Part II: Software Infrastructure in Data Centers: Distributed Execution Engines
|
|
|
- Deborah Horton
- 5 years ago
- Views:
Transcription
1 CSE 6350 File and Storage System Infrastructure in Data centers Supporting Internet-wide Services Part II: Software Infrastructure in Data Centers: Distributed Execution Engines 1
2 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters Want to use 1000s of CPUs But don t want hassle of managing things MapReduce provides Automatic parallelization & distribution Fault tolerance I/O scheduling Monitoring & status updates Jeffrey Dean, et al., MapReduce: Simplified Data Processing on Large Clusters in OSDI 04 2
3 Map/Reduce Map/Reduce Programming model from Lisp (and other functional languages) Many problems can be expressed this way Easy to distribute across nodes Nice retry/failure semantics 3
4 (map f list [list 2 list 3 ]) Map in Lisp (Scheme) (map square ( )) ( ) (reduce + ( )) (+ 16 (+ 9 (+ 4 1) ) ) 30 4
5 Map/Reduce ala Google map(key, val) is run on each item in a set emits new-key / new-val pairs reduce(key, vals) is run for each unique key emitted by map() emits final output 5
6 count words in docs Input consists of (url, contents) pairs map(key=url, val=contents): For each word w in contents, emit (w, 1 ) reduce(key=word, values=uniq_counts): Sum all 1 s in values list Emit result (word, sum) 6
7 Count, Illustrated map(key=url, val=contents): For each word w in contents, emit (w, 1 ) reduce(key=word, values=uniq_counts): Sum all 1 s in values list Emit result (word, sum) see bob throw see spot run see 1 bob 1 run 1 see 1 spot 1 throw 1 bob 1 run 1 see 2 spot 1 throw 1 7
8 Pseudo-code of WordCount Map(String input_key, String input_value): //input_key: document name //input_value: document contents for each word w in input_values: EmitIntermediate(w, "1"); Reduce(String key, Iterator intermediate_values): //key: a word, same for input and output //intermediate_values: a list of counts int result = 0; for each v in inermediate_values: result += ParseInt(v); Emit(AsString(result)) 8
9 Grep Input consists of (url+offset, single line) map(key=url+offset, val=line): If contents matches regexp, emit (line, 1 ) reduce(key=line, values=uniq_counts): Don t do anything; just emit line 9
10 Map Reverse Web-Link Graph For each URL linking to target (the link) in a source page Output <target, source> pairs Reduce Concatenate list of all source URLs Outputs: <target, list (source)> pairs 10
11 More examples Inverted index Distributed sort 11
12 Typical cluster: Implementation Overview 100s/1000s of 2-CPU x86 machines, 2-4 GB of memory Limited bisection bandwidth Storage is on local IDE disks GFS: distributed file system manages data (SOSP'03) Job scheduling system: jobs made up of tasks, scheduler assigns tasks to machines Implementation is a C++ library linked into user programs 12
13 How is this distributed? Execution 1. Partition input key/value pairs into chunks, run map() tasks in parallel 2. After all map()s are complete, consolidate all emitted values for each unique emitted key 3. Now partition space of output map keys, and run reduce() in parallel If map() or reduce() fails, reexecute! 13
14 MapReduce Overall Architecture 14
15 Reduce Phase Map Phase MapReduce: A Bird s-eye View In MapReduce, chunks are processed in isolation by tasks called Mappers chunks C0 C1 C2 C3 The outputs from the mappers are denoted as intermediate outputs (IOs) and are brought into a second set of tasks called Reducers mappers M0 M1 M2 M3 IO0 IO1 IO2 IO3 The process of bringing together IOs into a set of Reducers is known as shuffling process Shuffling Data Reducers R0 R1 The Reducers produce the final outputs (FOs) FO0 FO1 Overall, MapReduce breaks the data flow into two phases, map phase and reduce phase 15
16 Keys and Values The programmer in MapReduce has to specify two functions, the map function and the reduce function that implement the Mapper and the Reducer in a MapReduce program In MapReduce data elements are always structured as key-value (i.e., (K, V)) pairs The map and reduce functions receive and emit (K, V) pairs Input Splits Intermediate Outputs Final Outputs (K, V) Pairs Map Function (K, V ) Pairs Reduce Function (K, V ) Pairs 16
17 Partitions All values with the same key are presented to a single Reducer together More specifically, a different subset of intermediate key space is assigned to each Reducer These subsets are known as partitions using a partitioning function such as hash(key) mod R. Different colors represent different keys (potentially) from different Mappers Partitions are the input to Reducers 17
18 Task Scheduling in MapReduce MapReduce adopts a master-slave architecture The master node in MapReduce is referred to as Job Tracker (JT) TT Task Slots Each slave node in MapReduce is referred to as Task Tracker (TT) JT Tasks Queue T0 T1 T2 MapReduce adopts a pull scheduling strategy rather than a push one TT Task Slots I.e., JT does not push map and reduce tasks to TTs but rather TTs pull them by making pertaining requests 18
19 Job Processing TaskTracker 0TaskTracker 1TaskTracker 2 JobTracker grep TaskTracker 3TaskTracker 4TaskTracker 5 1. Client submits grep job, indicating code and input files 2. JobTracker breaks input file into k chunks, (in this case 6). Assigns work to ttrackers. 3. After map(), tasktrackers exchange mapoutput to build reduce() keyspace 4. JobTracker breaks reduce() keyspace into m chunks (in this case 6). Assigns work. 5. reduce() output may go to GFS/HDFS 19
20 Execution 20
21 Parallel Execution 21

22 Task Granularity & Pipelining Fine granularity tasks: map tasks >> machines Minimizes time for fault recovery Can pipeline shuffling with map execution Better dynamic load balancing Often use 200,000 map & 5000 reduce tasks Running on 2000 machines 22
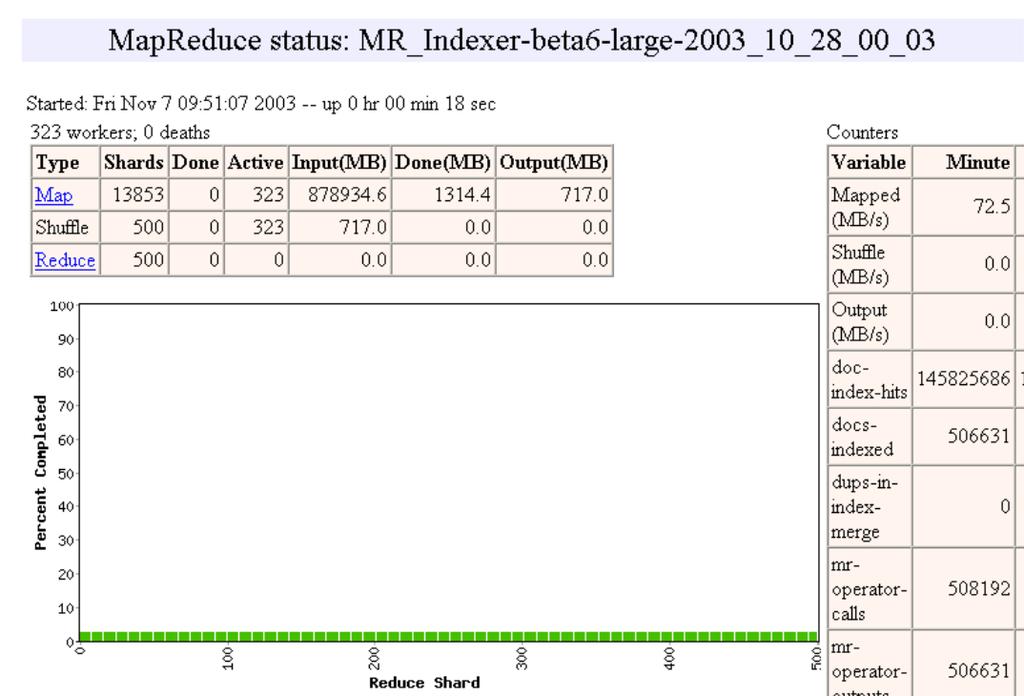
23 23
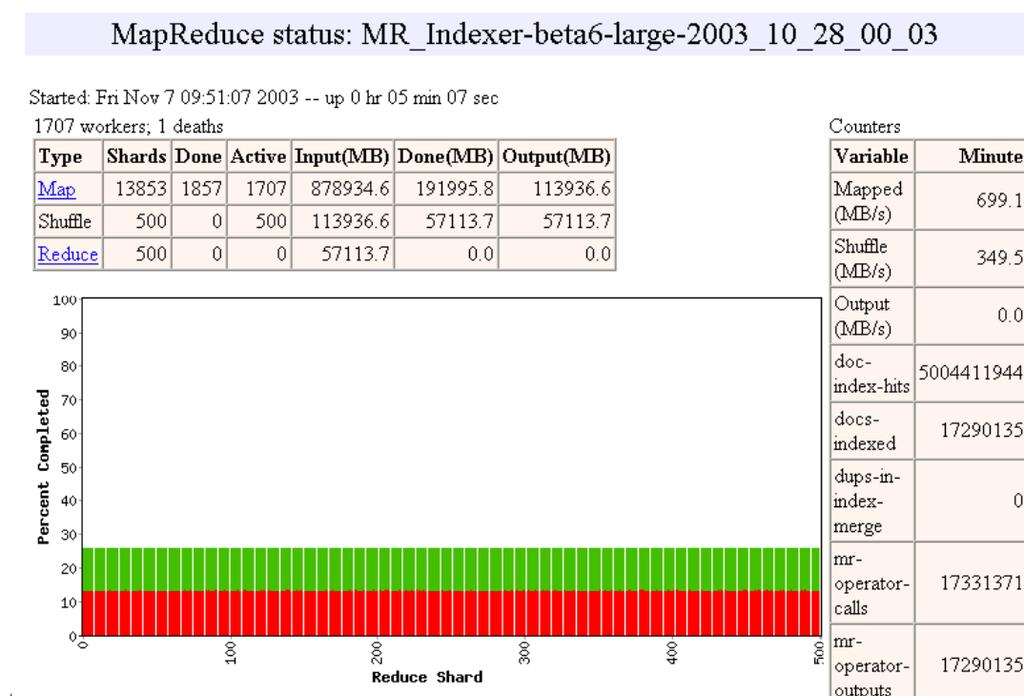
24 24
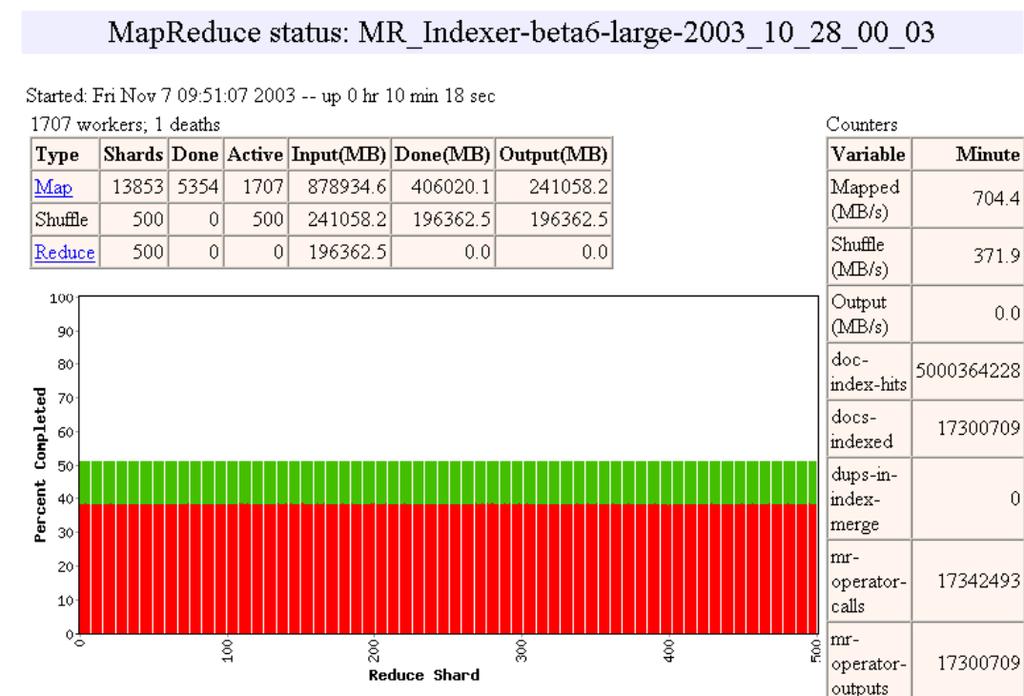
25 25
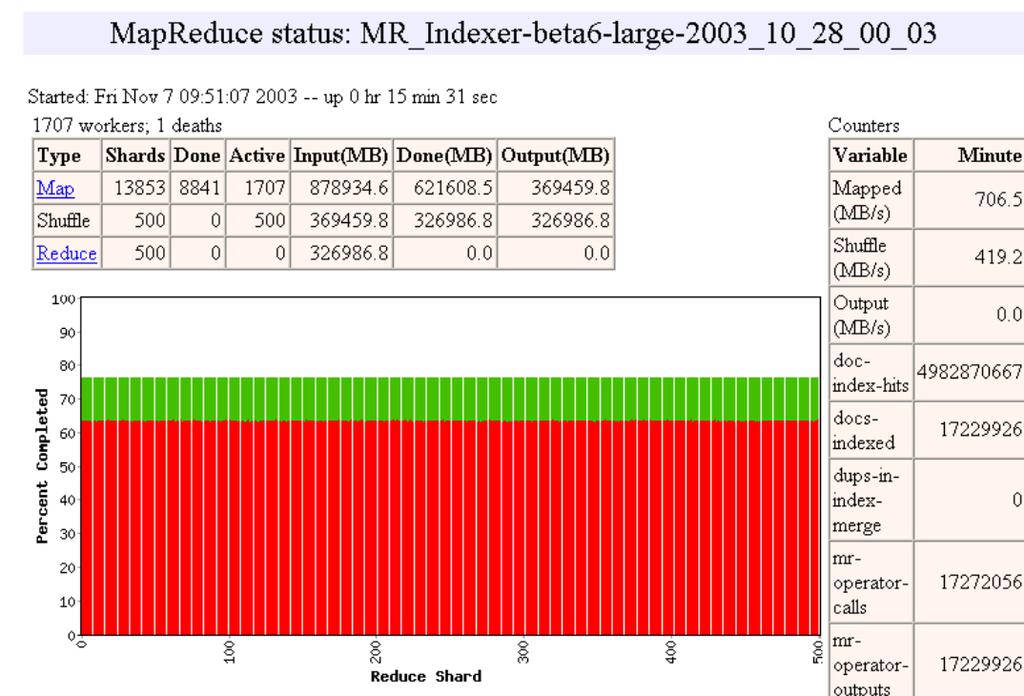
26 26
27 27
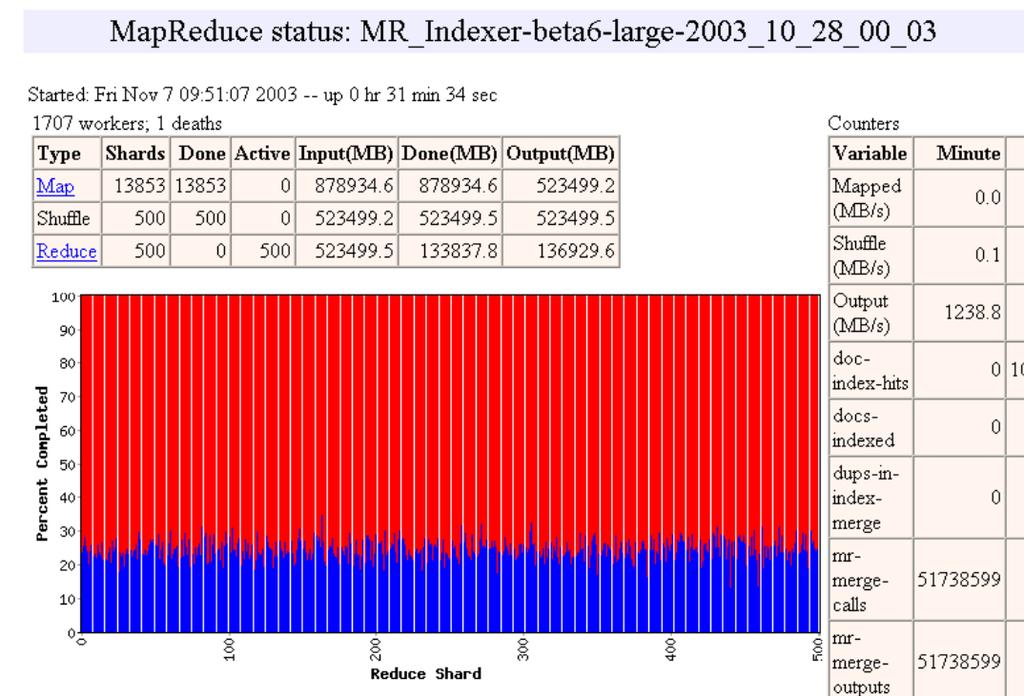
28 28
29 29
30 30
31 31
32 32
33 33
34 Fault Tolerance / Workers Handled via re-execution Detect failure via periodic heartbeats Re-execute completed + in-progress map tasks The map outputs are on the local disks. Re-execute in progress reduce tasks Task completion committed through master Robust: lost 1600/1800 machines once finished ok 34
35 Refinement: Redundant Execution Slow workers significantly delay completion time Other jobs consuming resources on machine Bad disks w/ soft errors transfer data slowly Weird things: processor caches disabled (!!) Solution: Near end of phase, spawn backup tasks Whichever one finishes first "wins" Dramatically shortens job completion time 35
36 Master scheduling policy: Refinement: Locality Optimization Asks GFS for locations of replicas of input file blocks Map tasks typically split into 64MB (GFS block size) Map tasks scheduled so GFS input block replica are on same machine or same rack Effect Thousands of machines read input at local disk speed Without this, rack switches limit read rate 36
37 Refinement Sorting guarantees within each reduce partition Combiner Useful for saving network bandwidth Local execution for debugging/testing User-defined counters 37
38 What Makes MapReduce Unique? MapReduce is characterized by: 1. Its simplified programming model which allows the user to quickly write and test distributed systems 2. Its efficient and automatic distribution of data and workload across machines 3. Its flat scalability curve. Specifically, after a Mapreduce program is written and functioning on 10 nodes, very little-if any- work is required for making that same program run on 1000 nodes 38
39 Comparison With Traditional Models Aspect Shared Memory Message Passing MapReduce Communication Implicit (via loads/stores) Explicit Messages Limited and Implicit Synchronization Explicit Implicit (via messages) Immutable (K, V) Pairs Hardware Support Typically Required None None Development Effort Lower Higher Lowest Tuning Effort Higher Lower Lowest 39
40 Summary of MapReduce MapReduce proven to be useful abstraction Greatly simplifies large-scale computations Fun to use: focus on problem, let library deal w/ messy details 40
41 Pregel: A System for Large-Scale Graph Processing Google was interested in applications that could perform internet-related graph algorithms, such as PageRank, so they designed Pregel to perform these tasks efficiently. It is a scalable, general-purpose system for implementing graph algorithms in a distributed environment. Focus on Thinking Like a Vertex and parallelism Grzegorz Greg Malewicz, et al., Pregel: A System for Large-Scale Graph Processing, in SIGMOD 10 41
42 What is a Graph? A graph is a representation of a set of objects (vertices) where some pairs of objects are connected by links (edges). 42
43 Introduction Many practical applications concern large graphs Large graph data Web graph Transportation routes Citation relationships Social networks Graph Applications PageRank Shortest path Connected components Clustering techniques 43




44 PageRank Depends on rank of who follows her Depends on rank of who follows them What s the rank of this user? Rank? 44
45 Graph Processing Computation is vertex-centric Many iterations Introduction Real world graphs are really large! the World Wide Web has billions of pages with billions of links Facebook s social graph had more than 700 million users and more than 68 billion friendships in 2011 Twitter s social graph has billions of follower relationships 45
46 Why not MapReduce? Map Reduce is ill-suited for graph processing Program model is not intuitive: hard to implement Not design for iterations Unnecessarily slow: each iteration is scheduled as separate MapReduce job with lots of overhead 46
47 Example: SSSP Parallel BFS in MapReduce Example: SSSP Parallel BFS in MapReduce Adjacency matrix Adjacency List A: (B, 10), (D, 5) B: (C, 1), (D, 2) C: (E, 4) A B C D E A 10 5 B 1 2 C 4 D E 7 6 A B 2 3 D C 4 6 E D: (B, 3), (C, 9), (E, 2) E: (A, 7), (C, 6) 47
48 Example: SSSP Parallel BFS in MapReduce Map input: <node ID, <dist, adj list>> <A, <0, <(B, 10), (D, 5)>>> <B, <inf, <(C, 1), (D, 2)>>> <C, <inf, <(E, 4)>>> <D, <inf, <(B, 3), (C, 9), (E, 2)>>> <E, <inf, <(A, 7), (C, 6)>>> Map output: <dest node ID, dist> <B, 10> <D, 5> <C, inf> <D, inf> <E, inf> <B, inf> <C, inf> <E, inf> <A, inf> <C, inf> A B <A, <0, <(B, D 10), (D, 5)>>> <B, <inf, <(C, 1), (D, 2)>>> <C, <inf, <(E, 4)>>> C 4 6 <D, <inf, <(B, 3), (C, 9), (E, 2)>>> <E, <inf, <(A, 7), (C, 6)>>> Flushed to local disk!! E 48
49 Reduce input: <node ID, dist> <A, <0, <(B, 10), (D, 5)>>> <A, inf> B 1 C <B, <inf, <(C, 1), (D, 2)>>> <B, 10> <B, inf> <C, <inf, <(E, 4)>>> <C, inf> <C, inf> <C, inf> A <D, <inf, <(B, 3), (C, 9), (E, 2)>>> <D, 5> <D, inf> D 2 E <E, <inf, <(A, 7), (C, 6)>>> <E, inf> <E, inf> 49
50 Reduce input: <node ID, dist> <A, <0, <(B, 10), (D, 5)>>> <A, inf> B 1 C <B, <inf, <(C, 1), (D, 2)>>> <B, 10> <B, inf> <C, <inf, <(E, 4)>>> <C, inf> <C, inf> <C, inf> A <D, <inf, <(B, 3), (C, 9), (E, 2)>>> <D, 5> <D, inf> D 2 E <E, <inf, <(A, 7), (C, 6)>>> <E, inf> <E, inf> 50
51 Reduce output: <node ID, <dist, adj list>> = Map input for next iteration B <A, <0, <(B, 10), (D, 5)>>> 10 <B, <10, <(C, 1), (D, 2)>>> <C, <inf, <(E, 4)>>> 10 A <D, <5, <(B, 3), (C, 9), (E, 0 2)>>> 2 3 <E, <inf, <(A, 7), (C, 6)>>> Map output: <dest node ID, dist> 5 <B, 10> <D, 5> 5 <C, 11> <D, 12> <E, inf> D <C, <inf, <(E, 4)>>> <B, 8> <C, 14> <E, 7> <A, inf> <C, inf> <A, <0, <(B, 10), (D, 5)>>> 2 <B, <10, <(C, 1), (D, 2)>>> Flushed to DFS!! <D, <5, <(B, 3), (C, 9), (E, 2)>>> C 4 6 <E, <inf, <(A, 7), (C, 6)>>> Flushed to local disk!! E 51
52 Reduce input: <node ID, dist> <A, <0, <(B, 10), (D, 5)>>> <A, inf> B C <B, <10, <(C, 1), (D, 2)>>> <B, 10> <B, 8> A <C, <inf, <(E, 4)>>> <C, 11> <C, 14> <C, inf> <D, <5, <(B, 3), (C, 9), (E, 2)>>> <D, 5> <D, 12> 5 D 2 E <E, <inf, <(A, 7), (C, 6)>>> <E, inf> <E, 7> 52
53 Reduce output: <node ID, <dist, adj list>> = Map input for next iteration B <A, <0, <(B, 10), (D, 5)>>> <B, <8, <(C, 1), (D, 2)>>> <C, <11, <(E, 4)>>> A <D, <5, <(B, 3), (C, 9), (E, 2)>>> 0 <E, <7, <(A, 7), (C, 6)>>> C the rest omitted Flushed to DFS!! 5 D 2 7 E 53
54 Computation Model (1/3) Input Supersteps (a sequence of iterations) Output 54
 Source: http://en.wikipedia.")
55 Computation Model (2/3) Think like a vertex Inspired by Valiant s Bulk Synchronous Parallel model (1990) Source: 55
56 Computation Model (3/3) Superstep: the vertices compute in parallel Each vertex Receives messages sent in the previous superstep Executes the same user-defined function Modifies its value or its outgoing edges Sends messages to other vertices (to be received in the next superstep) Mutates the topology of the graph Votes to halt if it has no further work to do Termination condition All vertices are simultaneously inactive There are no messages in transit 56
57 Example: SSSP Parallel BFS in Pregel
58 Example: SSSP Parallel BFS in Pregel
59 Example: SSSP Parallel BFS in Pregel
60 Example: SSSP Parallel BFS in Pregel
61 Example: SSSP Parallel BFS in Pregel
62 Example: SSSP Parallel BFS in Pregel
63 Example: SSSP Parallel BFS in Pregel
64 Example: SSSP Parallel BFS in Pregel
65 Example: SSSP Parallel BFS in Pregel
66 Differences from MapReduce Graph algorithms can be written as a series of chained MapReduce invocation Pregel Keeps vertices & edges on the machine that performs computation Uses network transfers only for messages MapReduce Passes the entire state of the graph from one stage to the next Needs to coordinate the steps of a chained MapReduce 66
67 System Architecture Pregel system also uses the master/worker model Master Maintains worker Recovers faults of workers Provides Web-UI monitoring tool of job progress Worker Processes its task Communicates with the other workers Persistent data is stored as files on a distributed storage system (such as GFS or BigTable) Temporary data is stored on local disk 67
68 Execution of a Pregel Program 1. Many copies of the program begin executing on a cluster of machines 2. The master assigns a partition of the input to each worker Each worker loads the vertices and marks them as active 3. The master instructs each worker to perform a superstep Each worker loops through its active vertices & computes for each vertex Messages are sent asynchronously, but are delivered before the end of the superstep This step is repeated as long as any vertices are active, or any messages are in transit 4. After the computation halts, the master may instruct each worker to save its portion of the graph 68
69 Checkpointing Fault Tolerance The master periodically instructs the workers to save the state of their partitions to persistent storage e.g., Vertex values, edge values, incoming messages Failure detection Using regular ping messages Recovery The master reassigns graph partitions to the currently available workers The workers all reload their partition state from most recent available checkpoint 69
70 Spark: A Fault-Tolerant Abstraction for In- Memory Cluster Computing The current frameworks are not efficient in two types of applications: Iterative algorithms (e.g. iterative machine learning & graph processing) More interactive ad-hoc queries (ad-hoc query: a user customize defined, specific query ) 70
71 Current framework weakness: MapReduce --- Lack efficient primitives for data sharing (slow): Between two Map-Reduce jobs,all the intermediate data would be written into the external stable storage (after reduce phase) such as GFS/HDFS or local disk (after map phase). (each iteration or interactive query is one MapReduce job). Pregel --- Specific and limited models, not flexible, fault tolerance not efficient : Although it keeps intermediate data in memory, it could only provide the strict BSP computation model, it can t provide more general data reuse abstractions such as let user load several datasets into memory and run arbitrary / ad-hoc queries. 71
72 Examples HDFS read HDFS write HDFS read HDFS write iter. 1 iter Input HDFS read query 1 query 2 result 1 result 2 Input query 3... result 3 Slow due to replication and disk I/O, but necessary for fault tolerance 72
73 Goal: In-Memory Data Sharing Input iter. 1 iter one-time processing query 1 query 2 Input query faster than network/disk, but how to get FT? 73
74 Challenge How to design a distributed memory abstraction that is both fault-tolerant and efficient? 74
75 Solution: Resilient Distributed Datasets (RDDs) Overview RDD is an in-memory abstraction for cluster computing with efficient fault tolerance. It is not a new framework or data work flow. RDD is designed for batch analytics applications rather than asynchronous fine-grained updates shared state applications such as web application storage system. For these system, traditional logging and data checking point such as databases, RAMCloud, Piccolo are more suitable. Simple programming interface: most transformations in Spark less than 20 lines of code. 75
76 Solution: Resilient Distributed Datasets (RDDs) Overview Restricted form of distributed shared memory for efficient fault tolerance. (borrowed from MapReduce, Pregel restricts the programming model for better fault tolerance) Immutable, partitioned collections of records Can only be built through coarse-grained deterministic transformations (map, filter, join, ) to apply the same operation to multiple data items. (like MapReduce --- the same map and reduce function to all of the data sets to achieve good independent task fault tolerance) Efficient fault recovery using lineage Log one operation to apply to many data elements. (lineage) Recompute specific lost partitions on failure of its derived RDDs : do not need to re-execute all the tasks. (like MapReduce fault tolerance) No cost if nothing fails (no needs to replicate data) MapReduce and Dryad s dependency among DAG are lost after each job finishes.(master maintains, and would burden the master s responsibility) 76
77 RDD Recovery iter. 1 iter Input one-time processing query 1 query 2 Input query
78 Another significant advantage: Generality of RDDs The main purpose of RDD is to utilize a new in-memory storage abstraction to re-express all the existing frameworks such as MapReduce, Pregel, Dryad --- The generality character is very important for RDD. Although the coarse-grained transformation seemed restricted, RDD could express many parallel algorithms flexibly because most of the parallel programming model apply the same operation to multiple data items. Unify many current programming models Data flow models: MapReduce, Dryad, SQL, Specialized models for iterative apps: BSP (Pregel), iterative MapReduce (Haloop), bulk incremental, Support new apps that these models don t include. e.g. User could run a MapReduce operation to build a graph and then run Pregel on it by sharing data through RDD. 78
79 RDD implementation --- Spark RDD abstraction Spark programming interface Fault Tolerance Implementation 79
80 RDD Abstraction 1. Immutable --- Read only, owns multiple partitioned collection of records. >> RDD could only be created through deterministic operations(transformations) on either data in stable storage or other RDDs. >> Purposes : a. consistency for Lineage b. straggler mitagation 2. Lineage --- Each RDD has enough information about how it is derived from other data sets to compute its partitions from data in stable storage. 3. Persistence and partitioning --- User could indicate which RDDs they would reuse and store in-memory or disk(not enough memory) in future operation; User could indicate an RDD s element be partitioned across machines based on a key on record (like MapReduce Reduce phase hash function partition). 4. Two types Operations on RDD : Transformation and Action --- >>a. Transformations are a set of specific lazy transformations to create new RDDs. >>b. Action launch a computation on the existing RDDs to return a value result to the program or write to external storage. 80

81 RDD Abstraction Each RDD with a common interface includes the five pieces of information: 1. A set of partitions, which are atomic pieces of dataset. 2. A set of dependencies on parent RDDs. 3. Metadata about its partitioning scheme and data placement. 81
 2. More efficient fault recovery.")
82 RDD Abstraction Narrow dependency: one partition to one partition. Wide dependency: multiple child partitions depend on one parent partition. Narrow dependency advantage: 1. piplined execution. (not like MapReduce wide dependency, there is a barrier between map phase and reduce phase) 2. More efficient fault recovery.(each failed partition only needs one partition re-computed) 82
83 Provides: Spark Programming Interface Resilient distributed datasets (RDDs) Operations on RDDs: transformations (build new RDDs), actions (compute and output results) Control of each RDD s partitioning (layout across nodes) and persistence (storage in RAM, on disk, etc) 83
84 Spark Operations Transformations (define a new RDD) Actions (return a result to driver program) Map : one-to-one mapping. filter sample groupbykey reducebykey sortbykey collect reduce count save lookupkey flatmap: each input value to one or more ouputs (like map in MapReduce) union join cogroup cross mapvalues 84
85 Example: Log Mining Load error messages from a log into memory, then interactively search for various patterns Base lines = spark.textfile( hdfs://... ) Transformed RDD RDD results errors = lines.filter(_.startswith( ERROR )) messages = errors.map(_.split( \t )(2)) tasks Master messages.persist() Worker Block 1 Msgs. 1 messages.filter(_.contains( foo )).count messages.filter(_.contains( bar )).count Result: scaled to 1 TB data in 5-7 Result: full-text search of Wikipedia sec in <1 sec (vs 20 sec for on-disk data) (vs 170 sec for on-disk data) Action Worker Block 3 Msgs. 3 Worker Block 2 Msgs. 2 85
86 Example: PageRank links = // RDD of (url, neighbors) pairs ranks = // RDD of (url, rank) pairs for (i <- 1 to ITERATIONS) { ranks = links.join(ranks).flatmap { (url, (links, rank)) => links.map(dest => (dest, rank/links.size)) }.reducebykey(_ + _) } 1. Start each page with a rank of 1 2. On each iteration, update each page s rank to Σ i neighbors rank i / neighbors i 86
87 Optimizing Placement links & ranks repeatedly joined Links (url, neighbors) Ranks 0 (url, rank) join Contribs 0 reduce Ranks 1 join Can co-partition them (e.g. hash both on URL) to avoid shuffles.(make sure rank partition and link partition at the same machine) --- Partition based on data locality links = links.partitionby( new URLPartitioner()) Contribs 2 reduce Ranks 2... Only needs to replicate some versions of ranks for fault tolerance rather than replicate large data set Links in HDFS like MapReduce 87


88 Time per iteration (s) PageRank Performance Hadoop Basic Spark Spark + Controlled Partitioning 88
89 How to achieve fault tolerance? Efficient Parallel re-compute the lost partition of the RDD. The master node knows the lineage graph and would assign parallel re-computation tasks to other available worker machine. Because for each error data set, we only perform the coarse-fined specific transformation filter and map, then if one partition of the message RDD is lost, spark would rebuild it by applying the map transformation on the corresponding partition of lost. There are only limited number of transformation operation, so spark only needs to log the name of the operation to each RDD, and then could use this information attached with lineage. The immutable character of RDD makes the fault tolerance efficient. Because each RDD is created by coarse-grained transformation, it is not the detail specific operation (Pregel), otherwise we need checking point to record every detail operation for fault tolerance rather than re-computing using lineage. 89
90 How to fault tolerance? The immutable character also makes RDDs could utilize backup tasks to solve the slow node straggler problem like MapReduce. >> DSM like Piccolo could not use backup tasks because the two copies of a task would access the same memory locations and interfere each other s update. RDD could efficiently remember each transformation as one step in a lineage graph and recover lost partitions without having to log large amounts of data. (where the data come from and what coarse-fined operation to these data) 90
).map(_.split( \t )(2)) HadoopRDD FilteredRDD MappedRDD HadoopRDD FilteredRDD MappedRDD path = hdfs:// func = _.contains(...) func = _.")
91 Fault Recovery RDDs track the graph of transformations that built them (their lineage) to rebuild lost data E.g.: messages = textfile(...).filter(_.contains( error )).map(_.split( \t )(2)) HadoopRDD FilteredRDD MappedRDD HadoopRDD FilteredRDD MappedRDD path = hdfs:// func = _.contains(...) func = _.split( ) 91
92 Implementation 1. Developer write a driver program that connects to a cluster of the workers. 2. The driver defines one or more RDDs and invokes actions on them. 3. The spark code on the driver also tracks the RDDs lineage. 4. The workers are long-lived processes that can store RDD partitions in RAM across operations. 5. The worker which runs the driver program is the master of each job, so each job has its own master to avoid MapReduce single master s bottleneck. 6. Data partition for each transformation is defined by a Partitioner class in a hash or range partitioned RDD. (during runtime, input data could also based on data locality) 92
93 Implementation 7. For each worker in same iteration, they would perform the same operation for different data partition (like Map-Reduce). One of RDD design purpose is to perform the same operation for different data partition to solve iteration job. Task Scheduler based on data locality: 1. If a task needs to process a partition that is available in memory on a node, we send it to that node. 2. Otherwise, if a task processes a partition for which the containing RDD provides preferred locations, we send it to those. 93
94 Memory Management 1. RDD Data format: >> In-memory storage as deserialized Java objects --- Fastest performance. (JVM directly access each RDD element natively) >> In-memory storage as serialized data --- Memory-efficient at the cost of lower performance. >> On-disk RDD storage ---- When too large keep in memory. The poorest performance. 2. RDD Data reclaim: >> When user doesn t claim, using LRU eviction if the memory do not have enough space. >> User could claim the persistence priority to each RDD they want to reuse in memory. 3. RDD Data reclaim: Every Spark job has separate memory space. 94
95 Memory Management 4. Task resource management within one node: a. Each task of a job is a thread in one process rather than a process like MapReduce task. (all the tasks of a job would share one executor process) >> Multi-threads within one Java VM could fast launch task rather than MapReduce s weakness: slow task launch(launch a new process: 1 second). >> Multi-threads would shared the memory more sufficiently---important for Spark s in-memory computation whose memory space is critical for the total performance. (multi-process could not share each processor s memory) >> One JVM executor would launch once and used by all the subsequent tasks, not like MapReduce each task would separately apply new resource(process) and release the resource after task finishes : it would reduce the resource request overhead which would significantly reduce the total completion time for the job with a high number of tasks. RDD In-memory computation is mainly designed for lightweight fast data processing, so the completion time is more critical for Spark rather than MapReduce. 95
96 Memory Management 4. Task resource management within one node: b. Disadvantage of Multi-threads in one JVM: >> Multi-threads within one JVM would compete for the resource, so it is hard to scheduler fine-grained resource allocation like MapReduce. MapReduce is designed for batch processing large job, so the resource isolation (multi- process) is critical for large job smooth execution. 96
97 Support for Check-pointing 1. Only be used for long-lineage chains and wide dependencies : Because one partition lost may cause the full re-computation across the whole cluster : not efficiency. 2. Narrow dependency RDD never needs check-pointing: They could be re-computing parallel to recover very efficiently. 3. Spark provides the check-pointing service by letting user define which RDD to check-pointing: In the paper, they mention that they are investing how to perform automatic check-pointing because the scheduler knows the size of each dataset as well as the time it took to first computing it, it should be able to select an optimal set of RDDs to checkpoint. 97
98 Conclusion RDDs offer a simple and efficient programming model for a broad range of applications RDD provides in-memory computing for data reuse application such as iteration algorithm or interactive ad-hoc query. Leverage the coarse-grained nature of many parallel algorithms for low-overhead recovery 98
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing. Lecture 6: MapReduce in Parallel Computing
 ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
ECE5610/CSC6220 Introduction to Parallel and Distribution Computing Lecture 6: MapReduce in Parallel Computing 1 MapReduce: Simplified Data Processing Motivation Large-Scale Data Processing on Large Clusters
Motivation. Map in Lisp (Scheme) Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters
 Map/Reduce. MapReduce: Simplified Data Processing on Large Clusters") Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Motivation MapReduce: Simplified Data Processing on Large Clusters These are slides from Dan Weld s class at U. Washington (who in turn made his slides based on those by Jeff Dean, Sanjay Ghemawat, Google,
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Distributed Computations MapReduce. adapted from Jeff Dean s slides
 Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
Distributed Computations MapReduce adapted from Jeff Dean s slides What we ve learnt so far Basic distributed systems concepts Consistency (sequential, eventual) Fault tolerance (recoverability, availability)
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Pregel: A System for Large-Scale Graph Proces sing
 Pregel: A System for Large-Scale Graph Proces sing Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkwoski Google, Inc. SIGMOD July 20 Taewhi
Pregel: A System for Large-Scale Graph Proces sing Grzegorz Malewicz, Matthew H. Austern, Aart J. C. Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Czajkwoski Google, Inc. SIGMOD July 20 Taewhi
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G.
 Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G. Speaker: Chong Li Department: Applied Health Science Program: Master of Health Informatics 1 Term
Authors: Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, L., Leiser, N., Czjkowski, G. Speaker: Chong Li Department: Applied Health Science Program: Master of Health Informatics 1 Term
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Fault Tolerant Distributed Main Memory Systems
 Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
Fault Tolerant Distributed Main Memory Systems CompSci 590.04 Instructor: Ashwin Machanavajjhala Lecture 16 : 590.04 Fall 15 1 Recap: Map Reduce! map!!,!! list!!!!reduce!!, list(!! )!! Map Phase (per record
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
The MapReduce Abstraction
 The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
The MapReduce Abstraction Parallel Computing at Google Leverages multiple technologies to simplify large-scale parallel computations Proprietary computing clusters Map/Reduce software library Lots of other
Parallel Computing: MapReduce Jin, Hai
 Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Parallel Computing: MapReduce Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology ! MapReduce is a distributed/parallel computing framework introduced by Google
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
PREGEL: A SYSTEM FOR LARGE-SCALE GRAPH PROCESSING
 PREGEL: A SYSTEM FOR LARGE-SCALE GRAPH PROCESSING Grzegorz Malewicz, Matthew Austern, Aart Bik, James Dehnert, Ilan Horn, Naty Leiser, Grzegorz Czajkowski (Google, Inc.) SIGMOD 2010 Presented by : Xiu
PREGEL: A SYSTEM FOR LARGE-SCALE GRAPH PROCESSING Grzegorz Malewicz, Matthew Austern, Aart Bik, James Dehnert, Ilan Horn, Naty Leiser, Grzegorz Czajkowski (Google, Inc.) SIGMOD 2010 Presented by : Xiu
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
CSE Lecture 11: Map/Reduce 7 October Nate Nystrom UTA
 CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
CSE 3302 Lecture 11: Map/Reduce 7 October 2010 Nate Nystrom UTA 378,000 results in 0.17 seconds including images and video communicates with 1000s of machines web server index servers document servers
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark
 Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Utah Distributed Systems Meetup and Reading Group - Map Reduce and Spark JT Olds Space Monkey Vivint R&D January 19 2016 Outline 1 Map Reduce 2 Spark 3 Conclusion? Map Reduce Outline 1 Map Reduce 2 Spark
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
MapReduce: Simplified Data Processing on Large Clusters
 MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
MapReduce: Simplified Data Processing on Large Clusters Jeffrey Dean and Sanjay Ghemawat OSDI 2004 Presented by Zachary Bischof Winter '10 EECS 345 Distributed Systems 1 Motivation Summary Example Implementation
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING
 PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
modern database systems lecture 10 : large-scale graph processing
 modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
Parallel Programming Concepts
 Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Parallel Programming Concepts MapReduce Frank Feinbube Source: MapReduce: Simplied Data Processing on Large Clusters; Dean et. Al. Examples for Parallel Programming Support 2 MapReduce 3 Programming model
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
CS6030 Cloud Computing. Acknowledgements. Today s Topics. Intro to Cloud Computing 10/20/15. Ajay Gupta, WMU-CS. WiSe Lab
 CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
CS6030 Cloud Computing Ajay Gupta B239, CEAS Computer Science Department Western Michigan University ajay.gupta@wmich.edu 276-3104 1 Acknowledgements I have liberally borrowed these slides and material
Google: A Computer Scientist s Playground
 Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Outline Mission, data, and scaling Systems infrastructure Parallel programming model: MapReduce Googles
Google: A Computer Scientist s Playground
 Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
Outline Mission, data, and scaling Google: A Computer Scientist s Playground Jochen Hollmann Google Zürich und Trondheim joho@google.com Systems infrastructure Parallel programming model: MapReduce Googles
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Computing. Leonidas Fegaras University of Texas at Arlington. Web Data Management and XML L12: Cloud Computing 1
 Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L12: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
NDBI040 Big Data Management and NoSQL Databases Lecture 2. MapReduce Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Framework A programming model
Deep Learning Comes of Age. Presenter: 齐琦 海南大学
 Deep Learning Comes of Age Presenter: 齐琦 海南大学 原文引用 Anthes, G. (2013). "Deep learning comes of age." Commun. ACM 56(6): 13-15. AI/Machine learning s new technology deep learning --- multilayer artificial
Deep Learning Comes of Age Presenter: 齐琦 海南大学 原文引用 Anthes, G. (2013). "Deep learning comes of age." Commun. ACM 56(6): 13-15. AI/Machine learning s new technology deep learning --- multilayer artificial
Introduction to MapReduce (cont.)
") Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
Introduction to MapReduce (cont.) Rafael Ferreira da Silva rafsilva@isi.edu http://rafaelsilva.com USC INF 553 Foundations and Applications of Data Mining (Fall 2018) 2 MapReduce: Summary USC INF 553 Foundations
CS 138: Google. CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVII 1 Copyright 2016 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
CS 138: Google. CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved.
 CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
CS 138: Google CS 138 XVI 1 Copyright 2017 Thomas W. Doeppner. All rights reserved. Google Environment Lots (tens of thousands) of computers all more-or-less equal - processor, disk, memory, network interface
6.830 Lecture Spark 11/15/2017
 6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
CS MapReduce. Vitaly Shmatikov
 CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
CS 5450 MapReduce Vitaly Shmatikov BackRub (Google), 1997 slide 2 NEC Earth Simulator, 2002 slide 3 Conventional HPC Machine ucompute nodes High-end processors Lots of RAM unetwork Specialized Very high
Pregel: A System for Large- Scale Graph Processing. Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010
 Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Announcements. Parallel Data Processing in the 20 th Century. Parallel Join Illustration. Introduction to Database Systems CSE 414
 Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to Database Systems CSE 414 Lecture 17: MapReduce and Spark Announcements Midterm this Friday in class! Review session tonight See course website for OHs Includes everything up to Monday s
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/90/104368640.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
CS 555: DISTRIBUTED SYSTEMS [MAPREDUCE] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Bit Torrent What is the right chunk/piece
Spark.jl: Resilient Distributed Datasets in Julia
 Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Spark.jl: Resilient Distributed Datasets in Julia Dennis Wilson, Martín Martínez Rivera, Nicole Power, Tim Mickel [dennisw, martinmr, npower, tmickel]@mit.edu INTRODUCTION 1 Julia is a new high level,
Overview. Why MapReduce? What is MapReduce? The Hadoop Distributed File System Cloudera, Inc.
 MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
MapReduce and HDFS This presentation includes course content University of Washington Redistributed under the Creative Commons Attribution 3.0 license. All other contents: Overview Why MapReduce? What
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Agenda. Request- Level Parallelism. Agenda. Anatomy of a Web Search. Google Query- Serving Architecture 9/20/10
 Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Agenda CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instructors: Randy H. Katz David A. PaHerson hhp://inst.eecs.berkeley.edu/~cs61c/fa10 Request and Data Level Parallelism Administrivia
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Pregel. Ali Shah
 Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Cloud Computing. Leonidas Fegaras University of Texas at Arlington. Web Data Management and XML L3b: Cloud Computing 1
 Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L3b: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
Cloud Computing Leonidas Fegaras University of Texas at Arlington Web Data Management and XML L3b: Cloud Computing 1 Computing as a Utility Cloud computing is a model for enabling convenient, on-demand
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
CS 345A Data Mining. MapReduce
 CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
CS 345A Data Mining MapReduce Single-node architecture CPU Machine Learning, Statistics Memory Classical Data Mining Disk Commodity Clusters Web data sets can be very large Tens to hundreds of terabytes
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Distributed Systems. 21. Graph Computing Frameworks. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
MapReduce. Kiril Valev LMU Kiril Valev (LMU) MapReduce / 35
 MapReduce / 35") MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
MapReduce Kiril Valev LMU valevk@cip.ifi.lmu.de 23.11.2013 Kiril Valev (LMU) MapReduce 23.11.2013 1 / 35 Agenda 1 MapReduce Motivation Definition Example Why MapReduce? Distributed Environment Fault Tolerance
Flat Datacenter Storage. Edmund B. Nightingale, Jeremy Elson, et al. 6.S897
 Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
Flat Datacenter Storage Edmund B. Nightingale, Jeremy Elson, et al. 6.S897 Motivation Imagine a world with flat data storage Simple, Centralized, and easy to program Unfortunately, datacenter networks
The MapReduce Framework
 The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
The MapReduce Framework In Partial fulfilment of the requirements for course CMPT 816 Presented by: Ahmed Abdel Moamen Agents Lab Overview MapReduce was firstly introduced by Google on 2004. MapReduce
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Big Graph Processing. Fenggang Wu Nov. 6, 2016
 Big Graph Processing Fenggang Wu Nov. 6, 2016 Agenda Project Publication Organization Pregel SIGMOD 10 Google PowerGraph OSDI 12 CMU GraphX OSDI 14 UC Berkeley AMPLab PowerLyra EuroSys 15 Shanghai Jiao
Big Graph Processing Fenggang Wu Nov. 6, 2016 Agenda Project Publication Organization Pregel SIGMOD 10 Google PowerGraph OSDI 12 CMU GraphX OSDI 14 UC Berkeley AMPLab PowerLyra EuroSys 15 Shanghai Jiao
COMP Parallel Computing. Lecture 22 November 29, Datacenters and Large Scale Data Processing
 - Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
- Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Part A: MapReduce. Introduction Model Implementation issues
 Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Part A: Massive Parallelism li with MapReduce Introduction Model Implementation issues Acknowledgements Map-Reduce The material is largely based on material from the Stanford cources CS246, CS345A and
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization