biokepler: A Comprehensive Bioinforma2cs Scien2fic Workflow Module for Distributed Analysis of Large- Scale Biological Data
|
|
|
- Irene Pearson
- 5 years ago
- Views:
Transcription
1 biokepler: A Comprehensive Bioinforma2cs Scien2fic Workflow Module for Distributed Analysis of Large- Scale Biological Data Ilkay Al/ntas 1, Jianwu Wang 2, Daniel Crawl 1, Shweta Purawat 1 1 San Diego Supercomputer Center, UC San Diego 2 UMBC WorDS.sdsc.edu


2 A Toolbox with Many Tools Data Search, database access, IO opera2ons, streaming data in real- 2me Compute Data- parallel paoerns, external execu2on, Network opera2ons Provenance and fault tolerance Need expertise to identify which tool to use when and how! Require computation models to schedule and optimize execution!
3 Workflows are Used in These Diverse Scenarios in Biological Sciences Often for data reduction In real-time or offline Data Analysis Data Publica2on Archival From analysis to searchable results Standardization Auto generation of methods and materials Data Acquisi2on Genera2on Sequencers Sensor networks Medical imaging Many forms Data-intensive HPC Local Exploratory Workflows foster collaborations! Flexibility and synergy Optimization of resources Increasing reuse Standards compliance
4 CAMERA Example: Using Scientific Workflows and Related Provenance for Collaborative Metagenomics Research Community Cyberinfrastructure for Advanced Microbial Ecology Research and Analysis (CAMERA)







5 CAMERA is a Collaborative Environment Data Discovery GIS and Advanced query options Data Cart Multiple Available Mixed collections of CAMERA Data (e.g. projects, samples) User Workspace Single workspace with access to all data and results (private and shared) Data Analysis Workflow based analysis Group Workspace Share specified User Workspace data with collaborators
6 Workflows are a Central Part of CAMERA CAMERA-supported 28 existing workflows Workflows under development Fragment Recruitment Viewer Next Generation Sequencing VIROME Pipeline Standalone bioinformatics tools National Center for Genome Research Joint Genome Institute User built Currently running in a sandbox Will be ported to a virtual cloud environment QC filter BLAST Duplicate filtering Assembly More than 1500 workflow submissions monthly! Taxonomy Binning Metagenomic Annotation and Clustering Comparison, Statistical analysis, and more workflows Inputs: from local or CAMERA file systems; user-supplied parameters Outputs: sharable with a group of users and links to the semantic database All can be reached through the CAMERA portal at:hop://portal.camera.calit2.net

7 CAMERA Portal - Workflows

8 CAMERA Workflows RAMMCAP

9 CAMERA Workflows

10 CAMERA Workflows

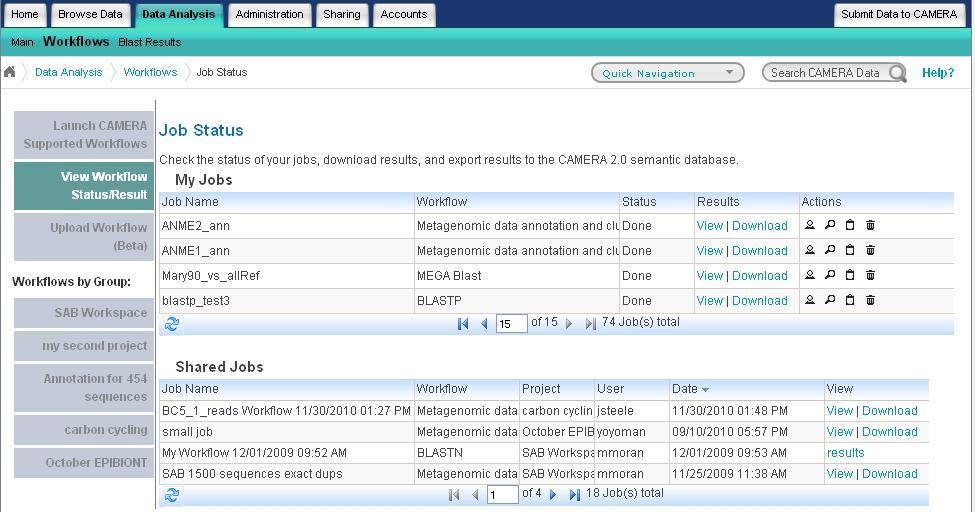
11 CAMERA Job Status

12 CAMERA Workflow Results
13 Pushing the boundaries of existing infrastructure and workflow system capabilities
14 New Requirements from the User Community Increase reuse best development practices by the scientific community other bio packages Increase programmability by end users users with various skill levels to formulate actual domain specific workflows Increase resource utilization optimize execution across available computing resources in an efficient, transparent and intuitive manner Make analysis a part of the end-to-end scientific model from data generation to publication
15 RAMMCAP Rapid Clustering and Functional Annotation for Metagenomic Sequences Annota2on features: trna predic2on (trnascan) rrna predic2on (meta_rna, BLAST) ORF call (ORF_finder, Metagene) RPS- BLAST against COG etc HMMER against Pfam / Tigrfam } Clustering of reads } Mul2- step clustering of ORFs } GO assignment } EC number assignment
16 A number of bioinforma2cs tools are used in RAMMCAP Tool BLAST MegaBLAST Diversity QC CD- HIT- 454 RAMMCAP FRV Assembly KEGG RDP binning BLAST binning trna Meta- RNA BLAST- RNA ORF_finder Metagene FragGeneScan Pfam TIGRfam COG KOG PRK CD- HIT- EST CD- HIT H- CD- HIT Descrip/on Scalable parallel database search with blastn, blastp, tblastn, blastx, tblastx Fast database search with MegaBLAST Diversity analysis for viral metagenome Quality control for 454 raw reads Iden2fy ar2ficial duplicates from 454 reads Metagenome annota2on - rrna, trna, ORF predic2on - reads and ORF clustering - reads and ORF informa2on - family and func2on annota2on (Pfam, TIGRfam, COG) - Gene Ontology and Enzyme Classifica2on annota2on - Combined annota2on summary Fragment Recruitment Viewer Consensus- based meta- assembler for 454 reads Pathway annota2on by search KEGG database with blastp Taxonomy binning of rrna sequences using RDP classifier Taxonomy binning by querying ref. rrna DB using blastn Iden2fica2on of trnas from fragments using trna- scan Iden2fica2on of rrnas from fragments using HMM Iden2fica2on of rrnas by querying ref. rrna DB using blastn ORF call by six reading frame transla2on ORF call by Metagene ORF call with FragGeneScan from 454 reads Protein family annota2on against Pfam using HMMER Protein family annota2on against TIGRfam using HMMER Protein family annota2on against NCBI COG using rps- blast Protein family annota2on against NCBI KOG using rps- blast Protein family annota2on against NCBI PRK using rps- blast Clustering of reads Clustering of ORFs Mul2ple level clustering of ORFs into ORF family




17 Original implementa2on of the annota2on workflow in Kepler Data flow is divided. A green box is called a actor, which performs a task. This special actor represents an annota2on component, such as BLAST search. Workflow parameters, which can be specified by users in portal, are passed to workflow components.


18 Each actor was a wrapper to a web service! Customized web services!
19 RAMMCAP metagene QC cd- hit hmmer blast trna Data size CPU 2me Memory Parallel KB MB GB TB Second QC cd- hit Hour metagene Day trna hmmer Month blast Year GB QC trna metagene hmmer blast 10GB cd- hit 100GB No need No Mul2 threading MPI Map Reduce QC cd- hit hmmer blast hmmer trna metagene blast
20 RAMMCAP Rapid Clustering and Functional Annotation for Metagenomic Sequences Data size KB MB GB TB CPU 2me Memory Parallel Minute QC cd- hit Hour metagene Day trna hmmer Month blast Year GB QC trna metagene hmmer blast 10GB cd- hit 100GB No need No Mul2 threading MPI Map Reduce QC cd- hit hmmer blast hmmer trna metagene blast Data size CPU 2me Memory Parallel KB MB GB NGS TB Minute QC Hour Day metagene cd- hit Month trna hmmer Year GB QC trna metagene hmmer 10GB blast cd- hit 100GB No need No Mul2 threading MPI Map Reduce blast QC cd- hit hmmer blast hmmer trna metagene blast



21 Another cases RNA- seq / genomic / metagenomic Raw reads Reads QC QC BWA Bow9e BLAST mapping mapping HQ reads Assemble Velvet, SOAPdenovo, Abyss Oases Trinity assembly Alignments Con2gs Further analysis Data size CPU 2me Memory Parallel KB MB GB NGS TB assembly Minute QC Hour Day Month mapping GB QC mapping 10GB 100GB No need No Mul2 threading MPI Map Reduce assembly mapping assembly QC mapping
22 biokepler implementa2on: Using bioactors instead of wrapper actors bio bio bio bio bio bio bio bio bio bio bio bio bio bio bio Wrapper Actors Need implementa2on of underlying computa2onal tools bioactors Reusable Mul2ple execu2on modes Build- in parallel execu2on capabili2es


23 Gateways and other user environments Kepler and Provenance Framework biokepler BioLinux Galaxy Clovr Hadoop CLOUD and OTHER COMPUTING RESOURCES e.g., SGE, Amazon, FutureGrid, XSEDE A coordinated ecosystem of biological and technological May packages 22nd, 2014 Scalable for Bioinforma2cs bioinformatics! Boot Camp
24 The biokepler Approach Parallel Computation Framework Use Distributed Data-Parallel (DDP) frameworks, e.g., MapReduce, and other parallelization methods to execute subworkflows bioactors Configurable and reusable higher-order components for bioinformatics and computational biology Transparent support for different execution engines and computational environments Deployment on diverse environments
25 Reuse, Programmability, Execution Funded by NSF ABI & CI Reuse programs - Altintas (PI) and Li (Co-PI) Development of a comprehensive bioinformatics scientific workflow module for distributed analysis of large-scale biological data Big improvement on usability and programmability by end users! biokepler CloudBioLinux Galaxy Bio-Linux Kepler CORE Distributed Data Parallel Provenance Repor2ng Run Manager Kepler supports Workflows Other third party programming tools, e.g., R, Matlab, KNIME Extensible task and data paralleliza2on Service orienta2on Execu2on on mul2ple engines, e.g., SDF, SGE, Hadoop
26 biokepler s Conceptual Framework Kepler Bioinformatics Tools Mapping Assembly Clustering biokepler Data-Parallel Execution Patterns Map-Reduce Master-Slave All-Pairs bioactors BLAST HMMER CD-HIT Workflow Director Scheduler Executable Workflow Plan Provenance Data Lineage Execution History Reporting Report Designer PDF Generation Run Manager Search Tag Bioinformatician Customize & Integrate Execution Engine Fault-Tolerance Alternatives Error Handling Deploy & Execute Data Ensembl CAMERA Genbank Transfer Amazon EC2 FutureGrid Compute Triton Resource Adhoc Network Sun Grid Engine
27 bioactors Set of steps to execute a bioinformatics tool locally or in an external environment Locally executable Parallelized external execution Customizable by the user based on external packages Tools imported from CloudBioLinux Tools are evaluated on their computational requirements
28 Transparent Execution includes Parallelization Solutions in Distributed Environments Tradi9onal parallel programming interfaces Examples: MPI and OpenMP Hard to implement Original sequen2al tools cannot be reused Parallel job execu9on Examples: SGE and Condor Original sequen2al tools can be reused Create small jobs by splikng data or tasks Hard to achieve data locality for each job Data parallel job execu9on Examples: Hadoop and Stratosphere Original sequen2al tools can be reused Support customized and automa2c data par22on and distribu2on Support data locality for each job through special distributed file system, HDFS
29 Distributed Data-Parallel bioactors Set of steps to execute a bioinformatics tool in DDP environment Customized from the ExecutionChoice actor Includes: Data-parallel patterns, e.g., Map, Reduce, Cross, All-Pairs, etc., to specify data grouping I/O to interface with storage Data format specifying how to split and join
30 DDP bioactor Usage Model User: Workflow Developer 1. Search 2b. Choose Generic 2b. Create Sub-Workflow bioactor Library A1 A2 An DDP Generic DDP Blast 2a. Choose Specific 3. Add to Workflow 4c. Save in Library DDP Director Workflow 4b. Add to Larger Workflow 4a. Execute Results

31 Status of bioactors 500+ bioactors are listed under current biokepler release, ~40 of them are parallelized.
32 Example bioactors Alignment: BLAST, BLAT Profile-Sequence Alignment: PSI-BLAST Hidden Markov Model: HMMER Mapping: Bowtie, BWA, Samtools Multiple Alignment: ClustalW, Muscle Clustering: CD-HIT, Blastclust Gene Prediction: Glimmer, Genescan, Fraggenescan trna prediction: trna-scan, Meta-RNA Phylogeny: FastTree, RAxML

33 Example Workflows
34 Current Release Downloadable as a package at: A biokepler VM executable on Amazon EC2, FutureGrid and SDSC Cloud Builds upon CloudBioLinux including Bio- Linux and Galaxy A bioactor template that can be customized for different execution choices e.g., local vs. Map/Reduce on a specific environment Example usecases

35 Demo and Ques2ons WorDS Director: Ilkay Al2ntas, Ph.D.
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System
 A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
Scientific Workflow Tools. Daniel Crawl and Ilkay Altintas San Diego Supercomputer Center UC San Diego
 Scientific Workflow Tools Daniel Crawl and Ilkay Altintas San Diego Supercomputer Center UC San Diego 1 escience Today Increasing number of Cyberinfrastructure (CI) technologies Data Repositories: Network
Scientific Workflow Tools Daniel Crawl and Ilkay Altintas San Diego Supercomputer Center UC San Diego 1 escience Today Increasing number of Cyberinfrastructure (CI) technologies Data Repositories: Network
RAMMCAP The Rapid Analysis of Multiple Metagenomes with a Clustering and Annotation Pipeline
 RAMMCAP The Rapid Analysis of Multiple Metagenomes with a Clustering and Annotation Pipeline Weizhong Li, liwz@sdsc.edu CAMERA project (http://camera.calit2.net) Contents: 1. Introduction 2. Implementation
RAMMCAP The Rapid Analysis of Multiple Metagenomes with a Clustering and Annotation Pipeline Weizhong Li, liwz@sdsc.edu CAMERA project (http://camera.calit2.net) Contents: 1. Introduction 2. Implementation
Introduc)on to annota)on with Artemis. Download presenta.on and data
on to annota)on with Artemis. Download presenta.on and data") Introduc)on to annota)on with Artemis Download presenta.on and data Annota)on Assign an informa)on to genomic sequences???? Genome annota)on 1. Iden.fying genomic elements by: Predic)on (structural annota.on
Introduc)on to annota)on with Artemis Download presenta.on and data Annota)on Assign an informa)on to genomic sequences???? Genome annota)on 1. Iden.fying genomic elements by: Predic)on (structural annota.on
A High-Level Distributed Execution Framework for Scientific Workflows
 A High-Level Distributed Execution Framework for Scientific Workflows Jianwu Wang 1, Ilkay Altintas 1, Chad Berkley 2, Lucas Gilbert 1, Matthew B. Jones 2 1 San Diego Supercomputer Center, UCSD, U.S.A.
A High-Level Distributed Execution Framework for Scientific Workflows Jianwu Wang 1, Ilkay Altintas 1, Chad Berkley 2, Lucas Gilbert 1, Matthew B. Jones 2 1 San Diego Supercomputer Center, UCSD, U.S.A.
San Diego Supercomputer Center, UCSD, U.S.A. The Consortium for Conservation Medicine, Wildlife Trust, U.S.A.
 Accelerating Parameter Sweep Workflows by Utilizing i Ad-hoc Network Computing Resources: an Ecological Example Jianwu Wang 1, Ilkay Altintas 1, Parviez R. Hosseini 2, Derik Barseghian 2, Daniel Crawl
Accelerating Parameter Sweep Workflows by Utilizing i Ad-hoc Network Computing Resources: an Ecological Example Jianwu Wang 1, Ilkay Altintas 1, Parviez R. Hosseini 2, Derik Barseghian 2, Daniel Crawl
Accelerating the Scientific Exploration Process with Kepler Scientific Workflow System
 Accelerating the Scientific Exploration Process with Kepler Scientific Workflow System Jianwu Wang, Ilkay Altintas Scientific Workflow Automation Technologies Lab SDSC, UCSD project.org UCGrid Summit,
Accelerating the Scientific Exploration Process with Kepler Scientific Workflow System Jianwu Wang, Ilkay Altintas Scientific Workflow Automation Technologies Lab SDSC, UCSD project.org UCGrid Summit,
Big Data Applications using Workflows for Data Parallel Computing
 Big Data Applications using Workflows for Data Parallel Computing Jianwu Wang, Daniel Crawl, Ilkay Altintas, Weizhong Li University of California, San Diego Abstract In the Big Data era, workflow systems
Big Data Applications using Workflows for Data Parallel Computing Jianwu Wang, Daniel Crawl, Ilkay Altintas, Weizhong Li University of California, San Diego Abstract In the Big Data era, workflow systems
Sequence Alignment. GBIO0002 Archana Bhardwaj University of Liege
 Sequence Alignment GBIO0002 Archana Bhardwaj University of Liege 1 What is Sequence Alignment? A sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity.
Sequence Alignment GBIO0002 Archana Bhardwaj University of Liege 1 What is Sequence Alignment? A sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity.
Using the Galaxy Local Bioinformatics Cloud at CARC
 Using the Galaxy Local Bioinformatics Cloud at CARC Lijing Bu Sr. Research Scientist Bioinformatics Specialist Center for Evolutionary and Theoretical Immunology (CETI) Department of Biology, University
Using the Galaxy Local Bioinformatics Cloud at CARC Lijing Bu Sr. Research Scientist Bioinformatics Specialist Center for Evolutionary and Theoretical Immunology (CETI) Department of Biology, University
MetaPhyler Usage Manual
 MetaPhyler Usage Manual Bo Liu boliu@umiacs.umd.edu March 13, 2012 Contents 1 What is MetaPhyler 1 2 Installation 1 3 Quick Start 2 3.1 Taxonomic profiling for metagenomic sequences.............. 2 3.2
MetaPhyler Usage Manual Bo Liu boliu@umiacs.umd.edu March 13, 2012 Contents 1 What is MetaPhyler 1 2 Installation 1 3 Quick Start 2 3.1 Taxonomic profiling for metagenomic sequences.............. 2 3.2
Discovery Net : A UK e-science Pilot Project for Grid-based Knowledge Discovery Services. Patrick Wendel Imperial College, London
 Discovery Net : A UK e-science Pilot Project for Grid-based Knowledge Discovery Services Patrick Wendel Imperial College, London Data Mining and Exploration Middleware for Distributed and Grid Computing,
Discovery Net : A UK e-science Pilot Project for Grid-based Knowledge Discovery Services Patrick Wendel Imperial College, London Data Mining and Exploration Middleware for Distributed and Grid Computing,
Integrated Machine Learning in the Kepler Scientific Workflow System
 Procedia Computer Science Volume 80, 2016, Pages 2443 2448 ICCS 2016. The International Conference on Computational Science Integrated Machine Learning in the Kepler Scientific Workflow System Mai H. Nguyen
Procedia Computer Science Volume 80, 2016, Pages 2443 2448 ICCS 2016. The International Conference on Computational Science Integrated Machine Learning in the Kepler Scientific Workflow System Mai H. Nguyen
Big Data, Big Compute, Big Interac3on Machines for Future Biology. Rick Stevens. Argonne Na3onal Laboratory The University of Chicago
 Assembly Annota3on Modeling Design Big Data, Big Compute, Big Interac3on Machines for Future Biology Rick Stevens stevens@anl.gov Argonne Na3onal Laboratory The University of Chicago There are no solved
Assembly Annota3on Modeling Design Big Data, Big Compute, Big Interac3on Machines for Future Biology Rick Stevens stevens@anl.gov Argonne Na3onal Laboratory The University of Chicago There are no solved
Large Scale Sky Computing Applications with Nimbus
 Large Scale Sky Computing Applications with Nimbus Pierre Riteau Université de Rennes 1, IRISA INRIA Rennes Bretagne Atlantique Rennes, France Pierre.Riteau@irisa.fr INTRODUCTION TO SKY COMPUTING IaaS
Large Scale Sky Computing Applications with Nimbus Pierre Riteau Université de Rennes 1, IRISA INRIA Rennes Bretagne Atlantique Rennes, France Pierre.Riteau@irisa.fr INTRODUCTION TO SKY COMPUTING IaaS
Galaxy workshop at the Winter School Igor Makunin
 Galaxy workshop at the Winter School 2016 Igor Makunin i.makunin@uq.edu.au Winter school, UQ, July 6, 2016 Plan Overview of the Genomics Virtual Lab Introduce Galaxy, a web based platform for analysis
Galaxy workshop at the Winter School 2016 Igor Makunin i.makunin@uq.edu.au Winter school, UQ, July 6, 2016 Plan Overview of the Genomics Virtual Lab Introduce Galaxy, a web based platform for analysis
Sky Computing on FutureGrid and Grid 5000 with Nimbus. Pierre Riteau Université de Rennes 1, IRISA INRIA Rennes Bretagne Atlantique Rennes, France
 Sky Computing on FutureGrid and Grid 5000 with Nimbus Pierre Riteau Université de Rennes 1, IRISA INRIA Rennes Bretagne Atlantique Rennes, France Outline Introduction to Sky Computing The Nimbus Project
Sky Computing on FutureGrid and Grid 5000 with Nimbus Pierre Riteau Université de Rennes 1, IRISA INRIA Rennes Bretagne Atlantique Rennes, France Outline Introduction to Sky Computing The Nimbus Project
BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite
 BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite Xinhui Tian, Shaopeng Dai, Zhihui Du, Wanling Gao, Rui Ren, Yaodong Cheng, Zhifei Zhang, Zhen Jia, Peijian Wang and Jianfeng Zhan INSTITUTE
BigDataBench- S: An Open- source Scien6fic Big Data Benchmark Suite Xinhui Tian, Shaopeng Dai, Zhihui Du, Wanling Gao, Rui Ren, Yaodong Cheng, Zhifei Zhang, Zhen Jia, Peijian Wang and Jianfeng Zhan INSTITUTE
NBIC Cloud. Mattias de Hollander David van Enckevort Leon Mei Rob Hooft
 NBIC Galaxy@HPC Cloud Mattias de Hollander David van Enckevort Leon Mei Rob Hooft SURFsara HPC Cloud 19 nodes, 32 cores and 256 GB RAM each Intel 2.13 GHz 32 cores (Xeon-E7 "Westmere-EX") 400 TB storage
NBIC Galaxy@HPC Cloud Mattias de Hollander David van Enckevort Leon Mei Rob Hooft SURFsara HPC Cloud 19 nodes, 32 cores and 256 GB RAM each Intel 2.13 GHz 32 cores (Xeon-E7 "Westmere-EX") 400 TB storage
MOHA: Many-Task Computing Framework on Hadoop
 Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Apache: Big Data North America 2017 @ Miami MOHA: Many-Task Computing Framework on Hadoop Soonwook Hwang Korea Institute of Science and Technology Information May 18, 2017 Table of Contents Introduction
Examining De Novo Transcriptome Assemblies via a Quality Assessment Pipeline
 Examining De Novo Transcriptome Assemblies via a Quality Assessment Pipeline Noushin Ghaffari, Osama A. Arshad, Hyundoo Jeong, John Thiltges, Michael F. Criscitiello, Byung-Jun Yoon, Aniruddha Datta, Charles
Examining De Novo Transcriptome Assemblies via a Quality Assessment Pipeline Noushin Ghaffari, Osama A. Arshad, Hyundoo Jeong, John Thiltges, Michael F. Criscitiello, Byung-Jun Yoon, Aniruddha Datta, Charles
How to Run NCBI BLAST on zcluster at GACRC
 How to Run NCBI BLAST on zcluster at GACRC BLAST: Basic Local Alignment Search Tool Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu 1 OVERVIEW What is BLAST?
How to Run NCBI BLAST on zcluster at GACRC BLAST: Basic Local Alignment Search Tool Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu 1 OVERVIEW What is BLAST?
Install and run external command line softwares. Yanbin Yin
 Install and run external command line softwares Yanbin Yin 1 Create a folder under your home called hw8 Change directory to hw8 Homework #8 Download Escherichia_coli_K_12_substr MG1655_uid57779 faa file
Install and run external command line softwares Yanbin Yin 1 Create a folder under your home called hw8 Change directory to hw8 Homework #8 Download Escherichia_coli_K_12_substr MG1655_uid57779 faa file
Scientific Workflows
 Scientific Workflows Overview More background on workflows Kepler Details Example Scientific Workflows Other Workflow Systems 2 Recap from last time Background: What is a scientific workflow? Goals: automate
Scientific Workflows Overview More background on workflows Kepler Details Example Scientific Workflows Other Workflow Systems 2 Recap from last time Background: What is a scientific workflow? Goals: automate
Grid Computing for Bioinformatics: An Implementation of a User-Friendly Web Portal for ASTI's In Silico Laboratory
 Grid Computing for Bioinformatics: An Implementation of a User-Friendly Web Portal for ASTI's In Silico Laboratory R. Babilonia, M. Rey, E. Aldea, U. Sarte gridapps@asti.dost.gov.ph Outline! Introduction:
Grid Computing for Bioinformatics: An Implementation of a User-Friendly Web Portal for ASTI's In Silico Laboratory R. Babilonia, M. Rey, E. Aldea, U. Sarte gridapps@asti.dost.gov.ph Outline! Introduction:
Categorized software tools: (this page is being updated and links will be restored ASAP. Click on one of the menu links for more information)
") Categorized software tools: (this page is being updated and links will be restored ASAP. Click on one of the menu links for more information) 1 / 5 For array design, fabrication and maintaining a database
Categorized software tools: (this page is being updated and links will be restored ASAP. Click on one of the menu links for more information) 1 / 5 For array design, fabrication and maintaining a database
Two Examples of Datanomic. David Du Digital Technology Center Intelligent Storage Consortium University of Minnesota
 Two Examples of Datanomic David Du Digital Technology Center Intelligent Storage Consortium University of Minnesota Datanomic Computing (Autonomic Storage) System behavior driven by characteristics of
Two Examples of Datanomic David Du Digital Technology Center Intelligent Storage Consortium University of Minnesota Datanomic Computing (Autonomic Storage) System behavior driven by characteristics of
INTRODUCTION TO BIOINFORMATICS
 Molecular Biology-2019 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Molecular Biology-2019 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Advanced Supercomputing Hub for OMICS Knowledge in Agriculture. Step-wise Help to Access Bio-computing Portal. (
 Advanced Supercomputing Hub for OMICS Knowledge in Agriculture Step-wise Help to Access Bio-computing Portal (http://webapp.cabgrid.res.in/biocomp/) Centre for Agricultural Bioinformatics ICAR - Indian
Advanced Supercomputing Hub for OMICS Knowledge in Agriculture Step-wise Help to Access Bio-computing Portal (http://webapp.cabgrid.res.in/biocomp/) Centre for Agricultural Bioinformatics ICAR - Indian
Big Data 2015: Sponsor and Participants Research Event ""
 Big Data 2015: Sponsor and Participants Research Event "" Center for Large-scale Data Systems Research, CLDS! San Diego Supercomputer Center! UC San Diego! Agenda" Welcome and introductions! SDSC: Who
Big Data 2015: Sponsor and Participants Research Event "" Center for Large-scale Data Systems Research, CLDS! San Diego Supercomputer Center! UC San Diego! Agenda" Welcome and introductions! SDSC: Who
Kepler and Grid Systems -- Early Efforts --
 Distributed Computing in Kepler Lead, Scientific Workflow Automation Technologies Laboratory San Diego Supercomputer Center, (Joint work with Matthew Jones) 6th Biennial Ptolemy Miniconference Berkeley,
Distributed Computing in Kepler Lead, Scientific Workflow Automation Technologies Laboratory San Diego Supercomputer Center, (Joint work with Matthew Jones) 6th Biennial Ptolemy Miniconference Berkeley,
2) NCBI BLAST tutorial This is a users guide written by the education department at NCBI.
 NCBI BLAST tutorial This is a users guide written by the education department at NCBI.") Web resources -- Tour. page 1 of 8 This is a guided tour. Any homework is separate. In fact, this exercise is used for multiple classes and is publicly available to everyone. The entire tour will take
Web resources -- Tour. page 1 of 8 This is a guided tour. Any homework is separate. In fact, this exercise is used for multiple classes and is publicly available to everyone. The entire tour will take
HPC learning using Cloud infrastructure
 HPC learning using Cloud infrastructure Florin MANAILA IT Architect florin.manaila@ro.ibm.com Cluj-Napoca 16 March, 2010 Agenda 1. Leveraging Cloud model 2. HPC on Cloud 3. Recent projects - FutureGRID
HPC learning using Cloud infrastructure Florin MANAILA IT Architect florin.manaila@ro.ibm.com Cluj-Napoca 16 March, 2010 Agenda 1. Leveraging Cloud model 2. HPC on Cloud 3. Recent projects - FutureGRID
INTRODUCTION TO BIOINFORMATICS
 Molecular Biology-2017 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Molecular Biology-2017 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Database Searching Using BLAST
 Mahidol University Objectives SCMI512 Molecular Sequence Analysis Database Searching Using BLAST Lecture 2B After class, students should be able to: explain the FASTA algorithm for database searching explain
Mahidol University Objectives SCMI512 Molecular Sequence Analysis Database Searching Using BLAST Lecture 2B After class, students should be able to: explain the FASTA algorithm for database searching explain
Genome Browser. Background and Strategy
 Genome Browser Background and Strategy Contents What is a genome browser? Purpose of a genome browser Examples Structure Extra Features Contents What is a genome browser? Purpose of a genome browser Examples
Genome Browser Background and Strategy Contents What is a genome browser? Purpose of a genome browser Examples Structure Extra Features Contents What is a genome browser? Purpose of a genome browser Examples
globus online The Galaxy Project and Globus Online
 globus online The Galaxy Project and Globus Online Ravi K Madduri Argonne National Lab University of Chicago Outline What is Globus Online? Globus Online and Sequencing Centers What is Galaxy? Integra;ng
globus online The Galaxy Project and Globus Online Ravi K Madduri Argonne National Lab University of Chicago Outline What is Globus Online? Globus Online and Sequencing Centers What is Galaxy? Integra;ng
BLAST MCDB 187. Friday, February 8, 13
 BLAST MCDB 187 BLAST Basic Local Alignment Sequence Tool Uses shortcut to compute alignments of a sequence against a database very quickly Typically takes about a minute to align a sequence against a database
BLAST MCDB 187 BLAST Basic Local Alignment Sequence Tool Uses shortcut to compute alignments of a sequence against a database very quickly Typically takes about a minute to align a sequence against a database
Hands-on tutorial on usage the Kepler Scientific Workflow System
 Hands-on tutorial on usage the Kepler Scientific Workflow System (including INDIGO-DataCloud extension) RIA-653549 Michał Konrad Owsiak (@mkowsiak) Poznan Supercomputing and Networking Center michal.owsiak@man.poznan.pl
Hands-on tutorial on usage the Kepler Scientific Workflow System (including INDIGO-DataCloud extension) RIA-653549 Michał Konrad Owsiak (@mkowsiak) Poznan Supercomputing and Networking Center michal.owsiak@man.poznan.pl
Bioinformatics explained: BLAST. March 8, 2007
 Bioinformatics Explained Bioinformatics explained: BLAST March 8, 2007 CLC bio Gustav Wieds Vej 10 8000 Aarhus C Denmark Telephone: +45 70 22 55 09 Fax: +45 70 22 55 19 www.clcbio.com info@clcbio.com Bioinformatics
Bioinformatics Explained Bioinformatics explained: BLAST March 8, 2007 CLC bio Gustav Wieds Vej 10 8000 Aarhus C Denmark Telephone: +45 70 22 55 09 Fax: +45 70 22 55 19 www.clcbio.com info@clcbio.com Bioinformatics
The National Center for Genome Analysis Support as a Model Virtual Resource for Biologists
 The National Center for Genome Analysis Support as a Model Virtual Resource for Biologists Internet2 Network Infrastructure for the Life Sciences Focused Technical Workshop. Berkeley, CA July 17-18, 2013
The National Center for Genome Analysis Support as a Model Virtual Resource for Biologists Internet2 Network Infrastructure for the Life Sciences Focused Technical Workshop. Berkeley, CA July 17-18, 2013
Introduction to High Performance Computing (HPC) Resources at GACRC
 Resources at GACRC") Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
Introduction to High Performance Computing (HPC) Resources at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? Concept
TBtools, a Toolkit for Biologists integrating various HTS-data
 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 TBtools, a Toolkit for Biologists integrating various HTS-data handling tools with a user-friendly interface Chengjie Chen 1,2,3*, Rui Xia 1,2,3, Hao Chen 4, Yehua
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 TBtools, a Toolkit for Biologists integrating various HTS-data handling tools with a user-friendly interface Chengjie Chen 1,2,3*, Rui Xia 1,2,3, Hao Chen 4, Yehua
Annotating a Genome in PATRIC
 Annotating a Genome in PATRIC The following step-by-step workflow is intended to help you learn how to navigate the new PATRIC workspace environment in order to annotate and browse your genome on the PATRIC
Annotating a Genome in PATRIC The following step-by-step workflow is intended to help you learn how to navigate the new PATRIC workspace environment in order to annotate and browse your genome on the PATRIC
Using Galaxy to provide a NGS Analysis Platform
 11/15/11 Using Galaxy to provide a NGS Analysis Platform Friedrich Miescher Institute - part of the Novartis Research Foundation - affiliated institute of Basel University - member of Swiss Institute of
11/15/11 Using Galaxy to provide a NGS Analysis Platform Friedrich Miescher Institute - part of the Novartis Research Foundation - affiliated institute of Basel University - member of Swiss Institute of
Pegasus Workflow Management System. Gideon Juve. USC Informa3on Sciences Ins3tute
 Pegasus Workflow Management System Gideon Juve USC Informa3on Sciences Ins3tute Scientific Workflows Orchestrate complex, multi-stage scientific computations Often expressed as directed acyclic graphs
Pegasus Workflow Management System Gideon Juve USC Informa3on Sciences Ins3tute Scientific Workflows Orchestrate complex, multi-stage scientific computations Often expressed as directed acyclic graphs
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Lecture 5 Advanced BLAST
 Introduction to Bioinformatics for Medical Research Gideon Greenspan gdg@cs.technion.ac.il Lecture 5 Advanced BLAST BLAST Recap Sequence Alignment Complexity and indexing BLASTN and BLASTP Basic parameters
Introduction to Bioinformatics for Medical Research Gideon Greenspan gdg@cs.technion.ac.il Lecture 5 Advanced BLAST BLAST Recap Sequence Alignment Complexity and indexing BLASTN and BLASTP Basic parameters
FANTOM: Functional and Taxonomic Analysis of Metagenomes
 FANTOM: Functional and Taxonomic Analysis of Metagenomes User Manual 1- FANTOM Introduction: a. What is FANTOM? FANTOM is an exploratory and comparative analysis tool for Metagenomic samples. b. What is
FANTOM: Functional and Taxonomic Analysis of Metagenomes User Manual 1- FANTOM Introduction: a. What is FANTOM? FANTOM is an exploratory and comparative analysis tool for Metagenomic samples. b. What is
High Performance Data Analytics for Numerical Simulations. Bruno Raffin DataMove
 High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
High Performance Data Analytics for Numerical Simulations Bruno Raffin DataMove bruno.raffin@inria.fr April 2016 About this Talk HPC for analyzing the results of large scale parallel numerical simulations
CLC Server. End User USER MANUAL
 CLC Server End User USER MANUAL Manual for CLC Server 10.0.1 Windows, macos and Linux March 8, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej 2 Prismet DK-8000 Aarhus C Denmark
CLC Server End User USER MANUAL Manual for CLC Server 10.0.1 Windows, macos and Linux March 8, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej 2 Prismet DK-8000 Aarhus C Denmark
Geneious 5.6 Quickstart Manual. Biomatters Ltd
 Geneious 5.6 Quickstart Manual Biomatters Ltd October 15, 2012 2 Introduction This quickstart manual will guide you through the features of Geneious 5.6 s interface and help you orient yourself. You should
Geneious 5.6 Quickstart Manual Biomatters Ltd October 15, 2012 2 Introduction This quickstart manual will guide you through the features of Geneious 5.6 s interface and help you orient yourself. You should
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications
 Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications Thilina Gunarathne, Tak-Lon Wu Judy Qiu, Geoffrey Fox School of Informatics, Pervasive Technology Institute Indiana University
Science-as-a-Service
 Science-as-a-Service The iplant Foundation Rion Dooley Edwin Skidmore Dan Stanzione Steve Terry Matthew Vaughn Outline Why, why, why! When duct tape isn t enough Building an API for the web Core services
Science-as-a-Service The iplant Foundation Rion Dooley Edwin Skidmore Dan Stanzione Steve Terry Matthew Vaughn Outline Why, why, why! When duct tape isn t enough Building an API for the web Core services
Galaxy. Daniel Blankenberg The Galaxy Team
 Galaxy Daniel Blankenberg The Galaxy Team http://galaxyproject.org Overview What is Galaxy? What you can do in Galaxy analysis interface, tools and datasources data libraries workflows visualization sharing
Galaxy Daniel Blankenberg The Galaxy Team http://galaxyproject.org Overview What is Galaxy? What you can do in Galaxy analysis interface, tools and datasources data libraries workflows visualization sharing
2013 AWS Worldwide Public Sector Summit Washington, D.C.
 2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
2013 AWS Worldwide Public Sector Summit Washington, D.C. EMR for Fun and for Profit Ben Butler Sr. Manager, Big Data butlerb@amazon.com @bensbutler Overview 1. What is big data? 2. What is AWS Elastic
The Materials Data Facility
 The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
TerraSwarm. A Machine Learning and Op0miza0on Toolkit for the Swarm. Ilge Akkaya, Shuhei Emoto, Edward A. Lee. University of California, Berkeley
 TerraSwarm A Machine Learning and Op0miza0on Toolkit for the Swarm Ilge Akkaya, Shuhei Emoto, Edward A. Lee University of California, Berkeley TerraSwarm Tools Telecon 17 November 2014 Sponsored by the
TerraSwarm A Machine Learning and Op0miza0on Toolkit for the Swarm Ilge Akkaya, Shuhei Emoto, Edward A. Lee University of California, Berkeley TerraSwarm Tools Telecon 17 November 2014 Sponsored by the
Sequence Alignment: Mo1va1on and Algorithms
 Sequence Alignment: Mo1va1on and Algorithms Mo1va1on and Introduc1on Importance of Sequence Alignment For DNA, RNA and amino acid sequences, high sequence similarity usually implies significant func1onal
Sequence Alignment: Mo1va1on and Algorithms Mo1va1on and Introduc1on Importance of Sequence Alignment For DNA, RNA and amino acid sequences, high sequence similarity usually implies significant func1onal
Image Processing on the Cloud. Outline
 Mars Science Laboratory! Image Processing on the Cloud Emily Law Cloud Computing Workshop ESIP 2012 Summer Meeting July 14 th, 2012 1/26/12! 1 Outline Cloud computing @ JPL SDS Lunar images Challenge Image
Mars Science Laboratory! Image Processing on the Cloud Emily Law Cloud Computing Workshop ESIP 2012 Summer Meeting July 14 th, 2012 1/26/12! 1 Outline Cloud computing @ JPL SDS Lunar images Challenge Image
BioExtract Server User Manual
 BioExtract Server User Manual University of South Dakota About Us The BioExtract Server harnesses the power of online informatics tools for creating and customizing workflows. Users can query online sequence
BioExtract Server User Manual University of South Dakota About Us The BioExtract Server harnesses the power of online informatics tools for creating and customizing workflows. Users can query online sequence
VT EGI-ELIXIR : French node
 By Tiphaine Martin, CNRS-University of Cambridge Information provided by Thierry Meinnel, French observer for Elixir; Claudine Médigue, Coordinator of ReNaBi, Jean-Françcois Gibrat, Director of IFB, Genevieve
By Tiphaine Martin, CNRS-University of Cambridge Information provided by Thierry Meinnel, French observer for Elixir; Claudine Médigue, Coordinator of ReNaBi, Jean-Françcois Gibrat, Director of IFB, Genevieve
BIR pipeline steps and subsequent output files description STEP 1: BLAST search
 Lifeportal (Brief description) The Lifeportal at University of Oslo (https://lifeportal.uio.no) is a Galaxy based life sciences portal lifeportal.uio.no under the UiO tools section for phylogenomic analysis,
Lifeportal (Brief description) The Lifeportal at University of Oslo (https://lifeportal.uio.no) is a Galaxy based life sciences portal lifeportal.uio.no under the UiO tools section for phylogenomic analysis,
MapReduce, Apache Hadoop
 NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
NDBI040: Big Data Management and NoSQL Databases hp://www.ksi.mff.cuni.cz/ svoboda/courses/2016-1-ndbi040/ Lecture 2 MapReduce, Apache Hadoop Marn Svoboda svoboda@ksi.mff.cuni.cz 11. 10. 2016 Charles University
8:15 Introduction/Overview Michelle Giglio. 8:45 CloVR background W. Florian Fricke. 9:15 Hands-on: Start CloVR W. Florian Fricke
 Hands-On Exercises 2016 1 Agenda 8:15 Introduction/Overview Michelle Giglio 8:45 CloVR background W. Florian Fricke 9:15 Hands-on: Start CloVR W. Florian Fricke 9:45 Break 9:55 Hands-on: Start CloVR-Microbe
Hands-On Exercises 2016 1 Agenda 8:15 Introduction/Overview Michelle Giglio 8:45 CloVR background W. Florian Fricke 9:15 Hands-on: Start CloVR W. Florian Fricke 9:45 Break 9:55 Hands-on: Start CloVR-Microbe
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
The iplant Data Commons
 The iplant Data Commons Using irods to Facilitate Data Dissemination, Discovery, and Reproducibility Jeremy DeBarry, jdebarry@iplantcollaborative.org Tony Edgin, tedgin@iplantcollaborative.org Nirav Merchant,
The iplant Data Commons Using irods to Facilitate Data Dissemination, Discovery, and Reproducibility Jeremy DeBarry, jdebarry@iplantcollaborative.org Tony Edgin, tedgin@iplantcollaborative.org Nirav Merchant,
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Enabling Phylogenetic Research via the CIPRES Science Gateway!
 Enabling Phylogenetic Research via the CIPRES Science Gateway Wayne Pfeiffer SDSC/UCSD August 5, 2013 In collaboration with Mark A. Miller, Terri Schwartz, & Bryan Lunt SDSC/UCSD Supported by NSF Phylogenetics
Enabling Phylogenetic Research via the CIPRES Science Gateway Wayne Pfeiffer SDSC/UCSD August 5, 2013 In collaboration with Mark A. Miller, Terri Schwartz, & Bryan Lunt SDSC/UCSD Supported by NSF Phylogenetics
Assessing Transcriptome Assembly
 Assessing Transcriptome Assembly Matt Johnson July 9, 2015 1 Introduction Now that you have assembled a transcriptome, you are probably wondering about the sequence content. Are the sequences from the
Assessing Transcriptome Assembly Matt Johnson July 9, 2015 1 Introduction Now that you have assembled a transcriptome, you are probably wondering about the sequence content. Are the sequences from the
Lightweight Streaming-based Runtime for Cloud Computing. Shrideep Pallickara. Community Grids Lab, Indiana University
 Lightweight Streaming-based Runtime for Cloud Computing granules Shrideep Pallickara Community Grids Lab, Indiana University A unique confluence of factors have driven the need for cloud computing DEMAND
Lightweight Streaming-based Runtime for Cloud Computing granules Shrideep Pallickara Community Grids Lab, Indiana University A unique confluence of factors have driven the need for cloud computing DEMAND
Genomic Data Analysis Services Available for PL-Grid Users
 Domain-oriented services and resources of Polish Infrastructure for Supporting Computational Science in the European Research Space PLGrid Plus Domain-oriented services and resources of Polish Infrastructure
Domain-oriented services and resources of Polish Infrastructure for Supporting Computational Science in the European Research Space PLGrid Plus Domain-oriented services and resources of Polish Infrastructure
Genome Assembly and De Novo RNAseq
 Genome Assembly and De Novo RNAseq BMI 7830 Kun Huang Department of Biomedical Informatics The Ohio State University Outline Problem formulation Hamiltonian path formulation Euler path and de Bruijin graph
Genome Assembly and De Novo RNAseq BMI 7830 Kun Huang Department of Biomedical Informatics The Ohio State University Outline Problem formulation Hamiltonian path formulation Euler path and de Bruijin graph
DCBench: a Data Center Benchmark Suite
 DCBench: a Data Center Benchmark Suite Zhen Jia ( 贾禛 ) http://prof.ict.ac.cn/zhenjia/ Institute of Computing Technology, Chinese Academy of Sciences workshop in conjunction with CCF October 31,2013,Guilin
DCBench: a Data Center Benchmark Suite Zhen Jia ( 贾禛 ) http://prof.ict.ac.cn/zhenjia/ Institute of Computing Technology, Chinese Academy of Sciences workshop in conjunction with CCF October 31,2013,Guilin
BLAST, Profile, and PSI-BLAST
 BLAST, Profile, and PSI-BLAST Jianlin Cheng, PhD School of Electrical Engineering and Computer Science University of Central Florida 26 Free for academic use Copyright @ Jianlin Cheng & original sources
BLAST, Profile, and PSI-BLAST Jianlin Cheng, PhD School of Electrical Engineering and Computer Science University of Central Florida 26 Free for academic use Copyright @ Jianlin Cheng & original sources
Op#mizing MapReduce for Highly- Distributed Environments
 Op#mizing MapReduce for Highly- Distributed Environments Abhishek Chandra Associate Professor Department of Computer Science and Engineering University of Minnesota hep://www.cs.umn.edu/~chandra 1 Big
Op#mizing MapReduce for Highly- Distributed Environments Abhishek Chandra Associate Professor Department of Computer Science and Engineering University of Minnesota hep://www.cs.umn.edu/~chandra 1 Big
Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis
 Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis Elif Dede, Madhusudhan Govindaraju Lavanya Ramakrishnan, Dan Gunter, Shane Canon Department of Computer Science, Binghamton
Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis Elif Dede, Madhusudhan Govindaraju Lavanya Ramakrishnan, Dan Gunter, Shane Canon Department of Computer Science, Binghamton
Challenges and Approaches for Distributed Workflow-Driven Analysis of Large-Scale Biological Data
 Challenges and Approaches for Distributed Workflow-Driven Analysis of Large-Scale Biological Data [Vision Paper] ABSTRACT Ilkay Altintas, Jianwu Wang, and Daniel Crawl San Diego Supercomputer Center University
Challenges and Approaches for Distributed Workflow-Driven Analysis of Large-Scale Biological Data [Vision Paper] ABSTRACT Ilkay Altintas, Jianwu Wang, and Daniel Crawl San Diego Supercomputer Center University
Prof. Konstantinos Krampis Office: Rm. 467F Belfer Research Building Phone: (212) Fax: (212)
 Fax: (212)") Director: Prof. Konstantinos Krampis agbiotec@gmail.com Office: Rm. 467F Belfer Research Building Phone: (212) 396-6930 Fax: (212) 650 3565 Facility Consultant:Carlos Lijeron 1/8 carlos@carotech.com Office:
Director: Prof. Konstantinos Krampis agbiotec@gmail.com Office: Rm. 467F Belfer Research Building Phone: (212) 396-6930 Fax: (212) 650 3565 Facility Consultant:Carlos Lijeron 1/8 carlos@carotech.com Office:
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220
 Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Introduction to HPC Using zcluster at GACRC On-Class GENE 4220 Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu Slides courtesy: Zhoufei Hou 1 OVERVIEW GACRC
Automating Real-time Seismic Analysis
 Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Automating Real-time Seismic Analysis Through Streaming and High Throughput Workflows Rafael Ferreira da Silva, Ph.D. http://pegasus.isi.edu Do we need seismic analysis? Pegasus http://pegasus.isi.edu
Sequence Alignment: Mo1va1on and Algorithms. Lecture 2: August 23, 2012
 Sequence Alignment: Mo1va1on and Algorithms Lecture 2: August 23, 2012 Mo1va1on and Introduc1on Importance of Sequence Alignment For DNA, RNA and amino acid sequences, high sequence similarity usually
Sequence Alignment: Mo1va1on and Algorithms Lecture 2: August 23, 2012 Mo1va1on and Introduc1on Importance of Sequence Alignment For DNA, RNA and amino acid sequences, high sequence similarity usually
Pairwise Sequence Alignment. Zhongming Zhao, PhD
 Pairwise Sequence Alignment Zhongming Zhao, PhD Email: zhongming.zhao@vanderbilt.edu http://bioinfo.mc.vanderbilt.edu/ Sequence Similarity match mismatch A T T A C G C G T A C C A T A T T A T G C G A T
Pairwise Sequence Alignment Zhongming Zhao, PhD Email: zhongming.zhao@vanderbilt.edu http://bioinfo.mc.vanderbilt.edu/ Sequence Similarity match mismatch A T T A C G C G T A C C A T A T T A T G C G A T
Pegasus. Automate, recover, and debug scientific computations. Rafael Ferreira da Silva.
 Pegasus Automate, recover, and debug scientific computations. Rafael Ferreira da Silva http://pegasus.isi.edu Experiment Timeline Scientific Problem Earth Science, Astronomy, Neuroinformatics, Bioinformatics,
Pegasus Automate, recover, and debug scientific computations. Rafael Ferreira da Silva http://pegasus.isi.edu Experiment Timeline Scientific Problem Earth Science, Astronomy, Neuroinformatics, Bioinformatics,
A Virtual Machine to teach NGS data analysis. Andreas Gisel CNR - ITB Bari, Italy
 A Virtual Machine to teach NGS data analysis Andreas Gisel CNR - ITB Bari, Italy The Virtual Machine A virtual machine is a tightly isolated software container that can run its own operating systems and
A Virtual Machine to teach NGS data analysis Andreas Gisel CNR - ITB Bari, Italy The Virtual Machine A virtual machine is a tightly isolated software container that can run its own operating systems and
MapReduce, Apache Hadoop
 Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
Czech Technical University in Prague, Faculty of Informaon Technology MIE-PDB: Advanced Database Systems hp://www.ksi.mff.cuni.cz/~svoboda/courses/2016-2-mie-pdb/ Lecture 12 MapReduce, Apache Hadoop Marn
Basic Local Alignment Search Tool (BLAST)
") BLAST 26.04.2018 Basic Local Alignment Search Tool (BLAST) BLAST (Altshul-1990) is an heuristic Pairwise Alignment composed by six-steps that search for local similarities. The most used access point to
BLAST 26.04.2018 Basic Local Alignment Search Tool (BLAST) BLAST (Altshul-1990) is an heuristic Pairwise Alignment composed by six-steps that search for local similarities. The most used access point to
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
EBI is an Outstation of the European Molecular Biology Laboratory.
 EBI is an Outstation of the European Molecular Biology Laboratory. InterPro is a database that groups predictive protein signatures together 11 member databases single searchable resource provides functional
EBI is an Outstation of the European Molecular Biology Laboratory. InterPro is a database that groups predictive protein signatures together 11 member databases single searchable resource provides functional
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase. Chen Zhang Hans De Sterck University of Waterloo
 CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
CloudBATCH: A Batch Job Queuing System on Clouds with Hadoop and HBase Chen Zhang Hans De Sterck University of Waterloo Outline Introduction Motivation Related Work System Design Future Work Introduction
Using MPI One-sided Communication to Accelerate Bioinformatics Applications
 Using MPI One-sided Communication to Accelerate Bioinformatics Applications Hao Wang (hwang121@vt.edu) Department of Computer Science, Virginia Tech Next-Generation Sequencing (NGS) Data Analysis NGS Data
Using MPI One-sided Communication to Accelerate Bioinformatics Applications Hao Wang (hwang121@vt.edu) Department of Computer Science, Virginia Tech Next-Generation Sequencing (NGS) Data Analysis NGS Data
Provenance for MapReduce-based Data-Intensive Workflows
 Provenance for MapReduce-based Data-Intensive Workflows Daniel Crawl, Jianwu Wang, Ilkay Altintas San Diego Supercomputer Center University of California, San Diego 9500 Gilman Drive La Jolla, CA 92093-0505
Provenance for MapReduce-based Data-Intensive Workflows Daniel Crawl, Jianwu Wang, Ilkay Altintas San Diego Supercomputer Center University of California, San Diego 9500 Gilman Drive La Jolla, CA 92093-0505
How to store and visualize RNA-seq data
 How to store and visualize RNA-seq data Gabriella Rustici Functional Genomics Group gabry@ebi.ac.uk EBI is an Outstation of the European Molecular Biology Laboratory. Talk summary How do we archive RNA-seq
How to store and visualize RNA-seq data Gabriella Rustici Functional Genomics Group gabry@ebi.ac.uk EBI is an Outstation of the European Molecular Biology Laboratory. Talk summary How do we archive RNA-seq
MacVector for Mac OS X. The online updater for this release is MB in size
 MacVector 17.0.3 for Mac OS X The online updater for this release is 143.5 MB in size You must be running MacVector 15.5.4 or later for this updater to work! System Requirements MacVector 17.0 is supported
MacVector 17.0.3 for Mac OS X The online updater for this release is 143.5 MB in size You must be running MacVector 15.5.4 or later for this updater to work! System Requirements MacVector 17.0 is supported
CloudMan cloud clusters for everyone
 CloudMan cloud clusters for everyone Enis Afgan usecloudman.org This is accessibility! But only sometimes So, there are alternatives BUT WHAT IF YOU WANT YOUR OWN, QUICKLY The big picture A. Users in different
CloudMan cloud clusters for everyone Enis Afgan usecloudman.org This is accessibility! But only sometimes So, there are alternatives BUT WHAT IF YOU WANT YOUR OWN, QUICKLY The big picture A. Users in different
A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis
 A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis Ashish Nagavaram, Gagan Agrawal, Michael A. Freitas, Kelly H. Telu The Ohio State University Gaurang Mehta, Rajiv. G. Mayani, Ewa Deelman
A Cloud-based Dynamic Workflow for Mass Spectrometry Data Analysis Ashish Nagavaram, Gagan Agrawal, Michael A. Freitas, Kelly H. Telu The Ohio State University Gaurang Mehta, Rajiv. G. Mayani, Ewa Deelman
Grid Scheduling Architectures with Globus
 Grid Scheduling Architectures with Workshop on Scheduling WS 07 Cetraro, Italy July 28, 2007 Ignacio Martin Llorente Distributed Systems Architecture Group Universidad Complutense de Madrid 1/38 Contents
Grid Scheduling Architectures with Workshop on Scheduling WS 07 Cetraro, Italy July 28, 2007 Ignacio Martin Llorente Distributed Systems Architecture Group Universidad Complutense de Madrid 1/38 Contents
HPC Cloud at SURFsara
 HPC Cloud at SURFsara Offering cloud as a service SURF Research Boot Camp 21st April 2016 Ander Astudillo Markus van Dijk What is cloud computing?
HPC Cloud at SURFsara Offering cloud as a service SURF Research Boot Camp 21st April 2016 Ander Astudillo Markus van Dijk What is cloud computing?
High Performance Computing (HPC) Using zcluster at GACRC
 Using zcluster at GACRC") High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?
High Performance Computing (HPC) Using zcluster at GACRC On-class STAT8060 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC?