SciSpark Tutorial 101
|
|
|
- Arthur Wheeler
- 6 years ago
- Views:
Transcription
1 SciSpark Tutorial 101 Introduction to Spark Super Cool Parallel Computing In-Memory Map-Reduce It Slices, It Dices, It Minces,... So Fast, You Won t Believe It!!! ORDER NOW!!!
2 Agenda for 101: Intro. to SciSpark Project Access your SciSpark & Notebook VM (personal sandbox) What is Spark? Lightning-Fast Cluster (Parallel) Computing Simple programming in python or scala SciSpark Extensions scitensor: N-dimensional arrays in Spark srdd: scientific RDD s Notebook Technology Tutorial Notebooks: 101-0: Spark Warmup 101-1: Intro. to Spark (in scala & python) 101-2: Spark SQL and DataFrames 101-3: Simple srdd Notebook (optional) 101-4: Parallel Statistical Rollups for a Time-Series of Grids (pyspark)
3 Claim your SciSpark VM Go to: You ll have to click through! Enter your name next to an IP address to claim it Enter the URL in your browser to access the SciSpark Notebook Chrome or Firefox preferred
4 Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays in Spark srdd: scientific RDD s Implementation of Mesoscale Convective Complexes (MCC) Analytics Find cloud elements, analyze evolution, connect the graph Tutorial Notebooks: 201-1: Using scitensor and srdd 201-2: More SciSpark API & Lazy Evaluation 201-3: End-to-end analysis of Mesoscale Convective Systems 201-4: MCS Cloud Element Analytics
5 Agenda for 301: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project PDF Clustering Use Case K-means Clustering of atmospheric behavior using a full probability density function (PDF) or just moments: histogram versus (std dev, skewness) SciSpark Challenges & Lessons Learned Tutorial Notebooks: 301-1, 2, 3: PDF Clustering in PySpark, in Scala, Side by Side 301-4: Regional Climate Model Evaluation (RCMES) - (optional) 301-5: CMDA Workflow Example 301-6: Lessons Learned Notebook Wrap-up Discussion: How do you do X in SciSpark? Bring your Use Cases and questions
6 SciSpark AIST Project AIST Funded by Mike Little PI: Christian Mattmann Project Mgr: Brian Wilson JPL Team: Kim Whitehall, Sujen Shah, Maziyar Boustani, Alex Goodman, Wayne Burke, Gerald Manipon, Paul Ramirez, Rishi Verma, Lewis McGibbney Interns: Rahul Palamuttam, Valerie Roth, Harsha Manjunatha, Renato Marroquin
7 How did we get involved with Spark?

8
9


10
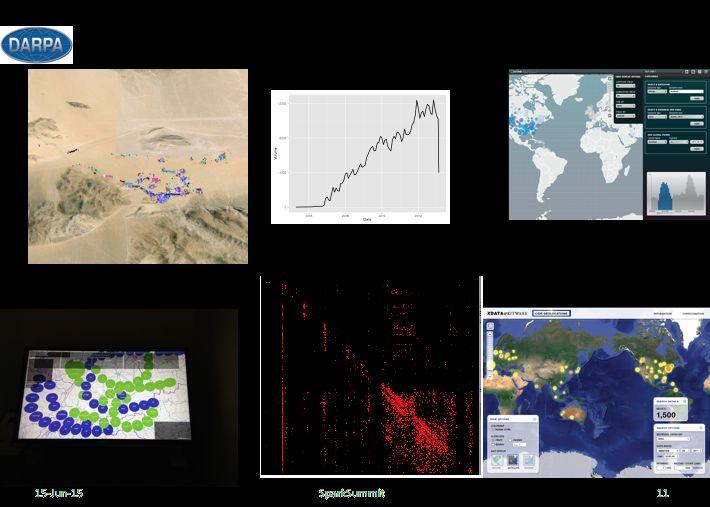
11 Motivation for SciSpark Experiment with in memory and frequent data reuse operations Regridding, Interactive Analytics such as MCC search, and variable clustering (min/max) over decadal datasets could benefit from in-memory testing (rather than frequent disk I/O) Data Ingestion (preparation, formatting)

12 SciSpark: Envisioned Architecture

13 SciSpark: Motivation Climate and weather directly impacts all aspects of society To understand average climate conditions, and extreme weather events, we need data from climate models and observations These data are voluminous & heterogeneous - varying spatial and temporal resolutions in various scientific data formats Provides important information for policyand decision- makers, as well as for Earth science and climate change researchers "AtmosphericModelSchematic" by NOAA - http: //celebrating200years.noaa. gov/breakthroughs/climate_model/atmosphericmo delschematic.png. Licensed under Public Domain via Commons - org/wiki/file:atmosphericmodelschematic. png#/media/file:atmosphericmodelschematic.png
14 SciSpark: an analytical engine for science data I/O is major performance bottleneck Reading voluminous hierarchical datasets Batch processing limits interaction and exploration of scientific datasets Regridding, interactive analytics, and variable clustering (min/max) over decadal datasets could benefit from in-memory computation Spark Resilient Distributed Dataset (RDD) Enables re-use of intermediate results Replicated, distributed, and reconstructed In memory for fast interactivity 14
15 SciSpark: A Two-Pronged Approach to Spark Extend Native Spark on the JVM (scala, java) Handle Earth Science geolocated arrays (variables as a function of time, lat, lon) Provide netcdf & OPeNDAP data ingest Provide array operators like numpy Implement two complex Use Cases: Mesoscale Convective Systems (MCS) - discover cloud elements, connect graph PDF Clustering of atmospheric state over N. America Exploit PySpark (Spark jobs using python gateway) Exploit numpy & scipy ecosystem Port and parallelize existing python analysis codes in PySpark Statistical Rollups over Long Time-Series Regional Climate Model Evaluation System (RCMES) Many others
16 PySpark Gateway Has full Python ecosystem available Numpy N-dimensional arrays Scipy algorithms However, now have two runtimes: Python & JVM Py4J gateway moves simple data structures back-and-forth At expense of communication overhead, format conversions Apache Spark actually supports three languages: Scala, Python, Java Can translate from Python to Scala almost line-by-line
17 Three Challenges using Spark for Earth Science Adapting Spark RDD to geospatial 2D & 3D (dense) arrays srdd, with loaders from netcdf & HDF files scitensor using ND4J or Breeze Reworking complex science algorithms (like GTG) into Spark s map-, filter-, and reduce- paradigm Generate parallel work at expense of duplicating some data Port or redevelop key algorithms from python/c to Scala Performance for bundles of dense arrays in Spark JVM Large arrays in memory require large JVM heap Garbage collection overheads
18 Parallel Computing Styles Task-Driven: Recursively Divide work into small Tasks Execute them in parallel Data-Driven: First, Partition the data across the Cluster Then Compute using map-filter-reduce Repartition (shuffle) data as necessary using groupbykey
19 Sources of Parallel Work (Independent Data) Parallelize Over Time: Variables (grids) over a Long Year Time-Series (keep grid together) Parallelize Over Space (and/or Altitude): By Pixel: Independent Time-Series, Massive Parallelism By Spatial Tiles: Subsetting, Area Averaging, Stencils (NEXUS) By Blocks: Blocked Array operations (harder algorithms) Parallelize Over Variable, Model, Metrics, Parameters, etc. Ensemble Model evaluation with multiple metrics Search Parameter Space with many analyses and runs

20 What is Apache Spark? - In-memory Map-Reduce 20
21 What is Apache Spark? - In-memory Map-Reduce Datasets partitioned across a compute cluster by key Shard by time, space, and/or variable RDD: Resilient Distributed Dataset Fault-tolerant, parallel data structures Intermediate results persisted in memory User controls the partitioning to optimize data placement New RDD s computed using pipeline of transformations Resilience: Lost shards can be recomputed from saved pipeline Rich set of operators on RDD s Parallel: Map, Filter, Sample, PartitionBy, Sort Reduce: GroupByKey, ReduceByKey, Count, Collect, Union, Join Computation is implicit (Lazy) until answers needed Pipeline of Transformations implicitly define a New RDD RDD computed only when needed (Action): Count, Collect, Reduce Persistence Hierarchy (SaveTo) Implicit Pipelined RDD, In-Memory, On fast SSD, On Hard Disk 21

22 Apache Spark Transformations & Actions
23 SciSpark Project Contributions Parallel Ingest of Science Data from netcdf and HDF Using OPeNDAP and Webification URL s to slice arrays Scientific RDD s for large arrays (srdd s) Bundles of 2,3,4-dimensional arrays keyed by name Partitioned by time and/or space More Operators ArraySplit by time and space, custom statistics, etc. Sophisticated Statistics and Machine Learning Higher-Order Statistics (skewness, kurtosis) Multivariate PDF s and histograms Clustering, Graph algorithms Partitioned Variable Cache (in development) Store named arrays in distributed Cassandra db or HDFS Interactive Statistics and Plots Live code window submits jobs to SciSpark Cluster Incremental statistics and plots stream into the browser UI
24 Spark Split Methods Sequence files: text files, log files, sequences of records If in HDFS, already split across the cluster (original use for Hadoop & Spark) sc.parallelize(list, numpartitions=32) Split a list or array into chunks across the cluster sc.textfile(path, numpartitions=32), sc.binaryfile() Split a text (or binary) file into chunks of records Each chunk is set of lines or records sc.wholetextfiles(), sc.wholebinaryfiles() Split list of files across the cluster, whole files are kept intact Custom Partition methods Write your own
25 SciSpark Extensions for netcdf scisparkcontext.netcdffile([path or DAP URL], numpartitions=32) Read multiple variables (arrays) & attributes into a scitensor scisparkcontext.netcdfdfsfile([list of netcdf files in local dir. or HDFS]) Split a list or array into chunks across the cluster scisparkcontext.openpath([all netcdf files nested under top directory]) scisparkcontext.readmergfile() Read a custom binary file
26 SciSpark Front-end: Notebooks
27 SciSpark Front-end: Notebooks Multi-interpreter support (by cell) Scala (default), Python (%pyspark), Spark SQL (%sql), etc. Documentation cells in markdown (%md), HTML, with images Notebook automatically connects to spark-shell (cluster) SparkContext available as sc Progress bars while executing Spark tasks Other features Auto-saved as you type Can share, copy & modify, group edit & view Run your own Notebook server using Spark standalone

28 SciSpark Infrastructure Stack Leverages open-sourced projects

29 SciSpark Extensions To Core Ecosystem SciSpark srdd scitensor
30 Notebook 101-0: Spark Warmup
31 Notebook 101-1: Intro. to Spark
32 Spark also does SQL and DataFrames This is useful for Earth Science Datasets because: Heterogeneity of data: In delimited file formats such as.csv files (e.g. NOAA s NCEI StormData, some station data) In text formats (e.g. NHC reports) In SQL databases (e.g. NWS and WMO databases for climate variables) Analysis with these datasets is usually limited to single core processing in one environment and involves: subsetting (required) data from the DB or the files and storing in tabular format performing analysis available for tables transferring the results to final locations. This process is usually not very reproducible.
33 Spark also does SQL and DataFrames The notebook interface backed by Spark allows for: Loading (all) the data into the parallelized environment Discovery through the ability to access to all the data within an SQL type of environment or a frame Analysis through querying the data and visualizations
34 Notebook 101-2: Spark SQL and DataFrames
35 Challenge of handling Earth Science data Heterogeneity of the data: Some instruments produce point source data - stored in ASCII formats and tabular formats Some instruments produce multi-dimensional data for the FOV as a function of time, level, lat, lon. These are stored in data formats hierarchical data formats that are self-describing, multidimensional and usually multivariable. Common formats are netcdf, HDF. Models usually produce multi-dimensional data as well. The Spark engine does not inherently handle N-dimensional arrays Size of the data: As instruments and models improve in resolution, the data grow significantly Getting N-dimensional data into SciSpark
36 SciSpark Accomplishments srdd architecture - Built srdd and scitensor to handle scientific data formats Demonstrated functionality to read hierarchical data Extend N-Dimensional Array operations - Provide common interface for both Breeze and ND4J Support loading scientific data from multiple sources & formats SciSpark Use Case: Distributed GTG - Generate a graph (nodes are cloud areas & edges are time) using SciSpark (run time seconds) 36
 Performance")
37 Garbage Collection (GC) Performance Lessons 37
38 Notebook 101-3: Simple srdd Notebook
39 Parallel Statistical Rollups for a Time-Series of Grids General Problem: Compute per-pixel statistics for a physical variable over time for a global or regional lat/lon grid. Specific Steps: Given daily files or OpenDAP URL's over years, load the grids and mask missing values. Then compute statistics of choice: count, mean, standard deviation, minimum, maximum, skewness, kurtosis, etc. Optionally "roll up" the statistics over time by sub-periods of choice: month, season, year, 5-year, and total period.


40 Parallel Statistical Rollups for Earth Time-Series 40
41 Notebook 101-4: Parallel Statistical Rollups for Time-Series of Earth Science Grids
42 Discussion in 301: How do you do X in SciSpark? What are your Use Cases? Bring them to SciSpark 301 Who is using Spark or Hadoop? Questions?
43 Notebook Exercises Try some of the exercises Just Play Ask Questions Notebook exercises: 101-0: Spark Warmup 101-1: Intro. to Spark (in scala & python) 101-2: Spark SQL and DataFrames 101-3: Simple srdd Notebook 101-4: Parallel Statistical Rollups for a Time-Series of Grids (pyspark)
SciSpark 201. Searching for MCCs
 SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
SciSpark 301. Build Your Own Climate Metrics
 SciSpark 301 Build Your Own Climate Metrics Agenda for 301: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project PDF Clustering Use Case SciSpark Challenges & Lessons
SciSpark 301 Build Your Own Climate Metrics Agenda for 301: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project PDF Clustering Use Case SciSpark Challenges & Lessons
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
About the Tutorial. Audience. Prerequisites. Copyright and Disclaimer. PySpark
 About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Accelerate Big Data Insights
 Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Accelerate Big Data Insights Executive Summary An abundance of information isn t always helpful when time is of the essence. In the world of big data, the ability to accelerate time-to-insight can not
Scientific Applications of the Regional Climate Model Evaluation System (RCMES)
") Scientific Applications of the Regional Climate Model Evaluation System (RCMES) Paul C. Loikith, Duane E. Waliser, Chris Mattmann, Jinwon Kim, Huikyo Lee, Paul M. Ramirez, Andrew F. Hart, Cameron E. Goodale,
Scientific Applications of the Regional Climate Model Evaluation System (RCMES) Paul C. Loikith, Duane E. Waliser, Chris Mattmann, Jinwon Kim, Huikyo Lee, Paul M. Ramirez, Andrew F. Hart, Cameron E. Goodale,
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Python Certification Training
 Introduction To Python Python Certification Training Goal : Give brief idea of what Python is and touch on basics. Define Python Know why Python is popular Setup Python environment Discuss flow control
Introduction To Python Python Certification Training Goal : Give brief idea of what Python is and touch on basics. Define Python Know why Python is popular Setup Python environment Discuss flow control
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
A very short introduction
 A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Pig on Spark project proposes to add Spark as an execution engine option for Pig, similar to current options of MapReduce and Tez.
 Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Spark.jl: Resilient Distributed Datasets in Julia
 Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Geospatial Analytics at Scale
 Geospatial Analytics at Scale Milos Milovanovic CoFounder & Data Engineer milos@thingsolver.com Things Solver ENLIGHTEN YOUR DATA What we do? Advanced Analytics company based in Belgrade, Serbia. We are
Geospatial Analytics at Scale Milos Milovanovic CoFounder & Data Engineer milos@thingsolver.com Things Solver ENLIGHTEN YOUR DATA What we do? Advanced Analytics company based in Belgrade, Serbia. We are
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci, Charles Zheng.
 CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
/ Cloud Computing. Recitation 13 April 17th 2018
 15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
Spark and HPC for High Energy Physics Data Analyses
 Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Spark and HPC for High Energy Physics Data Analyses Marc Paterno, Jim Kowalkowski, and Saba Sehrish 2017 IEEE International Workshop on High-Performance Big Data Computing Introduction High energy physics
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation. Chris Herrera Hashmap
 Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Apache Ignite - Using a Memory Grid for Heterogeneous Computation Frameworks A Use Case Guided Explanation Chris Herrera Hashmap Topics Who - Key Hashmap Team Members The Use Case - Our Need for a Memory
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Techno Expert Solutions An institute for specialized studies!
 Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Course Content of Big Data Hadoop( Intermediate+ Advance) Pre-requistes: knowledge of Core Java/ Oracle: Basic of Unix S.no Topics Date Status Introduction to Big Data & Hadoop Importance of Data& Data
Working with Scientific Data in ArcGIS Platform
 Working with Scientific Data in ArcGIS Platform Sudhir Raj Shrestha sshrestha@esri.com Hong Xu hxu@esri.com Esri User Conference, San Diego, CA. July 11, 2017 What we will cover today Scientific Multidimensional
Working with Scientific Data in ArcGIS Platform Sudhir Raj Shrestha sshrestha@esri.com Hong Xu hxu@esri.com Esri User Conference, San Diego, CA. July 11, 2017 What we will cover today Scientific Multidimensional
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
The Regional Climate Model Evalua4on System (RCMES): Introduc4on and Demonstra4on
: Introduc4on and Demonstra4on") The Regional Climate Model Evalua4on System (RCMES): Introduc4on and Demonstra4on Paul C. Loikith, Duane E. Waliser, Chris MaEmann, Jinwon Kim, Huikyo Lee, Paul M. Ramirez, Andrew F. Hart, Cameron E. Goodale,
The Regional Climate Model Evalua4on System (RCMES): Introduc4on and Demonstra4on Paul C. Loikith, Duane E. Waliser, Chris MaEmann, Jinwon Kim, Huikyo Lee, Paul M. Ramirez, Andrew F. Hart, Cameron E. Goodale,
Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks
 COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Introduction to Apache Spark
 1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application