GPU-Acceleration of CAE Simulations. Bhushan Desam NVIDIA Corporation
|
|
|
- Shanon Cunningham
- 5 years ago
- Views:
Transcription

1 GPU-Acceleration of CAE Simulations Bhushan Desam NVIDIA Corporation 1
2 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 2



3 NVIDIA Enterprise Group Visualization, Accelerated Computing & Virtualization QUADRO Revolutionizing Design & Visualization TESLA Accelerating Momentum in HPC and Big Data Analytics GRID Enabling End-to-End Enterprise Virtualization 3

4 TESLA Accelerating Computing GPUs enable tremendous breakthroughs by simply enabling us to do more, faster ANSYS, SIMULIA, and other major ISVs leverage GPUs to accelerate engineering simulation for better design The world s top10 energyefficient supercomputers use NVIDIA GPUs according to TheGreen500 list 4
5 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 5
6 Business Challenges in Product Development Improve productquality Faster time-tomarket Manage Product Complexity Simulation is playing an important role in meeting these challenges, thus add value to many product development companies 6
7 Changing Role of Simulation in Product Development From insight to product innovation Design variable 2 Final design concept E E E S E E S S E E S E S S Experience envelope E Experiment S Simulation Design variable 2 Final design concept S S S S S S E S S S S S S S S S S E E S S S S S S S Experience envelope S S S S S S S Innovation envelope Design variable 1 Building insight Design variable 1 Simulation-driven product innovation 7

8 Computing Capacity is Still a Major Challenge Frequency of limiting size/detail in simulation models due to compute infrastructure or turnaround time limitations Almost never 9% Nearly every model 34% For some models 57% Source: Survey by ANSYS with over 1,800 respondents 8
9 Increasing GPU Performance & Memory Bandwidth Peak Double Precision FP Peak Memory Bandwidth GFLOPS GB/s Kepler Kepler M1060 Nehalem 3 GHz Fermi M2070 Westmere 3 GHz Fermi+ M core Sandy Bridge 3 GHz M1060 Nehalem 3 GHz Fermi M2070 Westmere 3 GHz Fermi+ M core Sandy Bridge 3 GHz Double Precision: NVIDIA GPU Double Precision: x86 CPU NVIDIA GPU (ECC off) x86 CPU 9
10 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 10


11 Basics of GPU Computing GPU is an accelerator attached to an x86 CPU GPU acceleration is user-transparent Jobs launch and complete without additional user steps Schematic of a CPU with an attached GPU accelerator CPU begins/ends job, GPU manages heavy computations CPU I/O Hub Cache 1 4 DDR DDR PCI-Express 3 2 GDDR GDDR GPU Schematic of an x86 CPU with a GPU accelerator 1. Job launched on CPU 2. Solver operations sent to GPU 3. GPU sends results back to CPU 4. Job completes on CPU 11


12 GPU Acceleration of a CAE Application CAE Application Software Read input, matrix Set-up GPU Implicit Sparse Matrix Operations - Hand-CUDA Parallel 40% - 75% of Profile time, Small % LoC Implicit Sparse Matrix Operations CPU -GPU Libraries, CUBLAS -OpenACCDirectives Global solution, write output (Investigating OpenACC for more tasks on GPU) + 12
13 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 13

14 GPU-accelerated CFD Applications 14



15 ANSYS Fluent
16 GPU Acceleration in Fluent 15.0 Fluent solution time 30-40% Non- AMG 60-70% AMG GPU CPU In flow problems, pressure-based coupled solver typically spends 60-70% time in AMG where as segregated solver only spends 30-40% of the time in AMG Higher AMG times are ideal for GPU acceleration, thus coupled-problems benefit from GPUs 16
17 Fluent Speed-up from GPU acceleration 3.0 Coupled solver Speed-up factor in Fluent Segregated solver AMG speed-up on GPU Linear solver fraction 17
18 ANSYS 15.0 HPC licenses (new) Treats each GPU socket as a CPU core, which significantly increases simulation productivity from HPC licenses All ANSYS HPC products unlock GPUs in 15.0, including HPC, HPC Pack, HPC Workgroup, and HPC Enterprise products. License type ANSYS 14.5 ANSYS 15.0 HPC per core licenses None 1 HPC license 1 GPU 2 HPC licenses 2 GPUs N HPC licenses N GPUs HPC pack GPU support in ANSYS Licensing comparison 1 HPC pack 1 GPU 2 HPC packs 4 GPUs 1 HPC pack 4 GPUs 2 HPC packs 16 GPUs 18

19 GPU Acceleration of Water Jacket Analysis ANSYS Fluent 15.0 performance on pressure-based coupled Solver 6391 ANSYS Fluent Time (Sec) x 775 AMG solver time Lower is Better CPU only CPU + GPU CPU only 2.5x 2520 CPU + GPU Solution time Water jacket model Unsteady RANS model Fluid: water Internal flow CPU: Intel Xeon E5 2680; 8 cores GPU: 2 X Tesla K40 NOTE: Times for 20 time steps 19

20 GPU value proposition for Fluent secs/iter Formula 1 aerodynamic study (144 million cells) 2.1x 12 secs/iter Additional cost of adding GPUs and HPC licenses 55% 110% Additional productivity from GPUs CPU only 160 cores CPU + GPU 32 X K40 Lower is Better All results are based on turbulent flow over an F1 case (144million cells) over 1000 iterations; steady-state, pressure-based coupled solver with single-precision; CPU: 8 Ivy Bridge nodes with 20 cores each, F-cycle, size 8; GPU: 32 X Tesla K40, V-cycle, and size 2. 2X Additional productivity from HPC licenses and GPUs CPU-only solution cost 100% Cost CPU 100% Benefit GPU Simulation productivity from CPU-only system CPU-only solution cost is approximated and includes both hardware and paid-up software license costs. Benefit/productivity is based on the number of completed Fluent jobs/day. 20
21 GPU Scaling in Fluent 15.0 (F1 case) 33 secs/iter 1.9x 17 secs/iter 25 secs/iter 2.1x 12 secs/iter Lower is Better 21 secs/iter 1.8x 12 secs/iter CPU only 120 cores CPU + GPU 24 X K40 CPU only 160 cores CPU + GPU 32 X K40 CPU only 180 cores CPU + GPU 30 X K40 CPU:GPU=5 CPU:GPU=5 CPU:GPU=6 All results are based on turbulent flow over an F1 case (144million cells) over 1000 iterations; steady-state, pressure-based coupled solver with single-precision; CPU: Ivy Bridge with 10 cores per socket, F-cycle, size 8; GPU: Tesla K40, V-cycle, and size 2. 21
 and hardware (NVIDIA GPU) as soon as possible.")
22 Shorter Time to Solution with GPUs at PSI Inc. A customer success story Objective Meeting engineering services schedule & budget, and technical excellence are imperative for success. HPC Solution PSI evaluates and implements the new technology in software (ANSYS 15.0) and hardware (NVIDIA GPU) as soon as possible. GPU produces a 43% reduction in Fluent solution time on an Intel Xeon E (8 core, 64GB) workstation equipped with an NVIDIA K40 GPU Design Impact Increased simulation throughput allows meeting deliverytime requirements for engineering services. Images courtesy of Parametric Solutions, Inc. 22

23 ANSYS Fluent 15.0 Resources ANSYS solution web page at NVIDIA GPU user guide for ANSYS Fluent 15.0 available at - Accelerating+ANSYS+Fluent+15.0+Using+NVIDIA+GPUs Previously recorded ANSYS IT webcast series webinar titled How to Speed Up ANSYS 15.0 with NVIDIA GPUs, which is available at 23


24 GPU Acceleration of Computational Fluid Dynamics (CFD) in Industrial Applications using Culises and aerofluidx

25 Slide 25 Library Culises Concept and Features Simulation tool e.g. OpenFOAM Culises = Cuda Library for Solving Linear Equation Systems See also State of the art solvers for solution of linear systems Multi GPU and multi node capable Single precision or double precision available Krylov subspace methods CG, BiCGStab, GMRES for symmetric /non symmetric matrices Preconditioning options Jacobi (Diagonal) Incomplete Cholesky (IC) Incomplete LU (ILU) Algebraic Multigrid (AMG), see below Stand alone multigrid method Algebraic aggregation and classical coarsening Multitude of smoothers (Jacobi, Gauss Seidel, ILU etc. ) Flexible interfaces for arbitrary applications e.g.: established coupling with OpenFOAM
26 Slide 26 Culises: Auto OEM Model Multi GPU runs Automotive industrial setup (Japanese OEM) CPU linear solver for pressure: geometric algebraic multigrid (GAMG) of OpenFoam GPU linear solver for pressure: AMG preconditioned CG (AMGPCG) of Culises 200 SIMPLE iterations Grid Cells CPU cores Intel E GPUs Nvidia K40 Linear solve time [s] Total simulation time [s] Speedup linear solver Speedup total simulation 18M M M M M

27 Slide 27 Culises Potential speedup for hybrid approach total speedup s. : Limited speedup 2 acceleration of linear solver on GPU:, = 1.0 = 2.5, = 1.0 a :Speedup linear solver a : Speedup matrix assembly fraction f = f: Solve linear system CPU time spent in linear solver total CPU time 1 f: Assembly of linear system f(steady state run) << f(transient run)
28 Slide 28 aerofluidx an extension of the hybrid approach CPU flow solver e.g. OpenFOAM preprocessing discretization Linear solver postrocessing aerofluidx GPU implementation FV module FV module Culises Culises Porting discretization of equations to GPU discretization module (Finite Volume) running on GPU Possibility of direct coupling to Culises Zero overhead from CPU GPU CPU memory transfer and matrix format conversion Solution of momentum equations also beneficial OpenFOAM environment supported Enables plug in solution for OpenFOAM customers But communication with other input/output file formats possible
29 Slide 29 aerofluidx NACA0012 airfoil flow CPU: Intel E (all 8 cores) GPU: Nvidia K40 4M grid cells (unstructured) Running 100 SIMPLE steps with: OpenFOAM (OF) pressure: GAMG Velocitiy: Gauss Seidel OpenFOAM (OFC) Pressure: Culises AMGPCG (1.5x) Velocity: Gauss Seidel aerofluidx (AFXC) Pressure: Culises AMGPCG Velocity: Culises Jacobi Total speedup: OF (1x) OFC 1.22x AFXC 1.82x x 1x Normalized computing time 1x 1.35x all assembly all linear solve 2.23x 1.71x OpenFOAM OpenFOAM+Culises aerofluidx+culises all assembly = assembly of all linear systems (pressure and velocity) all linear solve = solution of all linear systems (pressure and velocity)
 k omega (SST) Spalart Allmaras Multi GPU Single node Multi node Unsteady flow Advanced turbulence modelling (LES/DES)")
30 aerofluidx Release Planning fv0.98 fv1.0 fv1.2 fv2.0 Steady state laminar flow Single GPU Speedup* > 2x Turbulent flow (RANS) k omega (SST) Spalart Allmaras Multi GPU Single node Multi node Unsteady flow Advanced turbulence modelling (LES/DES) Speedup* 2 3x Basic support for moving geometries (MRF) Porous media Advanced model for rotating devices (sliding mesh approach) aerofluidx V1.0 * Speedup against standard OpenFoam
31 Slide 31 Summary Culises hybrid approach for accelerated CFD applications (OpenFOAM) General applicability for industrial cases including various existing flow models Significant speedup ( 2x) of linear solver employing GPUs Moderate speedup ( 1.6x) of total simulation Culises V1.1 released: Commercial and academic licensing available Free testing & benchmarking opportunities at FluiDyna GPU servers aerofluidx fully ported flow solver on GPU to harvest full GPU computing power General applicability requires rewrite of large portion of existing code Steady state, incompressible unstructured multigrid flow solver established & validated Significant speedup ( 2x) of matrix assembly; without full code tuning/optimization! Enhanced speedup for total simulation
32 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 32
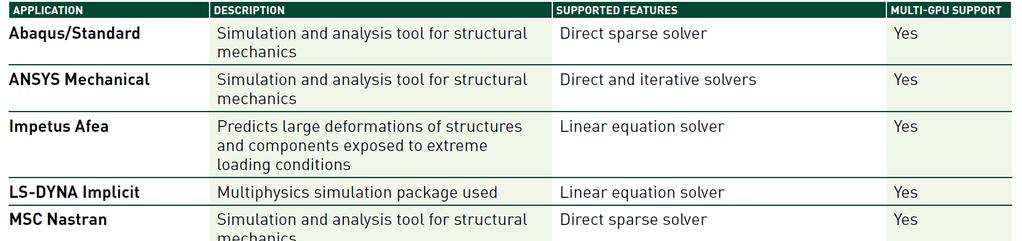

33 GPU-accelerated CSM Applications 33


34 ANSYS Mechanical

35 GPU Acceleration in Mechanical 15.0 Source: Accelerating Mechanical Solutions with GPUs by Sheldon Imaka, ANSYS Advantage Volume VII, Issue 3,



 8-core CPU and a Tesla K40 GPU with boost")
36 ANSYS Mechanical15.0 on Tesla K40 V14sp 5 Model ANSYS Mechanical jobs/day 3.8X Higher is Better 2.5X Turbine geometry 2,100,000 DOF SOLID187 FEs Static, nonlinear Distributed ANSYS 15.0 Direct sparse solver Distributed ANSYS Mechanical 15.0 with Sandy Bridge (Xeon E5-2687W 3.1 GHz) 8-core CPU and a Tesla K40 GPU with boost clocks; V145sp-5 model, Turbine geometry, 2.5 M DOF, and direct sparse solver. 36
37 GPU value proposition for Mechanical15.0 With one HPC license + Tesla K20 V14sp 6 Model ANSYS Mechanical jobs/day X CPU cores 2 CPU cores + Tesla K20 Simulation productivity Higher is Better V14sp-6 benchmark, 4.9 M DOF, static non-linear analysis; direct sparse solver, distributed ANSYS Mechanical 15.0 with Intel Xeon E v2 2.7 GHz CPU; Tesla K20 GPU. 7X Additional productivity from a GPU and one HPC license Additional cost of adding a GPU + HPC license CPU-only solution cost 25% 100% Cost CPU 180% 100% Benefit GPU Additional productivity from GPU Simulation productivity from CPU-only system CPU-only solution cost is approximated and includes both hardware and software license costs. Benefit is based on the number of completed Mechanical jobs/day. 37


38 GPU value proposition for Mechanical15.0 With an HPC pack + Tesla K20 ANSYS Mechanical jobs/day X CPU cores 7 CPU cores + Tesla K20 Simulation productivity Higher is Better V14sp-6 benchmark, 4.9 M DOF, static non-linear analysis; direct sparse solver, distributed ANSYS Mechanical 15.0 with Intel Xeon E v2 2.7 GHz CPU; Tesla K20 GPU. V14sp 6 Model 4X Additional productivity from a GPU and HPC pack CPU-only solution cost Additional cost of adding a GPU 12% 100% Cost CPU 50% 100% Benefit GPU Additional productivity from GPU Simulation productivity from CPU-only system CPU-only solution cost is approximated and includes both hardware and software license costs. Benefit is based on the number of completed Mechanical jobs/day. 38
 64 GB Ram NVIDIA C2075 GPU Solution")

39 ANSYS Mechanical 15.0 Success Story: PSI Inc. ANSYS V Windows 7 Pro SP1 5.8 Million DOF 8 Cores (Xeon E5-2687) 64 GB Ram NVIDIA C2075 GPU Solution Time : CPU-only: ~ 4 hours With GPU: ~ 2 hours Images courtesy of Parametric Solutions, Inc. GPU Produces a 50% Reduction in Solution Time 39
40 ANSYS Mechanical 15.0 Resources ANSYS solution web page at NVIDIA ANSYS Advantage magazine article titled Accelerating Mechanical Solutions with GPUs for download at Previously recorded ANSYS IT webcast series webinar titled How to Speed Up ANSYS 15.0 with NVIDIA GPUs, which is available at ANSYS ADVANTAGE Volume VII Issue


41 SIMULIA Abaqus with NVIDIA GPUs 41
42 Abaqus/Standard GPU Computing Abaqus 6.11, June 2011 Direct sparse solver is accelerated on single GPU Abaqus 6.12, June 2012 Multi-GPU/node; multi-node DMP clusters Abaqus 6.13, June 2013 Un-symmetric sparse solver on GPU Official Kepler (Tesla K20/K20X) support Abaqus 6.14, July 2014* Direct Sparse Solver Relaxation of memory requirements for GPU Improved performance / DMP split AMS Eigensolver GPUs used in the AMS reduced eigen solution phase. Note: Relevant only for models with ~10,000 or more modes AMS AMS Reduction Phase - Reduce the structure onto substructure modal subspaces AMS Reduced Eigensolution Phase - Compute reduced eigenmodes AMS Recovery Phase - Recover full/partial eigenmodes 42
 2 DMP Split (16 cores) Large Model (~77 TFLOPs), 4.71M DOF, Nonlinear Static, Direct Sparse Solver Abaqus 6.14-PR2 with Intel Xeon E5-2690v2, 3.")
43 Abaqus Performance with GPU Customer: Rolls Royce 5.1 UP TO 3.3X FASTER WITH NVIDIA GPU Elapsed Time (hr) 3.3X X Lower is Better DMP (8 cores) 2 DMP Split (16 cores) Large Model (~77 TFLOPs), 4.71M DOF, Nonlinear Static, Direct Sparse Solver Abaqus 6.14-PR2 with Intel Xeon E5-2690v2, 3.0 GHz CPU, 128 GB memory; Tesla K20x GPU 43

44 Abaqus Performance with GPU Customer: Rolls Royce Lower is Better Elapsed Time (hr) 2.4X 1.0 Additional cost of adding GPUs and HPC licenses 15% 140% Additional productivity from GPUs 9X CPU-only solution cost 100% 100% Simulation productivity from CPU-only system 20 CPU Cores 20 CPU Cores + CPU Only 2x CPU Tesla + K20X GPU 20 cores 2x K20X Additional productivity/$ spent on GPUs Large Model (~77 TFLOPs), 4.71M DOF, Nonlinear Static, Direct Sparse Solver, 2 DMP - Split Abaqus 6.14-PR2 with Intel Xeon E5-2690v2, 3.0 GHz CPU, 128 GB memory; Tesla K20X Cost CPU Benefit GPU CPU-only solution cost is approximated and includes both hardware and paid-up software license costs. Benefit/productivity is based on the number of completed Abaqus jobs/day. 44
 2 Nvidia K20m GPUs per compute node 128 Gb memory per compute node 0.50 0.00 43.6Tflops 68.1 Tflops 88.")
45 Symmetric Solver Speed-up with DMP Split 6.13 DMP 6.14 DMP Split Speedup Factor (relative to 32 core without GPU) x x 2.15x x x 2 HP SL250, 2 Intel E cpus (32 cores) 2 Nvidia K20m GPUs per compute node 128 Gb memory per compute node Tflops 68.1 Tflops 88.7 Tflops 155 Tflops 175 Tflops Direct Solver Floating Point Operations 45

46 Customer-confidential Auto model Up to 50% time savings! Time, sec x 1.74x x Std no GPU Std GPU Std Speedup Fct Speedup In addition to time saving, there is license cost advantage of running on 2 nodes with GPUs compared to 3 and 4 nodes without GPUs. 0 2 nodes 3 nodes 4 nodes MPI processes per compute node 11M DOF on Sandybridge (16 cores+256 GB) and two K20 cards Accelerated DMP execution mode (an optional feature in 6.14) 46
47 MSc Nastran with NVIDIA GPUs 47
48 MSC Nastran GPU Computing MSC Nastran direct equation solver is GPU accelerated Sparse direct factorization (MSCLDL, MSCLU) Handles very large fronts Impacts several solutions High (SOL101 Static Stress, SOL108 Direct Freq Response) Medium (SOL103 Modal Analysis) Low (SOL111 Modal Freq Response, SOL400 NL Static & Dynamic) Support of NVIDIA multi-gpus Tesla K20/K20X, Tesla K40, Quadro K6000 (compute & pre/post), Tesla 20-series GPU Licensing Separate license feature supports unlimited GPU cores 48 48
49 MSC Nastran GPU Computing Timeline MSC Nastran , 2H 2011 Real & symmetric sparse direct solver is accelerated on the GPU MSC Nastran 2012.x, 2012 Complex & unsymmetric sparse direct solver is accelerated on the GPU MSC Nastran 2013 & , 2013 Vastly reduced use of pinned host memory Ability to handle arbitrarily large fronts, for very large models (> 15M DOF) on a single GPU with 6GB device memory 49

50 MSC Nastran SMP SOL101 and SOL % time savings! x Higher is Better x 1.68x Hollow Sphere Sol101 Eser Sol101 xx0kst0 Sol103 piston 4 cpu 4cpu + k20x Turbine Blade Piston Server node: Ivy Bridge E5-2697v2 (2.7GHz), Tesla K20X GPU, 128 GB memory 50
51 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 51

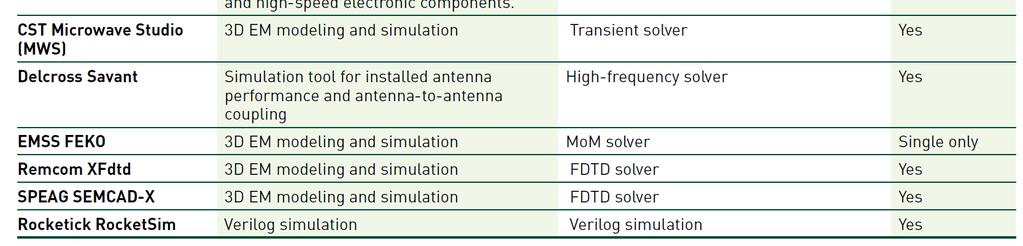
52 GPU-accelerated CEM Applications 52

53 GPU-acceleration of ANSYS HFSS Average speed up of 2.41x and a maximum of 5.21x on a Tesla K20 53
54 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 54

 K6000 (12")
55 NVIDIA Kepler family GPUs for CAE simulations K20 (5 GB) K20X (6 GB) K40 (12 GB) K6000 (12 GB) 55




56 MAXIMUS Solution for Workstations Visual Computing NVIDIA MAXIMUS Parallel Computing Intelligent GPU job Allocation Unified Driver for Quadro + Tesla CAD Operations FEA ISV Application Certifications HP, Dell, Lenovo, others Pre-processing CFD Now Kepler-based GPUs Post-processing CEM Available Since November
57 AGENDA GPUs in Enterprise Computing Business Challenges in Product Development NVIDIA GPUs for CAE Applications Computational Fluid Dynamics (CFD) Applications Computational Structural Mechanics (CSM) Applications Computational Electro Magnetics (CEM) Applications NVIDIA Solutions Value of GPU-accelerated Simulations 57



58 Benefits of GPU-accelerated simulations More simulations in the same amount of time or same number of simulations in less amount of time Improve productquality Faster time-tomarket Complex simulations More design points can be analyzed for better-quality products without slipping project schedules Simulation times can be cut into half, thus shorter product development times Mesh sizes can be doubled or advanced models can be used without increasing simulation times 58
59 Thank you Bhushan Desam 59
Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs
 Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Presented at the 2014 ANSYS Regional Conference- Detroit, June 5, 2014 Maximize automotive simulation productivity with ANSYS HPC and NVIDIA GPUs Bhushan Desam, Ph.D. NVIDIA Corporation 1 NVIDIA Enterprise
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs. Baskar Rajagopalan Accelerated Computing, NVIDIA
 Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
Faster Innovation - Accelerating SIMULIA Abaqus Simulations with NVIDIA GPUs Baskar Rajagopalan Accelerated Computing, NVIDIA 1 Engineering & IT Challenges/Trends NVIDIA GPU Solutions AGENDA Abaqus GPU
The Visual Computing Company
 The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
The Visual Computing Company GPU Acceleration Benefits for Applied CAE Axel Koehler, Senior Solutions Architect HPC, NVIDIA HPC Advisory Council Meeting, April 2014, Lugano Outline General overview about
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA
 Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Stan Posey, CAE Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA and HPC Evolution of GPUs Public, based in Santa Clara, CA ~$4B revenue ~5,500 employees Founded in 1999 with primary business in
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU. Robert Strzodka NVAMG Project Lead
 Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Accelerated ANSYS Fluent: Algebraic Multigrid on a GPU Robert Strzodka NVAMG Project Lead A Parallel Success Story in Five Steps 2 Step 1: Understand Application ANSYS Fluent Computational Fluid Dynamics
Why HPC for. ANSYS Mechanical and ANSYS CFD?
 Why HPC for ANSYS Mechanical and ANSYS CFD? 1 HPC Defined High Performance Computing (HPC) at ANSYS: An ongoing effort designed to remove computing limitations from engineers who use computer aided engineering
Why HPC for ANSYS Mechanical and ANSYS CFD? 1 HPC Defined High Performance Computing (HPC) at ANSYS: An ongoing effort designed to remove computing limitations from engineers who use computer aided engineering
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
Performance Benefits of NVIDIA GPUs for LS-DYNA
 Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Performance Benefits of NVIDIA GPUs for LS-DYNA Mr. Stan Posey and Dr. Srinivas Kodiyalam NVIDIA Corporation, Santa Clara, CA, USA Summary: This work examines the performance characteristics of LS-DYNA
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Solving Large Complex Problems. Efficient and Smart Solutions for Large Models
 Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Solving Large Complex Problems Efficient and Smart Solutions for Large Models 1 ANSYS Structural Mechanics Solutions offers several techniques 2 Current trends in simulation show an increased need for
Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations
 Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Performance Brief Quad-Core Workstation Enhancing Analysis-Based Design with Quad-Core Intel Xeon Processor-Based Workstations With eight cores and up to 80 GFLOPS of peak performance at your fingertips,
Application of GPU technology to OpenFOAM simulations
 Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
Application of GPU technology to OpenFOAM simulations Jakub Poła, Andrzej Kosior, Łukasz Miroslaw jakub.pola@vratis.com, www.vratis.com Wroclaw, Poland Agenda Motivation Partial acceleration SpeedIT OpenFOAM
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
GPU PROGRESS AND DIRECTIONS IN APPLIED CFD
 Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
Eleventh International Conference on CFD in the Minerals and Process Industries CSIRO, Melbourne, Australia 7-9 December 2015 GPU PROGRESS AND DIRECTIONS IN APPLIED CFD Stan POSEY 1*, Simon SEE 2, and
OpenFOAM + GPGPU. İbrahim Özküçük
 OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
ANSYS HPC. Technology Leadership. Barbara Hutchings ANSYS, Inc. September 20, 2011
 ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
ANSYS HPC Technology Leadership Barbara Hutchings barbara.hutchings@ansys.com 1 ANSYS, Inc. September 20, Why ANSYS Users Need HPC Insight you can t get any other way HPC enables high-fidelity Include
Stan Posey NVIDIA, Santa Clara, CA, USA;
 Stan Posey NVIDIA, Santa Clara, CA, USA; sposey@nvidia.com Agenda: GPU Progress and Directions for CAE Introduction of GPUs in HPC Progress of CFD on GPUs Review of OpenFOAM on GPUs Discussion on WRF Developments
Stan Posey NVIDIA, Santa Clara, CA, USA; sposey@nvidia.com Agenda: GPU Progress and Directions for CAE Introduction of GPUs in HPC Progress of CFD on GPUs Review of OpenFOAM on GPUs Discussion on WRF Developments
HPC and IT Issues Session Agenda. Deployment of Simulation (Trends and Issues Impacting IT) Mapping HPC to Performance (Scaling, Technology Advances)
 Mapping HPC to Performance (Scaling, Technology Advances)") HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
HPC and IT Issues Session Agenda Deployment of Simulation (Trends and Issues Impacting IT) Discussion Mapping HPC to Performance (Scaling, Technology Advances) Discussion Optimizing IT for Remote Access
Understanding Hardware Selection to Speedup Your CFD and FEA Simulations
 Understanding Hardware Selection to Speedup Your CFD and FEA Simulations 1 Agenda Why Talking About Hardware HPC Terminology ANSYS Work-flow Hardware Considerations Additional resources 2 Agenda Why Talking
Understanding Hardware Selection to Speedup Your CFD and FEA Simulations 1 Agenda Why Talking About Hardware HPC Terminology ANSYS Work-flow Hardware Considerations Additional resources 2 Agenda Why Talking
ANSYS High. Computing. User Group CAE Associates
 ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
ANSYS High Performance Computing User Group 010 010 CAE Associates Parallel Processing in ANSYS ANSYS offers two parallel processing methods: Shared-memory ANSYS: Shared-memory ANSYS uses the sharedmemory
Multi-GPU simulations in OpenFOAM with SpeedIT technology.
 Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
Multi-GPU simulations in OpenFOAM with SpeedIT technology. Attempt I: SpeedIT GPU-based library of iterative solvers for Sparse Linear Algebra and CFD. Current version: 2.2. Version 1.0 in 2008. CMRS format
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup
 The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
The Cray CX1 puts massive power and flexibility right where you need it in your workgroup Up to 96 cores of Intel 5600 compute power 3D visualization Up to 32TB of storage GPU acceleration Small footprint
The Fermi GPU and HPC Application Breakthroughs
 The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
The Fermi GPU and HPC Application Breakthroughs Peng Wang, PhD HPC Developer Technology Group Stan Posey HPC Industry Development NVIDIA, Santa Clara, CA, USA NVIDIA Corporation 2009 Overview GPU Computing:
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
GPU-Accelerated Algebraic Multigrid for Commercial Applications. Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA
 GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
GPU-Accelerated Algebraic Multigrid for Commercial Applications Joe Eaton, Ph.D. Manager, NVAMG CUDA Library NVIDIA ANSYS Fluent 2 Fluent control flow Accelerate this first Non-linear iterations Assemble
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS
 S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
S0432 NEW IDEAS FOR MASSIVELY PARALLEL PRECONDITIONERS John R Appleyard Jeremy D Appleyard Polyhedron Software with acknowledgements to Mark A Wakefield Garf Bowen Schlumberger Outline of Talk Reservoir
GPU Computing fuer rechenintensive Anwendungen. Axel Koehler NVIDIA
 GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
GPU Computing fuer rechenintensive Anwendungen Axel Koehler NVIDIA GeForce Quadro Tegra Tesla 2 Continued Demand for Ever Faster Supercomputers First-principles simulation of combustion for new high-efficiency,
Engineers can be significantly more productive when ANSYS Mechanical runs on CPUs with a high core count. Executive Summary
 white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
white paper Computer-Aided Engineering ANSYS Mechanical on Intel Xeon Processors Engineer Productivity Boosted by Higher-Core CPUs Engineers can be significantly more productive when ANSYS Mechanical runs
Recent Advances in ANSYS Toward RDO Practices Using optislang. Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH
 Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
Recent Advances in ANSYS Toward RDO Practices Using optislang Wim Slagter, ANSYS Inc. Herbert Güttler, MicroConsult GmbH 1 Product Development Pressures Source: Engineering Simulation & HPC Usage Survey
Performance of Implicit Solver Strategies on GPUs
 9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
9. LS-DYNA Forum, Bamberg 2010 IT / Performance Performance of Implicit Solver Strategies on GPUs Prof. Dr. Uli Göhner DYNAmore GmbH Stuttgart, Germany Abstract: The increasing power of GPUs can be used
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
Krishnan Suresh Associate Professor Mechanical Engineering
 Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Large Scale FEA on the GPU Krishnan Suresh Associate Professor Mechanical Engineering High-Performance Trick Computations (i.e., 3.4*1.22): essentially free Memory access determines speed of code Pick
Industrial achievements on Blue Waters using CPUs and GPUs
 Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
Industrial achievements on Blue Waters using CPUs and GPUs HPC User Forum, September 17, 2014 Seattle Seid Korić PhD Technical Program Manager Associate Adjunct Professor koric@illinois.edu Think Big!
FOR P3: A monolithic multigrid FEM solver for fluid structure interaction
 FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
Large-scale Gas Turbine Simulations on GPU clusters
 Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
Large-scale Gas Turbine Simulations on GPU clusters Tobias Brandvik and Graham Pullan Whittle Laboratory University of Cambridge A large-scale simulation Overview PART I: Turbomachinery PART II: Stencil-based
WHAT S NEW IN GRID 7.0. Mason Wu, GRID & ProViz Solutions Architect Nov. 2018
 WHAT S NEW IN GRID 7.0 Mason Wu, GRID & ProViz Solutions Architect Nov. 2018 VIRTUAL GPU OCTOBER 2018 (GRID 7.0) Unprecedented Performance & Manageability FPO FPO Multi-vGPU Support World s Most Powerful
WHAT S NEW IN GRID 7.0 Mason Wu, GRID & ProViz Solutions Architect Nov. 2018 VIRTUAL GPU OCTOBER 2018 (GRID 7.0) Unprecedented Performance & Manageability FPO FPO Multi-vGPU Support World s Most Powerful
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
TFLOP Performance for ANSYS Mechanical
 TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
TFLOP Performance for ANSYS Mechanical Dr. Herbert Güttler Engineering GmbH Holunderweg 8 89182 Bernstadt www.microconsult-engineering.de Engineering H. Güttler 19.06.2013 Seite 1 May 2009, Ansys12, 512
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Algorithms, System and Data Centre Optimisation for Energy Efficient HPC
 2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
2015-09-14 Algorithms, System and Data Centre Optimisation for Energy Efficient HPC Vincent Heuveline URZ Computing Centre of Heidelberg University EMCL Engineering Mathematics and Computing Lab 1 Energy
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
Computing on GPU Clusters
 Computing on GPU Clusters Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009
Computing on GPU Clusters Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009
GPU-based Parallel Reservoir Simulators
 GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
GPU-based Parallel Reservoir Simulators Zhangxin Chen 1, Hui Liu 1, Song Yu 1, Ben Hsieh 1 and Lei Shao 1 Key words: GPU computing, reservoir simulation, linear solver, parallel 1 Introduction Nowadays
Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project
 Workshop HPC enabling of OpenFOAM for CFD applications Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project A. De Maio (1), V. Krastev (2), P. Lanucara (3),
Workshop HPC enabling of OpenFOAM for CFD applications Aerodynamics of a hi-performance vehicle: a parallel computing application inside the Hi-ZEV project A. De Maio (1), V. Krastev (2), P. Lanucara (3),
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs
 3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
3D Helmholtz Krylov Solver Preconditioned by a Shifted Laplace Multigrid Method on Multi-GPUs H. Knibbe, C. W. Oosterlee, C. Vuik Abstract We are focusing on an iterative solver for the three-dimensional
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud
 Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud CFD Support s OpenFOAM and UberCloud Containers enable efficient, effective, and easy access and use of MEET THE TEAM End-User/CFD
Team 194: Aerodynamic Study of Airflow around an Airfoil in the EGI Cloud CFD Support s OpenFOAM and UberCloud Containers enable efficient, effective, and easy access and use of MEET THE TEAM End-User/CFD
GPU Cluster Computing for FEM
 GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
GPU Cluster Computing for FEM Dominik Göddeke Sven H.M. Buijssen, Hilmar Wobker and Stefan Turek Angewandte Mathematik und Numerik TU Dortmund, Germany dominik.goeddeke@math.tu-dortmund.de GPU Computing
SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND
 Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
PARALUTION - a Library for Iterative Sparse Methods on CPU and GPU
 - a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
- a Library for Iterative Sparse Methods on CPU and GPU Dimitar Lukarski Division of Scientific Computing Department of Information Technology Uppsala Programming for Multicore Architectures Research Center
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of Earth s Mantle
 ICES Student Forum The University of Texas at Austin, USA November 4, 204 Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of
ICES Student Forum The University of Texas at Austin, USA November 4, 204 Parallel High-Order Geometric Multigrid Methods on Adaptive Meshes for Highly Heterogeneous Nonlinear Stokes Flow Simulations of
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC
 Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Fourth Workshop on Accelerator Programming Using Directives (WACCPD), Nov. 13, 2017 Implicit Low-Order Unstructured Finite-Element Multiple Simulation Enhanced by Dense Computation using OpenACC Takuma
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs
 Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Efficient Finite Element Geometric Multigrid Solvers for Unstructured Grids on GPUs Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
GPU Acceleration of Matrix Algebra. Dr. Ronald C. Young Multipath Corporation. fmslib.com
 GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
GPU Acceleration of Matrix Algebra Dr. Ronald C. Young Multipath Corporation FMS Performance History Machine Year Flops DEC VAX 1978 97,000 FPS 164 1982 11,000,000 FPS 164-MAX 1985 341,000,000 DEC VAX
Using GPUs for unstructured grid CFD
 Using GPUs for unstructured grid CFD Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Schlumberger Abingdon Technology Centre, February 17th, 2011
Using GPUs for unstructured grid CFD Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Schlumberger Abingdon Technology Centre, February 17th, 2011
Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering
 State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
State of the art distributed parallel computational techniques in industrial finite element analysis Second Conference on Parallel, Distributed, Grid and Cloud Computing for Engineering Ajaccio, France
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Accelerating High Performance Computing.
 Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Accelerating High Performance Computing http://www.nvidia.com/tesla Computing The 3 rd Pillar of Science Drug Design Molecular Dynamics Seismic Imaging Reverse Time Migration Automotive Design Computational
Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program
 Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program C.T. Vaughan, D.C. Dinge, P.T. Lin, S.D. Hammond, J. Cook, C. R. Trott, A.M. Agelastos, D.M. Pase, R.E. Benner,
Early Experiences with Trinity - The First Advanced Technology Platform for the ASC Program C.T. Vaughan, D.C. Dinge, P.T. Lin, S.D. Hammond, J. Cook, C. R. Trott, A.M. Agelastos, D.M. Pase, R.E. Benner,
Block Distributed Schur Complement Preconditioners for CFD Computations on Many-Core Systems
 Block Distributed Schur Complement Preconditioners for CFD Computations on Many-Core Systems Dr.-Ing. Achim Basermann, Melven Zöllner** German Aerospace Center (DLR) Simulation- and Software Technology
Block Distributed Schur Complement Preconditioners for CFD Computations on Many-Core Systems Dr.-Ing. Achim Basermann, Melven Zöllner** German Aerospace Center (DLR) Simulation- and Software Technology
Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans
 Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans Introduction Company STAR-CCM+ Agenda Wind engineering at CD-adapco STAR-CCM+ & EnviroWizard Developments for Offshore Simulation CD-adapco:
Recent Advances in Modelling Wind Parks in STAR CCM+ Steve Evans Introduction Company STAR-CCM+ Agenda Wind engineering at CD-adapco STAR-CCM+ & EnviroWizard Developments for Offshore Simulation CD-adapco:
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010
 Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
Making Supercomputing More Available and Accessible Windows HPC Server 2008 R2 Beta 2 Microsoft High Performance Computing April, 2010 Windows HPC Server 2008 R2 Windows HPC Server 2008 R2 makes supercomputing
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING
 TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
TECHNICAL OVERVIEW ACCELERATED COMPUTING AND THE DEMOCRATIZATION OF SUPERCOMPUTING Accelerated computing is revolutionizing the economics of the data center. HPC enterprise and hyperscale customers deploy
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
HPC-CINECA infrastructure: The New Marconi System. HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati,
 HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
HPC-CINECA infrastructure: The New Marconi System HPC methods for Computational Fluid Dynamics and Astrophysics Giorgio Amati, g.amati@cineca.it Agenda 1. New Marconi system Roadmap Some performance info
CST STUDIO SUITE R Supported GPU Hardware
 CST STUDIO SUITE R 2017 Supported GPU Hardware 1 Supported Hardware CST STUDIO SUITE currently supports up to 8 GPU devices in a single host system, meaning each number of GPU devices between 1 and 8 is
CST STUDIO SUITE R 2017 Supported GPU Hardware 1 Supported Hardware CST STUDIO SUITE currently supports up to 8 GPU devices in a single host system, meaning each number of GPU devices between 1 and 8 is
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
ANSYS - Workbench Overview. From zero to results. AGH 2014 April, 2014 W0-1
 ANSYS - Workbench Overview From zero to results 2014 W0-1 Runing ANSYS WEiP ANSYS We are going to work in most advanced ANSYS Workbench W0-2 ANSYS Workbench WEiP What is Workbench? Platform for integration
ANSYS - Workbench Overview From zero to results 2014 W0-1 Runing ANSYS WEiP ANSYS We are going to work in most advanced ANSYS Workbench W0-2 ANSYS Workbench WEiP What is Workbench? Platform for integration
FEMAP/NX NASTRAN PERFORMANCE TUNING
 FEMAP/NX NASTRAN PERFORMANCE TUNING Chris Teague - Saratech (949) 481-3267 www.saratechinc.com NX Nastran Hardware Performance History Running Nastran in 1984: Cray Y-MP, 32 Bits! (X-MP was only 24 Bits)
FEMAP/NX NASTRAN PERFORMANCE TUNING Chris Teague - Saratech (949) 481-3267 www.saratechinc.com NX Nastran Hardware Performance History Running Nastran in 1984: Cray Y-MP, 32 Bits! (X-MP was only 24 Bits)
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers
 Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
Towards a complete FEM-based simulation toolkit on GPUs: Geometric Multigrid solvers Markus Geveler, Dirk Ribbrock, Dominik Göddeke, Peter Zajac, Stefan Turek Institut für Angewandte Mathematik TU Dortmund,
smooth coefficients H. Köstler, U. Rüde
 A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
A robust multigrid solver for the optical flow problem with non- smooth coefficients H. Köstler, U. Rüde Overview Optical Flow Problem Data term and various regularizers A Robust Multigrid Solver Galerkin
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI
 FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI MpCCI 4.5.2 Release Notes MpCCI 4.5.2 GUI Improve the start and error management of simulation codes in MpCCI GUI. Enhanced rules lists
FRAUNHOFER INSTITUTE FOR ALGORITHMS AND SCIENTIFIC COMPUTING SCAI MpCCI 4.5.2 Release Notes MpCCI 4.5.2 GUI Improve the start and error management of simulation codes in MpCCI GUI. Enhanced rules lists
Enhanced Oil Recovery simulation Performances on New Hybrid Architectures
 Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources Enhanced Oil Recovery simulation Performances on New Hybrid Architectures A. Anciaux, J-M.
Renewable energies Eco-friendly production Innovative transport Eco-efficient processes Sustainable resources Enhanced Oil Recovery simulation Performances on New Hybrid Architectures A. Anciaux, J-M.
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
TESLA P100 PERFORMANCE GUIDE. Deep Learning and HPC Applications
 TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA P PERFORMANCE GUIDE Deep Learning and HPC Applications SEPTEMBER 217 TESLA P PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Mesh Morphing and the Adjoint Solver in ANSYS R14.0. Simon Pereira Laz Foley
 Mesh Morphing and the Adjoint Solver in ANSYS R14.0 Simon Pereira Laz Foley 1 Agenda Fluent Morphing-Optimization Feature RBF Morph with ANSYS DesignXplorer Adjoint Solver What does an adjoint solver do,
Mesh Morphing and the Adjoint Solver in ANSYS R14.0 Simon Pereira Laz Foley 1 Agenda Fluent Morphing-Optimization Feature RBF Morph with ANSYS DesignXplorer Adjoint Solver What does an adjoint solver do,
OzenCloud Case Studies
 OzenCloud Case Studies Case Studies, April 20, 2015 ANSYS in the Cloud Case Studies: Aerodynamics & fluttering study on an aircraft wing using fluid structure interaction 1 Powered by UberCloud http://www.theubercloud.com
OzenCloud Case Studies Case Studies, April 20, 2015 ANSYS in the Cloud Case Studies: Aerodynamics & fluttering study on an aircraft wing using fluid structure interaction 1 Powered by UberCloud http://www.theubercloud.com
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Tesla GPU Computing A Revolution in High Performance Computing Mark Harris, NVIDIA Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory
Particleworks: Particle-based CAE Software fully ported to GPU
 Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Particleworks: Particle-based CAE Software fully ported to GPU Introduction PrometechVideo_v3.2.3.wmv 3.5 min. Particleworks Why the particle method? Existing methods FEM, FVM, FLIP, Fluid calculation
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of