A brief history on Hadoop
|
|
|
- Constance Marcia Shepherd
- 5 years ago
- Views:
Transcription
1 Hadoop Basics
2 A brief history on Hadoop Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct Google releases papers with GFS (Google File System) Dec Google releases papers with MapReduce Nutch used GFS and MapReduce to perform operations Yahoo! created Hadoop based on GFS and MapReduce (with Doug Cutting and team) Yahoo started using Hadoop on a 1000 node cluster Jan Apache took over Hadoop Jul Tested a 4000 node cluster with Hadoop successfully Hadoop successfully sorted a petabyte of data in less than 17 hours to handle billions of searches and indexing millions of web pages. Dec Hadoop releases version 1.0 Aug Version is available

3 Hadoop Ecosystem
4 The two major components of Hadoop Hadoop Distributed File System (HDFS) MapReduce Framework
5 HDFS HDFS is a filesystem designed for storing very large files running on clusters of commodity hardware. - Very large file: some hadoop clusters stores petabytes of data. - Commodity hardware: Hadoop doesn t require expensive, highly reliable harware to run on. It is designed to run on clusters of commodity hardware.
6 Blocks - Files in HDFS are broken into block-sized chunks. Each chunk is stored in an independent unit. - By default, the size of each block is 64 MB.
7 - Some benefits of splitting files into blocks. -- a file can be larger than any single disk in the network. -- Blocks fit well with replication for providing fault tolerance and availability. To insure against corrupted blocks and disk/machine failure, each block is replicated to a small number of physically separate machines.
8
9 Namenodes -- The namenode manages the filesystem namespace. -- It maintains the filesystem tree and the metadata for all the files and directories. -- It also contains the information on the locations of blocks for a given file. Datanodes - datanodes: stores blocks of files. They report back to the namenodes periodically
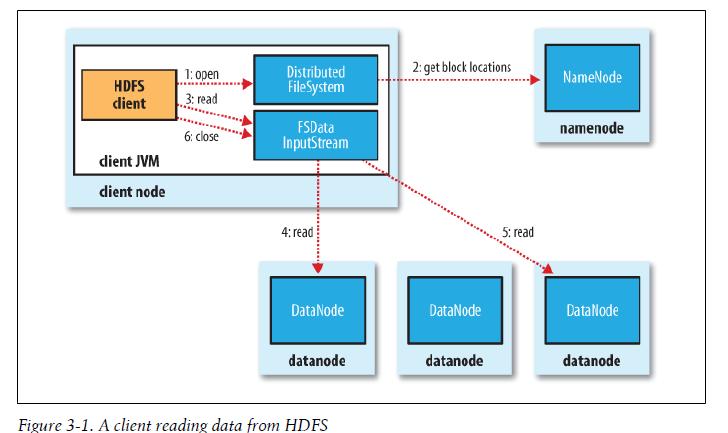
10
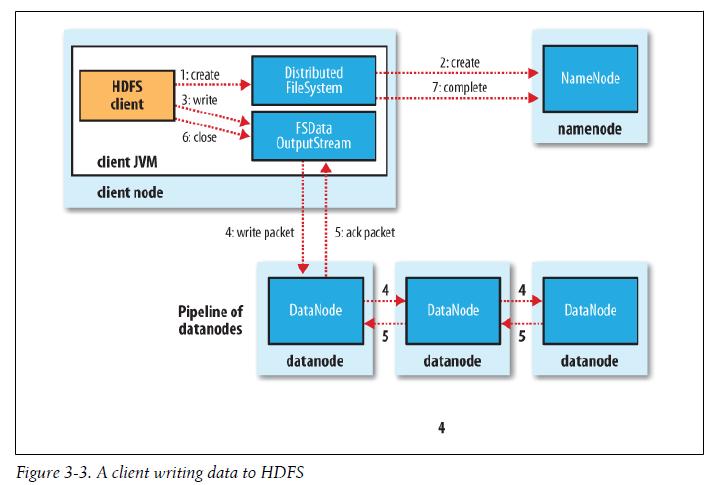
11
12 MapReduce Programming Model Mappers and Reducers In MapReduce, the programmer defines a mapper and a reducer with the following signatures: Implicit between the map and reduce phases is shuffle, sort, and group-by operation on intermediate keys. Output key-value pairs from each reducer are written persistently back onto the distributed file system.

13 MapReduce Schematic
14 Word Count- Schematic In Mappers Shuffle Reducers Out Key freq Key freq key freq Word1-Book1 n1 Word1-Book1 n1 Word1-Book2 n2 Word1-Book2 n2 Word1 n13 Book1 Word2-Book1 n3 Word1-Book3 n7 Book2 Word2-Book2 n4 Word1-Book4 n8 Word3-Book1 n5 Word3-Book2 n6 Word2-Book1 n3 Word2-Book2 n4 Word2 n14 Word2-Book3 n9 Word1-Book3 n7 Word2-Book4 n10 Word1-Book4 n8 Book3 Word2-Book3 n9 Book 4 Word2-Book4 n10 Word3-Book1 n5 Word3-Book3 n11 Word3-Book2 n6 Word3 n15 Word3-Book4 n12 Word3-Book3 n11 Word3-Book4 n12 Computation: n13 = (n1 + n1 + n7 + n8) n14 = (n3 + n4 + n9 + n10) n15 = (n5 + n6 + n11 + n12)
15 WordCount Example Given the following file that contains four documents #input file 1 Algorithm design with MapReduce 2 MapReduce Algorithm 3 MapReduce Algorithm Implementation 4 Hadoop Implementation of Hadoop We would like to count the frequency of each unique word in this file.
16
17 Two blocks of the input file #iblock 1 1 Algorithm design with MapReduce 2 MapReduce Algorithm #iblock 2 1 MapReduce Algorithm implementattion 2 Hadoop implmentation of MapReduce Computing node 1: Invoke map function on each key value pair Computing node 2: Invoke map function on each key value pair (algorithm, 1), (design, 1), (with, 1), (MapReduce, 1) (MapReduce, 1), (algorithm, 1), (implementation, 1) (MapReduce, 1), (algorithm, 1) (Hadoop, 1), (implementation, 1), (of, 1), (MapReduce, 1) Shuffle and Sort (algorithm, [1, 1, 1]), (desgin, [1]), (with, [1]), (MapReduce, [1, 1, 1, 1]), (implementation, [1, 1]), (Hadoop, [1], (of, [1]) (algorithm, [1, 1, 1]), (desgin, [1]), (Hadoop, [1]) Computing node 3 Reducer 1: Invoke reduce function on each pair (implementation, [1, 1]), (MapReduce, [1, 1, 1, 1]), (of, [1]), (with, [1]) Computing node 4 Reducer 2: : Invoke reduce function on each pair (algorithm, 3), (design, 1), (Hadoop, 1) (implementation, 2), (MapReduce, 4), (of, 1), (with, 1)
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Data Analysis Using MapReduce in Hadoop Environment
 Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
Data Analysis Using MapReduce in Hadoop Environment Muhammad Khairul Rijal Muhammad*, Saiful Adli Ismail, Mohd Nazri Kama, Othman Mohd Yusop, Azri Azmi Advanced Informatics School (UTM AIS), Universiti
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391
 Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
Hadoop محبوبه دادخواه کارگاه ساالنه آزمایشگاه فناوری وب زمستان 1391 Outline Big Data Big Data Examples Challenges with traditional storage NoSQL Hadoop HDFS MapReduce Architecture 2 Big Data In information
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Cloud Computing. Hwajung Lee. Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University
 Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Cloud Computing Hwajung Lee Key Reference: Prof. Jong-Moon Chung s Lecture Notes at Yonsei University Cloud Computing Cloud Introduction Cloud Service Model Big Data Hadoop MapReduce HDFS (Hadoop Distributed
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Scalable Web Programming. CS193S - Jan Jannink - 2/25/10
 Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Scalable Web Programming CS193S - Jan Jannink - 2/25/10 Weekly Syllabus 1.Scalability: (Jan.) 2.Agile Practices 3.Ecology/Mashups 4.Browser/Client 7.Analytics 8.Cloud/Map-Reduce 9.Published APIs: (Mar.)*
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Hadoop and HDFS Overview. Madhu Ankam
 Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Hadoop and HDFS Overview Madhu Ankam Why Hadoop We are gathering more data than ever Examples of data : Server logs Web logs Financial transactions Analytics Emails and text messages Social media like
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
CS60021: Scalable Data Mining. Sourangshu Bhattacharya
 CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
CS60021: Scalable Data Mining Sourangshu Bhattacharya In this Lecture: Outline: HDFS Motivation HDFS User commands HDFS System architecture HDFS Implementation details Sourangshu Bhattacharya Computer
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
CS370 Operating Systems
 CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
CS370 Operating Systems Colorado State University Yashwant K Malaiya Fall 2017 Lecture 26 File Systems Slides based on Text by Silberschatz, Galvin, Gagne Various sources 1 1 FAQ Cylinders: all the platters?
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Enhanced Hadoop with Search and MapReduce Concurrency Optimization
 Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
Volume 114 No. 12 2017, 323-331 ISSN: 1311-8080 (printed version); ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu Enhanced Hadoop with Search and MapReduce Concurrency Optimization
HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2017 1 Google Chubby ( Apache Zookeeper) 2 Chubby Distributed lock service + simple fault-tolerant file system
CS /30/17. Paul Krzyzanowski 1. Google Chubby ( Apache Zookeeper) Distributed Systems. Chubby. Chubby Deployment.
 Distributed Systems. Chubby. Chubby Deployment.") Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Distributed Systems 15. Distributed File Systems Google ( Apache Zookeeper) Paul Krzyzanowski Rutgers University Fall 2017 1 2 Distributed lock service + simple fault-tolerant file system Deployment Client
Informa)on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies
on Retrieval and Map- Reduce Implementa)ons. Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies") Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Informa)on Retrieval and Map- Reduce Implementa)ons Mohammad Amir Sharif PhD Student Center for Advanced Computer Studies mas4108@louisiana.edu Map-Reduce: Why? Need to process 100TB datasets On 1 node:
Distributed Systems. 15. Distributed File Systems. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems 15. Distributed File Systems Paul Krzyzanowski Rutgers University Fall 2016 1 Google Chubby 2 Chubby Distributed lock service + simple fault-tolerant file system Interfaces File access
Distributed Systems. CS422/522 Lecture17 17 November 2014
 Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Distributed Systems CS422/522 Lecture17 17 November 2014 Lecture Outline Introduction Hadoop Chord What s a distributed system? What s a distributed system? A distributed system is a collection of loosely
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Hadoop MapReduce Framework
 Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Hadoop MapReduce Framework Contents Hadoop MapReduce Framework Architecture Interaction Diagram of MapReduce Framework (Hadoop 1.0) Interaction Diagram of MapReduce Framework (Hadoop 2.0) Hadoop MapReduce
Batch Inherence of Map Reduce Framework
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 6, June 2015, pg.287
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Comparative Analysis of K means Clustering Sequentially And Parallely
 Comparative Analysis of K means Clustering Sequentially And Parallely Kavya D S 1, Chaitra D Desai 2 1 M.tech, Computer Science and Engineering, REVA ITM, Bangalore, India 2 REVA ITM, Bangalore, India
Comparative Analysis of K means Clustering Sequentially And Parallely Kavya D S 1, Chaitra D Desai 2 1 M.tech, Computer Science and Engineering, REVA ITM, Bangalore, India 2 REVA ITM, Bangalore, India
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Google File System (GFS) and Hadoop Distributed File System (HDFS)
 and Hadoop Distributed File System (HDFS)") Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Google File System (GFS) and Hadoop Distributed File System (HDFS) 1 Hadoop: Architectural Design Principles Linear scalability More nodes can do more work within the same time Linear on data size, linear
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
The Google File System. Alexandru Costan
 1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
1 The Google File System Alexandru Costan Actions on Big Data 2 Storage Analysis Acquisition Handling the data stream Data structured unstructured semi-structured Results Transactions Outline File systems
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Evaluation of Apache Hadoop for parallel data analysis with ROOT
 Evaluation of Apache Hadoop for parallel data analysis with ROOT S Lehrack, G Duckeck, J Ebke Ludwigs-Maximilians-University Munich, Chair of elementary particle physics, Am Coulombwall 1, D-85748 Garching,
Evaluation of Apache Hadoop for parallel data analysis with ROOT S Lehrack, G Duckeck, J Ebke Ludwigs-Maximilians-University Munich, Chair of elementary particle physics, Am Coulombwall 1, D-85748 Garching,
Introduction to the Hadoop Ecosystem - 1
 Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
Hello and welcome to this online, self-paced course titled Administering and Managing the Oracle Big Data Appliance (BDA). This course contains several lessons. This lesson is titled Introduction to the
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian ZHENG 1, Mingjiang LI 1, Jinpeng YUAN 1
 International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
International Conference on Intelligent Systems Research and Mechatronics Engineering (ISRME 2015) The Analysis Research of Hierarchical Storage System Based on Hadoop Framework Yan LIU 1, a, Tianjian
Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (
 MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (") HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
HADOOP Lecture 5 Timeline Dec 2004: Dean/Ghemawat (Google) MapReduce paper 2005: Doug Cutting and Mike Cafarella (Yahoo) create Hadoop, at first only to extend Nutch (the name is derived from Doug s son
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
Mixing and matching virtual and physical HPC clusters. Paolo Anedda
 Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Mixing and matching virtual and physical HPC clusters Paolo Anedda paolo.anedda@crs4.it HPC 2010 - Cetraro 22/06/2010 1 Outline Introduction Scalability Issues System architecture Conclusions & Future
Chuck Cartledge, PhD. 24 September 2017
 Introduction Basics Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Hadoop and R Chuck Cartledge, PhD 24 September 2017 1/26 Table of contents (1 of 1) 1 Introduction 2 Basics
Introduction Basics Hands-on Q&A Conclusion References Files Big Data: Data Analysis Boot Camp Hadoop and R Chuck Cartledge, PhD 24 September 2017 1/26 Table of contents (1 of 1) 1 Introduction 2 Basics
Introduction to HDFS and MapReduce
 Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Introduction to HDFS and MapReduce Who Am I - Ryan Tabora - Data Developer at Think Big Analytics - Big Data Consulting - Experience working with Hadoop, HBase, Hive, Solr, Cassandra, etc. 2 Who Am I -
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX
![KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX](/thumbs/87/96360053.jpg "KillTest *KIJGT 3WCNKV[ $GVVGT 5GTXKEG Q&A NZZV ]]] QORRZKYZ IUS =K ULLKX LXKK [VJGZK YKX\OIK LUX UTK _KGX") KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
KillTest Q&A Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Version : DEMO 1 / 4 1.When is the earliest point at which the reduce method of a given Reducer can be called?
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Apache Hadoop.Next What it takes and what it means
 Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Mounica B, Aditya Srivastava, Md. Faisal Alam
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2017 IJSRCSEIT Volume 2 Issue 3 ISSN : 2456-3307 Clustering of large datasets using Hadoop Ecosystem
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Getting Started with Hadoop
 Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
Getting Started with Hadoop May 28, 2018 Michael Völske, Shahbaz Syed Web Technology & Information Systems Bauhaus-Universität Weimar 1 webis 2018 What is Hadoop Started in 2004 by Yahoo Open-Source implementation
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Actual4Dumps. Provide you with the latest actual exam dumps, and help you succeed
 Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Actual4Dumps http://www.actual4dumps.com Provide you with the latest actual exam dumps, and help you succeed Exam : HDPCD Title : Hortonworks Data Platform Certified Developer Vendor : Hortonworks Version
Big Data and Object Storage
 Big Data and Object Storage or where to store the cold and small data? Sven Bauernfeind Computacenter AG & Co. ohg, Consultancy Germany 28.02.2018 Munich Volume, Variety & Velocity + Analytics Velocity
Big Data and Object Storage or where to store the cold and small data? Sven Bauernfeind Computacenter AG & Co. ohg, Consultancy Germany 28.02.2018 Munich Volume, Variety & Velocity + Analytics Velocity
A Study of Comparatively Analysis for HDFS and Google File System towards to Handle Big Data
 A Study of Comparatively Analysis for HDFS and Google File System towards to Handle Big Data Rajesh R Savaliya 1, Dr. Akash Saxena 2 1Research Scholor, Rai University, Vill. Saroda, Tal. Dholka Dist. Ahmedabad,
A Study of Comparatively Analysis for HDFS and Google File System towards to Handle Big Data Rajesh R Savaliya 1, Dr. Akash Saxena 2 1Research Scholor, Rai University, Vill. Saroda, Tal. Dholka Dist. Ahmedabad,
UNIT-IV HDFS. Ms. Selva Mary. G
 UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
UNIT-IV HDFS HDFS ARCHITECTURE Dataset partition across a number of separate machines Hadoop Distributed File system The Design of HDFS HDFS is a file system designed for storing very large files with
Hadoop-PR Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer)
") Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Hortonworks Hadoop-PR000007 Hortonworks Certified Apache Hadoop 2.0 Developer (Pig and Hive Developer) http://killexams.com/pass4sure/exam-detail/hadoop-pr000007 QUESTION: 99 Which one of the following
Map Reduce & Hadoop Recommended Text:
 Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Map Reduce & Hadoop Recommended Text: Hadoop: The Definitive Guide Tom White O Reilly 2010 VMware Inc. All rights reserved Big Data! Large datasets are becoming more common The New York Stock Exchange
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CCA-410. Cloudera. Cloudera Certified Administrator for Apache Hadoop (CCAH)
") Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Cloudera CCA-410 Cloudera Certified Administrator for Apache Hadoop (CCAH) Download Full Version : http://killexams.com/pass4sure/exam-detail/cca-410 Reference: CONFIGURATION PARAMETERS DFS.BLOCK.SIZE
Improved MapReduce k-means Clustering Algorithm with Combiner
 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation Improved MapReduce k-means Clustering Algorithm with Combiner Prajesh P Anchalia Department Of Computer Science and Engineering
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
itpass4sure Helps you pass the actual test with valid and latest training material.
 itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
itpass4sure http://www.itpass4sure.com/ Helps you pass the actual test with valid and latest training material. Exam : CCD-410 Title : Cloudera Certified Developer for Apache Hadoop (CCDH) Vendor : Cloudera
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction