The Visual Computing Company
|
|
|
- Claud Merritt
- 6 years ago
- Views:
Transcription


1 The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano
2 Outline General overview about GPU efforts in CAE Computational Structural Mechanics (CSM) ANSYS Mechanical, SIMULIA Abaqus/Standard, MSC Nastran, MSC Marc Computational Fluid Dynamics (CFD) ANSYS Fluent, OpenFOAM (FluiDyna, PARALUTION) Computational Electromagnetics (CEM) CST Studio Suite Conclusion
3 Status Summary of ISVs and GPU Computing Every primary ISV has products available on GPUs or undergoing evaluation The 4 largest ISVs all have products based on GPUs #1 ANSYS, #2 DS SIMULIA, #3 MSC Software, and #4 Altair The top 4 out of 5 ISV applications are available on GPUs today ANSYS Fluent, ANSYS Mechanical, SIMULIA Abaqus/Standard, MSC Nastran, (LS-DYNA implicit only) In addition several other ISV applications are already ported to GPUs AcuSolve, OptiStruct (Altair), NX Nastran (Siemens), Permas (Intes), Fire (AVL), Moldflow(Autodesk), AMLS, FastFRS (CDH),. Several new ISVs were founded with GPUs as a primary competitive strategy Prometech, FluiDyna, Vratis, IMPETUS, Turbostream, Open source CFD OpenFOAM available on GPUs today with many options Commercial options: FluiDyna, Vratis; Open source options: Cufflink, Symscape ofgpu, RAS, etc.

4 GPUs and Distributed Cluster Computing Partition on CPU Geometry decomposed: partitions put on independent cluster nodes; CPU distributed parallel processing Nodes distributed parallel using MPI N1 1 Execution on CPU + GPU N1 N2 N3 N4 G1 G2 G3 G4 GPUs shared memory parallel using OpenMP under distributed parallel Global Solution
 CD-adapco / STAR-CCM+ Autodesk Simulation CFD ESI / CFD-ACE+ SIMULIA / Abaqus/CFD #1 ANSYS / ANSYS Mechanical SIMULIA /")
5 CAE Priority for ISV Software Development on GPUs #4 LSTC / LS-DYNA SIMULIA / Abaqus/Explicit Altair / RADIOSS ESI / PAM-CRASH #2 ANSYS / ANSYS Mechanical Altair / RADIOSS Altair / AcuSolve (CFD) Autodesk / Moldflow #3 ANSYS / ANSYS Fluent OpenFOAM (Various ISVs) CD-adapco / STAR-CCM+ Autodesk Simulation CFD ESI / CFD-ACE+ SIMULIA / Abaqus/CFD #1 ANSYS / ANSYS Mechanical SIMULIA / Abaqus/Standard MSC Software / MSC Nastran MSC Software / Marc LSTC / LS-DYNA implicit Altair / RADIOSS Bulk Siemens / NX Nastran Autodesk / Mechanical
6 Computational Structural Mechanics ANSYS Mechanical

, Single GPU ANSYS")
7 ANSYS and NVIDIA Collaboration Roadmap Release ANSYS Mechanical ANSYS Fluent ANSYS EM 13.0 Dec 2010 SMP, Single GPU, Sparse and PCG/JCG Solvers ANSYS Nexxim 14.0 Dec Distributed ANSYS; + Multi-node Support Radiation Heat Transfer (beta) ANSYS Nexxim 14.5 Nov Multi-GPU Support; + Hybrid PCG; + Kepler GPU Support + Radiation HT; + GPU AMG Solver (beta), Single GPU ANSYS Nexxim 15.0 Dec CUDA 5 Kepler Tuning + Multi-GPU AMG Solver; + CUDA 5 Kepler Tuning ANSYS Nexxim ANSYS HFSS (Transient)

 Simulation productivity (with a HPC Pack) Distributed ANSYS Mechanical 15.")
8 ANSYS Mechanical jobs/day ANSYS Mechanical15.0 on Tesla GPUs 576 K K40 V14sp-5 Model 2.1X 2.2X 324 K K X X Higher is Better Turbine geometry 2,100,000 DOF SOLID187 FEs Static, nonlinear Distributed ANSYS 15.0 Direct sparse solver 2 CPU cores 2 CPU cores + Tesla K20 2 CPU cores 2 CPU cores + Tesla K40 8 CPU cores 7 CPU cores + Tesla K20 8 CPU cores 7 CPU cores + Tesla K40 Simulation productivity (with a HPC license) Simulation productivity (with a HPC Pack) Distributed ANSYS Mechanical 15.0 with Intel Xeon E v2 2.7 GHz CPU; Tesla K20 GPU and a Tesla K40 GPU with boost clocks.
9 Considerations for ANSYS Mechanical on GPUs Problems with high solver workloads benefit the most from GPU Characterized by both high DOF and high factorization requirements Models with solid elements and have >500K DOF experience good speedups Better performance when run on DMP mode over SMP mode GPU and system memories both play important roles in performance Sparse solver: If the model exceeds 5M DOF, then either add another GPU with 5-6 GB of memory (Tesla K20 or K20X) or use a single GPU with 12 GB memory (eg. Tesla K40) PCG/JCG solver: Memory saving (MSAVE) option should be turned off for enabling GPUs Models with lower Level of Difficulty value (Lev_Diff) are better suited for GPUs
10 Computational Structural Mechanics Abaqus/Standard
11 SIMUILA and Abaqus GPU Release Progression Abaqus 6.11, June 2011 Direct sparse solver is accelerated on the GPU Single GPU support; Fermi GPUs (Tesla 20-series, Quadro 6000) Abaqus 6.12, June 2012 Multi-GPU/node; multi-node DMP clusters Flexibility to run jobs on specific GPUs Fermi GPUs + Kepler Hotfix (since November 2012) Abaqus 6.13, June 2013 Un-symmetric sparse solver on GPU Official Kepler support (Tesla K20/K20X/K40)


12 Speed up relative to 8 core (1x) Rolls Royce: Abaqus 3.5x Speedup with 5M DOF Sandy Bridge + Tesla K20X Single Server 4.71M DOF (equations); ~77 TFLOPs Nonlinear Static (6 Steps) Direct Sparse solver, 100GB memory Elapsed Time in seconds Speed up relative to 8 core x x c 8c + 1g 8c + 2g 16c 16c + 2g 1 Server with 2x E5-2670, 2.6GHz CPUs, 128GB memory, 2x Tesla K20X, Linux RHEL 6.2, Abaqus/Standard
; ~77 TFLOPs Nonlinear Static (6 Steps) Direct Sparse solver, 100GB memory 9000 2.2x 6000 3000 2.04X 1.9x 1.8X 1.")
13 Elapsed Time in seconds Rolls Royce: Abaqus Speedups on an HPC Cluster Sandy Bridge + Tesla K20X for 4 x Servers 4.71M DOF (equations); ~77 TFLOPs Nonlinear Static (6 Steps) Direct Sparse solver, 100GB memory x X 1.9x 1.8X 1.8x 0 24c 24c+4g 36c 36c+6g 48c 48c8g 2 Servers 3 Servers 4 Servers Servers with 2x E5-2670, 2.6GHz CPUs, 128GB memory, 2x Tesla K20X, Linux RHEL 6.2, Abaqus/Standard

14 Abaqus/Standard ~15% Gain from K20X to K40 1.7x 2.9x 1.5x 2.5x 1.9x 4.1x 15% av 15% av 2.1x 4.8x

15 Abaqus 6.13-DEV Scaling on Tesla GPU Cluster PSG Cluster: Sandy Bridge CPUs with 2x E (8-core), 2.6 GHz, 128GB memory, 2x Tesla K20X, Linux RHEL 6.2, QDR IB, CUDA 5
16 Abaqus Licensing in a node and across a cluster Cores Tokens GPU Tokens GPU Tokens (1 CPU) (2 CPUs) nodes: 2x 16 cores + 2x 2 GPUs 32 cores: 21 tokens 32 cores + 4 GPUs: 22 tokens 3 nodes: 3x 16 cores + 3x 2 GPUs 48 cores: 25 tokens 48 cores + 6 GPUs: 26 tokens

17 Abaqus 6.12 Power consumption in a node
18 Computational Structural Mechanics MSC Nastran
19 MSC Nastran 2013 Nastran direct equation solver is GPU accelerated Sparse direct factorization (MSCLDL, MSCLU) Real, Complex, Symmetric, Un-symmetric Handles very large fronts with minimal use of pinned host memory Lowest granularity GPU implementation of a sparse direct solver; solves unlimited sparse matrix sizes Impacts several solution sequences: High impact (SOL101, SOL108), Mid (SOL103), Low (SOL111, SOL400) Support of multi-gpu and for Linux and Windows With DMP> 1, multiple fronts are factorized concurrently on multiple GPUs; 1 GPU per matrix domain NVIDIA GPUs include Tesla 20-series, Tesla K20/K20X, Tesla K40, Quadro 6000 CUDA 5 and later 19



20 MSC Nastran 2013 SMP + GPU acceleration of SOL101 and SOL X 4.5 Higher is Better serial 4c 4c+1g 3 2.7X 2.8X 1.5 1X 1X 1.9X Lanczos solver (SOL 103) Sparse matrix factorization 0 SOL101, 2.4M rows, 42K front SOL103, 2.6M rows, 18K front Iterate on a block of vectors (solve) Orthogonalization of vectors Server node: Sandy Bridge E (2.6GHz), Tesla K20X GPU, 128 GB memory
 Direct Sparse solver 600 400 2.7X 200 4.8X 5.2X 5.5X 11.1X 0 serial 1c + 1g 4c (smp) 4c + 1g 8c (dmp=2) 8c + 2g (dmp=2) Server node: Sandy Bridge 2.")
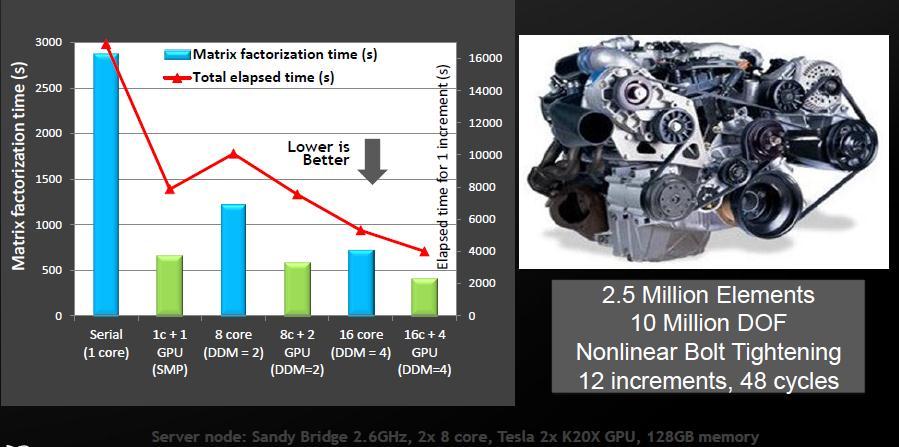
21 Elapsed Time (mins) MSC Nastran 2013 Coupled Structural-Acoustics simulation with SOL X Lower is Better Europe Auto OEM 710K nodes, 3.83M elements 100 frequency increments (FREQ1) Direct Sparse solver X X 5.2X 5.5X 11.1X 0 serial 1c + 1g 4c (smp) 4c + 1g 8c (dmp=2) 8c + 2g (dmp=2) Server node: Sandy Bridge 2.6GHz, 2x 8 core, Tesla 2x K20X GPU, 128GB memory
22 Computational Structural Mechanics MSC MARC
23 MARC 2013
24 Computational Fluid Dynamics ANSYS Fluent
25 ANSYS and NVIDIA Collaboration Roadmap Release ANSYS Mechanical ANSYS Fluent ANSYS EM 13.0 Dec 2010 SMP, Single GPU, Sparse and PCG/JCG Solvers ANSYS Nexxim 14.0 Dec Distributed ANSYS; + Multi-node Support Radiation Heat Transfer (beta) ANSYS Nexxim 14.5 Nov Multi-GPU Support; + Hybrid PCG; + Kepler GPU Support + Radiation HT; + GPU AMG Solver (beta), Single GPU ANSYS Nexxim 15.0 Dec CUDA 5 Kepler Tuning + Multi-GPU AMG Solver; + CUDA 5 Kepler Tuning ANSYS Nexxim ANSYS HFSS (Transient)

26 How to Enable NVIDIA GPUs in ANSYS Fluent Windows: Linux: fluent 3ddp -g -ssh t2 -gpgpu=1 -i journal.jou Cluster specification: nprocs = Total number of fluent processes M = Number of machines ngpgpus = Number of GPUs per machine Requirement 1 nprocs mod M = 0 Same number of solver processes on each machine Requirement 2 nproc M mod ngpgpus = 0 No. of processes should be an integer multiple of GPUs
27 Single-node configurations: Cluster Specification Examples CPU GPU GPU GPU GPU GPU GPU GPU GPU GPU 16 mpi 8 mpi 8 mpi 5 mpi 5 mpi 5 mpi Multi-node configurations: GPU 8 mpi GPU GPU 7 mpi GPU 8 mpi GPU GPU 7 mpi GPU 8 mpi GPU 8 mpi GPU GPU 7 mpi GPU 7 mpi Note: The problem must fit in the GPU memory for the solution to proceed
28 Considerations for ANSYS Fluent on GPUs GPUs accelerate the AMG solver of the CFD analysis Fine meshes and low-dissipation problems have high %AMG Coupled solution scheme spends 65% on average in AMG In many cases, pressure-based coupled solvers offer faster convergence compared to segregated solvers (problem-dependent) The system matrix must fit in the GPU memory For coupled PBNS, each 1 MM cells need about 4 GB of GPU memory High-memory GPUs such as Tesla K40 or Quadro K6000 are ideal Better performance with use of lower CPU core counts A ratio of 4 CPU cores to 1 GPU is recommended
29 NVIDIA-GPU Solution fit for ANSYS Fluent CFD analysis Yes Is it single-phase & flow dominant? No Which solver do you use? Not ideal for GPUs No Pressure based Coupled solver Segregated solver Is it a steady-state analysis? Best-fit for GPUs Yes Consider switching to the pressure-based coupled solver for better performance (faster convergence) and further speedups with GPUs. 29
30 ANSYS Fluent Time (Sec) ANSYS Fluent GPU Performance for Large Cases Better speed-ups on larger and harder-to-solve problems 36 CPU cores 36 CPU cores + 12 GPUs CPU cores 144 CPU cores + 48 GPUs Truck Body Model X 9.5 Lower is Better 2 X 18 External aerodynamics Steady, k-e turbulence Double-precision solver CPU: Intel Xeon E5-2667; 12 cores per node GPU: Tesla K40, 4 per node 14 million cells 111 million cells ANSYS Fluent 15.0 Performance Results by NVIDIA, Dec 2013 NOTE: Reported times are Fluent solution time in second per iteration


31 ANSYS Fluent Time (Sec) GPU Acceleration of Water Jacket Analysis ANSYS Fluent 15.0 performance on pressure-based coupled Solver 6391 Water jacket model x Lower is Better x Unsteady RANS model Fluid: water Internal flow CPU: Intel Xeon E5-2680; 8 cores GPU: 2 X Tesla K CPU only CPU + GPU CPU only AMG solver time CPU + GPU Solution time NOTE: Times for 20 time steps
 15 10 16 16 14 M Mixed cells Steady, k-e turbulence Coupled PBNS, DP Total solution")
32 ANSYS Fluent Number of Jobs Per Day ANSYS Fluent GPU Study on Productivity Gains ANSYS Fluent 15.0 Preview 3 Performance Results by NVIDIA, Sep 2013 Same solution times: 64 cores vs. 32 cores + 8 GPUs Higher is Better Truck Body Model Frees up 32 CPUs and HPC licenses for additional job(s) M Mixed cells Steady, k-e turbulence Coupled PBNS, DP Total solution times CPU: AMG F-cycle Approximate 56% increase in overall productivity for 25% increase in cost Cores 4 x Nodes x 2 CPUs (64 Cores Total) 32 Cores + 8 GPUs 2 x Nodes x 2 CPUs (32 Cores Total) 8 GPUs (4 each Node) GPU: FGMRES with AMG Preconditioner NOTE: All results fully converged


33 ANSYS 15.0 New HPC Licenses for GPUs Treats each GPU socket as a CPU core, which significantly increases simulation productivity of your HPC licenses Needs 1 HPC task to enable a GPU All ANSYS HPC products unlock GPUs in 15.0, including HPC, HPC Pack, HPC Workgroup, and HPC Enterprise products.
34 Computational Fluid Dynamics OpenFOAM
35 NVIDIA GPU Strategy for OpenFOAM Provide technical support for GPU solver developments FluiDyna (implementation of NVIDIA s AMG), Vratis and PARALUTION AMG development by Russian Academy of Science ISP (A. Monakov) Cufflink development by WUSTL now Engys North America (D. Combest) Invest in strategic alliances with OpenFOAM developers ESI and OpenCFD Foundation (H. Weller, M. Salari) Wikki and OpenFOAM-extend community (H. Jasak) Conduct performance studies and customer evaluations Collaborations: developers, customers, OEMs (Dell, SGI, HP, etc.)
36 GPU Acceleration of CFD in Industrial Applications using Culises and aerofluidx GTC 2014 Library Culises Concept and Features Simulation tool e.g. OpenFOAM Culises = Cuda Library for Solving Linear Equation Systems See also State-of-the-art solvers for solution of linear systems Multi-GPU and multi-node capable Single precision or double precision available Krylov subspace methods CG, BiCGStab, GMRES for symmetric /non-symmetric matrices Preconditioning options Jacobi (Diagonal) Incomplete Cholesky (IC) Incomplete LU (ILU) Algebraic Multigrid (AMG), see below Stand-alone Multigrid method Algebraic aggregation and classical coarsening Multitude of smoothers (Jacobi, Gauss-Seidel, ILU etc. ) Flexible interfaces for arbitrary applications e.g.: established coupling with OpenFOAM
 Full availability of existing flow models Easy/no validation needed Unsteady approach better for hybrid due to large")
37 Summary hybrid approach Simulation tool e.g. OpenFOAM Advantage: Universally applicable (coupled to simulation tool of choice) Full availability of existing flow models Easy/no validation needed Unsteady approach better for hybrid due to large linear solver times Disadvantages: Hybrid CPU-GPU produces overhead In case that solution of linear system not dominant Application speedup can be limited GPU Acceleration of CFD in Industrial Applications using Culises and aerofluidx GTC 2014
38 GPU Acceleration of CFD in Industrial Applications using Culises and aerofluidx GTC 2014 aerofluidx an extension of the hybrid approach CPU flow solver e.g. OpenFOAM preprocessing discretization Linear solver postrocessing aerofluidx GPU implementation FV module FV module Culises Culises Porting discretization of equations to GPU discretization module (Finite Volume) running on GPU Possibility of direct coupling to Culises Zero overhead from CPU-GPU-CPU memory transfer and matrix format conversion Solution of momentum equations also beneficial OpenFOAM environment supported Enables plug-in solution for OpenFOAM customers But communication with other input/output file formats possible
39 GPU Acceleration of CFD in Industrial Applications using Culises and aerofluidx GTC 2014 aerofluidx Cavity flow CPU: Intel E (all 8 cores) GPU: Nvidia K40 4M grid cells (unstructured) Running 100 SIMPLE steps with: OpenFOAM (OF) pressure: GAMG Velocitiy: Gauss-Seidel OpenFOAM (OFC) Pressure: Culises AMGPCG (2.4x) Velocity: Gauss-Seidel aerofluidx (AFXC) Pressure: Culises AMGPCG Velocity: Culises Jacobi Total speedup: OF (1x) OFC 1.62x AFXC 2.20x x 1x Normalized computing time 1x 1.96x all assembly all linear solve 2.1x 2.22x OpenFOAM OpenFOAM+Culises aerofluidx+culises all assembly = assembly of all linear systems (pressure and velocity) all linear solve = solution of all linear systems (pressure and velocity)

40 PARALUTION C++ Library to perform various sparse iterative solvers and preconditioner Contains Krylov subspace solvers (CR, CG, BiCGStab, GMRES, IDR), Multigrid (GMG, AMG), Deflated PCG,. Multi/many-core CPU and GPU support Allows seamless integration with other scientific software PARALUTION Library is Open Source released under GPL v3
41 PARALUTION OpenFOAM plugin OpenFOAM Plugin will be released soon
42 Computational Electromagnetics CST Studio Suite



43 CST - Company and Product Overview CST AG is one of the two largest suppliers of 3D EM simulation software. CST STUDIO SUITE is an integrated solution for 3D EM simulations it includes a parametric modeler, more than 20 solvers, and integrated post-processing. Currently, three solvers support GPU Computing. CST COMPUTER SIMULATION TECHNOLOGY


44 New GPU Cards - Quadro K6000/Tesla K40 The Quadro K6000 is the new high-end graphics adapter of the Kepler series whereas the Tesla K40 card is the new high-end computing device. CST STUDIO SUITE 2013 supports both cards for GPU computing with service pack 5. Speedup K20 vs Quadro K6000/Tesla K40 CST COMPUTER SIMULATION TECHNOLOGY -The Quadro K6000/Tesla K40 card is about % faster than the K20 card. -12 GB onboard RAM allows for larger model size.






")

45 Speedup GPU Computing Performance Speedup of Solver Loop CST STUDIO SUITE 2013 CST STUDIO SUITE Number of GPUs (Tesla K40) GPU computing performance has been improved for CST STUDIO SUITE 2014 as CPU and GPU resources are used in parallel. GPU CPU Benchmark performed on system equipped with dual Xeon E v2 (Ivy Bridge EP) processors, and four Tesla K40 cards. Model has 80 million mesh cells. CST COMPUTER SIMULATION TECHNOLOGY
 per Node 10 GPU Hardware Note: A GPU accelerated cluster system requires high-speed network in order to perform well! 5 0 1 1.5 2 2.5 3 3.")
46 Speedup MPI Computing Performance CST STUDIO SUITE offers native support for high speed/low latency networks MPI Cluster System CST STUDIO SUITE Frontend 25 Speedup of Solver Loop CPU 20 2 GPUs (K20) per Node Cluster Interconnect 15 4 GPUs (K20) per Node 10 GPU Hardware Note: A GPU accelerated cluster system requires high-speed network in order to perform well! Number of Cluster Nodes Benchmark Model Features: -Open boundaries -Dispersive and lossy material Base model size is 80 million cells. Problem size is scaled up linearly with the number of cluster nodes (i.e., weak scaling). Hardware: dual Xeon E processors, 128GB RAM per node (1600MHz), Infiniband QDR interconnect (40Gb/s). CST COMPUTER SIMULATION TECHNOLOGY
47 Conclusion GPUs provide significant performance acceleration for solver intensive large jobs Shorter product engineering cycles (Faster Time-to-Market) with improved product quality Cut down energy consumption in the CAE process Better Total Cost of Ownership (TCO) GPUs for 2 nd level parallelism, preserves costly MPI investment GPU acceleration contributing to growth in emerging CAE New ISV developments in particle based CFD (LBM, SPH, etc.) Rapid growth for range of CEM applications and GPU adoption Simulations recently considered intractable are now possible Large Eddy Simulation (LES) with a high degree of arithmetic intensity Parameter optimization with highly increased number of jobs
48 The Visual Computing Company Axel Koehler NVIDIA, the NVIDIA logo, GeForce, Quadro, Tegra, Tesla, GeForce Experience, GRID, GTX, Kepler, ShadowPlay, GameStream, SHIELD, and The Way It s Meant To Be Played are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries. Other company and product names may be trademarks of the respective companies with which they are associated NVIDIA Corporation. All rights reserved.
GPU-Acceleration of CAE Simulations. Bhushan Desam NVIDIA Corporation
 GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation bdesam@nvidia.com 1 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Stan Posey NVIDIA, Santa Clara, CA, USA;
 Stan Posey NVIDIA, Santa Clara, CA, USA; sposey@nvidia.com Agenda: GPU Progress and Directions for CAE Introduction of GPUs in HPC Progress of CFD on GPUs Review of OpenFOAM on GPUs Discussion on WRF Developments
Stan Posey NVIDIA, Santa Clara, CA, USA; sposey@nvidia.com Agenda: GPU Progress and Directions for CAE Introduction of GPUs in HPC Progress of CFD on GPUs Review of OpenFOAM on GPUs Discussion on WRF Developments
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs. Baskar Rajagopalan Accelerated Computing, NVIDIA
 Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA
 Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
The Fermi GPU and HPC Application Breakthroughs
 The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
Why HPC for. ANSYS Mechanical and ANSYS CFD?
 Why HPC for ANSYS Mechanical and ANSYS CFD? 1 HPC Defined High Performance Computing (HPC) at ANSYS: An ongoing effort designed to remove computing limitations from engineers who use computer aided engineering
Why HPC for ANSYS Mechanical and ANSYS CFD? 1 HPC Defined High Performance Computing (HPC) at ANSYS: An ongoing effort designed to remove computing limitations from engineers who use computer aided engineering
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
OpenFOAM + GPGPU. İbrahim Özküçük
 OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
GPU-Accelerated Algebraic Multigrid for Commercial Applications. Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA
 GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
GPU PROGRESS AND DIRECTIONS IN APPLIED CFD
 Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
PARALUTION - a Library for Iterative Sparse Methods on CPU and GPU
 - a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
- a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
Recent Advances in ANSYS Toward RDO Practices Using optislang. Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH
 Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
Understanding Hardware Selection to Speedup Your CFD and FEA Simulations
 Understanding Hardware Selection to Speedup Your CFD and FEA Simulations 1 Agenda Why Talking About Hardware HPC Terminology ANSYS Work-flow Hardware Considerations Additional resources 2 Agenda Why Talking
Understanding Hardware Selection to Speedup Your CFD and FEA Simulations 1 Agenda Why Talking About Hardware HPC Terminology ANSYS Work-flow Hardware Considerations Additional resources 2 Agenda Why Talking
Application of GPU technology to OpenFOAM simulations
 Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, Altair Compute
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Solving Large Complex Problems. Efficient and Smart Solutions for Large Models
 Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
OPENFOAM ON GPUS USING AMGX
 OPENFOAM ON GPUS USING AMGX Thilina Rathnayake Sanath Jayasena Mahinsasa Narayana ABSTRACT Field Operation and Manipulation (OpenFOAM) is a free, open-source, feature-rich Computational Fluid Dynamics
OPENFOAM ON GPUS USING AMGX Thilina Rathnayake Sanath Jayasena Mahinsasa Narayana ABSTRACT Field Operation and Manipulation (OpenFOAM) is a free, open-source, feature-rich Computational Fluid Dynamics
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations
 The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
The Effect of In-Network Computing-Capable Interconnects on the Scalability of CAE Simulations Ophir Maor HPC Advisory Council ophir@hpcadvisorycouncil.com The HPC-AI Advisory Council World-wide HPC non-profit
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
ANSYS High. Computing. User Group CAE Associates
 ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
Dell HPC System for Manufacturing System Architecture and Application Performance
 Dell HPC System for Manufacturing System Architecture and Application Performance This Dell technical white paper describes the architecture of the Dell HPC System for Manufacturing and discusses performance
Dell HPC System for Manufacturing System Architecture and Application Performance This Dell technical white paper describes the architecture of the Dell HPC System for Manufacturing and discusses performance
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup
 The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation
 Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation Andreas Buhr, Alexander Langwost, Fabrizio Zanella CST (Computer Simulation Technology) Abstract Computer Simulation Technology (CST)
Session S0069: GPU Computing Advances in 3D Electromagnetic Simulation Andreas Buhr, Alexander Langwost, Fabrizio Zanella CST (Computer Simulation Technology) Abstract Computer Simulation Technology (CST)
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
FUSION1200 Scalable x86 SMP System
 FUSION1200 Scalable x86 SMP System Introduction Life Sciences Departmental System Manufacturing (CAE) Departmental System Competitive Analysis: IBM x3950 Competitive Analysis: SUN x4600 / SUN x4600 M2
FUSION1200 Scalable x86 SMP System Introduction Life Sciences Departmental System Manufacturing (CAE) Departmental System Competitive Analysis: IBM x3950 Competitive Analysis: SUN x4600 / SUN x4600 M2
MSC Nastran Explicit Nonlinear (SOL 700) on Advanced SGI Architectures
 on Advanced SGI Architectures") MSC Nastran Explicit Nonlinear (SOL 700) on Advanced SGI Architectures Presented By: Dr. Olivier Schreiber, Application Engineering, SGI Walter Schrauwen, Senior Engineer, Finite Element Development, MSC
MSC Nastran Explicit Nonlinear (SOL 700) on Advanced SGI Architectures Presented By: Dr. Olivier Schreiber, Application Engineering, SGI Walter Schrauwen, Senior Engineer, Finite Element Development, MSC
Krishnan Suresh Associate Professor Mechanical Engineering
 Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
WHAT S NEW IN GRID 7.0. Mason Wu, GRID & ProViz Solutions Architect Nov. 2018
 WHAT S NEW IN GRID 7.0 Mason Wu, GRID & ProViz Solutions Architect Nov. 2018 VIRTUAL GPU OCTOBER 2018 (GRID 7.0) Unprecedented Performance & Manageability FPO FPO Multi-vGPU Support World s Most Powerful
WHAT S NEW IN GRID 7.0 Mason Wu, GRID & ProViz Solutions Architect Nov. 2018 VIRTUAL GPU OCTOBER 2018 (GRID 7.0) Unprecedented Performance & Manageability FPO FPO Multi-vGPU Support World s Most Powerful
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
SIDACTGmbH. D ata Analysis and Compression Technologies. femzip: compression of simulation results
 SIDACTGmbH Simulation D D ata Analysis and Compression Technologies femzip: compression of simulation results Compression with FEMZIP FEMZIP tools are specialized for the compression of simulation results.
SIDACTGmbH Simulation D D ata Analysis and Compression Technologies femzip: compression of simulation results Compression with FEMZIP FEMZIP tools are specialized for the compression of simulation results.
Industrial achievements on Blue Waters using CPUs and GPUs
 Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
Industrial finite element analysis: Evolution and current challenges. Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009
 Industrial finite element analysis: Evolution and current challenges Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009 Dr. Chief Numerical Analyst Office of Architecture and
Industrial finite element analysis: Evolution and current challenges Keynote presentation at NAFEMS World Congress Crete, Greece June 16-19, 2009 Dr. Chief Numerical Analyst Office of Architecture and
Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations
 Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Engineers can be significantly more productive when ANSYS Mechanical runs on CPUs with a high core count. Executive Summary
 white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Large-scale Gas Turbine Simulations on GPU clusters
 Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
TFLOP Performance for ANSYS Mechanical
 TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND
 Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Particleworks: Particle-based CAE Software fully ported to GPU
 Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
Scalable x86 SMP Server FUSION1200
 Scalable x86 SMP Server FUSION1200 Challenges Scaling compute-power is either Complex (scale-out / clusters) or Expensive (scale-up / SMP) Scale-out - Clusters Requires advanced IT skills / know-how (high
Scalable x86 SMP Server FUSION1200 Challenges Scaling compute-power is either Complex (scale-out / clusters) or Expensive (scale-up / SMP) Scale-out - Clusters Requires advanced IT skills / know-how (high
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
HPC Considerations for Scalable Multidiscipline CAE Applications on Conventional Linux Platforms. Author: Correspondence: ABSTRACT:
 HPC Considerations for Scalable Multidiscipline CAE Applications on Conventional Linux Platforms Author: Stan Posey Panasas, Inc. Correspondence: Stan Posey Panasas, Inc. Phone +510 608 4383 Email sposey@panasas.com
HPC Considerations for Scalable Multidiscipline CAE Applications on Conventional Linux Platforms Author: Stan Posey Panasas, Inc. Correspondence: Stan Posey Panasas, Inc. Phone +510 608 4383 Email sposey@panasas.com
Second OpenFOAM Workshop: Welcome and Introduction
 Second OpenFOAM Workshop: Welcome and Introduction Hrvoje Jasak h.jasak@wikki.co.uk Wikki Ltd, United Kingdom and FSB, University of Zagreb, Croatia 7-9th June 2007 Second OpenFOAM Workshop:Welcome and
Second OpenFOAM Workshop: Welcome and Introduction Hrvoje Jasak h.jasak@wikki.co.uk Wikki Ltd, United Kingdom and FSB, University of Zagreb, Croatia 7-9th June 2007 Second OpenFOAM Workshop:Welcome and
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI
 FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI MpCCI 4.5.2 Release Notes MpCCI 4.5.2 GUI Improve the start and error management of simulation codes in MpCCI GUI. Enhanced rules lists
FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI MpCCI 4.5.2 Release Notes MpCCI 4.5.2 GUI Improve the start and error management of simulation codes in MpCCI GUI. Enhanced rules lists
New Technologies in CST STUDIO SUITE CST COMPUTER SIMULATION TECHNOLOGY
 New Technologies in CST STUDIO SUITE 2016 Outline Design Tools & Modeling Antenna Magus Filter Designer 2D/3D Modeling 3D EM Solver Technology Cable / Circuit / PCB Systems Multiphysics CST Design Tools
New Technologies in CST STUDIO SUITE 2016 Outline Design Tools & Modeling Antenna Magus Filter Designer 2D/3D Modeling 3D EM Solver Technology Cable / Circuit / PCB Systems Multiphysics CST Design Tools
Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering
 State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
IBM Information Technology Guide For ANSYS Fluent Customers
 IBM ISV & Developer Relations Manufacturing IBM Information Technology Guide For ANSYS Fluent Customers A collaborative effort between ANSYS and IBM 2 IBM Information Technology Guide For ANSYS Fluent
IBM ISV & Developer Relations Manufacturing IBM Information Technology Guide For ANSYS Fluent Customers A collaborative effort between ANSYS and IBM 2 IBM Information Technology Guide For ANSYS Fluent
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
FOR P3: A monolithic multigrid FEM solver for fluid structure interaction
 FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance
 11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
11 th International LS-DYNA Users Conference Computing Technology LS-DYNA Best-Practices: Networking, MPI and Parallel File System Effect on LS-DYNA Performance Gilad Shainer 1, Tong Liu 2, Jeff Layton
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans
 Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans Introduction Company STAR-CCM+ Agenda Wind engineering at CD-adapco STAR-CCM+ & EnviroWizard Developments for Offshore Simulation CD-adapco:
Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans Introduction Company STAR-CCM+ Agenda Wind engineering at CD-adapco STAR-CCM+ & EnviroWizard Developments for Offshore Simulation CD-adapco:
LAMMPSCUDA GPU Performance. April 2011
 LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
LAMMPSCUDA GPU Performance April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Intel, Mellanox Compute resource - HPC Advisory Council
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
OpenFOAM on GPUs. 3rd Northern germany OpenFoam User meeting. Institute of Scientific Computing. September 24th 2015
 OpenFOAM on GPUs 3rd Northern germany OpenFoam User meeting September 24th 2015 Haus der Wissenschaften, Braunschweig Overview HPC on GPGPUs OpenFOAM on GPUs 2013 OpenFOAM on GPUs 2015 BiCGstab/IDR(s)
OpenFOAM on GPUs 3rd Northern germany OpenFoam User meeting September 24th 2015 Haus der Wissenschaften, Braunschweig Overview HPC on GPGPUs OpenFOAM on GPUs 2013 OpenFOAM on GPUs 2015 BiCGstab/IDR(s)
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project
 Workshop HPC enabling of OpenFOAM for CFD applications Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project A. De Maio (1), V. Krastev (2), P. Lanucara (3),
Workshop HPC enabling of OpenFOAM for CFD applications Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project A. De Maio (1), V. Krastev (2), P. Lanucara (3),
GPU Cluster Computing for FEM
 GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU-based Parallel Reservoir Simulators
 GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
"The real world is nonlinear"... 7 main Advantages using Abaqus
 "The real world is nonlinear"... 7 main Advantages using Abaqus FEA SERVICES LLC 6000 FAIRVIEW ROAD, SUITE 1200 CHARLOTTE, NC 28210 704.552.3841 WWW.FEASERVICES.NET AN OFFICIAL DASSAULT SYSTÈMES VALUE
"The real world is nonlinear"... 7 main Advantages using Abaqus FEA SERVICES LLC 6000 FAIRVIEW ROAD, SUITE 1200 CHARLOTTE, NC 28210 704.552.3841 WWW.FEASERVICES.NET AN OFFICIAL DASSAULT SYSTÈMES VALUE
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
OzenCloud Case Studies
 OzenCloud Case Studies Case Studies, April 20, 2015 ANSYS in the Cloud Case Studies: Aerodynamics & fluttering study on an aircraft wing using fluid structure interaction 1 Powered by UberCloud http://www.theubercloud.com
OzenCloud Case Studies Case Studies, April 20, 2015 ANSYS in the Cloud Case Studies: Aerodynamics & fluttering study on an aircraft wing using fluid structure interaction 1 Powered by UberCloud http://www.theubercloud.com
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids
 A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
Fast Setup and Integration of Abaqus on HPC Linux Cluster and the Study of Its Scalability
 Fast Setup and Integration of Abaqus on HPC Linux Cluster and the Study of Its Scalability Betty Huang, Jeff Williams, Richard Xu Baker Hughes Incorporated Abstract: High-performance computing (HPC), the
Fast Setup and Integration of Abaqus on HPC Linux Cluster and the Study of Its Scalability Betty Huang, Jeff Williams, Richard Xu Baker Hughes Incorporated Abstract: High-performance computing (HPC), the
Altair RADIOSS Performance Benchmark and Profiling. May 2013
 Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Iterative Sparse Triangular Solves for Preconditioning
 Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
Euro-Par 2015, Vienna Aug 24-28, 2015 Iterative Sparse Triangular Solves for Preconditioning Hartwig Anzt, Edmond Chow and Jack Dongarra Incomplete Factorization Preconditioning Incomplete LU factorizations
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
GPU ACCELERATED COMPUTING. 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation
 GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
GPU ACCELERATED COMPUTING 1 st AlsaCalcul GPU Challenge, 14-Jun-2016, Strasbourg Frédéric Parienté, Tesla Accelerated Computing, NVIDIA Corporation GAMING PRO ENTERPRISE VISUALIZATION DATA CENTER AUTO
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC
 Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma