Building LinkedIn s Real-time Data Pipeline. Jay Kreps
|
|
|
- Ann Snow
- 5 years ago
- Views:
Transcription
1 Building LinkedIn s Real-time Data Pipeline Jay Kreps
2
3 What is a data pipeline?
4 What data is there? Database data Activity data Page Views, Ad Impressions, etc Messaging JMS, AMQP, etc Application and System Metrics Rrdtool, graphite, etc Logs Syslog, log4j, etc
5
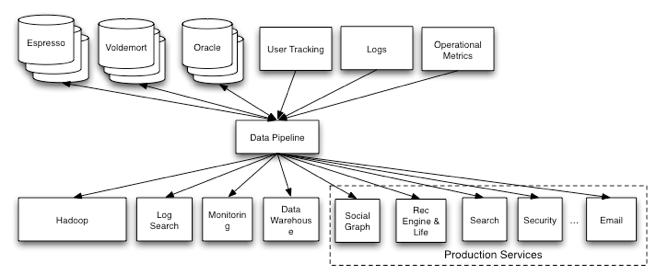
6 Data Systems at LinkedIn Search Social Graph Recommendations Live Storage Hadoop Data Warehouse Monitoring Systems
7 Problem: Data Integration

8 Point-to-Point Pipelines
9 Centralized Pipeline
10 How have companies solved this problem?

11 The Enterprise Data Warehouse
12 Problems Data warehouse is a batch system Central team that cleans all data? One person s cleaning Relational mapping is non-trivial
13 My Experience
14 LinkedIn s Pipeline
15 LinkedIn Circa 2010 Messaging: ActiveMQ User Activity: In house log aggregation Logging: Splunk Metrics: JMX => Zenoss Database data: Databus, custom ETL
16 2010 User Activity Data Flow
17 Problems Fragility Multi-hour delay Coverage Labor intensive Slow Does it work?
18 Four Ideas 1. Central commit log for all data 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness
19 Four Ideas 1. Central commit log for all data 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness
20 What kind of infrastructure is needed?
21 Very confused Messaging (JMS, AMQP, ) Log aggregation CEP, Streaming
22 First Attempt: Don t reinvent the wheel!

23
24 Problems With Messaging Systems Persistence is an afterthought Ad hoc distribution Odd semantics Featuritis
25 Second Attempt: Reinvent the wheel!
26 Idea: Central, Distributed Commit Log
27 What is a commit log?
28 Data Flow
29 Apache Kafka
30 Some Terminology Producers send messages to Brokers Consumers read messages from Brokers Messages are sent to a Topic Each topic is broken into one or more ordered partitions of messages
31 APIs send(string topic, String key, Message message) Iterator<Message>
32 Distribution
33 Performance 50MB/sec writes 110MB/sec reads

34 Performance
35 Performance Tricks Batching Producer Broker Consumer Avoid large in-memory structures Pagecache friendly Avoid data copying sendfile Batch Compression
36 Kafka Replication In 0.8 release Messages are highly available No centralized master
37 Kafka Info
38 Usage at LinkedIn 10 billion messages/day Sustained peak: 172,000 messages/second written 950,000 messages/second read 367 topics 40 real-time consumers Many ad hoc consumers 10k connections/colo 9.5TB log retained End-to-end delivery time: 10 seconds (avg)
39 Datacenters
40 Four Ideas 1. Central commit log for all data 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness
41 Problem Hundreds of message types Thousands of fields What do they all mean? What happens when they change?
42 Make activity data part of the domain model

43 Schema free?
44 LOAD student USING PigStorage() AS (name:chararray, age:int, gpa:float)
45 Schemas Structure can be exploited Performance Size Compatibility Need a formal contract

46 Avro Schema Avro data definition and schema Central repository of all schemas Reader always uses same schema as writer Programatic compatibility model
47 Workflow 1. Check in schema 2. Code review 3. Ship
48 Four Ideas 1. Central commit log for all data 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness
49 Hadoop Data Load Map/Reduce job does data load One job loads all events Hive registration done automatically Schema changes handled transparently ~5 minute lag on average to HDFS
50 Four Ideas 1. Central commit log for all data 2. Push data cleanliness upstream 3. O(1) ETL 4. Evidence-based correctness
51 Does it work?
52 All messages sent must be delivered to all consumers (quickly)
53 Audit Trail Each producer, broker, and consumer periodically reports how many messages it saw Reconcile these counts every few minutes Graph and alert
54 Audit Trail
55 Questions?
Introduction to Apache Kafka
 Introduction to Apache Kafka Chris Curtin Head of Technical Research Atlanta Java Users Group March 2013 About Me 20+ years in technology Head of Technical Research at Silverpop (12 + years at Silverpop)
Introduction to Apache Kafka Chris Curtin Head of Technical Research Atlanta Java Users Group March 2013 About Me 20+ years in technology Head of Technical Research at Silverpop (12 + years at Silverpop)
A Distributed System Case Study: Apache Kafka. High throughput messaging for diverse consumers
 A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
A Distributed System Case Study: Apache Kafka High throughput messaging for diverse consumers As always, this is not a tutorial Some of the concepts may no longer be part of the current system or implemented
Data Infrastructure at LinkedIn. Shirshanka Das XLDB 2011
 Data Infrastructure at LinkedIn Shirshanka Das XLDB 2011 1 Me UCLA Ph.D. 2005 (Distributed protocols in content delivery networks) PayPal (Web frameworks and Session Stores) Yahoo! (Serving Infrastructure,
Data Infrastructure at LinkedIn Shirshanka Das XLDB 2011 1 Me UCLA Ph.D. 2005 (Distributed protocols in content delivery networks) PayPal (Web frameworks and Session Stores) Yahoo! (Serving Infrastructure,
Introduc)on to Apache Ka1a. Jun Rao Co- founder of Confluent
on to Apache Ka1a. Jun Rao Co- founder of Confluent") Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Introduc)on to Apache Ka1a Jun Rao Co- founder of Confluent Agenda Why people use Ka1a Technical overview of Ka1a What s coming What s Apache Ka1a Distributed, high throughput pub/sub system Ka1a Usage
Tools for Social Networking Infrastructures
 Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Tools for Social Networking Infrastructures 1 Cassandra - a decentralised structured storage system Problem : Facebook Inbox Search hundreds of millions of users distributed infrastructure inbox changes
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2017/18 Valeria Cardellini The reference
Intra-cluster Replication for Apache Kafka. Jun Rao
 Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Intra-cluster Replication for Apache Kafka Jun Rao About myself Engineer at LinkedIn since 2010 Worked on Apache Kafka and Cassandra Database researcher at IBM Outline Overview of Kafka Kafka architecture
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
WHITE PAPER. Reference Guide for Deploying and Configuring Apache Kafka
 WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
WHITE PAPER Reference Guide for Deploying and Configuring Apache Kafka Revised: 02/2015 Table of Content 1. Introduction 3 2. Apache Kafka Technology Overview 3 3. Common Use Cases for Kafka 4 4. Deploying
Building LinkedIn s Real-time Activity Data Pipeline
 Building LinkedIn s Real-time Activity Data Pipeline Ken Goodhope, Joel Koshy, Jay Kreps, Neha Narkhede, Richard Park, Jun Rao, Victor Yang Ye LinkedIn Abstract One trend in the implementation of modern
Building LinkedIn s Real-time Activity Data Pipeline Ken Goodhope, Joel Koshy, Jay Kreps, Neha Narkhede, Richard Park, Jun Rao, Victor Yang Ye LinkedIn Abstract One trend in the implementation of modern
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics
 Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Increase Value from Big Data with Real-Time Data Integration and Streaming Analytics Cy Erbay Senior Director Striim Executive Summary Striim is Uniquely Qualified to Solve the Challenges of Real-Time
Hortonworks DataFlow Sam Lachterman Solutions Engineer
 Hortonworks DataFlow Sam Lachterman Solutions Engineer 1 Hortonworks Inc. 2011 2017. All Rights Reserved Disclaimer This document may contain product features and technology directions that are under development,
Hortonworks DataFlow Sam Lachterman Solutions Engineer 1 Hortonworks Inc. 2011 2017. All Rights Reserved Disclaimer This document may contain product features and technology directions that are under development,
Scaling the Yelp s logging pipeline with Apache Kafka. Enrico
 Scaling the Yelp s logging pipeline with Apache Kafka Enrico Canzonieri enrico@yelp.com @EnricoC89 Yelp s Mission Connecting people with great local businesses. Yelp Stats As of Q1 2016 90M 102M 70% 32
Scaling the Yelp s logging pipeline with Apache Kafka Enrico Canzonieri enrico@yelp.com @EnricoC89 Yelp s Mission Connecting people with great local businesses. Yelp Stats As of Q1 2016 90M 102M 70% 32
iway iway Big Data Integrator New Features Bulletin and Release Notes Version DN
 iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.0 DN3502232.1216 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,
iway iway Big Data Integrator New Features Bulletin and Release Notes Version 1.5.0 DN3502232.1216 Active Technologies, EDA, EDA/SQL, FIDEL, FOCUS, Information Builders, the Information Builders logo,
Architectural challenges for building a low latency, scalable multi-tenant data warehouse
 Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Architectural challenges for building a low latency, scalable multi-tenant data warehouse Mataprasad Agrawal Solutions Architect, Services CTO 2017 Persistent Systems Ltd. All rights reserved. Our analytics
Integrating Hive and Kafka
 3 Integrating Hive and Kafka Date of Publish: 2018-12-18 https://docs.hortonworks.com/ Contents... 3 Create a table for a Kafka stream...3 Querying live data from Kafka... 4 Query live data from Kafka...
3 Integrating Hive and Kafka Date of Publish: 2018-12-18 https://docs.hortonworks.com/ Contents... 3 Create a table for a Kafka stream...3 Querying live data from Kafka... 4 Query live data from Kafka...
/ Cloud Computing. Recitation 15 December 6 th 2016
 15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
Microsoft Exam
 Volume: 42 Questions Case Study: 1 Relecloud General Overview Relecloud is a social media company that processes hundreds of millions of social media posts per day and sells advertisements to several hundred
Volume: 42 Questions Case Study: 1 Relecloud General Overview Relecloud is a social media company that processes hundreds of millions of social media posts per day and sells advertisements to several hundred
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
An Information Asset Hub. How to Effectively Share Your Data
 An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Migrating from Oracle to Espresso
 Migrating from Oracle to Espresso David Max Senior Software Engineer LinkedIn About LinkedIn New York Engineering Located in Empire State Building Approximately 100 engineers and 1000 employees total New
Migrating from Oracle to Espresso David Max Senior Software Engineer LinkedIn About LinkedIn New York Engineering Located in Empire State Building Approximately 100 engineers and 1000 employees total New
Apache Kafka Your Event Stream Processing Solution
 Apache Kafka Your Event Stream Processing Solution Introduction Data is one among the newer ingredients in the Internet-based systems and includes user-activity events related to logins, page visits, clicks,
Apache Kafka Your Event Stream Processing Solution Introduction Data is one among the newer ingredients in the Internet-based systems and includes user-activity events related to logins, page visits, clicks,
Apache Kafka a system optimized for writing. Bernhard Hopfenmüller. 23. Oktober 2018
 Apache Kafka...... a system optimized for writing Bernhard Hopfenmüller 23. Oktober 2018 whoami Bernhard Hopfenmüller IT Consultant @ ATIX AG IRC: Fobhep github.com/fobhep whoarewe The Linux & Open Source
Apache Kafka...... a system optimized for writing Bernhard Hopfenmüller 23. Oktober 2018 whoami Bernhard Hopfenmüller IT Consultant @ ATIX AG IRC: Fobhep github.com/fobhep whoarewe The Linux & Open Source
Data pipelines with PostgreSQL & Kafka
 Data pipelines with PostgreSQL & Kafka Oskari Saarenmaa PostgresConf US 2018 - Jersey City Agenda 1. Introduction 2. Data pipelines, old and new 3. Apache Kafka 4. Sample data pipeline with Kafka & PostgreSQL
Data pipelines with PostgreSQL & Kafka Oskari Saarenmaa PostgresConf US 2018 - Jersey City Agenda 1. Introduction 2. Data pipelines, old and new 3. Apache Kafka 4. Sample data pipeline with Kafka & PostgreSQL
Building Event Driven Architectures using OpenEdge CDC Richard Banville, Fellow, OpenEdge Development Dan Mitchell, Principal Sales Engineer
 Building Event Driven Architectures using OpenEdge CDC Richard Banville, Fellow, OpenEdge Development Dan Mitchell, Principal Sales Engineer October 26, 2018 Agenda Change Data Capture (CDC) Overview Configuring
Building Event Driven Architectures using OpenEdge CDC Richard Banville, Fellow, OpenEdge Development Dan Mitchell, Principal Sales Engineer October 26, 2018 Agenda Change Data Capture (CDC) Overview Configuring
IBM Data Replication for Big Data
 IBM Data Replication for Big Data Highlights Stream changes in realtime in Hadoop or Kafka data lakes or hubs Provide agility to data in data warehouses and data lakes Achieve minimum impact on source
IBM Data Replication for Big Data Highlights Stream changes in realtime in Hadoop or Kafka data lakes or hubs Provide agility to data in data warehouses and data lakes Achieve minimum impact on source
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Oracle Data Integrator 12c: Integration and Administration
 Oracle University Contact Us: +34916267792 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive data integration platform
Oracle University Contact Us: +34916267792 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive data integration platform
Streaming Integration and Intelligence For Automating Time Sensitive Events
 Streaming Integration and Intelligence For Automating Time Sensitive Events Ted Fish Director Sales, Midwest ted@striim.com 312-330-4929 Striim Executive Summary Delivering Data for Time Sensitive Processes
Streaming Integration and Intelligence For Automating Time Sensitive Events Ted Fish Director Sales, Midwest ted@striim.com 312-330-4929 Striim Executive Summary Delivering Data for Time Sensitive Processes
Evolution of an Apache Spark Architecture for Processing Game Data
 Evolution of an Apache Spark Architecture for Processing Game Data Nick Afshartous WB Analytics Platform May 17 th 2017 May 17 th, 2017 About Me nafshartous@wbgames.com WB Analytics Core Platform Lead
Evolution of an Apache Spark Architecture for Processing Game Data Nick Afshartous WB Analytics Platform May 17 th 2017 May 17 th, 2017 About Me nafshartous@wbgames.com WB Analytics Core Platform Lead
Building Durable Real-time Data Pipeline
 Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Building Durable Real-time Data Pipeline Apache BookKeeper at Twitter @sijieg Twitter Background Layered Architecture Agenda Design Details Performance Scale @Twitter Q & A Publish-Subscribe Online services
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
<Insert Picture Here> Introduction to Big Data Technology
 Introduction to Big Data Technology The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into
Introduction to Big Data Technology The following is intended to outline our general product direction. It is intended for information purposes only, and may not be incorporated into
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
New Data Architectures For Netflow Analytics NANOG 74. Fangjin Yang - Imply
 New Data Architectures For Netflow Analytics NANOG 74 Fangjin Yang - Cofounder @ Imply The Problem Comparing technologies Overview Operational analytic databases Try this at home The Problem Netflow data
New Data Architectures For Netflow Analytics NANOG 74 Fangjin Yang - Cofounder @ Imply The Problem Comparing technologies Overview Operational analytic databases Try this at home The Problem Netflow data
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk
 Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
Bring Context To Your Machine Data With Hadoop, RDBMS & Splunk Raanan Dagan and Rohit Pujari September 25, 2017 Washington, DC Forward-Looking Statements During the course of this presentation, we may
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Top 20 Data Quality Solutions for Data Science
 Top 20 Data Quality Solutions for Data Science Data Science & Business Analytics Meetup Boulder, CO 2014-12-03 Ken Farmer DQ Problems for Data Science Loom Large & Frequently 4000000 Strikingly visible
Top 20 Data Quality Solutions for Data Science Data Science & Business Analytics Meetup Boulder, CO 2014-12-03 Ken Farmer DQ Problems for Data Science Loom Large & Frequently 4000000 Strikingly visible
Lecture 12 DATA ANALYTICS ON WEB SCALE
 Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Lecture 12 DATA ANALYTICS ON WEB SCALE Source: The Economist, February 25, 2010 The Data Deluge EIGHTEEN months ago, Li & Fung, a firm that manages supply chains for retailers, saw 100 gigabytes of information
Pig Latin Reference Manual 1
 Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Table of contents 1 Overview.2 2 Pig Latin Statements. 2 3 Multi-Query Execution 5 4 Specialized Joins..10 5 Optimization Rules. 13 6 Memory Management15 7 Zebra Integration..15 1. Overview Use this manual
Apache BookKeeper. A High Performance and Low Latency Storage Service
 Apache BookKeeper A High Performance and Low Latency Storage Service Hello! I am Sijie Guo - PMC Chair of Apache BookKeeper Co-creator of Apache DistributedLog Twitter Messaging/Pub-Sub Team Yahoo! R&D
Apache BookKeeper A High Performance and Low Latency Storage Service Hello! I am Sijie Guo - PMC Chair of Apache BookKeeper Co-creator of Apache DistributedLog Twitter Messaging/Pub-Sub Team Yahoo! R&D
Data Storage Infrastructure at Facebook
 Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
Data Storage Infrastructure at Facebook Spring 2018 Cleveland State University CIS 601 Presentation Yi Dong Instructor: Dr. Chung Outline Strategy of data storage, processing, and log collection Data flow
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Syncsort Incorporated, 2016
 Syncsort Incorporated, 2016 All rights reserved. This document contains proprietary and confidential material, and is only for use by licensees of DMExpress. This publication may not be reproduced in whole
Syncsort Incorporated, 2016 All rights reserved. This document contains proprietary and confidential material, and is only for use by licensees of DMExpress. This publication may not be reproduced in whole
Building a Data-Friendly Platform for a Data- Driven Future
 Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Building a Data-Friendly Platform for a Data- Driven Future Benjamin Hindman - @benh 2016 Mesosphere, Inc. All Rights Reserved. INTRO $ whoami BENJAMIN HINDMAN Co-founder and Chief Architect of Mesosphere,
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Virtual IMS user group: Newsletter 57
 : Newsletter 57 Welcome to the newsletter. The at www.fundi.com/virtualims is an independently-operated vendor-neutral site run by and for the IMS user community. presentation The latest webinar from the
: Newsletter 57 Welcome to the newsletter. The at www.fundi.com/virtualims is an independently-operated vendor-neutral site run by and for the IMS user community. presentation The latest webinar from the
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Real-time Data Engineering in the Cloud Exercise Guide
 Real-time Data Engineering in the Cloud Exercise Guide Jesse Anderson 2017 SMOKING HAND LLC ALL RIGHTS RESERVED Version 1.12.a9779239 1 Contents 1 Lab Notes 3 2 Kafka HelloWorld 6 3 Streaming ETL 8 4 Advanced
Real-time Data Engineering in the Cloud Exercise Guide Jesse Anderson 2017 SMOKING HAND LLC ALL RIGHTS RESERVED Version 1.12.a9779239 1 Contents 1 Lab Notes 3 2 Kafka HelloWorld 6 3 Streaming ETL 8 4 Advanced
Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
 Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Lustre* - Fast Forward to Exascale High Performance Data Division. Eric Barton 18th April, 2013
 Lustre* - Fast Forward to Exascale High Performance Data Division Eric Barton 18th April, 2013 DOE Fast Forward IO and Storage Exascale R&D sponsored by 7 leading US national labs Solutions to currently
Lustre* - Fast Forward to Exascale High Performance Data Division Eric Barton 18th April, 2013 DOE Fast Forward IO and Storage Exascale R&D sponsored by 7 leading US national labs Solutions to currently
Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
 Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Data Ingestion ETL, Distcp, Kafka, OpenRefine, Query & Exploration SQL, Search, Cypher, Stream Processing Platforms Storm, Spark,.. Batch Processing Platforms MapReduce, SparkSQL, BigQuery, Hive, Cypher,...
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018
 Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018 R E T H I N K I N G Stream Processing with Apache Kafka Kafka the Streaming Data Platform 1.0 Enterprise
Un'introduzione a Kafka Streams e KSQL and why they matter! ITOUG Tech Day Roma 1 Febbraio 2018 R E T H I N K I N G Stream Processing with Apache Kafka Kafka the Streaming Data Platform 1.0 Enterprise
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora
 Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
Turning NoSQL data into Graph Playing with Apache Giraph and Apache Gora Team Renato Marroquín! PhD student: Interested in: Information retrieval. Distributed and scalable data management. Apache Gora:
Before proceeding with this tutorial, you must have a good understanding of Core Java and any of the Linux flavors.
 About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
August 23, 2017 Revision 0.3. Building IoT Applications with GridDB
 August 23, 2017 Revision 0.3 Building IoT Applications with GridDB Table of Contents Executive Summary... 2 Introduction... 2 Components of an IoT Application... 2 IoT Models... 3 Edge Computing... 4 Gateway
August 23, 2017 Revision 0.3 Building IoT Applications with GridDB Table of Contents Executive Summary... 2 Introduction... 2 Components of an IoT Application... 2 IoT Models... 3 Edge Computing... 4 Gateway
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing Twitter Data with MongoDB. Xiaoxiao Liu
 Processing Twitter Data with MongoDB Xiaoxiao Liu Issue with Facebook Data Original, I planned to do this project with Facebook Data. - Facebook Graph API - Third-Party Java Library: restfb I was interested
Processing Twitter Data with MongoDB Xiaoxiao Liu Issue with Facebook Data Original, I planned to do this project with Facebook Data. - Facebook Graph API - Third-Party Java Library: restfb I was interested
Griddable.io architecture
 Griddable.io architecture Executive summary This whitepaper presents the architecture of griddable.io s smart grids for synchronized data integration. Smart transaction grids are a novel concept aimed
Griddable.io architecture Executive summary This whitepaper presents the architecture of griddable.io s smart grids for synchronized data integration. Smart transaction grids are a novel concept aimed
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench
 CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
CIS 612 Advanced Topics in Database Big Data Project Lawrence Ni, Priya Patil, James Tench Abstract Implementing a Hadoop-based system for processing big data and doing analytics is a topic which has been
rkafka rkafka is a package created to expose functionalities provided by Apache Kafka in the R layer. Version 1.1
 rkafka rkafka is a package created to expose functionalities provided by Apache Kafka in the R layer. Version 1.1 Wednesday 28 th June, 2017 rkafka Shruti Gupta Wednesday 28 th June, 2017 Contents 1 Introduction
rkafka rkafka is a package created to expose functionalities provided by Apache Kafka in the R layer. Version 1.1 Wednesday 28 th June, 2017 rkafka Shruti Gupta Wednesday 28 th June, 2017 Contents 1 Introduction
HCatalog. Table Management for Hadoop. Alan F. Page 1
 HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_
 Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Streaming analytics better than batch - when and why? _Adam Kawa - Dawid Wysakowicz_ About Us At GetInData, we build custom Big Data solutions Hadoop, Flink, Spark, Kafka and more Our team is today represented
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Big Data Infrastructure at Spotify
 Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Infrastructure at Spotify Wouter de Bie Team Lead Data Infrastructure September 26, 2013 2 Who am I? According to ZDNet: "The work they have done to improve the Apache Hive data warehouse system
Big Data Facebook
 Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Processing 11 billions events a day with Spark. Alexander Krasheninnikov
 Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
Processing 11 billions events a day with Spark Alexander Krasheninnikov Badoo facts 46 languages 10M Photos added daily 320M registered users 190 countries 21M daily active users 3000+ servers 2 data-centers
Talend Big Data Sandbox. Big Data Insights Cookbook
 Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Overview Pre-requisites Setup & Configuration Hadoop Distribution Download Demo (Scenario) Overview Pre-requisites Setup & Configuration Hadoop Distribution Demo (Scenario) About this cookbook What is
Tuning Intelligent Data Lake Performance
 Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
Tuning Intelligent Data Lake Performance 2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise) without
Exam C IBM Cloud Platform Application Development v2 Sample Test
 Exam C5050 384 IBM Cloud Platform Application Development v2 Sample Test 1. What is an advantage of using managed services in IBM Bluemix Platform as a Service (PaaS)? A. The Bluemix cloud determines the
Exam C5050 384 IBM Cloud Platform Application Development v2 Sample Test 1. What is an advantage of using managed services in IBM Bluemix Platform as a Service (PaaS)? A. The Bluemix cloud determines the
MSG: An Overview of a Messaging System for the Grid
 MSG: An Overview of a Messaging System for the Grid Daniel Rodrigues Presentation Summary Current Issues Messaging System Testing Test Summary Throughput Message Lag Flow Control Next Steps Current Issues
MSG: An Overview of a Messaging System for the Grid Daniel Rodrigues Presentation Summary Current Issues Messaging System Testing Test Summary Throughput Message Lag Flow Control Next Steps Current Issues
Apache Hadoop Goes Realtime at Facebook. Himanshu Sharma
 Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Apache Hadoop Goes Realtime at Facebook Guide - Dr. Sunny S. Chung Presented By- Anand K Singh Himanshu Sharma Index Problem with Current Stack Apache Hadoop and Hbase Zookeeper Applications of HBase at
Oracle Data Integrator 12c: Integration and Administration
 Oracle University Contact Us: Local: 1800 103 4775 Intl: +91 80 67863102 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive
Oracle University Contact Us: Local: 1800 103 4775 Intl: +91 80 67863102 Oracle Data Integrator 12c: Integration and Administration Duration: 5 Days What you will learn Oracle Data Integrator is a comprehensive
Lily 2.4 What s New Product Release Notes
 Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
Lily 2.4 What s New Product Release Notes WHAT S NEW IN LILY 2.4 2 Table of Contents Table of Contents... 2 Purpose and Overview of this Document... 3 Product Overview... 4 General... 5 Prerequisites...
MEAP Edition Manning Early Access Program Flink in Action Version 2
 MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for
MEAP Edition Manning Early Access Program Flink in Action Version 2 Copyright 2016 Manning Publications For more information on this and other Manning titles go to www.manning.com welcome Thank you for