Output Cache Output Cache Output Cache To slow Read DRAM To fast Output Cache Output 28
29 Element Fmax (MHz) Peak Throughput Nearly 100 elements 20% re-factored from Click modular router Cover packet parsing, checksum, tunnel encap/decap, crypto, hash tables, prefix matching, packet scheduling, rate limiting Delay (cycles) Resource LE % Throughput: 200 Mpps / 100 Gbps Mean delay: 0.19 us, max delay: 0.8 us Mean LoC: 80, max LoC: 196 Resource BRAM % L4_Parser Gbps % 0.2% IPChecksum Gbps % 1.3% NVGRE_Encap Gbps 9 1.5% 0.6% AES_CTR Gbps % 23.1% SHA Gbps % 6.6% CuckooHash Mpps % 65.5% HashTCAM Mpps % 22.0% LPM_Tree Mpps % 13.2% SRPrioQueue Mpps % 0.6% RateLimiter Mpps % 14.1% 29
30 Element Fmax (MHz) Peak Throughput Nearly 100 elements 20% re-factored from Click modular router Cover packet parsing, checksum, encap/decap, hash tables, prefix matching, rate limiting, crypto, packet scheduling Delay (cycles) Resource LE % Throughput: 200 Mpps / 100 Gbps Mean delay: 0.19 us, max delay: 0.8 us Mean LoC: 80, max LoC: 196 Resource BRAM % L4_Parser Gbps % 0.2% IPChecksum Gbps % 1.3% NVGRE_Encap Gbps 9 1.5% 0.6% AES_CTR Gbps % 23.1% SHA Gbps % 6.6% CuckooHash Mpps % 65.5% HashTCAM Mpps % 22.0% LPM_Tree Mpps % 13.2% SRPrioQueue Mpps % 0.6% RateLimiter Mpps % 14.1% 30
31 Element Fmax (MHz) Peak Throughput Nearly 100 elements 20% re-factored from Click modular router Cover packet parsing, checksum, encap/decap, hash tables, prefix matching, rate limiting, crypto, packet scheduling Delay (cycles) Resource LE % Throughput: 200 Mpps / 100 Gbps Mean delay: 0.19 us, max delay: 0.8 us Mean LoC: 80, max LoC: 196 Resource BRAM % L4_Parser Gbps % 0.2% IPChecksum Gbps % 1.3% NVGRE_Encap Gbps 9 1.5% 0.6% AES_CTR Gbps % 23.1% SHA Gbps % 6.6% CuckooHash Mpps % 65.5% HashTCAM Mpps % 22.0% LPM_Tree Mpps % 13.2% SRPrioQueue Mpps % 0.6% RateLimiter Mpps % 14.1% 31
32 Element Fmax (MHz) Peak Throughput Nearly 100 elements 20% re-factored from Click modular router Cover packet parsing, checksum, encap/decap, hash tables, prefix matching, rate limiting, crypto, packet scheduling Delay (cycles) Resource LE % Throughput: 200 Mpps / 100 Gbps Mean delay: 0.19 us, max delay: 0.8 us Mean LoC: 80, max LoC: 196 Resource BRAM % L4_Parser Gbps % 0.2% IPChecksum Gbps % 1.3% NVGRE_Encap Gbps 9 1.5% 0.6% AES_CTR Gbps % 23.1% SHA Gbps % 6.6% CuckooHash Mpps % 65.5% HashTCAM Mpps % 22.0% LPM_Tree Mpps % 13.2% SRPrioQueue Mpps % 0.6% RateLimiter Mpps % 14.1% 32
33 Network Function Lines of Code * Number of Elements Resource LE % Pkt generator % 12% Pkt capture % 5% OpenFlow firewall % 54% IPSec gateway % 74% L4 load balancer % 38% pfabric scheduler % 15% Resource BRAM % 33
34 34
35 35
36 36
37 scheduler pkt 1 pkt n 37
38 scheduler pkt 1 pkt n 38
39 ClickNP StrongSwan / Linux (out of the box) Throughput 37.8 Gbps 628 Mbps Latency 13 us (stable) 50us ~ 5ms 39
40 Nexthop allocation CPU element 40
41 Nexthop allocation CPU element 41

42 42
43 NetFPFA Function Resource Utilization Min / Max LUTs Registers BRAMs Input arbiter 2.1x / 3.4x 1.8x / 2.8x 0.9x / 1.3x Output queue 1.4x / 2.0x 2.0x / 3.2x 0.9x / 1.2x Header parser 0.9x / 3.2x 2.1x / 3.2x N/A Openflow table 0.9x / 1.6x 1.6x / 2.3x 1.1x / 1.2x IP checksum 4.3x / 12.1x 9.7x / 32.5x N/A Encap 0.9x / 5.2x 1.1x / 10.3x N/A 43
44 NetFPFA Function Resource Utilization Min / Max LUTs Registers BRAMs Input arbiter 2.1x / 3.4x 1.8x / 2.8x 0.9x / 1.3x Output queue 1.4x / 2.0x 2.0x / 3.2x 0.9x / 1.2x Header parser 0.9x / 3.2x 2.1x / 3.2x N/A Openflow table 0.9x / 1.6x 1.6x / 2.3x 1.1x / 1.2x IP checksum 4.3x / 12.1x 9.7x / 32.5x N/A Encap 0.9x / 5.2x 1.1x / 10.3x N/A 44
45 NetFPFA Function Resource Utilization Min / Max LUTs Registers BRAMs Input arbiter 2.1x / 3.4x 1.8x / 2.8x 0.9x / 1.3x Output queue 1.4x / 2.0x 2.0x / 3.2x 0.9x / 1.2x Header parser 0.9x / 3.2x 2.1x / 3.2x N/A Openflow table 0.9x / 1.6x 1.6x / 2.3x 1.1x / 1.2x IP checksum 4.3x / 12.1x 9.7x / 32.5x N/A Encap 0.9x / 5.2x 1.1x / 10.3x N/A 45
46 Click! N P 46



47 Click! N P
48 48
49 49



50 GPU NP FPGA Throughput High High High Latency High Low Low Power High Low Low General computing Yes No Yes 50
51 51
52 52
53 Define elements Define a configuration of elements Host manager program Windows/Linux, Altera/Xilinx 53
54 A B C Communicate by sharing memory Shared memory is the bottleneck! Batch processing has large latency! 54
55 A B C Do not communicate by sharing memory; instead, share memory by communicating. -- The slogan of Go language 55


56 Read key Check key Read counter Read Check Read Inc Write Read Check Read Inc Wr Increment R1 C1 R2 I2 W2 Write counter R1 C1 R2 I2 W2 56
57 Input Input Input sum i<4 Input Cksum Cksum Input Cksum sum sum += pkt[0] Cksum Cksum i<4 sum sum += pkt[1] Cksum Output Cksum Cksum sum += pkt[i] i<4 sum += pkt[2] Output i<4 sum sum += pkt[3] Output i<4 Output Input Output 57
58 Read Read Cache Hit? Slow path Slow element Output Read Read Cache Slow path Slow path Hit? To slow element Slow path Output Output Output Output 58
PacketShader: A GPU-Accelerated Software Router
 PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
PacketShader: A GPU-Accelerated Software Router Sangjin Han In collaboration with: Keon Jang, KyoungSoo Park, Sue Moon Advanced Networking Lab, CS, KAIST Networked and Distributed Computing Systems Lab,
Fast packet processing in the cloud. Dániel Géhberger Ericsson Research
 Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
SmartNIC Programming Models
 SmartNIC Programming Models Johann Tönsing 206--09 206 Open-NFP Agenda SmartNIC hardware Pre-programmed vs. custom (C and/or P4) firmware Programming models / offload models Switching on NIC, with SR-IOV
SmartNIC Programming Models Johann Tönsing 206--09 206 Open-NFP Agenda SmartNIC hardware Pre-programmed vs. custom (C and/or P4) firmware Programming models / offload models Switching on NIC, with SR-IOV
Providing Multi-tenant Services with FPGAs: Case Study on a Key-Value Store
 Zsolt István *, Gustavo Alonso, Ankit Singla Systems Group, Computer Science Dept., ETH Zürich * Now at IMDEA Software Institute, Madrid Providing Multi-tenant Services with FPGAs: Case Study on a Key-Value
Zsolt István *, Gustavo Alonso, Ankit Singla Systems Group, Computer Science Dept., ETH Zürich * Now at IMDEA Software Institute, Madrid Providing Multi-tenant Services with FPGAs: Case Study on a Key-Value
The Power of Batching in the Click Modular Router
 The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
SmartNIC Programming Models
 SmartNIC Programming Models Johann Tönsing 207-06-07 207 Open-NFP Agenda SmartNIC hardware Pre-programmed vs. custom (C and/or P4) firmware Programming models / offload models Switching on NIC, with SR-IOV
SmartNIC Programming Models Johann Tönsing 207-06-07 207 Open-NFP Agenda SmartNIC hardware Pre-programmed vs. custom (C and/or P4) firmware Programming models / offload models Switching on NIC, with SR-IOV
G-NET: Effective GPU Sharing in NFV Systems
 G-NET: Effective GPU Sharing in NFV Systems Kai Zhang, Bingsheng He, Jiayu Hu, Zeke Wang, Bei Hua, Jiayi Meng, Lishan Yang Fudan University National University of Singapore University of Science and Technology
G-NET: Effective GPU Sharing in NFV Systems Kai Zhang, Bingsheng He, Jiayu Hu, Zeke Wang, Bei Hua, Jiayi Meng, Lishan Yang Fudan University National University of Singapore University of Science and Technology
CSE 123A Computer Networks
 CSE 123A Computer Networks Winter 2005 Lecture 8: IP Router Design Many portions courtesy Nick McKeown Overview Router basics Interconnection architecture Input Queuing Output Queuing Virtual output Queuing
CSE 123A Computer Networks Winter 2005 Lecture 8: IP Router Design Many portions courtesy Nick McKeown Overview Router basics Interconnection architecture Input Queuing Output Queuing Virtual output Queuing
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
DPDK Summit China 2017
 Summit China 2017 Embedded Network Architecture Optimization Based on Lin Hao T1 Networks Agenda Our History What is an embedded network device Challenge to us Requirements for device today Our solution
Summit China 2017 Embedded Network Architecture Optimization Based on Lin Hao T1 Networks Agenda Our History What is an embedded network device Challenge to us Requirements for device today Our solution
Towards High-performance Flow-level level Packet Processing on Multi-core Network Processors
 Towards High-performance Flow-level level Packet Processing on Multi-core Network Processors Yaxuan Qi (presenter), Bo Xu, Fei He, Baohua Yang, Jianming Yu and Jun Li ANCS 2007, Orlando, USA Outline Introduction
Towards High-performance Flow-level level Packet Processing on Multi-core Network Processors Yaxuan Qi (presenter), Bo Xu, Fei He, Baohua Yang, Jianming Yu and Jun Li ANCS 2007, Orlando, USA Outline Introduction
Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel
 Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel David Lebrun, Olivier Bonaventure ICTEAM, UCLouvain Work supported by ARC grant 12/18-054 (ARC-SDN) and a Cisco grant Agenda IPv6 Segment Rou'ng Implementa'on
Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel David Lebrun, Olivier Bonaventure ICTEAM, UCLouvain Work supported by ARC grant 12/18-054 (ARC-SDN) and a Cisco grant Agenda IPv6 Segment Rou'ng Implementa'on
G-NET: Effective GPU Sharing In NFV Systems
 G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
G-NET: Effective Sharing In NFV Systems Kai Zhang*, Bingsheng He^, Jiayu Hu #, Zeke Wang^, Bei Hua #, Jiayi Meng #, Lishan Yang # *Fudan University ^National University of Singapore #University of Science
Overview. Implementing Gigabit Routers with NetFPGA. Basic Architectural Components of an IP Router. Per-packet processing in an IP Router
 Overview Implementing Gigabit Routers with NetFPGA Prof. Sasu Tarkoma The NetFPGA is a low-cost platform for teaching networking hardware and router design, and a tool for networking researchers. The NetFPGA
Overview Implementing Gigabit Routers with NetFPGA Prof. Sasu Tarkoma The NetFPGA is a low-cost platform for teaching networking hardware and router design, and a tool for networking researchers. The NetFPGA
The dark powers on Intel processor boards
 The dark powers on Intel processor boards Processing Resources (3U VPX) Boards with Multicore CPUs: Up to 16 cores using Intel Xeon D-1577 on TR C4x/msd Boards with 4-Core CPUs and Multiple Graphical Execution
The dark powers on Intel processor boards Processing Resources (3U VPX) Boards with Multicore CPUs: Up to 16 cores using Intel Xeon D-1577 on TR C4x/msd Boards with 4-Core CPUs and Multiple Graphical Execution
On the cost of tunnel endpoint processing in overlay virtual networks
 J. Weerasinghe; NVSDN2014, London; 8 th December 2014 On the cost of tunnel endpoint processing in overlay virtual networks J. Weerasinghe & F. Abel IBM Research Zurich Laboratory Outline Motivation Overlay
J. Weerasinghe; NVSDN2014, London; 8 th December 2014 On the cost of tunnel endpoint processing in overlay virtual networks J. Weerasinghe & F. Abel IBM Research Zurich Laboratory Outline Motivation Overlay
NetFPGA Hardware Architecture
 NetFPGA Hardware Architecture Jeffrey Shafer Some slides adapted from Stanford NetFPGA tutorials NetFPGA http://netfpga.org 2 NetFPGA Components Virtex-II Pro 5 FPGA 53,136 logic cells 4,176 Kbit block
NetFPGA Hardware Architecture Jeffrey Shafer Some slides adapted from Stanford NetFPGA tutorials NetFPGA http://netfpga.org 2 NetFPGA Components Virtex-II Pro 5 FPGA 53,136 logic cells 4,176 Kbit block
GPGPU introduction and network applications. PacketShaders, SSLShader
 GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
Experience with the NetFPGA Program
 Experience with the NetFPGA Program John W. Lockwood Algo-Logic Systems Algo-Logic.com With input from the Stanford University NetFPGA Group & Xilinx XUP Program Sunday, February 21, 2010 FPGA-2010 Pre-Conference
Experience with the NetFPGA Program John W. Lockwood Algo-Logic Systems Algo-Logic.com With input from the Stanford University NetFPGA Group & Xilinx XUP Program Sunday, February 21, 2010 FPGA-2010 Pre-Conference
P51: High Performance Networking
 P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
P51: High Performance Networking Lecture 6: Programmable network devices Dr Noa Zilberman noa.zilberman@cl.cam.ac.uk Lent 2017/18 High Throughput Interfaces Performance Limitations So far we discussed
An FPGA-based In-line Accelerator for Memcached
 An FPGA-based In-line Accelerator for Memcached MAYSAM LAVASANI, HARI ANGEPAT, AND DEREK CHIOU THE UNIVERSITY OF TEXAS AT AUSTIN 1 Challenges for Server Processors Workload changes Social networking Cloud
An FPGA-based In-line Accelerator for Memcached MAYSAM LAVASANI, HARI ANGEPAT, AND DEREK CHIOU THE UNIVERSITY OF TEXAS AT AUSTIN 1 Challenges for Server Processors Workload changes Social networking Cloud
Lecture 16: Router Design
 Lecture 16: Router Design CSE 123: Computer Networks Alex C. Snoeren Eample courtesy Mike Freedman Lecture 16 Overview End-to-end lookup and forwarding example Router internals Buffering Scheduling 2 Example:
Lecture 16: Router Design CSE 123: Computer Networks Alex C. Snoeren Eample courtesy Mike Freedman Lecture 16 Overview End-to-end lookup and forwarding example Router internals Buffering Scheduling 2 Example:
Introduction to the OpenCAPI Interface
 Introduction to the OpenCAPI Interface Brian Allison, STSM OpenCAPI Technology and Enablement Speaker name, Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration
Introduction to the OpenCAPI Interface Brian Allison, STSM OpenCAPI Technology and Enablement Speaker name, Title Company/Organization Name Join the Conversation #OpenPOWERSummit Industry Collaboration
Programming Netronome Agilio SmartNICs
 WHITE PAPER Programming Netronome Agilio SmartNICs NFP-4000 AND NFP-6000 FAMILY: SUPPORTED PROGRAMMING MODELS THE AGILIO SMARTNICS DELIVER HIGH- PERFORMANCE SERVER- BASED NETWORKING APPLICATIONS SUCH AS
WHITE PAPER Programming Netronome Agilio SmartNICs NFP-4000 AND NFP-6000 FAMILY: SUPPORTED PROGRAMMING MODELS THE AGILIO SMARTNICS DELIVER HIGH- PERFORMANCE SERVER- BASED NETWORKING APPLICATIONS SUCH AS
Design principles in parser design
 Design principles in parser design Glen Gibb Dept. of Electrical Engineering Advisor: Prof. Nick McKeown Header parsing? 2 Header parsing? Identify headers & extract fields A???? B???? C?? Field Field
Design principles in parser design Glen Gibb Dept. of Electrical Engineering Advisor: Prof. Nick McKeown Header parsing? 2 Header parsing? Identify headers & extract fields A???? B???? C?? Field Field
Hillstone IPSec VPN Solution
 1. Introduction With the explosion of Internet, more and more companies move their network infrastructure from private lease line to internet. Internet provides a significant cost advantage over private
1. Introduction With the explosion of Internet, more and more companies move their network infrastructure from private lease line to internet. Internet provides a significant cost advantage over private
RouteBricks: Exploiting Parallelism To Scale Software Routers
 outebricks: Exploiting Parallelism To Scale Software outers Mihai Dobrescu & Norbert Egi, Katerina Argyraki, Byung-Gon Chun, Kevin Fall, Gianluca Iannaccone, Allan Knies, Maziar Manesh, Sylvia atnasamy
outebricks: Exploiting Parallelism To Scale Software outers Mihai Dobrescu & Norbert Egi, Katerina Argyraki, Byung-Gon Chun, Kevin Fall, Gianluca Iannaccone, Allan Knies, Maziar Manesh, Sylvia atnasamy
Tracking Acceleration with FPGAs. Future Tracking, CMS Week 4/12/17 Sioni Summers
 Tracking Acceleration with FPGAs Future Tracking, CMS Week 4/12/17 Sioni Summers Contents Introduction FPGAs & 'DataFlow Engines' for computing Device architecture Maxeler HLT Tracking Acceleration 2 Introduction
Tracking Acceleration with FPGAs Future Tracking, CMS Week 4/12/17 Sioni Summers Contents Introduction FPGAs & 'DataFlow Engines' for computing Device architecture Maxeler HLT Tracking Acceleration 2 Introduction
vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018
 x vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018 Current Network Solution for Virtualization Control Plane Control Plane virtio virtio user space PF VF2 user space TAP1 SW Datapath
x vswitch Acceleration with Hardware Offloading CHEN ZHIHUI JUNE 2018 Current Network Solution for Virtualization Control Plane Control Plane virtio virtio user space PF VF2 user space TAP1 SW Datapath
Packet Manipulator Processor: A RISC-V VLIW core for networking applications
 Packet Manipulator Processor: A RISC-V VLIW core for networking applications Salvatore Pontarelli, Marco Bonola, Marco Spaziani Brunella, Giuseppe Bianchi Speaker: Salvatore Pontarelli Introduction Network
Packet Manipulator Processor: A RISC-V VLIW core for networking applications Salvatore Pontarelli, Marco Bonola, Marco Spaziani Brunella, Giuseppe Bianchi Speaker: Salvatore Pontarelli Introduction Network
Routers Technologies & Evolution for High-Speed Networks
 Routers Technologies & Evolution for High-Speed Networks C. Pham Université de Pau et des Pays de l Adour http://www.univ-pau.fr/~cpham Congduc.Pham@univ-pau.fr Router Evolution slides from Nick McKeown,
Routers Technologies & Evolution for High-Speed Networks C. Pham Université de Pau et des Pays de l Adour http://www.univ-pau.fr/~cpham Congduc.Pham@univ-pau.fr Router Evolution slides from Nick McKeown,
P4FPGA Expedition. Han Wang
 P4FPGA Expedition Han Wang Ki Suh Lee, Vishal Shrivastav, Hakim Weatherspoon, Nate Foster, Robert Soule 1 Cornell University 1 Università della Svizzera italiana Networking and Programming Language Workshop
P4FPGA Expedition Han Wang Ki Suh Lee, Vishal Shrivastav, Hakim Weatherspoon, Nate Foster, Robert Soule 1 Cornell University 1 Università della Svizzera italiana Networking and Programming Language Workshop
Day 2: NetFPGA Cambridge Workshop Module Development and Testing
 Day 2: NetFPGA Cambridge Workshop Module Development and Testing Presented by: Andrew W. Moore and David Miller (University of Cambridge) Martin Žádník (Brno University of Technology) Cambridge UK September
Day 2: NetFPGA Cambridge Workshop Module Development and Testing Presented by: Andrew W. Moore and David Miller (University of Cambridge) Martin Žádník (Brno University of Technology) Cambridge UK September
NetFPGA Update at GEC4
 NetFPGA Update at GEC4 http://netfpga.org/ NSF GENI Engineering Conference 4 (GEC4) March 31, 2009 John W. Lockwood http://stanford.edu/~jwlockwd/ jwlockwd@stanford.edu NSF GEC4 1 March 2009 What is the
NetFPGA Update at GEC4 http://netfpga.org/ NSF GENI Engineering Conference 4 (GEC4) March 31, 2009 John W. Lockwood http://stanford.edu/~jwlockwd/ jwlockwd@stanford.edu NSF GEC4 1 March 2009 What is the
Gateware Defined Networking (GDN) for Ultra Low Latency Trading and Compliance
 for Ultra Low Latency Trading and Compliance") Gateware Defined Networking (GDN) for Ultra Low Latency Trading and Compliance STAC Summit: Panel: FPGA for trading today: December 2015 John W. Lockwood, PhD, CEO Algo-Logic Systems, Inc. JWLockwd@algo-logic.com
Gateware Defined Networking (GDN) for Ultra Low Latency Trading and Compliance STAC Summit: Panel: FPGA for trading today: December 2015 John W. Lockwood, PhD, CEO Algo-Logic Systems, Inc. JWLockwd@algo-logic.com
CMU /618 Practice Exercise 1
 CMU 15-418/618 Practice Exercise 1 A Task Queue on a Multi-Core, Multi-Threaded CPU The figure below shows a simple single-core CPU with an and execution contexts for up to two threads of control. Core
CMU 15-418/618 Practice Exercise 1 A Task Queue on a Multi-Core, Multi-Threaded CPU The figure below shows a simple single-core CPU with an and execution contexts for up to two threads of control. Core
Programmable Software Switches. Lecture 11, Computer Networks (198:552)
") Programmable Software Switches Lecture 11, Computer Networks (198:552) Software-Defined Network (SDN) Centralized control plane Data plane Data plane Data plane Data plane Why software switching? Early
Programmable Software Switches Lecture 11, Computer Networks (198:552) Software-Defined Network (SDN) Centralized control plane Data plane Data plane Data plane Data plane Why software switching? Early
Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
 University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
University of Crete School of Sciences & Engineering Computer Science Department Master Thesis by Michael Papamichael Network Interface Architecture and Prototyping for Chip and Cluster Multiprocessors
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
High Performance Packet Processing with FlexNIC
 High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
Programming NFP with P4 and C
 WHITE PAPER Programming NFP with P4 and C THE NFP FAMILY OF FLOW PROCESSORS ARE SOPHISTICATED PROCESSORS SPECIALIZED TOWARDS HIGH-PERFORMANCE FLOW PROCESSING. CONTENTS INTRODUCTION...1 PROGRAMMING THE
WHITE PAPER Programming NFP with P4 and C THE NFP FAMILY OF FLOW PROCESSORS ARE SOPHISTICATED PROCESSORS SPECIALIZED TOWARDS HIGH-PERFORMANCE FLOW PROCESSING. CONTENTS INTRODUCTION...1 PROGRAMMING THE
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Trying to design a simple yet efficient L1 cache. Jean-François Nguyen
 Trying to design a simple yet efficient L1 cache Jean-François Nguyen 1 Background Minerva is a 32-bit RISC-V soft CPU It is described in plain Python using nmigen FPGA-friendly Designed for reasonable
Trying to design a simple yet efficient L1 cache Jean-François Nguyen 1 Background Minerva is a 32-bit RISC-V soft CPU It is described in plain Python using nmigen FPGA-friendly Designed for reasonable
This document provides an overview of buffer tuning based on current platforms, and gives general information about the show buffers command.
 Contents Introduction Prerequisites Requirements Components Used Conventions General Overview Low-End Platforms (Cisco 1600, 2500, and 4000 Series Routers) High-End Platforms (Route Processors, Switch
Contents Introduction Prerequisites Requirements Components Used Conventions General Overview Low-End Platforms (Cisco 1600, 2500, and 4000 Series Routers) High-End Platforms (Route Processors, Switch
Lecture 17: Router Design
 Lecture 17: Router Design CSE 123: Computer Networks Alex C. Snoeren Eample courtesy Mike Freedman Lecture 17 Overview Finish up BGP relationships Router internals Buffering Scheduling 2 Peer-to-Peer Relationship
Lecture 17: Router Design CSE 123: Computer Networks Alex C. Snoeren Eample courtesy Mike Freedman Lecture 17 Overview Finish up BGP relationships Router internals Buffering Scheduling 2 Peer-to-Peer Relationship
GPUs have enormous power that is enormously difficult to use
 524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
524 GPUs GPUs have enormous power that is enormously difficult to use Nvidia GP100-5.3TFlops of double precision This is equivalent to the fastest super computer in the world in 2001; put a single rack
Router Architectures
 Router Architectures Venkat Padmanabhan Microsoft Research 13 April 2001 Venkat Padmanabhan 1 Outline Router architecture overview 50 Gbps multi-gigabit router (Partridge et al.) Technology trends Venkat
Router Architectures Venkat Padmanabhan Microsoft Research 13 April 2001 Venkat Padmanabhan 1 Outline Router architecture overview 50 Gbps multi-gigabit router (Partridge et al.) Technology trends Venkat
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Overview of ROCCC 2.0
 Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
Overview of ROCCC 2.0 Walid Najjar and Jason Villarreal SUMMARY FPGAs have been shown to be powerful platforms for hardware code acceleration. However, their poor programmability is the main impediment
Design of a Web Switch in a Reconfigurable Platform
 ANCS 2006 ACM/IEEE Symposium on Architectures for Networking and Communications Systems December 4-5, 2006 San Jose, California, USA Design of a Web Switch in a Reconfigurable Platform Christoforos Kachris
ANCS 2006 ACM/IEEE Symposium on Architectures for Networking and Communications Systems December 4-5, 2006 San Jose, California, USA Design of a Web Switch in a Reconfigurable Platform Christoforos Kachris
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
Cloud Networking (VITMMA02) Network Virtualization: Overlay Networks OpenStack Neutron Networking
 Network Virtualization: Overlay Networks OpenStack Neutron Networking") Cloud Networking (VITMMA02) Network Virtualization: Overlay Networks OpenStack Neutron Networking Markosz Maliosz PhD Department of Telecommunications and Media Informatics Faculty of Electrical Engineering
Cloud Networking (VITMMA02) Network Virtualization: Overlay Networks OpenStack Neutron Networking Markosz Maliosz PhD Department of Telecommunications and Media Informatics Faculty of Electrical Engineering
Parallelizing IPsec: switching SMP to On is not even half the way
 Parallelizing IPsec: switching SMP to On is not even half the way Steffen Klassert secunet Security Networks AG Dresden June 11 2010 Table of contents Some basics about IPsec About the IPsec performance
Parallelizing IPsec: switching SMP to On is not even half the way Steffen Klassert secunet Security Networks AG Dresden June 11 2010 Table of contents Some basics about IPsec About the IPsec performance
Survey of ETSI NFV standardization documents BY ABHISHEK GUPTA FRIDAY GROUP MEETING FEBRUARY 26, 2016
 Survey of ETSI NFV standardization documents BY ABHISHEK GUPTA FRIDAY GROUP MEETING FEBRUARY 26, 2016 VNFaaS (Virtual Network Function as a Service) In our present work, we consider the VNFaaS use-case
Survey of ETSI NFV standardization documents BY ABHISHEK GUPTA FRIDAY GROUP MEETING FEBRUARY 26, 2016 VNFaaS (Virtual Network Function as a Service) In our present work, we consider the VNFaaS use-case
Scalability Considerations
 CHAPTER 3 This chapter presents the steps to selecting products for a VPN solution, starting with sizing the headend, and then choosing products that can be deployed for headend devices. This chapter concludes
CHAPTER 3 This chapter presents the steps to selecting products for a VPN solution, starting with sizing the headend, and then choosing products that can be deployed for headend devices. This chapter concludes
LegUp: Accelerating Memcached on Cloud FPGAs
 0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
0 LegUp: Accelerating Memcached on Cloud FPGAs Xilinx Developer Forum December 10, 2018 Andrew Canis & Ruolong Lian LegUp Computing Inc. 1 COMPUTE IS BECOMING SPECIALIZED 1 GPU Nvidia graphics cards are
HKG net_mdev: Fast-path userspace I/O. Ilias Apalodimas Mykyta Iziumtsev François-Frédéric Ozog
 HKG18-110 net_mdev: Fast-path userspace I/O Ilias Apalodimas Mykyta Iziumtsev François-Frédéric Ozog Why userland I/O Time sensitive networking Developed mostly for Industrial IOT, automotive and audio/video
HKG18-110 net_mdev: Fast-path userspace I/O Ilias Apalodimas Mykyta Iziumtsev François-Frédéric Ozog Why userland I/O Time sensitive networking Developed mostly for Industrial IOT, automotive and audio/video
Parallelizing FPGA Technology Mapping using GPUs. Doris Chen Deshanand Singh Aug 31 st, 2010
 Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
GRVI Phalanx Update: Plowing the Cloud with Thousands of RISC-V Chickens. Jan Gray
 If you were plowing a field, which would you rather use: two strong oxen or 1024 chickens? Seymour Cray GRVI Phalanx Update: Plowing the Cloud with Thousands of RISC-V Chickens Jan Gray jan@fpga.org http://fpga.org
If you were plowing a field, which would you rather use: two strong oxen or 1024 chickens? Seymour Cray GRVI Phalanx Update: Plowing the Cloud with Thousands of RISC-V Chickens Jan Gray jan@fpga.org http://fpga.org
Topics for Today. Network Layer. Readings. Introduction Addressing Address Resolution. Sections 5.1,
 Topics for Today Network Layer Introduction Addressing Address Resolution Readings Sections 5.1, 5.6.1-5.6.2 1 Network Layer: Introduction A network-wide concern! Transport layer Between two end hosts
Topics for Today Network Layer Introduction Addressing Address Resolution Readings Sections 5.1, 5.6.1-5.6.2 1 Network Layer: Introduction A network-wide concern! Transport layer Between two end hosts
Open Source Traffic Analyzer
 Open Source Traffic Analyzer Daniel Turull June 2010 Outline 1 Introduction 2 Background study 3 Design 4 Implementation 5 Evaluation 6 Conclusions 7 Demo Outline 1 Introduction 2 Background study 3 Design
Open Source Traffic Analyzer Daniel Turull June 2010 Outline 1 Introduction 2 Background study 3 Design 4 Implementation 5 Evaluation 6 Conclusions 7 Demo Outline 1 Introduction 2 Background study 3 Design
INT 1011 TCP Offload Engine (Full Offload)
") INT 1011 TCP Offload Engine (Full Offload) Product brief, features and benefits summary Provides lowest Latency and highest bandwidth. Highly customizable hardware IP block. Easily portable to ASIC flow,
INT 1011 TCP Offload Engine (Full Offload) Product brief, features and benefits summary Provides lowest Latency and highest bandwidth. Highly customizable hardware IP block. Easily portable to ASIC flow,
Tile Processor (TILEPro64)
") Tile Processor Case Study of Contemporary Multicore Fall 2010 Agarwal 6.173 1 Tile Processor (TILEPro64) Performance # of cores On-chip cache (MB) Cache coherency Operations (16/32-bit BOPS) On chip bandwidth
Tile Processor Case Study of Contemporary Multicore Fall 2010 Agarwal 6.173 1 Tile Processor (TILEPro64) Performance # of cores On-chip cache (MB) Cache coherency Operations (16/32-bit BOPS) On chip bandwidth
Much Faster Networking
 Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
Much Faster Networking David Riddoch driddoch@solarflare.com Copyright 2016 Solarflare Communications, Inc. All rights reserved. What is kernel bypass? The standard receive path The standard receive path
Scrypt ASIC Prototyping Preliminary Design Document
 Scrypt ASIC Prototyping Preliminary Design Document 1/13 Revision History Version Date Author Remarks Approved by v0.1 2/13 Contents 1 Scrypt Algorithm... 5 2 Major blocks in a Scrypt core... 6 3 Internal
Scrypt ASIC Prototyping Preliminary Design Document 1/13 Revision History Version Date Author Remarks Approved by v0.1 2/13 Contents 1 Scrypt Algorithm... 5 2 Major blocks in a Scrypt core... 6 3 Internal
Network Processors Outline
 High-Performance Networking The University of Kansas EECS 881 James P.G. Sterbenz Department of Electrical Engineering & Computer Science Information Technology & Telecommunications Research Center The
High-Performance Networking The University of Kansas EECS 881 James P.G. Sterbenz Department of Electrical Engineering & Computer Science Information Technology & Telecommunications Research Center The
Making Network Functions Software-Defined
 Making Network Functions Software-Defined Yotam Harchol VMware Research / The Hebrew University of Jerusalem Joint work with Anat Bremler-Barr and David Hay Appeared in ACM SIGCOMM 2016 THE HEBREW UNIVERSITY
Making Network Functions Software-Defined Yotam Harchol VMware Research / The Hebrew University of Jerusalem Joint work with Anat Bremler-Barr and David Hay Appeared in ACM SIGCOMM 2016 THE HEBREW UNIVERSITY
Extreme TCP Speed on GbE
 TOE1G-IP Introduction (Xilinx) Ver1.1E Extreme TCP Speed on GbE Design Gateway Page 1 Agenda Advantage and Disadvantage of TCP on GbE TOE1G-IP core overview TOE1G-IP core description Initialization High-speed
TOE1G-IP Introduction (Xilinx) Ver1.1E Extreme TCP Speed on GbE Design Gateway Page 1 Agenda Advantage and Disadvantage of TCP on GbE TOE1G-IP core overview TOE1G-IP core description Initialization High-speed
Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference
 The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
The 2017 IEEE International Symposium on Workload Characterization Performance Characterization, Prediction, and Optimization for Heterogeneous Systems with Multi-Level Memory Interference Shin-Ying Lee
Comparing TCP performance of tunneled and non-tunneled traffic using OpenVPN. Berry Hoekstra Damir Musulin OS3 Supervisor: Jan Just Keijser Nikhef
 Comparing TCP performance of tunneled and non-tunneled traffic using OpenVPN Berry Hoekstra Damir Musulin OS3 Supervisor: Jan Just Keijser Nikhef Outline Introduction Approach Research Results Conclusion
Comparing TCP performance of tunneled and non-tunneled traffic using OpenVPN Berry Hoekstra Damir Musulin OS3 Supervisor: Jan Just Keijser Nikhef Outline Introduction Approach Research Results Conclusion
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou
 SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou University of California, Los Angeles 1 What is stencil computation? 2 What is Stencil Computation? A sliding
SODA: Stencil with Optimized Dataflow Architecture Yuze Chi, Jason Cong, Peng Wei, Peipei Zhou University of California, Los Angeles 1 What is stencil computation? 2 What is Stencil Computation? A sliding
LegUp HLS Tutorial for Microsemi PolarFire Sobel Filtering for Image Edge Detection
 LegUp HLS Tutorial for Microsemi PolarFire Sobel Filtering for Image Edge Detection This tutorial will introduce you to high-level synthesis (HLS) concepts using LegUp. You will apply HLS to a real problem:
LegUp HLS Tutorial for Microsemi PolarFire Sobel Filtering for Image Edge Detection This tutorial will introduce you to high-level synthesis (HLS) concepts using LegUp. You will apply HLS to a real problem:
Exploration of Cache Coherent CPU- FPGA Heterogeneous System
 Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Exploration of Cache Coherent CPU- FPGA Heterogeneous System Wei Zhang Department of Electronic and Computer Engineering Hong Kong University of Science and Technology 1 Outline ointroduction to FPGA-based
Programmable NICs. Lecture 14, Computer Networks (198:552)
") Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Introduction to FPGA Design with Vivado High-Level Synthesis. UG998 (v1.0) July 2, 2013
 July 2, 2013") Introduction to FPGA Design with Vivado High-Level Synthesis Notice of Disclaimer The information disclosed to you hereunder (the Materials ) is provided solely for the selection and use of Xilinx products.
Introduction to FPGA Design with Vivado High-Level Synthesis Notice of Disclaimer The information disclosed to you hereunder (the Materials ) is provided solely for the selection and use of Xilinx products.
Be Fast, Cheap and in Control with SwitchKV. Xiaozhou Li
 Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Goal: fast and cost-efficient key-value store Store, retrieve, manage key-value objects Get(key)/Put(key,value)/Delete(key) Target: cluster-level
Be Fast, Cheap and in Control with SwitchKV Xiaozhou Li Goal: fast and cost-efficient key-value store Store, retrieve, manage key-value objects Get(key)/Put(key,value)/Delete(key) Target: cluster-level
An Intelligent NIC Design Xin Song
 2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) An Intelligent NIC Design Xin Song School of Electronic and Information Engineering Tianjin Vocational
2nd International Conference on Advances in Mechanical Engineering and Industrial Informatics (AMEII 2016) An Intelligent NIC Design Xin Song School of Electronic and Information Engineering Tianjin Vocational
OVS Acceleration using Network Flow Processors
 Acceleration using Network Processors Johann Tönsing 2014-11-18 1 Agenda Background: on Network Processors Network device types => features required => acceleration concerns Acceleration Options (or )
Acceleration using Network Processors Johann Tönsing 2014-11-18 1 Agenda Background: on Network Processors Network device types => features required => acceleration concerns Acceleration Options (or )
Introducing the Cray XMT. Petr Konecny May 4 th 2007
 Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Introducing the Cray XMT Petr Konecny May 4 th 2007 Agenda Origins of the Cray XMT Cray XMT system architecture Cray XT infrastructure Cray Threadstorm processor Shared memory programming model Benefits/drawbacks/solutions
Today s Data Centers. How can we improve efficiencies?
 Today s Data Centers O(100K) servers/data center Tens of MegaWatts, difficult to power and cool Very noisy Security taken very seriously Incrementally upgraded 3 year server depreciation, upgraded quarterly
Today s Data Centers O(100K) servers/data center Tens of MegaWatts, difficult to power and cool Very noisy Security taken very seriously Incrementally upgraded 3 year server depreciation, upgraded quarterly
Ultra-Fast NoC Emulation on a Single FPGA
 The 25 th International Conference on Field-Programmable Logic and Applications (FPL 2015) September 3, 2015 Ultra-Fast NoC Emulation on a Single FPGA Thiem Van Chu, Shimpei Sato, and Kenji Kise Tokyo
The 25 th International Conference on Field-Programmable Logic and Applications (FPL 2015) September 3, 2015 Ultra-Fast NoC Emulation on a Single FPGA Thiem Van Chu, Shimpei Sato, and Kenji Kise Tokyo
AN 831: Intel FPGA SDK for OpenCL
 AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread Subscribe Send Feedback Latest document on the web: PDF HTML Contents Contents 1 Intel FPGA SDK for OpenCL Host Pipelined Multithread...3 1.1
Bringing the Power of ebpf to Open vswitch. Linux Plumber 2018 William Tu, Joe Stringer, Yifeng Sun, Yi-Hung Wei VMware Inc. and Cilium.
 Bringing the Power of ebpf to Open vswitch Linux Plumber 2018 William Tu, Joe Stringer, Yifeng Sun, Yi-Hung Wei VMware Inc. and Cilium.io 1 Outline Introduction and Motivation OVS-eBPF Project OVS-AF_XDP
Bringing the Power of ebpf to Open vswitch Linux Plumber 2018 William Tu, Joe Stringer, Yifeng Sun, Yi-Hung Wei VMware Inc. and Cilium.io 1 Outline Introduction and Motivation OVS-eBPF Project OVS-AF_XDP
Introduction to Routers and LAN Switches
 Introduction to Routers and LAN Switches Session 3048_05_2001_c1 2001, Cisco Systems, Inc. All rights reserved. 3 Prerequisites OSI Model Networking Fundamentals 3048_05_2001_c1 2001, Cisco Systems, Inc.
Introduction to Routers and LAN Switches Session 3048_05_2001_c1 2001, Cisco Systems, Inc. All rights reserved. 3 Prerequisites OSI Model Networking Fundamentals 3048_05_2001_c1 2001, Cisco Systems, Inc.
Table of Contents. Cisco Buffer Tuning for all Cisco Routers
 Table of Contents Buffer Tuning for all Cisco Routers...1 Interactive: This document offers customized analysis of your Cisco device...1 Introduction...1 Prerequisites...1 Requirements...1 Components Used...1
Table of Contents Buffer Tuning for all Cisco Routers...1 Interactive: This document offers customized analysis of your Cisco device...1 Introduction...1 Prerequisites...1 Requirements...1 Components Used...1
ntop Users Group Meeting
 ntop Users Group Meeting PF_RING Tutorial Alfredo Cardigliano Overview Introduction Installation Configuration Tuning Use cases PF_RING Open source packet processing framework for
ntop Users Group Meeting PF_RING Tutorial Alfredo Cardigliano Overview Introduction Installation Configuration Tuning Use cases PF_RING Open source packet processing framework for
Zilog Real-Time Kernel
 An Company Configurable Compilation RZK allows you to specify system parameters at compile time. For example, the number of objects, such as threads and semaphores required, are specez80acclaim! Family
An Company Configurable Compilation RZK allows you to specify system parameters at compile time. For example, the number of objects, such as threads and semaphores required, are specez80acclaim! Family
Netronome NFP: Theory of Operation
 WHITE PAPER Netronome NFP: Theory of Operation TO ACHIEVE PERFORMANCE GOALS, A MULTI-CORE PROCESSOR NEEDS AN EFFICIENT DATA MOVEMENT ARCHITECTURE. CONTENTS 1. INTRODUCTION...1 2. ARCHITECTURE OVERVIEW...2
WHITE PAPER Netronome NFP: Theory of Operation TO ACHIEVE PERFORMANCE GOALS, A MULTI-CORE PROCESSOR NEEDS AN EFFICIENT DATA MOVEMENT ARCHITECTURE. CONTENTS 1. INTRODUCTION...1 2. ARCHITECTURE OVERVIEW...2
An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware
 An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware Tao Chen, Shreesha Srinath Christopher Batten, G. Edward Suh Computer Systems Laboratory School of Electrical
An Architectural Framework for Accelerating Dynamic Parallel Algorithms on Reconfigurable Hardware Tao Chen, Shreesha Srinath Christopher Batten, G. Edward Suh Computer Systems Laboratory School of Electrical
Did I Just Do That on a Bunch of FPGAs?
 Did I Just Do That on a Bunch of FPGAs? Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto About the Talk Title It s the measure
Did I Just Do That on a Bunch of FPGAs? Paul Chow High-Performance Reconfigurable Computing Group Department of Electrical and Computer Engineering University of Toronto About the Talk Title It s the measure
The latency of user-to-user, kernel-to-kernel and interrupt-to-interrupt level communication
 The latency of user-to-user, kernel-to-kernel and interrupt-to-interrupt level communication John Markus Bjørndalen, Otto J. Anshus, Brian Vinter, Tore Larsen Department of Computer Science University
The latency of user-to-user, kernel-to-kernel and interrupt-to-interrupt level communication John Markus Bjørndalen, Otto J. Anshus, Brian Vinter, Tore Larsen Department of Computer Science University
Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no commitme
 NET1343BU NSX Performance Samuel Kommu #VMworld #NET1343BU Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no
NET1343BU NSX Performance Samuel Kommu #VMworld #NET1343BU Disclaimer This presentation may contain product features that are currently under development. This overview of new technology represents no
High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK
 High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK Sándor Laki Eötvös Loránd University Budapest, Hungary lakis@elte.hu Motivation Programmability of network data plane
High-Speed Forwarding: A P4 Compiler with a Hardware Abstraction Library for Intel DPDK Sándor Laki Eötvös Loránd University Budapest, Hungary lakis@elte.hu Motivation Programmability of network data plane
NAT Router Performance Evaluation
 University of Aizu, Graduation Thesis. Mar, 22 17173 1 NAT Performance Evaluation HAYASHI yu-ichi 17173 Supervised by Atsushi Kara Abstract This thesis describes a quantitative analysis of NAT routers
University of Aizu, Graduation Thesis. Mar, 22 17173 1 NAT Performance Evaluation HAYASHI yu-ichi 17173 Supervised by Atsushi Kara Abstract This thesis describes a quantitative analysis of NAT routers
Computer Networks CS 552
 Computer Networks CS 552 Routers Badri Nath Rutgers University badri@cs.rutgers.edu. High Speed Routers 2. Route lookups Cisco 26: 8 Gbps Cisco 246: 32 Gbps Cisco 286: 28 Gbps Power: 4.2 KW Cost: $5K Juniper
Computer Networks CS 552 Routers Badri Nath Rutgers University badri@cs.rutgers.edu. High Speed Routers 2. Route lookups Cisco 26: 8 Gbps Cisco 246: 32 Gbps Cisco 286: 28 Gbps Power: 4.2 KW Cost: $5K Juniper
Netchannel 2: Optimizing Network Performance
 Netchannel 2: Optimizing Network Performance J. Renato Santos +, G. (John) Janakiraman + Yoshio Turner +, Ian Pratt * + HP Labs - * XenSource/Citrix Xen Summit Nov 14-16, 2007 2003 Hewlett-Packard Development
Netchannel 2: Optimizing Network Performance J. Renato Santos +, G. (John) Janakiraman + Yoshio Turner +, Ian Pratt * + HP Labs - * XenSource/Citrix Xen Summit Nov 14-16, 2007 2003 Hewlett-Packard Development
Overlay Engine. VNS3 Plugins Guide 2018
 Overlay Engine VNS3 Plugins Guide 2018 Table of Contents Introduction 3 Overlay Engine Detail 7 Running the Overlay Engine Plugin 12 Overlay Engine Best Practices 20 Restrictions/Limitations 22 Resources
Overlay Engine VNS3 Plugins Guide 2018 Table of Contents Introduction 3 Overlay Engine Detail 7 Running the Overlay Engine Plugin 12 Overlay Engine Best Practices 20 Restrictions/Limitations 22 Resources
SDACCEL DEVELOPMENT ENVIRONMENT. The Xilinx SDAccel Development Environment. Bringing The Best Performance/Watt to the Data Center
 SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently