Advanced HBase Schema Design. Berlin Buzzwords, June 2012 Lars George
|
|
|
- Elmer Carter
- 5 years ago
- Views:
Transcription


1 Advanced HBase Schema Design Berlin Buzzwords, June 2012 Lars George

2 About Me SoluDons Cloudera Apache HBase & Whirr CommiIer Author of HBase The Defini.ve Guide Working with HBase since end of 2007 Organizer of the Munich OpenHUG

3 Agenda 1 Overview of HBase 2 Schema Design 3 Examples 4 Wrap up 3
4 HBase Tables
5 HBase Tables
6 HBase Tables

7 HBase Tables
8 HBase Tables

9 HBase Tables

10 HBase Tables
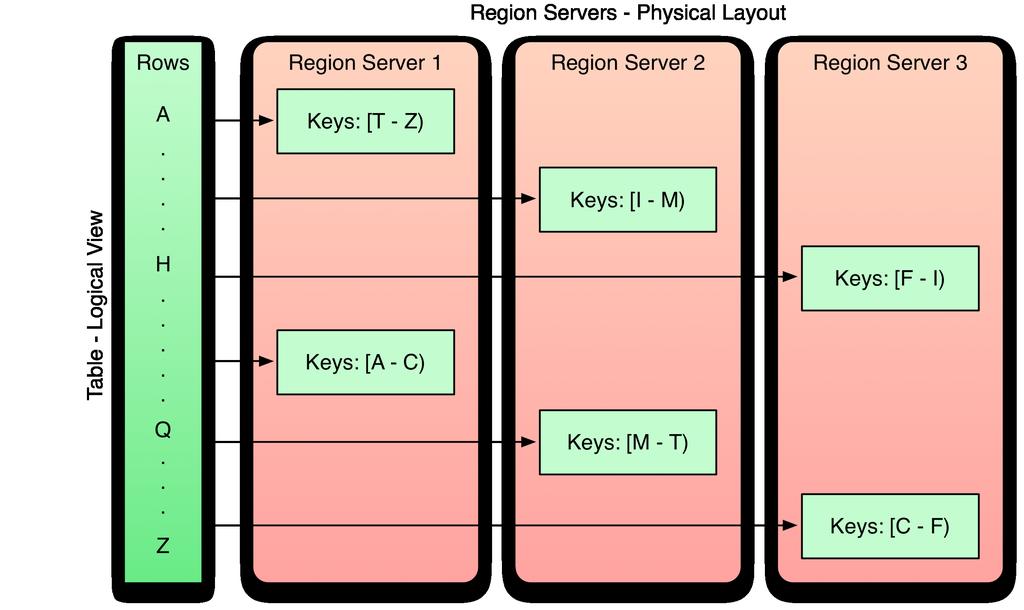
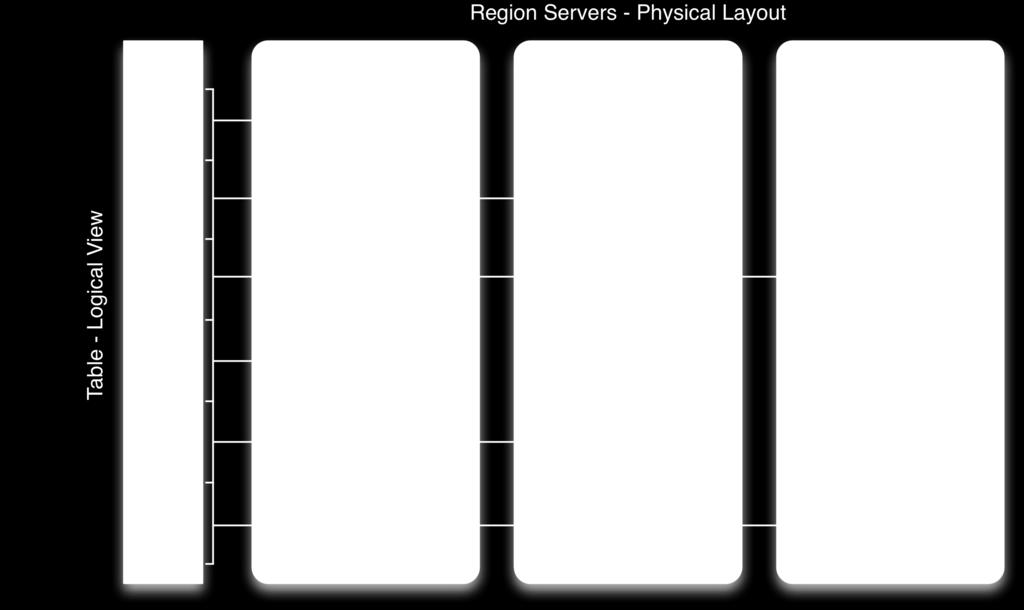
11 Physical Model: HBase Tables and Regions Table is made up of any number if regions Region is specified by its startkey and endkey Each region may live on a different node and is made up of several HDFS files and blocks, each of which is replicated by Hadoop
12 DistribuDon
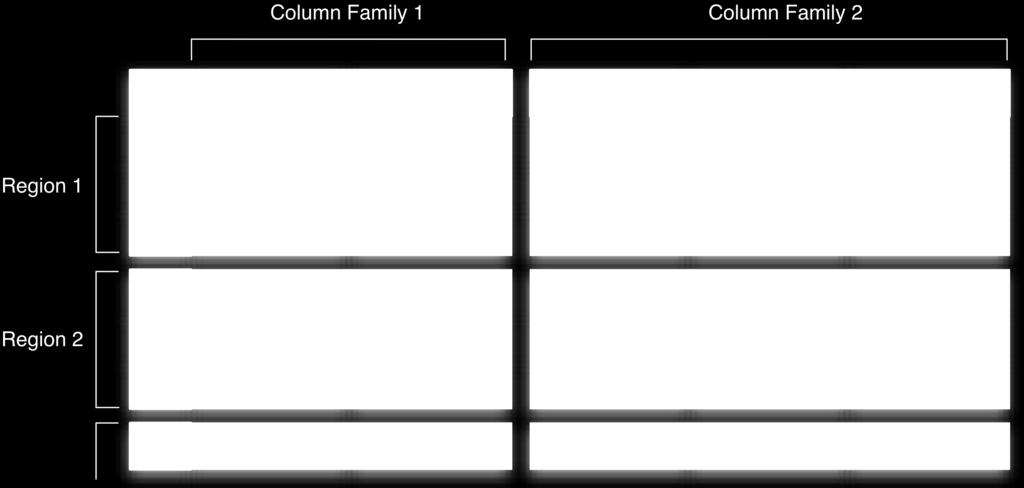
13 Storage SeparaDon Column Families allow for separadon of data Used by Columnar Databases for fast analydcal queries, but on column level only Allows different or no compression depending on the content type Segregate informadon based on access paiern Data is stored in one or more storage file, called HFiles

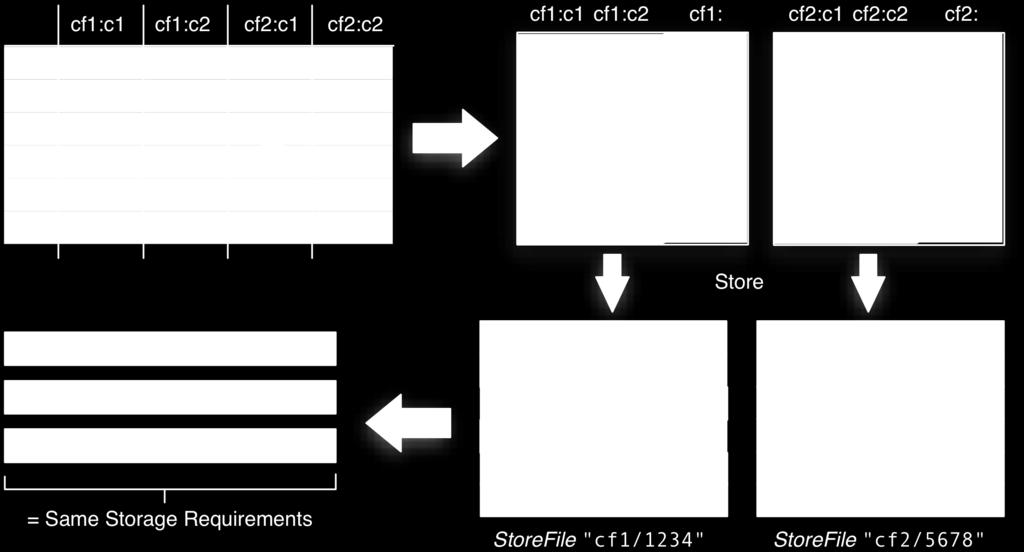
14 Fold, Store, and Shi\
15 Fold, Store, and Shi\ Logical layout does not match physical one All values are stored with the full coordinates, including: Row Key, Column Family, Column Qualifier, and Timestamp Folds columns into row per column NULLs are cost free as nothing is stored Versions are muldple rows in folded table
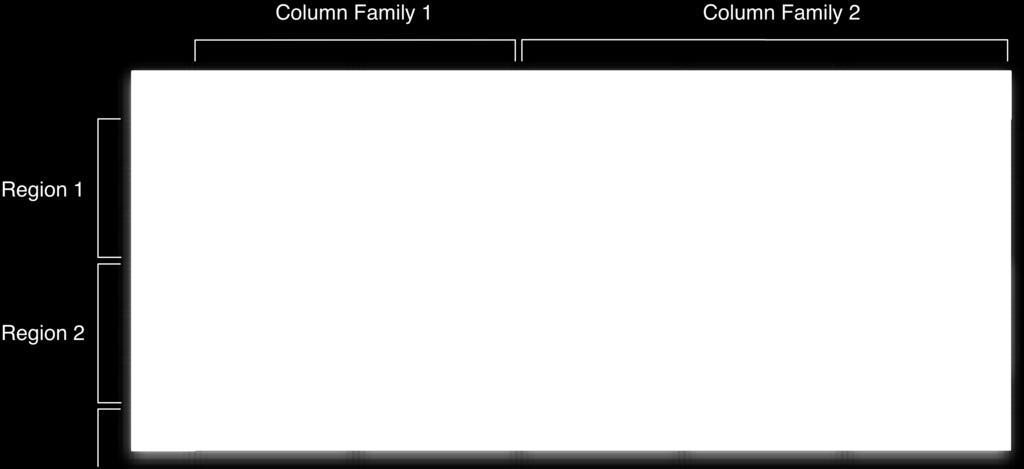
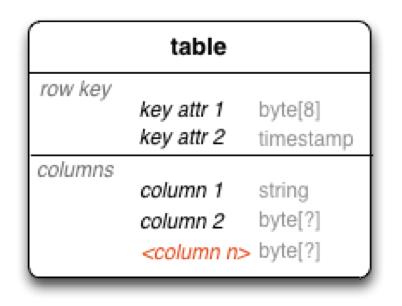
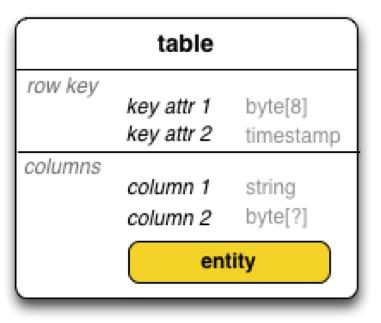
16 Logical Model: HBase Tables Tables are sorted by Row in lexicographical order Table schema only defines its column families Each family consists of any number of columns Each column consists of any number of versions Columns only exist when inserted, NULLs are free Columns within a family are sorted and stored together Everything except table names are byte[] (Table, Row, Family:Column, Timestamp) - > Value
17 Column Family vs. Column Use only a few column families Causes many files that need to stay open per region plus class overhead per family Best used when logical separadon between data and meta columns SorDng per family can be used to convey applicadon logic or access paiern
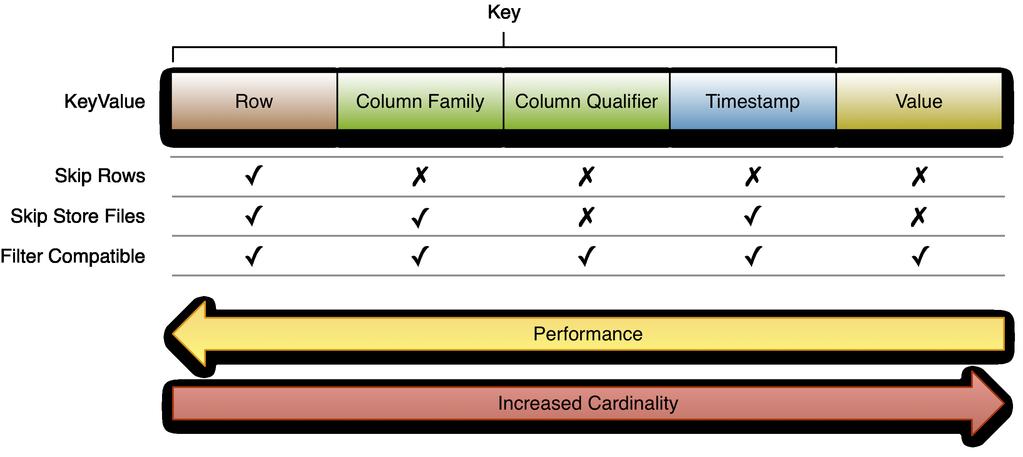
18 Key Cardinality
19 Key Cardinality The best performance is gained from using row keys Time range bound reads can skip store files So can Bloom Filters SelecDng column families reduces the amount of data to be scanned Pure value based filtering is a full table scan Filters o\en are too, but reduce network traffic
20 Key/Table Design Crucial to gain best performance Why do I need to know? Well, you also need to know that RDBMS is only working well when columns are indexed and query plan is OK Absence of secondary indexes forces use of row key or column name sordng Transfer muldple indexes into one Generate large table - > Good since fits architecture and spreads across cluster
21 DDI Stands for DenormalizaDon, DuplicaDon and Intelligent Keys Needed to overcome shortcomings of architecture DenormalizaDon - > Replacement for JOINs DuplicaDon - > Design for reads Intelligent Keys - > Implement indexing and sordng, opdmize reads


22 Key Design
23 Key Design Summary Based on access paiern, either use sequendal or random keys O\en a combinadon of both is needed Overcome architectural limitadons Neither is necessarily bad Use bulk import for sequendal keys and reads Random keys are good for random access paierns
24 Pre- materialize Everything Achieve one read per customer request if possible Otherwise keep at lowest number Reads between 10ms (cache miss) and 1ms (cache hit) Use MapReduce to compute exacts in batch Store and merge updates live Use incrementcolumnvalue MoIo: Design for Reads
25 RelaDonal Model

26 Muddled Up!

27 Remodeling
28 WTH?
29

30 Example: OpenTSDB Metric Type, Tags are stored as IDs Periodically rolled up
31 Summary Design for Use- Case Read, Write, or Both? Avoid Hotspomng Consider using IDs instead of full text Leverage Column Family to HFile reladon Shi\ details to appropriate posidon Composite Keys Column Qualifiers
32 Summary (cont.) Schema design is a combinadon of Designing the keys (row and column) Segregate data into column families Choose compression and block sizes Similar techniques are needed to scale most systems Add indexes, parddon data, consistent hashing DenormalizaDon, DuplicaDon, and Intelligent Keys (DDI)

33 QuesDons?
34 Tall- Narrow vs. Flat- Wide Tables Rows do not split Might end up with one row per region Same storage footprint Put more details into the row key SomeDmes dummy column only Make use of pardal key scans Tall with Scans, Wide with Gets Atomicity only on row level Example: Large graphs, stored as adjacency matrix
35 Example: Mail Inbox <userid> : <colfam> : <messageid> : <timestamp> : < -message> : data : 5fc38314-e290-ae5da5fc375d : : "Hi Lars,..." : data : 725aae5f-d72e-f90f3f : : "Welcome, and..." : data : cc6775b3-f249-c6dd2b1a7467 : : "To Whom It..." : data : dcbee495-6d5e-6ed c : : "Hi, how are..." or fc38314-e290-ae5da5fc375d : data : : : "Hi Lars,..." aae5f-d72e-f90f3f : data : : : "Welcome, and..." cc6775b3-f249-c6dd2b1a7467 : data : : : "To Whom It..." dcbee495-6d5e-6ed c : data : : : "Hi, how are..." è Same Storage Requirements
36 ParDal Key Scans Key <userid> <userid>-<date> <userid>-<date>-<messageid> <userid>-<date>-<messageid>-<attachmentid> Descrip2on Scan over all messages for a given user ID Scan over all messages on a given date for the given user ID Scan over all parts of a message for a given user ID and date Scan over all aiachments of a message for a given user ID and date
37 SequenDal Keys <timestamp><more key>: {CF: {CQ: {TS : Val}}} Hotspomng on Regions: bad! Instead do one of the following: SalDng Prefix <timestamp> with distributed value Binning or buckedng rows across regions Key field swap/promodon Move <more key> before the Dmestamp (see OpenTSDB later) RandomizaDon Move <timestamp> out of key
38 SalDng Prefix row keys to gain spread Use well known or numbered prefixes Use modulo to spread across servers Enforce common data stay close to each other for subsequent scanning or MapReduce processing 0_rowkey1, 1_rowkey2, 2_rowkey3 0_rowkey4, 1_rowkey5, 2_rowkey6 Sorted by prefix first 0_rowkey1 0_rowkey4 1_rowkey2 1_rowkey5
39 Hashing vs. SequenDal Keys Uses hashes for best spread Use for example MD5 to be able to recreate key Key = MD5(customerID) Counter producdve for range scans Use sequendal keys for locality Makes use of block caches May tax one server overly, may be avoided by saldng or splimng regions while keeping them small

40 ConfiguraDon Layers (aka OSI for HBase )

41 HBase Architecture (cont.)


42 Write- Ahead- Log (WAL) Flow

")
43 Write- Ahead- Log (cont.)

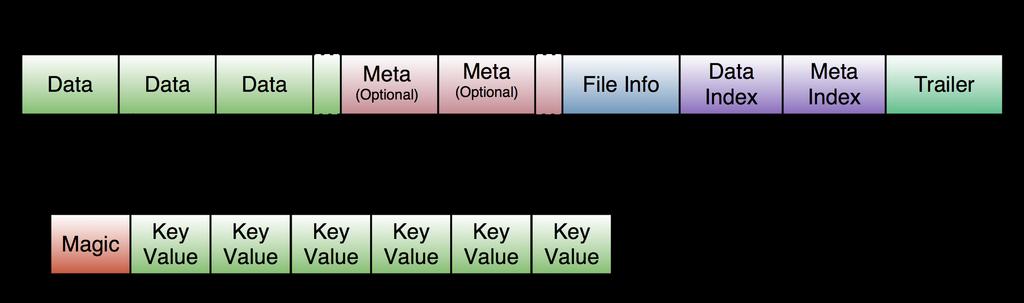
44 HFile and KeyValue
45 Raw Data View $./bin/hbase org.apache.hadoop.hbase.io.hfile.hfile -f file:///tmp/ hbase-larsgeorge/hbase/testtable/272a63b23bdb5fae759be5192cabc0ce/ f1/ p K: row1/f1:/ /put/vlen=6 V: value1 K: row2/f1:/ /put/vlen=6 V: value2 K: row3/f1:/ /put/vlen=6 V: value3 K: row4/f1:/ /put/vlen=6 V: value4 K: row5/f1:c1/ /put/vlen=6 V: value5 K: row6/f1:c2/ /put/vlen=6 V: value6 K: row7/f1:c1/ /put/vlen=7 V: value10 K: row7/f1:c1/ /put/vlen=6 V: value7 K: row7/f1:c10/ /deletecolumn/vlen=0 V: K: row7/f1:c10/ /put/vlen=7 V: value11 K: row7/f1:c11/ /put/vlen=7 V: value14 K: row7/f1:c12/ /put/vlen=7 V: value15 K: row7/f1:c13/ /put/vlen=7 V: value16 K: row7/f1:c2/ /put/vlen=6 V: value8 K: row7/f1:c3/ /put/vlen=6 V: value9 K: row7/f1:c8/ /put/vlen=7 V: value13 K: row7/f1:c9/ /put/vlen=7 V: value12
ADVANCED HBASE. Architecture and Schema Design GeeCON, May Lars George Director EMEA Services
 ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
HBase. Леонид Налчаджи
 HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
HBASE INTERVIEW QUESTIONS
 HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
Ghislain Fourny. Big Data 5. Column stores
 Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Ghislain Fourny Big Data 5. Column stores 1 Introduction 2 Relational model 3 Relational model Schema 4 Issues with relational databases (RDBMS) Small scale Single machine 5 Can we fix a RDBMS? Scale up
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
COSC 6339 Big Data Analytics. NoSQL (II) HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables
 HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables") COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
HBase... And Lewis Carroll! Twi:er,
 HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
HBase... And Lewis Carroll! jw4ean@cloudera.com Twi:er, LinkedIn: @jw4ean 1 Introduc@on 2010: Cloudera Solu@ons Architect 2011: Cloudera TAM/DSE 2012-2013: Cloudera Training focusing on Partners and Newbies
Facebook. The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011
 Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011") HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang
 International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
International Conference on Engineering Management (Iconf-EM 2016) Research on the Application of Bank Transaction Data Stream Storage based on HBase Xiaoguo Wang*, Yuxiang Liu and Lin Zhang School of
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Lecture 36 12/4/15. CMPSC431W: Database Management Systems. Instructor: Yu- San Lin
 CMPSC431W: Database Management Systems Lecture 36 12/4/15 Instructor: Yu- San Lin yusan@psu.edu Course Website: hcp://www.cse.psu.edu/~yul189/cmpsc431w Slides based on McGraw- Hill & Dr. Wang- Chien Lee
CMPSC431W: Database Management Systems Lecture 36 12/4/15 Instructor: Yu- San Lin yusan@psu.edu Course Website: hcp://www.cse.psu.edu/~yul189/cmpsc431w Slides based on McGraw- Hill & Dr. Wang- Chien Lee
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Using space-filling curves for multidimensional
 Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Using space-filling curves for multidimensional indexing Dr. Bisztray Dénes Senior Research Engineer 1 Nokia Solutions and Networks 2014 In medias res Performance problems with RDBMS Switch to NoSQL store
Cloudera Kudu Introduction
 Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
Faster HBase queries. Introducing hindex Secondary indexes for HBase. ApacheCon North America Rajeshbabu Chintaguntla
 Security Level: Faster HBase queries Introducing hindex Secondary indexes for HBase ApacheCon North America 2014 www.huawei.com Rajeshbabu Chintaguntla rajeshbabu@apache.org HUAWEI TECHNOLOGIES CO., LTD.
Security Level: Faster HBase queries Introducing hindex Secondary indexes for HBase ApacheCon North America 2014 www.huawei.com Rajeshbabu Chintaguntla rajeshbabu@apache.org HUAWEI TECHNOLOGIES CO., LTD.
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Copyright 2013, Oracle and/or its affiliates. All rights reserved.
 1 Oracle NoSQL Database: Release 3.0 What s new and why you care Dave Segleau NoSQL Product Manager The following is intended to outline our general product direction. It is intended for information purposes
1 Oracle NoSQL Database: Release 3.0 What s new and why you care Dave Segleau NoSQL Product Manager The following is intended to outline our general product direction. It is intended for information purposes
Column-Family Databases Cassandra and HBase
 Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
Column-Family Databases Cassandra and HBase Kevin Swingler Google Big Table Google invented BigTableto store the massive amounts of semi-structured data it was generating Basic model stores items indexed
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب
 Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Fattane Zarrinkalam کارگاه ساالنه آزمایشگاه فناوری وب 1391 زمستان Outlines Introduction DataModel Architecture HBase vs. RDBMS HBase users 2 Why Hadoop? Datasets are growing to Petabytes Traditional datasets
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2016) Week 10: Mutable State (1/2) March 15, 2016 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
Column Stores and HBase. Rui LIU, Maksim Hrytsenia
 Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
Column Stores and HBase Rui LIU, Maksim Hrytsenia December 2017 Contents 1 Hadoop 2 1.1 Creation................................ 2 2 HBase 3 2.1 Column Store Database....................... 3 2.2 HBase
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Integration of Apache Hive
 Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 Agenda Overview of Hive and HBase Hive + HBase Features and Improvements Future of Hive and HBase Q&A Page
Integration of Apache Hive and HBase Enis Soztutar enis [at] apache [dot] org @enissoz Page 1 Agenda Overview of Hive and HBase Hive + HBase Features and Improvements Future of Hive and HBase Q&A Page
Scaling Up HBase. Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics
 Chau Assistant Professor Associate Director, MS Analytics Georgia Tech. CSE6242 / CX4242: Data & Visual Analytics") http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
http://poloclub.gatech.edu/cse6242 CSE6242 / CX4242: Data & Visual Analytics Scaling Up HBase Duen Horng (Polo) Chau Assistant Professor Associate Director, MS Analytics Georgia Tech Partly based on materials
CA485 Ray Walshe NoSQL
 NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
NoSQL BASE vs ACID Summary Traditional relational database management systems (RDBMS) do not scale because they adhere to ACID. A strong movement within cloud computing is to utilize non-traditional data
Introduction to Column Oriented Databases in PHP
 Introduction to Column Oriented Databases in PHP By Slavey Karadzhov About Me Name: Slavey Karadzhov (Славей Караджов) Programmer since my early days PHP programmer since 1999
Introduction to Column Oriented Databases in PHP By Slavey Karadzhov About Me Name: Slavey Karadzhov (Славей Караджов) Programmer since my early days PHP programmer since 1999
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
The State of Apache HBase. Michael Stack
 The State of Apache HBase Michael Stack Michael Stack Chair of the Apache HBase PMC* Caretaker/Janitor Member of the Hadoop PMC Engineer at Cloudera in SF * Project Management
The State of Apache HBase Michael Stack Michael Stack Chair of the Apache HBase PMC* Caretaker/Janitor Member of the Hadoop PMC Engineer at Cloudera in SF * Project Management
HBase Security. Works in Progress Andrew Purtell, an Intel HBase guy
 HBase Security Works in Progress Andrew Purtell, an Intel HBase guy Outline Project Rhino Extending the HBase ACL model to per-cell granularity Introducing transparent encryption I don t always need encryption,
HBase Security Works in Progress Andrew Purtell, an Intel HBase guy Outline Project Rhino Extending the HBase ACL model to per-cell granularity Introducing transparent encryption I don t always need encryption,
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
HBase: Overview. HBase is a distributed column-oriented data store built on top of HDFS
 HBase 1 HBase: Overview HBase is a distributed column-oriented data store built on top of HDFS HBase is an Apache open source project whose goal is to provide storage for the Hadoop Distributed Computing
HBase 1 HBase: Overview HBase is a distributed column-oriented data store built on top of HDFS HBase is an Apache open source project whose goal is to provide storage for the Hadoop Distributed Computing
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
Hadoop & Big Data Analytics Complete Practical & Real-time Training
 An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
An ISO Certified Training Institute A Unit of Sequelgate Innovative Technologies Pvt. Ltd. www.sqlschool.com Hadoop & Big Data Analytics Complete Practical & Real-time Training Mode : Instructor Led LIVE
Presented by Sunnie S Chung CIS 612
 By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
By Yasin N. Silva, Arizona State University Presented by Sunnie S Chung CIS 612 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. See http://creativecommons.org/licenses/by-nc-sa/4.0/
COSC 6397 Big Data Analytics. Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading. Edgar Gabriel Spring 2014.
 HBase: Java API, HBase in MapReduce and HBase Bulk Loading. Edgar Gabriel Spring 2014.") COSC 6397 Big Data Analytics Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading Edgar Gabriel Spring 2014 Recap on HBase Column-Oriented data store NoSQL DB Data is stored in
COSC 6397 Big Data Analytics Data Formats (III) HBase: Java API, HBase in MapReduce and HBase Bulk Loading Edgar Gabriel Spring 2014 Recap on HBase Column-Oriented data store NoSQL DB Data is stored in
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Time Series Live 2017
 1 Time Series Schemas @Percona Live 2017 Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2
1 Time Series Schemas @Percona Live 2017 Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Apache HBase Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel
 Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
HBASE MOCK TEST HBASE MOCK TEST III
 http://www.tutorialspoint.com HBASE MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to HBase. You can download these sample mock tests at your local machine
http://www.tutorialspoint.com HBASE MOCK TEST Copyright tutorialspoint.com This section presents you various set of Mock Tests related to HBase. You can download these sample mock tests at your local machine
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Strategies for Incremental Updates on Hive
 Strategies for Incremental Updates on Hive Copyright Informatica LLC 2017. Informatica, the Informatica logo, and Big Data Management are trademarks or registered trademarks of Informatica LLC in the United
Strategies for Incremental Updates on Hive Copyright Informatica LLC 2017. Informatica, the Informatica logo, and Big Data Management are trademarks or registered trademarks of Informatica LLC in the United
Apache Accumulo 1.4 & 1.5 Features
 Apache Accumulo 1.4 & 1.5 Features Inaugural Accumulo DC Meetup Keith Turner What is Accumulo? A re-implementation of Big Table Distributed Database Does not support SQL Data is arranged by Row Column
Apache Accumulo 1.4 & 1.5 Features Inaugural Accumulo DC Meetup Keith Turner What is Accumulo? A re-implementation of Big Table Distributed Database Does not support SQL Data is arranged by Row Column
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
A Fast and High Throughput SQL Query System for Big Data
 A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
A Fast and High Throughput SQL Query System for Big Data Feng Zhu, Jie Liu, and Lijie Xu Technology Center of Software Engineering, Institute of Software, Chinese Academy of Sciences, Beijing, China 100190
REPORT ON DELIVERABLE Big Water Data Management engine. Ref. Ares(2015) /03/2015
 /03/2015") REPORT ON DELIVERABLE 5.1.1 Big Water Data Management engine Ref. Ares(2015)1151516-16/03/2015 PROJECT NUMBER: 619186 START DATE OF PROJECT: 01/03/2014 DURATION: 42 months DAIAD is a research project funded
REPORT ON DELIVERABLE 5.1.1 Big Water Data Management engine Ref. Ares(2015)1151516-16/03/2015 PROJECT NUMBER: 619186 START DATE OF PROJECT: 01/03/2014 DURATION: 42 months DAIAD is a research project funded
Columnstore and B+ tree. Are Hybrid Physical. Designs Important?
 Columnstore and B+ tree Are Hybrid Physical Designs Important? 1 B+ tree 2 C O L B+ tree 3 B+ tree & Columnstore on same table = Hybrid design 4? C O L C O L B+ tree B+ tree ? C O L C O L B+ tree B+ tree
Columnstore and B+ tree Are Hybrid Physical Designs Important? 1 B+ tree 2 C O L B+ tree 3 B+ tree & Columnstore on same table = Hybrid design 4? C O L C O L B+ tree B+ tree ? C O L C O L B+ tree B+ tree
SEARCHING BILLIONS OF PRODUCT LOGS IN REAL TIME. Ryan Tabora - Think Big Analytics NoSQL Search Roadshow - June 6, 2013
 SEARCHING BILLIONS OF PRODUCT LOGS IN REAL TIME Ryan Tabora - Think Big Analytics NoSQL Search Roadshow - June 6, 2013 1 WHO AM I? Ryan Tabora Think Big Analytics - Senior Data Engineer Lover of dachshunds,
SEARCHING BILLIONS OF PRODUCT LOGS IN REAL TIME Ryan Tabora - Think Big Analytics NoSQL Search Roadshow - June 6, 2013 1 WHO AM I? Ryan Tabora Think Big Analytics - Senior Data Engineer Lover of dachshunds,
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Big Data Facebook
 Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
Big Data Architectures@ Facebook QCon London 2012 Ashish Thusoo Outline Big Data @ Facebook - Scope & Scale Evolution of Big Data Architectures @ FB Past, Present and Future Questions Big Data @ FB: Scale
Understanding NoSQL Database Implementations
 Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Time Series Storage with Apache Kudu (incubating)
") Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
MongoDB. David Murphy MongoDB Practice Manager, Percona
 MongoDB Click Replication to edit Master and Sharding title style David Murphy MongoDB Practice Manager, Percona Who is this Person and What Does He Know? Former MongoDB Master Former Lead DBA for ObjectRocket,
MongoDB Click Replication to edit Master and Sharding title style David Murphy MongoDB Practice Manager, Percona Who is this Person and What Does He Know? Former MongoDB Master Former Lead DBA for ObjectRocket,
Getting to know. by Michelle Darling August 2013
 Getting to know by Michelle Darling mdarlingcmt@gmail.com August 2013 Agenda: What is Cassandra? Installation, CQL3 Data Modelling Summary Only 15 min to cover these, so please hold questions til the end,
Getting to know by Michelle Darling mdarlingcmt@gmail.com August 2013 Agenda: What is Cassandra? Installation, CQL3 Data Modelling Summary Only 15 min to cover these, so please hold questions til the end,
How Apache Hadoop Complements Existing BI Systems. Dr. Amr Awadallah Founder, CTO Cloudera,
 How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
How Apache Hadoop Complements Existing BI Systems Dr. Amr Awadallah Founder, CTO Cloudera, Inc. Twitter: @awadallah, @cloudera 2 The Problems with Current Data Systems BI Reports + Interactive Apps RDBMS
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack. Chief Architect RainStor
 Mark Cusack. Chief Architect RainStor") Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Making the Most of Hadoop with Optimized Data Compression (and Boost Performance) Mark Cusack Chief Architect RainStor Agenda Importance of Hadoop + data compression Data compression techniques Compression,
Apache Kudu. Zbigniew Baranowski
 Apache Kudu Zbigniew Baranowski Intro What is KUDU? New storage engine for structured data (tables) does not use HDFS! Columnar store Mutable (insert, update, delete) Written in C++ Apache-licensed open
Apache Kudu Zbigniew Baranowski Intro What is KUDU? New storage engine for structured data (tables) does not use HDFS! Columnar store Mutable (insert, update, delete) Written in C++ Apache-licensed open
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase
 Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase Bumjoon Jo and Sungwon Jung (&) Department of Computer Science and Engineering, Sogang University, 35 Baekbeom-ro, Mapo-gu, Seoul 04107,
Quadrant-Based MBR-Tree Indexing Technique for Range Query Over HBase Bumjoon Jo and Sungwon Jung (&) Department of Computer Science and Engineering, Sogang University, 35 Baekbeom-ro, Mapo-gu, Seoul 04107,
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Part 1: Indexes for Big Data
 JethroData Making Interactive BI for Big Data a Reality Technical White Paper This white paper explains how JethroData can help you achieve a truly interactive interactive response time for BI on big data,
JethroData Making Interactive BI for Big Data a Reality Technical White Paper This white paper explains how JethroData can help you achieve a truly interactive interactive response time for BI on big data,
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
MyRocks deployment at Facebook and Roadmaps. Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom
 MyRocks deployment at Facebook and Roadmaps Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom Agenda MySQL at Facebook MyRocks overview Production Deployment
MyRocks deployment at Facebook and Roadmaps Yoshinori Matsunobu Production Engineer / MySQL Tech Lead, Facebook Feb/2018, #FOSDEM #mysqldevroom Agenda MySQL at Facebook MyRocks overview Production Deployment
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Trafodion Enterprise-Class Transactional SQL-on-HBase
 Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
HBase Java Client API
 2012 coreservlets.com and Dima May HBase Java Client API Basic CRUD operations Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop
2012 coreservlets.com and Dima May HBase Java Client API Basic CRUD operations Originals of slides and source code for examples: http://www.coreservlets.com/hadoop-tutorial/ Also see the customized Hadoop
big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures
 mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures") Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Lecture 20 -- 11/20/2017 BigTable big picture parallel db (one data center) mix of OLTP and batch analysis lots of data, high r/w rates, 1000s of cheap boxes thus many failures what does paper say Google
Enable Spark SQL on NoSQL Hbase tables with HSpark IBM Code Tech Talk. February 13, 2018
 Enable Spark SQL on NoSQL Hbase tables with HSpark IBM Code Tech Talk February 13, 2018 https://developer.ibm.com/code/techtalks/enable-spark-sql-onnosql-hbase-tables-with-hspark-2/ >> MARC-ARTHUR PIERRE
Enable Spark SQL on NoSQL Hbase tables with HSpark IBM Code Tech Talk February 13, 2018 https://developer.ibm.com/code/techtalks/enable-spark-sql-onnosql-hbase-tables-with-hspark-2/ >> MARC-ARTHUR PIERRE
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
7. Query Processing and Optimization
 7. Query Processing and Optimization Processing a Query 103 Indexing for Performance Simple (individual) index B + -tree index Matching index scan vs nonmatching index scan Unique index one entry and one
7. Query Processing and Optimization Processing a Query 103 Indexing for Performance Simple (individual) index B + -tree index Matching index scan vs nonmatching index scan Unique index one entry and one
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
University of Waterloo Midterm Examination Sample Solution
 1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
HCatalog. Table Management for Hadoop. Alan F. Page 1
 HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
HCatalog Table Management for Hadoop Alan F. Gates @alanfgates Page 1 Who Am I? HCatalog committer and mentor Co-founder of Hortonworks Tech lead for Data team at Hortonworks Pig committer and PMC Member
Practical MySQL indexing guidelines
 Practical MySQL indexing guidelines Percona Live October 24th-25th, 2011 London, UK Stéphane Combaudon stephane.combaudon@dailymotion.com Agenda Introduction Bad indexes & performance drops Guidelines
Practical MySQL indexing guidelines Percona Live October 24th-25th, 2011 London, UK Stéphane Combaudon stephane.combaudon@dailymotion.com Agenda Introduction Bad indexes & performance drops Guidelines
Hadoop Overview. Lars George Director EMEA Services
 Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Hadoop Overview Lars George Director EMEA Services 1 About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer HBase and Whirr O Reilly Author HBase The Definitive
Who Am I? Chris Larsen
 2.4 and 3.0 Update Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2 What Is OpenTSDB? Open
2.4 and 3.0 Update Who Am I? Chris Larsen Maintainer and author for OpenTSDB since 2013 Software Engineer @ Yahoo Central Monitoring Team Who I m not: A marketer A sales person 2 What Is OpenTSDB? Open
Big Data and Scripting map reduce in Hadoop
 Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Big Data and Scripting map reduce in Hadoop 1, 2, connecting to last session set up a local map reduce distribution enable execution of map reduce implementations using local file system only all tasks
Rails on HBase. Zachary Pinter and Tony Hillerson RailsConf 2011
 Rails on HBase Zachary Pinter and Tony Hillerson RailsConf 2011 What we will cover What is it? What are the tradeoffs that HBase makes? Why HBase is probably the wrong choice for your app Why HBase might
Rails on HBase Zachary Pinter and Tony Hillerson RailsConf 2011 What we will cover What is it? What are the tradeoffs that HBase makes? Why HBase is probably the wrong choice for your app Why HBase might