CS 696 Intro to Big Data: Tools and Methods Fall Semester, 2016 Doc 25 Spark 2 Nov 29, 2016
|
|
|
- Christina Freeman
- 5 years ago
- Views:
Transcription
1 CS 696 Intro to Big Data: Tools and Methods Fall Semester, 2016 Doc 25 Spark 2 Nov 29, 2016 Copyright, All rights reserved SDSU & Roger Whitney, 5500 Campanile Drive, San Diego, CA USA. OpenContent ( license defines the copyright on this document.
2 Transformations JavaSparkContext sc = new JavaSparkContext(); JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(1,2,3,3)); rdd.map(x -> x + 1) [2, 3, 4, 4] rdd.distinct() [1, 2, 3] rdd.sample(false,0.5); varies 2
3 Transformations JavaSparkContext sc = new JavaSparkContext(); JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(1, 2, 3)); JavaRDD<Integer> other = sc.parallelize(arrays.aslist(3, 4, 5)); rdd.union(other) [1, 2, 3, 3, 4, 5] rdd.intersection(other) [3] rdd.subtract(other) [1, 2] 3
4 Transformations & Output JavaSparkContext sc = new JavaSparkContext(); JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(1, 2, 3)); JavaRDD<Integer> other = sc.parallelize(arrays.aslist(3, 4, 5)); JavaRDD<Integer> result = rdd.union(other); result.saveastextfile(somepath); 4
5 Actions & Output JavaSparkContext sc = new JavaSparkContext(); JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(1, 2, 3)); JavaRDD<Integer> other = sc.parallelize(arrays.aslist(3, 4, 5)); JavaRDD<Integer> result = rdd.union(other); List onmaster = result.collect(); List is java.util.list - no spark method saveastextfile 5
6 Writing to HDFS import org.apache.hadoop.conf.configuration; import org.apache.hadoop.fs.filesystem; import org.apache.hadoop.fs.fsdataoutputstream; import org.apache.hadoop.fs.path; static void saveastextfile(string destination, Object contents) throws Exception { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(destination), conf); FSDataOutputStream out = fs.create(new Path(destination)); out.writechars(contents.tostring()); out.close(); } destination /full/path/to/file.txt local/path/file.txt s2://bucket/file.txt 6
7 Actions JavaSparkContext sc = new JavaSparkContext(); JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(3, 1, 2, 3)); rdd.collect() [3,1, 2, 3] rdd.reduce((a,b) -> a + b) 9 rdd.first 3 rdd.top(2) [3, 1] rdd.take(2) [3, 1] rdd.takeordered(2) [1, 2] rdd.count() 3 rdd.countbyvalue() {3=2, 1=1, 2=1} 7
8 Actions on DoubleRDD JavaSparkContext sc = new JavaSparkContext(); JavaDoubleRDD rdd = sc.parallelizedoubles(arrays.aslist(5.0,1.0,2.0,3.0,4.0,5.0)); rdd.mean() rdd.min() rdd.sum() rdd.variance() rdd.stdev() rdd.stats() rdd.histogram(bucketcount) 8
9 JavaPairRDD RDD on key-value pairs JavaSparkContext sc = new JavaSparkContext(); JavaRDD a = sc.parallelize(arrays.aslist(1, 3, 3)); JavaRDD b = sc.parallelize(arrays.aslist(2, 4, 6)); JavaPairRDD<Integer, Integer> rdd = a.zip(b); rdd.collect(); // [(1,2), (3,4), (3,6)] 9
10 Transformations on Pair RDD rdd.collect(); // [(1,2), (3,4), (3,6)] rdd.reducebykey( (x, y) -> x + y) [(1, 2), (3, 10)] rdd.groupbykey() [(1, [2]), (3, [4, 6])] rdd.mapvalues( x -> x + 1) [(1,3), (3,5), (3,7)] rdd.top(2) [3, 1] rdd.keys() [1, 3, 6] rdd.values() [2, 4, 6] rdd.sortbykey() [(1,2), (3,4), (3,6)] 10
11 Transformations on Pair RDD rdd [(1,2), (3,4), (3,6)] other [(3,9)] rdd.subtractbykey(other) [(1,2)] rdd.join(other) [(3, (4, 9)), (3, (6,9))] rdd.cogroup(other) [(1, ([2], [])), (3, ([4, 6],[9]))] 11
12 Shared Variables BroadCast Variables Read-only variable on each machine Sent from master Broadcast<int[]> broadcastvar = sc.broadcast(new int[] {1, 2, 3}); Accumulators Write-only on each machine - using add() Master can read LongAccumulator accum = jsc.sc().longaccumulator(); 12
13 Some Debugging help JavaRDD<Integer> rdd = sc.parallelize(arrays.aslist(1,2,3,3)); JavaRDD<Integer> result = rdd.map(x -> x + 2); String test = result.todebugstring(); test (2) MapPartitionsRDD[1] at map at JavaWordCount.java:41 [] ParallelCollectionRDD[0] at parallelize at JavaWordCount.java:40 [] 13
14 Spark vs Hadoop MapReduce Hadoop MapReduce Implements two common functional programming functions is OO manner Spark Uses set of common functional programming functions in a functional way 14
15 Spark SQL 15
16 Spark SQL Structured data processing Structure allow extra optimizations via Spark SQL optimized catalyst engine Structured data SQL Datasets & Dataframes Data Sources Hive (distributed data warehouse) Parquet (compressed column data) SQL databases JSON, CSV, text files RDD 16
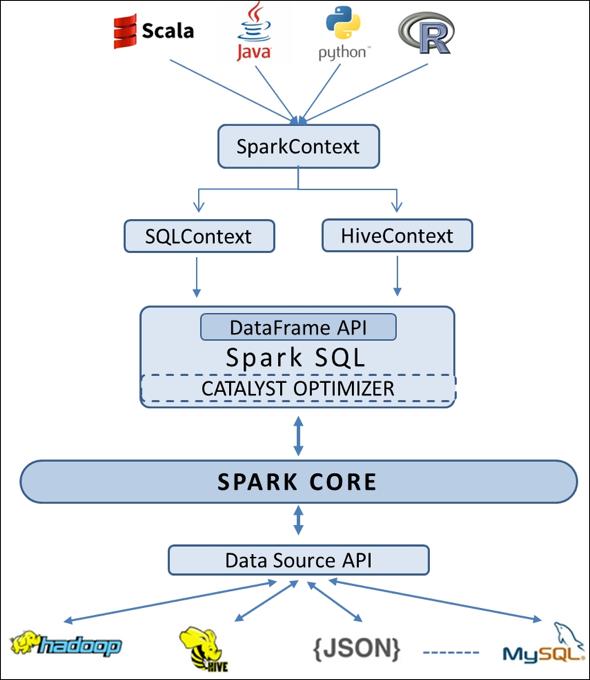
17 17
18 Datasets & DataFrames Dataset Distributed collection of structured data Like RDD but uses Spark SQL optimized execution engine Scala, Java, JVM languages only (no python or R) DataFrame Dataset organized into named columns Like SQL table or dataframe in Julia Dataset<Row> in Java 18
19 Creating DataFrames SparkSession spark = SparkSession.builder().appName("JavaWordCount").getOrCreate(); Dataset<Row> df = spark.read().json( people.json ); df.show(); age name null Michael 30 Andy 19 Justin people.json {"name":"michael"} {"name":"andy", "age":30} {"name":"justin", "age":19} 19
20 Reading CSV SparkSession spark = SparkSession.builder().appName("JavaWordCount").getOrCreate(); DataFrameReader reader = spark.read(); reader.option("header",true); reader.option("inferschema",true); Dataset<Row> df = reader.csv(args[0]); df.show(); df.printschema(); people.csv name,age Andy,30 Justin,19 Michael, name age Andy 30 Justin 19 Michael null root -- name: string (nullable = true) -- age: integer (nullable = true) 20
21 Types We Can Read csv jdbc json orc parquet text 21
22 Some CSV options encoding sep (erator) header inferschema ignoreleadingwhitespace nullvalue dateformat timestampformat mode PERMISSIVE - sets record field on corrupt record DROPMALFORMED - ignores whole corrupt records FAILFAST - throw exception on corrupt record 22
23 Dataset Functions common with RDDs collect count distinct filter flatmap foreach groupby map reduce 23
24 We can work with columns import static org.apache.spark.sql.functions.col; Dataset<Row> df = reader.csv( people.csv ); df.select("name").show(); df.select(col("name")).show(); people.csv name,age Andy,30 Justin,19 Michael, name Andy Justin Michael
25 // Select everybody, but increment the age by 1 df.select(col("name"), col("age").plus(1)).show(); name (age + 1) Andy 31 Justin 20 Michael null
26 // Select people older than 21 df.filter(col("age").gt(21)).show(); name age Andy // Count people by age df.groupby("age").count().show(); age count null
27 Using SQL df.createorreplacetempview("people"); Dataset<Row> sqldf = spark.sql("select * FROM people"); sqldf.show(); name age Andy 30 Justin 19 Michael null
28 Saving DataFrames df.write().format("json").save("people2.json"); {"name":"andy","age":30} {"name":"justin","age":19} {"name":"michael"} Formats json, parquet, jdbc, orc, libsvm, csv, text 28
29 DataFrames & Objects Can define encoders/decoders so can have dataframes/datasets of objects Efficient transmission on network Efficient in memory allocation 29
30 DataFrames & RDDs Can convert RDDs to dataframes/datasets - But need schema for dataframe Converting DataFame to RDD fd.tojavardd() 30
31 More Statistics DataFrameStatFunctions stat = df.stat(); approxquantile bloomfilter corr (Pearson Correlation Coeffient) cov (Covariance) freqitems find frequent items in column(s) 31
32 Spark vs Hadoop MapReduce Hadoop MapReduce Implements two common functional programming functions is OO manner Spark Uses set of common functional programming functions in a functional way Reads more data formats SQL More queries Interacts with SQL databases directly 10 to 100 times faster But there is more - machine learning! 32
33 MLib Linear Algebra Statistics Correlations, Hypothesis testing, Sampling, density estimation Classification & regression Linear, logistic, isotonic, & ridge regression Decision trees, naive Bayes Collaborative filtering (recommender systems) Clustering Dimensionality reduction Feature extraction Frequent pattern mining 33
The input data can be queried by using
 1 Spark SQL is the Spark component for structured data processing It provides a programming abstraction called Dataset and can act as a distributed SQL query engine The input data can be queried by using
1 Spark SQL is the Spark component for structured data processing It provides a programming abstraction called Dataset and can act as a distributed SQL query engine The input data can be queried by using
2/26/2017. DataFrame. The input data can be queried by using
 Spark SQL is the Spark component for structured data processing It provides a programming abstraction called s and can act as distributed SQL query engine The input data can be queried by using Ad-hoc
Spark SQL is the Spark component for structured data processing It provides a programming abstraction called s and can act as distributed SQL query engine The input data can be queried by using Ad-hoc
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
spark-testing-java Documentation Release latest
 spark-testing-java Documentation Release latest Nov 20, 2018 Contents 1 Input data preparation 3 2 Java 5 2.1 Context creation............................................. 5 2.2 Data preparation.............................................
spark-testing-java Documentation Release latest Nov 20, 2018 Contents 1 Input data preparation 3 2 Java 5 2.1 Context creation............................................. 5 2.2 Data preparation.............................................
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/05/2018. The following slides show how to
 The following slides show how to Create a classification model based on the logistic regression algorithm for textual documents Apply the model to new textual documents The input training dataset represents
The following slides show how to Create a classification model based on the logistic regression algorithm for textual documents Apply the model to new textual documents The input training dataset represents
09/05/2018. Spark MLlib is the Spark component providing the machine learning/data mining algorithms
 Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS
 WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
SparkSQL 11/14/2018 1
 SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
SparkSQL 11/14/2018 1 Where are we? Pig Latin HiveQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 2 Where are we? Pig Latin HiveQL SQL Pig Hive??? Hadoop MapReduce Spark RDD HDFS 11/14/2018 3
/ Cloud Computing. Recitation 13 April 17th 2018
 15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
15-319 / 15-619 Cloud Computing Recitation 13 April 17th 2018 Overview Last week s reflection Team Project Phase 2 Quiz 11 OLI Unit 5: Modules 21 & 22 This week s schedule Project 4.2 No more OLI modules
Using Numerical Libraries on Spark
 Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
Using Numerical Libraries on Spark Brian Spector London Spark Users Meetup August 18 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm with
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
2/26/2017. Spark MLlib is the Spark component providing the machine learning/data mining algorithms. MLlib APIs are divided into two packages:
 Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
Spark MLlib is the Spark component providing the machine learning/data mining algorithms Pre-processing techniques Classification (supervised learning) Clustering (unsupervised learning) Itemset mining
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Parallel Processing Spark and Spark SQL
 Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Parallel Processing Spark and Spark SQL Amir H. Payberah amir@sics.se KTH Royal Institute of Technology Amir H. Payberah (KTH) Spark and Spark SQL 2016/09/16 1 / 82 Motivation (1/4) Most current cluster
Chapter 1 - The Spark Machine Learning Library
 Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
Chapter 1 - The Spark Machine Learning Library Objectives Key objectives of this chapter: The Spark Machine Learning Library (MLlib) MLlib dense and sparse vectors and matrices Types of distributed matrices
Using Existing Numerical Libraries on Spark
 Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
CMU MSP 36602: Spark, Part 3
 CMU MSP 36602: Spark, Part 3 H. Seltman, March 27, 2019 I) pyspark DataFrames i) These are implemented in module pyspark.sql (http://spark.apache.org/docs/2.1.0/api/python/pyspark.sql.html). ii) Spark
CMU MSP 36602: Spark, Part 3 H. Seltman, March 27, 2019 I) pyspark DataFrames i) These are implemented in module pyspark.sql (http://spark.apache.org/docs/2.1.0/api/python/pyspark.sql.html). ii) Spark
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
13/05/2018. Spark MLlib provides
 Spark MLlib provides An itemset mining algorithm based on the FPgrowth algorithm That extracts all the sets of items (of any length) with a minimum frequency A rule mining algorithm That extracts the association
Spark MLlib provides An itemset mining algorithm based on the FPgrowth algorithm That extracts all the sets of items (of any length) with a minimum frequency A rule mining algorithm That extracts the association
Spark 2. Alexey Zinovyev, Java/BigData Trainer in EPAM
 Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Spark 2 Alexey Zinovyev, Java/BigData Trainer in EPAM With IT since 2007 With Java since 2009 With Hadoop since 2012 With EPAM since 2015 About Secret Word from EPAM itsubbotnik Big Data Training 3 Contacts
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Spark supports several storage levels
 1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
15/04/2018. Spark supports several storage levels. The storage level is used to specify if the content of the RDD is stored
 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Intro To Spark. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Spark Capabilities (i.e. Hadoop shortcomings) Performance First, use RAM Also, be smarter Ease of
Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Spark Capabilities (i.e. Hadoop shortcomings) Performance First, use RAM Also, be smarter Ease of
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Using Spark SQL in Spark 2
 201704 Using Spark SQL in Spark 2 Spark SQL in Spark 2: Overview and SparkSession Chapter 1 Course Chapters Spark SQL in Spark 2: Overview and SparkSession Spark SQL in Spark 2: Datasets, DataFrames, and
201704 Using Spark SQL in Spark 2 Spark SQL in Spark 2: Overview and SparkSession Chapter 1 Course Chapters Spark SQL in Spark 2: Overview and SparkSession Spark SQL in Spark 2: Datasets, DataFrames, and
Intro To Spark. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Performance First, use RAM Also, be smarter Spark Capabilities (i.e. Hadoop shortcomings) Ease of
Intro To Spark John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Performance First, use RAM Also, be smarter Spark Capabilities (i.e. Hadoop shortcomings) Ease of
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
An Introduction to Apache Spark
 An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Apache Spark Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Apache Spark Feb. 2, 2016 1 / 67 Big Data small data big data Amir H. Payberah (SICS) Apache Spark
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Data Science Bootcamp Curriculum. NYC Data Science Academy
 Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
CSE 414: Section 7 Parallel Databases. November 8th, 2018
 CSE 414: Section 7 Parallel Databases November 8th, 2018 Agenda for Today This section: Quick touch up on parallel databases Distributed Query Processing In this class, only shared-nothing architecture
CSE 414: Section 7 Parallel Databases November 8th, 2018 Agenda for Today This section: Quick touch up on parallel databases Distributed Query Processing In this class, only shared-nothing architecture
Distributed Machine Learning" on Spark
 Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Distributed Machine Learning" on Spark Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Outline Data flow vs. traditional network programming Spark computing engine Optimization Example Matrix Computations
Hadoop File Formats and Data Ingestion. Prasanth Kothuri, CERN
 Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
Prasanth Kothuri, CERN 2 Files Formats not just CSV - Key factor in Big Data processing and query performance - Schema Evolution - Compression and Splittability - Data Processing Write performance Partial
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Spark MLlib provides a (limited) set of clustering algorithms
 set of clustering algorithms") 1 Spark MLlib provides a (limited) set of clustering algorithms K-means Gaussian mixture 3 Each clustering algorithm has its own parameters However, all the provided algorithms identify a set of groups
1 Spark MLlib provides a (limited) set of clustering algorithms K-means Gaussian mixture 3 Each clustering algorithm has its own parameters However, all the provided algorithms identify a set of groups
빅데이터기술개요 2016/8/20 ~ 9/3. 윤형기
 빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
빅데이터기술개요 2016/8/20 ~ 9/3 윤형기 (hky@openwith.net) D4 http://www.openwith.net 2 Hive http://www.openwith.net 3 What is Hive? 개념 a data warehouse infrastructure tool to process structured data in Hadoop. Hadoop
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Submitted to: Dr. Sunnie Chung. Presented by: Sonal Deshmukh Jay Upadhyay
 Submitted to: Dr. Sunnie Chung Presented by: Sonal Deshmukh Jay Upadhyay Submitted to: Dr. Sunny Chung Presented by: Sonal Deshmukh Jay Upadhyay What is Apache Survey shows huge popularity spike for Apache
Submitted to: Dr. Sunnie Chung Presented by: Sonal Deshmukh Jay Upadhyay Submitted to: Dr. Sunny Chung Presented by: Sonal Deshmukh Jay Upadhyay What is Apache Survey shows huge popularity spike for Apache
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
CS 378 Big Data Programming. Lecture 20 Spark Basics
 CS 378 Big Data Programming Lecture 20 Spark Basics Review Assignment 9 Download and run Spark Controlling logging output CS 378 - Fall 2018 Big Data Programming 2 Review - Spark RDDs Resilient Distributed
CS 378 Big Data Programming Lecture 20 Spark Basics Review Assignment 9 Download and run Spark Controlling logging output CS 378 - Fall 2018 Big Data Programming 2 Review - Spark RDDs Resilient Distributed
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
TestsDumps. Latest Test Dumps for IT Exam Certification
 TestsDumps http://www.testsdumps.com Latest Test Dumps for IT Exam Certification Exam : CCA175 Title : CCA Spark and Hadoop Developer Exam Vendor : Cloudera Version : DEMO Get Latest & Valid CCA175 Exam's
TestsDumps http://www.testsdumps.com Latest Test Dumps for IT Exam Certification Exam : CCA175 Title : CCA Spark and Hadoop Developer Exam Vendor : Cloudera Version : DEMO Get Latest & Valid CCA175 Exam's
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
WHITE PAPER. Apache Spark: RDD, DataFrame and Dataset. API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3
 WHITE PAPER Apache Spark: RDD, DataFrame and Dataset API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3 Prepared by: Eyal Edelman, Big Data Practice Lead Michael Birch, Big Data and
WHITE PAPER Apache Spark: RDD, DataFrame and Dataset API comparison and Performance Benchmark in Spark 2.1 and Spark 1.6.3 Prepared by: Eyal Edelman, Big Data Practice Lead Michael Birch, Big Data and
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Python With Data Science
 Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Course Overview This course covers theoretical and technical aspects of using Python in Applied Data Science projects and Data Logistics use cases. Who Should Attend Data Scientists, Software Developers,
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Apache Spark: Hands-on Session A.A. 2016/17
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2016/17 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Big Data Analytics with. Apache Spark. Machiel Jansen. Matthijs Moed
 Big Data Analytics with Apache Spark Machiel Jansen Matthijs Moed Schedule 10:15-10:45 General introduction to Spark 10:45-11:15 Hands-on: Python notebook 11:15-11:30 General introduction to Spark (continued)
Big Data Analytics with Apache Spark Machiel Jansen Matthijs Moed Schedule 10:15-10:45 General introduction to Spark 10:45-11:15 Hands-on: Python notebook 11:15-11:30 General introduction to Spark (continued)
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark: Hands-on Session A.A. 2017/18
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Apache Spark: Hands-on Session A.A. 2017/18 Matteo Nardelli Laurea Magistrale in Ingegneria Informatica
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Data Analytics with Spark
 Data Analytics with Spark Peter Vanroose TRAINING & CONSULTING GSE NL Nat.Conf. 16 November 2017 Almere - Van Der Valk Digital Transformation Data Analytics with Spark Outline : Data analytics - history
Data Analytics with Spark Peter Vanroose TRAINING & CONSULTING GSE NL Nat.Conf. 16 November 2017 Almere - Van Der Valk Digital Transformation Data Analytics with Spark Outline : Data analytics - history
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Scalable Machine Learning in R. with H2O
 Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with