NVIDIA Fermi Architecture
|
|
|
- Blaze Pearson
- 5 years ago
- Views:
Transcription
 New GPU Generation What are the technical goals for a new GPU")
1 Administrivia NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS Spring 2011 Assignment 4 grades returned Project checkpoint on Monday Post an update on your blog beforehand Poster session: 04/28 Three weeks from tomorrow G80, GT200, and Fermi November 2006: G80 June 2008: GT200 March 2011: Fermi (GF100) New GPU Generation What are the technical goals for a new GPU generation? 1
2 New GPU Generation What are the technical goals for a new GPU generation? Improve existing application performance. How? New GPU Generation What are the technical goals for a new GPU generation? Improve existing application performance. How? Advance programmability. In what ways? Fermi: What s More? More total cores (SPs) not SMs though More registers: 32K per SM More shared memory: up to 48K per SM More Super Functional Units (SFUs) Fermi: What s Faster? Faster double precision 8x over GT200 Faster atomic operations. What for? 5-20x Faster context switches Between applications 10x Between graphics and compute, e.g., OpenGL and CUDA 2
 memory support")
3 Fermi: What s New? G80, GT200, and Fermi L1 and L2 caches. For compute or graphics? Dual warp scheduling Concurrent kernel execution C++ support Full IEEE support in hardware Unified address space Error Correcting Code (ECC) memory support Fixed function tessellation for graphics G80, GT200, and Fermi GT200 and Fermi 3


4 Fermi Block Diagram GF SMs Each with 32 cores 512 total cores Each SM hosts up to 48 warps, or 1,536 threads In flight, up to 24,576 threads Fermi SM Why 32 cores per SM instead of 8? Why not more SMs? G80 8 cores GT200 8 cores GF cores Fermi SM Dual warp scheduling Why? 32K registers 32 cores Floating point and integer unit per core 16 Load/stores 4 SFUs Fermi SM 16 SMs * 32 cores/sm = 512 floating point operations per cycle Why not in practice? 4


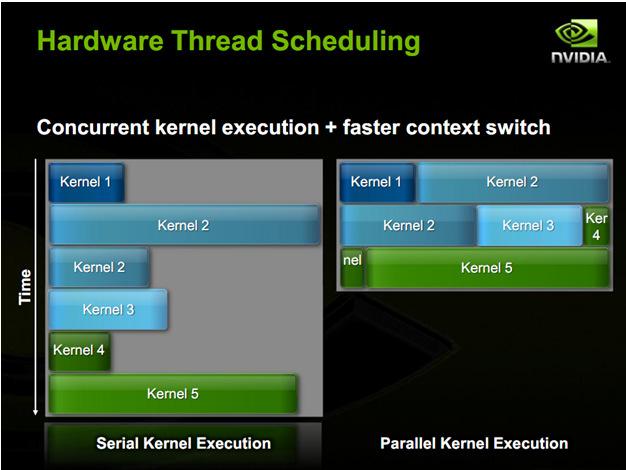
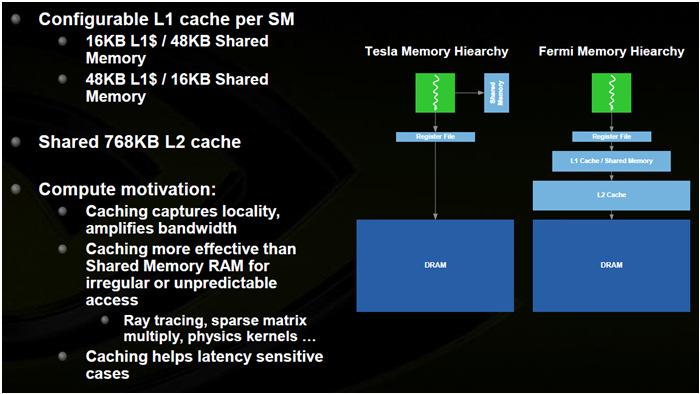
5 Fermi SM Each SM 64KB on-chip memory 48KB shared memory / 16KB L1 cache, or 16KB L1 cache / 48 KB shared memory Configurable by CUDA developer Fermi Dual Warping Scheduling Fermi Caches Slide from: Slide from: 5


6 Fermi Caches Fermi: Unified Address Space Slide from: Fermi: Unified Address Space 64-bit virtual addresses 40-bit physical addresses (currently) CUDA 4: Shared address space with CPU. Why? Fermi: Unified Address Space 64-bit virtual addresses 40-bit physical addresses (currently) CUDA 4: Shared address space with CPU. Why? No explicit CPU/GPU copies Direct GPU-GPU copies Direct I/O device to GPU copies 6



7 Fermi ECC Fermi Tessellation ECC Protected Register file, L1, L2, DRAM Uses redundancy to ensure data integrity against cosmic rays flipping bits For example, 64 bits is stored as 72 bits Fix single bit errors, detect multiple bit errors What are the applications? Fermi Tessellation Fermi Tessellation Fixed function hardware on each SM for graphics Texture filtering Texture cache Tessellation Vertex Fetch / Attribute Setup Stream Output Viewport Transform. Why? 7
8 Observations Becoming easier to port CPU code to the GPU Recursion, fast atomics, L1/L2 caches, faster global memory In fact Observations Becoming easier to port CPU code to the GPU Recursion, fast atomics, L1/L2 caches, faster global memory In fact GPUs are starting to look like CPUs Beefier SMs, L1 and L2 caches, dual warp scheduling, double precision, fast atomics 8
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012
 Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS Spring 2012") CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
CUDA Performance Considerations (2 of 2) Varun Sampath Original Slides by Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Agenda Instruction Optimizations Mixed Instruction Types Loop Unrolling
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CUDA Performance Considerations (2 of 2)
") Administrivia CUDA Performance Considerations (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Friday 03/04, 11:59pm Assignment 4 due Presentation date change due via email Not bonus
Administrivia CUDA Performance Considerations (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Friday 03/04, 11:59pm Assignment 4 due Presentation date change due via email Not bonus
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Tuning CUDA Applications for Fermi. Version 1.2
 Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
GPU Basics. Introduction to GPU. S. Sundar and M. Panchatcharam. GPU Basics. S. Sundar & M. Panchatcharam. Super Computing GPU.
 Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
Basics of s Basics Introduction to Why vs CPU S. Sundar and Computing architecture August 9, 2014 1 / 70 Outline Basics of s Why vs CPU Computing architecture 1 2 3 of s 4 5 Why 6 vs CPU 7 Computing 8
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7.
 1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
CS 179: GPU Programming
 CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
CS 179: GPU Programming Introduction Lecture originally written by Luke Durant, Tamas Szalay, Russell McClellan What We Will Cover Programming GPUs, of course: OpenGL Shader Language (GLSL) Compute Unified
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
GPGPU: Parallel Reduction and Scan
 Administrivia GPGPU: Parallel Reduction and Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 3 due Wednesday 11:59pm on Blackboard Assignment 4 handed out Monday, 02/14 Final Wednesday
Administrivia GPGPU: Parallel Reduction and Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 3 due Wednesday 11:59pm on Blackboard Assignment 4 handed out Monday, 02/14 Final Wednesday
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis
 GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU Programming and Architecture: Course Overview
 Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2012 Monday and Wednesday 9-10:30am Moore 212 Lectures will be recorded Image from http://pinoytutorial.com/techtorial/geforce-gtx-580-vs-amd-radeon-hd-6870-review-and-comparison-conclusion/
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME
 CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects. Werner Nedel, Fernanda Kastensmidt, José.
 Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects Werner Nedel, Fernanda Kastensmidt, José Universidade Federal do Rio Grande do Sul (UFRGS) Rodrigo Azambuja Instituto
Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects Werner Nedel, Fernanda Kastensmidt, José Universidade Federal do Rio Grande do Sul (UFRGS) Rodrigo Azambuja Instituto
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
GPU! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017!
 Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
Advanced Topics on Heterogeneous System Architectures GPU! Politecnico di Milano! Seminar Room, Bld 20! 11 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2 Introduction!
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Lecture 5. Performance programming for stencil methods Vectorization Computing with GPUs
 Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
Lecture 5 Performance programming for stencil methods Vectorization Computing with GPUs Announcements Forge accounts: set up ssh public key, tcsh Turnin was enabled for Programming Lab #1: due at 9pm today,
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
CS516 Programming Languages and Compilers II
 CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
CS516 Programming Languages and Compilers II Zheng Zhang Spring 2015 Jan 22 Overview and GPU Programming I Rutgers University CS516 Course Information Staff Instructor: zheng zhang (eddy.zhengzhang@cs.rutgers.edu)
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Technical Report on IEIIT-CNR
 Technical Report on Architectural Evolution of NVIDIA GPUs for High-Performance Computing (IEIIT-CNR-150212) Angelo Corana (Decision Support Methods and Models Group) IEIIT-CNR Istituto di Elettronica
Technical Report on Architectural Evolution of NVIDIA GPUs for High-Performance Computing (IEIIT-CNR-150212) Angelo Corana (Decision Support Methods and Models Group) IEIIT-CNR Istituto di Elettronica
Introduction to CUDA (2 of 2)
") Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
Announcements Introduction to CUDA (2 of 2) Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Open pull request for Project 0 Project 1 released. Due Sunday 09/30 Not due Tuesday, 09/25 Code
Martin Kruliš, v
 Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example Optimizing Previous Example Alternative Architectures 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator for desktop
Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example Optimizing Previous Example Alternative Architectures 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator for desktop
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Martin Kruliš, v
 Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example (and its Optimization) Alternative Frameworks Most Recent Innovations 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator
Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example (and its Optimization) Alternative Frameworks Most Recent Innovations 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
CS195V Week 9. GPU Architecture and Other Shading Languages
 CS195V Week 9 GPU Architecture and Other Shading Languages GPU Architecture We will do a short overview of GPU hardware and architecture Relatively short journey into hardware, for more in depth information,
CS195V Week 9 GPU Architecture and Other Shading Languages GPU Architecture We will do a short overview of GPU hardware and architecture Relatively short journey into hardware, for more in depth information,
Inside Kepler. Manuel Ujaldon Nvidia CUDA Fellow. Computer Architecture Department University of Malaga (Spain)
") Inside Kepler Manuel Ujaldon Nvidia CUDA Fellow Computer Architecture Department University of Malaga (Spain) Talk outline [46 slides] 1. Introducing the architecture [2] 2. Cores organization [9] 3. Memory
Inside Kepler Manuel Ujaldon Nvidia CUDA Fellow Computer Architecture Department University of Malaga (Spain) Talk outline [46 slides] 1. Introducing the architecture [2] 2. Cores organization [9] 3. Memory
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Sparse Linear Algebra in CUDA
 Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
Sparse Linear Algebra in CUDA HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 22 nd 2017 Table of Contents Homework - Worksheet 2
CUDA Odds and Ends. Administrivia. Administrivia. Agenda. Patrick Cozzi University of Pennsylvania CIS Spring Assignment 5.
 Administrivia CUDA Odds and Ends Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 5 Handed out Wednesday, 03/16 Due Friday, 03/25 Project One page pitch due Sunday, 03/20, at 11:59pm
Administrivia CUDA Odds and Ends Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Assignment 5 Handed out Wednesday, 03/16 Due Friday, 03/25 Project One page pitch due Sunday, 03/20, at 11:59pm
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
POST-SIEVING ON GPUs
 POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
POST-SIEVING ON GPUs Andrea Miele 1, Joppe W Bos 2, Thorsten Kleinjung 1, Arjen K Lenstra 1 1 LACAL, EPFL, Lausanne, Switzerland 2 NXP Semiconductors, Leuven, Belgium 1/18 NUMBER FIELD SIEVE (NFS) Asymptotically
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
GPU Programming and Architecture: Course Overview
 Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Monday and Wednesday 6-7:30pm Moore 212 Lectures are recorded Attendance is required
Lectures GPU Programming and Architecture: Course Overview Patrick Cozzi University of Pennsylvania CIS 565 - Fall 2012 Monday and Wednesday 6-7:30pm Moore 212 Lectures are recorded Attendance is required
GPU Architecture. Michael Doggett Department of Computer Science Lund university
 GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
GPU Architecture Michael Doggett Department of Computer Science Lund university GPUs from my time at ATI R200 Xbox360 GPU R630 R610 R770 Let s start at the beginning... Graphics Hardware before GPUs 1970s
Peter Messmer Developer Technology Group Stan Posey HPC Industry and Applications
 Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
Peter Messmer Developer Technology Group pmessmer@nvidia.com Stan Posey HPC Industry and Applications sposey@nvidia.com U Progress Reported at This Workshop 2011 2012 CAM SE COSMO GEOS 5 CAM SE COSMO GEOS
NVIDIA Parallel Nsight. Jeff Kiel
 NVIDIA Parallel Nsight Jeff Kiel Agenda: NVIDIA Parallel Nsight Programmable GPU Development Presenting Parallel Nsight Demo Questions/Feedback Programmable GPU Development More programmability = more
NVIDIA Parallel Nsight Jeff Kiel Agenda: NVIDIA Parallel Nsight Programmable GPU Development Presenting Parallel Nsight Demo Questions/Feedback Programmable GPU Development More programmability = more
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Challenges for GPU Architecture. Michael Doggett Graphics Architecture Group April 2, 2008
 Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated
Michael Doggett Graphics Architecture Group April 2, 2008 Graphics Processing Unit Architecture CPUs vsgpus AMD s ATI RADEON 2900 Programming Brook+, CAL, ShaderAnalyzer Architecture Challenges Accelerated