POWER6 Processor and Systems
|
|
|
- Maurice Small
- 5 years ago
- Views:
Transcription


1 POWER6 Processor and Systems Jim McInnes Compiler Optimization IBM Canada Toronto Software Lab
2 Role I am a Technical leader in the Compiler Optimization Team Focal point to the hardware development team Member of the Power ISA Architecture Board For each new microarchitecture I help direct the design toward helpful features Design and deliver specific compiler optimizations to enable hardware exploitation 2

3 POWER5 Chip Overview High frequency dual-core chip 8 execution units 2LS, 2FP, 2FX, 1BR, 1CR 1.9MB on-chip shared L2 point of coherency, 3 slices On-chip directory and controller On-chip memory controller Technology & Chip Stats 130nm lithography, Cu, SOI 276M transistors, 389 mm 2 I/Os: 2313 signal, 3057 Power/Gnd 3

4 POWER6 Chip Overview Ultra-high frequency dual-core chip 8 execution units 2LS, 2FP, 2FX, 1BR, 1VMX L2 QUAD IFU SDU LSU FXU RU Core0 FPU VMX L2 QUAD 2 x 4MB on-chip L2 point of coherency, 4 quads On-chip directory and controller L2 CNTL CNTL Two on-chip memory controllers Technology & Chip stats M C FBC GXC M C CMOS 65nm lithography, SOI Cu 790M transistors, 341 mm 2 die L2 CNTL CNTL I/Os: 1953 signal, 5399 Power/Gnd Full error checking and recovery (RU) L2 QUAD IFU LSU FXU L2 QUAD SDU FPU RU Core1 VMX 4
5 POWER4 / POWER5 / POWER6 POWER4 POWER4 POWER4 Core Core L2 Ctl POWER5 POWER5 Core POWER5 Core L2 Alti Ve c Ctrl POWER6 P6 P6 Core 4 MB L2 Core 4 MB L2 Alti Ve c Ctrl Distributed Switch Enhanced Distributed Switch GX Bus Cntrl Mem Ctl GX Bus Mem Ctl Memory Cntrl Fabric Bus Controller GX Bus Cntrl Memory Cntrl Memory Memory Memor y+ GX+ Bridge Memor y+ 5
6 POWER6 I/O: Speeds and Feeds DRAM Memory connected by up to 4 channels, MHz DIMMS DDR2 (channels run at 4X DRAM frequency) Nova Nova Nova Nova Nova Nova Nova Nova Nova Nova Nova Nova Memory port (1 of 2): 8B Read (4x2B), 4B Write (4x1B) Nova Nova Nova Nova Off-Node Fabric Buses (2 pairs): 4B/bc or 8B/bc per unidirectional pair 2 MB L2 Quad 0 (Core0) Memory Cntlr 0 2 MB L2 Quad 20 (Core 1) L2 Ctrl Dir L2 Ctrl Dir Fabric Switch L2 reload: 32B/Pc SMT Core 0 64KB L1D SMT Core 1 64KB L1D Ctrl Dir I/O Ctlr Cntlr Ctrl Dir 2 MB L2 Quad 1 (Core0) Memory Cntlr 1 2 MB L2 Quad 3 (Core 1) buses: 16B/bc Read 16B/bc Write (Split into two, 8 and 8) 32 MB 1 (2x16MB) (same as MC0) I/O Interface: 4B Read, 4B Write at 2-8:1 the pc Buses scale at 2:1 with core frequency pc = processor clock bc = bus clock 2 pc = 1 bc On-Node Fabric Buses (3 pairs): 2B/bc or 8B/bc per unidirectional pair Total L2 on chip: 8MB 1 May be a single 32MB chip with 8B buses 6

7 POWER6 Core Pipelines 7
8 POWER5 vs. POWER6 Pipeline Comparison POWER5 Pipe Stages 22 FO4 Pre-Dec Pre-Dec Pre-Dec Pre-Dec Pre-Dec POWER6 Pipe Stages 13 FO4 3-4 cycle redirect I Cache Xmit IBUF Group Form Decode 12 cycle Branch Resolution 5 cycle redirect I Cache I Cache Xmit Rotate IBUF0 14 cycle Branch Resolution Assembly IBUF1 Group Xfer Pre-dispatch Group Disp Group Disp 3 cycle Load-load/fx Rename Issue RF AG/Ex D Cache Fmt Writeback Finish 2 cycle Fx-Fx 6 cycle FP-FP 5 cycle LD-FP 4 cycle Load-load 2 cycle Load-Fx RF AG/RF DCache / Ex DCache Fmt1 Fmt2 Writeback 1 cycle Fx-FX 6 cycle FP to local FP use 8 cycle FP to remote FP use 0 cycle LD to FP use Completion Completion Chkpt 8
9 Side-by-Side comparisons POWER5+ POWER6 Style General out-of-order execution Mostly in-order with special case out-of-order execution Units 2FX, 2LS, 2FP, 1BR, 1CR 2FX, 2LS, 2FP, 1BR/CR, 1VMX Threading 2 SMT threads Alternate ifetch Alternate dispatch (up to 5 instructions) 2 SMT threads Priority-based dispatch Simultaneous dispatch from two threads (up to 7 instructions) 9
10 Side-by-side comparisons L1 Cache ICache capacity, associativity DCache capacity, associativity L2 Cache Capacity, line size Associativity, replacement Off-chip Cache Capacity, line size Associativity, replacement Memory Memory bus POWER5+ 64 KB, 2-way 32 KB, 4-way Point of Coherency 1.9 MB, 128 B line 10-way, LRU 36 MB, 256 B line 12-way, LRU 4 TB maximum 2x DRAM frequency POWER6 64 KB, 4-way 64 KB, 8-way Point of Coherency 2 x 4 MB, 128 B line each 8-way, LRU 32 MB, 128 B line 16-way, LRU 8 TB maximum 4x DRAM frequency 10
11 Latency Profiles Local Memory 120 Time (ns GHz L Size (MB) 11
12 Processor Core Functional Features PowerPC AS Architecture Simultaneous Multithreading ( 2 threads) Decimal Floating Point (extension to PowerPC ISA) 48 Bit Real Address Support Virtualization Support (1024 partitions) Concurrent support of 4 page sizes (4K, 64K, 16M, 16G) New storage key support Bi-Endian Support Dynamic Power Management Single Bit Error Detection on all Dataflow Robust Error Recovery (R unit) CPU sparing support (dynamic CPU swapping) Common Core for I, P, and Blade 12
13 Achieving High Frequency: POWER6 13FO4 Challenge Example Circuit Design 1 FO4 = delay of 1 inverter that drives 4 receivers 1 Logical Gate = 2 FO4 1 cycle = Latch + function + wire 1 cycle = 3 FO4 + function + 4 FO4 Function = 6 FO4 = 3 Gates Integration It takes 6 cycles to send a signals across the core Communication between units takes 1 cycle using good wire Control across a 64-bit data flow takes a cycle 13
14 Sacrifices associated with high frequency In-order design instead of out-of-order Longer pipelines Fp-compare latency FX multiply done in FPU Memory bandwidth reduced Esp. Store queue draining bandwidth Mitigating this: SMT implementation is improved 14
15 In-Order vs. Out of Order In-Order Dispatch Out-of-Order Execution Fetch Dispatch Load R2, Addi R2,R2,1 Load R3, In-Order Dispatch In-Order Execution Fetch Dispatch Operands must be available Instruction Queue Instruction Queue Operands must be available Functional Unit Functional Unit STQ Functional Unit Functional Unit STQ 15
16 P5 vs. P6 instruction groups Both machines are superscalar, meaning that instructions are formed into groups and dispatched together. There are two big differences between P5 and P6: On P5 there are few restrictions on what types on insns and how many can be grouped together, while on P6 each group must fit in the available resources (2 fp, 2 fx, 2 ldst,..) On P5, insns are placed in queues to wait for operands to be ready, while on P6 dispatch must wait until all operands are ready for the whole group On p6, cycles are shorter, but there are more stall cycles and more partial instruction groups 16
17 Strategic NOP insertion ORI 1,1,0 terminates a dispatch group early Suppose at cycle 10 the current group contains FMA, FMA, LFL and all are ready to go. And the only other available instruction is a LFL ready in cycle 15 Including the LFL holds up the first three Could be harmless or catastrophic Sometimes Nops are inserted to fix this 17
18 FP compares Fp compare has an 11-cycle latency to its use This is a significant delay the best defence is for the programmer to work around it arranging lots of work between a compare and where it is used. Several branch free sequences are available for such code. The compiler will in some cases try to replace fp compares with fx compares. 18
19 Store Queue optimizations On Power6 stores are placed into a queue to await completion. This queue can drain 1 store every other cycle If the next store in the queue is to consecutive storage with the first, they both can go that cycle. A 2*8 byte fp store is provided to make this more convenient 19
20 Symmetric Multithreading (SMT) P6 operates in two modes, ST (single thread) and SMT (multithreaded) In SMT mode two independent threads execute simultaneously, possibly from the same parallel program Instructions from both threads can dispatch in the same group, subject to unit availability This is highly profitable on P6 it is a good way to fill otherwise empty machine cycles and achieve better resource usage 20
21 FPU details Two Binary Floating Point units and one Decimal Floating Point unit 7 stage FPU with bypass in 6 stages locally and 8 stages to other fpu Interleaves execution of independent arithmetic instructions with divide/sqrt Handles fixed point multiply/divide (pipelined) Always run at or behind other units 10 group entry queues (group= 2ldf and 2 fp/stf instructions) Allows pipelined issue of dependent store instructions 10 group entry load target buffer allowing speculative FP load execution Multiple Interrupt modes Ignore, imprecise non-recoverable, imprecise recoverable, precise 21
22 FP loads FPU: more detail FP arithmetics/stores dispatch xmit xmit RF gprs agen CA fmt xmit Load Target Buffer FP Registers isq dep select steer issue isq dep select steer issue RF RF shift shift align/mul align/mul align/mul align/mul add add add add normalize normalize round round 22 Store Data to LSU writeback writeback
23 Linpack HPC Performance GFLOPS Power5+ Power6 0 1-way 8-way 16-way 23
24 Datastream Prefetching in POWER6 Load-Look-Ahead (LLA) mode Triggered on a data cache miss to hide latency Datastream prefetching with no filtering Sixteen (16) Prefetch Request Queues (PRQs) Prefetch 2 lines ahead to L1, up to 24 to L2, demand paced Speculative L2 prefetch for next line on cache miss Depth/aggressiveness control via SPR and dcbt instructions int dscr_ctl() dscrctl change O/S default Store prefetching into L2 (with hardware detection) Full compliment of line and stream touches for both loads and stores Sized for dual-thread performance (8 PRQs/thread) 24
25 Memory Physical Organization SLOT 0 Channel 0 MC 1B 2B 1B 2B 1B 2B 1B 2B DIMM 0 Rank0 Rank1 Rank2 Rank3 SLOT 1 DIMM 0 Rank0 Rank1 Rank2 Rank3 SLOT 2 DIMM 0 Rank0 Rank1 Rank2 Rank3 SLOT 3 DIMM 0 Rank0 Rank1 Rank2 Rank3 Channel 1 DIMM 1 Rank0 Rank1 Rank2 Rank3 DIMM 1 Rank0 Rank1 Rank2 Rank3 DIMM 1 Rank0 Rank1 Rank2 Rank3 DIMM 1 Rank0 Rank1 Rank2 Rank3 Channel 2 DIMM 2 Rank0 Rank1 Rank2 Rank3 DIMM 2 Rank0 Rank1 Rank2 Rank3 DIMM 2 Rank0 Rank1 Rank2 Rank3 DIMM 2 Rank0 Rank1 Rank2 Rank3 Channel 3 DIMM 3 Rank0 Rank1 Rank2 Rank3 DIMM 3 Rank0 Rank1 Rank2 Rank3 DIMM 3 Rank0 Rank1 Rank2 Rank3 DIMM 3 Rank0 Rank1 Rank2 Rank3 DIMMs populated in quads Single NOVA per DIMM (or pair of DIMMS) DIMMs may be 1/2/4 ranks Actual bandwidth depends on: DIMM speed, type # of ranks/dimms/channel DIMM channel b/w MC read/write bandwidth (from/to buffers) pattern of reads/writes presented to MC 25
26 POWER5 vs POWER6 bus architecture POWER5 Chip POWER5 Chip POWER6 Chip POWER6 Chip POWER5 Chip POWER5 Chip POWER6 Chip POWER6 Chip Data buses Combined buses Address buses 26
27 POWER6 Eight-Processor Node Off-node SMP interconnect Node a & b Building block for larger systems 64-way system has 8 nodes Eight off-node SMP links chip chip POWER6 Chip x y POWER6 Chip chip chip Fully connects 8 nodes in a z 64-way Additional link for RAS chip chip POWER6 Chip POWER6 Chip chip chip Can be used to build 128-core SMP Off-node SMP interconnect 27
28 POWER6 64 way high-end system 28
29 POWER6 32-way Quad Quad A-bus B-bus XYZ-bus Quad 1 14 Quad 3 12 IOC GX 29 Interconnect GX
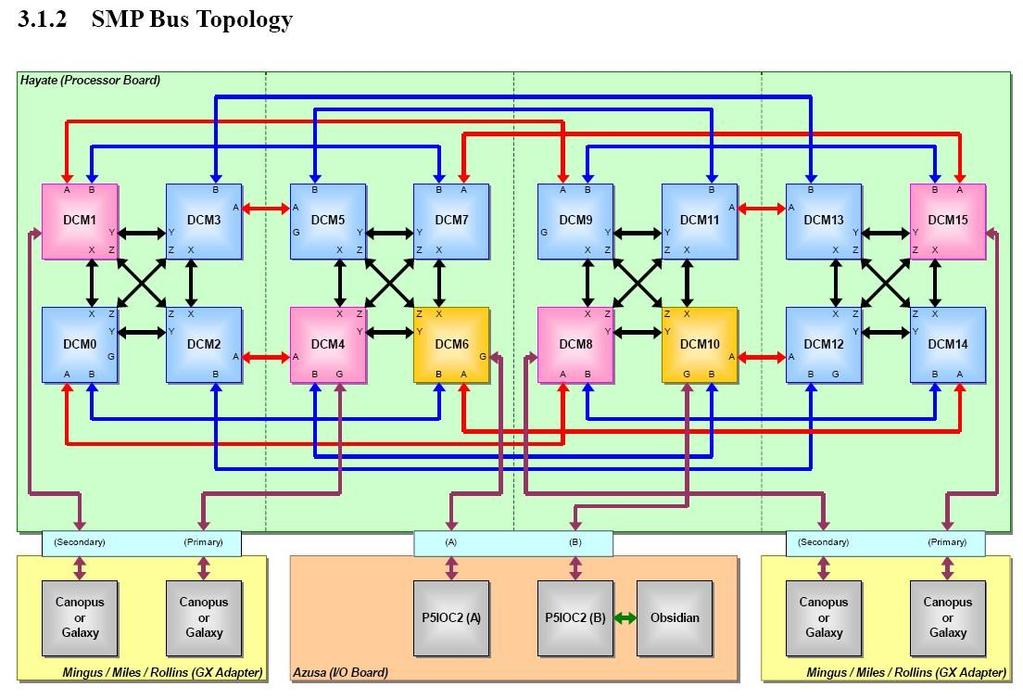
30 30

31 HV8 X X X X 31
32 Snoop Filtering: Broadcast Localized Adaptive-Scope Transaction Protocol (BLAST) Most significant microarchitectural enhancement to P6 nest Coherence broadcasts may be speculatively limited to subset (node or possibly chip) of SMP NUMA-directory-like combination of cache states and domain state info in memory provide ability to resolve coherence without global broadcast Provides significant leverage for SW that exhibits node or chip level processor/memory affinity Several system designs significantly cost reduced by cutting bandwidth of chip interconnect 32
33 Snoop Filtering: Local/System/Double Pump Send request to entire system (System Pump) Longer latency within local node Shorter latency to remote nodes burn address bandwidth on all nodes Send request to local node only (Local Pump) better latency if data is found locally uses only local XYZ address bandwidth re-send to entire system if not found (Double Pump) Adds pclks latency (depends on system type) Local predictor uses thread ID, request type, memory address 33
34 Tracking off-node copies T/Te/Tn/Ten: e =not dirty / n =no off-node copies In/Ig: on- or off-node request took line away castout Ig state to memory directory bit Memory directory extra bit per cache line tells whether off node copies exist MC updates when sourcing data off-node allows node pump to work (MC can provide data) always know from Ig or mem dir if off-node copies exist Double pump No on-node cache has any info about line If memory directory tells us off-node copies exist with data return (data not valid), have to do second pump 34
35 POWER6 Summary Extends POWER leadership for both Technical and Commercial Computing Approx. twice the frequency of P5+, with similar instruction pipeline length and dependency 6 cycle FP to FP use, same as P5+ Mostly in-order but with OOO-like features (LTB, LLA) 5 instruction dispatch group from a thread, up to 7 for both threads, with one branch at any position Significant improvement in cache-memory-latency profile More cache with higher associativity Lower latency to all levels of cache and to memory Enhanced datastream prefetching with adjustable depth, store-stream prefetching Load look-ahead data prefetching Advanced simultaneous multi-threading gives added dimension to chip level performance Predictive subspace snooping for vastly increased SMP coherence throughput Continued technology exploitation CMOS 65nm, Cu SOI Technology All buses scale with processor frequency Enhanced Power Management Advanced server virtualization Advanced RAS: robust error detection, hardware checkpoint and recovery 35
Power 7. Dan Christiani Kyle Wieschowski
 Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
IBM's POWER5 Micro Processor Design and Methodology
 IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group Outline POWER5 Overview Design Process Power POWER Server Roadmap 2001 POWER4 2002-3 POWER4+ 2004* POWER5 2005* POWER5+ 2006*
Agenda. System Performance Scaling of IBM POWER6 TM Based Servers
 System Performance Scaling of IBM POWER6 TM Based Servers Jeff Stuecheli Hot Chips 19 August 2007 Agenda Historical background POWER6 TM chip components Interconnect topology Cache Coherence strategies
System Performance Scaling of IBM POWER6 TM Based Servers Jeff Stuecheli Hot Chips 19 August 2007 Agenda Historical background POWER6 TM chip components Interconnect topology Cache Coherence strategies
IBM POWER6 microarchitecture
 IBM POWER6 microarchitecture This paper describes the implementation of the IBM POWER6e microprocessor, a two-way simultaneous multithreaded (SMT) dual-core chip whose key features include binary compatibility
IBM POWER6 microarchitecture This paper describes the implementation of the IBM POWER6e microprocessor, a two-way simultaneous multithreaded (SMT) dual-core chip whose key features include binary compatibility
POWER7: IBM's Next Generation Server Processor
 POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
POWER7: IBM's Next Generation Server Processor Acknowledgment: This material is based upon work supported by the Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002 Outline
Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group
 Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
Simultaneous Multi-threading Implementation in POWER5 -- IBM's Next Generation POWER Microprocessor Ron Kalla, Balaram Sinharoy, Joel Tendler IBM Systems Group Outline Motivation Background Threading Fundamentals
POWER7: IBM's Next Generation Server Processor
 Hot Chips 21 POWER7: IBM's Next Generation Server Processor Ronald Kalla Balaram Sinharoy POWER7 Chief Engineer POWER7 Chief Core Architect Acknowledgment: This material is based upon work supported by
Hot Chips 21 POWER7: IBM's Next Generation Server Processor Ronald Kalla Balaram Sinharoy POWER7 Chief Engineer POWER7 Chief Core Architect Acknowledgment: This material is based upon work supported by
1. PowerPC 970MP Overview
 1. The IBM PowerPC 970MP reduced instruction set computer (RISC) microprocessor is an implementation of the PowerPC Architecture. This chapter provides an overview of the features of the 970MP microprocessor
1. The IBM PowerPC 970MP reduced instruction set computer (RISC) microprocessor is an implementation of the PowerPC Architecture. This chapter provides an overview of the features of the 970MP microprocessor
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 19 Advanced Processors III 2006-11-2 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last
CS 152 Computer Architecture and Engineering Lecture 19 Advanced Processors III 2006-11-2 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2005-4-12 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Eric Schwarz. IBM Accelerators. July 11, IBM Corporation
 Eric Schwarz IBM Accelerators July 11, 2016 2016 IBM Corporation Outline Roadmaps of Z and Power Arithmetic Feature Comparison How to Get Performance without Frequency 2 2016 IBM Corporation z Systems
Eric Schwarz IBM Accelerators July 11, 2016 2016 IBM Corporation Outline Roadmaps of Z and Power Arithmetic Feature Comparison How to Get Performance without Frequency 2 2016 IBM Corporation z Systems
Gemini: Sanjiv Kapil. A Power-efficient Chip Multi-Threaded (CMT) UltraSPARC Processor. Gemini Architect Sun Microsystems, Inc.
 UltraSPARC Processor. Gemini Architect Sun Microsystems, Inc.") Gemini: A Power-efficient Chip Multi-Threaded (CMT) UltraSPARC Processor Sanjiv Kapil Gemini Architect Sun Microsystems, Inc. Design Goals Designed for compute-dense, transaction oriented systems (webservers,
Gemini: A Power-efficient Chip Multi-Threaded (CMT) UltraSPARC Processor Sanjiv Kapil Gemini Architect Sun Microsystems, Inc. Design Goals Designed for compute-dense, transaction oriented systems (webservers,
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors
 PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
PowerPC TM 970: First in a new family of 64-bit high performance PowerPC processors Peter Sandon Senior PowerPC Processor Architect IBM Microelectronics All information in these materials is subject to
Power Technology For a Smarter Future
 2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
IBM POWER4: a 64-bit Architecture and a new Technology to form Systems
 IBM POWER4: a 64-bit Architecture and a new Technology to form Systems Rui Daniel Gomes de Macedo Fernandes Departamento de Informática, Universidade do Minho 4710-057 Braga, Portugal ruif@net.sapo.pt
IBM POWER4: a 64-bit Architecture and a new Technology to form Systems Rui Daniel Gomes de Macedo Fernandes Departamento de Informática, Universidade do Minho 4710-057 Braga, Portugal ruif@net.sapo.pt
Multi-Threading. Last Time: Dynamic Scheduling. Recall: Throughput and multiple threads. This Time: Throughput Computing
 CS Computer Architecture and Engineering Lecture Advanced Processors III -- Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs/ Last
CS Computer Architecture and Engineering Lecture Advanced Processors III -- Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs/ Last
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
POWER3: Next Generation 64-bit PowerPC Processor Design
 POWER3: Next Generation 64-bit PowerPC Processor Design Authors Mark Papermaster, Robert Dinkjian, Michael Mayfield, Peter Lenk, Bill Ciarfella, Frank O Connell, Raymond DuPont High End Processor Design,
POWER3: Next Generation 64-bit PowerPC Processor Design Authors Mark Papermaster, Robert Dinkjian, Michael Mayfield, Peter Lenk, Bill Ciarfella, Frank O Connell, Raymond DuPont High End Processor Design,
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 10: Memory Part II CSC 631: High-Performance Computer Architecture 1 Two predictable properties of memory references: Temporal Locality:
Portland State University ECE 588/688. Cray-1 and Cray T3E
 Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
Portland State University ECE 588/688 Cray-1 and Cray T3E Copyright by Alaa Alameldeen 2014 Cray-1 A successful Vector processor from the 1970s Vector instructions are examples of SIMD Contains vector
The Pentium II/III Processor Compiler on a Chip
 The Pentium II/III Processor Compiler on a Chip Ronny Ronen Senior Principal Engineer Director of Architecture Research Intel Labs - Haifa Intel Corporation Tel Aviv University January 20, 2004 1 Agenda
The Pentium II/III Processor Compiler on a Chip Ronny Ronen Senior Principal Engineer Director of Architecture Research Intel Labs - Haifa Intel Corporation Tel Aviv University January 20, 2004 1 Agenda
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU
 1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
1-6x86 PROCESSOR Superscalar, Superpipelined, Sixth-generation, x86 Compatible CPU Product Overview Introduction 1. ARCHITECTURE OVERVIEW The Cyrix 6x86 CPU is a leader in the sixth generation of high
In-order vs. Out-of-order Execution. In-order vs. Out-of-order Execution
 In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
POWER9 Announcement. Martin Bušek IBM Server Solution Sales Specialist
 POWER9 Announcement Martin Bušek IBM Server Solution Sales Specialist Announce Performance Launch GA 2/13 2/27 3/19 3/20 POWER9 is here!!! The new POWER9 processor ~1TB/s 1 st chip with PCIe4 4GHZ 2x Core
POWER9 Announcement Martin Bušek IBM Server Solution Sales Specialist Announce Performance Launch GA 2/13 2/27 3/19 3/20 POWER9 is here!!! The new POWER9 processor ~1TB/s 1 st chip with PCIe4 4GHZ 2x Core
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
CS650 Computer Architecture. Lecture 9 Memory Hierarchy - Main Memory
 CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Keywords and Review Questions
 Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
Keywords and Review Questions lec1: Keywords: ISA, Moore s Law Q1. Who are the people credited for inventing transistor? Q2. In which year IC was invented and who was the inventor? Q3. What is ISA? Explain
OPENSPARC T1 OVERVIEW
 Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
Chapter Four OPENSPARC T1 OVERVIEW Denis Sheahan Distinguished Engineer Niagara Architecture Group Sun Microsystems Creative Commons 3.0United United States License Creative CommonsAttribution-Share Attribution-Share
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Open Innovation with Power8
 2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Open Innovation with Power8 Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation 2013
2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Open Innovation with Power8 Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation 2013
CPU Architecture Overview. Varun Sampath CIS 565 Spring 2012
 CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
CPU Architecture Overview Varun Sampath CIS 565 Spring 2012 Objectives Performance tricks of a modern CPU Pipelining Branch Prediction Superscalar Out-of-Order (OoO) Execution Memory Hierarchy Vector Operations
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Portland State University ECE 588/688. IBM Power4 System Microarchitecture
 Portland State University ECE 588/688 IBM Power4 System Microarchitecture Copyright by Alaa Alameldeen 2018 IBM Power4 Design Principles SMP optimization Designed for high-throughput multi-tasking environments
Portland State University ECE 588/688 IBM Power4 System Microarchitecture Copyright by Alaa Alameldeen 2018 IBM Power4 Design Principles SMP optimization Designed for high-throughput multi-tasking environments
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
PowerPC 740 and 750
 368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
368 floating-point registers. A reorder buffer with 16 elements is used as well to support speculative execution. The register file has 12 ports. Although instructions can be executed out-of-order, in-order
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor. David Johnson Systems Technology Division Hewlett-Packard Company
 Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
Techniques for Mitigating Memory Latency Effects in the PA-8500 Processor David Johnson Systems Technology Division Hewlett-Packard Company Presentation Overview PA-8500 Overview uction Fetch Capabilities
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2004-11-18 Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 22 Advanced Processors III 2004-11-18 Dave Patterson (www.cs.berkeley.edu/~patterson) John Lazzaro (www.cs.berkeley.edu/~lazzaro) www-inst.eecs.berkeley.edu/~cs152/
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Limitations of Scalar Pipelines
 Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Limitations of Scalar Pipelines Superscalar Organization Modern Processor Design: Fundamentals of Superscalar Processors Scalar upper bound on throughput IPC = 1 Inefficient unified pipeline
Module 5: "MIPS R10000: A Case Study" Lecture 9: "MIPS R10000: A Case Study" MIPS R A case study in modern microarchitecture.
 Module 5: "MIPS R10000: A Case Study" Lecture 9: "MIPS R10000: A Case Study" MIPS R10000 A case study in modern microarchitecture Overview Stage 1: Fetch Stage 2: Decode/Rename Branch prediction Branch
Module 5: "MIPS R10000: A Case Study" Lecture 9: "MIPS R10000: A Case Study" MIPS R10000 A case study in modern microarchitecture Overview Stage 1: Fetch Stage 2: Decode/Rename Branch prediction Branch
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
HP PA-8000 RISC CPU. A High Performance Out-of-Order Processor
 The A High Performance Out-of-Order Processor Hot Chips VIII IEEE Computer Society Stanford University August 19, 1996 Hewlett-Packard Company Engineering Systems Lab - Fort Collins, CO - Cupertino, CA
The A High Performance Out-of-Order Processor Hot Chips VIII IEEE Computer Society Stanford University August 19, 1996 Hewlett-Packard Company Engineering Systems Lab - Fort Collins, CO - Cupertino, CA
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR
 IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR FEATURING SINGLE- AND MULTITHREADED EXECUTION, THE POWER5 PROVIDES HIGHER PERFORMANCE IN THE SINGLE-THREADED MODE THAN ITS POWER4 PREDECESSOR AT EQUIVALENT
IBM POWER5 CHIP: A DUAL-CORE MULTITHREADED PROCESSOR FEATURING SINGLE- AND MULTITHREADED EXECUTION, THE POWER5 PROVIDES HIGHER PERFORMANCE IN THE SINGLE-THREADED MODE THAN ITS POWER4 PREDECESSOR AT EQUIVALENT
Jim Keller. Digital Equipment Corp. Hudson MA
 Jim Keller Digital Equipment Corp. Hudson MA ! Performance - SPECint95 100 50 21264 30 21164 10 1995 1996 1997 1998 1999 2000 2001 CMOS 5 0.5um CMOS 6 0.35um CMOS 7 0.25um "## Continued Performance Leadership
Jim Keller Digital Equipment Corp. Hudson MA ! Performance - SPECint95 100 50 21264 30 21164 10 1995 1996 1997 1998 1999 2000 2001 CMOS 5 0.5um CMOS 6 0.35um CMOS 7 0.25um "## Continued Performance Leadership
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Itanium 2 Processor Microarchitecture Overview
 Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
Itanium 2 Processor Microarchitecture Overview Don Soltis, Mark Gibson Cameron McNairy, August 2002 Block Diagram F 16KB L1 I-cache Instr 2 Instr 1 Instr 0 M/A M/A M/A M/A I/A Template I/A B B 2 FMACs
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
The Alpha Microprocessor: Out-of-Order Execution at 600 Mhz. R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA
 The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
The Alpha 21264 Microprocessor: Out-of-Order ution at 600 Mhz R. E. Kessler COMPAQ Computer Corporation Shrewsbury, MA 1 Some Highlights z Continued Alpha performance leadership y 600 Mhz operation in
Thread-level Parallelism. Synchronization. Explicit multithreading Implicit multithreading Redundant multithreading Summary
 Chapter 11: Executing Multiple Threads Modern Processor Design: Fundamentals of Superscalar Processors Executing Multiple Threads Thread-level parallelism Synchronization Multiprocessors Explicit multithreading
Chapter 11: Executing Multiple Threads Modern Processor Design: Fundamentals of Superscalar Processors Executing Multiple Threads Thread-level parallelism Synchronization Multiprocessors Explicit multithreading
IBM ^ POWER4 System Microarchitecture
 IBM ^ POWER4 System Microarchitecture Technical White Paper POWER4 introduces a new microprocessor organized in a system structure that includes new technology to form systems. POWER4 as used in this context
IBM ^ POWER4 System Microarchitecture Technical White Paper POWER4 introduces a new microprocessor organized in a system structure that includes new technology to form systems. POWER4 as used in this context
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
A Key Theme of CIS 371: Parallelism. CIS 371 Computer Organization and Design. Readings. This Unit: (In-Order) Superscalar Pipelines
 Superscalar Pipelines") A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
Pentium IV-XEON. Computer architectures M
 Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
Pentium IV-XEON Computer architectures M 1 Pentium IV block scheme 4 32 bytes parallel Four access ports to the EU 2 Pentium IV block scheme Address Generation Unit BTB Branch Target Buffer I-TLB Instruction
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
EC 513 Computer Architecture
 EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
EC 513 Computer Architecture Complex Pipelining: Superscalar Prof. Michel A. Kinsy Summary Concepts Von Neumann architecture = stored-program computer architecture Self-Modifying Code Princeton architecture
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
CS 152, Spring 2011 Section 8
 CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Page 1. Multilevel Memories (Improving performance using a little cash )
") Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
Page 1 Multilevel Memories (Improving performance using a little cash ) 1 Page 2 CPU-Memory Bottleneck CPU Memory Performance of high-speed computers is usually limited by memory bandwidth & latency Latency
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Creating a Scalable Microprocessor:
 Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
CS 152 Computer Architecture and Engineering Lecture 20 Advanced Processors I 2005-4-5 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Ted Hong and David Marquardt www-inst.eecs.berkeley.edu/~cs152/ Last
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]
![Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]](/thumbs/93/113797768.jpg "Performance. CS 3410 Computer System Organization & Programming. [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon]") Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Performance CS 3410 Computer System Organization & Programming [K. Bala, A. Bracy, E. Sirer, and H. Weatherspoon] Performance Complex question How fast is the processor? How fast your application runs?
Intel Architecture for Software Developers
 Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Intel Architecture for Software Developers 1 Agenda Introduction Processor Architecture Basics Intel Architecture Intel Core and Intel Xeon Intel Atom Intel Xeon Phi Coprocessor Use Cases for Software
Case Study IBM PowerPC 620
 Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
Case Study IBM PowerPC 620 year shipped: 1995 allowing out-of-order execution (dynamic scheduling) and in-order commit (hardware speculation). using a reorder buffer to track when instruction can commit,
 1 cycle per instruction I
1 cycle per instruction I CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 18 Advanced Processors II 2006-10-31 John Lazzaro (www.cs.berkeley.edu/~lazzaro) Thanks to Krste Asanovic... TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/
Parallelism, Multicore, and Synchronization
 Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
SISTEMI EMBEDDED. Computer Organization Pipelining. Federico Baronti Last version:
 SISTEMI EMBEDDED Computer Organization Pipelining Federico Baronti Last version: 20160518 Basic Concept of Pipelining Circuit technology and hardware arrangement influence the speed of execution for programs
SISTEMI EMBEDDED Computer Organization Pipelining Federico Baronti Last version: 20160518 Basic Concept of Pipelining Circuit technology and hardware arrangement influence the speed of execution for programs
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Next Generation Technology from Intel Intel Pentium 4 Processor
 Next Generation Technology from Intel Intel Pentium 4 Processor 1 The Intel Pentium 4 Processor Platform Intel s highest performance processor for desktop PCs Targeted at consumer enthusiasts and business
Next Generation Technology from Intel Intel Pentium 4 Processor 1 The Intel Pentium 4 Processor Platform Intel s highest performance processor for desktop PCs Targeted at consumer enthusiasts and business
and data combined) is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed
 is equal to 7% of the number of instructions. Miss Rate with Second- Level Cache, Direct- Mapped Speed") 5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
5.3 By convention, a cache is named according to the amount of data it contains (i.e., a 4 KiB cache can hold 4 KiB of data); however, caches also require SRAM to store metadata such as tags and valid
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle