/ Cloud Computing. Recitation 13 April 17th 2018
|
|
|
- Adam Davis
- 5 years ago
- Views:
Transcription
1 / Cloud Computing Recitation 13 April 17th 2018
2 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules and quizzes! Twitter Analytics: The Team Project Phase 3
3 Project 4 Project 4.1 Batch Processing with MapReduce Project 4.2 Iterative Batch Processing Using Apache Spark Project 4.3 Stream Processing with Kafka and Samza
4 Typical MapReduce Batch Job Simplistic view of a MapReduce job Input HDFS Output Mapper Reducer HDFS You write code to implement the following classes Mapper Reducer Inputs are read from disk and outputs are written to disk Intermediate data is spilled to local disk
5 Iterative MapReduce Jobs Some applications require iterative processing Eg: Machine Learning Input HDFS Output Mapper Reducer HDFS Prepare data for the next iteration MapReduce: Data is always written to disk This leads to added overhead for each iteration Can we keep data in memory? Across Iterations? How do you manage this?

6 Apache Spark General-purpose cluster computing framework APIs in Python, Java, Scala and R Runs on Windows and UNIX-like systems

7 Spark Ecosystem Spark SQL Process structured data Run SQL-like queries against RDDs Spark Streaming Ingest data from sources like Kafka Process data with high level functions like map and reduce Output data to live dashboards or databases MLlib Machine learning algorithms such as regression Utilities such as linear algebra and statistics GraphX Graph-parallel framework Support for graph algorithms and analysis
8 Spark Web UI Provides useful information on your Spark programs You can learn about resource utilization of your cluster Is a stepping stone to optimize your jobs Status of RDD actions being computed In-depth job info Info about cached RDDs and memory usage
9 Apache Spark APIs There exists 3 sets of APIs for handling data in Spark Resilient Distributed Datasets (RDD) DataFrame Distribute collection of JVM objects Functional operators (map, filter, etc.) Distribute collection of Row objects Expressionbased operations Fast, efficient internal representations DataSet Internally rows, externally JVM objects Type safe and fast Slower than dataframes
10 Resilient Distributed Datasets Focus of Project 4.2 Can be in-memory or on disk Read-only objects Partitioned across the cluster based on a range or the hash of a key in each record Machine A Machine B RDD1 RDD2 RDD1 RDD Operation (e.g. map, filter) RDD2 Machine C RDD3 RDD3
11 Operations on RDDs Loading data >>> input_rdd = sc.textfile("text.file") Transformation Applies an operation to derive a new RDD Lazily evaluated -- may not be executed immediately >>> transform_rdd = input_rdd.filter(lambda x: "abcd" in x) Action Forces the computation on an RDD Returns a single object >>> print "Number of abcd :" + transform_rdd.count() Saving data >>> output.saveastextfile( hdfs:///output )
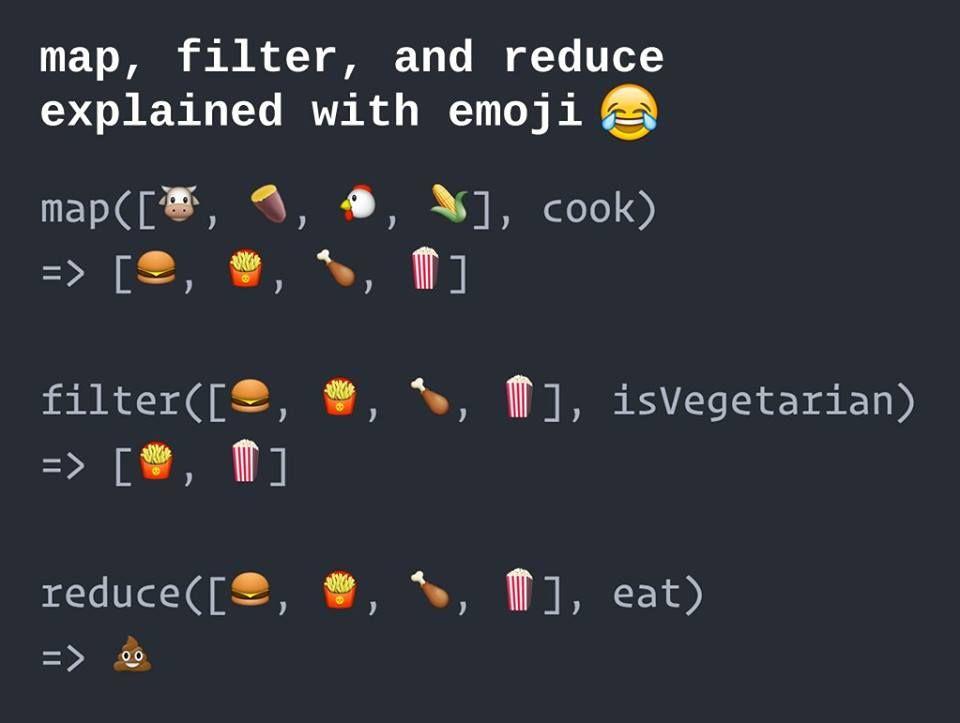
12 Operations on RDDs
13 RDDs and Fault Tolerance Actions create new RDDs Uses the notion of lineage to support fault tolerance Lineage is a log of transformations Stores lineage on the driver node Upon node failure, Spark loads data from disk to recompute the entire sequence of operations based on lineage

14 DataFrames A DataFrame is an immutable distributed collection of data Organized into named columns, like a table in a relational database A DataFrame is represented as a DataSet of rows
15 Operations on DataFrames Suppose we have a file people.json {"name":"michael"} {"name":"andy", "age":30} {"name":"justin", "age":19} Create a DataFrame with its contents val df = spark.read.json("people.json") Run SQL-like queries against the data val sqldf = df.filter($"age" > 20).show() age name Andy Save data to file df.filter($"age" > 20).select( name ).write.format( parquet ).save( output ) Note: Parquet is a column-based storage format for Hadoop. You will need special dependencies to read this file
16 Project 4.2 Task Points Description Language Tutorial 15 Reimplement the data filtering portion of Project 1.2 in Apache Spark Scala 1 10 Get familiarized with the Spark shell and running Spark programs by doing some data analysis on a Twitter graph dataset Python, Scala or Java 2 40 Calculate the influence of users in the Twitter graph dataset with the pagerank algorithm Python, Scala or Java Bonus 10 Optimize the pagerank algorithm in task 2 Probably Scala - Reflection and 5 discussion Optional, ungraded task 0 Use the Apache Spark GraphX API to implement a second degree centrality algorithm on the graph Scala


17 Tutorial Task Data filtering on a month s worth of Wikipedia data Similar to Project 1.2 Output page titles and the number of views Starter code in Scala is provided Use map, filter Use reducebykey and aggregatebykey over groupbykey
18 Twitter Social Graph Dataset that we will be using in Project 4.2 ~8GB of data Edge list of (follower, followee) pairs Directed edges (u, v) and (v, u) are two distinct edges
19 Task 1 Four parts to Task 1 Find the number of edges Find the number of vertices Find the top 100 users with the RDD API Find the top 100 users with the SparkSQL API
20 Task 2: PageRank Started as an algorithm to rank websites in search engine results Assign ranks based on the number of links pointing to them A page that has links from Many nodes high rank A high-ranking node high rank In Task 2, we will implement pagerank to find the top 100 influential vertices in the Twitter social graph
21 Basic PageRank How do we measure influence? Intuitively, it should be the node with the most followers
22 Basic PageRank Influence scores are initialized to 1.0/number of vertices
23 Basic PageRank Influence scores are initialized to 1.0/number of vertices In each iteration of the algorithm, scores of each user are redistributed between the users they are following
24 Basic PageRank Influence scores are initialized to 1.0/number of vertices In each iteration of the algorithm, scores of each user are redistributed between the users they are following From Node 0 From Node /2 = /2 = From Node From Node 2
25 Basic PageRank Influence scores are initialized to 1.0/number of vertices In each iteration of the algorithm, scores of each user are redistributed between the users they are following Convergence is achieved when the scores of nodes do not change between iterations Pagerank is guaranteed to converge From Node 0 From Node /2 = /2 = From Node From Node 2
26 Basic PageRank Influence scores are initialized to 1.0/number of vertices In each iteration of the algorithm, scores of each user are redistributed between the users they are following Convergence is achieved when the scores of nodes do not change between iterations Pagerank is guaranteed to converge
27 Basic PageRank Pseudocode (Note: This does not meet the requirements of Task 2) val links = spark.textfile(...).map(...).persist() var ranks = // RDD of (URL, rank) pairs for (i <- 1 to ITERATIONS) { // Build an RDD of (targeturl, float) pairs // with the contributions sent by each page val contribs = links.join(ranks).flatmap { (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) } // Sum contributions by URL and get new ranks ranks = contribs.reducebykey((x,y) => x+y).mapvalues(sum => a/n + (1-a)*sum) }
28 PageRank Terminology Dangling or sink vertex No outgoing edges Redistribute contribution equally among all vertices Isolated vertex No incoming and outgoing edges No isolated nodes in Project 4.2 dataset Damping factor d Represents the probability that a user clicking on links will continue clicking on them, traveling down an edge Use d = 0.85 Dangling vertex Isolated vertex
29 Visualizing Transitions Adjacency matrix: Transition matrix: (rows sum to 1)
30 Task 2: PageRank Formula for calculating rank d = 0.85
31 Task 2: PageRank Formula for calculating rank d = 0.85 Note: contributions from isolated and dangling vertices are constant in an iteration Let
32 Task 2: PageRank Formula for calculating rank d = 0.85 This simplifies the formula to Note: contributions from isolated and dangling vertices are constant in an iteration Let
33 Task 2: PageRank Formula for calculating rank d = 0.85
34 Task 2: PageRank Formula for calculating rank d = 0.85
35 Optional Non-Graded Task Implement a second-degree centrality algorithm with Apache Spark s GraphX API PageRank score is a type of centrality score Importance of a node in a graph. Score for Node 0 and Node 4 is the same: Does not make sense The 2nd degree centrality algorithm calculates a node s importance as the average of your followees and followee s followees
36 General Hints Consider the implementation differences between reducebykey, groupbykey and aggregatebykey Test out commands in the Spark Shell REPL for Spark Scala:./spark/bin/spark-shell Python:./spark/bin/pyspark Test locally on small datasets Spark can run on your local machine EMR r3 clusters are expensive Each task can take 45 min - 1 hour to run on EMR When in doubt, read the docs! SparkSQL RDD Don t forget to include in your submission Updated references file Shell commands used in Task 1 Arguably the hardest P4 project. Start early!
37 Pagerank Hints Ensuring correctness Make sure total scores sum to 1.0 in every iteration Understand closures in Spark Do not do something like this val data = Array(1,2,3,4,5) var counter = 0 var rdd = sc.parallelize(data) rdd.foreach(x => counter += x) println("counter value: " + counter) Graph representation Adjacency lists use less memory than matrices More detailed walkthroughs and sample calculations can be found here
38 Pagerank Hints Optimization Eliminate repeated calculations Use the Spark Web UI Monitor your instances to make sure they are fully utilized Identify bottlenecks Understand RDD manipulations Actions vs transformations Lazy transformations Explore parameter tuning to optimize resource usage Be careful with repartition on your RDDs
39 Upcoming Deadlines Team Project : Phase 2 Code and report due: 04/17/ :59 PM Pittsburgh Project 4.2 : Iterative Programming with Spark Due: 04/22/ :59 PM Pittsburgh Team Project : Phase 3 Live-test due: 04/29/2018 3:59 PM Pittsburgh Code and report due: 05/01/ :59 PM Pittsburgh


40 Questions?

41 twitter DATA ANALYTICS: TEAM PROJECT
42 Team Project Phase 2 MySQL Live Test Honor Board Hong Kong Journalists monoid wen as dog KingEdward FatTiger Faster Hong Kong Journalists Cerulean TaZoRo liulaliula 30 centimeter
43 Team Project Phase 2 HBase Live Test Honor Board Faster Hong Kong Journalists liulaliula 30 centimeter HLW Hong Kong Journalists DDLKiller We Bare Bears TakemezhuangbTakemefly return no_sleep Pyrocumulus
44 Team Project Phase 2 Live Test Honor Board Faster Hong Kong Journalists 80 liulaliula 80 We Bare Bears 80 HLW 78 wen as dog 76 Hong Kong Journalists 76 TakemezhuangbTakemefly 75 monoid 74 team Pyrocumulus 74
45 Query 4: Interactive Tweet Server You are going to build a web service that supports READ, WRITE, SET and DELETE requests on tweets. General Info: 1. Four operations: write, set, read and delete 2. Operations under the same uuid should be executed in the order of the sequence number 3. Be wary of malformed queries 4. Only English tweets are needed
46 Query 4: Interactive Tweet Server field type example tweetid long int userid long int username string CloudComputing timestamp string Mon Feb 15 19:19: text string Welcome to P4!#CC15619#P3 favorite_count int 22 retweet_count int 33
47 Query 4: Interactive Tweet Server Write Request /q4?op=write&payload=json_string&uuid=unique_id&s eq=sequence_number Response TEAMID,TEAM_AWS_ACCOUNT_ID\n success\n payload It is a url-encoded json string; It has the same structure as the original tweet json; It only contains the seven fields needed. For tid and uid, Don t get them from the id_str field, only get them from the id field.
48 Query 4: Interactive Tweet Server Read Request /q4?op=read&uid1=userid_1&uid2=userid_2&n=max_num ber_of_tweets&uuid=unique_id&seq=sequence_number Response TEAMID,TEAM_AWS_ACCOUNT_ID\n tid_n\ttimestamp_n\tuid_n\tusername_n\ttext_n\tfavo rite_count_n\tretweet_count_n\n
49 Query 4: Tweet Server Delete Request /q4?op=delete&tid=tweet_id&uuid=unique_id&seq=seq uence_number Response TEAMID,TEAM_AWS_ACCOUNT_ID\n success\n Delete the whole tweet
50 Query 4: Tweet Server Set Request /q4?op=set&field=field_to_set&tid=tweet_id&payloa d=string&uuid=unique_id&seq=sequence_number Response TEAMID,TEAM_AWS_ACCOUNT_ID\n success\n Set one of the text, favorite_count, retweet_count of a particular tweet Payload is a url-encoded string
51 Query 4: Tweet Server Malformed Request /q4?op=set&field=field_to_set&tid1=tweet_id&tid2= <empty>&payload=0;drop+tables+littlebobby&uuid=un ique_id&seq=sequence_number Response TEAMID,TEAM_AWS_ACCOUNT_ID\n success\n
52 Phase 2 Live Test Issues Cache became too large Used up IOPS Forgot to catch exceptions
53 Team Project General Hints Identify the bottlenecks using fine-grained profiling. Do not cache naively. Use logging to debug concurrent issues Review what we have learned in previous project modules Load balancing (are requests balanced?) Replication and sharding Multi-threading programming Look at the feedback of your Phase 1 and Phase 2 reports! To test mixed queries, run your own load generator. Use jmeter/ab/etc.
54 Team Project, Q4 Hints Start with one machine if you are not sure that your concurrency model is correct. Adopt a forwarding mechanism or a non-forwarding mechanism You may need a custom load balancer Think carefully about your async/sync design May need many connections and threads at the same time, in the case of out of order sequence numbers.
55 Team Project Time Table Phase (and query due) Start Deadlines Code and Report Due Phase 1 Q1, Q2 Monday 02/26/ :00:00 ET Checkpoint 1, Report: Sunday 03/11/ :59:59 ET Checkpoint 2, Q1: Sunday 03/25/ :59:59 ET Phase 1, Q2: Sunday 04/01/ :59:59 ET Phase 1: Tuesday 04/03/ :59:59 ET Phase 2 Q1, Q2,Q3 Monday 04/02/ :00:00 ET Sunday 04/15/ :59:59 ET Phase 2 Live Test (Hbase AND MySQL) Q1, Q2, Q3 Sunday 04/15/ :00:00 ET Sunday 04/15/ :59:59 ET Phase 3 Q1, Q2, Q3, Q4 Monday 04/16/ :00:00 ET Sunday 04/29/ :59:59 ET Phase 3 Live Test (Hbase OR MySQL) Sunday 04/29/ :00:00 ET Sunday 04/29/ :59:59 ET Q1, Q2, Q3, Q4 Tuesday 04/17/ :59:59 ET Tuesday 05/01/ :59:59 ET
56 Questions?
2
 2 3 4 5 Prepare data for the next iteration 6 7 >>>input_rdd = sc.textfile("text.file") >>>transform_rdd = input_rdd.filter(lambda x: "abcd" in x) >>>print "Number of abcd :" + transform_rdd.count() 8
2 3 4 5 Prepare data for the next iteration 6 7 >>>input_rdd = sc.textfile("text.file") >>>transform_rdd = input_rdd.filter(lambda x: "abcd" in x) >>>print "Number of abcd :" + transform_rdd.count() 8
/ Cloud Computing. Recitation 13 April 12 th 2016
 15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
/ Cloud Computing. Recitation 13 April 14 th 2015
 15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
15-319 / 15-619 Cloud Computing Recitation 13 April 14 th 2015 Overview Last week s reflection Project 4.1 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 18 Project 4.2 Demo
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
/ Cloud Computing. Recitation 10 March 22nd, 2016
 15-319 / 15-619 Cloud Computing Recitation 10 March 22nd, 2016 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.3, OLI Unit 4, Module 15, Quiz 8 This week
15-319 / 15-619 Cloud Computing Recitation 10 March 22nd, 2016 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.3, OLI Unit 4, Module 15, Quiz 8 This week
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Database Systems CSE 414
 Database Systems CSE 414 Lecture 26: Spark CSE 414 - Spring 2017 1 HW8 due next Fri Announcements Extra office hours today: Rajiv @ 6pm in CSE 220 No lecture Monday (holiday) Guest lecture Wednesday Kris
Database Systems CSE 414 Lecture 26: Spark CSE 414 - Spring 2017 1 HW8 due next Fri Announcements Extra office hours today: Rajiv @ 6pm in CSE 220 No lecture Monday (holiday) Guest lecture Wednesday Kris
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
/ Cloud Computing. Recitation 8 October 18, 2016
 15-319 / 15-619 Cloud Computing Recitation 8 October 18, 2016 1 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 3, Module 13, Quiz 6 This week
15-319 / 15-619 Cloud Computing Recitation 8 October 18, 2016 1 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 3, Module 13, Quiz 6 This week
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
/ Cloud Computing. Recitation 7 October 10, 2017
 15-319 / 15-619 Cloud Computing Recitation 7 October 10, 2017 Overview Last week s reflection Project 3.1 OLI Unit 3 - Module 10, 11, 12 Quiz 5 This week s schedule OLI Unit 3 - Module 13 Quiz 6 Project
15-319 / 15-619 Cloud Computing Recitation 7 October 10, 2017 Overview Last week s reflection Project 3.1 OLI Unit 3 - Module 10, 11, 12 Quiz 5 This week s schedule OLI Unit 3 - Module 13 Quiz 6 Project
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
/ Cloud Computing. Recitation 15 December 6 th 2016
 15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
15-319 / 15-619 Cloud Computing Recitation 15 December 6 th 2016 Overview Last week s reflection Team project phase 3 Quiz 12 This week s schedule Phase3 report Deadline TODAY 12/6 Project 4.3 Deadline
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Lightning Fast Cluster Computing. Michael Armbrust Reflections Projections 2015 Michast
 Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Lightning Fast Cluster Computing Michael Armbrust - @michaelarmbrust Reflections Projections 2015 Michast What is Apache? 2 What is Apache? Fast and general computing engine for clusters created by students
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Fault Tolerant Distributed Main Memory Systems
 Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Distributed Computing with Spark
 Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
Distributed Computing with Spark Reza Zadeh Thanks to Matei Zaharia Outline Data flow vs. traditional network programming Limitations of MapReduce Spark computing engine Numerical computing on Spark Ongoing
CS / Cloud Computing. Recitation 11 November 5 th and Nov 8 th, 2013
 CS15-319 / 15-619 Cloud Computing Recitation 11 November 5 th and Nov 8 th, 2013 Announcements Encounter a general bug: Post on Piazza Encounter a grading bug: Post Privately on Piazza Don t ask if my
CS15-319 / 15-619 Cloud Computing Recitation 11 November 5 th and Nov 8 th, 2013 Announcements Encounter a general bug: Post on Piazza Encounter a grading bug: Post Privately on Piazza Don t ask if my
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Spark & Spark SQL. High- Speed In- Memory Analytics over Hadoop and Hive Data. Instructor: Duen Horng (Polo) Chau
 Chau") CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
CSE 6242 / CX 4242 Data and Visual Analytics Georgia Tech Spark & Spark SQL High- Speed In- Memory Analytics over Hadoop and Hive Data Instructor: Duen Horng (Polo) Chau Slides adopted from Matei Zaharia
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
In-Memory Processing with Apache Spark. Vincent Leroy
 In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
In-Memory Processing with Apache Spark Vincent Leroy Sources Resilient Distributed Datasets, Henggang Cui Coursera IntroducBon to Apache Spark, University of California, Databricks Datacenter OrganizaBon
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS
 WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Assignment 3 ITCS-6010/8010: Cloud Computing for Data Analysis
 Assignment 3 ITCS-6010/8010: Cloud Computing for Data Analysis Due by 11:59:59pm on Tuesday, March 16, 2010 This assignment is based on a similar assignment developed at the University of Washington. Running
Assignment 3 ITCS-6010/8010: Cloud Computing for Data Analysis Due by 11:59:59pm on Tuesday, March 16, 2010 This assignment is based on a similar assignment developed at the University of Washington. Running
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
/ Cloud Computing. Recitation 6 October 2 nd, 2018
 15-319 / 15-619 Cloud Computing Recitation 6 October 2 nd, 2018 1 Overview Announcements for administrative issues Last week s reflection OLI unit 3 module 7, 8 and 9 Quiz 4 Project 2.3 This week s schedule
15-319 / 15-619 Cloud Computing Recitation 6 October 2 nd, 2018 1 Overview Announcements for administrative issues Last week s reflection OLI unit 3 module 7, 8 and 9 Quiz 4 Project 2.3 This week s schedule
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
 Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.814/6.830 Database Systems: Fall 2016 Quiz II There are 14 questions and?? pages in this quiz booklet.
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.814/6.830 Database Systems: Fall 2016 Quiz II There are 14 questions and?? pages in this quiz booklet.
/ Cloud Computing. Recitation 9 March 15th, 2016
 15-319 / 15-619 Cloud Computing Recitation 9 March 15th, 2016 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 4, Module 14, Quiz 7 This week
15-319 / 15-619 Cloud Computing Recitation 9 March 15th, 2016 Overview Administrative issues Office Hours, Piazza guidelines Last week s reflection Project 3.2, OLI Unit 4, Module 14, Quiz 7 This week
/ Cloud Computing. Recitation 3 Sep 13 & 15, 2016
 15-319 / 15-619 Cloud Computing Recitation 3 Sep 13 & 15, 2016 1 Overview Administrative Issues Last Week s Reflection Project 1.1, OLI Unit 1, Quiz 1 This Week s Schedule Project1.2, OLI Unit 2, Module
15-319 / 15-619 Cloud Computing Recitation 3 Sep 13 & 15, 2016 1 Overview Administrative Issues Last Week s Reflection Project 1.1, OLI Unit 1, Quiz 1 This Week s Schedule Project1.2, OLI Unit 2, Module
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Big Data Infrastructures & Technologies Hadoop Streaming Revisit.
 Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Big Data Infrastructures & Technologies Hadoop Streaming Revisit ENRON Mapper ENRON Mapper Output (Excerpt) acomnes@enron.com blake.walker@enron.com edward.snowden@cia.gov alex.berenson@nyt.com ENRON Reducer
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
CS / Cloud Computing. Recitation 3 September 9 th & 11 th, 2014
 CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
CS15-319 / 15-619 Cloud Computing Recitation 3 September 9 th & 11 th, 2014 Overview Last Week s Reflection --Project 1.1, Quiz 1, Unit 1 This Week s Schedule --Unit2 (module 3 & 4), Project 1.2 Questions
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark
 Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL. May 2015
 Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Lambda Architecture for Batch and Real- Time Processing on AWS with Spark Streaming and Spark SQL May 2015 2015, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
1
 1 2 3 6 7 8 9 10 Storage & IO Benchmarking Primer Running sysbench and preparing data Use the prepare option to generate the data. Experiments Run sysbench with different storage systems and instance
1 2 3 6 7 8 9 10 Storage & IO Benchmarking Primer Running sysbench and preparing data Use the prepare option to generate the data. Experiments Run sysbench with different storage systems and instance
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Dell In-Memory Appliance for Cloudera Enterprise
 Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
Dell In-Memory Appliance for Cloudera Enterprise Spark Technology Overview and Streaming Workload Use Cases Author: Armando Acosta Hadoop Product Manager/Subject Matter Expert Armando_Acosta@Dell.com/
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills