Apache Accumulo 1.4 & 1.5 Features
|
|
|
- Cleopatra Potter
- 6 years ago
- Views:
Transcription
1 Apache Accumulo 1.4 & 1.5 Features Inaugural Accumulo DC Meetup Keith Turner
2 What is Accumulo? A re-implementation of Big Table Distributed Database Does not support SQL Data is arranged by Row Column Time No need to declare columns, types

3 Massively Distributed
4 Key Structure Key Value Row Column Family Column Qualifier Column Visibility Time Stamp Value Primary Partitioning Component Secondary Partitioning Component Uniqueness Control Access Control Versioning Control Value
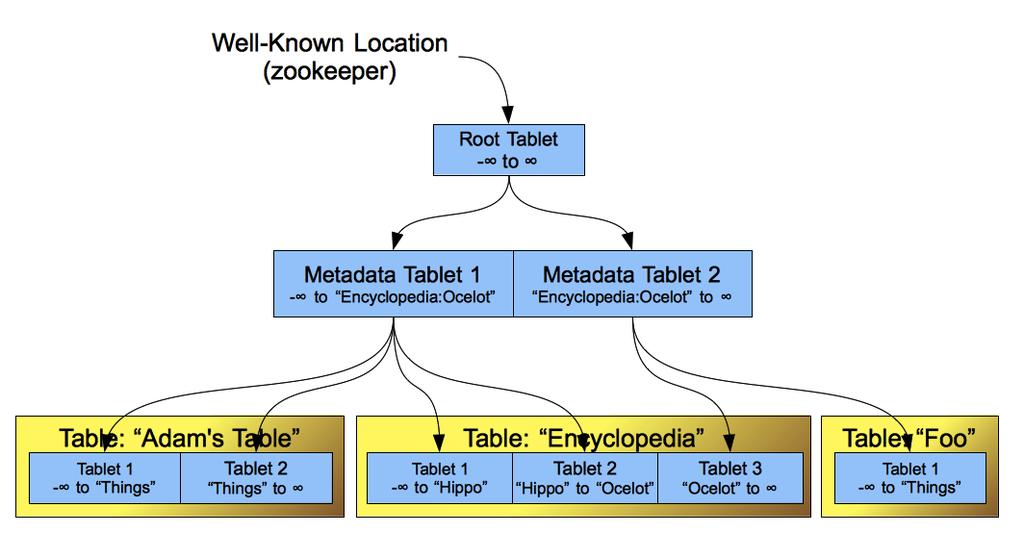
5 Tablet Organization
6 System Processes

7 Tablet Data Flow
8 Rfile Multi-level index
9 1.3 Rfile Index Index is an array of keys One key per data block Complete index loaded into memory when file opened Complete index kept in memory when writing file Slow load times Memory exhaustion
10 1.3 RFile Index Data Block Data Block Data Block
11 Non multi-level 9G file Locality group : <DEFAULT> Start block : 0 Num blocks : 182,691 Index level 0 size : 8,038,404 bytes First key : ae5d6 0e94:74e1 [] false Last key : 7ffffff7daec0b4e 43ee:1c1e [] false Num entries : 172,014,468 Column families : <UNKNOWN> Meta block : BCFile.index Raw size : 2,148,491 bytes Compressed size : 1,485,697 bytes Compression type : lzo Meta block : RFile.index Raw size : 8,038,470 bytes Compressed size : 5,664,704 bytes Compression type : lzo
12 1.4 RFile Index Level 1 Index Level 0 Data Block Data Block Data Block Data Block Data Block
13 File layout Data Data Index L0 Data Data Index L0 Data Data Index L0 Index L1 Index blocks written as data is written complete index not kept in memory during write Index block for each level kept in memory
14 Multi-level 9G file Locality group : <DEFAULT> Start block : 0 Num blocks : 187,070 Index level 1 : 4,573 bytes 1 blocks Index level 0 : 10,431,126 bytes 82 blocks First key : ae5d6 0e94:74e1 [] false Last key : 7ffffff7daec0b4e 43ee:1c1e [] false Num entries : 172,014,468 Column families : <UNKNOWN> Meta block : BCFile.index Raw size : 5 bytes Compressed size : 17 bytes Compression type : lzo Meta block : RFile.index Raw size : 4,652 bytes Compressed size : 3,745 bytes Compression type : lzo
15 Test Setup Files in FS cache for test (cat test.rf > /dev/null) Too much variability when some of file was in FS cache and some was not Easier to force all of file into cache than out
16 Open, seek 9G file Multilevel Index Cache Avg Time N N ms N Y ms Y N 8.48 ms Y Y 3.90 ms
17 Randomly seeking 9G file Multilevel Index Cache Avg Time N N 2.08 ms N Y 2.32 ms Y N 4.33 ms Y Y 2.14 ms
18 Configuration Index block size configurable per table Make index block size large and it will behave like old rfile Enabled index cache by default in 1.4

19 Cache hit rate on monitor page
20 Fault tolerant concurrent table operations
21 Problematic situations Master dies during create table Create and delete table run concurrently Client dies during bulk ingest Table deleted while writing or scanning
22 Create table fault Master dies during Could leave accumulo metadata in bad state Master creates table, but then dies before notifying client If client retries, it gets table exist exception
23 FATE Fault Tolerant Executor If process dies, previously submitted operations continue to execute on restart. Serializes operation in zookeeper before execution Master uses FATE to execute table operations
24 Bulk import test Create table with summation aggregator Bulk import files of +1 or -1, graph ensures final sum is 0 Concurrently merge, split, compact, and consistency check table Exit point verifies 0
25 Adampotent Idempotent f(f(x)) = f(x) Adampotent f(f'(x)) = f(x) f'(x) denotes partial execution of f(x)
26 REPO Repeatable Persisted Operation public interface Repo<T> extends Serializable { long isready(long tid, T environment) throws Exception; Repo<T> call(long tid, T environment) throws Exception; void undo(long tid, T environment) throws Exception; } call() returns next op, null if done call() and undo() must be adampotent undo() should clean up partial execution of isready() or call()
27 FATE interface long starttransaction(); void seedtransaction(long tid, Repo op); TStatus waitforcompletion(long tid); Exception getexception(long tid); void delete(long tid);
28 Client calling FATE on master Start Tx Seed Tx Wait Tx Delete Tx
29 FATE transaction states NEW IN PROGRESS FAILED IN PROGRESS SUCCESSFUL FAILED
30 FATE Persistent store public interface TStore { long reserve(); Repo top(long tid); void push(long tid, Repo repo); void pop(long tid); Tstatus getstatus(long tid); void setstatus(long tid, Tstatus status);... }
31 Seeding void seedtransaction(long tid, Repo repo){ if(store.getstatus(tid) == NEW){ if(store.top(tid) == null) store.push(tid, repo); store.setstatus(tid, IN_PROGRESS); } }
32 FATE transaction execution Mark success Reserve tx Execute top op Push op Save Exception Mark failed in progress Pop op Undo top op Mark fail
33 Concurrent table ops Per-table read/write lock in zookeeper Zookeeper recipe with slight modification : store fate tid as lock data Use persistent sequential instead of ephemeral sequential
34 Concurrent delete table Table deleted during read or write 1.3 Most likely, scan hangs forever Rarely, permission exception thrown (seen in test) In 1.4 check if table exists when : Nothing in!metadata See a permission exception
35 Rogue threads Bulk import fate op pushes work to tservers Threads on tserver execute after fate op done Master deletes WID in ZK, waits until counts 0 Tablet server worker thread Synchronized Synchronized Start WID Exist? cnt[wid]++ Do work cnt[wid]-- exit
36 Create Table Ops 1. CreateTable Allocates table id 2. SetupPermissions 3. PopulateZookeeper Reentrantly lock table in isready() Relate table name to table id 4. CreateDir 5. PopulateMetadata 6. FinishCreateTable
37 Random walk concurrent test Perform all table operation on 5 well known tables Run multiple test clients concurrently Ensure accumulo or test client does not crash or hang Too chaotic to verify data correctness Found many bugs
38 Future Work Allow multiple processes to run fate operations Stop polling Hulk Smash Tolerant
39 Other 1.4 Features
40 Tablet Merging Splits exists forever; data is often aged off Admin requested, not automatic Merge by range or size
41 Merging Minor Compaction 1.3: minor compactions always add new files: 1.4: limits the total of new files:
42 Merging Minor Compactions Slows down minor compactions Memory fills up Creates back-pressure on ingest Prevents unable to open enough files to scan
43 Table Cloning Create a new table using the same read-only files Fast Testing At scale, with representative data Compaction with a broken iterator: no more data Offline and Copy create an consistent snapshot in minutes
44 Range Operations Compact Range Compact all tablets that fall within a row range down to a single file Useful for tail-insert indexes Data purge Delete Range Delete all the content within a row range Uses split and will delete whole tablets for efficiency Useful for data purge
45 Logical Time for Bulk Import Bulk files created on different machines will get different actual times (hours) Bulk files always contain the timestamp created by the client A single bulk import request can set a consistent time across all files Implemented using iterators
46 Roadmap
47 1.4.1 Improvements Snappy, LZ4 HDFS Kerberos compatability Bloom filter improvements Map Reduce directly over Accumulo files Server side row select iterator Bulk ingest support for map only jobs BigTop support Wikisearch example improvements
48 Possible 1.5 features
49 Performance Multiple namenode support WAL performance improvements In-memory map locality groups Timestamp visibility filter optimization Prefix encoding Distributed FATE ops
50 API Stats API Automatic deployment of iterators Tuplestream support Coprocessor integration Support other client languages Client session migration
51 Admin/Security Kerberos support/pluggable authentication Administration monitor page Data center replication Rollback/snapshot backup/recovery
52 Reliability Decentralize master operations Tablet server state model
53 Testing Mini-cluster test harness Continuous random walk testing
Accumulo Extensions to Google s Bigtable Design
 Drivers Extensions to Google s Bigtable National Security Agency Computer and Information Sciences Research Group March 29, 2012 Contents Drivers 1 Drivers 2 3 4 Progress Drivers 1 Drivers 2 3 4 Drivers
Drivers Extensions to Google s Bigtable National Security Agency Computer and Information Sciences Research Group March 29, 2012 Contents Drivers 1 Drivers 2 3 4 Progress Drivers 1 Drivers 2 3 4 Drivers
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
HBase. Леонид Налчаджи
 HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
HBase Леонид Налчаджи leonid.nalchadzhi@gmail.com HBase Overview Table layout Architecture Client API Key design 2 Overview 3 Overview NoSQL Column oriented Versioned 4 Overview All rows ordered by row
BigTable. CSE-291 (Cloud Computing) Fall 2016
 Fall 2016") BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
BigTable CSE-291 (Cloud Computing) Fall 2016 Data Model Sparse, distributed persistent, multi-dimensional sorted map Indexed by a row key, column key, and timestamp Values are uninterpreted arrays of bytes
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
NPTEL Course Jan K. Gopinath Indian Institute of Science
 Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Storage Systems NPTEL Course Jan 2012 (Lecture 39) K. Gopinath Indian Institute of Science Google File System Non-Posix scalable distr file system for large distr dataintensive applications performance,
Bigtable. A Distributed Storage System for Structured Data. Presenter: Yunming Zhang Conglong Li. Saturday, September 21, 13
 Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
Bigtable A Distributed Storage System for Structured Data Presenter: Yunming Zhang Conglong Li References SOCC 2010 Key Note Slides Jeff Dean Google Introduction to Distributed Computing, Winter 2008 University
ZooKeeper & Curator. CS 475, Spring 2018 Concurrent & Distributed Systems
 ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
ZooKeeper & Curator CS 475, Spring 2018 Concurrent & Distributed Systems Review: Agreement In distributed systems, we have multiple nodes that need to all agree that some object has some state Examples:
Apache HBase Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel
 Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
Apache HBase 0.98 Andrew Purtell Committer, Apache HBase, Apache Software Foundation Big Data US Research And Development, Intel Who am I? Committer on the Apache HBase project Member of the Big Data Research
BigTable. Chubby. BigTable. Chubby. Why Chubby? How to do consensus as a service
 BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
BigTable BigTable Doug Woos and Tom Anderson In the early 2000s, Google had way more than anybody else did Traditional bases couldn t scale Want something better than a filesystem () BigTable optimized
Distributed PostgreSQL with YugaByte DB
 Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Distributed PostgreSQL with YugaByte DB Karthik Ranganathan PostgresConf Silicon Valley Oct 16, 2018 1 CHECKOUT THIS REPO: github.com/yugabyte/yb-sql-workshop 2 About Us Founders Kannan Muthukkaruppan,
Bigtable. Presenter: Yijun Hou, Yixiao Peng
 Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Bigtable Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber Google, Inc. OSDI 06 Presenter: Yijun Hou, Yixiao Peng
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
TRANSACTIONS AND ABSTRACTIONS
 TRANSACTIONS AND ABSTRACTIONS OVER HBASE Andreas Neumann @anew68! Continuuity AGENDA Transactions over HBase: Why? What? Implementation: How? The approach Transaction Manager Abstractions Future WHO WE
TRANSACTIONS AND ABSTRACTIONS OVER HBASE Andreas Neumann @anew68! Continuuity AGENDA Transactions over HBase: Why? What? Implementation: How? The approach Transaction Manager Abstractions Future WHO WE
Release Notes for Patches for the MapR Release
 Release Notes for Patches for the MapR 5.0.0 Release Release Notes for the December 2016 Patch Released 12/09/2016 These release notes describe the fixes that are included in this patch. Packages Server
Release Notes for Patches for the MapR 5.0.0 Release Release Notes for the December 2016 Patch Released 12/09/2016 These release notes describe the fixes that are included in this patch. Packages Server
HBase Solutions at Facebook
 HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
HBase Solutions at Facebook Nicolas Spiegelberg Software Engineer, Facebook QCon Hangzhou, October 28 th, 2012 Outline HBase Overview Single Tenant: Messages Selection Criteria Multi-tenant Solutions
Distributed Systems. Fall 2017 Exam 3 Review. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
Distributed Systems Fall 2017 Exam 3 Review Paul Krzyzanowski Rutgers University Fall 2017 December 11, 2017 CS 417 2017 Paul Krzyzanowski 1 Question 1 The core task of the user s map function within a
CSE 444: Database Internals. Lectures 26 NoSQL: Extensible Record Stores
 CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
CSE 444: Database Internals Lectures 26 NoSQL: Extensible Record Stores CSE 444 - Spring 2014 1 References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No. 4)
References. What is Bigtable? Bigtable Data Model. Outline. Key Features. CSE 444: Database Internals
 References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
References CSE 444: Database Internals Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol 39, No 4) Lectures 26 NoSQL: Extensible Record Stores Bigtable: A Distributed
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores
 YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
YCSB++ Benchmarking Tool Performance Debugging Advanced Features of Scalable Table Stores Swapnil Patil Milo Polte, Wittawat Tantisiriroj, Kai Ren, Lin Xiao, Julio Lopez, Garth Gibson, Adam Fuchs *, Billie
! Design constraints. " Component failures are the norm. " Files are huge by traditional standards. ! POSIX-like
 Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
Cloud background Google File System! Warehouse scale systems " 10K-100K nodes " 50MW (1 MW = 1,000 houses) " Power efficient! Located near cheap power! Passive cooling! Power Usage Effectiveness = Total
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Operating Systems. Operating Systems Professor Sina Meraji U of T
 Operating Systems Operating Systems Professor Sina Meraji U of T How are file systems implemented? File system implementation Files and directories live on secondary storage Anything outside of primary
Operating Systems Operating Systems Professor Sina Meraji U of T How are file systems implemented? File system implementation Files and directories live on secondary storage Anything outside of primary
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores
 YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
YCSB++ benchmarking tool Performance debugging advanced features of scalable table stores Swapnil Patil M. Polte, W. Tantisiriroj, K. Ren, L.Xiao, J. Lopez, G.Gibson, A. Fuchs *, B. Rinaldi * Carnegie
The Google File System
 October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
October 13, 2010 Based on: S. Ghemawat, H. Gobioff, and S.-T. Leung: The Google file system, in Proceedings ACM SOSP 2003, Lake George, NY, USA, October 2003. 1 Assumptions Interface Architecture Single
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
CLOUD-SCALE FILE SYSTEMS
 Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
Data Management in the Cloud CLOUD-SCALE FILE SYSTEMS 92 Google File System (GFS) Designing a file system for the Cloud design assumptions design choices Architecture GFS Master GFS Chunkservers GFS Clients
HARDFS: Hardening HDFS with Selective and Lightweight Versioning
 HARDFS: Hardening HDFS with Selective and Lightweight Versioning Thanh Do, Tyler Harter, Yingchao Liu, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau Haryadi S. Gunawi 1 Cloud Reliability q Cloud
HARDFS: Hardening HDFS with Selective and Lightweight Versioning Thanh Do, Tyler Harter, Yingchao Liu, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau Haryadi S. Gunawi 1 Cloud Reliability q Cloud
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612
 Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Bigtable: A Distributed Storage System for Structured Data by Google SUNNIE CHUNG CIS 612 Google Bigtable 2 A distributed storage system for managing structured data that is designed to scale to a very
Data Access 3. Managing Apache Hive. Date of Publish:
 3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
3 Managing Apache Hive Date of Publish: 2018-07-12 http://docs.hortonworks.com Contents ACID operations... 3 Configure partitions for transactions...3 View transactions...3 View transaction locks... 4
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
GFS Overview. Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures
 GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
GFS Overview Design goals/priorities Design for big-data workloads Huge files, mostly appends, concurrency, huge bandwidth Design for failures Interface: non-posix New op: record appends (atomicity matters,
HBASE INTERVIEW QUESTIONS
 HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
HBASE INTERVIEW QUESTIONS http://www.tutorialspoint.com/hbase/hbase_interview_questions.htm Copyright tutorialspoint.com Dear readers, these HBase Interview Questions have been designed specially to get
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
Snapshots and Repeatable reads for HBase Tables
 Snapshots and Repeatable reads for HBase Tables Note: This document is work in progress. Contributors (alphabetical): Vandana Ayyalasomayajula, Francis Liu, Andreas Neumann, Thomas Weise Objective The
Snapshots and Repeatable reads for HBase Tables Note: This document is work in progress. Contributors (alphabetical): Vandana Ayyalasomayajula, Francis Liu, Andreas Neumann, Thomas Weise Objective The
Google File System. Arun Sundaram Operating Systems
 Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
Arun Sundaram Operating Systems 1 Assumptions GFS built with commodity hardware GFS stores a modest number of large files A few million files, each typically 100MB or larger (Multi-GB files are common)
BookKeeper overview. Table of contents
 by Table of contents 1...2 1.1 BookKeeper introduction...2 1.2 In slightly more detail...2 1.3 Bookkeeper elements and concepts... 3 1.4 Bookkeeper initial design... 3 1.5 Bookkeeper metadata management...
by Table of contents 1...2 1.1 BookKeeper introduction...2 1.2 In slightly more detail...2 1.3 Bookkeeper elements and concepts... 3 1.4 Bookkeeper initial design... 3 1.5 Bookkeeper metadata management...
Tuning Enterprise Information Catalog Performance
 Tuning Enterprise Information Catalog Performance Copyright Informatica LLC 2015, 2018. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the United States
Tuning Enterprise Information Catalog Performance Copyright Informatica LLC 2015, 2018. Informatica and the Informatica logo are trademarks or registered trademarks of Informatica LLC in the United States
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop
 HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
CSE 124: Networked Services Lecture-16
 Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
Fall 2010 CSE 124: Networked Services Lecture-16 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa10/cse124 11/23/2010 CSE 124 Networked Services Fall 2010 1 Updates PlanetLab experiments
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis
 Slides adapted by Tyler Davis") BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
BigTable: A Distributed Storage System for Structured Data (2006) Slides adapted by Tyler Davis Motivation Lots of (semi-)structured data at Google URLs: Contents, crawl metadata, links, anchors, pagerank,
18-hdfs-gfs.txt Thu Oct 27 10:05: Notes on Parallel File Systems: HDFS & GFS , Fall 2011 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Oct 27 10:05:07 2011 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2011 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Apache Flink. Alessandro Margara
 Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
Apache Flink Alessandro Margara alessandro.margara@polimi.it http://home.deib.polimi.it/margara Recap: scenario Big Data Volume and velocity Process large volumes of data possibly produced at high rate
CS435 Introduction to Big Data FALL 2018 Colorado State University. 11/7/2018 Week 12-B Sangmi Lee Pallickara. FAQs
 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.0.0 CS435 Introduction to Big Data 11/7/2018 CS435 Introduction to Big Data - FALL 2018 W12.B.1 FAQs Deadline of the Programming Assignment 3
Applications of Paxos Algorithm
 Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Applications of Paxos Algorithm Gurkan Solmaz COP 6938 - Cloud Computing - Fall 2012 Department of Electrical Engineering and Computer Science University of Central Florida - Orlando, FL Oct 15, 2012 1
Facebook. The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011
 Kannan Muthukkaruppan Software Engineer, Facebook. March 11, 2011") HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
HBase @ Facebook The Technology Behind Messages (and more ) Kannan Muthukkaruppan Software Engineer, Facebook March 11, 2011 Talk Outline the new Facebook Messages, and how we got started with HBase quick
Google File System. Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google fall DIP Heerak lim, Donghun Koo
 Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google 2017 fall DIP Heerak lim, Donghun Koo 1 Agenda Introduction Design overview Systems interactions Master operation Fault tolerance
Programming model and implementation for processing and. Programs can be automatically parallelized and executed on a large cluster of machines
 A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
A programming model in Cloud: MapReduce Programming model and implementation for processing and generating large data sets Users specify a map function to generate a set of intermediate key/value pairs
10 Million Smart Meter Data with Apache HBase
 10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
10 Million Smart Meter Data with Apache HBase 5/31/2017 OSS Solution Center Hitachi, Ltd. Masahiro Ito OSS Summit Japan 2017 Who am I? Masahiro Ito ( 伊藤雅博 ) Software Engineer at Hitachi, Ltd. Focus on
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Trinity File System (TFS) Specification V0.8
 Specification V0.8") Trinity File System (TFS) Specification V0.8 Jiaran Zhang (v-jiarzh@microsoft.com), Bin Shao (binshao@microsoft.com) 1. Introduction Trinity File System (TFS) is a distributed file system designed to run
Trinity File System (TFS) Specification V0.8 Jiaran Zhang (v-jiarzh@microsoft.com), Bin Shao (binshao@microsoft.com) 1. Introduction Trinity File System (TFS) is a distributed file system designed to run
HDFS Architecture. Gregory Kesden, CSE-291 (Storage Systems) Fall 2017
 Fall 2017") HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
HDFS Architecture Gregory Kesden, CSE-291 (Storage Systems) Fall 2017 Based Upon: http://hadoop.apache.org/docs/r3.0.0-alpha1/hadoopproject-dist/hadoop-hdfs/hdfsdesign.html Assumptions At scale, hardware
18-hdfs-gfs.txt Thu Nov 01 09:53: Notes on Parallel File Systems: HDFS & GFS , Fall 2012 Carnegie Mellon University Randal E.
 18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
18-hdfs-gfs.txt Thu Nov 01 09:53:32 2012 1 Notes on Parallel File Systems: HDFS & GFS 15-440, Fall 2012 Carnegie Mellon University Randal E. Bryant References: Ghemawat, Gobioff, Leung, "The Google File
Google File System 2
 Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
Google File System 2 goals monitoring, fault tolerance, auto-recovery (thousands of low-cost machines) focus on multi-gb files handle appends efficiently (no random writes & sequential reads) co-design
BigTable: A Distributed Storage System for Structured Data
 BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
BigTable: A Distributed Storage System for Structured Data Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) BigTable 1393/7/26
ORC Files. Owen O June Page 1. Hortonworks Inc. 2012
 ORC Files Owen O Malley owen@hortonworks.com @owen_omalley owen@hortonworks.com June 2013 Page 1 Who Am I? First committer added to Hadoop in 2006 First VP of Hadoop at Apache Was architect of MapReduce
ORC Files Owen O Malley owen@hortonworks.com @owen_omalley owen@hortonworks.com June 2013 Page 1 Who Am I? First committer added to Hadoop in 2006 First VP of Hadoop at Apache Was architect of MapReduce
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
9/26/2017 Sangmi Lee Pallickara Week 6- A. CS535 Big Data Fall 2017 Colorado State University
 CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
CS535 Big Data - Fall 2017 Week 6-A-1 CS535 BIG DATA FAQs PA1: Use only one word query Deadends {{Dead end}} Hub value will be?? PART 1. BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 4. GOOGLE FILE SYSTEM
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
What is a file system
 COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
COSC 6397 Big Data Analytics Distributed File Systems Edgar Gabriel Spring 2017 What is a file system A clearly defined method that the OS uses to store, catalog and retrieve files Manage the bits that
Typical size of data you deal with on a daily basis
 Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Typical size of data you deal with on a daily basis Processes More than 161 Petabytes of raw data a day https://aci.info/2014/07/12/the-dataexplosion-in-2014-minute-by-minuteinfographic/ On average, 1MB-2MB
Ghislain Fourny. Big Data 5. Wide column stores
 Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
Ghislain Fourny Big Data 5. Wide column stores Data Technology Stack User interfaces Querying Data stores Indexing Processing Validation Data models Syntax Encoding Storage 2 Where we are User interfaces
CSE-E5430 Scalable Cloud Computing Lecture 9
 CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
CSE-E5430 Scalable Cloud Computing Lecture 9 Keijo Heljanko Department of Computer Science School of Science Aalto University keijo.heljanko@aalto.fi 15.11-2015 1/24 BigTable Described in the paper: Fay
W b b 2.0. = = Data Ex E pl p o l s o io i n
 Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Hypertable Doug Judd Zvents, Inc. Background Web 2.0 = Data Explosion Web 2.0 Mt. Web 2.0 Traditional Tools Don t Scale Well Designed for a single machine Typical scaling solutions ad-hoc manual/static
Cloudera Kudu Introduction
 Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
TRANSACTIONS OVER HBASE
 TRANSACTIONS OVER HBASE Alex Baranau @abaranau Gary Helmling @gario Continuuity WHO WE ARE We ve built Continuuity Reactor: the world s first scale-out application server for Hadoop Fast, easy development,
TRANSACTIONS OVER HBASE Alex Baranau @abaranau Gary Helmling @gario Continuuity WHO WE ARE We ve built Continuuity Reactor: the world s first scale-out application server for Hadoop Fast, easy development,
Trafodion Enterprise-Class Transactional SQL-on-HBase
 Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Trafodion Enterprise-Class Transactional SQL-on-HBase Trafodion Introduction (Welsh for transactions) Joint HP Labs & HP-IT project for transactional SQL database capabilities on Hadoop Leveraging 20+
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Distributed Systems. Lec 10: Distributed File Systems GFS. Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
 Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Distributed Systems Lec 10: Distributed File Systems GFS Slide acks: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung 1 Distributed File Systems NFS AFS GFS Some themes in these classes: Workload-oriented
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
TokuDB vs RocksDB. What to choose between two write-optimized DB engines supported by Percona. George O. Lorch III Vlad Lesin
 TokuDB vs RocksDB What to choose between two write-optimized DB engines supported by Percona George O. Lorch III Vlad Lesin What to compare? Amplification Write amplification Read amplification Space amplification
TokuDB vs RocksDB What to choose between two write-optimized DB engines supported by Percona George O. Lorch III Vlad Lesin What to compare? Amplification Write amplification Read amplification Space amplification
CS5412: OTHER DATA CENTER SERVICES
 1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
1 CS5412: OTHER DATA CENTER SERVICES Lecture V Ken Birman Tier two and Inner Tiers 2 If tier one faces the user and constructs responses, what lives in tier two? Caching services are very common (many
Chapter 11: File System Implementation. Objectives
 Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Chapter 11: File System Implementation Objectives To describe the details of implementing local file systems and directory structures To describe the implementation of remote file systems To discuss block
Google File System and BigTable. and tiny bits of HDFS (Hadoop File System) and Chubby. Not in textbook; additional information
 and Chubby. Not in textbook; additional information") Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
Subject 10 Fall 2015 Google File System and BigTable and tiny bits of HDFS (Hadoop File System) and Chubby Not in textbook; additional information Disclaimer: These abbreviated notes DO NOT substitute
CSE 124: Networked Services Fall 2009 Lecture-19
 CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
CSE 124: Networked Services Fall 2009 Lecture-19 Instructor: B. S. Manoj, Ph.D http://cseweb.ucsd.edu/classes/fa09/cse124 Some of these slides are adapted from various sources/individuals including but
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
The Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung Google SOSP 03, October 19 22, 2003, New York, USA Hyeon-Gyu Lee, and Yeong-Jae Woo Memory & Storage Architecture Lab. School
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [HADOOP/HDFS] Trying to have your cake and eat it too Each phase pines for tasks with locality and their numbers on a tether Alas within a phase, you get one,
CS /29/18. Paul Krzyzanowski 1. Question 1 (Bigtable) Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams") Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
Question 1 (Bigtable) What is an SSTable in Bigtable? Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams It is the internal file format used to store Bigtable data. It maps keys
ZooKeeper. Wait-free coordination for Internet-scale systems
 ZooKeeper Wait-free coordination for Internet-scale systems Patrick Hunt and Mahadev (Yahoo! Grid) Flavio Junqueira and Benjamin Reed (Yahoo! Research) Internet-scale Challenges Lots of servers, users,
ZooKeeper Wait-free coordination for Internet-scale systems Patrick Hunt and Mahadev (Yahoo! Grid) Flavio Junqueira and Benjamin Reed (Yahoo! Research) Internet-scale Challenges Lots of servers, users,
Fluentd + MongoDB + Spark = Awesome Sauce
 Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
Fluentd + MongoDB + Spark = Awesome Sauce Nishant Sahay, Sr. Architect, Wipro Limited Bhavani Ananth, Tech Manager, Wipro Limited Your company logo here Wipro Open Source Practice: Vision & Mission Vision
IT Best Practices Audit TCS offers a wide range of IT Best Practices Audit content covering 15 subjects and over 2200 topics, including:
 IT Best Practices Audit TCS offers a wide range of IT Best Practices Audit content covering 15 subjects and over 2200 topics, including: 1. IT Cost Containment 84 topics 2. Cloud Computing Readiness 225
IT Best Practices Audit TCS offers a wide range of IT Best Practices Audit content covering 15 subjects and over 2200 topics, including: 1. IT Cost Containment 84 topics 2. Cloud Computing Readiness 225
Distributed Systems Pre-exam 3 review Selected questions from past exams. David Domingo Paul Krzyzanowski Rutgers University Fall 2018
 Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
Distributed Systems 2018 Pre-exam 3 review Selected questions from past exams David Domingo Paul Krzyzanowski Rutgers University Fall 2018 November 28, 2018 1 Question 1 (Bigtable) What is an SSTable in
CS 318 Principles of Operating Systems
 CS 318 Principles of Operating Systems Fall 2017 Lecture 16: File Systems Examples Ryan Huang File Systems Examples BSD Fast File System (FFS) - What were the problems with the original Unix FS? - How
CS 318 Principles of Operating Systems Fall 2017 Lecture 16: File Systems Examples Ryan Huang File Systems Examples BSD Fast File System (FFS) - What were the problems with the original Unix FS? - How
The Google File System (GFS)
") 1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
1 The Google File System (GFS) CS60002: Distributed Systems Antonio Bruto da Costa Ph.D. Student, Formal Methods Lab, Dept. of Computer Sc. & Engg., Indian Institute of Technology Kharagpur 2 Design constraints
7680: Distributed Systems
 Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
Cristina Nita-Rotaru 7680: Distributed Systems GFS. HDFS Required Reading } Google File System. S, Ghemawat, H. Gobioff and S.-T. Leung. SOSP 2003. } http://hadoop.apache.org } A Novel Approach to Improving
COSC 6339 Big Data Analytics. NoSQL (II) HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables
 HBase. Edgar Gabriel Fall HBase. Column-Oriented data store Distributed designed to serve large tables") COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
COSC 6339 Big Data Analytics NoSQL (II) HBase Edgar Gabriel Fall 2018 HBase Column-Oriented data store Distributed designed to serve large tables Billions of rows and millions of columns Runs on a cluster
ADVANCED HBASE. Architecture and Schema Design GeeCON, May Lars George Director EMEA Services
 ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
ADVANCED HBASE Architecture and Schema Design GeeCON, May 2013 Lars George Director EMEA Services About Me Director EMEA Services @ Cloudera Consulting on Hadoop projects (everywhere) Apache Committer
Distributed Systems. 29. Distributed Caching Paul Krzyzanowski. Rutgers University. Fall 2014
 Distributed Systems 29. Distributed Caching Paul Krzyzanowski Rutgers University Fall 2014 December 5, 2014 2013 Paul Krzyzanowski 1 Caching Purpose of a cache Temporary storage to increase data access
Distributed Systems 29. Distributed Caching Paul Krzyzanowski Rutgers University Fall 2014 December 5, 2014 2013 Paul Krzyzanowski 1 Caching Purpose of a cache Temporary storage to increase data access
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia,
 Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
Konstantin Shvachko, Hairong Kuang, Sanjay Radia, Robert Chansler Yahoo! Sunnyvale, California USA {Shv, Hairong, SRadia, Chansler}@Yahoo-Inc.com Presenter: Alex Hu } Introduction } Architecture } File
File Systems: Consistency Issues
 File Systems: Consistency Issues File systems maintain many data structures Free list/bit vector Directories File headers and inode structures res Data blocks File Systems: Consistency Issues All data
File Systems: Consistency Issues File systems maintain many data structures Free list/bit vector Directories File headers and inode structures res Data blocks File Systems: Consistency Issues All data
Before proceeding with this tutorial, you must have a good understanding of Core Java and any of the Linux flavors.
 About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache
About the Tutorial Storm was originally created by Nathan Marz and team at BackType. BackType is a social analytics company. Later, Storm was acquired and open-sourced by Twitter. In a short time, Apache